Word ドキュメント内のハイパーリンクは、読者が他の Web ページ、外部ファイル、電子メールアドレス、またはドキュメントの特定の場所にすばやくアクセスできるようにします。ドキュメントに多数のハイパーリンクが含まれている場合には、手動でリンクを取得するよりも、プログラミングされた方法でリンク情報を直接検索して抽出するほうが時間の節約になります。この記事では、Spire.Doc for Java を使用して Word でハイパーリンクを検索して抽出する方法を示します。
Spire.Doc for Java をインストールします
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.11.6</version>
</dependency>
</dependencies>Word で指定したハイパーリンクを検索して抽出する
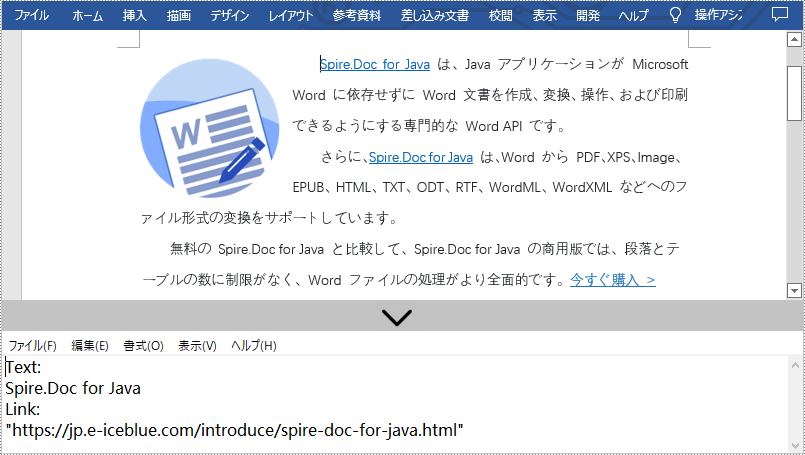
Spire.Doc for Java が提供する Field.getFieldText() メソッドと Field.getValue() メソッドは、それぞれハイパーリンクのテキストとリンクの取得をサポートしています。具体的な手順は以下の通りです。
- Document インスタンスを作成し、Document.loadFromFile() メソッドを使用して Word ドキュメントをディスクからロードします。
- ArrayList<Field> のオブジェクトを作成します。
- セクション内のアイテムをループして、すべてのハイパーリンクを検索します。
- Field.getFieldText() メソッドを使用して、最初のハイパーリンクのテキストを取得します。Field.getValue()メソッドを使用して最初のハイパーリンクのリンクを取得します。
- カスタム writeStringToText() メソッドを使用して、最初のハイパーリンクのテキストとリンクを TXT に保存します。
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.Field;
import java.io.*;
import java.util.ArrayList;
public class findHyperlinks {
public static void main(String[] args) throws IOException {
//Documentインスタンスを作成し、Wordをディスクからロードする
String input = "sample.docx";
Document doc = new Document();
doc.loadFromFile(input);
//ArrayList<Field>のオブジェクトを作成する
ArrayList<Field> hyperlinks = new ArrayList<Field>();
//セクション内のアイテムをループして、すべてのハイパーリンクを検索する
for (Section section : (Iterable<Section>) doc.getSections()) {
for (DocumentObject object : (Iterable<DocumentObject>) section.getBody().getChildObjects()) {
if (object.getDocumentObjectType().equals(DocumentObjectType.Paragraph)) {
Paragraph paragraph = (Paragraph) object;
for (DocumentObject cObject : (Iterable<DocumentObject>) paragraph.getChildObjects()) {
if (cObject.getDocumentObjectType().equals(DocumentObjectType.Field)) {
Field field = (Field) cObject;
if (field.getType().equals(FieldType.Field_Hyperlink)) {
hyperlinks.add(field);
}
}
}
}
}
}
//最初のハイパーリンクのテキストとリンクを取得する
String hyperlinksText = hyperlinks.get(0).getFieldText();
String hyperlinkAddress = hyperlinks.get(0).getValue();
//最初のハイパーリンクのテキストとリンクをTXTに保存する
String output = "result.txt";
writeStringToText("Text:\r\n" + hyperlinksText+ "\r\n" + "Link:\r\n" + hyperlinkAddress, output);
}
//TXTファイルにテキストとリンクを書き込む方法を作成する
public static void writeStringToText(String content, String textFileName) throws IOException {
File file = new File(textFileName);
if (file.exists())
{
file.delete();
}
FileWriter fWriter = new FileWriter(textFileName, true);
try {
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Word ですべてのハイパーリンクを検索して抽出する
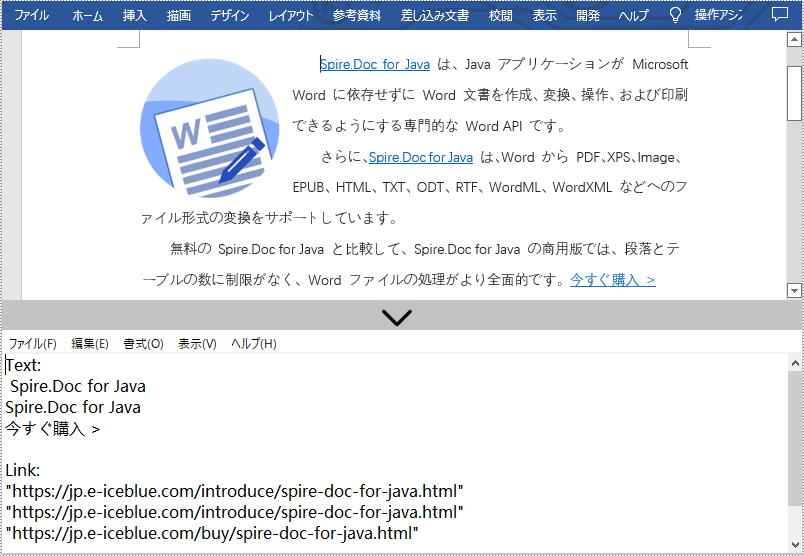
Spire.Doc for Java が提供する Field.getFieldText() メソッドと Field.getValue() メソッドは、それぞれハイパーリンクのテキストとリンクの取得をサポートしています。具体的な手順は以下の通りです。
- Document インスタンスを作成し、Document.loadFromFile() メソッドを使用して Word ドキュメントをディスクからロードします。
- ArrayList<Field> のオブジェクトを作成します。
- セクション内のアイテムをループして、すべてのハイパーリンクを検索します。
- Field.getFieldText() メソッドを使用して、ハイパーリンクのテキストを取得します。Field.getValue() メソッドを使用してハイパーリンクのリンクを取得します。
- カスタム writeStringToText() メソッドを使用して、すべてのハイパーリンクのテキストとリンクをTXTに保存します。
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.Field;
import java.io.*;
import java.util.ArrayList;
public class findHyperlinks {
public static void main(String[] args) throws IOException {
//Documentインスタンスを作成し、Wordをディスクからロードする
String input = "sample.docx";
Document doc = new Document();
doc.loadFromFile(input);
//ArrayList<Field>のオブジェクトを作成する
ArrayList<Field> hyperlinks = new ArrayList<Field>();
String hyperlinkText = "";
String hyperlinkAddress = "";
//セクション内のアイテムをループして、すべてのハイパーリンクを検索する
for (Section section : (Iterable<Section>) doc.getSections()) {
for (DocumentObject object : (Iterable<DocumentObject>) section.getBody().getChildObjects()) {
if (object.getDocumentObjectType().equals(DocumentObjectType.Paragraph)) {
Paragraph paragraph = (Paragraph) object;
for (DocumentObject cObject : (Iterable<DocumentObject>) paragraph.getChildObjects()) {
if (cObject.getDocumentObjectType().equals(DocumentObjectType.Field)) {
Field field = (Field) cObject;
if (field.getType().equals(FieldType.Field_Hyperlink)) {
hyperlinks.add(field);
//すべてのハイパーリンクのテキストとリンクを取得する
hyperlinkText += field.getFieldText() + "\r\n";
hyperlinkAddress += field.getValue() + "\r\n";
}
}
}
}
}
}
//テキストとリンクをTXTに保存する
String output = "result.txt";
writeStringToText("Text:\r\n " + hyperlinkText + "\r\n" + "Link:\r\n" + hyperlinkAddress + "\r\n", output);
}
//TXTにテキストとリンクを書き込む方法を作成する
public static void writeStringToText(String content, String textFileName) throws IOException {
File file = new File(textFileName);
if (file.exists())
{
file.delete();
}
FileWriter fWriter = new FileWriter(textFileName, true);
try {
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





