テキストと画像は、Word 文書のコンテンツを豊かにする重要な要素です。文書内のテキストや画像を個別に処理する必要がある場合、プログラムで Word 文書から抽出することができます。テキストを手動でコピーするよりも、テキストを抽出することで大規模な文書をより便利かつ効率的に処理することができます。また、画像を抽出することで文書内の画像を編集したり、他人と簡単に共有することができます。この記事では、Spire.Doc for Java を使用して Word 文書からテキストと画像を抽出する方法を示します。
Spire.Doc for Java をインストールします
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.6.0</version>
</dependency>
</dependencies>Java で Word 文書からテキストの抽出方法
Spire.Doc for Java は、Word 文書からテキストを抽出し、txt ファイル形式として保存することをサポートしています。これにより、ユーザーはデバイス制限なしにテキストコンテンツを表示できます。以下は、Word 文書からテキストを抽出するための詳細な手順です。
- Document オブジェクトを作成します。
- Document.loadFromFile メソッドを使用して Word 文書をロードします。
- Document.getText() メソッドを使用して、Word 文書から文字列としてテキストを取得します。
- writeStringToTxt() メソッドを呼び出して、文字列を指定されたテキストファイルに書き込みます。
- Java
import com.spire.doc.Document;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractText {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成してWord文書をロードする
Document document = new Document();
document.loadFromFile("sample1.docx");
//文書から文字列としてテキストを取得する
String text=document.getText();
//文字列を.txtファイルに書き込む
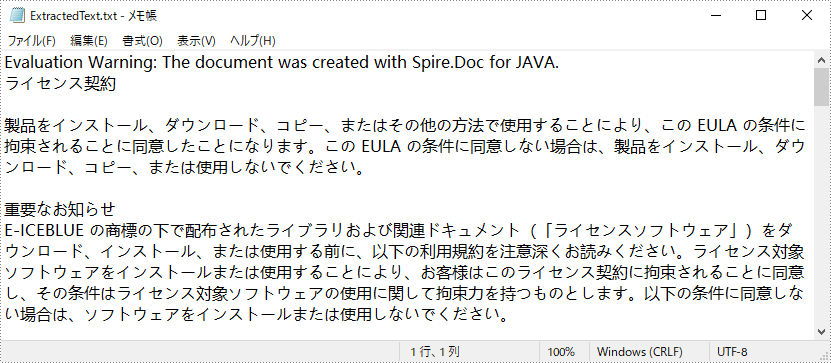
writeStringToTxt(text,"ExtractedText.txt");
}
public static void writeStringToTxt(String content, String txtFileName) throws IOException{
FileWriter fWriter= new FileWriter(txtFileName,true);
try {
fWriter.write(content);
}catch(IOException ex){
ex.printStackTrace();
}finally{
try{
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Java で Word 文書から画像の抽出方法
画像を抽出することにより、ユーザーは簡単に他のアプリケーションに画像データをインポートしてさらなる処理ができます。Spire.Doc for Java では、Word 文書から画像を抽出し、指定されたパスに保存することができます。以下は詳細な手順です。
- Document オブジェクトを作成します。
- Document.loadFromFile() メソッドを使用して Word 文書をロードします。
- 複合オブジェクトのキューを作成します。
- Queue<ICompositeObject>.add(ICompositeObject e) メソッドを使用して、ルートドキュメントの要素をキューに追加します。
- 抽出された画像を格納する ArrayList オブジェクトを作成します。
- ドキュメントツリーをループし、各ノードの子ノードをループして、複合オブジェクトまたは画像オブジェクトをチェックします。
- 子要素が複合オブジェクトかどうかを確認します。そうである場合は、さらに処理するためにキューに追加します。
- 子要素が画像オブジェクトかどうかを確認します。そうである場合は、その画像データを抽出して、画像リストに追加します。
- ImageIO.write(RenderedImage im, String formatName, File output) メソッドを使用して、画像を指定されたフォルダに保存します。
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import com.spire.doc.interfaces.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.*;
public class ExtractImage {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成してWord文書をロードする
Document document = new Document();
document.loadFromFile("Sample2.docx");
//キューを作成し、ルートドキュメントの要素を追加する
Queue nodes = new LinkedList<>();
nodes.add(document);
//抽出された画像を保存するためのArrayListオブジェクトを作成する
List images = new ArrayList<>();
//ドキュメントツリーをループする
while (nodes.size() > 0) {
ICompositeObject node = nodes.poll();
for (int i = 0; i < node.getChildObjects().getCount(); i++)
{
IDocumentObject child = node.getChildObjects().get(i);
if (child instanceof ICompositeObject)
{
nodes.add((ICompositeObject) child);
}
else if (child.getDocumentObjectType() == DocumentObjectType.Picture)
{
DocPicture picture = (DocPicture) child;
images.add(picture.getImage());
}
}
}
//画像を特定のフォルダに保存する
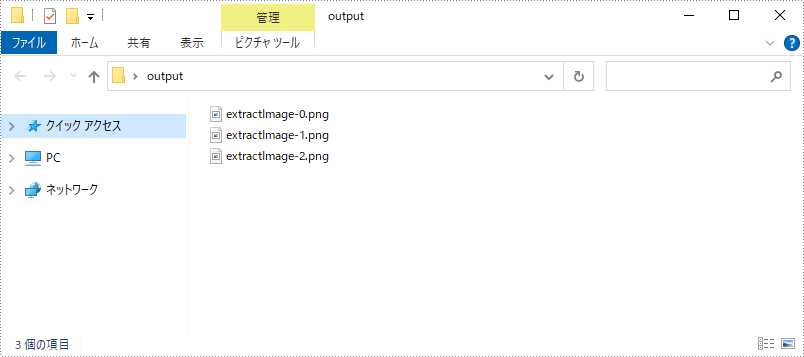
for (int i = 0; i < images.size(); i++) {
File file = new File(String.format("output/extractImage-%d.png", i));
ImageIO.write(images.get(i), "PNG", file);
}
}
} 
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





