表は PDF の請求書や財務報告書によく見られます。MS Excel が提供するツールを使ってデータを分析できるように、PDF の表データを Excel にエクスポートする必要がある場面に遭遇するかもしれません。この記事では、Spire.Office for Java を使って PDF ページから表を抽出し、それを Excel ワークシートに書き込む方法を説明します。
Spire.Office for Java をインストールします
実際には、PDF から表を抽出するために Spire.PDF for Java を使用し、Excel ファイルを生成するために Spire.XLS for Java を使用します。同じプロジェクトでこれらを使用するには、Java プログラムの依存関係として Spire.Office.jar ファイルを追加する必要があります。
JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>9.1.10</version>
</dependency>
</dependencies>PDF から表データを Excel に書き出す
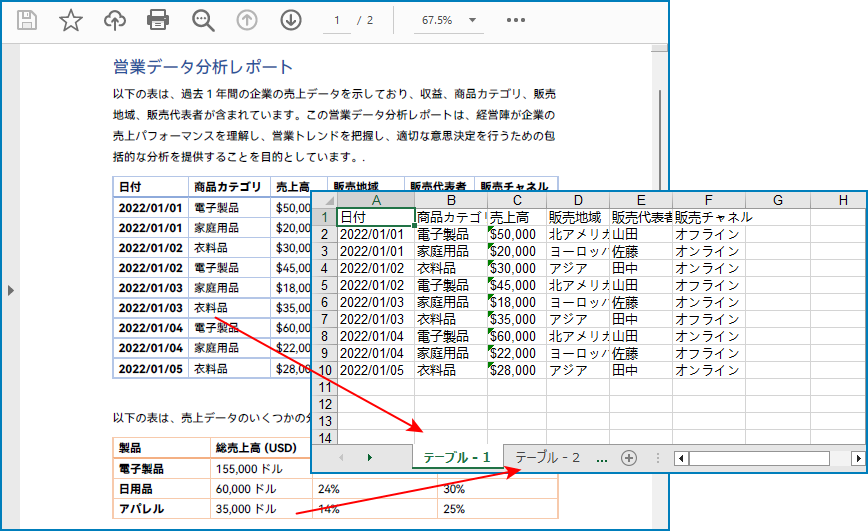
以下は、あるページからすべての表を抽出し、それぞれを独立したワークシートとして Excel ファイルに保存するための主な手順です。
- PdfDocument のオブジェクトを初期化し、PdfDocument.loadFromFile() メソッドを用いて PDF ドキュメントを読み込みます。
- PdfTableExtractor のオブジェクトを作成し、このクラスの下で extactTable(int pageIndex) メソッドを呼び出して、最初のページのすべての表を抽出します。
- Workbook のインスタンスを作成します。
- PdfTable[] 配列内の表をループし、インデックスで特定の表を取得します。
- Workbook.getWorksheets.add() メソッドを使用して ワークブックにワークシートを追加します。
- PDF 表内のセルをループし、PdfTable.getText(int rowIndex, int columnIndex) メソッドを用いて特定のセルの値を取得します。次に、Worksheet.get(int row, int column).setText(String string) メソッドを使って値をワークシートに挿入します。
- Workbook.saveToFile() メソッドを使用して、ワークブックを Excel ファイルに保存します。
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractTableDataAndSaveInExcel {
public static void main(String[] args) {
//PDFドキュメントをロードします
PdfDocument pdf = new PdfDocument("サンプル.pdf");
//PdfTableExtractorインスタンスを作成します
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//最初のページからテーブルを抽出します
PdfTable[] pdfTables = extractor.extractTable(0);
//Workbookオブジェクトを作成します
Workbook wb = new Workbook();
//デフォルトのワークシートを削除します
wb.getWorksheets().clear();
//テーブルが見つかった場合
if (pdfTables != null && pdfTables.length > 0) {
//テーブルをループします
for (int tableNum = 0; tableNum < pdfTables.length; tableNum++) {
//ワークシートをワークブックに追加します
String sheetName = String.format("テーブル - %d", tableNum + 1);
Worksheet sheet = wb.getWorksheets().add(sheetName);
//現在のテーブルの行をループします
for (int rowNum = 0; rowNum < pdfTables[tableNum].getRowCount(); rowNum++) {
//現在のテーブルの列をループします
for (int colNum = 0; colNum < pdfTables[tableNum].getColumnCount(); colNum++) {
//現在のテーブルセルからデータを抽出します
String text = pdfTables[tableNum].getText(rowNum, colNum);
//特定のセルにデータを挿入します
sheet.get(rowNum + 1, colNum + 1).setText(text);
}
}
//列幅を自動調整します
for (int sheetColNum = 0; sheetColNum < sheet.getColumns().length; sheetColNum++) {
sheet.autoFitColumn(sheetColNum + 1);
}
}
}
//ワークブックをExcelファイルに保存します
wb.saveToFile("output/PDFの表をExcelに書き出す.xlsx", ExcelVersion.Version2016);
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





