PDF ドキュメントはもっとも一般的に使われていて、便利な形式です、そのため、PDF ドキュメントにテーブルを使用するのもよくある場合です。しかし PDF ドキュメントは安全性を考慮して、簡単に編集できないです、この時テーブルの内容を抽出したいなら、どうやって操作しますか?この記事で、Spire.PDF for .NET によって提供されるテーブルを抽出するクラスとメソッドを呼び出して、テーブルセルのテキストコンテンツを取得する方法をご紹介します。
環境構成
- Visual Studio 2017
- .net framework 4.6.1
- PDF テストドキュメント
- ライブラリー:Spire.PDF for .NET
Dll ファイルを参照する二つの方法
方法一、NuGet からダウンロードしてインストールします
1、「参照」を右クリックして、「NuGet パッケージの管理」を選択します。
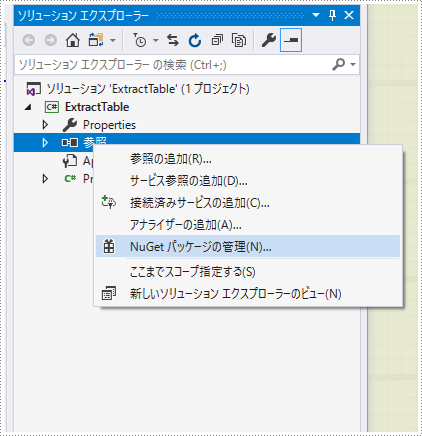
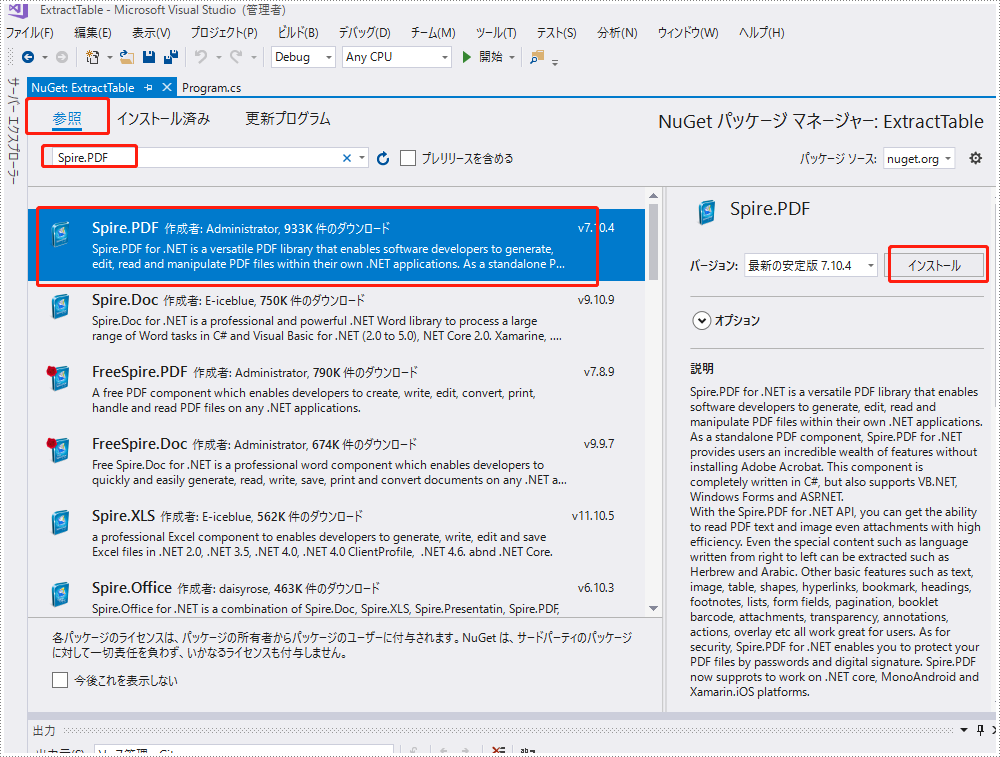
2、「参照」を選択し、検索バーに「Spire.PDF」を入力してインストールします。
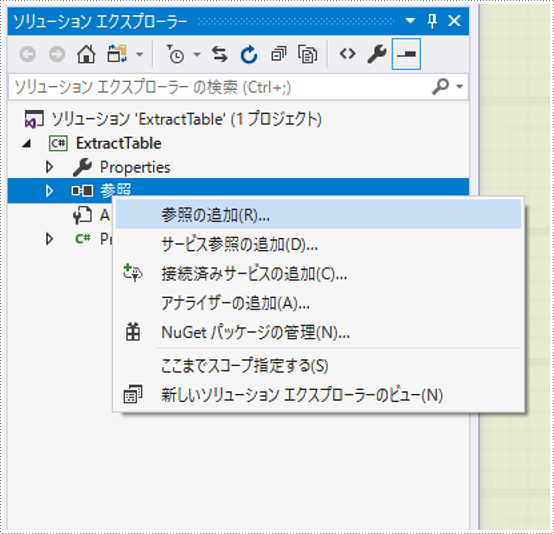
方法二、手動で参照を追加します
1、「参照」を右クリックして、「参照の追加」を選択します。
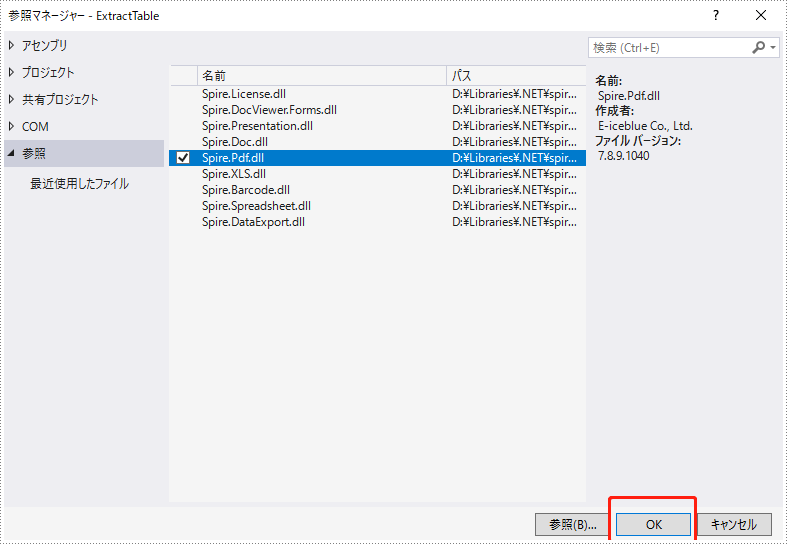
2、「参照」を選択し、「OK」ボタンをクリックします(事前に参照リストに追加する必要があります)
コードの表示:
- C#
using Spire.Pdf;
using Spire.Pdf.Tables;
using Spire.Pdf.Utilities;
using System.IO;
using System.Text;
namespace ExtractTable
{
class Program
{
static void Main(string[] args)
{
//PDFドキュメントをロードする
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("sample.pdf");
StringBuilder builder = new StringBuilder();
//テーブルを抽出する
PdfTableExtractor Extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = null;
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
tableLists = extractor.ExtractTable(pageIndex);
if (tableLists != null && tableLists.Length > 0)
{
foreach (PdfTable table in tableLists)
{
int row = table.GetRowCount();
int column = table.GetColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
string text = table.GetText(i, j);
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//抽出されたテーブルの内容をtxtドキュメントに保存する
File.WriteAllText("ExtractedTable.txt", builder.ToString());
}
}
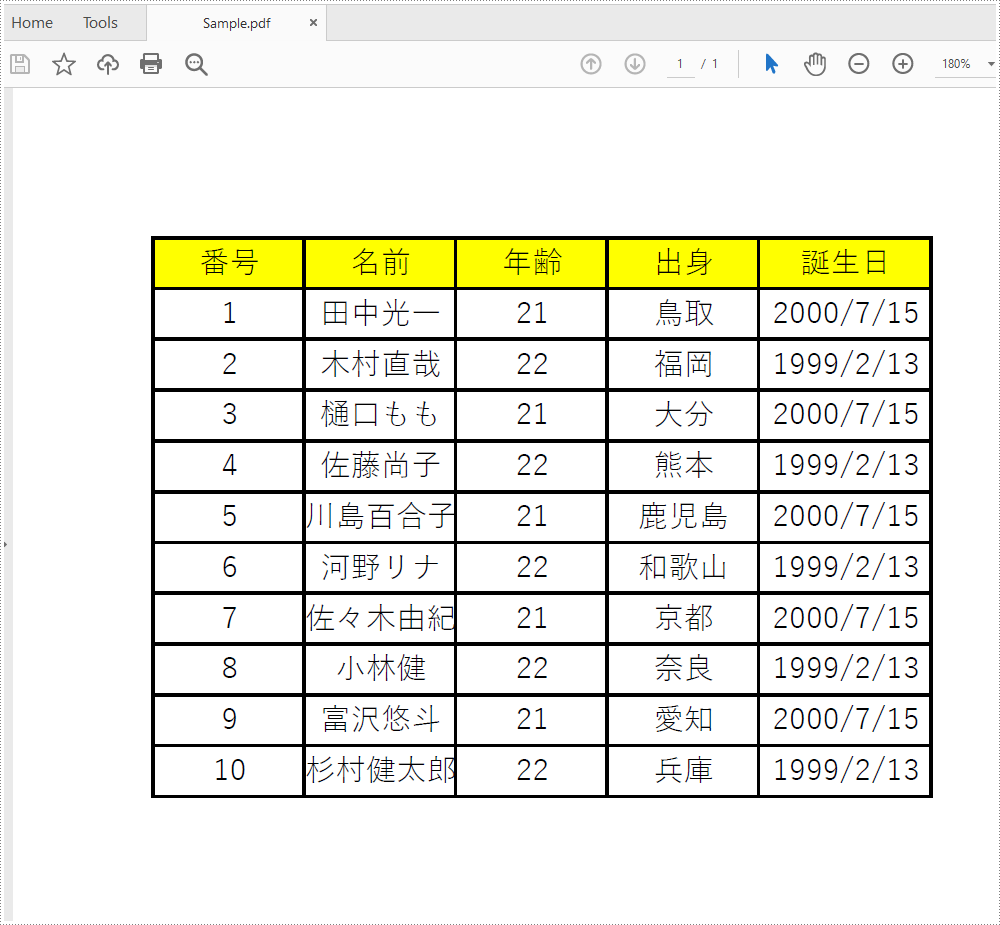
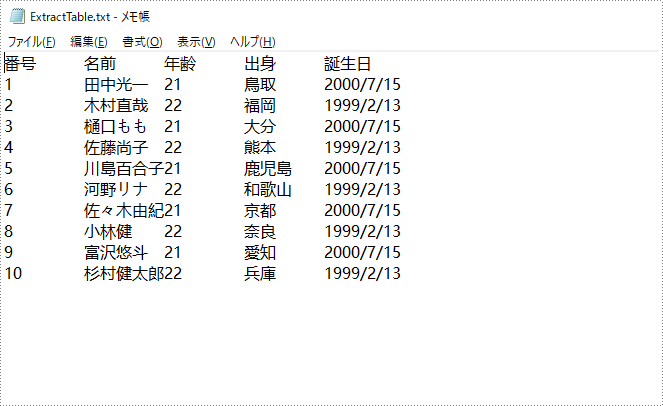
}抽出した結果は以下のように:
以上になりました、最後までお読みいただき、誠にありがとうございます。
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30日間有効な一時ライセンスを取得してください。





