PDF ドキュメントのページレイアウトは固定されており、ユーザーによる変更は許可されていません。PDF コンテンツを再編集するには、PDF を Word に変換するか、PDF からテキストを抽出します。この記事では、Spire.PDF for .NET を使用して、C# および VB.NET でプログラムによって特定の PDF ページからテキストを抽出する方法、特定の長方形領域からテキストを抽出する方法、および SimpleTextExtractionStrategy メソッドでテキストを抽出する方法を示します。
Spire.PDF for.NET をインストールします
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDF特定の PDF ページからテキストを抽出する
Spire.PDF for .NET が提供する PdfDocument.Pages[index] プロパティは、特定のページの取得をサポートします。次に、PdfTextExtractor.ExtractText() メソッドを使用して、特定のページからテキストを抽出します。以下に詳細な操作手順を示します。
- PdfDocument オブジェクトを作成します。
- PdfDocument.LoadFromFile() メソッドを使用して PDF ファイルをロードします。
- PdfDocument.Pages[index] プロパティで特定のページを取得します。
- PdfTextExtractor オブジェクトを作成します。
- PdfTextExtractOptions オブジェクトを作成し、IsExtractAllText プロパティを true に設定します。
- PdfTextExtractor.ExtractText() メソッドを使用して、選択したページからテキストを抽出します。
- 抽出したテキストを TXT ファイルに書き込みます。
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルをロードする
doc.LoadFromFile(@"sample.pdf");
//2ページ目を取得する
PdfPageBase page = doc.Pages[1];
//PdfTextExtractotオブジェクトを作成する
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//PdfTextExtractOptionsオブジェクトを作成する
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//isExtractAllTextをtrueに設定
extractOptions.IsExtractAllText = true;
//ページからテキストを抽出する
string text = textExtractor.ExtractText(extractOptions);
//TXTファイルに書き込み
File.WriteAllText("Extracted.txt", text);
}
}
}Imports System
Imports System.IO
Imports Spire.Pdf
Imports Spire.Pdf.Texts
Namespace ExtractTextFromPage
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentオブジェクトを作成する
Dim doc As PdfDocument = New PdfDocument()
'PDFファイルをロードする
doc.LoadFromFile("sample.pdf")
'2ページ目を取得する
Dim page As PdfPageBase = doc.Pages(1)
'PdfTextExtractotオブジェクトを作成する
Dim textExtractor As PdfTextExtractor = New PdfTextExtractor(page)
'PdfTextExtractOptionsオブジェクトを作成する
Dim extractOptions As PdfTextExtractOptions = New PdfTextExtractOptions()
'isExtractAllTextをtrueに設定
extractOptions.IsExtractAllText = True
'ページからテキストを抽出する
Dim text As String = textExtractor.ExtractText(extractOptions)
'TXTファイルに書き込み
File.WriteAllText("Extracted.txt", text)
End Sub
End Class
End Namespace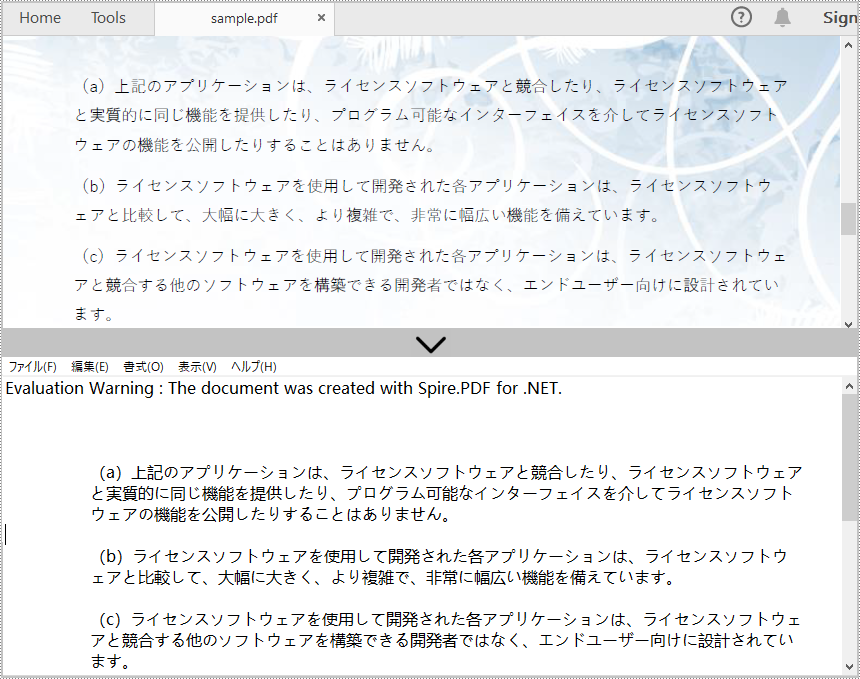
特定の長方形領域からテキストを抽出する
長方形領域からテキストを抽出するには、ExtractArea プロパティで長方形領域を指定します。次に、PdfTextExtractor.ExtractText() メソッドを使用してテキストを抽出します。以下に詳細な操作手順を示します。
- PdfDocument オブジェクトを作成します。
- PdfDocument.LoadFromFile() メソッドを使用して PDF ファイルをロードします。
- PdfDocument.Pages[index] プロパティで特定のページを取得します。
- PdfTextExtractor オブジェクトを作成します。
- PdfTextExtractOptions オブジェクトを作成し、ExtractArea プロパティで長方形領域を指定します。
- PdfTextExtractor.ExtractText() メソッドを使用して長方形領域からテキストを抽出します。
- 抽出したテキストを TXT ファイルに書き込みます。
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルをロードする
doc.LoadFromFile(@"sample.pdf");
//2ページ目を取得する
PdfPageBase page = doc.Pages[1];
//PdfTextExtractorオブジェクトを作成する
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//PdfTextExtractOptionsオブジェクトを作成する
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//長方形領域を指定する
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 190);
//長方形からテキストを抽出する
string text = textExtractor.ExtractText(extractOptions);
//TXTファイルに書き込み
File.WriteAllText("Extracted.txt", text);
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Texts
Imports System.IO
Imports System.Drawing
Namespace ExtractTextFromRectangleArea
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentオブジェクトを作成する
Dim doc As PdfDocument = New PdfDocument()
'PDFファイルをロードする
doc.LoadFromFile("sample.pdf")
'2ページ目を取得する
Dim page As PdfPageBase = doc.Pages(1)
'PdfTextExtractorオブジェクトを作成する
Dim textExtractor As PdfTextExtractor = New PdfTextExtractor(page)
'PdfTextExtractOptionsオブジェクトを作成する
Dim extractOptions As PdfTextExtractOptions = New PdfTextExtractOptions()
'長方形領域を指定する
extractOptions.ExtractArea = New RectangleF(0, 0, 890, 190);
'長方形からテキストを抽出する
Dim text As String = textExtractor.ExtractText(extractOptions)
'TXTファイルに書き込み
File.WriteAllText("Extracted.txt", text)
End Sub
End Class
End Namespace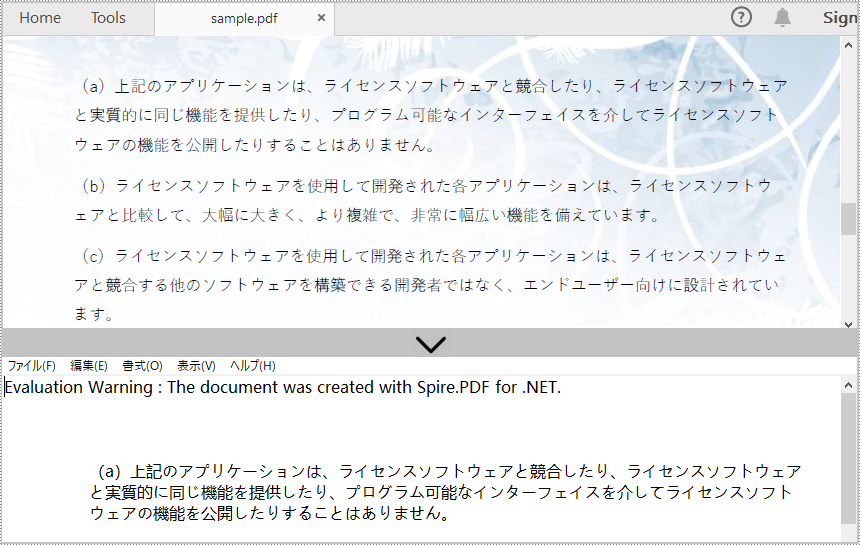
SimpleTextExtractionStrategy メソッドでテキストを抽出する
以上の方法は、行ごとにテキストを抽出するのに適しています。SimpleTextExtractionStrategy メソッドを使用してテキストを抽出すると、各文字列の Y 位置を追跡し、Y 位置が変化したときに出力に改行文字を挿入することができます。以下に詳細な手順を示します。
- PdfDocument オブジェクトを作成します。
- PdfDocument.LoadFromFile() メソッドを使用してPDFファイルをロードします。
- PdfDocument.Pages[index] プロパティで特定のページを取得します。
- PdfTextExtractor オブジェクトを作成します。
- PdfTextExtractOptions オブジェクトを作成し、IsSimpleExtraction プロパティを true に設定します。
- PdfTextExtractor.ExtractText() メソッドを使用して、選択したページからテキストを抽出します。
- 抽出したテキストを TXT ファイルに書き込みます。
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルをロードする
doc.LoadFromFile(@"sample.pdf");
//最初のページを取得する
PdfPageBase page = doc.Pages[0];
//PdfTextExtractorオブジェクトを作成する
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//PdfTextExtractOptionsオブジェクトを作成する
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//IsSimpleExtractionをtrueに設定する
extractOptions.IsSimpleExtraction = true;
//選択したページからテキストを抽出する
string text = textExtractor.ExtractText(extractOptions);
//TXTファイルへの書き込み
File.WriteAllText("Extracted.txt", text);
}
}
}Imports System.IO
Imports Spire.Pdf
Imports Spire.Pdf.Texts
Namespace SimpleExtraction
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentオブジェクトを作成する
Dim doc As PdfDocument = New PdfDocument()
'PDFファイルをロードする
doc.LoadFromFile("sample.pdf");
'最初のページを取得する
Dim page As PdfPageBase = doc.Pages(0)
'PdfTextExtractorオブジェクトを作成する
Dim textExtractor As PdfTextExtractor = New PdfTextExtractor(page)
'PdfTextExtractOptionsオブジェクトを作成する
Dim extractOptions As PdfTextExtractOptions = New PdfTextExtractOptions()
'IsSimpleExtractionをtrueに設定する
extractOptions.IsSimpleExtraction = True
'選択したページからテキストを抽出する
Dim text As String = textExtractor.ExtractText(extractOptions)
'TXTファイルへの書き込み
File.WriteAllText("Extracted.txt", text)
End Sub
End Class
End Namespace
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





