Word ドキュメントからコンテンツを抽出することは、仕事でも勉強でも重要な役割を果たします。1 ページ分の内容を抽出すると、重要なポイントをすばやく閲覧して要約するのに役立ち、1 つのセクションから内容を抽出すると、特定のトピックやセクションを詳しく学習するのに役立ちます。ドキュメント全体を抽出することで、ドキュメントの内容を包括的に理解することができ、深い分析や包括的な理解が容易になります。この記事では、Java プロジェクトで Spire.Doc for Java を使用して Word ドキュメントのページ、セクション、コンテンツ全体を読み取る方法を紹介します。
Spire.Doc for Java をインストールします
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.3.1</version>
</dependency>
</dependencies>Java で Word ドキュメントからページを読み取る
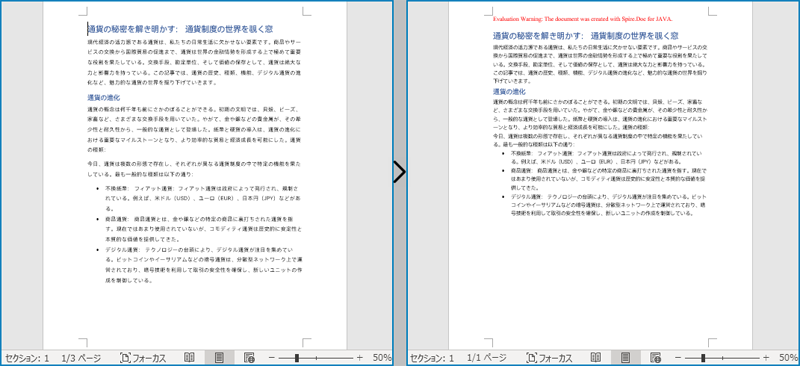
FixedLayoutDocument クラスと FixedLayoutPage クラスを使用すると、指定したページから内容を簡単に抽出することができます。抽出された内容を見やすくするために、次のコード例では、抽出された内容を新しい Word ドキュメントに保存しています。詳しい手順は以下の通りです:
- Document クラスのオブジェクトを作成します。
- Document.loadFromFile() メソッドを使用して Word ドキュメントを読み込みます。
- FixedLayoutDocument クラスのオブジェクトを作成します。
- ドキュメント内のページの FixedLayoutPage オブジェクトを取得します。
- FixedLayoutPage.getSection() メソッドを使用して、ページのあるセクションを取得します。
- セクション内のページの最初の段落のインデックス位置を取得します。
- セクション内のページの最後の段落のインデックス位置を取得します。
- 別の Document クラスのオブジェクトを作成 します。
- Document.addSection() メソッドを使用して新しいセクションを追加します。
- Section.cloneSectionPropertiesTo(newSection) メソッドを使用して、元のセクションのプロパティを新しいセクションにコピーします。
- ページの内容を、元のドキュメントから新しいドキュメントにコピーします。
- Document.saveToFile() メソッドを使用して、結果のドキュメントを保存します。
- Java
import com.spire.doc.*;
import com.spire.doc.pages.*;
import com.spire.doc.documents.*;
public class readWordPage {
public static void main(String[] args) {
// 新しいドキュメントオブジェクトを作成する
Document document = new Document();
// 指定されたファイルからドキュメントの内容を読み込む
document.loadFromFile("サンプル.docx");
// 固定レイアウトドキュメントオブジェクトを作成する
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// 最初のページを取得する
FixedLayoutPage page = layoutDoc.getPages().get(0);
// ページが所属しているセクションを取得する
Section section = page.getSection();
// ページの最初の段落を取得する
Paragraph paragraphStart = page.getColumns().get(0).getLines().getFirst().getParagraph();
int startIndex = 0;
if (paragraphStart != null) {
// セクション内での段落のインデックスを取得する
startIndex = section.getBody().getChildObjects().indexOf(paragraphStart);
}
// ページの最後の段落を取得する
Paragraph paragraphEnd = page.getColumns().get(0).getLines().getLast().getParagraph();
int endIndex = 0;
if (paragraphEnd != null) {
// セクション内での段落のインデックスを取得する
endIndex = section.getBody().getChildObjects().indexOf(paragraphEnd);
}
// 新しいドキュメントオブジェクトを作成する
Document newdoc = new Document();
// 新しいセクションを追加する
Section newSection = newdoc.addSection();
// 元のセクションのプロパティを新しいセクションにクローンする
section.cloneSectionPropertiesTo(newSection);
// 元のドキュメントのページの内容を新しいドキュメントにコピーする
for (int i = startIndex; i <= endIndex; i++) {
newSection.getBody().getChildObjects().add(section.getBody().getChildObjects().get(i).deepClone());
}
// 新しいドキュメントを指定されたファイルに保存する
newdoc.saveToFile("output/ページの内容.docx", FileFormat.Docx);
// 新しいドキュメントを閉じて解放する
newdoc.close();
newdoc.dispose();
// 元のドキュメントを閉じて解放する
document.close();
document.dispose();
}
}
Java で Word ドキュメントからセクションを読み取る
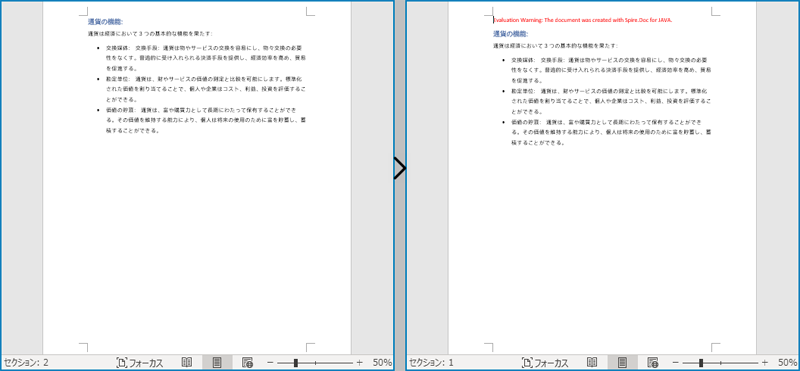
Document.Sections[index] プロパティを使用すると、ドキュメントのヘッダー、フッター、本文を含む特定のセクションクラスのオブジェクトにアクセスすることができます。次の例では、あるセクションのすべての内容を別のドキュメントにコピーする簡単な方法を示します。詳しい手順は以下のとおりです:
- Document クラスのオブジェクトを作成します。
- Document.loadFromFile() メソッドを使用して Word ドキュメントを読み込みます。
- Document.getSections().get(1) メソッドを使用して、ドキュメントの 2 番目のセクションを取得します。
- 別の新しい Document クラスのオブジェクトを作成します。
- Document.cloneDefaultStyleTo(newdoc) メソッドを使用して、元のドキュメントのデフォルトのスタイルを新しいドキュメントに複製します。
- Document.getSections().add(section.deepClone()) メソッドを使用して、元のドキュメントの 2 番目のセクションの内容を新しいドキュメントにコピーします。
- Document.saveToFile() メソッドを使用して、結果のドキュメントを保存します。
- Java
import com.spire.doc.*;
public class readWordSection {
public static void main(String[] args) {
// 新しいドキュメントオブジェクトを作成する
Document document = new Document();
// ファイルからWordドキュメントを読み込む
document.loadFromFile("サンプル.docx");
// ドキュメントの2番目のセクションを取得する
Section section = document.getSections().get(1);
// 新しいドキュメントオブジェクトを作成する
Document newdoc = new Document();
// デフォルトスタイルを新しいドキュメントにクローンする
document.cloneDefaultStyleTo(newdoc);
// 2番目のセクションを新しいドキュメントにクローンする
newdoc.getSections().add(section.deepClone());
// 新しいドキュメントをファイルに保存する
newdoc.saveToFile("output/セクションの内容.docx", FileFormat.Docx);
// 新しいドキュメントオブジェクトを閉じて解放する
newdoc.close();
newdoc.dispose();
// 元のドキュメントオブジェクトを閉じて解放する
document.close();
document.dispose();
}
}
Java で Word ドキュメントから内容全体を読み取る
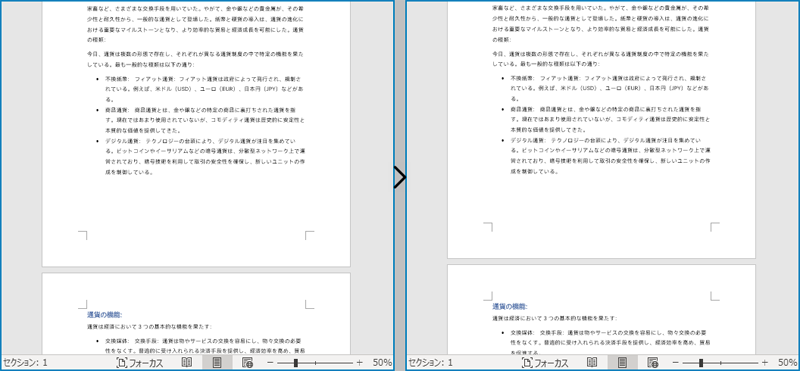
この例では、元のドキュメントの各セクションを繰り返し処理して、ドキュメントの内容全体を読み取り、各セクションを新しいドキュメントにコピーする方法を示します。この方法は、ドキュメント全体の構造と内容の両方をすばやく複製し、新しいドキュメントで元のドキュメントの書式とレイアウトを保持するのに役立ちます。このような操作は、ドキュメント構造の整合性と一貫性を維持するために非常に便利です。詳しい手順は以下のとおりです:
- Document クラスのオブジェクトを作成します。
- Document.loadFromFile() メソッドを使用して Word ドキュメントを読み込みます。
- 別の新しい Document クラスのオブジェクトを作成します。
- Document.cloneDefaultStyleTo(newdoc) メソッドを使用して、元のドキュメントのデフォルトのスタイルを新しいドキュメントにコピーします。
- 元のドキュメントの各セクションを繰り返し処理し、新しいドキュメントにコピーします。
- Document.saveToFile() メソッドを使用して、結果のドキュメントを保存します。
- Java
import com.spire.doc.*;
public class readWordContent {
public static void main(String[] args) {
// 新しいドキュメントオブジェクトを作成する
Document document = new Document();
// ファイルからWordドキュメントを読み込む
document.loadFromFile("サンプル.docx");
// 新しいドキュメントオブジェクトを作成する
Document newdoc = new Document();
// デフォルトスタイルを新しいドキュメントにクローンする
document.cloneDefaultStyleTo(newdoc);
// 元のドキュメント内の各セクションをイテレーションし、新しいドキュメントにクローンする
for (Section sourceSection : (Iterable<Section>) document.getSections()) {
newdoc.getSections().add(sourceSection.deepClone());
}
// 新しいドキュメントをファイルに保存する
newdoc.saveToFile("output/ドキュメント内容.docx", FileFormat.Docx);
// 新しいドキュメントオブジェクトを閉じて解放する
newdoc.close();
newdoc.dispose();
// 元のドキュメントオブジェクトを閉じて解放する
document.close();
document.dispose();
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





