PDF 文書内のテキストを検索して強調表示することは、多くの個人や組織にとって非常に重要な作業です。研究を行う学生であれ、契約書をレビューする専門家であれ、デジタル記録を整理するアーキビストであれ、特定の情報を素早く見つけて強調する能力は非常に貴重です。
この記事では、Spire.PDF for Java ライブラリを使用して、Java で PDF 文書内のテキストを検索して強調表示する方法を説明します。
- Java で特定のページのテキストを検索して強調表示する
- Java で矩形領域内のテキストを検索して強調表示する
- Java で PDF 全体のテキストを検索して強調表示する
- Java で正規表現を使ってテキストを検索して強調表示する
Spire.PDF for Java をインストールします
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.4.4</version>
</dependency>
</dependencies>Java で特定のページのテキストを検索して強調表示する
Spire.PDF for Java では、PdfTextFinder クラスを使用してページ内の特定のテキストを検索することができます。検索操作を実行する前に、PdfTextFinder.getOptions.setTextFindParameter() メソッドを使用して、WholeWord や IgnoreCase などの検索オプションを設定できます。テキストが見つかったら、ハイライトを適用してテキストを視覚的に区別することができます。
以下は、Java を使用して PDF 内の特定のページでテキストを検索し、強調表示する手順です。
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使って PDF ドキュメントを読み込みます。
- PdfDocument.getPages().get() メソッドを使用して、ドキュメントから特定のページを取得します。
- そのページに基づいて PdfTextFinder オブジェクトを作成します。
- PdfTextFinder.getOptions().setTextFindParameter() メソッドを使用して検索オプションを指定します。
- PdfTextFinder.find() メソッドを使用して、指定したテキストの出現箇所をすべて検索します。
- 検索結果を繰り返し処理し、PdfTextFragment.highlight() メソッドを使用して各出現箇所を強調表示します。
- PdfDocument.saveToFile() メソッドを使用してドキュメントを保存します。
- Java
import com.spire.ms.System.Collections.Generic.List;
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextFinder;
import com.spire.pdf.texts.PdfTextFragment;
import com.spire.pdf.texts.TextFindParameter;
import java.awt.*;
import java.util.EnumSet;
public class FindAndHighlightTextInPage {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.loadFromFile("サンプル.pdf");
// 特定のページを取得する
PdfPageBase page = doc.getPages().get(0);
// ページに基づいてPdfTextFinderオブジェクトを作成する
PdfTextFinder finder = new PdfTextFinder(page);
// 検索オプションを指定する
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.WholeWord));
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.IgnoreCase));
// 指定したテキストのインスタンスを検索する
List results = finder.find("クラウドサーバー");
// 検索結果を反復処理する
for (int i = 0; i < results.size(); i++)
{
// Get a finding result
PdfTextFragment fragment = (PdfTextFragment)results.get(i);
// Highlight the text
fragment.highLight();
}
// 別のPDFファイルに保存する
doc.saveToFile("output/PDFページ内のテキストをハイライト.pdf", FileFormat.PDF);
doc.dispose();
}
}
Java で矩形領域内のテキストを検索して強調表示する
ドキュメント内の特定のセクションや情報に注目させるために、ユーザはページ内の矩形領域内で指定されたテキストを見つけて強調表示することができます。こ の矩形領域は、PdfTextFinder.getOptions().setFindArea() メソッドを用いて定義することができます。
以下は、Java を使用して PDF ページの矩形領域内のテキストを検索して強調表示する手順です。
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使って PDF ドキュメントを読み込みます。
- PdfDocument.getPages().get() メソッドを使ってドキュメントから特定のページを取得します。
- そのページに基づいて PdfTextFinder オブジェクトを作成します。
- PdfTextFinder.getOptions().setTextFindParameter() メソッドを使用して検索オプションを指定します。
- PdfTextFinder.find() メソッドを使用して、矩形領域内で指定したテキストが出現する箇所をすべて検索します。
- 検索結果を繰り返し処理し、PdfTextFragment.fighlight() メソッドを使用して各出現箇所を強調表示します。
- PdfDocument.saveToFile() メソッドを使用してドキュメントを保存します。
- Java
import com.spire.ms.System.Collections.Generic.List;
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextFinder;
import com.spire.pdf.texts.PdfTextFragment;
import com.spire.pdf.texts.TextFindParameter;
import java.awt.*;
import java.awt.geom.Rectangle2D;
import java.util.EnumSet;
public class FindAndHighlightTextInRectangle {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
// PDFファイルをロードします
doc.loadFromFile("サンプル.pdf");
// 特定のページを取得します
PdfPageBase page = doc.getPages().get(0);
// ページに基づいてPdfTextFinderオブジェクトを作成します
PdfTextFinder finder = new PdfTextFinder(page);
// テキストを検索するための長方形の領域を指定します
finder.getOptions().setFindArea(new Rectangle2D.Float(0,0,841,180));
// その他のオプションを指定します
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.WholeWord));
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.IgnoreCase));
// 指定したテキストのインスタンスを長方形の領域内で検索します
List results = finder.find("クラウドサーバー");
// 検索結果を反復処理します
for (int i = 0; i < results.size(); i++) {
// テキストのインスタンスを取得します
PdfTextFragment fragment = (PdfTextFragment)results.get(i);
// テキストをハイライト表示します
fragment.highLight(Color.lightGray);
}
// 別のPDFファイルに保存します
doc.saveToFile("output/矩形領域内のPDFテキストをハイライト.pdf", FileFormat.PDF);
// リソースを解放します
doc.dispose();
}
}
Java で PDF 全体のテキストを検索して強調表示する
最初のコード例では、特定のページのテキストを強調表示する方法を示します。文書全体のテキストを強調表示するには、文書の各ページを走査して検索操作を実行し、特定されたテキストに強調表示を適用します。
Java を使って PDF 文書全体のテキストを検索し、強調表示する手順は以下のとおりです。
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使用して PDF ドキュメントを読み込みます。
- ドキュメントの各ページを繰り返し処理します。
- 指定したページに基づいて PdfTextFinder オブジェクトを作成します。
- PdfTextFinder.getOptions().setTextFindParameter() メソッドを使用して検索オプションを指定します。
- PdfTextFinder.find() メソッドを使用して、指定したテキストの出現箇所をすべて検索します。
- 検索結果を反復処理し、PdfTextFragment.fighlight() メソッドを使用して各出現箇所を強調表示 し ます。
- PdfDocument.saveToFile() メソッドを使用してドキュメントを保存します。
- Java
import com.spire.ms.System.Collections.Generic.List;
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextFinder;
import com.spire.pdf.texts.PdfTextFragment;
import com.spire.pdf.texts.TextFindParameter;
import java.awt.*;
import java.util.EnumSet;
public class FindAndHighlightTextInDocument {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
// PDFファイルをロードします
doc.loadFromFile("サンプル.pdf");
// PDFファイル内のページを反復処理します
for (Object pageObj : doc.getPages()) {
// 特定のページを取得します
PdfPageBase page = (PdfPageBase) pageObj;
// ページに基づいてPdfTextFinderオブジェクトを作成します
PdfTextFinder finder = new PdfTextFinder(page);
// 検索オプションを指定します
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.WholeWord));
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.IgnoreCase));
// 指定したテキストのインスタンスを検索します
List results = finder.find("クラウドサーバー");
// 検索結果を反復処理します
for (int i = 0; i < results.size(); i++) {
// テキストのインスタンスを取得します
PdfTextFragment fragment = (PdfTextFragment) results.get(i);
// テキストのインスタンスを強調表示します
fragment.highLight(Color.cyan);
}
}
// 別のPDFファイルに保存します
doc.saveToFile("output/PDF文書のテキストをハイライト.pdf", FileFormat.PDF);
// リソースを解放します
doc.dispose();
}
}
Java で正規表現を使ってテキストを検索して強調表示する
ドキュメント内の特定のテキストを探す場合、正規表現を使用すると検索条件の柔軟性と制御性が向上します。正規表現を利用するには、TextFindParameter を Regex として設定 し 、find() メソッドへの入力として希望の正規表現パターンを与える必要があります。
以下は、Java を使用して正規表現を使って PDF 内のテキストを検索し、強調表示する手順です。
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッド を使用して PDF ドキュメントを読み込みます。
- ドキュメント内の各ページを繰り返し処理します。
- 特定のページに基づいて PdfTextFinder オブジェクトを作成します。
- PdfTextFinder.getOptions().setTextFindParameter() メソッドを使用して、TextFindParameter を正規表現として設定します。
- 検索する特定のテキストにマッチする正規表現パターンを作成します。
- PdfTextFinder.find() メソッドを使用して、検索対象のテキストが出現する箇所をすべて検索します。
- 検索結果を反復処理し、PdfTextFragment.fighlight() メソッドを使用して各出現箇所を強調表示 し ます。
- PdfDocument.saveToFile() メソッドを使用してドキュメントを保存します。
- Java
import com.spire.ms.System.Collections.Generic.List;
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextFinder;
import com.spire.pdf.texts.PdfTextFragment;
import com.spire.pdf.texts.TextFindParameter;
import java.awt.*;
import java.util.EnumSet;
public class FindAndHighlightTextUsingRegex {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
// PDFファイルをロードします
doc.loadFromFile("サンプル.pdf");
// PDFファイル内のページを反復処理します
for (Object pageObj : doc.getPages()) {
// 特定のページを取得します
PdfPageBase page = (PdfPageBase) pageObj;
// ページに基づいてPdfTextFinderオブジェクトを作成します
PdfTextFinder finder = new PdfTextFinder(page);
// 検索モデルを正規表現に指定します
finder.getOptions().setTextFindParameter(EnumSet.of(TextFindParameter.Regex));
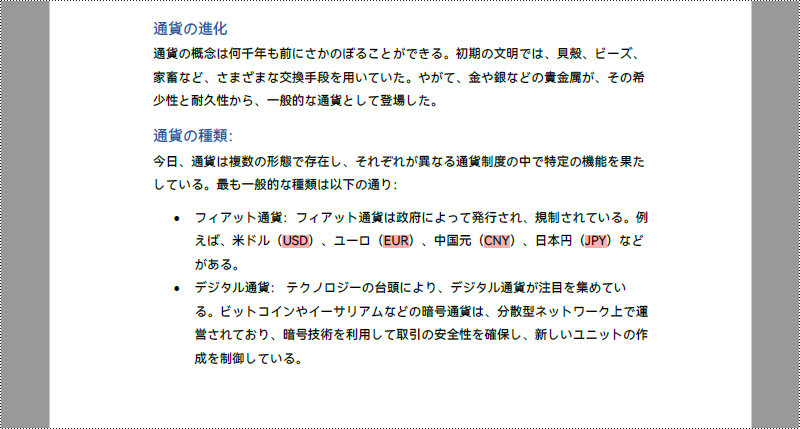
// 連続する3つの大文字にマッチする正規表現を指定します
String pattern = "[A-Z]{3}";
// 正規表現に一致するテキストを検索します
List results = finder.find(pattern);
// 検索結果を反復処理します
for (int i = 0; i < results.size(); i++) {
// テキストを取得します
PdfTextFragment fragment = (PdfTextFragment) results.get(i);
// テキストをハイライト表示します
fragment.highLight(Color.PINK);
}
}
// 別のPDFファイルに保存します
doc.saveToFile("output/正規表現でPDFテキストをハイライト.pdf", FileFormat.PDF);
// リソースを解放します
doc.dispose();
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





