テーブルは、PDF で最もよく使用される書式設定要素の 1 つです。 場合によっては、さらに分析を行うために PDF のテーブルからデータを抽出する必要がある場合があります。この記事では、Spire.PDF for Java を使用して PDF からテーブルのデータを抽出する方法を紹介します。
Spire.PDF for Java をインストールします
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.12.0</version>
</dependency>
</dependencies>PDF からテーブルのデータを抽出する
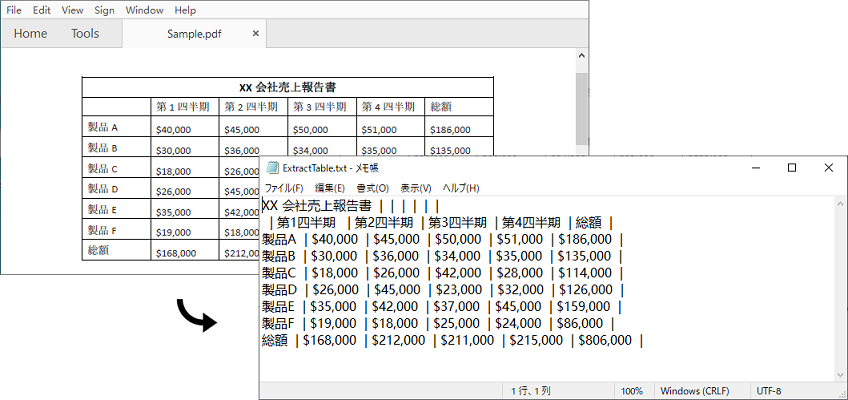
Spire.PDF for Java は、PdfTableExtractor.extractTable(int pageIndex) メソッドを使用して、特定の PDF ページからテーブルを検出して抽出します。以下は、PDF ファイルからテーブルデータを抽出する手順です。
- PdfDocument クラスを使用して、サンプル PDF ファイルをロードします。
- StringBuilder インスタンスと PdfTableExtractor インスタンスを作成します。
- PDFのページをループし、PdfTableExtractor.extractTable(int pageIndex) メソッドを使用して、各ページから PdfTable 配列にテーブルを抽出します。
- 配列内のテーブルをループします。
- 各テーブルの行と列をループし、PdfTable.getText(int rowIndex、int columnIndex) メソッドを使用して、各テーブルのセルからデータを抽出します。
- StringBuilder.append() メソッドを使用して、StringBuilder インスタンスにデータを追加します。
- Writer.write() メソッドを使用して、抽出したデータを txt ファイルに書き込みます。
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String []args) throws Exception {
//サンプルPDFファイルをロードする
PdfDocument pdf = new PdfDocument("Sample.pdf");
//StringBuilder インスタンスを作成する
StringBuilder builder = new StringBuilder();
//PdfTableExtractor インスタンスを作成する
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//PDFのページをループする
for (int pageIndex = 0; pageIndex < pdf.getPages().getCount(); pageIndex++) {
//現在のページからテーブルを PdfTable 配列に抽出する
PdfTable[] tableLists = extractor.extractTable(pageIndex);
//テーブルが見つかった場合
if (tableLists != null && tableLists.length > 0) {
//配列内のテーブルをループする
for (PdfTable table : tableLists) {
//現在のテーブルの行をループする
for (int i = 0; i < table.getRowCount(); i++) {
//現在のテーブルの列をループする
for (int j = 0; j < table.getColumnCount(); j++) {
//現在のテーブルのセルからデータを抽出し、StringBuilder に追加する
String text = table.getText(i, j);
builder.append(text + " | ");
}
builder.append("\r\n");
}
}
}
}
//データを .txt ファイルに書き込む
FileWriter fw = new FileWriter("ExtractTable.txt");
fw.write(builder.toString());
fw.flush();
fw.close();
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





