多くのユーザーは、PDF ドキュメント内に添付ファイルとして様々なファイルを保存しています。これらの添付ファイルは必要に応じて抽出され、他の目的で使用することができます。基本的に、PDF には2種類の添付ファイルがあります。ドキュメントレベルの添付ファイルと注釈添付ファイルです。以下に、それらの違いを示します。
- ドキュメントレベルの添付ファイル(PdfAttachment クラスで表される):ドキュメントレベルで PDF に添付されたファイルは、ページには表示されず、PDF リーダーの「添付ファイル」パネルでのみ表示されます。
- 注釈添付ファイル(PdfAttachmentAnnotation クラスで表される):ファイルはページの特定の位置に追加されます。注釈添付ファイルは、ページにペーパークリップのアイコンとして表示されます。閲覧者はアイコンをダブルクリックしてファイルを開くことができます。
この記事では、Spire.PDF for Java を使用して、Java で PDF ドキュメントからこれら 2 種類の添付ファイルを抽出する方法について説明します。
Spire.PDF for Java をインストールします
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.4.4</version>
</dependency>
</dependencies>Java で PDF から添付ファイルを抽出する
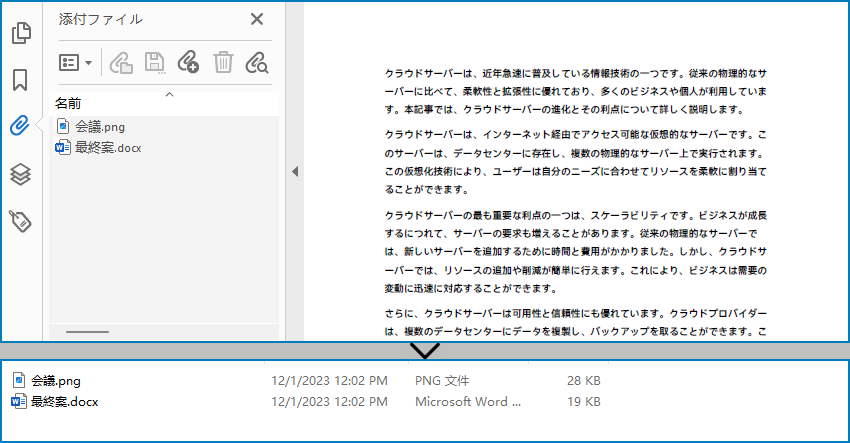
PDF ドキュメントのドキュメントレベルの添付ファイルは、PdfDocument.getAttachments() メソッドを使用して取得できます。以下の手順は、添付ファイルを抽出してローカルフォルダに保存する方法を示しています。
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使用して PDF ファイルを読み込みます。
- PdfDocument.getAttachments() メソッドを使用してドキュメントから添付ファイルコレクションを取得します。
- PdfAttachmentCollection.get() メソッドを使用して特定の添付ファイルを取得し、PdfAttachment.getData() メソッドを使用してそのデータを取得します。
- データをファイルに書き込み、指定されたフォルダに保存します。
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.attachments.PdfAttachmentCollection;
import java.io.*;
public class ExtractAttachments {
public static void main(String[] args) throws Exception {
// PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
// 添付ファイルを含むPDFファイルをロードします
doc.loadFromFile("サンプル.pdf");
// PDFドキュメントの添付ファイルコレクションを取得します
PdfAttachmentCollection attachments = doc.getAttachments();
// コレクションをループします
for (int i = 0; i < attachments.getCount(); i++) {
// 出力ファイルのパスと名前を指定します
File file = new File("output/添付ファイル/" + attachments.get(i).getFileName());
OutputStream output = new FileOutputStream(file);
BufferedOutputStream bufferedOutput = new BufferedOutputStream(output);
// 特定の添付ファイルを取得してファイルに書き込みます
bufferedOutput.write(attachments.get(i).getData());
bufferedOutput.close();
}
}
}
Java で PDF から注釈添付ファイルを抽出する
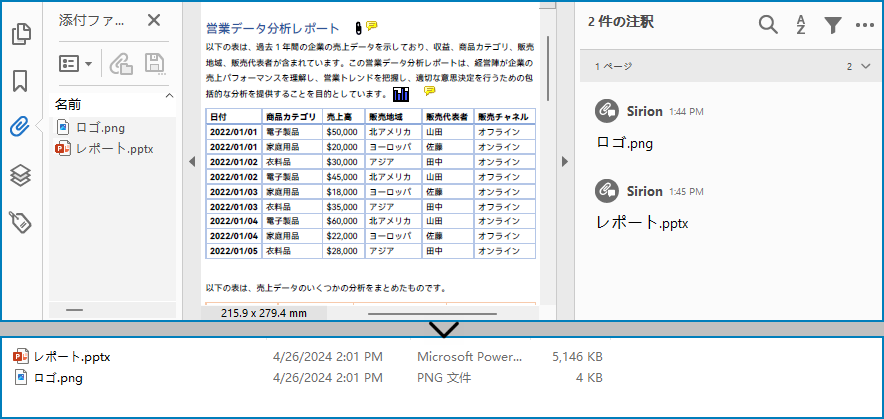
注釈添付ファイルはページベースの要素です。特定のページから注釈を取得するには、PdfPageBase.getAnnotationsWidget() メソッドを使用します。その後、特定の注釈が注釈添付ファイルかどうかを判断する必要があります。以下の手順は、ドキュメント全体から注釈添付ファイルを抽出してローカルフォルダに保存する方法です。
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使用して PDF ファイルを読み込みます。
- PdfDocument.getPages().get() メソッドを使用してドキュメントから特定のページを取得します。
- PdfPageBase.getAnnotationsWidget() メソッドを使用してページから注釈コレクションを取得します。
- 特定の注釈が PdfAttachmentAnnotationWidget のインスタンスかどうかを判断します。もしそうであれば、注釈添付ファイルをファイルに書き込み、指定されたフォルダに保存します。
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.annotations.PdfAnnotationCollection;
import com.spire.pdf.annotations.PdfAttachmentAnnotationWidget;
import java.io.*;
public class ExtractAnnotationAttachments {
public static void main(String[] args) throws Exception {
// PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
// 添付ファイルを含むPDFファイルをロードします
doc.loadFromFile("サンプル1.pdf");
// ページをループします
for (int i = 0; i < doc.getPages().getCount(); i++) {
// 注釈コレクションを取得します
PdfAnnotationCollection collection = doc.getPages().get(i).getAnnotationsWidget();
// 注釈をループします
for (Object annotation : collection) {
// 注釈がPdfAttachmentAnnotationWidgetのインスタンスかどうかを判別します
if (annotation instanceof PdfAttachmentAnnotationWidget) {
// ドキュメントから注釈の添付ファイルを保存します
String fullPath = ((PdfAttachmentAnnotationWidget) annotation).getFileName();
String fileName = fullPath.substring(fullPath.lastIndexOf("/") + 1);
File file = new File("output/注釈添付ファイル/" + fileName);
OutputStream output = new FileOutputStream(file);
BufferedOutputStream bufferedOutput = new BufferedOutputStream(output);
bufferedOutput.write(((PdfAttachmentAnnotationWidget) annotation).getData());
bufferedOutput.close();
}
}
}
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





