Word ドキュメントから内容を抽出して、別の用途に使用したい場合があります。例えば、Word ドキュメントからテキストや画像を抽出し、それらを再配列して新しいドキュメントを作成することができます。これは、Spire.Doc for .NET を使用することによって簡単に達成することができます。このツールは、Word ドキュメント内のあらゆる種類の要素を取得し、それらをエクスポート、再配列、または変更することを可能にします。この記事では、Spire.Doc for .NET を使用して Word 文書からテキストと画像を抽出する方法について説明します。
Spire.Doc for .NET をインストールします
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocWord 文書からテキストを抽出する
テキストを抽出するには、Paragraph.Text プロパティを使って段落内のすべてのテキストを取得し、StringBuilder.AppendLine() メソッドを使って StringBuilder クラスのインスタンスにそれを入れます。最後に、テキストを TXT ファイルに書き出すことができます。
詳しい手順は以下の通りです。
- Document クラスのインスタンスを作成します。
- Document.LoadFromFile() メソッドを使用して Word 文書を読み込みます。
- StringBuilder クラスのインスタンスを作成します。
- 文書内の各セクションの各段落を取得します。
- Paragraph.Text プロパティを使って指定した段落のテキストを取得し、StringBuilder.AppendLine() メソッドを使って抽出したテキストを StringBuilder クラスのインスタンスに追加します。
- 新規に txt ファイルを作成し、File.WriteAllText() メソッドを使用して抽出したテキストをファイルに書き込みます。
- C#
- VB.NET
using Spire.Doc;
using Spire.Doc.Documents;
using System.Text;
using System.IO;
namespace ExtractTextfromWord
{
class ExtractText
{
static void Main(string[] args)
{
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Word文書の読み込み
document.LoadFromFile("C:/洞窟の芸術.docx");
//StringBuilderクラスのインスタンスを作成する
StringBuilder sb = new StringBuilder();
//Word文書からテキストを抽出し、StringBuilderクラスのインスタンスに保存する
foreach (Section section in document.Sections)
{
foreach (Paragraph paragraph in section.Paragraphs)
{
sb.AppendLine(paragraph.Text);
}
}
//新たにtxtファイルを作成し、抽出したテキストを保存する
File.WriteAllText("テキストの抽出.txt", sb.ToString());
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System.Text
Imports System.IO
Namespace ExtractTextfromWord
Class ExtractText
Shared Sub Main(ByVal args() As String)
'Documentクラスのインスタンスを作成する
Dim document As Document = New Document()
'Word文書の読み込み
document.LoadFromFile("C:/洞窟の芸術.docx")
'StringBuilderクラスのインスタンスを作成する
Dim sb As StringBuilder = New StringBuilder()
'Word文書からテキストを抽出し、StringBuilderクラスのインスタンスに保存する
Dim section As Section
For Each section In document.Sections
Dim paragraph As Paragraph
For Each paragraph In section.Paragraphs
sb.AppendLine(paragraph.Text)
Next
Next
'新たにtxtファイルを作成し、抽出したテキストを保存する
File.WriteAllText("テキストの抽出.txt", sb.ToString())
End Sub
End Class
End Namespace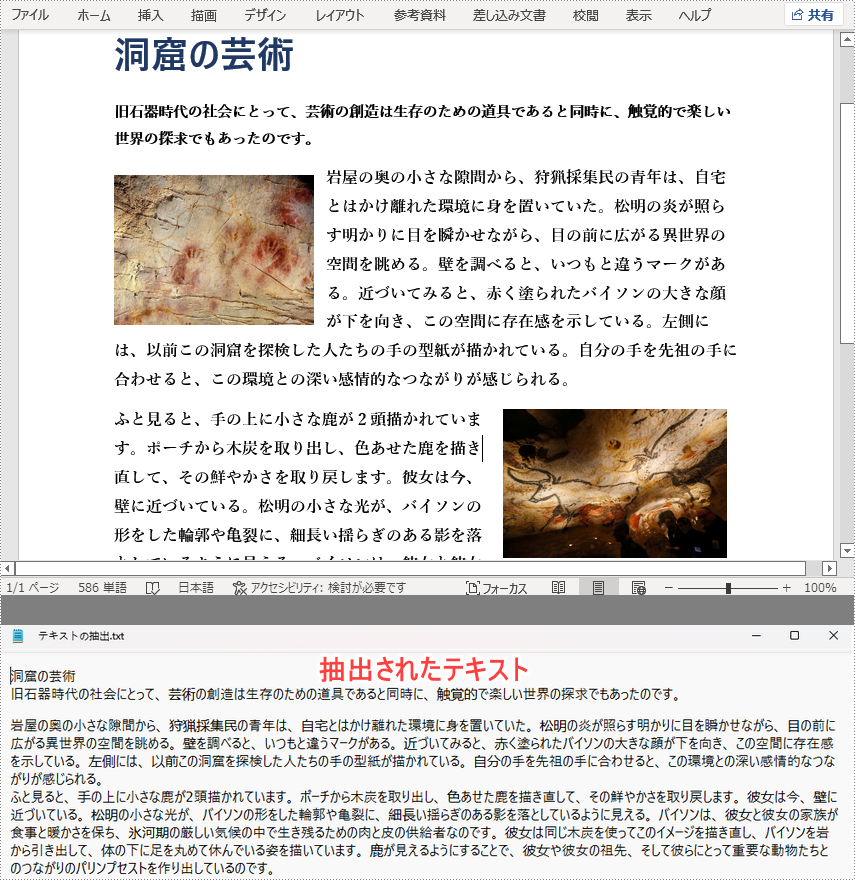
Word 文書から画像を抽出する
Word ドキュメントから画像を抽出するには、各段落にあるオブジェクトを取得し、それが画像であるかどうかを検出します。そして、それらの画像オブジェクトを PNG ファイルとして保存します。
- Document クラスのインスタンスを作成し、Document.LoadFromFile() メソッドを使用して Word 文書を読み込みます。
- 文書内の各セクションの各段落を取得します。
- 特定の段落の各文書オブジェクトを取得します。
- 文書オブジェクトのタイプが画像であるかどうかを判断します。画像であれば、DocPicture.Image.Save(String, ImageFormat) メソッドでドキュメントから画像を保存します。
- C#
- VB.NET
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
namespace ExtractImage
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.LoadFromFile("C:/洞窟の芸術.docx");
int index = 0;
//文書の各セクションを取得する
foreach (Section section in document.Sections)
{
//セクションの各段落を取得する
foreach (Paragraph paragraph in section.Paragraphs)
{
//指定された段落の各文書オブジェクトを取得する
foreach (DocumentObject docObject in paragraph.ChildObjects)
{
//DocumentObjectTypeが画像であれば、ファイルに保存する
if (docObject.DocumentObjectType == DocumentObjectType.Picture)
{
DocPicture picture = docObject as DocPicture;
picture.Image.Save(string.Format("画像/画像{0}.png", index), System.Drawing.Imaging.ImageFormat.Png);
index++;
}
}
}
}
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Namespace ExtractImage
Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのオブジェクトを作成する
Dim document As Document = New Document()
'Word文書の読み込み
document.LoadFromFile("C:/洞窟の芸術.docx")
Dim index As Integer = 0
'文書の各セクションを取得する
Dim section As Section
For Each section In document.Sections
'セクションの各段落を取得する
Dim paragraph As Paragraph
For Each paragraph In section.Paragraphs
'指定された段落の各文書オブジェクトを取得する
Dim docObject As DocumentObject
For Each docObject In paragraph.ChildObjects
'DocumentObjectTypeが画像であれば、ファイルに保存する
If docObject.DocumentObjectType = DocumentObjectType.Picture Then
Dim picture As DocPicture = docObject
picture.Image.Save(String.Format("画像/画像{0}.png", index), System.Drawing.Imaging.ImageFormat.Png)
index = index + 1
End If
Next
Next
Next
End Sub
End Class
End Namespace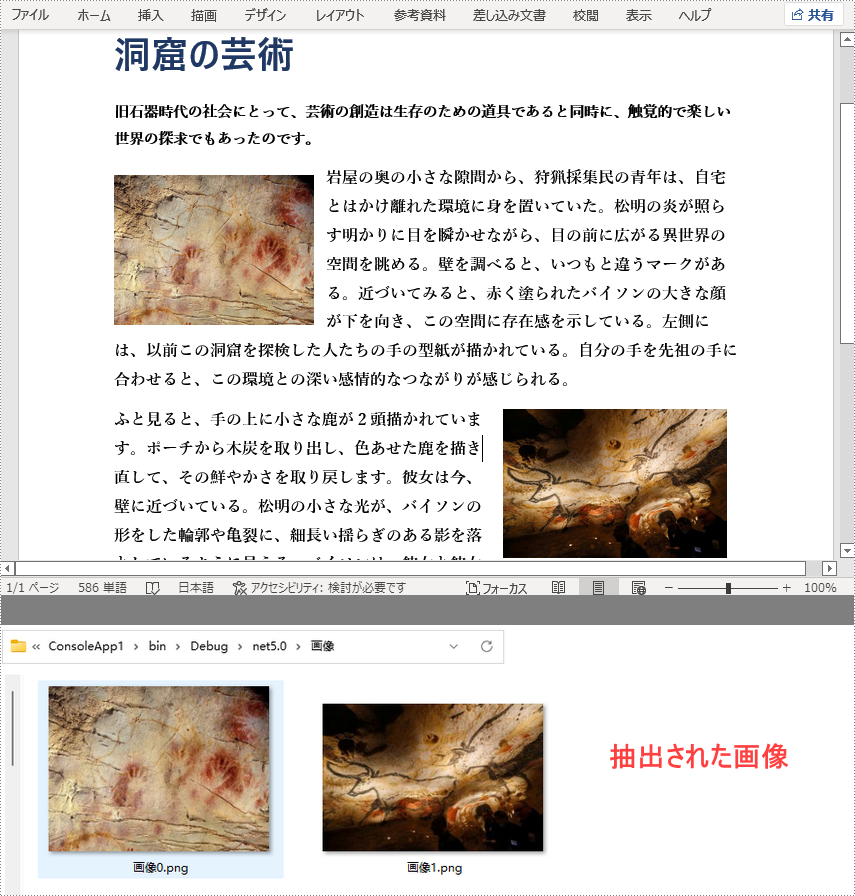
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





