PDF は、データの共有や記録に広く使われる人気のあるドキュメント形式です。特に PDF に含まれる表のデータを抽出する必要がある場面に出くわすことがあります。例えば、請求書の PDF に保存された表の中に有用な情報があり、そのデータを分析や計算に利用したい場合です。本記事では、Spire.PDF for .NET を使用して、PDF の表からデータを抽出し、それをテキストファイルや Excel ワークシートに保存する方法を紹介します。
Spire.PDF for .NET をインストールします
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
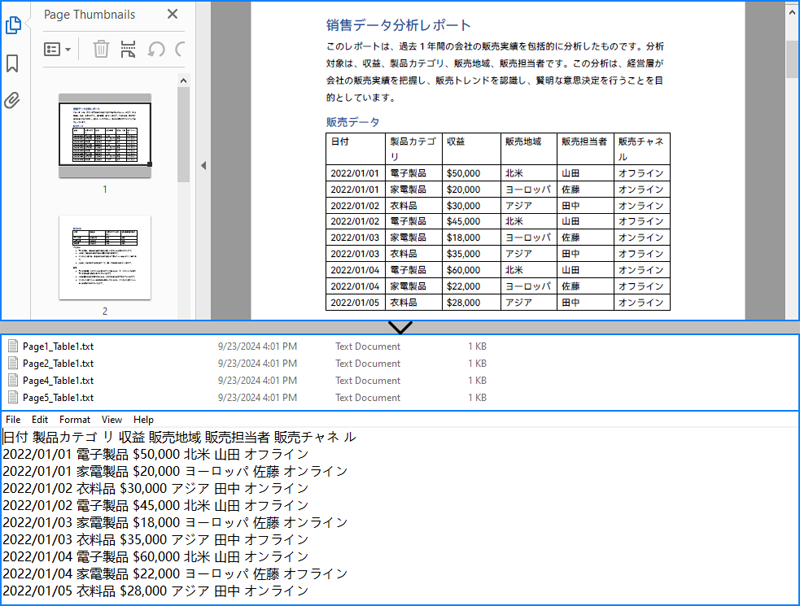
PM> Install-Package Spire.PDFC# で PDF 表データをテキストファイルに抽出する
Spire.PDF for .NET には、PdfTableExtractor.ExtractTable() メソッドがあり、PDF ページ上のすべての表を抽出することができます。このメソッドを使用して PDF ドキュメントから表を抽出した後、PdfTable.GetText() メソッドを使用して表の値を取得し、それをテキストファイルに書き出すことができます。PDF表データをテキストファイルに抽出する手順は以下の通りです:
- PdfDocument オブジェクトを作成し、PdfDocument.LoadFromFile() メソッドで PDF ドキュメントを読み込みます。
- 読み込んだ PDF ドキュメントに対して PdfTableExtractor オブジェクトを作成します。
- PdfTableExtractor.ExtractTable() メソッドを使ってドキュメントの各ページにある表を抽出します。
- 各表を順に処理します:
- StringBuilder オブジェクトを作成し、表データを格納します。
- 行と列をループして、Table.GetText() メソッドを使ってセルの値を取得し、それを StringBuilder オブジェクトに追加します。
- 最終的に StringBuilder オブジェクトをテキストファイルに書き出します。
- C#
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Text;
namespace PDFTableToText
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成し、PDFドキュメントをロード
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// 読み込んだPDFのためのテーブルエクストラクターを初期化
PdfTableExtractor tableExtractor = new PdfTableExtractor(pdf);
// PDFの各ページを繰り返し処理
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
// 現在のページからテーブルを抽出
PdfTable[] tables = tableExtractor.ExtractTable(pageIndex);
if (tables != null)
{
// 抽出された各テーブルを繰り返し処理
for (int tableIndex = 0; tableIndex < tables.Length; tableIndex++)
{
// StringBuilderオブジェクトを作成
StringBuilder stringBuilder = new StringBuilder();
// テーブルの各行と列を繰り返し処理
for (int rowIndex = 0; rowIndex < tables[tableIndex].GetRowCount(); rowIndex++)
{
for (int columnIndex = 0; columnIndex < tables[tableIndex].GetColumnCount(); columnIndex++)
{
// テーブルのセルテキストを取得し、改行を削除
string cellText = tables[tableIndex].GetText(rowIndex, columnIndex);
string text = cellText.Replace("\n", " ");
// StringBuilderオブジェクトにセルテキストを追加
if (columnIndex < tables[tableIndex].GetColumnCount() - 1)
{
stringBuilder.Append(text + "");
}
else
{
stringBuilder.Append(text);
}
}
// 各テーブル行のために行を切り替え
if (rowIndex < tables[tableIndex].GetRowCount() - 1)
{
stringBuilder.AppendLine();
}
}
// テーブル内容をテキストファイルに書き込み
string outputFilePath = $"output/Page{pageIndex + 1}_Table{tableIndex + 1}.txt";
File.WriteAllText(outputFilePath, stringBuilder.ToString());
}
}
}
}
}
}
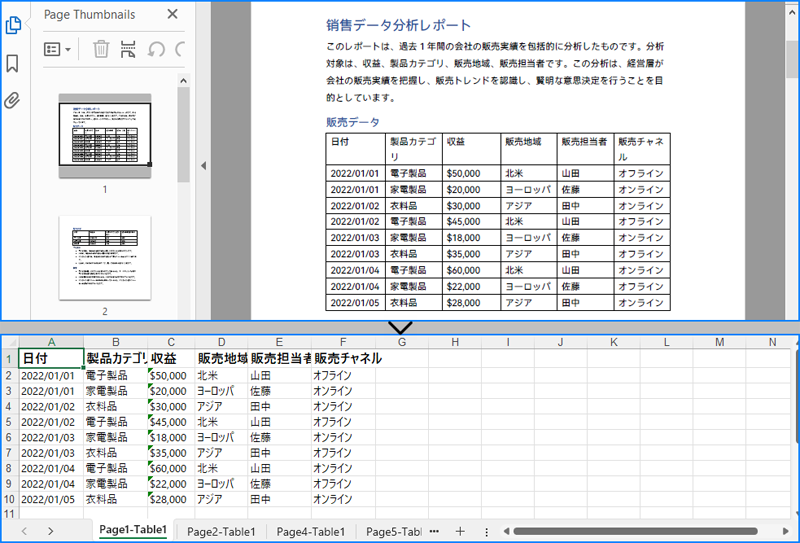
C# で PDF 表データを Excel ファイルに抽出する
PDF 表のセルの値を上記と同様に取得し、Spire.XLS for .NET を使用して Excel ファイルに書き出すことができます。最初に Spire.XLS for .NET をインストールする必要があります:
PM> Install-Package Spire.XLSPDF 表データを Excel ファイルに抽出する手順は以下の通りです:
- PdfDocument オブジェクトを作成し、PdfDocument.LoadFromFile() メソッドで PDF ドキュメントを読み込みます。
- Workbook オブジェクトを作成し、Workbook.Worksheets.Clear() メソッドでデフォルトのワークシートをクリアします。
- 読み込んだ PDF ドキュメントに対して PdfTableExtractor オブジェクトを作成します。
- PdfTableExtractor.ExtractTable() メソッドを使ってドキュメントの各ページにある表を抽出します。
- 各表を順に処理します:
- 表ごとに Workbook にワークシートを追加します。
- 行と列をループして、Table.GetText() メソッドを使ってセルの値を取得し、Worksheet.Range[].Text プロパティを通じて対応する位置に挿入します。
- セルの書式を設定します。
- 最後に Workbook.SaveToFile() メソッドを使ってワークブックを保存します。
- C#
using Spire.Pdf;
using Spire.Pdf.Utilities;
using Spire.Xls;
using System.Text;
namespace PDFTableToText
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成し、PDFドキュメントをロード
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Workbookオブジェクトを作成
Workbook workbook = new Workbook();
// デフォルトのワークシートをクリア
workbook.Worksheets.Clear();
// 読み込んだPDFのためのテーブルエクストラクターを初期化
PdfTableExtractor tableExtractor = new PdfTableExtractor(pdf);
// PDFの各ページを繰り返し処理
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
// 現在のページからテーブルを抽出
PdfTable[] tables = tableExtractor.ExtractTable(pageIndex);
if (tables != null)
{
// ページ上の各抽出されたテーブルを繰り返し処理
for (int tableIndex = 0; tableIndex < tables.Length; tableIndex++)
{
// ワークブックにワークシートを追加
Worksheet sheet = workbook.Worksheets.Add($"Page{pageIndex + 1}-Table{tableIndex + 1}");
// テーブル内の各行と列を繰り返し処理
for (int rowIndex = 0; rowIndex < tables[tableIndex].GetRowCount(); rowIndex++)
{
for (int columnIndex = 0; columnIndex < tables[tableIndex].GetColumnCount(); columnIndex++)
{
// テーブルからセルテキストを取得し、改行を削除
string cellText = tables[tableIndex].GetText(rowIndex, columnIndex);
string text = cellText.Replace("\n", "");
// ワークシートの対応する位置にセルテキストを挿入
sheet.Range[rowIndex + 1, columnIndex + 1].Text = text;
}
}
// テーブルヘッダのフォーマットを設定
sheet.Rows[0].Style.Font.FontName = "Yu Gothic UI";
sheet.Rows[0].Style.Font.Size = 12;
sheet.Rows[0].Style.Font.IsBold = true;
sheet.Rows[0].Style.HorizontalAlignment = HorizontalAlignType.Center;
// データ行のフォーマットを設定
for (int rowIndex = 1; rowIndex < sheet.Rows.Length; rowIndex++)
{
sheet.Rows[rowIndex].Style.Font.FontName = "Yu Gothic UI";
sheet.Rows[0].Style.Font.Size = 12;
sheet.Rows[0].Style.HorizontalAlignment = HorizontalAlignType.Left;
}
// 各列を自動調整
for (int columnIndex = 1; columnIndex <= sheet.Columns.Length; columnIndex++)
{
sheet.AutoFitColumn(columnIndex);
}
}
}
}
// ワークブックを保存
workbook.SaveToFile("PDFTableToExcel.xlsx", Spire.Xls.FileFormat.Version2016);
pdf.Close();
workbook.Dispose();
}
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





