PDF ドキュメントには、情報を分かりやすく伝えるために画像がよく使用されます。場合によっては、PDF ドキュメントから画像を抽出する必要があります。例えば、プレゼンテーションや他のドキュメントで、PDF レポートのチャート画像を使用したい場合です。本記事では、C# で Spire.PDF for .NET を使用して PDF から画像を抽出する方法を紹介します。
Spire.PDF for .NET をインストールします
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFC# で PDF ドキュメントから画像を抽出する
PdfPageBase.ExtractImages() メソッドを使用すると、1ページ内のすべての画像を抽出できます。開発者は、PDF ドキュメント内のすべてのページを繰り返し処理し、このメソッドを使用して画像を抽出することができます。詳細な手順は以下の通りです:
- PdfDocument オブジェクトを作成します。
- PdfDocument.LoadFromFile() メソッドを使用して PDF ドキュメントを読み込みます。
- ドキュメント内のすべてのページを繰り返し処理します。
- 各ページから PdfPageBase.ExtractImages() メソッドを使って画像を抽出し、保存します。
- C#
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.LoadFromFile("Sample.pdf");
int i = 0;
// Iterate through the pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
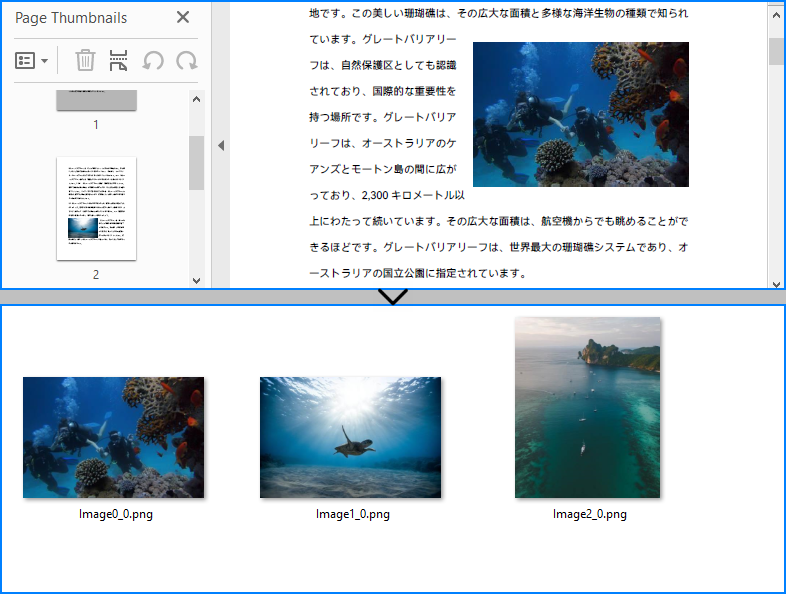
// Extract the images from the page and save them to file
int j = 0;
foreach (Image image in page.ExtractImages())
{
image.Save("Images/Image" + i + "_" + j + ".png");
j++;
}
i++;
}
}
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





