PDF 内のテキストや画像の座標を取得することで、要素を正確に特定でき、コンテンツの抽出が容易になります。これは特にデータ分析において重要で、複雑なレイアウトから必要な情報を引き出す際に役立ちます。また、座標を把握することで、適切な場所に注釈、マーク、スタンプを追加できるようになり、重要な箇所を強調表示したり、コメントを正確に追加したりすることで、ドキュメントのインタラクティブ性やコラボレーションを向上させることができます。
この記事では、Java で Spire.PDF for Java ライブラリを使用して、PDF ドキュメント内の特定のテキストや画像の座標を取得する方法を示します。
Spire.PDF for Java をインストールします
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.11.2</version>
</dependency>
</dependencies>Spire.PDF における座標系
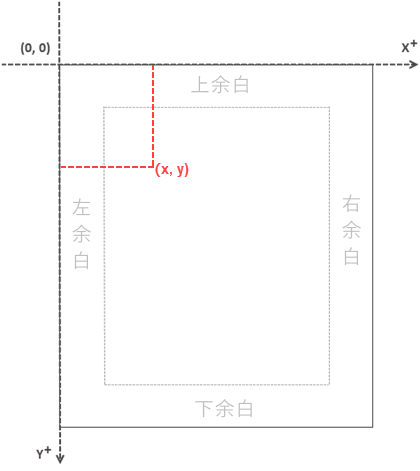
Spire.PDF for Java を使用して既存の PDF ドキュメントを操作する場合、座標系の原点はページの左上隅に位置していることに注意してください。X 軸は右方向に伸び、y 軸は下方向に伸びています。この座標系は以下の図で説明されています。
PDF 内の特定のテキストの座標を取得する
まず、PdfTextFinder.find() メソッドを使用して、ページ内の特定のテキストのすべての出現箇所を検索し、その結果を PdfTextFragment のリストとして取得します。その後、PdfTextFragment.getPositions() メソッドを使用して、指定したテキストの最初の出現箇所の座標を取得することができます。
以下は、PDF 内の特定のテキストの座標を取得する手順です:
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使用して PDF ファイルを読み込みます。
- PdfDocument.getPages().get() メソッドを使用して特定のページを取得します。
- PdfTextFinder.find() メソッドを使用して、ページ内の指定したテキストのすべての出現箇所を検索し、その結果を PdfTextFragment のリストとして取得します。
- リスト内の特定の PdfTextFragment にアクセスし、PdfTextFragment.getPositions() メソッドを使用してそのフラグメントの座標を取得します。
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextFindOptions;
import com.spire.pdf.texts.PdfTextFinder;
import com.spire.pdf.texts.PdfTextFragment;
import com.spire.pdf.texts.TextFindParameter;
import java.awt.geom.Point2D;
import java.util.EnumSet;
import java.util.List;
public class GetTextCoordinates {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.loadFromFile("Sample.pdf");
// 特定のページを取得
PdfPageBase page = doc.getPages().get(0);
// PdfTextFinderオブジェクトを作成
PdfTextFinder finder = new PdfTextFinder(page);
// 検索オプションを設定
PdfTextFindOptions options = new PdfTextFindOptions();
options.setTextFindParameter(EnumSet.of(TextFindParameter.WholeWord));
finder.setOptions(options);
// テキストのすべてのインスタンスを検索
List fragments = finder.find("海洋哺乳類");
// 特定のテキストフラグメントを取得
PdfTextFragment fragment = fragments.getFirst();
// テキストの位置を取得(テキストが複数行にまたがっている場合、複数の位置が返される)
Point2D[] positions = fragment.getPositions();
// 最初の位置を取得
double x = positions[0].getX();
double y = positions[0].getY();
// 結果を表示
System.out.printf("テキストの位置: (%f, %f).%n", x, y);
}
} 
PDF 内の特定の画像の座標を取得する
まず、PdfImageHelper.getImagesInfo() メソッドを使用して、指定したページ内のすべての画像情報を取得し、その結果を PdfImageInfo の配列として保存します。その後、PdfImageInfo.getBounds().getX() および PdfImageInfo.getBounds().getY() メソッドを使用して、特定の画像の X 座標および Y 座標を取得します。
以下は、PDF 内の特定の画像の座標を取得する手順です:
- PdfDocument オブジェクトを作成します。
- PdfDocument.loadFromFile() メソッドを使用して PDF ファイルを読み込みます。
- PdfDocument.getPages().get() メソッドを使用して特定のページを取得します。
- PdfImageHelper.getImagesInfo() メソッドを使用してページ内のすべての画像情報を取得し、その結果を PdfImageInfo の配列として保存します。
- PdfImageInfo.getBounds().getX() および PdfImageInfo.getBounds().getY() メソッドを使用して、特定の画像のX座標およびY座標を取得します。
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
public class GetImageCoordinates {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.loadFromFile("Sample.pdf");
// 特定のページを取得
PdfPageBase page = doc.getPages().get(0);
// PdfImageHelperオブジェクトを作成
PdfImageHelper helper = new PdfImageHelper();
// ページから画像情報を取得
PdfImageInfo[] imageInfo = helper.getImagesInfo(page);
// 最初の画像のX, Y座標を取得
double x = imageInfo[0].getBounds().getX();
double y = imageInfo[0].getBounds().getY();
// 結果を表示
System.out.printf("画像の位置: (%f, %f).%n", x, y);
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





