Spire.OCR for .NET は、プロフェッショナルな OCR ライブラリであり、.NET Framework および .NET Core アプリケーションで画像(JPG、PNG、GIF、BMP、TIFF など)からテキストを認識することをサポートします。本記事では、Spire.OCR for .NET を使用して .NET Framework アプリケーションで画像からテキストを抽出する方法を説明します。
具体的な手順は以下の通りです。
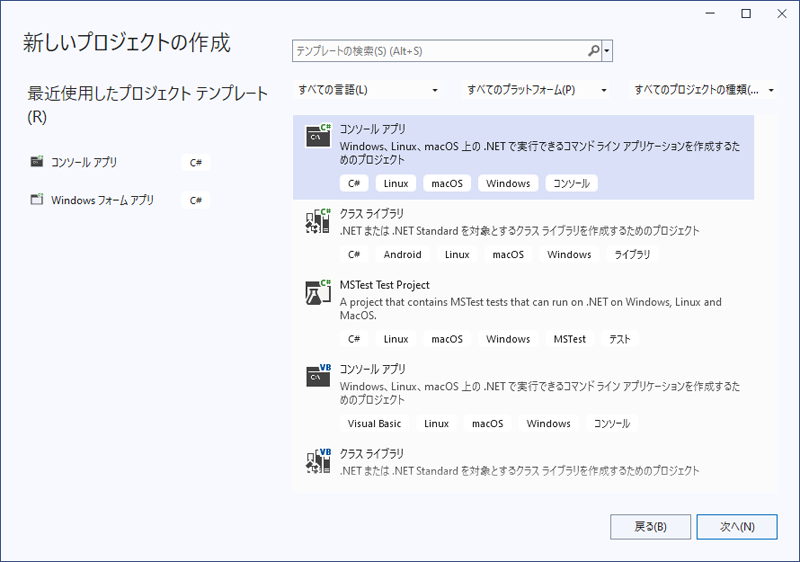
1. Visual Studio でコンソールアプリ (.NET Framework) を作成する
まず、Visual Studio を使用して .NET Framework を対象としたコンソールアプリを作成します。
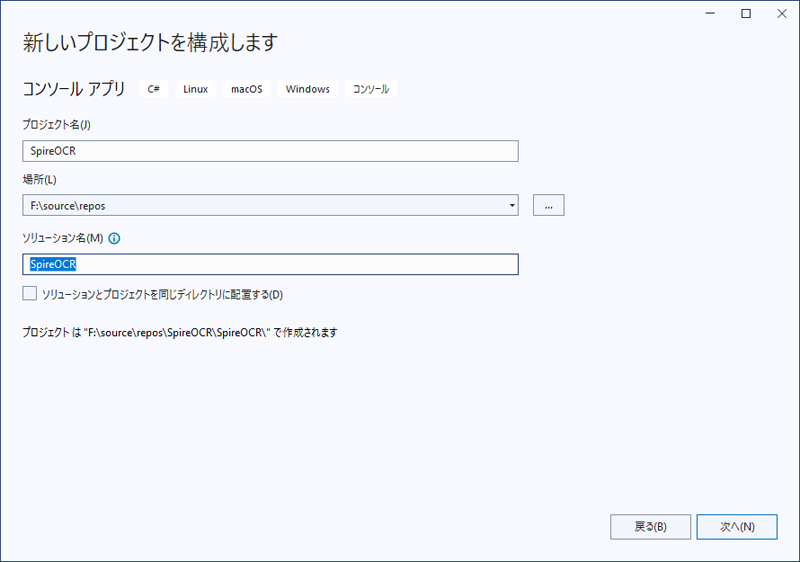
2. アプリケーションのプラットフォームターゲットを x64 に変更する
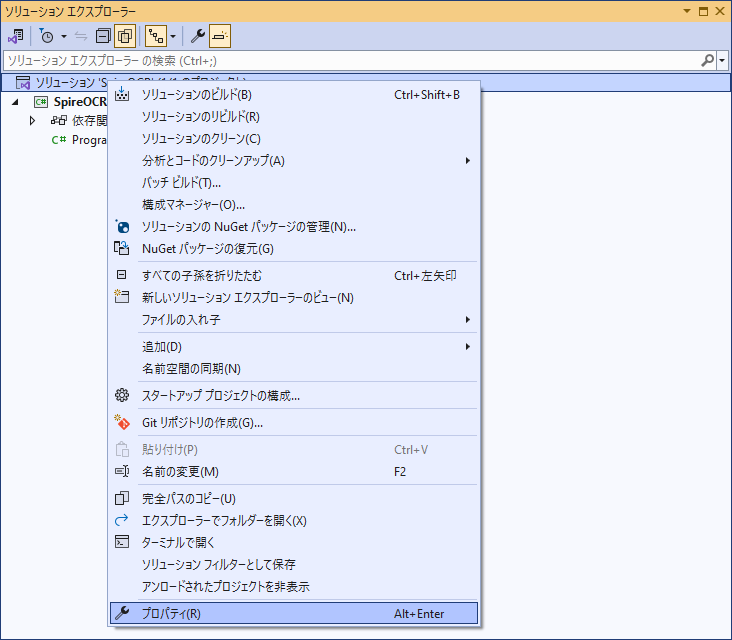
アプリケーションのソリューションエクスプローラーでプロジェクト名を右クリックし、「プロパティ」を選択します。
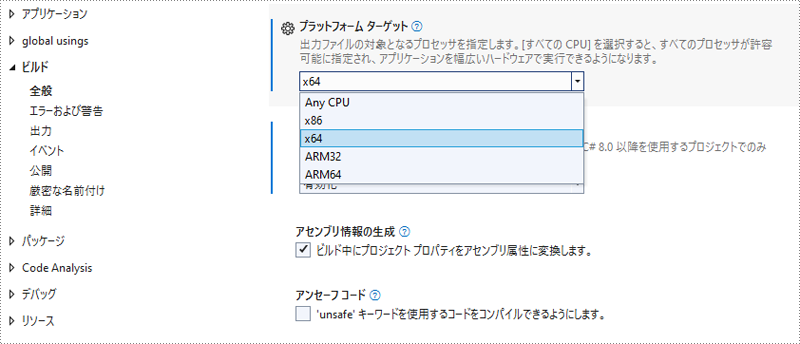
プラットフォームターゲットを x64 に変更します。この手順は必須で、Spire.OCR が 64 ビットプラットフォームのみをサポートしているためです。
3. Spire.OCR for .NET をアプリケーションにインストールする
NuGet を使用して Spire.OCR for .NET をインストールします。以下のコマンドを NuGet パッケージマネージャーコンソールで実行してください。
Install-Package Spire.OCR
4. Spire.OCR for .NET の新しいモデルをダウンロードする
お使いのオペレーティングシステムに適したモデルを以下のリンクからダウンロードしてください。
次に、パッケージを解凍し、コンピューター上の特定のディレクトリに保存します。この例では、パッケージを "D:\" に保存しました。
5. C# で Spire.OCR for .NET を使用して画像からテキストを抽出する
以下のコード例は、C# を使用して Spire.OCR for .NET の新しいモデルで画像からテキストを抽出する方法を示しています。
- C#
using Spire.OCR;
using System.IO;
namespace NewOCRModel
{
internal class Program
{
static void Main(string[] args)
{
// ライセンスキーを設定
// Spire.OCR.License.LicenseProvider.SetLicenseKey("your-license-key");
// OcrScanner クラスのインスタンスを作成
OcrScanner scanner = new OcrScanner();
// スキャナー構成を設定するために ConfigureOptions クラスのインスタンスを作成
ConfigureOptions configureOptions = new ConfigureOptions();
// モデルのパスを設定
configureOptions.ModelPath = "D:\\win-x64";
// テキスト認識の言語を設定します。デフォルトは英語です。
// サポートされている言語には、英語、中国語、中国語繁体字、フランス語、ドイツ語、日本語、韓国語があります。
configureOptions.Language = "English";
// 構成オプションをスキャナーに適用
scanner.ConfigureDependencies(configureOptions);
// 画像からテキストを抽出
scanner.Scan("test.png");
// 抽出したテキストをテキストファイルに保存
string text = scanner.Text.ToString();
File.WriteAllText("Output.txt", text);
}
}
}一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





