OCR(光学文字認識)技術は、画像からテキストを抽出するための主要な方法です。Spire.OCR for Java は、Java プロジェクトにおいて画像からテキストをスキャンして抽出するための迅速かつ効率的なソリューションを提供します。本記事では、Spire.OCR for Java を使用して、画像からテキストを認識・抽出する方法を解説します。
Spire.OCR for Java のインストール手順
Spire.OCR for Java を使用して画像内のテキストをスキャンおよび認識するには、まず Spire.OCR.jar ファイルとモデルファイルを Java プロジェクトにインポートする必要があります。
以下は、Spire.OCR for Java とモデルファイルを Java プラグラムにインストールする手順です:
1. IntelliJ IDEA で Java プロジェクトを作成する
最初に、IntelliJ IDEA を使用して新しい Java プロジェクトを作成します。
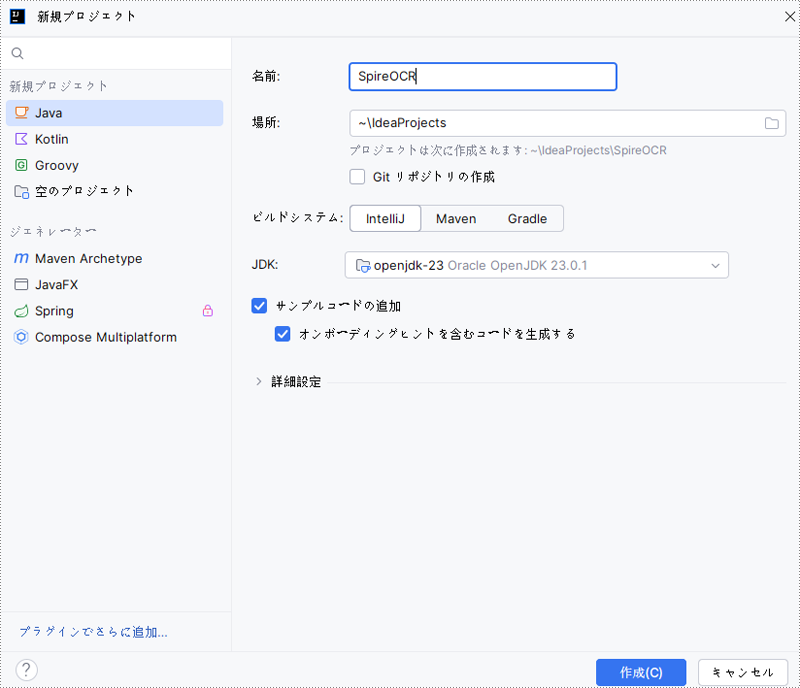
2. プロジェクトに Spire.OCR.jar を追加する
オプション 1:Maven を使用して Spire.OCR for Java をインストールする
Maven を使用している場合、次のコードをプロジェクトの pom.xml ファイルに追加することで、Spire.OCR for Java をインストールできます:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>1.9.19</version>
</dependency>
</dependencies>オプション 2:Spire.OCR.jar を手動でインポートする
まず、以下のリンクから Spire.OCR for Java をダウンロードし、特定のディレクトリに解凍します:
https://jp.e-iceblue.com/download/spire-ocr-for-java.html
次に、IntelliJ IDEA で「ファイル」>「プロジェクト構造」>「モジュール」>「依存関係」に移動します。依存関係のペインで「+」ボタンをクリックし、「JARs または ディレクトリ」を選択します。Spire.OCR for Java が保存されているディレクトリに移動し、lib フォルダを開いて Spire.OCR.jar ファイルを選択し、OK をクリックしてプロジェクトの依存関係として追加します。
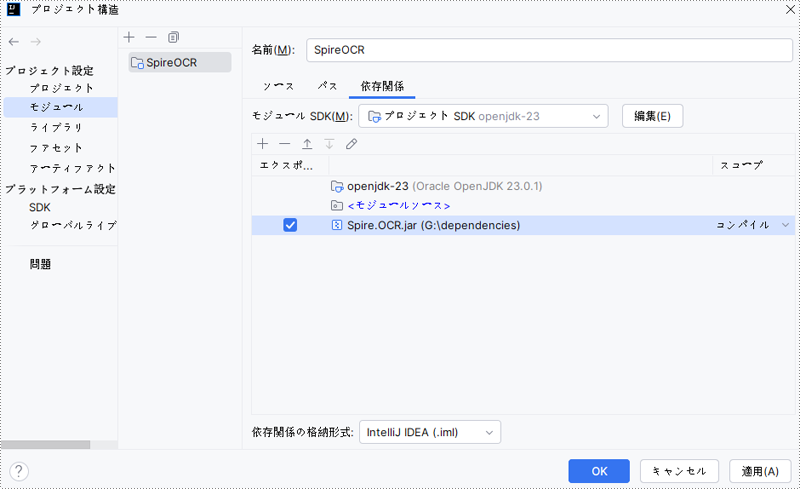
3. その他の依存ファイルをダウンロードして配置する
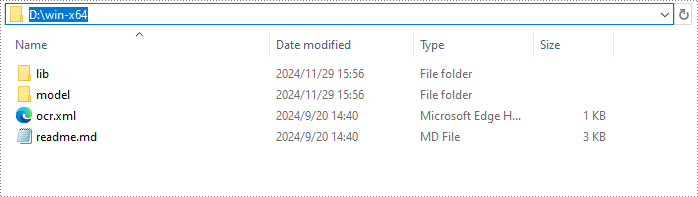
ご使用のオペレーティングシステムに適したモデルを以下のリンクからダウンロードしてください。
次に、パッケージを解凍し、コンピューターの特定のディレクトリに保存します。この例では、パッケージを「D:\」に保存しました。
Spire.OCR for Java を使用して画像からテキストを抽出する
以下は、Spire.OCR for Java を使用して画像からテキストを認識および抽出するためのコード例です:
- Java
import com.spire.ocr.*;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
try {
// OcrScanner クラスのインスタンスを作成
OcrScanner scanner = new OcrScanner();
// スキャナー設定を行うために ConfigureOptions クラスのインスタンスを作成
ConfigureOptions configureOptions = new ConfigureOptions();
// 新しいモデルへのパスを設定
configureOptions.setModelPath("D:\\win-x64");
// テキスト認識の言語を設定。デフォルトは英語です。
// サポートされている言語には、英語、中国語、繁体字中国語、フランス語、ドイツ語、日本語、韓国語があります。
// English, Chinese, Chinesetraditional, French, German, Japanese, Korean
configureOptions.setLanguage("Japanese");
// スキャナーに設定オプションを適用
scanner.ConfigureDependencies(configureOptions);
// 画像からテキストを抽出
scanner.scan("Sample.png");
// 抽出したテキストをテキストファイルに保存
saveTextToFile(scanner, "output.txt");
} catch (OcrException e) {
e.printStackTrace();
}
}
private static void saveTextToFile(OcrScanner scanner, String filePath) {
try {
String text = scanner.getText().toString();
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
writer.write(text);
}
} catch (IOException | OcrException e) {
e.printStackTrace();
}
}
}一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





