

Web コンテンツやドキュメントを扱う際、Python で HTML を解析する能力は、さまざまな分野の開発者にとって不可欠なスキルです。HTML 解析とは、HTML ドキュメントから必要な情報を抽出し、コンテンツを操作し、Web データを効率的に処理することを指します。Web スクレイピング、データ抽出、コンテンツ分析、ドキュメント処理など、どのような用途でも、Python での HTML 解析を習得することで、開発効率と処理能力を大幅に向上させることができます。
本記事では、Spire.Doc for Python を使用して HTML を効率的に解析する方法を紹介します。HTML 文字列・ローカル HTML ファイル・Web URL から HTML を読み込む実践的な方法と、HTML 解析のベストプラクティスについて解説します。
HTML(HyperText Markup Language)は Web の基盤であり、Web コンテンツの構造化と表示に使用されます。HTML を解析することで、次のような処理が可能になります。
BeautifulSoup のようなライブラリが軽量な解析に優れている一方で、Spire.Doc for Python は、HTML 解析とドキュメント作成や変換を統合する必要がある場合に真価を発揮します。構造化されたドキュメントオブジェクトモデル (DOM) として HTML コンテンツを解析し、操作するための堅牢なフレームワークを提供します。
HTML 解析を始める前に、Spire.Doc for Python をインストールする必要があります。PyPI から簡単にインストールできます。
pip install Spire.Doc
このコマンドにより、最新バージョンのライブラリと依存関係がインストールされます。インストール後、すぐに HTML 解析を開始できます。
Spire.Doc は、HTML のタグベース構造を階層型ドキュメントモデルへ変換することで HTML を解析します。このモデルは、セクション・段落・その他の要素を表すオブジェクトで構成されており、元の HTML 構造を再現します。
それでは、実際のコードで確認してみましょう。
API レスポンスやユーザー入力など、小さな HTML スニペットを扱う場合は、文字列から直接 HTML を解析できます。テスト用途や短い静的 HTML の処理に最適です。
from spire.doc import *
from spire.doc.common import *
# HTMLコンテンツを文字列として定義
html_string = """
<html>
<head>
<title>サンプルページ</title>
</head>
<body>
<h1>ようこそ</h1>
<p>これは<strong>HTML解析</strong>のデモです。</p>
<ul>
<li>機能1:文字列の読み取り</li>
<li>機能2:ファイルの読み取り</li>
<li>機能3:URLの読み取り</li>
</ul>
</body>
</html>
"""
# 新しいDocumentオブジェクトを初期化
doc = Document()
# ドキュメントにセクションと段落を追加
section = doc.AddSection()
paragraph = section.AddParagraph()
# 文字列からHTMLコンテンツを読み込む
paragraph.AppendHTML(html_string)
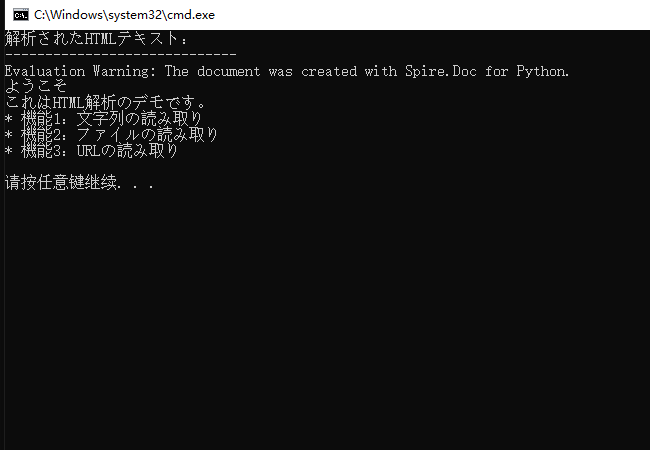
print("解析されたHTMLテキスト:")
print("-----------------------------")
# 解析されたHTMLからテキストコンテンツを抽出
parsed_text = doc.GetText()
# 結果を表示
print(parsed_text)
# ドキュメントを閉じる
doc.Close()
動作の仕組み:
<h1> は「見出し1」スタイルに、<ul> はリストになります)。出力結果:
また、Spire.Doc は SaveToFile() メソッドを使用して、解析した HTML を PDF や Word 形式などへエクスポートすることも可能です。
ローカル HTML ファイルの場合、Spire.Doc を使えば 1 つのメソッドで読み込みと解析を行えます。ダウンロードした Web ページや静的レポートなど、オフラインコンテンツの処理に便利です。
from spire.doc import *
from spire.doc.common import *
# ローカルHTMLファイルへのパスを定義
html_file_path = "example.html"
# Documentインスタンスを作成
doc = Document()
# HTMLファイルを読み込み、解析
doc.LoadFromFile(html_file_path, FileFormat.Html)
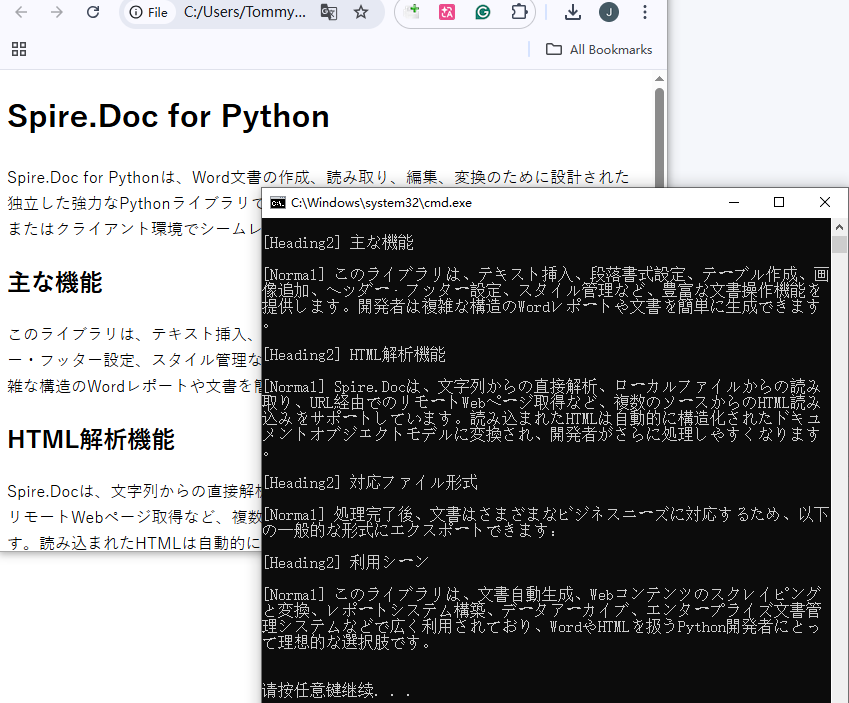
# ドキュメント構造を分析
print(f"ドキュメントには{doc.Sections.Count}個のセクションがあります")
print("-"*40)
# 各セクションを処理
for section_idx in range(doc.Sections.Count):
section = doc.Sections.get_Item(section_idx)
print(f"セクション {section_idx + 1}")
print(f"セクションには{section.Body.Paragraphs.Count}個の段落があります")
print("-"*40)
# 現在のセクション内の段落を走査
for para_idx in range(section.Paragraphs.Count):
para = section.Paragraphs.get_Item(para_idx)
# 段落スタイル名とテキストコンテンツを取得
style_name = para.StyleName
para_text = para.Text
# コンテンツが存在する場合に段落情報を表示
if para_text.strip():
print(f"[{style_name}] {para_text}\n")
# セクション間に間隔を追加
print()
# ドキュメントを閉じる
doc.Close()
主な機能:
出力結果:
HTML を Document オブジェクトへ読み込んだ後は、テキストやハイパーリンクなどの要素も抽出できます。
Web ページを直接解析する場合は、まず requests ライブラリで HTML を取得し、その HTML を Spire.Doc に渡して解析します。これは Web スクレイピングやリアルタイムデータ抽出の基本的な方法です。
Requests ライブラリをインストール:
pip install requests
Web ページ解析用 Python コード:
from spire.doc import *
from spire.doc.common import *
import requests
# URLからHTMLコンテンツを取得
def fetch_html_from_url(url):
"""URLからHTMLを取得し、エラー(404、ネットワーク問題など)を処理する"""
# User-Agentでブラウザを模倣する(Webサイトによるブロックを回避)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # HTTPエラーに対して例外を発生させる
return response.text # 生のHTMLコンテンツを返す
except requests.exceptions.RequestException as e:
raise Exception(f"HTMLの取得エラー: {str(e)}")
# 対象URLを指定
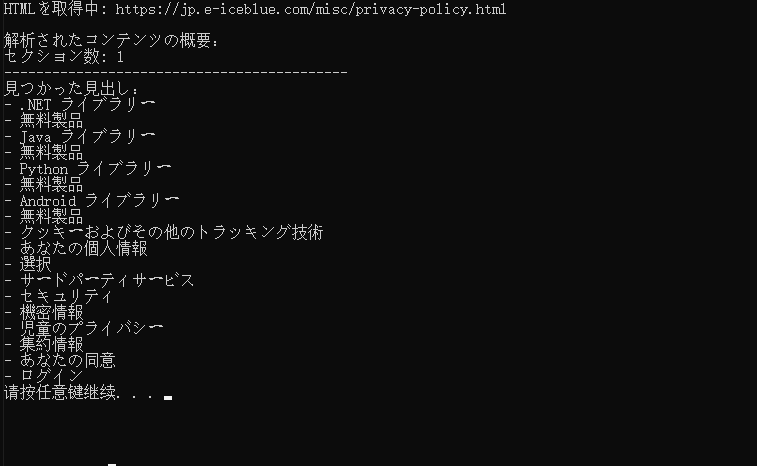
url = "https://jp.e-iceblue.com/misc/privacy-policy.html"
print(f"HTMLを取得中: {url}")
# HTMLコンテンツを取得
html_content = fetch_html_from_url(url)
# ドキュメントを作成し、HTMLコンテンツを挿入
doc = Document()
section = doc.AddSection()
paragraph = section.AddParagraph()
paragraph.AppendHTML(html_content)
# 概要情報を抽出して表示
print("\n解析されたコンテンツの概要:")
print(f"セクション数: {doc.Sections.Count}")
print("-------------------------------------------")
# 見出しを抽出して表示
print("見つかった見出し:")
for para_idx in range(section.Paragraphs.Count):
para = section.Paragraphs.get_Item(para_idx)
if isinstance(para, Paragraph) and para.StyleName.startswith("Heading"):
print(f"- {para.Text.strip()}")
# ドキュメントを閉じる
doc.Close()
手順の説明:
出力結果:
Spire.Doc を使った HTML 解析を最適化するために、以下のポイントを意識しましょう。
import os
html_file = "data.html"
if os.path.exists(html_file):
doc.LoadFromFile(html_file, FileFormat.Html)
else:
print(f"エラー: ファイル '{html_file}' が見つかりません。")
try:
doc.LoadFromFile("sample.html", FileFormat.Html)
except Exception as e:
print(f"HTMLの読み込みエラー: {e}")
大きなファイルの最適化:大きな HTML ファイルの場合、パフォーマンスを向上させるために、コンテンツをチャンクで読み込むか、必須でない解析機能を無効にすることを検討してください。
抽出データのクリーニング:strip() や replace() を使って不要な空白や文字を削除します。
ライブラリを最新に保つ:pip install --upgrade Spire.Doc で Spire.Doc を定期的に更新し、改善された解析ロジックとバグ修正の恩恵を受けてください。
Python により、あらゆるスキルレベルの開発者が HTML 解析にアクセスできるようになります。HTML 文字列、ローカルファイル、Web URL のいずれを扱う場合でも、Requests(HTML 取得)と Spire.Doc(構造化解析)を組み合わせることで、Web スクレイピングやコンテンツ抽出をシンプルに実現できます。
本記事のサンプルコードとベストプラクティスを活用すれば、非構造化 HTML を数分で整理された実用的なデータへ変換できるようになります。
Spire.Doc for Python の全機能を試したい場合は、30 日間の試用ライセンスを申請してください。

PDF ドキュメントに適切なフォントを適用することで、可読性と視覚的な魅力が向上します。基本的なテキストレンダリング、多言語サポート、またはカスタムブランディングのいずれが必要であっても、Spire.PDF for Python は標準 PDF フォント、TrueType フォント、プライベートフォント、CJK フォントを含む柔軟なフォントオプションを提供します。
このチュートリアルでは、Spire.PDF for Python を使用して Python でさまざまなフォントを扱う実践的な手法を紹介し、プロ品質の PDF 文書を効率的に作成する方法について解説します。
クイックナビゲーション
開始する前に、以下を確認してください:
Python 3.x がインストールされていること
Spire.PDF for Python がインストールされていること:
pip install Spire.PDF
また、Spire.PDF for Python をダウンロードして、プロジェクトに手動で追加することもできます。
オプション: プライベートフォント用のカスタムフォントファイル (.ttf または .otf)
標準 PDF フォントは PDF 仕様に組み込まれており、埋め込みは不要です。14 の標準フォントには、Helvetica、Times Roman、Courier、Symbol、ZapfDingbats (太字/斜体バリアントを含む) があります。軽量ドキュメントで普遍的な互換性が必要な場合に最適です。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
pdf = PdfDocument()
page = pdf.Pages.Add()
brush = PdfBrushes.get_Black()
y = 50.0
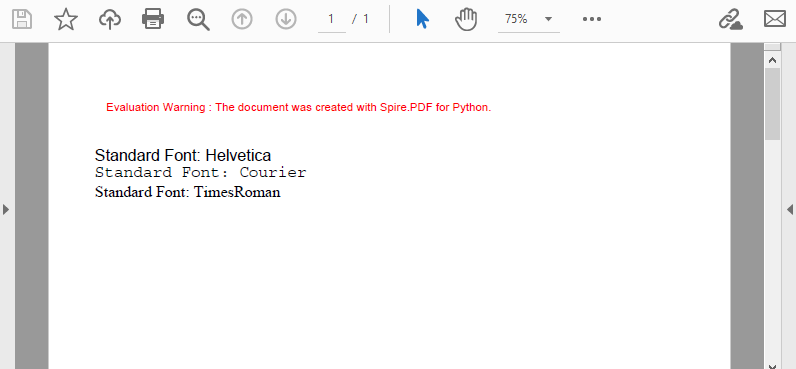
# Helvetica フォントを適用
font = PdfFont(PdfFontFamily.Helvetica, 14.0)
page.Canvas.DrawString("Standard Font: Helvetica", font, brush, 0.0, y)
# Courier フォントを適用
font = PdfFont(PdfFontFamily.Courier, 14.0)
page.Canvas.DrawString("Standard Font: Courier", font, brush, 0.0, (y := y + 16.0))
# Times Roman フォントを適用
font = PdfFont(PdfFontFamily.TimesRoman, 14.0)
page.Canvas.DrawString("Standard Font: TimesRoman", font, brush, 0.0, (y := y + 16.0))
# ドキュメントを保存
pdf.SaveToFile("StandardFonts.pdf")
pdf.Close()
以下に生成されたPDF文書を示します。
重要なポイント:
PdfFontFamily 列挙型を使用してフォントインスタンスを作成PDF にテキストを描画する方法についてさらに詳しく知りたい場合は、「Python で PDF にテキストを追加する方法」をご参照ください。
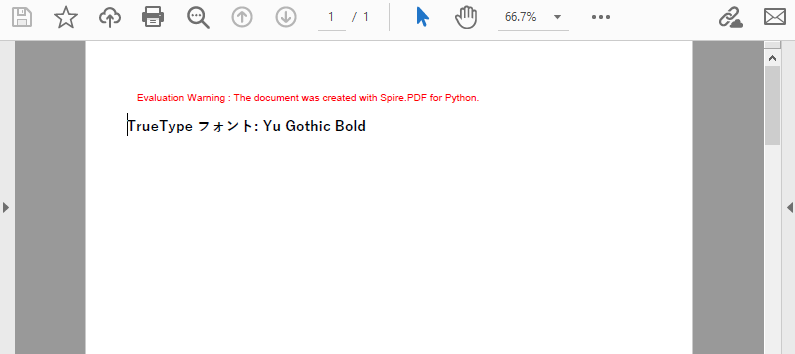
TrueType フォント (.ttf) は、標準フォントと比較してより優れたレンダリング品質と拡張された文字サポートを提供します。太字、斜体スタイルをサポートし、多言語コンテンツに適しています。
from spire.pdf.common import *
from spire.pdf import *
pdf = PdfDocument()
page = pdf.Pages.Add()
brush = PdfBrushes.get_Black()
y = 30.0
# Yu Gothic フォントを太字スタイルで適用
trueTypeFont = PdfTrueTypeFont("Yu Gothic", 14.0, PdfFontStyle.Bold, True)
page.Canvas.DrawString("TrueType フォント: Yu Gothic Bold", trueTypeFont, brush, 0.0, y)
pdf.SaveToFile("TrueTypeFonts.pdf")
pdf.Close()
以下に生成されたPDF文書を示します。
API の説明:
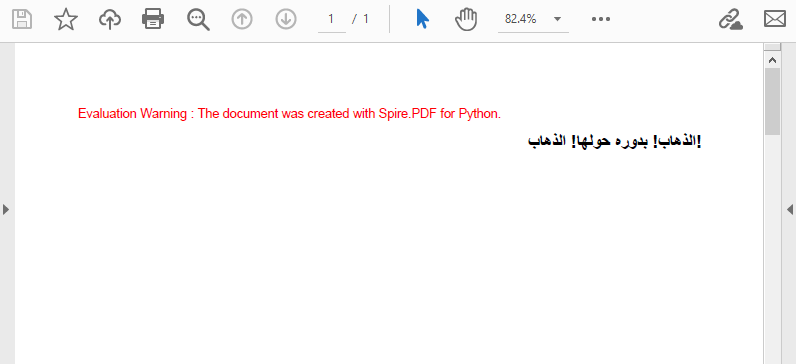
アラビア語やヘブライ語などの言語の場合、テキスト方向を設定:
from spire.pdf.common import *
from spire.pdf import *
pdf = PdfDocument()
page = pdf.Pages.Add()
brush = PdfBrushes.get_Black()
y = 30.0
# アラビア語テキストの例
arabicText = "\u0627\u0644\u0630\u0647\u0627\u0628\u0021\u0020" + \
"\u0628\u062F\u0648\u0631\u0647\u0020\u062D\u0648\u0644\u0647\u0627\u0021\u0020" + \
"\u0627\u0644\u0630\u0647\u0627\u0628\u0021"
trueTypeFont = PdfTrueTypeFont("Arial", 14.0, PdfFontStyle.Bold, True)
rctg = RectangleF(PointF(0.0, y), page.Canvas.ClientSize)
strformat = PdfStringFormat(PdfTextAlignment.Right)
strformat.RightToLeft = True
page.Canvas.DrawString(arabicText, trueTypeFont, brush, rctg, strformat)
pdf.SaveToFile("RTLText.pdf")
pdf.Close()
以下に生成されたPDF文書を示します。
実装ノート:
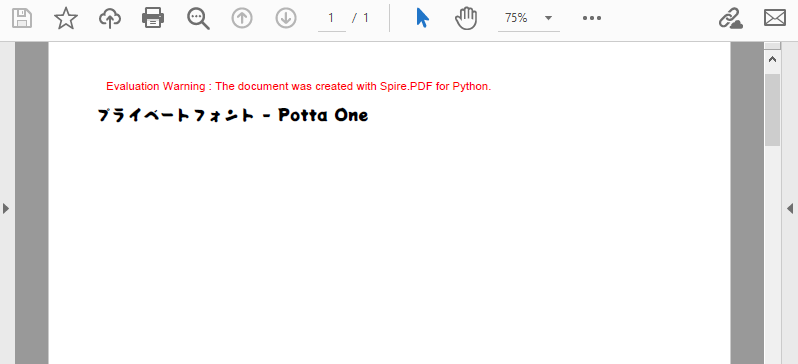
RightToLeft = True を設定PdfStringFormat を使用してテキスト配置を制御RectangleF) を定義プライベートフォントにより、ターゲットシステムにインストールされていないカスタムフォントファイル (.ttf/.otf) を埋め込むことができます。これにより、異なる環境間で一貫したブランディングとタイポグラフィが保証されます。
from spire.pdf.common import *
from spire.pdf import *
pdf = PdfDocument()
page = pdf.Pages.Add()
brush = PdfBrushes.get_Black()
y = 30.0
# カスタムフォントファイルを読み込む (作業ディレクトリにファイルが存在することを確認)
trueTypeFont = PdfTrueTypeFont("POTTAONE-REGULAR.TTF", 14.0)
page.Canvas.DrawString("プライベートフォント - Potta One", trueTypeFont, brush, 0.0, y)
pdf.SaveToFile("PrivateFonts.pdf")
pdf.Close()
以下に生成されたPDF文書を示します。
使用のヒント:
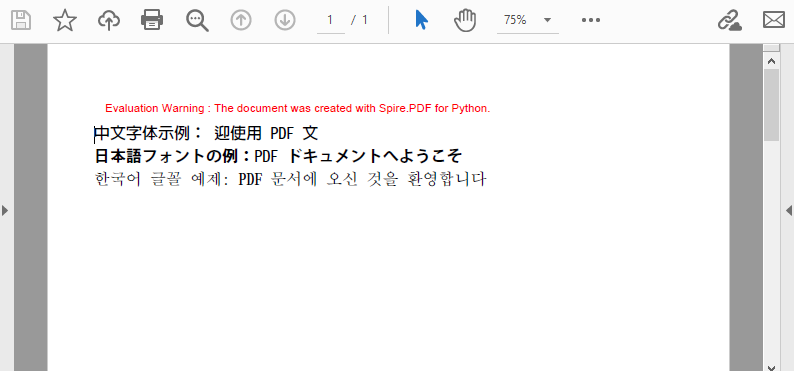
PdfTrueTypeFont を介して読み込まれると、フォントは自動的に埋め込まれるCJK (中国語、日本語、韓国語) フォントは、東アジア言語に必要な数千の文字をサポートします。Spire.PDF は、各言語に最適化されたフォントファミリーを提供します。
from spire.pdf.common import *
from spire.pdf import *
pdf = PdfDocument()
page = pdf.Pages.Add()
brush = PdfBrushes.get_Black()
y = 30.0
# Monotype Hei Medium で中国語テキストを描画
cjkFont = PdfCjkStandardFont(PdfCjkFontFamily.MonotypeHeiMedium, 14.0)
page.Canvas.DrawString("中文字体示例:欢迎使用 PDF 文档", cjkFont, brush, 0.0, y)
# Hanyang Systems Gothic Medium で日本語テキストを描画
cjkFont = PdfCjkStandardFont(PdfCjkFontFamily.HanyangSystemsGothicMedium, 14.0)
page.Canvas.DrawString("日本語フォントの例:PDF ドキュメントへようこそ", cjkFont, brush, 0.0, (y := y + 20.0))
# Hanyang Systems Shin MyeongJo Medium で韓国語テキストを描画
cjkFont = PdfCjkStandardFont(PdfCjkFontFamily.HanyangSystemsShinMyeongJoMedium, 14.0)
page.Canvas.DrawString("한국어 글꼴 예제: PDF 문서에 오신 것을 환영합니다", cjkFont, brush, 0.0, (y := y + 20.0))
pdf.SaveToFile("CJKFonts.pdf")
pdf.Close()
以下に生成されたPDF文書を示します。
フォントファミリーの選択:
正しいフォントファミリーを使用することで、各言語の適切なグリフレンダリングが保証されます。
問題: フォントファイルが見つからない場合、PdfTrueTypeFont がエラーをスロー。
解決策:
import os
font_path = "custom_font.ttf"
if os.path.exists(font_path):
font = PdfTrueTypeFont(font_path, 14.0)
else:
print(f"フォントファイルが見つかりません: {font_path}")
問題: 中国語/日本語/韓国語の文字が空白の四角形または疑問符として表示される。
解決策:
問題: アラビア語またはヘブライ語のテキストが右から左ではなく左から右にレンダリングされる。
解決策:
strformat = PdfStringFormat(PdfTextAlignment.Right)
strformat.RightToLeft = True
page.Canvas.DrawString(text, font, brush, rectangle, strformat)
RightToLeft = True を設定問題: 一部の文字が正しく表示されないか、完全に欠落している。
解決策:
PDF ドキュメントに適切なフォントを適用することは、可読性、多言語サポート、全体的なドキュメントプレゼンテーションを向上させるために不可欠です。Spire.PDF for Python を使用すると、標準 PDF フォント、TrueType フォント、プライベートフォント、CJK フォントを扱うことができ、異なる言語と書式要件に対応したプロフェッショナルな PDF ドキュメントを作成できます。
各シナリオに適したフォントタイプを選択することで、互換性、外観、ファイルサイズのバランスをより効果的に取ることができます。レポート、請求書、多言語ドキュメント、またはブランド付き PDF を生成する場合でも、Spire.PDF は Python アプリケーション向けの柔軟なフォント処理機能を提供します。
Spire.PDF for Python を評価し、評価制限を解除したい場合は、30 日間の無料トライアルを申請できます。
標準 PDF フォントは埋め込みを必要としない 14 の組み込みフォント (Helvetica、Times Roman など) で、ファイルサイズが小さくなります。TrueType フォント (.ttf) は外部フォントファイルで、より優れたレンダリング品質と幅広い文字サポートを提供しますが、PDF に埋め込む必要があります。
はい、任意の TrueType (.ttf) または OpenType (.otf) フォントファイルを使用できます。ただし、フォントのライセンス条項を確認してください — 一部のフォントは埋め込みを制限したり、配布に商用ライセンスを必要としたりします。
CJK 表示の問題は通常、言語に対して間違ったフォントファミリーを使用した場合に発生します。言語固有の CJK フォントを使用してください: 中国語には MonotypeHeiMedium、日本語には HanyangSystemsGothicMedium、韓国語には HanyangSystemsShinMyeongJoMedium。
はい、フォントデータが PDF に含まれるため、フォントの埋め込みによりファイルサイズが増加します。影響を最小限に抑えるには:
もちろんです。同じ PDF 内で標準フォント、TrueType フォント、プライベートフォント、CJK フォントを組み合わせることができます。各テキスト要素に異なるフォントを使用できるため、豊かなタイポグラフィと多言語コンテンツが可能になります。
本番環境デプロイメントの場合:

リストは PDF ドキュメント作成 の基本的な要素であり、項目のコレクションを効率的に整理して提示することができます。PDF で最も一般的に使用される 3 つのリストタイプは、順序付きリスト、順序なしリスト(箇条書きリストとも呼ばれる)、および ネストされたリスト です。これらのリストは、PDF ドキュメント内で情報を整理され視覚的に魅力的な方法で提示することを可能にします。
このガイドでは、Spire.PDF for Python を使用して、プロフェッショナルな PDF ドキュメントを生成するために PDF ドキュメントで順序付き、順序なし、ネストされたリストを作成する方法を探ります。Spire.PDF for Python が提供する機能を利用することで、開発者はこれらのリストを簡単にフォーマットし、PDF ページに組み込むことができます。
クイックナビゲーション
開始する前に、以下が準備されていることを確認してください:
Python 3.x がインストールされていること
Spire.PDF for Python および plum-dispatch v1.7.4 がインストールされていること:
pip install Spire.PDF
また、Spire.PDF for Python パッケージをダウンロードして、プロジェクトに手動で追加することもできます。
PDF ドキュメント構造の基本的な理解
このガイドでは、単純な順序付きリストから複雑なネスト構造まで、さまざまなリスト作成手法を実演します。
実装に入る前に、Spire.PDF for Python でリストを作成するために利用可能な主要なクラスとプロパティを理解することが重要です。
PdfSortedList クラスと PdfList クラスは、PDF ドキュメントでさまざまなタイプのリストを生成するための主要なコンポーネントです。以下の表は、主要なクラスとプロパティを要約しています:
| クラスまたはプロパティ | 説明 |
|---|---|
PdfSortedList クラス |
PDF ドキュメント内の順序付きリストを表します。 |
PdfList クラス |
PDF ドキュメント内の順序なしリストを表します。 |
Brush プロパティ |
リストのブラシを取得または設定します。 |
Font プロパティ |
リストのフォントを取得または設定します。 |
Indent プロパティ |
リストのインデントを取得または設定します。 |
TextIndent プロパティ |
マーカーからリスト項目テキストまでのインデントを取得または設定します。 |
Items プロパティ |
リストの項目を取得します。 |
Marker プロパティ |
リストのマーカーを取得または設定します。 |
Draw() メソッド |
指定された位置でページのキャンバスにリストを描画します。 |
PdfOrderedMarker クラス |
数字、文字、ローマ数字など、順序付きリストのマーカー样式を表します。 |
PdfMarker クラス |
順序なしリストの箇条記号样式を表します。 |
これらのクラスはリストのフォーマットを包括的に制御し、開発者がフォント、マーカー、インデント、位置付けをカスタマイズしてプロフェッショナルな PDF 出力を可能にします。
開発者は Spire.PDF for Python の PdfSortedList クラスを使用して順序付きリストを作成し、このクラスで使用可能なプロパティを使用してフォーマットできます。その後、PdfSortedList.Draw() メソッドを使用してリストを PDF ページに描画できます。
PDF ドキュメントで順序付きリストを作成する方法の詳細なステップバイステップガイド:
PdfDocument クラスのオブジェクトを作成PdfDocument.Pages.Add() メソッドを使用してドキュメントにページを追加PdfPageBase.Canvas.DrawString() メソッドを使用してページ上にリストタイトルを描画PdfSortedList クラスのインスタンスを初期化PdfOrderedMarker クラスのインスタンスを初期化PdfSortedList.Draw() メソッドを使用してページ上にリストを描画PdfDocument.SaveToFile() メソッドを使用してドキュメントを保存from spire.pdf import *
from spire.pdf.common import *
# PdfDocument クラスのオブジェクトを作成
pdf = PdfDocument()
# 指定されたページサイズと余白でドキュメントにページを追加
page = pdf.Pages.Add()
# タイトルフォントとリストフォントを作成
titleFont = PdfTrueTypeFont("Yu Gothic UI", 14.0, 1, True)
listFont = PdfTrueTypeFont("Yu Gothic UI", 12.0, 0, True)
# リストを描画するためのブラシを作成
brush = PdfBrushes.get_Black()
# 初期座標を指定
x = 50.0
y = 50.0
# タイトルを描画
title = "PDF 作成の基本手順"
page.Canvas.DrawString(title, titleFont, brush, x, y)
# 番号付きリストを作成
listItems = "PdfDocument オブジェクトを作成します。\n" \
+ "ドキュメントにページを追加します。\n" \
+ "テキストやリストなどのコンテンツを描画します。\n"\
+ "PDF ファイルとして保存します。"
list = PdfSortedList(listItems)
# リスト用のマーカーを作成
marker = PdfOrderedMarker(PdfNumberStyle.UpperRoman, listFont)
# リストをフォーマット
list.Font = listFont
list.Indent = 2
list.TextIndent = 4
list.Brush = brush
list.Marker = marker
# ページ上にリストを描画
list.Draw(page.Canvas, x, y + float(titleFont.MeasureString(title).Height + 5))
# ドキュメントを保存
pdf.SaveToFile("output/CreateNumberedList.pdf")
pdf.Close()
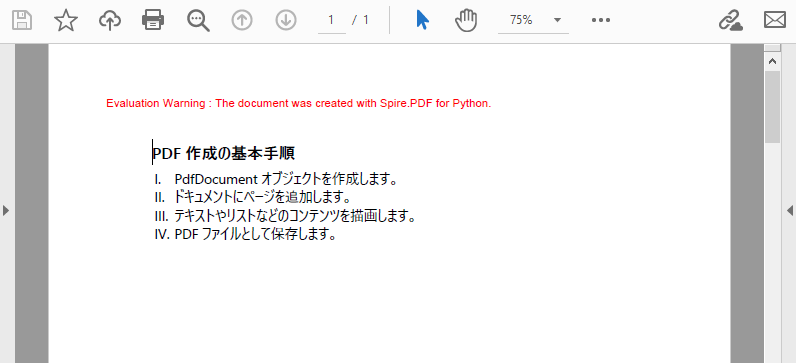
PdfSortedList はリスト項目を自動的に番号付けPdfOrderedMarker はさまざまな番号付け样式(アラビア数字、ローマ数字、アルファベット)をサポートDraw() メソッドは指定された座標にリストを配置Spire.PDF for Python では、リストの作成だけでなく、図形を描画して PDF ページに追加することもできます。詳しくは、「Python を使用して PDF 文書に図形を描画する方法」をご参照ください。
Spire.PDF for Python は PDF ドキュメントで順序なしリストを作成するための PdfList クラスを提供します。開発者はマーカー样式、フォント、インデント、ブラシを設定することでリストの外観をカスタマイズできます。順序なしリストは組み込みの記号マーカーとカスタム画像マーカーの両方をサポートし、さまざまなドキュメント样式とプレゼンテーション要件に適しています。
記号マーカーを使用した順序なしリストの作成には、PdfList.Marker.Style および PdfList.Marker.Font プロパティを通じてマーカー样式とマーカーフォントを設定することが含まれます。
実装手順
詳細な手順は以下の通りです:
PdfDocument クラスのオブジェクトを作成PdfDocument.Pages.Add() メソッドを使用してドキュメントにページを追加PdfPageBase.Canvas.DrawString() メソッドを使用してページ上にリストタイトルを描画PdfList クラスのインスタンスを初期化PdfList.Marker.Style および PdfList.Marker.Font プロパティを通じてマーカー样式とフォントを設定PdfList.Draw() メソッドを使用してページ上にリストを描画PdfDocument.SaveToFile() メソッドを使用してドキュメントを保存コード例
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument クラスのオブジェクトを作成
pdf = PdfDocument()
# 指定されたページサイズと余白でドキュメントにページを追加
page = pdf.Pages.Add()
# タイトルフォント、リストフォント、マーカーフォントを作成
titleFont = PdfTrueTypeFont("Yu Gothic UI", 14.0, 1, True)
listFont = PdfTrueTypeFont("Yu Gothic UI", 12.0, 0, True)
markerFont = PdfTrueTypeFont("Yu Gothic UI", 8.0, 0, True)
# リストを描画するためのブラシを作成
brush = PdfBrushes.get_Black()
# 初期座標を指定
x = 50.0
y = 50.0
# タイトルを描画
title = "製品の特徴"
page.Canvas.DrawString(title, titleFont, brush, x, y)
# 順序なしリストを作成
listContent = "高速な PDF 処理をサポートします。\n" \
+ "複数のドキュメント形式に対応しています。\n" \
+ "シンプルな API で PDF を柔軟に操作できます。"
list = PdfList(listContent)
# リストをフォーマット
list.Font = listFont
list.Indent = 2
list.TextIndent = 4
list.Brush = brush
# マーカーをフォーマット
list.Marker.Style = PdfUnorderedMarkerStyle.Asterisk
list.Marker.Font = markerFont
# ページ上にリストを描画
list.Draw(page.Canvas, x, float(y + titleFont.MeasureString(title).Height + 5))
# ドキュメントを保存
pdf.SaveToFile("output/CreateSymbolBulletedList.pdf")
pdf.Close()
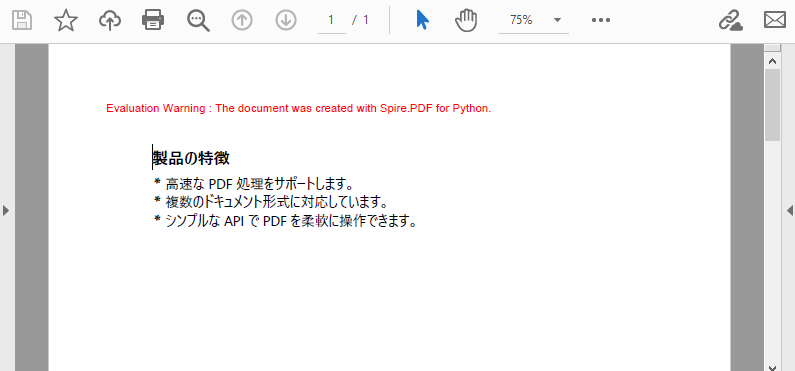
Spire.PDF for Python はさまざまな記号マーカー样式をサポートします:
Asterisk(*)Bullet(•)Circle(○)Diamond(◆)Square(■)ドキュメントのデザイン要件に基づいて適切な样式を選択してください。
記号マーカーに加えて、Spire.PDF for Python では開発者がカスタム画像をリストマーカーとして使用することも可能です。このアプローチは、ブランド化されたドキュメントや視覚的にカスタマイズされた PDF レイアウトを作成する場合に役立ちます。
実装手順
詳細な手順は以下の通りです:
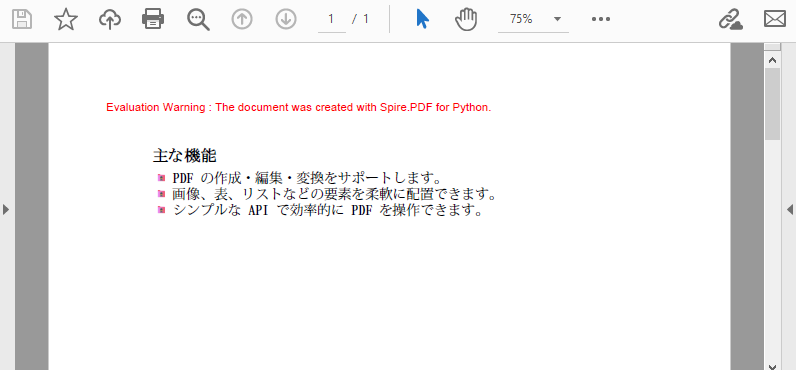
PdfDocument クラスのオブジェクトを作成PdfDocument.Pages.Add() メソッドを使用してドキュメントにページを追加PdfPageBase.Canvas.DrawString() メソッドを使用してページ上にリストタイトルを描画PdfList クラスのインスタンスを初期化PdfImage.FromFile() メソッドを使用して画像を読み込みPdfUnorderedMarkerStyle.CustomImage に設定し、読み込んだ画像をマーカーとして設定PdfList.Draw() メソッドを使用してページ上にリストを描画PdfDocument.SaveToFile() メソッドを使用してドキュメントを保存コード例
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument クラスのオブジェクトを作成
pdf = PdfDocument()
# 指定されたページサイズと余白でドキュメントにページを追加
page = pdf.Pages.Add()
# タイトルフォントとリストフォントを作成
titleFont = PdfCjkStandardFont(PdfCjkFontFamily.HeiseiMinchoW3, 14.0, PdfFontStyle.Bold)
listFont = PdfCjkStandardFont(PdfCjkFontFamily.HeiseiMinchoW3, 12.0, PdfFontStyle.Regular)
# リストを描画するためのブラシを作成
brush = PdfBrushes.get_Black()
# 初期座標を指定
x = 50.0
y = 50.0
# タイトルを描画
title = "主な機能"
page.Canvas.DrawString(title, titleFont, brush, x, y)
# 順序なしリストを作成
listContent = "PDF の作成・編集・変換をサポートします。\n" \
+ "画像、表、リストなどの要素を柔軟に配置できます。\n" \
+ "シンプルな API で効率的に PDF を操作できます。"
list = PdfList(listContent)
# リストをフォーマット
list.Font = listFont
list.Indent = 2
list.TextIndent = 4
list.Brush = brush
# 画像を読み込み
image = PdfImage.FromFile("Marker.png")
# マーカーをカスタム画像に設定
list.Marker.Style = PdfUnorderedMarkerStyle.CustomImage
list.Marker.Image = image
# ページ上にリストを描画
list.Draw(page.Canvas, x, float(y + titleFont.MeasureString(title).Height + 5))
# ドキュメントを保存
pdf.SaveToFile("output/CreateImageBulletedList.pdf")
pdf.Close()
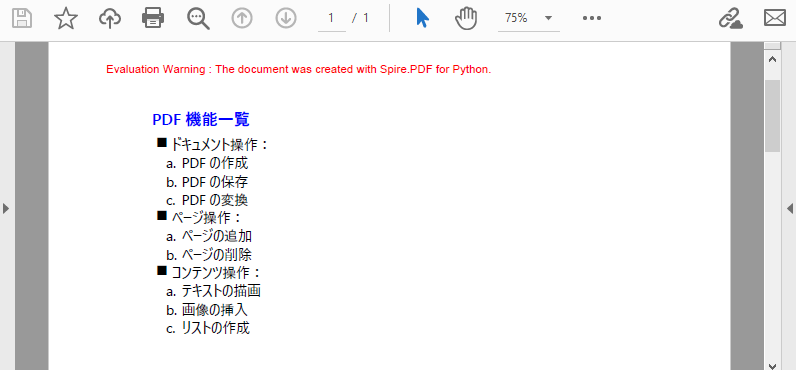
ネストされたリストを作成する場合、親リストと各レベルのサブリストの両方を順序なしリストまたは順序付きリストとして作成できます。各レベルのリストが作成されると、PdfListItem.SubList プロパティを使用してリストを親リストの対応する項目のサブリストとして設定できます。
ネストされたリストを作成する手順は以下の通りです:
PdfDocument クラスのオブジェクトを作成PdfDocument.Pages.Add() メソッドを使用してドキュメントにページを追加PdfPageBase.Canvas.DrawString() メソッドを使用してページ上にリストタイトルを描画PdfList.Items.get_Item() メソッドを使用して親リストの項目を取得PdfListItem.SubList プロパティを使用して指定されたリストをサブリストとして設定PdfList.Draw() メソッドを使用してページ上にリストを描画PdfDocument.SaveToFile() メソッドを使用してドキュメントを保存from spire.pdf import *
from spire.pdf.common import *
# PdfDocument クラスのオブジェクトを作成
pdf = PdfDocument()
# 指定されたページサイズと余白でドキュメントにページを追加
page = pdf.Pages.Add()
# タイトルフォントとリストフォントを作成
titleFont = PdfTrueTypeFont("Yu Gothic UI", 14.0, 1, True)
listFont = PdfTrueTypeFont("Yu Gothic UI", 12.0, 0, True)
markerFont = PdfTrueTypeFont("Yu Gothic UI", 12.0, 0, True)
# タイトルとリストを描画するためのブラシを作成
titleBrush = PdfBrushes.get_Blue()
firstListBrush = PdfBrushes.get_Purple()
secondListBrush = PdfBrushes.get_Black()
# 初期座標を指定
x = 50.0
y = 50.0
# タイトルを描画
title = "PDF 機能一覧"
page.Canvas.DrawString(title, titleFont, titleBrush, x, y)
# 親リストを作成
parentListContent = "ドキュメント操作:\n" + "ページ操作:\n" + "コンテンツ操作:"
parentList = PdfList(parentListContent)
# 親リストをフォーマット
indent = 4
textIndent = 4
parentList.Font = listFont
parentList.Indent = indent
parentList.TextIndent = textIndent
# 親リストマーカーを設定
parentList.Marker.Style = PdfUnorderedMarkerStyle.Square
parentList.Marker.Font = markerFont
# ネストされたサブリストを作成し、それらをフォーマット
subListMarker = PdfOrderedMarker(PdfNumberStyle.LowerLatin, markerFont)
subList1Content = "PDF の作成\n" + "PDF の保存\n" + "PDF の変換"
subList1 = PdfSortedList(subList1Content, subListMarker)
subList1.Font = listFont
subList1.Indent = indent * 2
subList1.TextIndent = textIndent
subList2Content = "ページの追加\n" + "ページの削除"
subList2 = PdfSortedList(subList2Content, subListMarker)
subList2.Font = listFont
subList2.Indent = indent * 2
subList2.TextIndent = textIndent
subList3Content = "テキストの描画\n" + "画像の挿入\n" + "リストの作成"
subList3 = PdfSortedList(subList3Content, subListMarker)
subList3.Font = listFont
subList3.Indent = indent * 2
subList3.TextIndent = textIndent
# 作成されたリストを親リストの各項目のネストされたサブリストとして設定
item1 = parentList.Items.get_Item(0)
item1.SubList = subList1
item2 = parentList.Items.get_Item(1)
item2.SubList = subList2
item3 = parentList.Items.get_Item(2)
item3.SubList = subList3
# リストを描画
parentList.Draw(page.Canvas, x, float(y + titleFont.MeasureString(title).Height + 5))
# ドキュメントを保存
pdf.SaveToFile("output/CreateNestedList.pdf")
pdf.Close()
リストは、コンテンツを明確かつ構造化された方法で整理するために PDF ドキュメントで広く使用されています。Spire.PDF for Python を使用することで、開発者はビジネス、教育、技術シナリオ向けにさまざまなタイプのリストベースの PDF コンテンツを自動的に生成できます。
一般的な使用事例には以下が含まれます:
順序付きリスト、順序なしリスト、ネストされたリストを組み合わせることで、開発者は読みやすさと視覚的構造が向上したプロフェッショナルな PDF ドキュメントを作成できます。
PDF ドキュメントでリストを作成することは、情報を明確かつプロフェッショナルに整理するために不可欠です。Spire.PDF for Python を使用することで、開発者は 順序付きリスト、記号または画像を使用した順序なしリスト、および ネストされたリスト を簡単に実装して、ドキュメントの読みやすさを向上させることができます。
順序付きリスト用の PdfSortedList と順序なしリスト用の PdfList という主要なクラスは、フォーマット、マーカー、レイアウトを包括的に制御します。これらを適切なインデントとマーカーのカスタマイズと組み合わせることで、ビジネス、教育、技術目的に適した洗練された PDF ドキュメントを生成できます。
このアプローチは、レポート生成の自動化、構造化されたドキュメントの作成、プログラム的にプロフェッショナル品質の PDF 出力を生成する場合に特に役立ちます。
Spire.PDF for Python のパフォーマンスを評価し、制限を解除したい場合は、30 日間の無料トライアルを申請 できます。
順序付きリスト は順序や優先度を示すために連続的なマーカー(数字、文字、ローマ数字)を使用しますが、順序なしリスト は順序を暗示せずに項目を提示するために記号(箇条書き、アスタリスク、円)またはカスタム画像を使用します。
はい。同じドキュメント内で順序付きリストと順序なしリストを組み合わせることができます。さらに、ネストされたリストを使用すると、異なる階層レベルでリストタイプを混合できます。例えば、順序付きサブリストを持つ順序なしの親リストなどです。
Indent プロパティを使用してページ余白からの全体的なリストインデントを制御し、TextIndent プロパティを使用してマーカーとリスト項目テキスト間の間隔を調整します。
はい。PdfList.Marker.Style を PdfUnorderedMarkerStyle.CustomImage に設定し、PdfImage オブジェクトを PdfList.Marker.Image に割り当てます。画像ファイルがアクセス可能でサポートされている形式であることを確認してください。
各ネストレベル用に別々のリストオブジェクトを作成し、PdfListItem.SubList プロパティを使用してサブリストを特定の親項目に接続します。視覚的な明確さのためにインデントを段階的に調整します(例:indent * 2、indent * 3)。
PdfOrderedMarker は以下の複数の番号付け样式をサポートします:
ドキュメントのコンテキストに最适合する样式を選択してください。

PDF ドキュメント内のテキストの検索と強調表示は、ドキュメントのレビュー、注釈付け、情報抽出に不可欠です。法務文書における重要な条項のマーキング、研究論文における主要な発見の強調、レポートにおける重要データの強調など、プログラム的にテキストを検索して視覚的な強調を適用することで、ドキュメントの可読性とワークフローの効率性を大幅に向上させることができます。
長大な PDF を手動で検索するのは時間がかかり、エラーが発生しやすい作業です。Python による自動化により、開発者は特定のテキストパターンを迅速に見つけ、ドキュメント全体または対象領域に視覚的な強調表示を適用できます。
本ガイドでは、Spire.PDF for Python を使用して PDF 内のテキストを検索・強調表示 する 3 つの強力なアプローチを紹介します。
目次
開始する前に、以下を用意してください。
Python 3.x がインストールされていること
Spire.PDF for Python がインストールされていること:
pip install Spire.PDF
または、Spire.PDF for Python パッケージをダウンロード して手動でインストールすることもできます。
テスト用のサンプル PDF ドキュメント
最も一般的な使用例は、PDF ドキュメント全体で特定のテキストのすべての発生箇所を検索し、強調表示を適用することです。この方法は、キーワード、技術用語、重要なフレーズをマークするのに最適です。
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# PDF ドキュメントのすべてのページをループ処理
for i in range(pdf.Pages.Count):
# 現在のページを取得
page = pdf.Pages.get_Item(i)
# 特定のテキストのすべての発生箇所を検索 (大文字小文字を区別しない)
finder = PdfTextFinder(page)
result = finder.Find("東京本社データセンター")
# 見つかったすべての箇所をシアン色で強調表示
for text in result:
text.HighLight(Color.get_Cyan())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlight.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
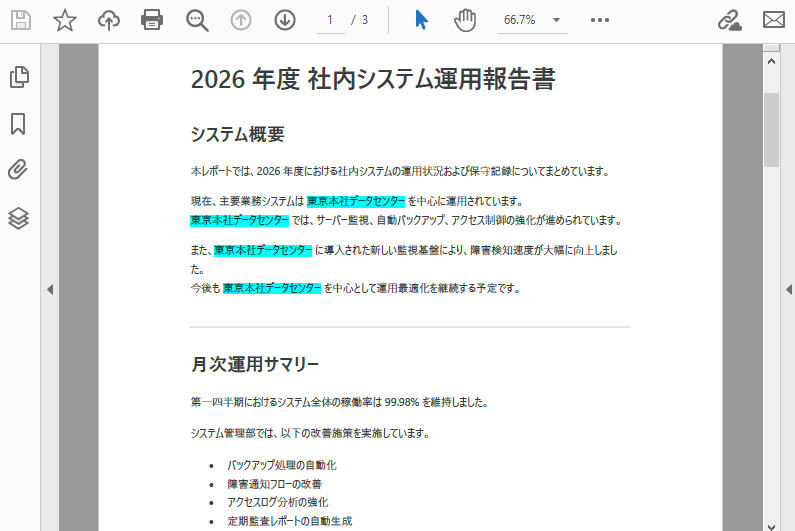
LoadFromFile(): ソース PDF ドキュメントを読み込むPages.Count: ページの総数を返すPdfTextFinder: テキスト検索を実行するためのクラスFind() メソッドで特定のテキストを検索Find() の戻り値: 見つかったテキストインスタンスのコレクションを返すHighLight(): テキストに背景の強調表示色を適用場合によっては、ヘッダー、フッター、サイドバー、特定のセクションなど、ページの特定の領域内でのみ検索が必要なことがあります。Spire.PDF for Python は、RectangleF パラメータを受け取ることで、領域ベースのテキスト検索をサポートしています。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 最初のページ (インデックス 0) を取得
pdfPageBase = pdf.Pages.get_Item(0)
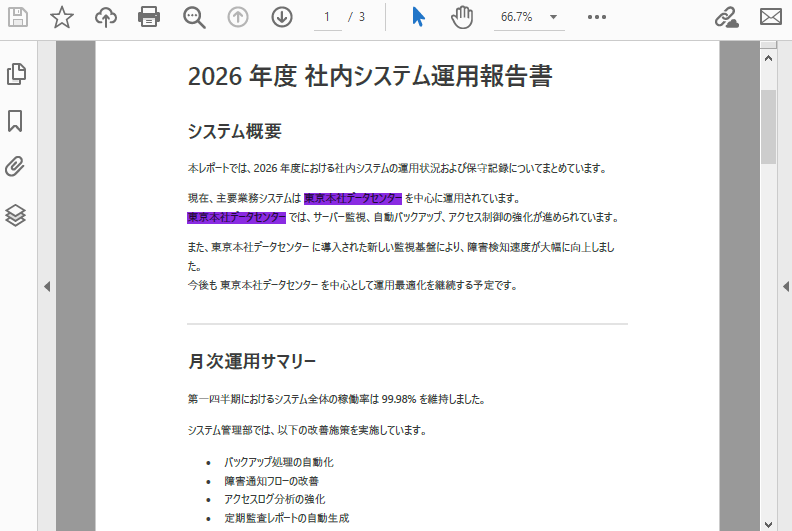
# 矩形領域を定義 (x, y, 幅, 高さ)
# この例では、ページの上部 (高さ 240 ポイント) を検索
rctg = RectangleF(0.0, 0.0, pdfPageBase.ActualSize.Width, 240.0)
# PdfTextFindOptions を作成し、矩形領域を検索領域として設定
options = PdfTextFindOptions()
options.Area = rctg
# 「検索」オプションを使用してテキストを検索
finder = PdfTextFinder(pdfPageBase)
finder.Options = options
findCollection = finder.Find("東京本社データセンター")
# 見つかったすべてのテキストを青色でハイライト
for find in findCollection:
find.HighLight(Color.get_BlueViolet())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlightArea.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
強調表示が必要なテキストが完全一致ではなくパターンに従っている場合、正規表現は強力な柔軟性を提供します。たとえば、すべてのメールアドレス、電話番号、日付、特定の単語の組み合わせを強調表示したい場合があります。
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
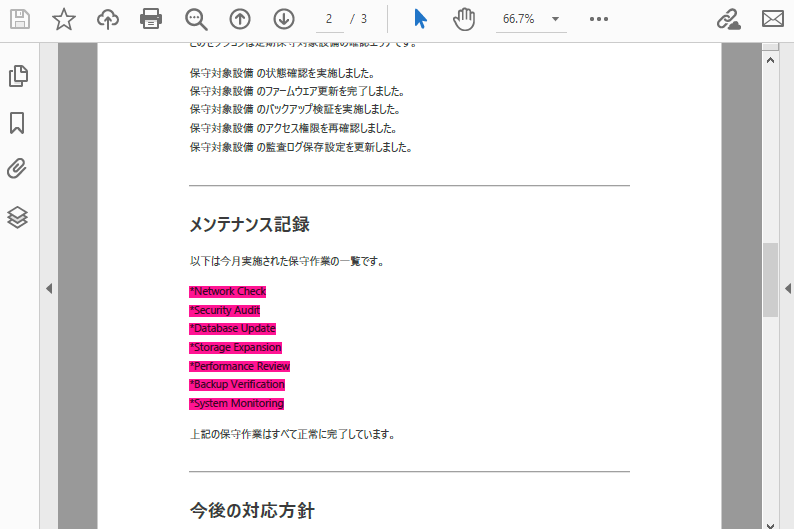
# 正規表現パターンを定義
# この例では、アスタリスク (*) の後に続く 2 つの単語にマッチ
regex = "\\*(\\w+\\s+\\w+)"
# 2 番目のページ (インデックス 1) を取得
page = pdf.Pages.get_Item(1)
# 正規表現にマッチするテキストを検索 PdfTextFindOptions オブジェクトを作成し、正規表現を使用して検索するように設定
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.Regex
# 検索オプションを適用し、正規表現を使用してテキストを検索
finder = PdfTextFinder(page)
finder.Options = options
result = finder.Find(regex)
# マッチしたすべてのテキストをディープピンク色で強調表示
for text in result:
text.HighLight(Color.get_DeepPink())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlightRegex.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
理論的には PDF でのテキスト検索と強調表示は簡単ですが、実際にはいくつかの課題が発生する可能性があります。
問題: PDF ビューアーにはテキストが表示されているが、Find() が結果を返さない。
原因:
解決策:
PdfTextFinder の検索オプションを確認問題: 数百ページの検索が遅い。
解決策:
# 例: 特定のページのみを検索
target_pages = [0, 5, 10, 15] # ページインデックス
for i in target_pages:
page = pdf.Pages.get_Item(i)
# 検索を実行...
問題: 特殊文字、アクセント付き文字、非 ASCII 記号を含むテキストの検索が失敗する。
解決策:
# 例: アクセント付き文字にマッチ
pattern = r"café|naïve|résumé"
問題: 大文字小文字のバリエーションを見逃す。
解決策:
PdfTextFinder のオプションで大文字小文字を区別しない設定を使用# 大文字小文字を区別しない検索の設定例
finder = PdfTextFinder(page)
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.IgnoreCase
finder.Options = options
result = finder.Find("keyword")
# 大文字小文字を区別しない正規表現
finder = PdfTextFinder(page)
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.Regex
finder.Options = options
result = finder.Find(r"(?i)pattern")
Spire.PDF を使用すれば、Python での PDF テキストの検索と強調表示は簡単です。完全一致、領域ベースのフィルタリング、正規表現パターンのいずれが必要でも、これらの方法でほとんどの使用例をカバーできます。
このプロセスを自動化することで、ドキュメントレビューを高速化し、データ抽出の効率性を向上させることができます。本番環境での使用では、スキャン済み PDF の処理とパフォーマンスの最適化を検討してください。
制限なしで Spire.PDF for Python を評価したい場合は、30 日間の無料トライアルを申請 できます。
Spire.PDF for Python の PdfTextFinder クラスを使用してテキストを検索し、HighLight() メソッドで色の強調表示を追加します。PdfDocument.LoadFromFile() で PDF を読み込み、PdfTextFinder でページを検索し、SaveToFile() で結果を保存します。
はい。PdfTextFindOptions の Parameter プロパティに TextFindParameter.Regex を設定し、PdfTextFinder.Find() メソッドに正規表現パターンを渡します。これにより、メール、日付、電話番号、その他の構造化データのパターンベースのマッチングが可能になります。
必要な座標と寸法で RectangleF オブジェクトを定義し、PdfTextFindOptions の Area プロパティに設定します。その後、このオプションを PdfTextFinder に適用して検索を実行します。これにより、指定した矩形領域に検索が制限されます。
はい。pdf.Pages.Count をループ処理し、各ページで PdfTextFinder を使用して検索を実行します。本ガイドの例では、複数ページの検索を示しています。
はい。パスワードを指定してパスワード保護された PDF を読み込みます。
pdf.LoadFromFile("protected.pdf", "your_password")
その後、通常の検索と強調表示操作を進めます。

PowerPoint プレゼンテーションは、研修資料、製品デモ、オンライン講座、ビジネスレポートなどで広く活用されています。しかし、生の PPT または PPTX ファイルを共有する際には、受信者が PowerPoint をインストールしていない場合がある、アニpngメーションが正しく再生されない、大量処理では手動エクスポートが非効率的になるなどの問題が発生する可能性があります。
MP4 や WMV などの動画形式に PowerPoint を変換することで、書式設定とアニメーションを保持した汎用性の高いコンテンツを作成し、これらの課題を解決できます。e-iceblue の Spire.Presentation を使用すれば、開発者は Microsoft PowerPoint のインストールなしで、プログラムによって PowerPoint から動画への変換を自動化できます。
本記事では、Spire.Presentation for .NET を使用して C# で PowerPoint プレゼンテーションを MP4 および WMV 動画に変換する方法を、フレームレート、スライド持続時間、トランジション保持などの設定オプションを含めて解説します。
目次
開発者は、より大規模なビジネスワークフローの一部として、PowerPoint プレゼンテーションを動画に変換する必要が生じることがあります。Microsoft PowerPoint で手動でファイルをエクスポートする場合と比較して、プログラムによる変換は柔軟性と拡張性に優れています。
一般的なユースケースには以下が含まれます:
プログラムによる変換は、再現可能なワークフロー、サーバーサイド処理、または既存のドキュメント自動化システムとの統合が必要な場合に特に有用です。
PowerPoint プレゼンテーションを動画に変換する前に、以下の 2 つのコンポーネントを準備する必要があります:
Spire はプレゼンテーションのレンダリングを担当し、FFmpeg は最終的な動画出力を生成します。両方が正常な変換に必要となります。
NuGet からライブラリをインストールします:
Install-Package Spire.Presentation
Spire.Presentation for .NET パッケージをダウンロードして手動でインストールすることも可能です。
このパッケージにより、C# アプリケーションで PowerPoint プレゼンテーションを開き、スライドにアクセスし、プログラムでエクスポートできるようになります。
Spire.Presentation は、レンダリングされたスライドフレームを組み合わせて再生可能な動画ファイルにするために FFmpeg に依存しています。FFmpeg がインストールされていないか、パスが正しく設定されていない場合、エクスポートプロセスは失敗します。
以下の手順で FFmpeg をインストールします:
FFmpeg essentials ビルドをダウンロード
パッケージをローカルマシンに展開
bin フォルダのパスを確認
例:
D:\tools\ffmpeg\bin
このパスは後で SaveToVideoOption を設定する際に使用します。
以下のコマンドを使用して FFmpeg をインストールします:
sudo yum install epel-release
sudo yum localinstall --nogpgcheck https://download1.rpmfusion.org/free/el/rpmfusion-free-release-7.noarch.rpm
sudo yum install ffmpeg ffmpeg-devel
インストール後、以下のコマンドを実行して FFmpeg のパスを確認できます:
which ffmpeg
注意:古いバージョンの FFmpeg では、特定のスライドトランジション効果を完全にサポートできない場合があります。
環境設定が完了したら、数行のコードで PowerPoint プレゼンテーションを MP4 に変換できます。
基本的なワークフローは以下の通りです:
次の例では、PPTX ファイルを MP4 動画に変換します:
using Spire.Presentation;
namespace PowerPointToVideo
{
class Program
{
static void Main(string[] args)
{
// 入力ファイルと出力ファイルのパスを設定
string inputFile = "ProductDemo.pptx";
string outputFile = "ProductDemo.mp4";
// Presentation オブジェクトを作成してファイルを読み込む
Presentation presentation = new Presentation();
presentation.LoadFromFile(inputFile);
// FFmpeg のパスを指定して動画エクスポートオプションを設定
presentation.SaveToVideoOption = new SaveToVideoOption(
@"D:\tools\ffmpeg\bin"
);
// フレームレートを 30 FPS に設定
presentation.SaveToVideoOption.Fps = 30;
// 各スライドの表示時間を 2 秒に設定
presentation.SaveToVideoOption.DurationForEachSlide = 2;
// MP4 形式で動画を保存
presentation.SaveToFile(outputFile, FileFormat.MP4);
// リソースを解放
presentation.Dispose();
}
}
}
コード実行後の処理:
以下は、サンプルの PowerPoint プレゼンテーションと変換後の動画出力です。
入力:PowerPoint プレゼンテーション
出力:変換された MP4 動画

上記のプレビューをクリックすると、トランジションとアニメーションを保持しながら PowerPoint スライドが MP4 動画に変換される様子が確認できます。
この例では、いくつかの主要な API メソッドを使用しています:
この基本的なワークフローは、ほとんどの標準的な PowerPoint から動画への変換タスクに対応できます。他の形式やカスタマイズオプションが必要な場合は、以下の高度なシナリオを参照してください。
静的な共有形式が必要な場合は、C# で PowerPoint プレゼンテーションを画像(JPG/PNG)に変換して、配布と Web 表示を容易にすることも可能です。
基本的な例はほとんどのシナリオに対応しますが、一部のアプリケーションでは異なる出力形式、カスタム再生設定、または一括変換ワークフローが必要になる場合があります。
MP4 が最も広く使用されている動画形式ですが、一部のレガシーエンタープライズシステムや Windows ベースの環境では WMV 出力が必要となる場合があります。
PowerPoint ファイルを WMV としてエクスポートするには、出力ファイルの拡張子を変更するだけです:
using Spire.Presentation;
// Presentation オブジェクトを作成してファイルを読み込む
Presentation presentation = new Presentation();
presentation.LoadFromFile("TrainingSlides.pptx");
// FFmpeg のパスを指定して動画エクスポートオプションを設定
presentation.SaveToVideoOption = new SaveToVideoOption(
@"D:\tools\ffmpeg\bin"
);
// WMV 形式で動画を保存
presentation.SaveToFile("TrainingVideo.wmv", FileFormat.WMV);
// リソースを解放
presentation.Dispose();
プレゼンテーションに複雑なアニメーションが含まれている場合や、特定の再生タイミングが必要な場合は、フレームレートとスライド持続時間の設定を調整できます。
using Spire.Presentation;
// Presentation オブジェクトを作成してファイルを読み込む
Presentation presentation = new Presentation();
presentation.LoadFromFile("MarketingPitch.pptx");
// FFmpeg のパスを指定して動画エクスポートオプションを設定
presentation.SaveToVideoOption = new SaveToVideoOption(
@"D:\tools\ffmpeg\bin"
);
// より滑らかな再生のために FPS を高く設定
presentation.SaveToVideoOption.Fps = 60;
// 各スライドの表示時間を長く設定
presentation.SaveToVideoOption.DurationForEachSlide = 10;
// HD 品質の MP4 動画として保存
presentation.SaveToFile("MarketingPitch_HD.mp4", FileFormat.MP4);
// リソースを解放
presentation.Dispose();
動画設定リファレンス
| 設定項目 | デフォルト | 最大値 | 目的 |
|---|---|---|---|
| Fps | 30 | 60 | 再生の滑らかさを制御 |
| DurationForEachSlide | 5 秒 | 5 分 | スライド表示時間を制御 |
高い値を設定すると、処理時間と一時ストレージの使用量が増加する可能性があります。
一括変換は、複数のプレゼンテーションを自動的に処理する必要がある LMS プラットフォーム、エンタープライズレポートシステム、ドキュメント自動化ワークフローで有用です。
using Spire.Presentation;
using System.IO;
// FFmpeg のパスを設定
string ffmpegPath = @"D:\tools\ffmpeg\bin";
// 入力フォルダと出力フォルダのパスを設定
string inputFolder = @"C:\Presentations\";
string outputFolder = @"C:\Videos\";
// 入力フォルダ内のすべての PPTX ファイルを取得
string[] pptxFiles = Directory.GetFiles(inputFolder, "*.pptx");
// 各ファイルを順番に処理
foreach (string inputFile in pptxFiles)
{
// ファイル名から拡張子を除いた部分を取得
string fileName = Path.GetFileNameWithoutExtension(inputFile);
// 出力ファイルのパスを構築
string outputFile = Path.Combine(outputFolder, fileName + ".mp4");
// Presentation オブジェクトを作成してファイルを読み込む
Presentation presentation = new Presentation();
presentation.LoadFromFile(inputFile);
// 動画エクスポートオプションを設定
presentation.SaveToVideoOption = new SaveToVideoOption(ffmpegPath);
presentation.SaveToVideoOption.Fps = 30;
presentation.SaveToVideoOption.DurationForEachSlide = 3;
// MP4 形式で動画を保存
presentation.SaveToFile(outputFile, FileFormat.MP4);
// リソースを解放
presentation.Dispose();
}
このアプローチにより、Microsoft PowerPoint で手動エクスポートすることなく、大規模な PowerPoint から動画への変換ワークフローを自動化できます。
変換前に C# で PowerPoint プレゼンテーションを編集して、結果として生成される動画のレイアウトとアニメーション効果を改善することも可能です。
PowerPoint から動画への変換过程中、Spire.Presentation は主要な視覚効果を保持して、出力動画が元のプレゼンテーション体験にできるだけ近くなるようにします。
PowerPoint のスライドトランジションは、動画生成中にレンダリングされて、スライド間のスムーズな視覚フローを維持します。
以下のトランジションがサポートされています:
これらのトランジションはフレームレンダリング中に適用され、最終的な動画で自然なスライド進行をシミュレートします。
アニメーションは動画生成中に処理およびレンダリングされ、PowerPoint の再生動作をシミュレートします。
開始アニメーション:
終了アニメーション:
アニメーションシーケンスは単一の再生ユニットとして処理され、最終的な動画で一貫したレンダリングを保証します。
PowerPoint スライド内の埋め込みメディアはエクスポートされた動画に含まれ、マルチメディアコンテンツを含むプレゼンテーションに適しています。
スライドタイミングとアニメーションの持続時間は、変換中に自動的に解釈され、最終的な動画出力で正確な再生を保証します。
変換プロセスは Windows と Linux の両方の環境で実行可能であり、サーバーサイド自動化とエンタープライズワークフローに適しています。
PowerPoint プレゼンテーションを動画に変換する際、出力品質やランタイム実行に影響を与える可能性のあるいくつかの一般的な問題があります。これらの問題を把握しておくことで、本番環境でのよりスムーズな変換プロセスが保証されます。
動画エクスポートプロセスは、最終的な MP4 または WMV ファイルをエンコードするために FFmpeg に依存しています。
FFmpeg のパスが正しく構成され、FFmpeg 実行ファイルを含む bin ディレクトリを指していることを確認してください。
Windows の場合、通常は以下のようになります:
D:\tools\ffmpeg\bin
FFmpeg のパスが正しくないかアクセスできない場合、動画エクスポートプロセスはランタイムで失敗します。
PowerPoint から動画への変換には、スライドを中間フレームにレンダリングしてから最終的な動画ファイルにエンコードするプロセスが含まれます。
その結果、以下の要因に応じてディスク使用量が大幅に増加する可能性があります:
高品質または長時間のプレゼンテーションの場合、一時ディスク使用量が相当になる可能性があります。大量の一括変換を処理する前に、十分な空きディスク容量を確保することをお勧めします。
一般的な PowerPoint トランジションのほとんどは変換中にサポートされます。ただし、一部の複雑または高度なトランジション効果は、Microsoft PowerPoint とまったく同じようにレンダリングされない場合があります。
そのような場合、最終的な動画はスライドフローを保持しますが、視覚効果は元のプレゼンテーションと比較して簡略化されて表示される可能性があります。
本番ワークフローで使用する前に、高度なトランジションを含むプレゼンテーションをテストすることをお勧めします。
PowerPoint プレゼンテーションはシステムにインストールされたフォントに依存しています。変換が実行される環境で必要なフォントが欠落している場合、最終的な動画のレイアウトまたはテキストの外観が変更される可能性があります。
一貫したレンダリングを保証するために:
これは多言語プレゼンテーションやサーバーサイド変換シナリオで特に重要です。
本記事では、Spire.Presentation を使用して C# で PowerPoint プレゼンテーションを MP4 および WMV 動画に変換する方法を解説しました。Spire API を活用することで、開発者はカスタマイズ可能なフレームレート、スライド持続時間、トランジション保持を備えた動画生成を自動化できます。
動画変換に加え、Spire.Presentation はスライド編集、メディア抽出、プレゼンテーション生成などのタスクにも使用でき、より広範なドキュメント自動化ワークフローに有用です。
制限なしで全機能を評価したい場合は、一時ライセンスを申請できます。
はい。Spire.Presentation は独立して変換を実行し、Microsoft PowerPoint のインストールを必要としません。
はい、多くの一般的なスライドトランジションと開始/終了アニメーションは変換中に保持されます。
現在、動画エクスポートには MP4 と WMV 形式がサポートされています。
はい。Spire.Presentation はサーバー環境をサポートし、自動化されたドキュメント処理ワークフローで広く使用されています。
動画生成では一時画像フレームが作成されます。60 FPS で 5 分の持続時間を持つ 5 スライドのプレゼンテーションの場合、約 25GB の一時ストレージが必要になる可能性があります。

PDF OCR(光学文字認識)の実行は、スキャン済み文書を扱う際の一般的な要件です。標準的なデジタル PDF には検索可能なテキストレイヤーが含まれていますが、スキャン済み PDF は本質的に印刷文書の画像であるため、従来のテキスト抽出方法では効果的ではありません。
コンテンツにアクセス可能で編集可能にするために、開発者はまず PDF ファイルを画像に変換 し、その後 OCR 技術を使用してテキストを認識・抽出する必要があります。このプロセスを手動で実行するのは時間がかかり非効率的であり、特に複数の文書を扱う場合に問題となります。
このガイドでは、Spire.PDF for Python と Spire.OCR for Python を使用して、スキャン済み PDF からのテキスト抽出を自動化する完全な Python PDF OCR パイプライン の構築に焦点を当てています。このアプローチは、実世界の文書処理ワークフローに対応するスケーラブルなソリューションを提供します。
クイックナビゲーション
PDF ファイルからテキストを抽出する場合、アプローチを決定する重要な要素の一つが PDF の種類です。一般的に、PDF は 2 つのカテゴリーに分類されます:スキャン済み(画像ベース)PDF と検索可能 PDF です。それぞれに異なるテキスト抽出戦略が必要です。
スキャン済み PDF は通常、書籍、請求書、契約書、雑誌などの物理文書をデジタル化して作成されます。テキストは人間の目には読み取れるように見えますが、実際には画像として埋め込まれているため、従来のテキスト抽出ツールではアクセスできません。古いデジタルファイルやパスワード保護された PDF にも、実際のテキストレイヤーがない場合があります。
一方、検索可能 PDF には、コンピューターがコンテンツを検索、コピー、または解析できる隠しテキストレイヤーが含まれています。これらのファイルは通常、Microsoft Word や PDF エディターなどのアプリケーションから直接生成され、プログラムによる処理がはるかに容易です。
この違いは、スキャン済み PDF を扱う際の OCR(光学文字認識)の重要性を浮き彫りにしています。Python PDF OCR のようなツールを使用することで、これらの画像ベースの PDF を画像に変換し、OCR を実行してテキストを認識し、さらに使用するために抽出することがすべて自動化された方法で可能になります。
開始する前に、以下が準備されていることを確認してください:
Python 3.x がインストールされていること
Spire.PDF for Python がインストールされていること:
pip install spire.pdf
Spire.OCR for Python がインストールされていること:
pip install spire.ocr
公式の Spire.PDF および Spire.OCR ページにアクセスして手動でダウンロードおよびインストールすることもできます。
Spire.OCR 言語モデルファイルがダウンロードされていること(英語、中国語、フランス語、ドイツ語、その他の言語で利用可能)
このガイドでは、両方のライブラリを使用して完全な PDF OCR パイプラインを作成するワークフローを示します。
Python PDF OCR に取り組む前に、基本的なステップを理解することが重要です:OCR 技術は PDF ファイルを直接処理しません。特に画像ベースの PDF(スキャン済み文書から作成されたものなど)の場合、まず個々の画像ファイルに変換する必要があります。
Spire.PDF ライブラリを使用して PDF を画像に変換するのは簡単です。対象の PDF 文書を読み込み、各ページを反復処理するだけです。各ページに対して、PdfDocument.SaveAsImage() メソッドを呼び出して個別の画像ファイルとして保存します。このステップが完了すると、画像は後続の OCR プロセスの準備が整います。
以下は、PDF ページを PNG 画像に変換する方法の例です:
from spire.pdf import *
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# ページをループ処理して画像として保存
for i in range(pdf.Pages.Count):
# 各ページを画像に変換
with pdf.SaveAsImage(i) as image:
# 必要に応じて異なる形式で保存
image.Save(f"output/pdftoimage/ToImage_{i}.png")
# image.Save(f"output/ToImage_{i}.jpg")
# image.Save(f"output/ToImage_{i}.bmp")
# PDF 文書を閉じる
pdf.Close()
以下は変換結果のプレビューです:
i)を画像オブジェクトに変換この段階で、PDF は個別の画像ファイルに変換されています。これらの画像は現在、OCR 技術を使用してテキストコンテンツを抽出するために処理できます。
PDF 変換オプションの詳細については、次を参照してください:Python で PDF を画像形式に変換
スキャン済み PDF を画像に変換した後、Python で PDF OCR を実行して PDF からテキストを抽出する作業に進むことができます。Spire.OCR の OcrScanner.Scan() を使用すると、画像内のテキスト認識が簡単になります。英語、中国語、フランス語、ドイツ語など、複数の言語をサポートしています。テキストが抽出されると、.txt ファイルに簡単に保存したり、Word 文書を生成したりできます。
以下のコード例は、最初の PDF ページを OCR して Python でテキストにエクスポートする方法を示しています:
from spire.ocr import *
# OCR スキャナーインスタンスを作成
scanner = OcrScanner()
# OCR モデルパスと言語を設定
configureOptions = ConfigureOptions()
configureOptions.ModelPath = r'E:/win-x64/'
configureOptions.Language = 'Japanese'
scanner.ConfigureDependencies(configureOptions)
# 画像に対して OCR を実行
scanner.Scan(r'output/pdftoimage/ToImage_0.png')
# 抽出されたテキストをファイルに保存
text = scanner.Text.ToString()
with open('output/scannedpdfoutput.txt', 'a', encoding='utf-8') as file:
file.write(text + '\n')
以下は OCR 結果のプレビューです:
.txt ファイルに保存このセクションでは、単一の画像からテキストを抽出するためのコア OCR ワークフローを示しています。次のセクションでは、このアプローチを拡張して すべてのページを自動的に 処理する方法を説明します。
以下は、PDF OCR からテキスト抽出までの完全なワークフローを示す実行可能な例です:
from spire.pdf import *
from spire.ocr import *
import os
# ---------------------------
# 設定
# ---------------------------
pdf_path = "AI生成アート.pdf"
output_image_dir = "output/pdftoimage"
output_text_file = "output/scannedpdfoutput.txt"
ocr_model_path = r"E:/win-x64/"
ocr_language = "Japanese"
# 出力ディレクトリが存在しない場合は作成
os.makedirs(output_image_dir, exist_ok=True)
os.makedirs(os.path.dirname(output_text_file), exist_ok=True)
# ---------------------------
# ステップ 1: PDF を画像に変換
# ---------------------------
pdf = PdfDocument()
pdf.LoadFromFile(pdf_path)
image_paths = []
for i in range(pdf.Pages.Count):
# 各ページを画像に変換
with pdf.SaveAsImage(i) as image:
image_path = f"{output_image_dir}/ToImage_{i}.png"
image.Save(image_path)
image_paths.append(image_path)
print(f"ページ {i} を {image_path} に変換しました")
pdf.Close()
print(f"変換された総ページ数: {len(image_paths)}")
# ---------------------------
# ステップ 2: すべての画像に対して OCR を実行
# ---------------------------
# OCR スキャナーインスタンスを作成
scanner = OcrScanner()
# OCR モデルパスと言語を設定
configureOptions = ConfigureOptions()
configureOptions.ModelPath = ocr_model_path
configureOptions.Language = ocr_language
scanner.ConfigureDependencies(configureOptions)
# 以前の出力ファイルをクリア
if os.path.exists(output_text_file):
os.remove(output_text_file)
# 各画像を処理
for i, image_path in enumerate(image_paths):
print(f"ページ {i} を処理中: {image_path}")
# 画像に対して OCR を実行
scanner.Scan(image_path)
# テキストを抽出して保存
text = scanner.Text.ToString()
with open(output_text_file, 'a', encoding='utf-8') as file:
file.write(f"--- ページ {i} ---\n")
file.write(text + '\n\n')
print(f"ページ {i} の OCR が完了しました")
print(f"\nOCR が完了しました。テキストは次の場所に保存されました: {output_text_file}")
この完全な例は、PDF OCR パイプライン全体を示しています:
このコードを直接実行して、スキャン済み PDF を編集可能なテキストファイルに変換できます。出力には、より良い整理のためにページ区切りが含まれています。
PDF OCR を実行するプロセスは単純に見えるかもしれませんが、いくつかの実用的な課題が発生する可能性があります。
低解像度のスキャンやぼやけた画像は、OCR の精度を低下させる可能性があります。
解決策:
マルチカラムレイアウト、表、または混合コンテンツを含む PDF は、OCR エンジンを混乱させる可能性があります。
解決策:
特殊なフォント、手書きのテキスト、装飾的なテキストは、正確に認識されない場合があります。
解決策:
間違った言語モデルを使用すると、認識精度が大幅に低下します。
解決策:
数百ページの処理には時間がかかる可能性があります。
解決策:
数学記号、図、または非標準の文字は正しく抽出されない可能性があります。
解決策:
これらの問題を予測することで、より信頼性の高い PDF OCR ワークフロー を構築し、全体的な抽出品質を向上させることができます。
Python で PDF OCR を実行することは、ワンステップの操作ではなく、PDF を画像に変換し、その後 OCR 技術を使用してテキストコンテンツを認識・抽出する構造化されたプロセスです。
2 段階のパイプライン(PDF から画像への変換、その後に OCR テキスト抽出)に焦点を当て、Spire.PDF と Spire.OCR を備えた Python を使用することで、完全な PDF OCR ソリューション を効率的に実装でき、文書処理タスクの自動化が容易になります。
このアプローチは、編集可能で検索可能なテキストに変換する必要があるスキャン済みの請求書、契約書、レポート、その他の画像ベースの PDF を処理する場合に特に有用です。
Spire.PDF for Python と Spire.OCR for Python のパフォーマンスを評価し、制限を解除したい場合は、30 日間の無料トライアルを申請できます。
PDF OCR(光学文字認識)は、スキャン済みまたは画像ベースの PDF を検索可能で編集可能なテキストに変換するプロセスです。スキャン済み PDF には実際のテキストではなく画像が含まれているため、画像内の文字を認識して機械可読のテキストに変換するには OCR 技術が必要です。
いいえ。Python は PDF ファイルに対してワンステップで直接 OCR を実行できません。典型的なワークフローには以下が含まれます:
Spire.OCR は、英語、中国語(簡体字および繁体字)、フランス語、ドイツ語、日本語、韓国語など、複数の言語をサポートしています。適切な言語モデルファイルをダウンロードし、Language パラメーターを適切に設定する必要があります。
OCR の精度はいくつかの要因に依存します:
高品質のスキャンと明確なフォントは通常 95% 以上の精度を達成します。画質が悪い画像や特殊なフォントは手動修正が必要になる場合があります。
はい。複数の PDF ファイルをループ処理し、同じ OCR パイプラインをそれぞれに適用できます。大規模な処理の場合は、パフォーマンスを向上させるために並列処理の実装を検討してください。
この違いを理解することは、PDF 処理ワークフローに OCR が必要かどうかを判断するのに役立ちます。

PDF ファイルは至る所にあります。契約書や研究論文から電子書籍や請求書まで。フォーマットを完璧に保持できますが、PDF からのテキスト抽出は、特に大規模または複雑なドキュメントの場合、課題となる可能性があります。手動でのコピーは遅いだけでなく、正確性に欠けることも多いです。
ワークフローを自動化する開発者、コンテンツを処理するデータアナリスト、あるいは単に迅速なテキスト抽出が必要な方にとって、プログラムによる方法は貴重な時間と労力を節約できます。
この包括的なガイドでは、Spire.PDF for Python を使用して Python で PDF ファイルからテキストを抽出する方法を学びます。これは強力で使いやすい PDF 処理ライブラリです。すべてのテキストの抽出、特定のページや領域のターゲット指定、非表示テキストの無視、テキストの位置やサイズなどのレイアウト情報の取得について解説します。
クイックナビゲーション
PDF からのテキスト抽出は、多くのユースケースで不可欠です:
プログラムによるテキスト抽出は、手動の方法では実現できない精度、速度、スケーラビリティを提供します。
Spire.PDF for Python は、すべての PDF 操作ニーズを簡素化する包括的で使いやすい PDF 処理ライブラリです。単純な PDF ドキュメントと複雑な PDF ドキュメントの両方でシームレスに動作する高度なテキスト抽出機能を提供します。
ライブラリは pip を介して簡単にインストールできます。ターミナルを開き、次のコマンドを実行してください:
pip install spire.pdf
また、Spire.PDF for Python パッケージをダウンロードして、プロジェクトに手動で追加することもできます。
PDF からすべてのテキストをすばやく読み取りたい場合、この簡単な例がその方法を示しています。各ページを反復処理し、PdfTextExtractor を使用して完全なテキストを抽出し、スペースと改行を保持した状態でテキストファイルに保存します。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDF ドキュメントを読み込む
doc.LoadFromFile('/Sample.pdf')
# 抽出したテキストを保持する変数を準備
all_text = ""
# PdfTextExtractOptions オブジェクトを作成
extractOptions = PdfTextExtractOptions()
# 空白を含むすべてのテキストを抽出
extractOptions.IsExtractAllText = True
# すべてのページをループしてテキストを抽出
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
# 各ページのテキストを追加
all_text += text + "\n"
# 抽出したすべてのテキストをファイルに書き込む
with open('output/全ページのテキスト.txt', 'w', encoding='utf-8') as file:
file.write(all_text)
True に設定すると、空白とフォーマットを保持この基本的なアプローチは、レイアウトや位置を気にせずに完全なテキストコンテンツが必要な単純なドキュメントに最適です。
何をどのように抽出するかをより細かく制御するために、Spire.PDF for Python は高度なオプションを提供します。特定のページや領域からコンテンツを選択的に抽出したり、テキストの位置やサイズなどのレイアウト詳細情報を取得したりすることで、特定のデータ処理ニーズに適切に対応できます。
PDF 全体を処理する代わりに、テキスト抽出のために特定のページをターゲットにすることができます。これは、タスクに関連するセクションのみが必要な大規模なドキュメントで特に役立ちます。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDF ドキュメントを読み込む
doc.LoadFromFile('/Sample.pdf')
# PdfTextExtractOptions オブジェクトを作成し、完全なテキスト抽出を有効化
extractOptions = PdfTextExtractOptions()
# 空白を含むすべてのテキストを抽出
extractOptions.IsExtractAllText = True
# 特定のページを取得 (例: 2 ページ目)
page = doc.Pages.get_Item(1)
# PdfTextExtractor オブジェクトを作成
textExtractor = PdfTextExtractor(page)
# ページからテキストを抽出
text = textExtractor.ExtractText(extractOptions)
# UTF-8 エンコーディングを使用して抽出したテキストをファイルに書き込む
with open('output/ページのテキスト.txt', 'w', encoding='utf-8') as file:
file.write(text)
以下は抽出結果のプレビューです:
フォームや請求書などの構造化ドキュメントを扱う場合、特定の領域からテキストを抽出する方が効率的です。矩形領域を定義し、ページ上のその境界内にあるテキストのみを抽出できます。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDF ドキュメントを読み込む
doc.LoadFromFile('/利用規約.pdf')
# 特定のページを取得 (例: 2 ページ目)
page = doc.Pages.get_Item(1)
# PdfTextExtractor オブジェクトを作成
textExtractor = PdfTextExtractor(page)
# PdfTextExtractOptions オブジェクトを作成
extractOptions = PdfTextExtractOptions()
# テキストを抽出する矩形領域を定義
# RectangleF(左, 上, 幅, 高さ)
extractOptions.ExtractArea = RectangleF(0.0, 100.0, 890.0, 80.0)
# 指定された領域から空白を保持してテキストを抽出
text = textExtractor.ExtractText(extractOptions)
# UTF-8 エンコーディングを使用して抽出したテキストをファイルに書き込む
with open('output/矩形領域のテキスト.txt', 'w', encoding='utf-8') as file:
file.write(text)
以下は抽出結果のプレビューです:
RectangleF パラメーターは抽出領域を定義します:
座標はポイント単位で測定されます (1 ポイント = 1/72 インチ)。原点 (0, 0) はページの左上隅にあります。
一部の PDF には、アクセシビリティや OCR レイヤーによく使用される非表示または不可視のテキストが含まれています。ユーザーに実際に見えるコンテンツのみに焦点を当てるために、抽出中にこのようなコンテンツを無視することを選択できます。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDF ドキュメントを読み込む
doc.LoadFromFile('/利用規約.pdf')
# PdfTextExtractOptions オブジェクトを作成
extractOptions = PdfTextExtractOptions()
# 抽出中に非表示テキストを無視
extractOptions.IsShowHiddenText = False
# 特定のページを取得 (例: 2 ページ目)
page = doc.Pages.get_Item(1)
# PdfTextExtractor オブジェクトを作成
textExtractor = PdfTextExtractor(page)
# ページからテキストを抽出
text = textExtractor.ExtractText(extractOptions)
# UTF-8 エンコーディングを使用して抽出したテキストをファイルに書き込む
with open('output/非表示テキストを除く.txt', 'w', encoding='utf-8') as file:
file.write(text)
この機能は、OCR ソフトウェアで処理されたスキャン済みドキュメントを扱う場合に特に重要です。
レイアウトに敏感なアプリケーション (PDF コンテンツを編集可能な形式に変換したり、ページ構造を再構築したりするなど) では、テキストをその位置とサイズとともに抽出できます。これにより、コンテンツの解釈と使用方法を精密に制御できます。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDF ドキュメントを読み込む
doc.LoadFromFile('/利用規約.pdf')
# ドキュメントのすべてのページをループ
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
# 現在のページ用に PdfTextFinder オブジェクトを作成
finder = PdfTextFinder(page)
# ページ上のすべてのテキストフラグメントを検索
fragments = finder.FindAllText()
print(f"{i + 1} ページ:")
# すべてのテキストフラグメントをループ
for fragment in fragments:
# 現在のテキストフラグメントからテキストコンテンツを抽出
text = fragment.Text
# 位置とサイズ情報を含むバウンディング矩形を取得
rects = fragment.Bounds
print(f'テキスト: "{text}"')
# すべての矩形を反復処理
for rect in rects:
# 現在の矩形の位置とサイズ情報を出力
print(f"位置: ({rect.X}, {rect.Y}), サイズ: ({rect.Width} x {rect.Height})")
print()
このレベルの詳細により、単純なテキスト抽出を超えた高度なドキュメント処理ワークフローが可能になります。
Spire.PDF for Python を使用すると、Python での PDF ファイルからのテキスト抽出が効率的かつ柔軟になります。ドキュメント全体を処理する必要がある場合でも、特定のページや領域からテキストを抽出する必要がある場合でも、Spire.PDF はニーズを満たす堅牢なツールセットを提供します。
テキスト抽出を自動化することで、以下のことが可能になります:
基本的な抽出、選択的ページ処理、領域ベースの抽出、非表示テキストのフィルタリング、位置認識抽出の組み合わせにより、PDF コンテンツ処理を完全に制御できます。
Spire.PDF for Python のパフォーマンスを評価し、制限を解除したい場合は、30 日間の無料トライアルを申請できます。
はい、Spire.PDF for Python は、PDF ドキュメントを読み込む際に正しいパスワードを提供することで、保護されたファイルを開いてテキストを抽出できます。LoadFromFile メソッドにパラメーターとしてパスワードを渡すだけです。
はい、Spire.PDF for Python を使用して、PDF ファイルのディレクトリをプログラムで反復処理し、各ファイルに効率的にテキスト抽出を適用できます。これは大規模なドキュメントコレクションの処理に理想的です。
このガイドはテキスト抽出に焦点を当てていますが、Spire.PDF for Python は画像抽出と表抽出もサポートしています。表抽出については、表の抽出に関する詳細については、Python を使って PDF の表を簡単に抽出する方法に関するガイドをご覧ください。
スキャン済み PDF からのテキスト抽出には OCR (光学文字認識) が必要です。Spire.PDF for Python には組み込みの OCR は含まれていませんが、Spire.OCR for Python などの OCR ライブラリと組み合わせて画像からテキストへの変換を行うことができます。
Spire.PDF for Python は、ネイティブ PDF ファイル (スキャンではなくデジタルで作成されたもの) に対して高精度のテキスト抽出を提供します。精度は PDF の内部構造とフォントエンコーディングによって異なります。最良の結果を得るには、画像としてではなく選択可能なテキストで作成された PDF を使用してください。
生のテキストコンテンツが必要か、位置メタデータが必要かに基づいてツールを選択してください。
CSV(Comma-Separated Values)は、アプリケーション、データベース、プログラミング言語間でのデータ交換において最も広く使用されている形式の1つです。Python 開発者にとって、Python リストを CSV 形式に変換する必要性は頻繁に発生します。アプリケーションデータのエクスポート、レポートの生成、分析用データセットの準備など、さまざまな場面で必要となります。
Python の組み込み csv モジュールは基本的な操作を処理できますが、ネストされたリストや辞書などの複雑なデータ構造を扱うには、追加のロジックとエラー処理が必要です。これらの変換を手動で管理することは、特に複数のデータ型やカスタムフォーマット要件を扱う場合、非効率的でエラーが発生しやすくなります。
このガイドでは、Spire.XLS for Python を使用して、さまざまな Python リスト構造を CSV 形式に変換する完全なパイプラインの構築に焦点を当てます。このアプローチは、単純な1次元リストから複雑なネストされた辞書まで、データの整合性を維持しながら柔軟な方法を提供する堅牢でスケーラブルなソリューションです。
クイックナビゲーション
実装に入る前に、CSV に変換される一般的な Python リスト構造の種類を理解することが重要です。
["りんご", "バナナ", "さくらんぼ"])— 単一行または単一列のデータに最適[{"名前": "田中", "年齢": 30}])— キーを通じて意味的な意味を維持この包括的なアプローチは、現実世界のアプリケーションがリストから CSV へのワークフローをどのように処理するかを反映しています。異なるデータ構造に対して柔軟な方法を提供しながら、一貫した出力品質を確保します。
開始する前に、以下を用意してください。
Python 3.x がインストールされていること
Spire.XLS for Python がインストールされていること:
pip install Spire.XLS
または、Spire.XLS for Python をダウンロードして、プロジェクトに手動で追加することもできます。
Python コードを記述するためのテキストエディタまたは IDE
Python の組み込み csv モジュールは単純な CSV 操作に優れていますが、Spire.XLS は以下の追加の利点を提供します。
1次元リストは値の単純なシーケンスです。以下の手順では、これらの値を CSV の単一行または単一列に書き込む方法を説明します。
手順1: Spire.XLS モジュールをインポート
まず、Spire.XLS から必要なクラスをインポートします。
from spire.xls import *
from spire.xls.common import *
手順2: ワークブックとワークシートを作成
Spire.XLS はデータを整理するためにワークブックとワークシートを使用します。新しいワークブックを作成し、新しいワークシートを追加します。
# ワークブックインスタンスを作成
workbook = Workbook()
# デフォルトのワークシートを削除し、新しいワークシートを追加
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
手順3: 1次元リストデータをワークシートに書き込む
リストを単一行(横方向)または単一列(縦方向)に書き込むかを選択します。
例1: 1次元リストを単一行に書き込む
# サンプル 1次元リスト
data_list = ["りんご", "バナナ", "オレンジ", "ぶどう", "マンゴー"]
# リストを行1に書き込む
for i, item in enumerate(data_list):
worksheet.Range[1, i+1].Value = item
例2: 1次元リストを単一列に書き込む
# サンプル 1次元リスト
data_list = ["りんご", "バナナ", "オレンジ", "ぶどう", "マンゴー"]
# リストを列1に書き込む
for i, item in enumerate(data_list):
worksheet.Range[i + 1, 1].Value = item
手順4: ワークシートを CSV として保存
SaveToFile() を使用してワークブックを CSV ファイルにエクスポートします。適切なフォーマットを確保するために FileFormat.CSV を指定します。
# CSV ファイルとして保存
workbook.SaveToFile("ListToCSV.csv", FileFormat.CSV)
# リソースを解放するためにワークブックを閉じる
workbook.Dispose()
以下は変換結果のプレビューです。
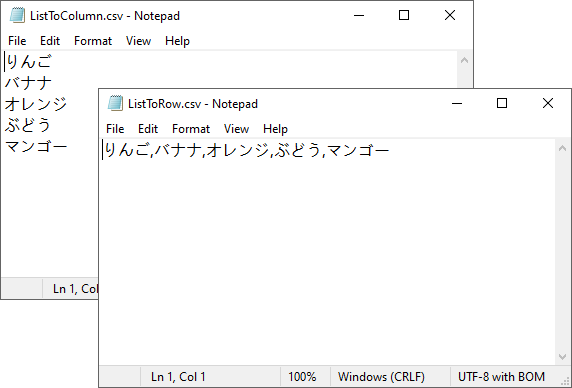
この段階で、1次元リストは正常に CSV 形式に変換されました。このアプローチは、商品名、スコア、識別子などの単純なシーケンスに適しています。
2次元リストは、タブラーデータを表すリストのリストです。より一般的には、各内部リストが CSV ファイルの行を表すこのタイプのリストを扱います。
以下のコードは、2次元リストを CSV に変換する方法を示しています。
from spire.xls import *
from spire.xls.common import *
# ワークブックインスタンスを作成
workbook = Workbook()
# デフォルトのワークシートを削除し、新しいワークシートを追加
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
# サンプル 2次元リスト(ヘッダー + データ)
data = [
["名前", "年齢", "都市", "給与"],
["佐藤太郎", 30, "東京", 500000],
["鈴木花子", 25, "大阪", 450000],
["高橋次郎", 35, "名古屋", 600000],
["田中美咲", 28, "福岡", 520000]
]
# 2次元リストをワークシートに書き込む
for row_index, row_data in enumerate(data):
for col_index, cell_data in enumerate(row_data):
worksheet.Range[row_index + 1, col_index + 1].Value = str(cell_data)
# CSV ファイルとして保存
workbook.SaveToFile("2DListToCSV.csv", FileFormat.CSV)
workbook.Dispose()
以下は変換結果のプレビューです。
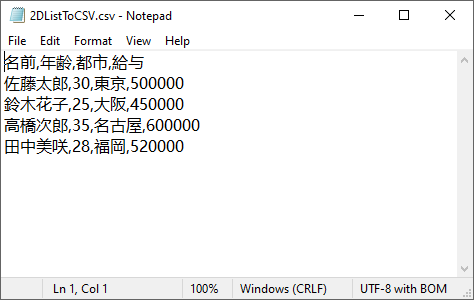
str(cell_data) が混合データ型(数値、文字列)を処理生成された CSV ファイルは、さらに加工することができます。デバイス間で安全にプレゼンテーションを行うために、PDF に変換することも可能です。詳細なオプションについては、Python を使用して Excel や CSV を PDF に変換する方法に関するガイドをご参照ください。
辞書のリストは、データに名前付きフィールドがある場合に理想的です(例: [{"名前": "田中", "年齢": 30}, {"名前": "鈴木", "年齢": 25}])。辞書のキーが CSV ヘッダーになり、値が行になります。
以下のコードは、辞書のリストを CSV に変換する方法を示しています。
from spire.xls import *
from spire.xls.common import *
# ワークブックインスタンスを作成
workbook = Workbook()
# デフォルトのワークシートを削除し、新しいワークシートを追加
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add("Data")
# サンプル辞書のリスト
customer_list = [
{"顧客ID": 101, "名前": "山田花子", "メール": "yamada@ example.com"},
{"顧客ID": 102, "名前": "伊藤健太", "メール": "ito@ example.com"},
{"顧客ID": 103, "名前": "中村美香", "メール": "nakamura@ example.com"}
]
# ヘッダー(辞書キー)を抽出して行1に書き込む
if customer_list: # リストが空でないことを確認
headers = list(customer_list[0].keys())
# ヘッダーを書き込む
for col_index, header in enumerate(headers):
worksheet.Range[1, col_index + 1].Value = str(header)
# 辞書の値を行2以降に書き込む
for row_index, record in enumerate(customer_list):
for col_index, header in enumerate(headers):
# 安全に値を取得、キーが存在しない場合は空の文字列を使用
value = record.get(header, "")
worksheet.Range[row_index + 2, col_index + 1].Value = str(value)
# CSVファイルとして保存
workbook.SaveToFile("Customer_Data.csv", FileFormat.CSV)
workbook.Dispose()
以下は変換結果のプレビューです。
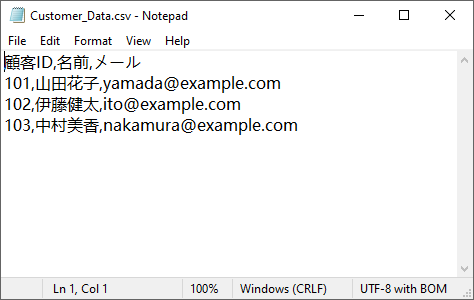
.keys() を使用して列名を自動的に取得.get() メソッドを使用: デフォルトの空の文字列で欠落したキーを適切に処理このアプローチは、API レスポンス、データベースクエリ結果、または CSV にエクスポートする必要がある名前付きフィールドを持つデータに特に役立ちます。
Spire.XLS for Python を使用する最大の利点の1つは、カスタム区切り文字とエンコーディングで CSV ファイルを保存する柔軟性です。これにより、異なる地域、アプリケーション、データ要件に合わせて CSV 出力を調整できます。
区切り文字とエンコーディングを指定するには、Worksheet クラスの SaveToFile() メソッドの対応するパラメーターを変更するだけです。
# 異なる区切り文字とエンコーディングで保存
worksheet.SaveToFile("semicolon_delimited.csv", ";", Encoding.get_UTF8())
worksheet.SaveToFile("tab_delimited.csv", "\t", Encoding.get_UTF8())
worksheet.SaveToFile("unicode_encoded.csv", ",", Encoding.get_Unicode())
セミコロン区切り文字(欧州ロケール)
多くの欧州諸国では小数点の区切り文字としてカンマの代わりにセミコロンを使用するため、カンマ区切りの CSV ファイルは問題を引き起こす可能性があります。セミコロンを使用することで競合を回避できます。
worksheet.SaveToFile("european_data.csv", ";", Encoding.get_UTF8())
タブ区切り文字(TSV 形式)
タブ区切り値は、データ内にフィールドにカンマが含まれている場合に役立ちます。
worksheet.SaveToFile("tab_separated.csv", "\t", Encoding.get_UTF8())
Unicode エンコーディング
国際文字(中国語、日本語、アラビア語など)の場合は、Unicode エンコーディングを使用します。
worksheet.SaveToFile("international_data.csv", ",", Encoding.get_Unicode())
Python リストを CSV に変換するプロセスは単純に見えるかもしれませんが、いくつかの実用的な課題が発生する可能性があります。
リストには混合データ型(文字列、整数、浮動小数点数、None)が含まれる可能性があり、変換中に型エラーが発生する原因となります。
解決策:
str() を使用して文字列に変換None 値をデフォルトの置換で明示的に処理辞書のリストを変換する際、一部のレコードに特定のキーがない場合、KeyError 例外が発生する可能性があります。
解決策:
.get(key, default_value) メソッドを使用空のリストを処理しようとすると、インデックスエラーが発生したり、無効な CSV ファイルが作成されたりする可能性があります。
解決策:
if customer_list:カンマ、引用符、改行を含むフィールド値は CSV 構造を壊す可能性があります。
解決策:
ワークブックの破棄に失敗すると、特にバッチ処理シナリオでメモリリークにつながる可能性があります。
解決策:
workbook.Dispose() を呼び出す非 ASCII 文字は、誤ったエンコーディングが使用されると破損して表示される可能性があります。
解決策:
Encoding.get_UTF8()非常に大きなリストを処理すると、 상당한 메모리와 시간이 소비될 수 있습니다.
解決策:
これらの問題を予測することで、より信頼性の高いリストから CSV への変換ワークフローを構築できます。
Python リストを CSV に変換することは、単純なデータ変換だけでなく、リストデータの読み取り、タブラー形式への整理、標準化された CSV ファイルへの書き込みを含む構造化されたプロセスです。
適切なデータ構造化に焦点を当て、Python と Spire.XLS を使用することで、完全なリストから CSV へのパイプラインを効率的に実装でき、データエクスポートタスクの自動化が容易になります。
このアプローチは、以下の処理に特に役立ちます。
Spire.XLS for Python を使用すると、以下のことが可能です。
単純なシーケンス、構造化されたテーブル、意味的な辞書のいずれを扱っていても、Spire.XLS は基本的なスクリプトから本番システムまでスケールする堅牢なソリューションを提供します。
Spire.XLS for Python のパフォーマンスを評価し、制限を解除したい場合は、30日間の無料トライアルを申請できます。
以下のベストプラクティスに従ってください。
Dispose() を使用してリソースをクリーンアップはい。リストをループ処理し、それぞれを別々の CSV として保存できます。
lists = {
"fruits": ["りんご", "バナナ", "さくらんぼ"],
"scores": [85, 92, 78]
}
for name, data in lists.items():
wb = Workbook()
wb.Worksheets.Clear()
ws = wb.Worksheets.Add(name)
for i, val in enumerate(data):
ws.Range[i + 1, 1].Value = str(val)
wb.SaveToFile(f"{name}.csv", FileFormat.CSV)
wb.Dispose()
このアプローチは、複数のデータセットを一括エクスポートする場合に役立ちます。
CSV は数値をプレーンテキストとして保存するため、保存前にフォーマットを適用する必要があります。
ws.Range["A1:A10"].NumberFormat = "¥#,##0"
これにより、数値が CSV で ¥1,234 として表示されます。詳細な数値フォーマットオプションについては、Python で数値フォーマットを設定を参照してください。
CSV 形式は XLSX と比較してフォーマットサポートが限られていることに注意してください。豊富なフォーマットが必要な場合は、代わりに Excel 形式で保存することを検討してください。
はい!Spire.XLS for Python はクロスプラットフォームであり、Windows、macOS、Linux システムをサポートしています。このライブラリは可能な限り純粋な Python 実装を使用しており、異なる環境間での互換性を確保しています。
2次元リストを変換する際、すべての行が同じ数の列を持っていることを確認してください。
# 短い行を空の文字列でパディング
max_cols = max(len(row) for row in data)
for row in data:
while len(row) < max_cols:
row.append("")
これにより、出力 CSV で列のずれを防ぎます。
はい。データを書き込む前にヘッダー行を挿入するだけです。
worksheet.Range[1, 1].Value = "項目" # ヘッダー
for i, item in enumerate(data_list):
worksheet.Range[i + 2, 1].Value = item # データは行2から開始
これにより、CSV 出力にラベル付きの列が作成されます。
カスタム設定を使用した CSV 変換の場合、最大限の柔軟性のために Worksheet.SaveToFile(delimiter, encoding) を使用してください。
Python でデータを扱う際、TXT を CSV に変換するニーズは非常に一般的です。TXT ファイルは非構造のプレーンテキストとして保存されることが多く、プログラムでの処理が難しい場合があります。一方、CSV ファイルはデータを行と列に整理して格納するため、データ分析、レポート作成、アプリケーション間での共有に適しています。
テキストデータをより扱いやすく構造化するため、開発者は TXT ファイルの内容を解析し、表形式に整理して CSV に変換する必要があります。しかし、この処理を手動で行うのは非効率でミスも発生しやすく、特に複数ファイルや複雑な区切り文字を扱う場合は問題が顕著になります。
本ガイドでは、Spire.XLS for Python を使用し、Python で TXT ファイルを CSV 形式に変換する一連の処理フローを構築する方法を解説します。実務において拡張性と実用性を兼ね備えたアプローチです。
クイックナビゲーション
CSV(Comma-Separated Values)は、表形式データを保存するためのシンプルなテキストベースのファイル形式です。各行が1レコードを表し、行内の値はカンマ(またはタブやセミコロンなどの区切り文字)で区切られます。
CSV は、Excel、Google スプレッドシート、データベース、Python などのプログラミング言語で広くサポートされています。そのシンプルな構造により、データのインポート、エクスポート、分析、自動処理が容易に行えます。
CSV ファイルの例:
Name, Age, City
John, 28, New York
Alice, 34, Los Angeles
Bob, 25, Chicago
このような構造化形式は効率的なデータ処理を可能にし、非構造の TXT ファイルからの変換に適しています。
開始する前に、以下を準備してください:
Python 3.x がインストールされていること
Spire.XLS for Python のインストール:
pip install Spire.XLS
または、Spire.XLS for Python をダウンロード して手動でプロジェクトに追加することもできます。
Python コードを作成するためのテキストエディターまたは IDE
Python で TXT ファイルを CSV に変換する処理はシンプルで、以下の手順で実行できます:
以下のコードは、Python を使用して TXT ファイルを CSV にエクスポートする方法を示します:
from spire.xls import *
# TXT ファイルを読み込む
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# 各行をスペースで分割して処理(必要に応じて区切り文字を変更)
processed_data = [line.strip().split() for line in lines]
# Excel ワークブックを作成
workbook = Workbook()
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# 処理済みデータをワークシートに書き込む
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
# セルにデータを書き込む
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# ワークシートを CSV ファイルとして保存(UTF-8 エンコーディング)
sheet.SaveToFile("TxtToCsv.csv", ",", Encoding.get_UTF8())
# リソースを解放
workbook.Dispose()
以下は変換結果のイメージです:
データがすでにリスト形式になっている場合は、Spire.XLS for Python を使用して、そのリストを Excel や CSV ファイルに変換することもできます。
複数の TXT ファイルを自動的に CSV に変換する場合、フォルダー内のすべての .txt ファイルをループ処理して順番に変換できます。
以下のコードは、複数の TXT ファイルを一括で CSV に変換する方法を示します:
import os
from spire.xls import *
# TXT ファイルが格納されているフォルダー
input_folder = "txt_files"
output_folder = "csv_files"
# 出力フォルダーが存在しない場合は作成
os.makedirs(output_folder, exist_ok=True)
# 単一ファイルを変換する関数
def convert_txt_to_csv(file_path, output_path):
# TXT ファイルを読み込む
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
# 各行を処理(スペース区切り。必要に応じて変更)
processed_data = [line.strip().split() for line in lines if line.strip()]
# ワークブックを作成し、最初のワークシートを取得
workbook = Workbook()
sheet = workbook.Worksheets[0]
# データを書き込み
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# CSV として保存(UTF-8)
sheet.SaveToFile(output_path, ",", Encoding.get_UTF8())
workbook.Dispose()
print(f"Converted '{file_path}' -> '{output_path}'")
# フォルダー内のすべての TXT ファイルを処理
for filename in os.listdir(input_folder):
if filename.lower().endswith(".txt"):
input_path = os.path.join(input_folder, filename)
output_name = os.path.splitext(filename)[0] + ".csv"
output_path = os.path.join(output_folder, output_name)
convert_txt_to_csv(input_path, output_path)
この方法により、大量のファイルを扱う際の作業効率が大幅に向上します。
テキストファイルを CSV に変換する際は、ファイルのレイアウトの違いや想定外のエラーが発生する可能性があります。以下のポイントを押さえることで、さまざまなケースに柔軟かつ安定して対応できます。
すべての TXT ファイルがスペース区切りとは限りません。タブ、カンマ、またはその他の文字が使用されている場合は、split() 関数の引数を適切に変更する必要があります。
タブ区切りファイル(.tsv)の場合:
processed_data = [line.strip().split('\t') for line in lines]
カンマ区切りの場合:
processed_data = [line.strip().split(',') for line in lines]
カスタム区切り文字(例:|)の場合:
processed_data = [line.strip().split('|') for line in lines]
このように事前に正しく列分割を行うことで、CSV 出力時のデータ構造を正確に保つことができます。
ファイルの読み込み・書き込み処理では、例外処理(try-except)を導入することが重要です。これにより、スクリプトの安定性が向上し、予期しないクラッシュを防ぐことができます。
try:
# 変換処理
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# ... 続きの処理
except FileNotFoundError:
print("エラー:指定されたファイルが見つかりません。")
except Exception as e:
print(f"エラー:{e}")
補足: エラーメッセージはできるだけ具体的に記述すると、原因特定が容易になります。
TXT ファイルには空行が含まれている場合があります。そのまま処理すると、CSV に空行が出力されてしまいます。
processed_data = [line.strip().split() for line in lines if line.strip()]
このように条件を付けてフィルタリングすることで、実データのみを処理し、よりクリーンな CSV を生成できます。
TXT から CSV への変換は一見シンプルですが、実際にはいくつかの実務的な課題が存在します。
同一ファイル内でも、行ごとに異なる区切り文字が使われている場合があります。その結果、列がずれてしまうことがあります。
対策:
行によって列数が異なると、データの整合性が崩れます。
対策:
TXT ファイルは UTF-8、ASCII、Latin-1 など異なるエンコーディングで保存されている場合があります。これにより文字化けが発生する可能性があります。
対策:
chardet などのライブラリでエンコーディングを検出するカンマ、引用符、改行などを含むフィールドは、CSV の構造を破壊する可能性があります。
対策:
非常に大きな TXT ファイルを扱う場合、メモリ使用量が増大する可能性があります。
対策:
余分なスペースや不統一なフォーマットは、データ品質に影響します。
対策:
これらのポイントを事前に考慮することで、より信頼性の高い TXT → CSV 変換ワークフロー を構築できます。
TXT ファイルを CSV に変換する処理は、単なるファイル形式の変換ではなく、テキストデータの読み込み・解析・構造化を含む一連のプロセスです。
Python と Spire.XLS を組み合わせることで、安定性と拡張性を兼ね備えた TXT → CSV 変換パイプライン を効率よく構築できます。これにより、データ前処理の自動化が大幅に容易になります。
この手法は、ログファイル、データエクスポート、各種テキストデータを分析・レポート・スプレッドシート連携用に構造化する場面で特に有効です。
Spire.XLS for Python を使用することで、以下が実現できます:
より詳細に機能を評価したい場合や制限を解除したい場合は、30日間の無料トライアル を利用できます。
はい。Spire.XLS for Python は Microsoft Excel に依存せずに動作するため、Excel がインストールされていない環境でも CSV ファイルの生成・出力が可能です。
フォルダー内のすべての TXT ファイルをループ処理し、各ファイルに対して変換関数を適用します。本記事では、指定ディレクトリ内の .txt ファイルを自動処理するサンプルコードを紹介しています。
if line.strip() のような条件で空行を除外し、さらに列数の検証ロジックを追加することで、不整合や空行の出力を防ぐことができます。
TXT ファイルの区切り文字に応じて、split() の引数を変更します。例えば、タブ(\t)、カンマ、パイプ(|)などに対応するには、split('\t')、split(',')、split('|') のように指定します。
UTF-8 の使用が推奨されます。多言語文字に対応でき、さまざまな環境・アプリケーションとの互換性を確保できます。
はい。Spire.XLS for Python を使用すれば、TXT ファイルを XLSX / XLS 形式に直接変換することも可能です。詳細は関連チュートリアルを参照してください。

.NET ドキュメント処理ワークフローにおいて、C# で TIFF を PDF に変換することは一般的な要件です。開発者は、スキャン文書や複数ページの TIFF ファイルを PDF 形式に変換して、互換性の向上、配布プロセスの簡素化、標準化されたドキュメント管理を実現する必要があります。
TIFF ファイルはスキャンおよびアーカイブシステムで広く使用されており、特に単一ファイルに複数のページを保存する場合に適しています。ただし、この形式は共有やクロスプラットフォームでの閲覧時に必ずしも理想的ではなく、PDF はより普遍的で一貫性のあるフォーマットを提供します。
Spire.PDF for .NET を使用すると、簡潔で信頼性の高い C# コードを使用して TIFF 画像を効率的に PDF に変換できます。本記事では、.NET で TIFF から PDF への変換を実行する方法を示し、複数ページの TIFF 画像の処理、ページレイアウトの調整、実際のシナリオにおけるベストプラクティスの適用について説明します。
目次
TIFF(タグ付き画像ファイル形式)は、単一ファイルに複数のページを含めることができる柔軟な画像形式です。この特性により、以下のシナリオで広く利用されています。
TIFF を PDF に変換することには、次のような利点があります。
このセクションでは、Spire.PDF を使用して C# で TIFF 画像を PDF に変換する手順の例を提供します。
まず、NuGet パッケージマネージャーを使用してライブラリをインストールします。
Install-Package FreeSpire.PDF
または、.NET CLI を使用します。
dotnet add package FreeSpire.PDF
Spire.PDF for .NET パッケージをダウンロードして、プロジェクトに手動で追加することも可能です。
単一ページの TIFF ファイルの場合、最も簡単な方法は元の画像サイズに一致する PDF ページを作成し、画像を直接ページに描画することです。これにより、TIFF コンテンツが PDF ページ全体に完全に填充され、不要な余白やスケーリングの問題を回避できます。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
// TIFF 画像を読み込む
PdfImage tiffImage = PdfImage.FromFile("Sample_Page.tiff");
// 新しい PDF ドキュメントを作成する
PdfDocument pdf = new PdfDocument();
// デフォルトのページ余白を削除する
pdf.PageSettings.Margins.All = 0;
// 画像サイズを取得する
float width = tiffImage.PhysicalDimension.Width;
float height = tiffImage.PhysicalDimension.Height;
// TIFF 画像と同じサイズの PDF ページを追加する
PdfPageBase page = pdf.Pages.Add(new SizeF(width, height));
// 画像を描画してページを完全に埋める
page.Canvas.DrawImage(tiffImage, 0, 0, width, height);
// PDF ドキュメントを保存する
pdf.SaveToFile("Sample_Page.pdf");
pdf.Close();
以下は変換結果のプレビューです。
主要な API の説明:
PdfImage.FromFile: TIFF 画像を PDF 互換オブジェクトとして読み込むPageSettings.Margins.All: デフォルトの余白を削除して全ページレンダリングを実現Pages.Add(SizeF): TIFF サイズに正確に一致する PDF ページを作成Canvas.DrawImage: TIFF 画像を描画してページを完全に埋めるSaveToFile: 変換後の PDF ファイルを保存この方法では元の TIFF サイズが保持され、出力された PDF で画像コンテンツがページ全体に鮮明に表示されることが保証されます。
画像から PDF への変換に関するその他のシナリオについては、C# で画像を PDF に変換する方法 を参照してください。
複数ページの TIFF ファイルには複数のフレームが含まれており、各フレームは独立したページを表します。変換プロセスでは、各フレームを反復処理し、現在の TIFF フレームにサイズが一致する PDF ページを作成して、元のレイアウトを保持する必要があります。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.Drawing.Imaging;
// 複数ページの TIFF ファイルを読み込む
Image tiffImage = Image.FromFile("Sample.tiff");
// フレーム情報を取得する
FrameDimension dimension = new FrameDimension(tiffImage.FrameDimensionsList[0]);
int frameCount = tiffImage.GetFrameCount(dimension);
// 新しい PDF ドキュメントを作成する
PdfDocument pdf = new PdfDocument();
// デフォルトの余白を削除する
pdf.PageSettings.Margins.All = 0;
// 各 TIFF フレームを処理する
for (int i = 0; i < frameCount; i++)
{
// 現在のフレームを選択する
tiffImage.SelectActiveFrame(dimension, i);
// 現在のフレームを PdfImage に変換する
PdfImage pdfImage = PdfImage.FromImage(tiffImage);
// 現在のフレームサイズを取得する
float width = pdfImage.PhysicalDimension.Width;
float height = pdfImage.PhysicalDimension.Height;
// フレームサイズに一致する PDF ページを作成する
PdfPageBase page = pdf.Pages.Add(new SizeF(width, height));
// フレームを描画してページを埋める
page.Canvas.DrawImage(pdfImage, 0, 0, width, height);
}
// PDF ドキュメントを保存する
pdf.SaveToFile("Sample.pdf");
pdf.Close();
// リソースを解放する
tiffImage.Dispose();
以下は変換結果のプレビューです。
核心概念の解説:
FrameDimension: 複数ページの TIFF ファイル内のフレームコレクションを識別GetFrameCount: TIFF ファイルの総ページ数を取得SelectActiveFrame: 指定された TIFF フレームに切り替えて処理Pages.Add(SizeF): 各 TIFF ページにサイズが一致する PDF ページを作成Canvas.DrawImage: 各 TIFF フレームを対応する PDF ページにレンダリングこの方法では、元の TIFF ファイル内のすべてのページが完全に保持され、各ページが PDF キャンバスを完全に占有することが保証され、追加の余白やスケーリングによる歪みが発生しません。
一部のワークフローでは、出力される PDF が印刷、ドキュメント共有、またはアーカイブのために標準的なページサイズ(A4 や Letter など)に従う必要があります。この場合、元の TIFF サイズに基づいて PDF ページを作成するのではなく、画像を比例スケーリングして固定ページサイズに適合させ、水平方向に中央揃えにすることができます。
using Spire.Pdf;
using Spire.Pdf.Graphics;
PdfDocument pdf = new PdfDocument();
PdfImage image = PdfImage.FromFile("Sample_Page.tiff");
// 余白付きの A4 ページを作成する
PdfPageBase page = pdf.Pages.Add(PdfPageSize.A4, new PdfMargins(20));
// 比例スケーリングを計算する
float scale = Math.Min(
page.Canvas.ClientSize.Width / image.PhysicalDimension.Width,
page.Canvas.ClientSize.Height / image.PhysicalDimension.Height
);
// 最終的な画像サイズを計算する
float width = image.PhysicalDimension.Width * scale;
float height = image.PhysicalDimension.Height * scale;
// 水平方向に中央揃えし、上部に配置
float x = (page.Canvas.ClientSize.Width - width) / 2;
// 画像を PDF ページに描画する
page.Canvas.DrawImage(image, x, 0, width, height);
// PDF ファイルを保存する
pdf.SaveToFile("Sample_Page1.pdf");
pdf.Close();
生成された PDF は標準的なページサイズに適合し、同時に元の画像のアスペクト比を保持します。
この方法を採用する利点:
TIFF ファイルを元のサイズを保持するのではなく、標準化された PDF レイアウトに適合させる必要がある場合、この方法が特に効果的です。
さらに多くの C# を使用した PDF レイアウトとページ設定のチュートリアル を探索することも可能です。
本番環境では、通常、変換プロセスに対してよりきめ細かい制御が必要です。
ドキュメント管理システム、スキャンアーカイブ、または自動化ワークフローでは、一度に複数の TIFF ファイルを PDF 形式に変換する必要がある場合があります。次の例では、フォルダー内のすべての TIFF ファイルを処理し、各ファイルを個別の PDF に変換しながら、元の画像サイズを保持します。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;
string inputFolder = @"C:\Documents\TIFF";
string outputFolder = @"C:\Documents\PDF";
// 出力フォルダーが存在しない場合は作成する
Directory.CreateDirectory(outputFolder);
// フォルダー内のすべての TIFF ファイルを処理する
foreach (string tiffFile in Directory.GetFiles(inputFolder, "*.tiff"))
{
PdfImage image = PdfImage.FromFile(tiffFile);
using (PdfDocument pdf = new PdfDocument())
{
// TIFF サイズに一致する PDF ページを作成する
PdfPageBase page = pdf.Pages.Add(
new SizeF(
image.PhysicalDimension.Width,
image.PhysicalDimension.Height
)
);
// TIFF 画像をページに描画する
page.Canvas.DrawImage(
image,
0,
0,
image.PhysicalDimension.Width,
image.PhysicalDimension.Height
);
// 出力ファイルパスを生成する
string outputFile = Path.Combine(
outputFolder,
Path.GetFileNameWithoutExtension(tiffFile) + ".pdf"
);
// PDF を保存する
pdf.SaveToFile(outputFile);
}
}
バッチ変換の利点:
この方法は、大量の単一ページ TIFF ファイルを変換するのに最適です。フォルダーに複数ページの TIFF ドキュメントが含まれている場合は、この方法を前述の複数ページ変換ロジックと組み合わせることができます。
複数の TIFF 画像を単一の PDF ドキュメントに統合する必要がある場合、各 TIFF ファイルを個別の PDF ページとして追加できます。これは、スキャン文書、請求書、または画像ベースのレポートを統合する際に役立ちます。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
string[] tiffFiles =
{
"Page1.tiff",
"Page2.tiff",
"Page3.tiff"
};
PdfDocument pdf = new PdfDocument();
foreach (string file in tiffFiles)
{
PdfImage image = PdfImage.FromFile(file);
float width = image.PhysicalDimension.Width;
float height = image.PhysicalDimension.Height;
// TIFF サイズに一致するページを作成する
PdfPageBase page = pdf.Pages.Add(new SizeF(width, height));
// TIFF 画像を描画する
page.Canvas.DrawImage(image, 0, 0, width, height);
}
// 統合された PDF を保存する
pdf.SaveToFile("CombinedDocument.pdf");
pdf.Close();
TIFF ファイルを統合する利点:
各 TIFF ファイルが単一の PDF ドキュメント内の個別のページとして表示される必要がある場合、この方法が最適です。
大型の複数ページ TIFF ファイルは、変換プロセス中に大量のメモリを消費します。パフォーマンスを向上させるために、各フレームを順次処理し、使用直後にリソースを解放することをお勧めします。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.Drawing.Imaging;
// 大型の TIFF ファイルを効率的に処理する
using (Image tiffImage = Image.FromFile("LargeDocument.tiff"))
using (PdfDocument pdf = new PdfDocument())
{
FrameDimension dimension =
new FrameDimension(tiffImage.FrameDimensionsList[0]);
int frameCount = tiffImage.GetFrameCount(dimension);
for (int i = 0; i < frameCount; i++)
{
// 現在のフレームをアクティブにする
tiffImage.SelectActiveFrame(dimension, i);
using (PdfImage image = PdfImage.FromImage(tiffImage))
{
float width = image.PhysicalDimension.Width;
float height = image.PhysicalDimension.Height;
// フレームサイズに一致するページを作成する
PdfPageBase page = pdf.Pages.Add(
new SizeF(width, height)
);
// 現在のフレームを描画する
page.Canvas.DrawImage(
image,
0,
0,
width,
height
);
}
}
pdf.SaveToFile("LargeDocument.pdf");
}
メモリ最適化のテクニック:
using ステートメントを使用してリソースを自動的に解放この方法は、大型のアーカイブ TIFF ファイル、医療スキャン、企業ドキュメント移行タスクに特に有用です。
TIFF を PDF に変換する際、開発者は以下のような一般的な問題に遭遇する可能性があります。
問題: PDF 出力に最初のページのみが表示される。
原因: TIFF ファイル内のすべてのフレームが正しく反復処理されていない。
解決策: GetFrameCount と SelectActiveFrame を使用して各フレームを処理する。
int frameCount = tiffImage.GetFrameCount(dimension);
for (int i = 0; i < frameCount; i++)
{
tiffImage.SelectActiveFrame(dimension, i);
// 各フレームを処理する
}
問題: 画像が引き伸ばされたり、PDF ページに正しく適合しない。
原因: TIFF を固定サイズページ(A4 など)に適合させる際に、スケーリング計算が正しくない。
解決策: アスペクト比を保持する比例スケーリングアルゴリズムを使用する。
float scale = Math.Min(
page.Canvas.ClientSize.Width / image.PhysicalDimension.Width,
page.Canvas.ClientSize.Height / image.PhysicalDimension.Height
);
float width = image.PhysicalDimension.Width * scale;
float height = image.PhysicalDimension.Height * scale;
問題: 大型の TIFF ファイルを処理する際にパフォーマンスが遅くなったり、メモリ不足エラーが発生する。
原因: 複数ページの TIFF がメモリに読み込まれ、リソースが適時に解放されていない。
解決策: フレームを順次処理し、適時にリソースを解放する。
using (Image tiffImage = Image.FromFile("Large.tiff"))
using (PdfDocument pdf = new PdfDocument())
{
// フレームを逐个処理する
}
問題: 一部の TIFF ファイルを読み込む際にエラーが発生する。
原因: TIFF ファイルが非標準の圧縮またはカラー形式を使用している。
解決策: TIFF ファイルがライブラリでサポートされている標準形式を使用していることを確認する。
Spire.PDF for .NET を使用して C# で TIFF を PDF に変換することは、簡潔で効率的なプロセスです。このライブラリは、単一ページおよび複数ページの TIFF ファイルを処理するための包括的なメソッドを提供し、同時に画像品質とレイアウトの正確性を保持します。
本記事で示された例とベストプラクティスに従うことで、開発者はドキュメントアーカイブ、バッチ処理、企業ドキュメント管理システムなど、さまざまなシナリオに対応する信頼性の高い TIFF から PDF への変換を実装できます。
Spire.PDF for .NET の機能を評価したい場合は、無料トライアルライセンスを申請 できます。
FrameDimension を使用して TIFF ファイル内の各フレームにアクセスし、各フレームに対して個別の PDF ページを作成します。GetFrameCount メソッドはフレームの総数を返し、SelectActiveFrame を使用して各フレームを逐次処理できます。
専用ライブラリ(Spire.PDF for .NET など)を使用することが、最も信頼性が高く効率的なソリューションを提供します。最小限のコードで画像の読み込みと PDF の生成を処理し、複数ページの TIFF ファイルを全面的にサポートします。
未圧縮の TIFF ファイルと比較して、PDF 圧縮は通常ファイルサイズを縮小できます。ただし、実際のサイズ縮小幅は、元の TIFF 圧縮方式、画像コンテンツ、PDF 設定によって異なります。高解像度画像は依然として较大的な PDF ファイルになる可能性があります。
はい。Spire.PDF for .NET は独立して動作し、Microsoft Office、Adobe Acrobat、または他の外部ソフトウェアを必要としません。独自のレンダリングエンジンを使用してすべての変換操作を実行します。
画像品質を保持するには、不要なスケーリングを回避し、PDF ページサイズを TIFF 画像サイズに正確に一致させて最適な効果を得ることが推奨されます。





