Word 文書には重要なデータを含む表がよくあります。この表からデータを抽出することは、さらなる分析やレポート作成、コンテンツの再作成など、さまざまなシナリオで使用できます。Java を使用して Word 文書から表を自動的に抽出することで、開発者は効率的にこの構造化データにアクセスし、データベースやスプレッドシートなどに適した形式に変換することができ、このデータをさまざまなシナリオで活用できます。本記事では、Spire.Doc for Java を使用して、Java プロジェクトで Word 文書から表を抽出する方法を紹介します。
Spire.Doc for Java をインストールします
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.1.3</version>
</dependency>
</dependencies>Java で Word 文書から表を抽出する
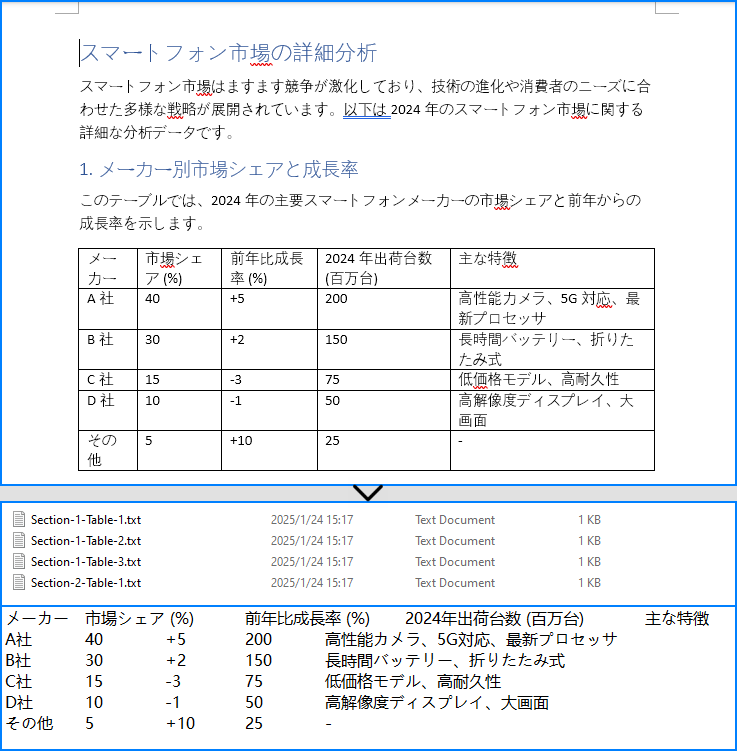
Spire.Doc for Java を使用すると、開発者は Section.getTables() メソッドを利用して Word 文書から表を抽出できます。表のデータは、行とセルを繰り返し処理することでアクセスできます。表抽出の手順は以下の通りです:
- Document オブジェクトを作成します。
- Document.loadFromFile() メソッドを使用して Word 文書を読み込みます。
- Document.getSections() メソッドを使用して文書のセクションにアクセスし、繰り返し処理します。
- 各セクションの表に Section.getTables() メソッドを使用してアクセスし、繰り返し処理します。
- 各表の行に Table.getRows() メソッドを使用してアクセスし、繰り返し処理します。
- 各行のセルに TableRow.getCells() メソッドを使用してアクセスし、繰り返し処理します。
- 各セルのテキストを TableCell.getParagraphs() と Paragraph.getText() メソッドを使用して、その段落を繰り返し処理することで取得します。
- 抽出した表データを StringBuilder オブジェクトに追加します。
- StringBuilder オブジェクトをテキストファイルに書き込むか、必要に応じて使用します。
- Java
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractWordTable {
public static void main(String[] args) {
// Documentオブジェクトを作成します
Document doc = new Document();
try {
// Wordドキュメントを読み込みます
doc.loadFromFile("Sample.docx");
// ドキュメント内のセクションを繰り返し処理します
for (int i = 0; i < doc.getSections().getCount(); i++) {
// セクションを取得します
Section section = doc.getSections().get(i);
// セクション内のテーブルを繰り返し処理します
for (int j = 0; j < section.getTables().getCount(); j++) {
// テーブルを取得します
Table table = section.getTables().get(j);
// テーブルの内容を収集します
StringBuilder tableText = new StringBuilder();
for (int k = 0; k < table.getRows().getCount(); k++) {
// 行を取得します
TableRow row = table.getRows().get(k);
// 行内のセルを繰り返し処理します
StringBuilder rowText = new StringBuilder();
for (int l = 0; l < row.getCells().getCount(); l++) {
// セルを取得します
TableCell cell = row.getCells().get(l);
// セル内の段落を繰り返し処理してテキストを取得します
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
cellText += paragraph.getText() + " ";
}
if (l < row.getCells().getCount() - 1) {
rowText.append(cellText).append("\t");
} else {
rowText.append(cellText).append("\n");
}
}
tableText.append(rowText);
}
// try-with-resourcesを使用して、テーブルの内容をファイルに書き込みます
try (FileWriter writer = new FileWriter("output/Tables/Section-" + (i + 1) + "-Table-" + (j + 1) + ".txt")) {
writer.write(tableText.toString());
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
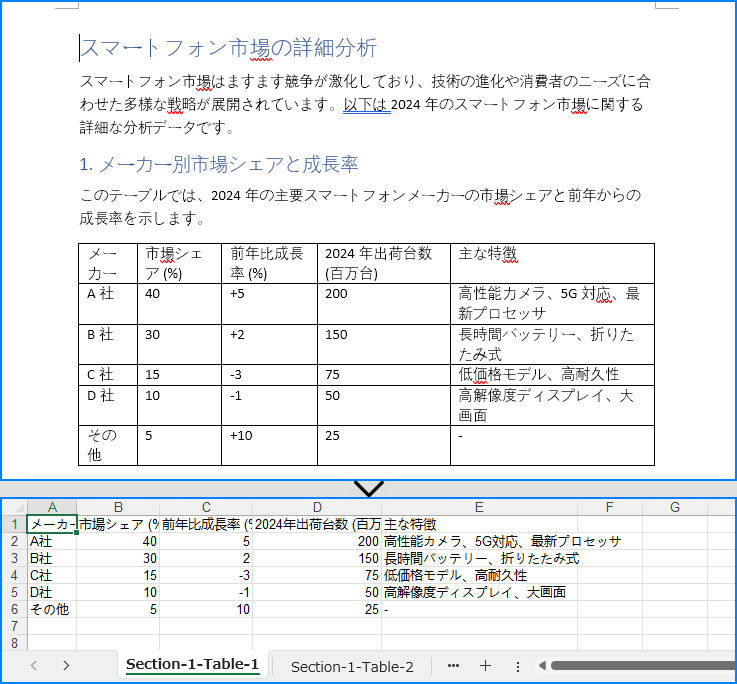
Word 文書の表を Excel ワークシートに抽出する
開発者は Spire.Doc for Java と Spire.XLS for Java を組み合わせて、Word 文書から表データを抽出し、Excel ワークシートに書き込むことができます。まず、Spire.XLS for Java をダウンロードするか、以下の Maven 設定を追加します:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>15.1.3</version>
</dependency>
</dependencies>Word 文書から Excel ワークブックに表を抽出する詳細な手順は以下の通りです:
- Document オブジェクトを作成します。
- Workbook オブジェクトを作成し、Workbook.getWorksheets().clear() メソッドを使用してデフォルトのワークシートを削除します。
- Document.loadFromFile() メソッドを使用して Word 文書を読み込みます。
- Document.getSections() メソッドを使用して文書のセクションにアクセスし、繰り返し処理します。
- 各セクションの表に Section.getTables() メソッドを使用してアクセスし、繰り返し処理します。
- 各表に対して Workbook.getWorksheets().add() メソッドを使用してワークシートを作成します。
- 各表の行に Table.getRows() メソッドを使用してアクセスし、繰り返し処理します。
- 各行のセルに TableRow.getCells() メソッドを使用してアクセスし、繰り返し処理します。
- 各セルのテキストを TableCell.getParagraphs() と Paragraph.getText() メソッドを使用して、その段落を繰り返し処理することで取得します。
- 抽出したセルのテキストを Worksheet.getRange().get(row, column).setValue() メソッドを使用して、ワークシートの対応するセルに書き込みます。
- 必要に応じてワークシートのフォーマットを調整します。
- Workbook.saveToFile() メソッドを使用してワークブックを Excel ファイルとして保存します。
- Java
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractWordTableToExcel {
public static void main(String[] args) {
// Documentオブジェクトを作成します
Document doc = new Document();
// Workbookオブジェクトを作成します
Workbook workbook = new Workbook();
// デフォルトのワークシートを削除します
workbook.getWorksheets().clear();
try {
// Wordドキュメントを読み込みます
doc.loadFromFile("Sample.docx");
// ドキュメント内のセクションを繰り返し処理します
for (int i = 0; i < doc.getSections().getCount(); i++) {
// セクションを取得します
Section section = doc.getSections().get(i);
// セクション内のテーブルを繰り返し処理します
for (int j = 0; j < section.getTables().getCount(); j++) {
// テーブルを取得します
Table table = section.getTables().get(j);
// 各テーブル用のワークシートを作成します
Worksheet sheet = workbook.getWorksheets().add("Section-" + (i + 1) + "-Table-" + (j + 1));
for (int k = 0; k < table.getRows().getCount(); k++) {
// 行を取得します
TableRow row = table.getRows().get(k);
for (int l = 0; l < row.getCells().getCount(); l++) {
// セルを取得します
TableCell cell = row.getCells().get(l);
// セル内の段落を繰り返し処理してテキストを取得します
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
if (m > 0 && m < cell.getParagraphs().getCount() - 1) {
cellText += paragraph.getText() + "\n";
} else {
cellText += paragraph.getText();
}
// セルのテキストを対応するワークシートのセルに書き込みます
sheet.getRange().get(k + 1, l + 1).setValue(cellText);
}
// 列の自動調整を行います
sheet.autoFitColumn(l + 1);
}
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
// Excelファイルとして保存します
workbook.saveToFile("output/WordTableToExcel.xlsx", FileFormat.Version2016);
workbook.dispose();
}
}
一時ライセンスを申請する
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





