チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Word で入力可能なフォームを作成すると、他のユーザーが簡単に入力・カスタマイズできる文書を設計できます。情報収集、フィードバックの取得、インタラクティブな文書の作成など、入力可能なフォームを使用することで、データを電子的に効率よく取得できます。テキスト フィールド、チェック ボックス、ドロップダウン リストなどの要素を追加することで、目的に応じたフォームを作成できます。
Word で入力可能なフォームを作成するには、次のツールを使用します。
Word のコンテンツ コントロールは、文書内の内容を整理するためのコンテナーとして機能し、構造化された文書を作成できます。Word 2013 では 10 種類のコンテンツ コントロールが提供されています。本記事では、Spire.Doc for Python を使用して、一般的に利用される 7 種類のコンテンツ コントロールを含む入力可能なフォームの作成方法を紹介します。
| コンテンツ コントロール | 説明 |
| テキスト(プレーン テキスト) | 書式設定が適用できないプレーン テキスト フィールド。 |
| リッチ テキスト | 書式付きテキストや表、画像、他のコンテンツ コントロールを含められるテキスト フィールド。 |
| 画像 | 1 つの画像を挿入可能。 |
| ドロップダウン リスト | 事前に定義されたリストから選択できるドロップダウン リスト。 |
| コンボ ボックス | 事前に定義されたリストから選択するか、ユーザーが独自の値を入力できるテキスト ボックス付きのコントロール。 |
| チェック ボックス | ユーザーが「はい(チェックあり)」または「いいえ(チェックなし)」を選択できるチェック ボックス。 |
| 日付選択 | ユーザーがカレンダー コントロールから日付を選択できるコントロール。 |
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python では、StructureDocumentTagInline クラスを使用して、段落内に構造化ドキュメント タグを作成できます。このクラスの SDTProperties プロパティと SDTContent プロパティを利用することで、構造化ドキュメント タグのプロパティや内容を定義できます。以下に、Python を使用して Word 文書に入力可能なフォームを作成する手順を示します。
from spire.doc import *
# Document オブジェクトを作成
doc = Document()
# セクションを追加
section = doc.AddSection()
section.PageSetup.Margins.Top = 60
# テーブルを追加
table = section.AddTable(True)
table.ResetCells(7, 2)
table.SetColumnWidth(0, 120, CellWidthType.Point)
table.SetColumnWidth(1, 350, CellWidthType.Point)
# 1列目のセルにテキストを追加
paragraph = table.Rows[0].Cells[0].AddParagraph()
paragraph.AppendText("氏名")
paragraph = table.Rows[1].Cells[0].AddParagraph()
paragraph.AppendText("プロフィール")
paragraph = table.Rows[2].Cells[0].AddParagraph()
paragraph.AppendText("写真")
paragraph = table.Rows[3].Cells[0].AddParagraph()
paragraph.AppendText("国籍")
paragraph = table.Rows[4].Cells[0].AddParagraph()
paragraph.AppendText("趣味")
paragraph = table.Rows[5].Cells[0].AddParagraph()
paragraph.AppendText("生年月日")
paragraph = table.Rows[6].Cells[0].AddParagraph()
paragraph.AppendText("性別")
# (0,1) のセルにプレーンテキストのコンテンツコントロールを追加
paragraph = table.Rows[0].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.Text
sdt.SDTProperties.Alias = "プレーンテキスト"
sdt.SDTProperties.Tag = "プレーンテキスト"
sdt.SDTProperties.IsShowingPlaceHolder = True
text = SdtText(True)
text.IsMultiline = False
sdt.SDTProperties.ControlProperties = text
textRange = TextRange(doc)
textRange.Text = "ここに氏名を入力"
sdt.SDTContent.ChildObjects.Add(textRange)
# (1,1) のセルにリッチテキストのコンテンツコントロールを追加
paragraph = table.Rows[1].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.RichText
sdt.SDTProperties.Alias = "リッチテキスト"
sdt.SDTProperties.Tag = "リッチテキスト"
sdt.SDTProperties.IsShowingPlaceHolder = True
text = SdtText(True)
text.IsMultiline = False
sdt.SDTProperties.ControlProperties = text
textRange = TextRange(doc)
textRange.Text = "自己紹介を簡単に入力"
sdt.SDTContent.ChildObjects.Add(textRange)
# (2,1) のセルに画像コンテンツコントロールを追加
paragraph = table.Rows[2].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.Picture
sdt.SDTProperties.Alias = "画像"
sdt.SDTProperties.Tag = "画像"
sdtPicture = SdtPicture(True)
sdt.SDTProperties.ControlProperties = sdtPicture
pic = DocPicture(doc)
pic.LoadImage("G:/Documents/Holder.png")
sdt.SDTContent.ChildObjects.Add(pic)
# (3,1) のセルにドロップダウンリストのコンテンツコントロールを追加
paragraph = table.Rows[3].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
sdt.SDTProperties.SDTType = SdtType.DropDownList
sdt.SDTProperties.Alias = "ドロップダウンリスト"
sdt.SDTProperties.Tag = "ドロップダウンリスト"
paragraph.ChildObjects.Add(sdt)
stdList = SdtDropDownList()
stdList.ListItems.Add(SdtListItem("アメリカ", "1"))
stdList.ListItems.Add(SdtListItem("日本", "2"))
stdList.ListItems.Add(SdtListItem("ブラジル", "3"))
stdList.ListItems.Add(SdtListItem("オーストラリア", "4"))
sdt.SDTProperties.ControlProperties = stdList
textRange = TextRange(doc)
textRange.Text = stdList.ListItems[0].DisplayText
sdt.SDTContent.ChildObjects.Add(textRange)
# (4,1) のセルにチェックボックスのコンテンツコントロールを2つ追加
paragraph = table.Rows[4].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.CheckBox
sdtCheckBox = SdtCheckBox()
sdt.SDTProperties.ControlProperties = sdtCheckBox
textRange = TextRange(doc)
sdt.ChildObjects.Add(textRange)
sdtCheckBox.Checked = False
paragraph.AppendText(" 映画")
paragraph = table.Rows[4].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.CheckBox
sdtCheckBox = SdtCheckBox()
sdt.SDTProperties.ControlProperties = sdtCheckBox
textRange = TextRange(doc)
sdt.ChildObjects.Add(textRange)
sdtCheckBox.Checked = False
paragraph.AppendText(" ゲーム")
# (5,1) のセルに日付ピッカーのコンテンツコントロールを追加
paragraph = table.Rows[5].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.DatePicker
sdt.SDTProperties.Alias = "日付選択"
sdt.SDTProperties.Tag = "日付選択"
stdDate = SdtDate()
stdDate.CalendarType = CalendarType.Default
stdDate.DateFormat = "yyyy.MM.dd"
stdDate.FullDate = DateTime.get_Now()
sdt.SDTProperties.ControlProperties = stdDate
textRange = TextRange(doc)
textRange.Text = "生年月日を入力"
sdt.SDTContent.ChildObjects.Add(textRange)
# (6,1) のセルにコンボボックスのコンテンツコントロールを追加
paragraph = table.Rows[6].Cells[1].AddParagraph()
sdt = StructureDocumentTagInline(doc)
paragraph.ChildObjects.Add(sdt)
sdt.SDTProperties.SDTType = SdtType.ComboBox
sdt.SDTProperties.Alias = "コンボボックス"
sdt.SDTProperties.Tag = "コンボボックス"
stdComboBox = SdtComboBox()
stdComboBox.ListItems.Add(SdtListItem("男性"))
stdComboBox.ListItems.Add(SdtListItem("女性"))
sdt.SDTProperties.ControlProperties = stdComboBox
textRange = TextRange(doc)
textRange.Text = stdComboBox.ListItems[0].DisplayText
sdt.SDTContent.ChildObjects.Add(textRange)
# 段落スタイルを作成して適用する
style = ParagraphStyle(doc)
style.Name = "本文"
style.CharacterFormat.FontName = "Yu Gothic UI"
style.CharacterFormat.FontSize = 12
doc.Styles.Add(style)
for i in range(7):
for j in range(2):
table.Rows[i].Cells[j].Paragraphs[0].ApplyStyle(style.Name)
# フォームフィールドのみ編集を許可
doc.Protect(ProtectionType.AllowOnlyFormFields, "permission-psd")
# ファイルに保存
doc.SaveToFile("output/記入可能フォーム.docx", FileFormat.Docx2019)
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word の検索と置換機能は、文書内のテキストを効率的に更新するための便利な手段です。手作業による検索や編集の手間を省き、文書全体の対象テキストを一括で置換できます。これにより、作業時間を短縮できるだけでなく、すべての該当箇所が確実に更新されるため、一貫性のある修正が可能です。本記事では、Spire.Doc for Python を使用して、Python で Word 文書内のテキストを検索して置換する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocDocument.Replace() メソッドを使用すると、特定のテキストを検索し、そのすべての該当箇所を別のテキストに置換できます。詳細な手順は以下のとおりです。
from spire.doc import Document
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample.docx")
# 指定したテキストを検索し、すべての出現箇所を別のテキストに置換します
document.Replace("ビタミン", "Vitamin ", False, True)
# 置換後の文書を保存します
document.SaveToFile("output/すべての検索と置換.docx")
document.Close()
Spire.Doc for Python では、Document.ReplaceFirst プロパティを使用することで、すべての該当箇所ではなく、最初の該当箇所のみを置換するモードに変更できます。以下の手順で、最初の該当箇所のみを置換する方法を説明します。
from spire.doc import Document
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample.docx")
# 置換モードを最初の一致のみ置換するように設定します
document.ReplaceFirst = True
# 指定したテキストの最初の出現箇所を別のテキストに置換します
document.Replace("ビタミン", "Vitamin ", False, True)
# 置換後の文書を保存します
document.SaveToFile("output/最初の一致の検索と置換.docx")
document.Close()
Document.Replace() メソッドに Regex オブジェクトと新しいテキストを渡すことで、正規表現に一致するテキストを置換できます。詳細な手順は以下のとおりです。
from spire.doc import Document, Regex
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample1.docx")
# 先頭が # のテキストに一致する正規表現を作成します
regex = Regex(r"ORD-\d{8}")
# 正規表現に一致するテキストを検索し、別のテキストに置換します
document.Replace(regex, "ORD-[注文ID]")
# 文書を保存します
document.SaveToFile("output/正規表現での検索と置換.docx")
document.Close()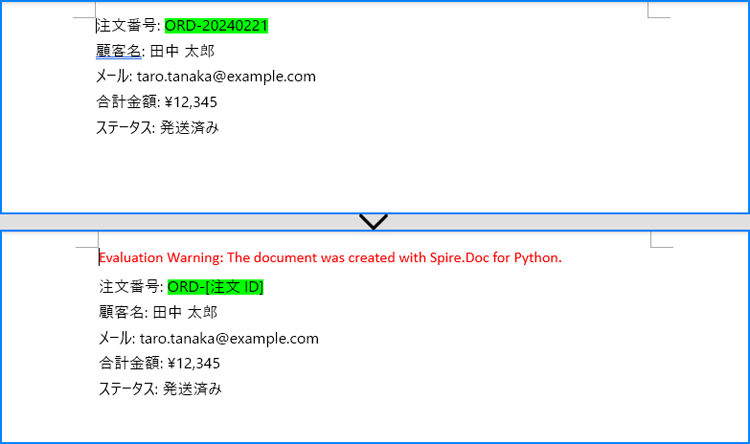
Spire.Doc for Python には、テキストを直接画像に置換するメソッドはありませんが、テキストの位置に画像を挿入し、その後テキストを削除することで実現できます。詳細な手順は以下のとおりです。
from spire.doc import Document, DocPicture
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample2.docx")
# 文書内の指定したテキストを検索します
selections = document.FindAllString("image_laptop", True, True)
index = 0
testRange = None
# 検索結果をループ処理します
for selection in selections:
# 画像を読み込みます
pic = DocPicture(document)
pic.LoadImage("Laptop.jpg")
# 検索されたテキストを単一のテキスト範囲として取得します
testRange = selection.GetAsOneRange()
# テキスト範囲が属する段落内のインデックスを取得します
index = testRange.OwnerParagraph.ChildObjects.IndexOf(testRange)
# 指定したインデックスに画像を挿入します
testRange.OwnerParagraph.ChildObjects.Insert(index, pic)
# テキスト範囲を削除します
testRange.OwnerParagraph.ChildObjects.Remove(testRange)
# 変更後の文書を保存します
document.SaveToFile("output/テキストを検索して画像に置き換える.docx")
document.Close()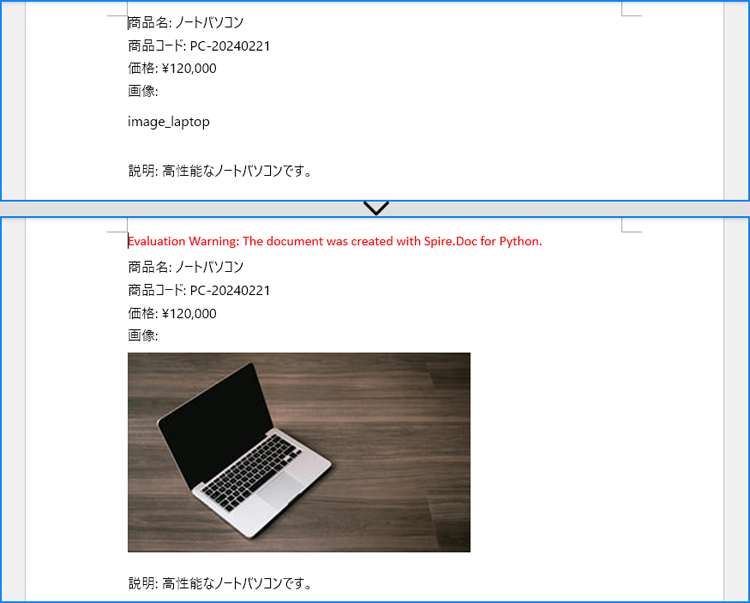
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書からテキストを抽出すると、文書内の記述情報を簡単に取得できます。これにより、テキストの操作、分析、整理が容易になり、テキストマイニング、感情分析、自然言語処理などの作業を実行できます。一方、画像を抽出すると、Word 文書に埋め込まれた視覚要素にアクセスでき、画像認識、コンテンツ抽出、画像データベースの作成などの作業に役立ちます。本記事では、Spire.Doc for Python を使用して、Python で Word 文書からテキストと画像を抽出する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.Docセクション内の特定の段落を取得するには、Section.Paragraphs[index] プロパティを使用します。その後、Paragraph.Text プロパティを使用して、段落のテキストを取得できます。詳細な手順は以下のとおりです。
from spire.doc import Document
# Document オブジェクトを作成します
doc = Document()
# Word 文書を読み込みます
doc.LoadFromFile("Sample.docx")
# 指定したセクションを取得します
section = doc.Sections.get_Item(0)
# 指定した段落を取得します
paragraph = section.Paragraphs.get_Item(1)
# 段落のテキストを取得します
str = paragraph.Text
# 結果を出力します
print(str)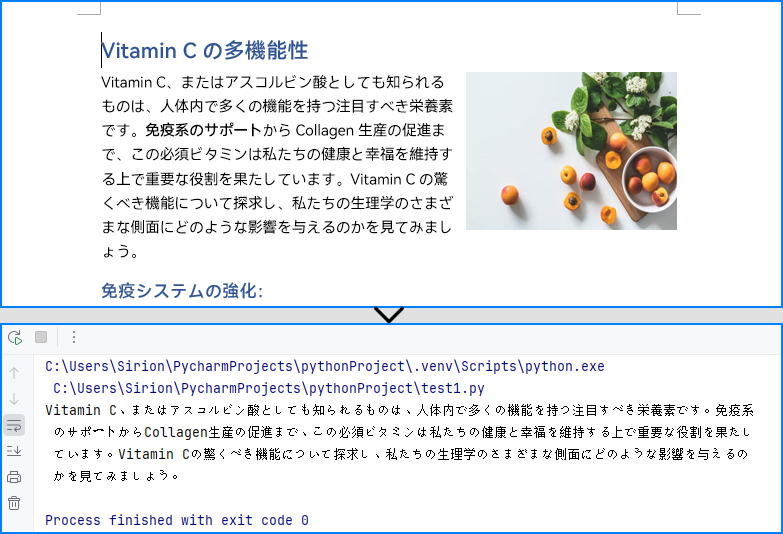
文書全体のテキストを取得する場合は、Document.GetText() メソッドを使用することで簡単に取得できます。手順は以下のとおりです。
from spire.doc import Document
# Document オブジェクトを作成します
doc = Document()
# Word ファイルを読み込みます
doc.LoadFromFile("Sample.docx")
# 文書全体のテキストを取得します
docText = doc.GetText()
# 結果を出力します
print(docText)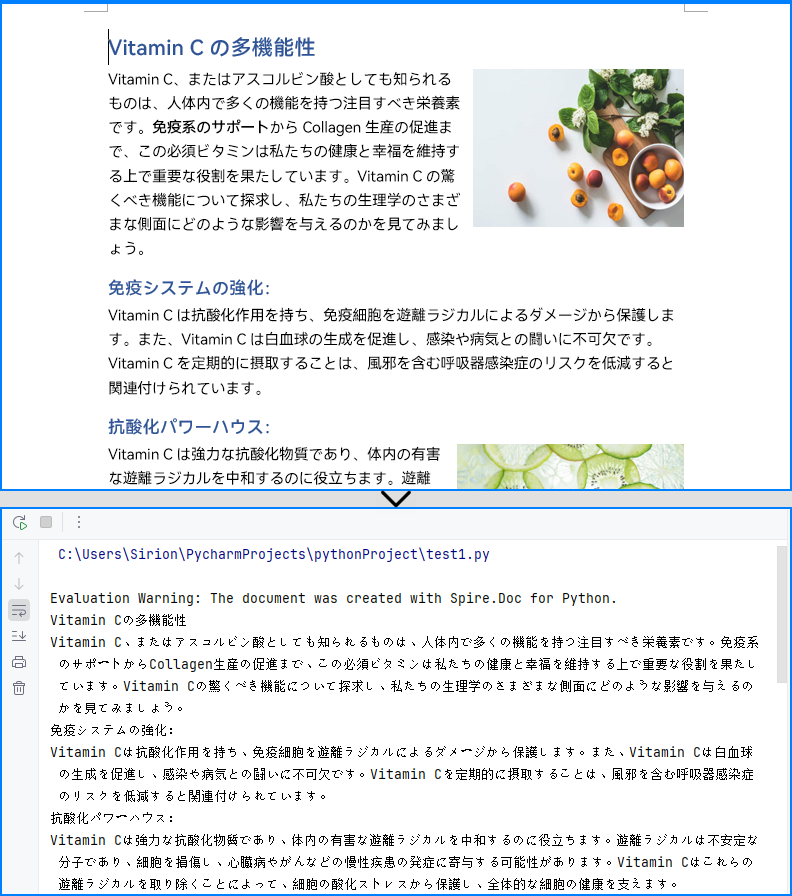
Spire.Doc for Python には、Word 文書から画像を直接取得するメソッドはありません。そのため、文書内の子オブジェクトを走査し、それぞれのオブジェクトが DocPicture であるかを判定する必要があります。DocPicture である場合、DocPicture.ImageBytes プロパティを使用して画像データを取得し、一般的な画像フォーマットで保存できます。主な手順は以下のとおりです。
import queue
from spire.doc import Document, DocumentObjectType, DocPicture, ICompositeObject
# Document オブジェクトを作成します
doc = Document()
# Word ファイルを読み込みます
doc.LoadFromFile("Sample.docx")
# Queue オブジェクトを作成します
nodes = queue.Queue()
nodes.put(doc)
# リストを作成します
images = []
while nodes.qsize() > 0:
node = nodes.get()
# 文書内の子オブジェクトをループ処理します
for i in range(node.ChildObjects.Count):
child = node.ChildObjects.get_Item(i)
# 子オブジェクトが画像かどうかを判定します
if child.DocumentObjectType == DocumentObjectType.Picture:
picture = child if isinstance(child, DocPicture) else None
dataBytes = picture.ImageBytes
# 画像データをリストに追加します
images.append(dataBytes)
elif isinstance(child, ICompositeObject):
nodes.put(child if isinstance(child, ICompositeObject) else None)
# リスト内の画像をループ処理します
for i, item in enumerate(images):
fileName = "Image-{}.png".format(i)
with open("output/抽出した画像/" + fileName, 'wb') as imageFile:
# 指定したパスに画像を書き込みます
imageFile.write(item)
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
カスタムドキュメントプロパティは、Word 文書内にユーザーが定義できるメタデータフィールドです。タイトル、作成者、件名などの標準プロパティとは異なり、カスタムプロパティはユーザーが独自の要件に応じて柔軟に管理できます。本記事では、Spire.Doc for Python を使用して、Word 文書のカスタムプロパティを追加、取得、削除する方法を解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python では、CustomDocumentProperties.Add() メソッドを使用して、カスタムプロパティにテキスト、日時、数値、Yes/No などの異なる種類の値を設定できます。
以下の手順でカスタムプロパティを追加します。
Python
from spire.doc import Document, String, Int32, DateTime, Boolean
# Documentオブジェクトを作成
document = Document()
# Word文書を読み込む
document.LoadFromFile("Sample.docx")
# 文書に異なる型のカスタムプロパティを追加
customProperties = document.CustomDocumentProperties
customProperties.Add("文書カテゴリ", String("技術報告書"))
customProperties.Add("改訂番号", Int32(5))
customProperties.Add("最終レビュー日", DateTime(2024, 12, 1, 0, 0, 0, 0))
customProperties.Add("フォローアップ必要", Boolean(False))
# 文書を保存
document.SaveToFile("output/カスタムプロパティの追加.docx")
document.Close()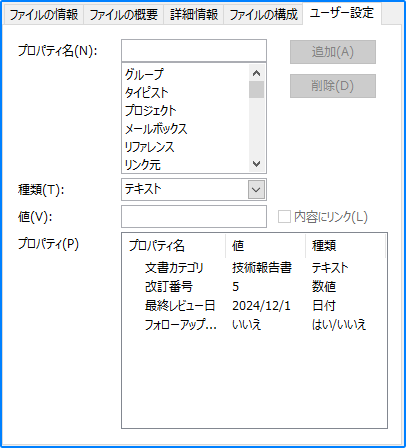
カスタムプロパティを取得することで、メタデータを分析やレポート作成、他のアプリケーションとの統合に活用できます。Spire.Doc for Python を使用すると、CustomDocumentProperty.Name および CustomDocumentProperty.Value プロパティを使って簡単に取得できます。
以下の手順でカスタムプロパティを取得します。
from spire.doc import Document
# Documentオブジェクトを作成
document = Document()
# Word文書を読み込む
document.LoadFromFile("output/カスタムプロパティの追加.docx")
# カスタムプロパティを抽出してテキストファイルに保存
with open("output/取得したカスタムプロパティ.txt", "w", encoding="utf-8") as output_file:
# すべてのカスタムプロパティを繰り返し処理
for i in range(document.CustomDocumentProperties.Count):
# 各カスタムプロパティの名前と値を取得
property_name = document.CustomDocumentProperties.get_Item(i).Name
property_value = document.CustomDocumentProperties.get_Item(i).ToString()
# プロパティの詳細をテキストファイルに書き込む
output_file.write(f"{property_name}: {property_value}\n")
document.Close()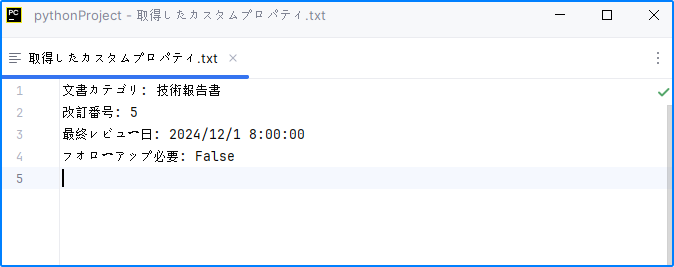
カスタムプロパティを削除することで、機密情報の保護、ファイルサイズの削減、不要なメタデータの整理が可能になります。Spire.Doc for Python を使用すると、DocumentProperties.Remove() メソッドでカスタムプロパティを削除できます。
以下の手順でカスタムプロパティを削除します。
from spire.doc import Document
# Documentオブジェクトを作成
document = Document()
# Word文書を読み込む
document.LoadFromFile("output/カスタムプロパティの追加.docx")
# すべてのカスタムプロパティを削除
customProperties = document.CustomDocumentProperties
for i in range(customProperties.Count - 1, -1, -1):
# 各カスタムプロパティを名前で削除
customProperties.Remove(customProperties[i].Name)
# 文書を保存
document.SaveToFile("output/カスタムプロパティの削除.docx")
document.Close()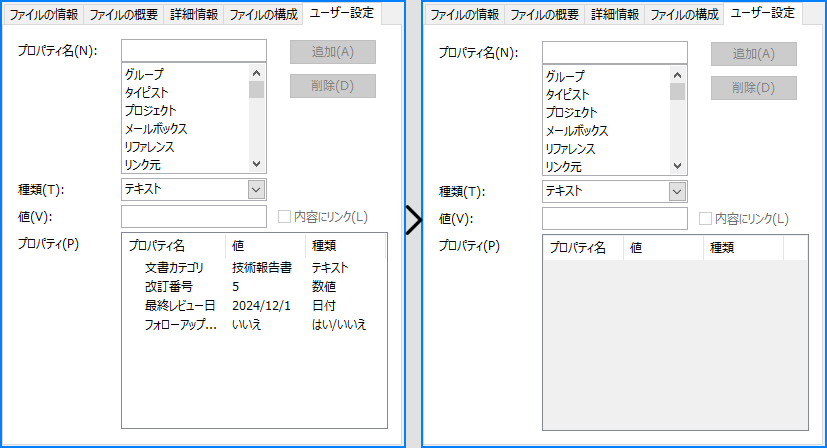
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書には、タイトル、作成者、件名、キーワードなどの情報を含むメタデータとして「ドキュメントプロパティ」が存在します。これらのプロパティを適切に管理することで、文書の整理、検索性の向上、共同作業における適切な情報付与が可能になります。Spire.Doc for Python を使用すると、Word 文書のドキュメントプロパティを自動的に追加、読み取り、削除でき、ドキュメント管理のワークフローを効率化し、より大規模な自動化システムとの統合を容易にします。本記事では、Spire.Doc for Python を用いたドキュメントプロパティの管理方法について、具体的な手順とコード例を交えて解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python では、Document.BuiltinDocumentProperties プロパティを使用して、Word 文書の組み込みプロパティにアクセスできます。これらのプロパティの値は、BuiltinDocumentProperties クラスの対応するプロパティを設定することで変更可能です。
以下の手順で、Word 文書の主要な組み込みプロパティを追加できます。
from spire.doc import Document
# Documentオブジェクトの作成
doc = Document()
# Word文書の読み込み
doc.LoadFromFile("Sample.docx")
# 組み込みプロパティの設定
builtinProperty = doc.BuiltinDocumentProperties
builtinProperty.Title = "人工知能の革命"
builtinProperty.Subject = "人工知能におけるニューラルネットワークの高度な応用と未来の方向性"
builtinProperty.Author = "サイモン"
builtinProperty.Manager = "アリエ"
builtinProperty.Company = "AIリサーチラボ"
builtinProperty.Category = "研究"
builtinProperty.Keywords = "機械学習、ニューラルネットワーク、人工知能"
builtinProperty.Comments = "この論文は人工知能の最前線に関するものです。"
builtinProperty.HyperLinkBase = "www.e-iceblue.com"
# 文書の保存
doc.SaveToFile("output/プロパティの追加.docx")
doc.Close()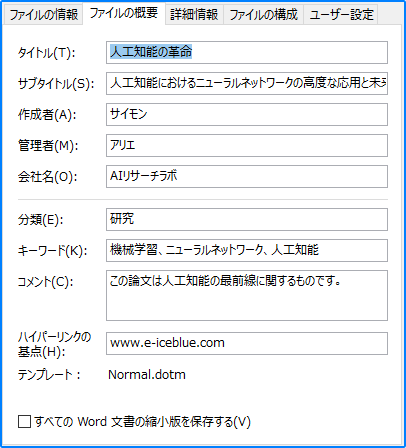
BuiltinDocumentProperties クラスのプロパティを利用すると、Word 文書に既に設定されている組み込みプロパティを読み取ることができます。これにより、ドキュメントの検索、情報抽出、文書分析などの機能を実装可能です。
以下の手順で、Word 文書の組み込みプロパティを取得できます。
from spire.doc import Document
# Documentオブジェクトの作成
doc = Document()
# Word文書の読み込み
doc.LoadFromFile("output/プロパティの追加.docx")
# 文書の組み込みプロパティを取得
builtinProperties = doc.BuiltinDocumentProperties
# 組み込みプロパティの値を取得
properties = [
"作成者: " + builtinProperties.Author,
"会社: " + builtinProperties.Company,
"タイトル: " + builtinProperties.Title,
"件名: " + builtinProperties.Subject,
"キーワード: " + builtinProperties.Keywords,
"カテゴリ: " + builtinProperties.Category,
"管理者: " + builtinProperties.Manager,
"コメント: " + builtinProperties.Comments,
"ハイパーリンクベース: " + builtinProperties.HyperLinkBase,
"単語数: " + str(builtinProperties.WordCount),
"ページ数: " + str(builtinProperties.PageCount),
]
# 組み込みプロパティを出力
for i in range(0, len(properties)):
print(properties[i])
doc.Close()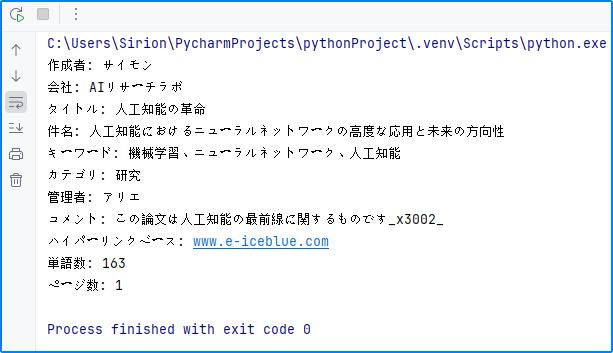
Word 文書の組み込みドキュメントプロパティの中で特定の内容を持つものは、値を None に設定することで削除できます。これにより、不要な情報を削除しながら、必要なデータを保持することが可能になります。
以下の手順で、Word 文書の特定の組み込みプロパティを削除できます。
from spire.doc import Document
# Documentクラスのインスタンスを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("output/プロパティの追加.docx")
# 文書の組み込みプロパティを取得
builtinProperties = doc.BuiltinDocumentProperties
# 組み込みプロパティを削除(Noneを設定)
builtinProperties.Author = None
builtinProperties.Company = None
builtinProperties.Title = None
builtinProperties.Subject = None
builtinProperties.Keywords = None
builtinProperties.Comments = None
builtinProperties.Category = None
builtinProperties.Manager = None
# 文書を保存
doc.SaveToFile("output/プロパティの削除.docx")
doc.Close()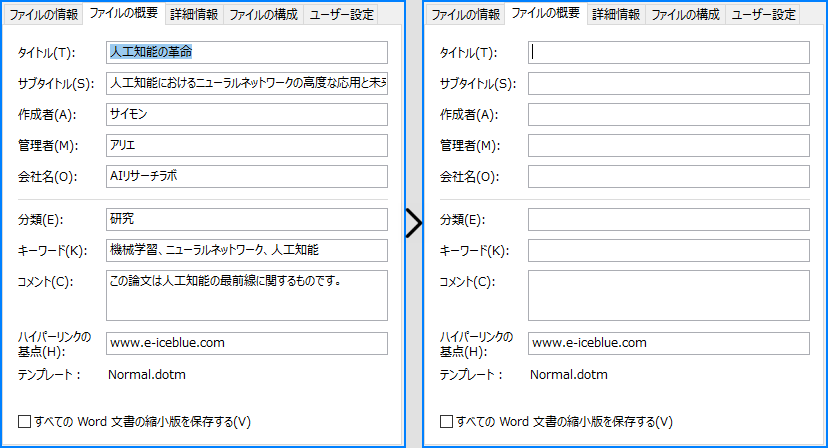
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
差し込み印刷は、膨大な数の受取人に対してパーソナライズされた文書を効率的に作成するための強力なツールです。差し込み印刷を使用することで、ユーザーはテンプレート文書とデータソースを自動的に統合し、各受取人に合わせたパーソナライズされたプロフェッショナルな文書を迅速に作成できます。これにより、個別のメール送信、請求書の作成、カスタマイズされたマーケティング資料の作成などのタスクを効率化できます。本記事では、Spire.Doc for Python を使用して、Python コードで Word 文書内で差し込み印刷を作成および実行する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocWord 文書での差し込み印刷には、差し込みフィールドの使用が含まれます。Spire.Doc for Python では、Paragraph.AppendField(str: fieldName, FieldType.FieldMergeField) メソッドを提供しており、ユーザーは文書内の指定された段落に効率的に差し込みフィールドを作成できます。この機能により、ユーザーは後でパーソナライズされた情報を入力することで、特定の受取人向けの文書を迅速に生成できます。
Word文書に差し込みフィールドを作成するための詳細な手順は以下の通りです:
from spire.doc import Document, FieldType
# Documentクラスのオブジェクトを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("Sample.docx")
# セクションを取得
section = doc.Sections.get_Item(1)
# メールマージフィールドを追加するための段落を取得
para1 = section.Paragraphs.get_Item(0)
para2 = section.Paragraphs.get_Item(1)
para3 = section.Paragraphs.get_Item(2)
para4 = section.Paragraphs.get_Item(3)
# メールマージフィールドを追加し、フィールド名を指定
para1.AppendField("名前", FieldType.FieldMergeField)
para2.AppendField("年齢", FieldType.FieldMergeField)
para3.AppendField("電話番号", FieldType.FieldMergeField)
para4.AppendField("会員種別", FieldType.FieldMergeField)
# 文書を保存
doc.SaveToFile("output/差し込み印刷フィールドの作成.docx")
doc.Close()
差し込み印刷を作成した後は、MailMerge.Execute(List: fieldNames, List: dataSource) メソッドを使用して文書内で差し込み印刷を実行できます。これにより、指定されたデータソースに基づいて、個別の内容を含む複数の Word 文書を迅速に生成できます。
差し込み印刷を実行してパーソナライズされた文書を生成するための詳細な手順は以下の通りです:
from spire.doc import Document
# データソースを指定(日本語のデータ)
dataSource = member_data = [
["佐藤 太郎", "30", "+81-90-1234-5678", "プレミアム"],
["鈴木 次郎", "40", "+81-80-2345-6789", "スタンダード"],
["高橋 三郎", "25", "+44-70-3456-7890", "ベーシック"],
]
# データソースをループ
for i in range(len(dataSource)):
# Documentのインスタンスを作成
doc = Document()
# メールマージフィールドを含むWord文書を読み込む
doc.LoadFromFile("output/差し込み印刷フィールドの作成.docx")
# マージフィールド名を取得
fieldNames = doc.MailMerge.GetMergeFieldNames()
# メールマージを実行
doc.MailMerge.Execute(fieldNames, dataSource[i])
# 文書を保存
doc.SaveToFile(f"output/Members/Member-{dataSource[i][0]}.docx")
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
長文の Word 文書では、効率的な文書の整理とナビゲーションが重要です。文書の可読性とアクセス性を向上させる強力な方法の一つが、目次(TOC)を挿入することです。これにより、読者は特定のセクションを迅速に見つけて、関連する内容に簡単にジャンプすることができます。Python の機能を活用することで、文書が進化する際に動的に更新される目次を簡単に作成できます。
本記事では、Spire.Doc for Python を使用して Python プログラムで Word 文書に目次を挿入する方法を、ステップバイステップで解説し、プロフェッショナルな見た目の文書を簡単に作成できるようにします。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python は、異なるレベルの見出しに基づいて Word 文書に目次を挿入する機能をサポートしています。文書に見出しレベルが設定されていない場合、開発者は Paragraph.ApplyStyle(BuiltinStyle) メソッドを使用して見出しレベルを設定した後に目次を挿入することができます。
Paragraph.AppendTOC(lowerLevel: int, upperLevel: int) メソッドを使用することで、任意の段落に目次を挿入し、表示するタイトルを指定することができます。目次を挿入した後、目次の内容が正しく表示されるように、Document.UpdateTableOfContents() メソッドを使用して目次を更新することが重要です。
以下の手順で目次を挿入できます:
from spire.doc import Document
# Documentクラスのオブジェクトを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("Sample.docx")
# 目次用のセクションを作成
section = doc.AddSection()
# セクションに段落を追加
paragraph = section.AddParagraph()
# 段落に目次を追加(レベル1からレベル2)
paragraph.AppendTOC(1, 2)
# カバーセクションの後にセクションを挿入
doc.Sections.Insert(1, section)
# 目次を更新
doc.UpdateTableOfContents()
# 文書を保存
doc.SaveToFile("output/デフォルトの目次.docx")
doc.Close()
開発者は、TableOfContent オブジェクトを初期化することで目次を作成し、スイッチを使用してカスタマイズすることもできます。例えば、スイッチ「{\o \"1-2\" \n 1-1}」は、目次にレベル 1 からレベル 3 までの見出しを表示し、レベル 1 の見出しにはページ番号を表示しないように指定します。カスタマイズされた目次を Word 文書に挿入する手順は以下の通りです:
from spire.doc import Document, TableOfContent, FieldMarkType
# Documentクラスのオブジェクトを作成し、Word文書を読み込む
doc = Document()
doc.LoadFromFile("Sample.docx")
# セクションと段落を追加し、カバーセクションの後にセクションを挿入
section = doc.AddSection()
paragraph = section.AddParagraph()
doc.Sections.Insert(1, section)
# スイッチを使って目次をカスタマイズ
toc = TableOfContent(doc, "{\\o \"1-2\" \\n 1-1}")
# 段落に目次を挿入
paragraph.Items.Add(toc)
# 目次フィールドのセパレータと終了マークを挿入
paragraph.AppendFieldMark(FieldMarkType.FieldSeparator)
paragraph.AppendFieldMark(FieldMarkType.FieldEnd)
# ドキュメントの目次フィールドを設定
doc.TOC = toc
# 目次を更新
doc.UpdateTableOfContents()
# 文書を保存
doc.SaveToFile("output/カスタムの目次.docx")
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
大量の Word 文書を扱うのは非常に大変です。編集やレビューを行う際に、多くの文書を開閉するだけで多くの時間が浪費されます。さらに、多数の Word 文書を個別に共有・受信するのは煩雑で、送信者と受信者の両方にとって繰り返しの操作が必要になります。そのため、効率を向上させ、時間を節約するために、関連する Word 文書を 1 つのファイルに結合するのが望ましいです。本記事では、Spire.Doc for Python を使用して、Python プログラムで簡単に Word 文書を結合する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocDocument.insertTextFromFile() メソッドを使用すると、他の Word 文書を現在の文書に挿入できます。このメソッドを使用すると、挿入された内容は新しいページから開始されます。ファイルの挿入による Word 文書の結合手順は以下のとおりです。
from spire.doc import Document, FileFormat
# Document クラスのオブジェクトを作成し、Word 文書を読み込む
doc = Document()
doc.LoadFromFile("Sample1.docx")
# 別の Word 文書の内容をこの文書に挿入する
doc.InsertTextFromFile("Sample2.docx", FileFormat.Auto)
# 文書を保存する
doc.SaveToFile("output/ドキュメントの挿入.docx")
doc.Close()
Word 文書の結合は、ある文書の内容を別の文書にクローン(複製)する方法でも実現できます。この方法では、元の文書の書式を保持し、クローンされた内容は新しいページを作成せずに既存の文書の末尾に追加されます。具体的な手順は以下のとおりです。
from spire.doc import Document
# Document クラスのオブジェクトを 2 つ作成し、2 つの Word 文書を読み込む
doc1 = Document()
doc1.LoadFromFile("Sample1.docx")
doc2 = Document()
doc2.LoadFromFile("Sample2.docx")
# 最初の文書の最後のセクションを取得する
lastSection = doc1.Sections.get_Item(doc1.Sections.Count - 1)
# 2 つ目の文書のセクションを順番に処理する
for i in range(doc2.Sections.Count):
section = doc2.Sections.get_Item(i)
# セクション内の子オブジェクトを順番に処理する
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
# 2 つ目の文書の子オブジェクトを最初の文書の最後のセクションに追加する
lastSection.Body.ChildObjects.Add(obj.Clone())
# 結果の文書を保存する
doc1.SaveToFile("output/ドキュメント内容のコピー.docx")
doc1.Close()
doc2.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Python を使用して Word 文書を作成、読み込み、更新することは、多くの開発者にとって重要なニーズです。レポートの生成、既存文書の操作、文書作成プロセスの自動化など、Word 文書をプログラムで扱える能力は、生産性と効率の向上に大きく寄与します。本記事では、Spire.Doc for Python を利用して、Python で Word 文書を作成、読み込み、更新する方法を解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python は、Word 文書のモデルを表現するために Document クラスを提供しています。Word 文書は、最低でも 1 つのセクション(Section クラスで表現)を含み、各セクションは段落、表、グラフ、画像などさまざまな要素を格納するコンテナとして機能します。以下の手順では、Spire.Doc for Python を使って複数の段落を含むシンプルな Word 文書を作成する方法を紹介します。
from spire.doc import Document, FileFormat, BuiltinStyle, ParagraphStyle, HorizontalAlignment
# ドキュメントオブジェクトを作成
doc = Document()
# セクションを追加
section = doc.AddSection()
# ページの余白を設定
section.PageSetup.Margins.All = 40
# タイトルを追加
titleParagraph = section.AddParagraph()
titleParagraph.AppendText("Spire.Doc for Pythonの紹介")
# 2つの段落を追加
bodyParagraph_1 = section.AddParagraph()
bodyParagraph_1.AppendText("Spire.Doc for Pythonは、開発者が任意のPythonアプリケーション内で高速かつ高品質なパフォーマンスでWord文書を作成、読み取り、書き込み、変換、比較、印刷するために設計されたプロフェッショナルなPythonライブラリです。")
bodyParagraph_2 = section.AddParagraph()
bodyParagraph_2.AppendText("独立したWord用Python APIであるSpire.Doc for Pythonは、開発システムやターゲットシステムにMicrosoft Wordがインストールされている必要はありません。しかしながら、どの開発者のPythonアプリケーションにもMicrosoft Wordの文書作成機能を組み込むことが可能です。")
# タイトルに見出し1のスタイルを適用
titleParagraph.ApplyStyle(BuiltinStyle.Heading1)
# 段落用のスタイルを作成
style2 = ParagraphStyle(doc)
style2.Name = "paraStyle"
style2.CharacterFormat.FontName = "Yu Gothic UI"
style2.CharacterFormat.FontSize = 13
doc.Styles.Add(style2)
bodyParagraph_1.ApplyStyle("paraStyle")
bodyParagraph_2.ApplyStyle("paraStyle")
# 段落の水平位置揃えを設定
titleParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
bodyParagraph_1.Format.HorizontalAlignment = HorizontalAlignment.Left
bodyParagraph_2.Format.HorizontalAlignment = HorizontalAlignment.Left
# 段落後の余白を設定
titleParagraph.Format.AfterSpacing = 10
bodyParagraph_1.Format.AfterSpacing = 10
# ファイルに保存
doc.SaveToFile("output/Word文書.docx", FileFormat.Docx2019)
doc.Close()
Word 文書全体のテキストを取得するには、Document.GetText() メソッドを使用します。以下に手順を示します。
from spire.doc import *
from spire.doc.common import *
# Documentオブジェクトを作成
doc = Document()
# Wordファイルを読み込む
doc.LoadFromFile("output/Word文書.docx")
# ドキュメント全体のテキストを取得
text = doc.GetText()
# テキストを出力
print(text)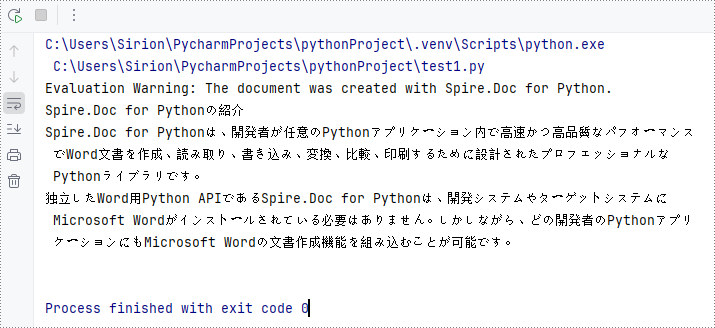
特定の段落にアクセスするには、Section.Paragraphs[index] プロパティを使用します。段落のテキストを変更する場合は、Paragraph.Text プロパティに新しいテキストを再割り当てします。以下の手順に従って操作します。
from spire.doc import *
from spire.doc.common import *
# Document オブジェクトを作成
doc = Document()
# Word ファイルを読み込む
doc.LoadFromFile("output/Word文書.docx")
# 特定のセクションを取得
section = doc.Sections[0]
# 特定の段落を取得
paragraph = section.Paragraphs[1]
# 段落のテキストを変更
paragraph.Text = "タイトルが変更されました"
# ファイルに保存
doc.SaveToFile("output/更新されたWord文書.docx", FileFormat.Docx2019)
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
HTML は Web ページを作成するための標準マークアップ言語であり、PDF は異なるプラットフォーム間で一貫した書式を保持しながらドキュメントを共有・保存するための広く採用されている形式です。HTML を PDF に変換することで、印刷可能なドキュメントを作成したり、Web コンテンツをオフラインで共有したり、レポートを簡単に生成したりできます。本記事では、Spire.Doc for Python を使用して、HTML ファイルや HTML 文字列を PDF に変換する方法を解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocDocument.LoadFromFile() メソッドは、Doc や Docx ファイルだけでなく、HTML ファイルの読み込みにも対応しています。このメソッドを使用して HTML ファイルを読み込み、Document.SaveToFile() メソッドを使用して PDF ファイルとして保存できます。Python で HTML ファイルを PDF に変換する手順は以下のとおりです。
from spire.doc import Document, FileFormat, XHTMLValidationType
# Document のインスタンスを作成する
doc = Document()
# HTMLファイルを読み込む
doc.LoadFromFile("Sample.html", FileFormat.Html, XHTMLValidationType.none)
# PDF形式で保存する
doc.SaveToFile("output/HTMLToPDF.pdf", FileFormat.PDF)
doc.Close()
単純な HTML 文字列(通常はテキストとその書式)を Word ページ上にレンダリングする場合、Paragraph.AppendHTML() メソッドを使用できます。作成した Word ドキュメントは Document.SaveToFile() メソッドで PDF として保存可能です。Python で HTML 文字列を PDF に変換する手順は以下のとおりです。
from spire.doc import Document, FileFormat
# Document のインスタンスを作成する
doc = Document()
# 文書にセクションを追加する
section = doc.AddSection()
# セクションに段落を追加する
paragraph = section.AddParagraph()
# HTML文字列を定義する
htmlString = """
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>哲学的パステル研究</title>
<style>
body {
font-family: 'Yu Gothic', Meiryo, sans-serif;
margin: 0;
padding: 0;
background: linear-gradient(135deg, #f0e6ff, #e0d6ff);
color: #4a4453;
min-height: 100vh;
display: flex;
align-items: center;
justify-content: center;
}
.container {
max-width: 600px;
width: 90%;
background-color: #fff;
border-radius: 12px;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);
margin: 2rem;
padding: 2rem;
}
h1, h2 {
color: #6b5b95;
text-align: center;
margin-bottom: 1rem;
}
.section {
margin: 1.5rem 0;
padding: 1.5rem;
background: linear-gradient(135deg, #faf7ff, #f2eefc);
border-radius: 8px;
transition: transform 0.3s ease, box-shadow 0.3s ease;
}
.section:hover {
transform: translateY(-5px);
box-shadow: 0 6px 15px rgba(0, 0, 0, 0.1);
}
ul {
list-style-type: disc;
padding-left: 1.5rem;
}
p, li {
line-height: 1.6;
}
@media (max-width: 640px) {
.container {
padding: 1.5rem;
}
.section {
padding: 1rem;
}
}
</style>
</head>
<body>
<div class="container">
<h1>色彩形而上学研究所</h1>
<div class="section">
<h2>紫紺色の効果</h2>
<p>紫紺色は時間延長効果を持つとされています。</p>
</div>
<div class="section">
<h2>基本色相分類</h2>
<ul>
<li>アウリウム: 創造性の覚醒</li>
<li>ヴェルディト: 時間知覚の変化</li>
</ul>
</div>
</div>
</body>
</html>
"""
# HTML文字列を文書に挿入する
paragraph.AppendHTML(htmlString)
# 文書をPDF形式で保存する
doc.SaveToFile("output/HTMLStringToPDF.pdf", FileFormat.PDF)
doc.Close()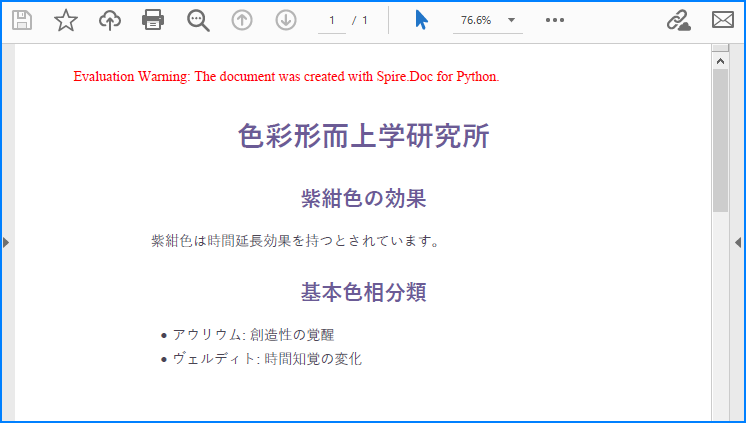
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





