
Python を使って PDF ファイルを読み取ることは、ドキュメントの自動化、コンテンツの分析、データのスクレイピングといった作業において非常に重要です。契約書や報告書、請求書、学術論文など、どのような PDF であっても、その内容にプログラムからアクセスできれば、作業の効率が飛躍的に向上し、より高度なワークフローを構築できます。
PythonでPDFのテキスト、表、画像、メタデータなどを正確に読み取るためには、信頼性の高いPDFリーダーライブラリが必要です。本ガイドでは、サードパーティツールに依存せず、豊富な機能を備えたプロフェッショナルかつ使いやすいライブラリ Spire.PDF for Python を使って、PythonでPDFを読み取る方法をご紹介します。
目次
開発環境の準備
Spire.PDF for Python は、PDFのテキスト、表、画像、メタデータを高精度かつ簡単に読み取ることができるライブラリです。
- ディスクまたはメモリからPDFを読み取り可能
- 表・テキスト・画像・文書情報をすべて取得可能
- 外部ツール不要でスタンドアロン動作
- 精度の高い構造データ抽出
- 無料バージョンもあり
pipを使用したインストール方法:
pip install spire.pdf
小規模なPDF処理を行う場合は、Free Spire.PDF for Python をご利用いただくことも可能です:
pip install spire.pdf.free
PythonでPDFファイルを読み込む方法
PDFファイルの内容を取得する前に、まずメモリ上に読み込む必要があります。Spire.PDF を使えば、ローカルファイルからでも、バイト配列などのメモリ経由でもPDFを簡単に読み込めます。
ファイルパスからPDFを読み込む
PdfDocument.LoadFromFile() を使用して、PDFファイルをローカルから読み込みます。
from spire.pdf import PdfDocument
# PdfDocument のインスタンスを作成します
pdf = PdfDocument()
# PDF ドキュメントを読み込みます
pdf.LoadFromFile("sample.pdf")
メモリ上のバイト配列からPDFを読み込む
API経由で受信したPDFや一時ファイルなど、ディスクに保存せずにバイト配列から直接読み込むには、Stream オブジェクトを使います。
from spire.pdf import PdfDocument, Stream
# PDF ファイルをバイト配列として読み込みます
with open("sample.pdf", "rb") as f:
byte_data = f.read()
# バイト配列を使ってストリームを作成します
pdfStream = Stream(byte_data)
# ストリームを使って PdfDocument を作成します
pdf = PdfDocument(pdfStream)
PDFからテキストを読み取る
PDF内のテキスト情報を抽出することは、文書解析や自動処理における最も基本的な操作です。Spire.PDF を使えば、全体のテキストやページ単位、指定エリアのテキストも簡単に取得できます。
PDF全体のテキストを抽出する
全ページをループし、PdfTextExtractor.ExtractText() を使ってテキストを抽出します。
from spire.pdf import PdfDocument, PdfTextExtractor, PdfTextExtractOptions
# PdfDocument のインスタンスを作成します
pdf = PdfDocument()
# PDF ドキュメントを読み込みます
pdf.LoadFromFile("sample.pdf")
all_text = ""
# 各ページをループ処理します
for pageIndex in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(pageIndex)
# PdfTextExtractor のインスタンスを作成します
text_extractor = PdfTextExtractor(page)
# テキスト抽出オプションを設定します
options = PdfTextExtractOptions()
options.IsExtractAllText = True
options.IsSimpleExtraction = True
# 現在のページからテキストを抽出します
all_text += text_extractor.ExtractText(options)
print(all_text)
サンプルテキストの内容を取得しました:
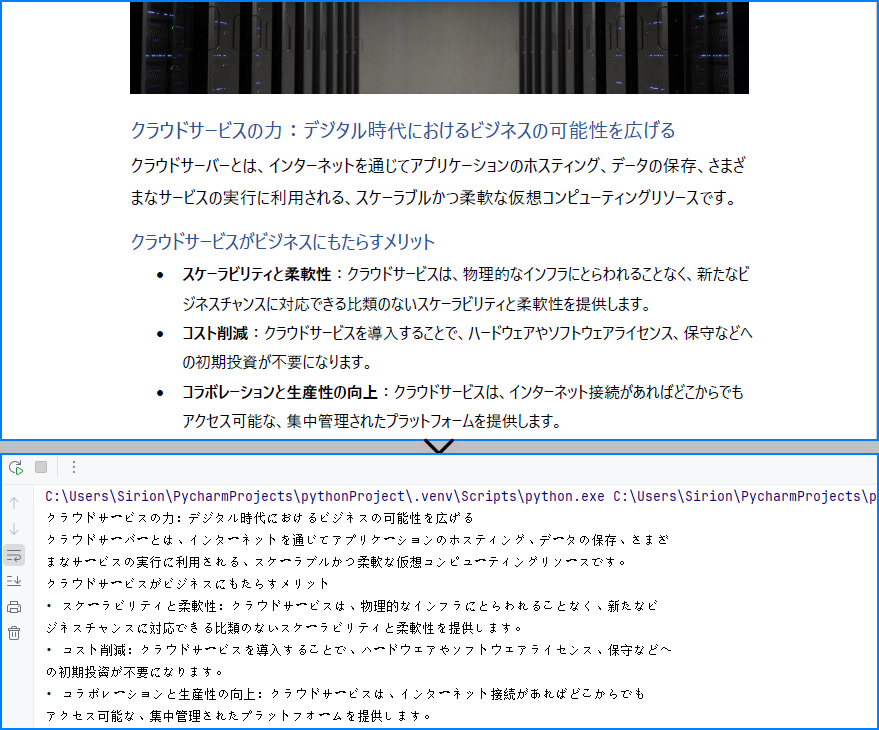
ページ内の特定エリアからテキストを読み取る
領域を指定して、PDFの一部分のみからテキストを取得することも可能です。必要な情報がレイアウトの特定部分にある場合に便利です。
from spire.pdf import RectangleF, PdfDocument, PdfTextExtractor, PdfTextExtractOptions
# PDF ファイルを読み込みます
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# 最初のページを取得します
page = pdf.Pages.get_Item(0)
# PdfTextExtractor のインスタンスを作成します
textExtractor = PdfTextExtractor(page)
# PdfTextExtractOptions を設定してテキスト抽出範囲を指定します
options = PdfTextExtractOptions()
area = RectangleF.FromLTRB(0, 200, page.Size.Width, 250) # x, y, 幅, 高さ
options.ExtractArea = area
options.IsSimpleExtraction = True
# 指定した範囲からテキストを抽出します
text = textExtractor.ExtractText(options)
text = text.split("Spire.PDF for Python.")[1]
print(text)
PDFページの領域から読み込まれたテキスト:
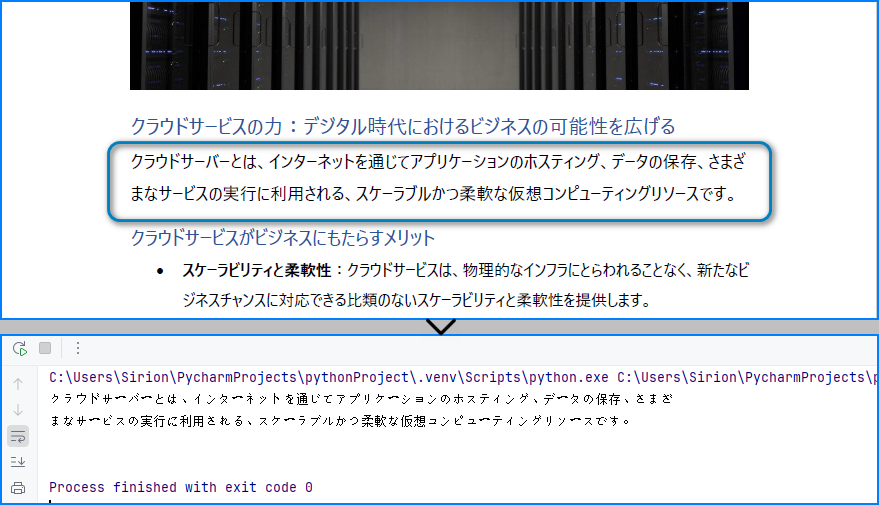
PDFから表データを抽出する
PDFの中には表形式でデータが記載されているケースが多く、特に請求書や明細、帳票などに頻出します。Spire.PDF は、レイアウト構造を認識して表を抽出する機能を持っており、PdfTableExtractor.ExtractTable() を使用して行単位・セル単位の情報を取得できます。
from spire.pdf import PdfDocument, PdfTableExtractor
# PDF ファイルを読み込みます
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# PdfTableExtractor のインスタンスを作成します
table_extractor = PdfTableExtractor(pdf)
# 最初のページから表を抽出します
tables = table_extractor.ExtractTable(0)
for table in tables:
# 行数と列数を取得します
row_count = table.GetRowCount()
column_count = table.GetColumnCount()
# すべての行をループ処理します
for i in range(row_count):
table_row = []
# すべての列をループ処理します
for j in range(column_count):
# セルのテキストを取得します
cell_text = table.GetText(i, j)
table_row.append(cell_text)
print(table_row)
上記のコードを使用して抽出された表の内容:
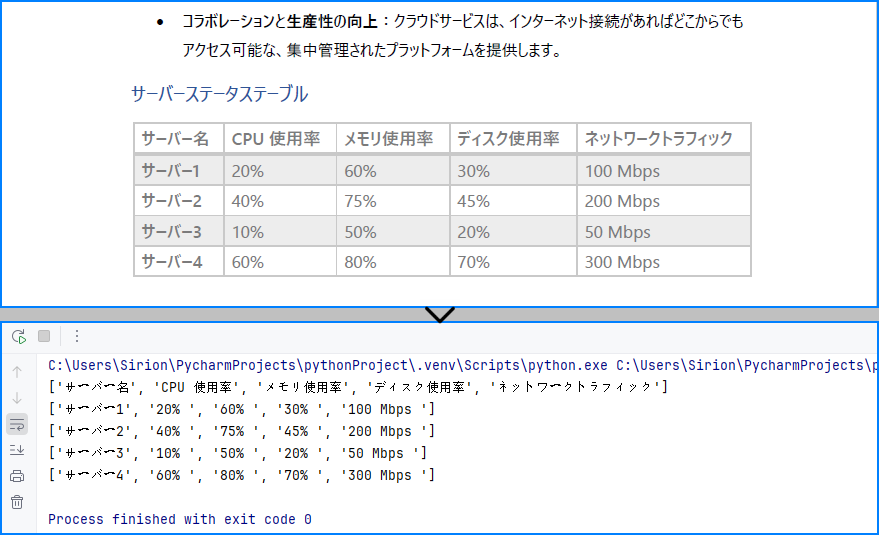
画像ベースのPDFからテーブルを抽出したい場合は、OCRを併用する必要があります:Pythonで画像からテキストを認識する方法
PDFから画像を取得する
PDFにはロゴやスキャン画像などのビジュアル要素が含まれていることがあります。Spire.PDF を使えば、ページに含まれる画像を抽出・保存できます。PdfImageHelper.GetImagesInfo() を使用して各ページの画像情報を取得し、保存します。
from spire.pdf import PdfDocument, PdfImageHelper
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
page = pdf.Pages.get_Item(0)
image_helper = PdfImageHelper()
images_info = image_helper.GetImagesInfo(page)
for i in range(len(images_info)):
images_info[i].Image.Save("output/Images/image" + str(i) + ".png")
PDFファイルから読み込まれた画像:
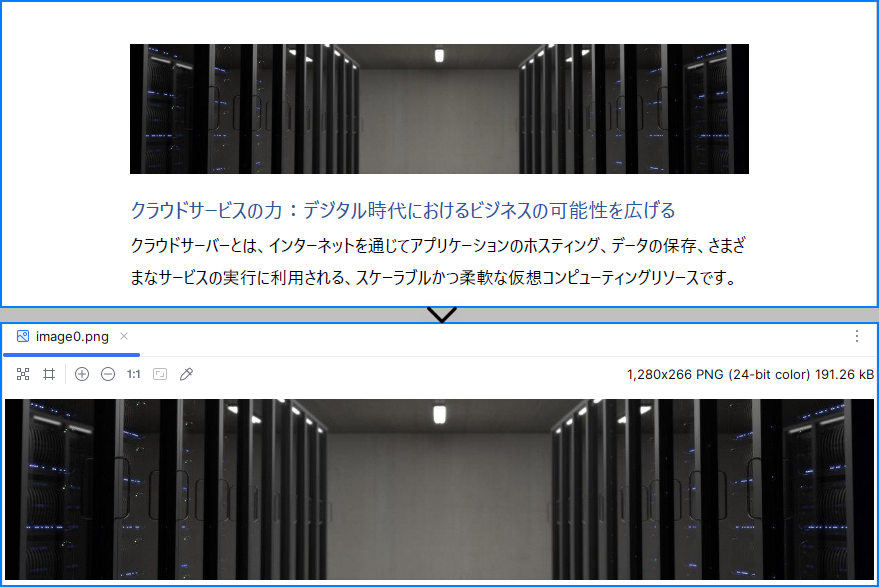
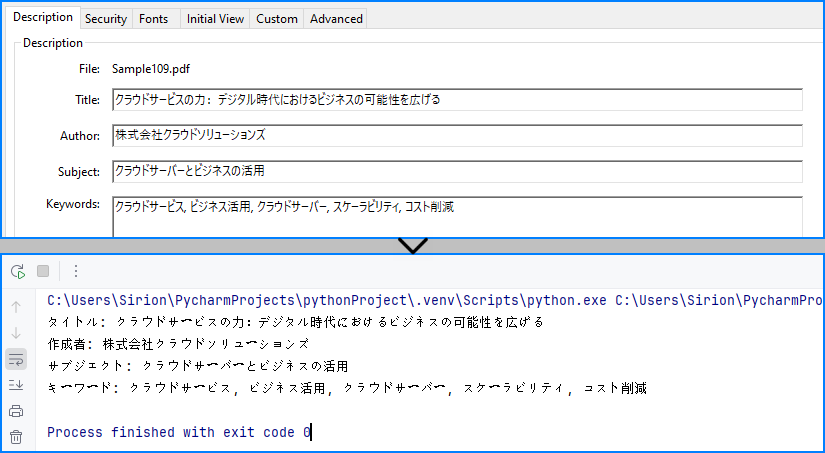
PDFのメタデータを読み取る(タイトル・著者など)
PDFには、タイトル、著者、キーワードなどのメタ情報が含まれています。これらを取得することで、ファイルの整理や検索の効率が向上します。DocumentInformation プロパティからアクセス可能です。
from spire.pdf import PdfDocument
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
properties = pdf.DocumentInformation
print("Title: " + properties.Title)
print("Author: " + properties.Author)
print("Subject: " + properties.Subject)
print("Keywords: " + properties.Keywords)
PDF文書から読み取ったメタデータ:
よくある質問(FAQ)
PythonでPDFを読み取ることはできますか?
はい。Spire.PDF for Python を使えば、テキスト・表・画像・メタ情報などを簡単に取得できます。
Jupyter Notebookでも使えますか?
はい。pipでインストールすれば、Jupyter Notebook環境でもそのまま使用できます。
PDFからテキストを取り出す方法は?
PdfTextExtractor.ExtractText() を使って、各ページごとの可視テキストを抽出可能です。
PDFをディスクに保存せず読み込むには?
LoadFromStream() を使えば、メモリ上のバイトデータから直接PDFを読み込めます。
まとめ
Spire.PDF for Python を使えば、PythonでのPDFファイル読み取りを簡単に実現できます。テキスト、表、画像、メタデータのすべてに対応し、ドキュメント自動化やデータ分析に最適です。
大規模なPDF処理や全機能の活用には、無料ライセンスを申請 してフルバージョンをご活用ください。





