チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

PDF ドキュメントのヘッダーとフッターは、タイトル、著者、日付、ページ番号などの貴重な情報を提供し、ドキュメントの使いやすさとブランドアイデンティティを向上させます。この記事では、C# で Spire.PDF for .NET を使用して既存の PDF ドキュメントにヘッダーとフッターを追加する方法を説明します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET を使用して既存の PDF を操作する場合、座標系の原点はページの左上にあり、X 軸は右に、Y 軸は下に伸びています。ヘッダーを追加するには、上部の空白領域にコンテンツを配置し、フッターを追加するには下部の空白領域にコンテンツを配置します。
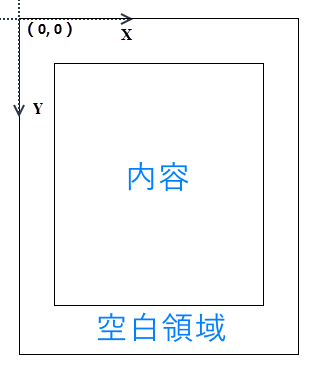
空白領域がコンテンツを収容するのに十分でない場合は、PDF ページの余白を広げることを検討できます。
Spire.PDF for .NET では、PdfCanvas.DrawString()、PdfCanvas.DrawImage()、PdfCanvas.DrawLine() などのメソッドを使用して、PDF ページにテキスト、画像、図形を描画できます。ページ番号や日付などの動的情報をヘッダーに追加するには、PdfPageNumberField、PdfSectionNumberField、PdfCreationDateField などの自動フィールドを使用します。
以下は Spire.PDF for .NET を使用して、テキスト、画像、日付、線で構成されるヘッダーを PDF ドキュメントに追加する手順です。
using Spire.Pdf;
using Spire.Pdf.AutomaticFields;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace AddHeaderToExistingPdf
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
//ヘッダー用の画像を読み込む
PdfImage headerImage = PdfImage.FromFile("Logo.png");
//画像の幅をピクセルで取得
float width = headerImage.Width;
//ピクセルをポイントに変換
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
float pointWidth = unitCvtr.ConvertUnits(width, PdfGraphicsUnit.Pixel, PdfGraphicsUnit.Point);
//ヘッダー用のテキストを指定
string headerText = "E-iceblue テック\nwww.e-iceblue.com";
//TrueTypeフォントを作成
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Gothic UI", 12f, FontStyle.Bold), true);
//ブラシを作成
PdfBrush brush = PdfBrushes.Purple;
//ペンを作成
PdfPen pen = new PdfPen(brush, 1.0f);
//作成日時フィールドを作成
PdfCreationDateField creationDateField = new PdfCreationDateField(font, brush);
creationDateField.DateFormatString = "yyyy-MM-dd";
//静的文字列と日付フィールドを組み合わせる複合フィールドを作成
PdfCompositeField compositeField = new PdfCompositeField(font, brush, "作成時間:{0}", creationDateField);
compositeField.Location = new Point(55, 48);
//ドキュメント内のページをループ
for (int i = 0; i < doc.Pages.Count; i++)
{
//特定のページを取得
PdfPageBase page = doc.Pages[i];
//画像を上部の空白領域に描画
page.Canvas.DrawImage(headerImage, page.ActualSize.Width - pointWidth - 55, 20);
//テキストを上部の空白領域に描画
page.Canvas.DrawString(headerText, font, brush, 55, 20);
//上部の空白領域に線を描画
page.Canvas.DrawLine(pen, new PointF(55, 70), new PointF(page.ActualSize.Width - 55, 70));
//複合フィールドを上部の空白領域に描画
compositeField.Draw(page.Canvas);
}
//ファイルに保存
doc.SaveToFile("output/PDFにヘッダーを挿入.pdf");
doc.Dispose();
}
}
}
同様に、PdfCanvas.DrawString()、PdfCanvas.DrawImage()、PdfCanvas.DrawLine() を使用してフッターを追加できます。PdfPageNumberField や PdfPageCountField などの自動フィールドは動的データの統合を助けます。
以下は Spire.PDF for .NET を使用して、画像とページ番号で構成されるフッターを PDF ドキュメントに追加する手順です。
using Spire.Pdf;
using Spire.Pdf.AutomaticFields;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace AddHeaderToExistingPdf
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
//画像を読み込む
PdfImage footerImage = PdfImage.FromFile("bg.png");
//TrueTypeフォントを作成
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Gothic UI", 12f, FontStyle.Bold), true);
//ブラシを作成
PdfBrush brush = PdfBrushes.White;
//ページ番号フィールドを作成
PdfPageNumberField pageNumberField = new PdfPageNumberField();
//ページ数フィールドを作成
PdfPageCountField pageCountField = new PdfPageCountField();
//ページ数フィールドとページ番号フィールドを単一の文字列に結合する複合フィールドを作成
PdfCompositeField compositeField = new PdfCompositeField(font, brush, "{0} / {1}", pageNumberField, pageCountField);
//テキストサイズを取得
SizeF fontSize = font.MeasureString(compositeField.Text);
//ページサイズを取得
SizeF pageSize = doc.Pages[0].Size;
//複合フィールドの位置を設定
compositeField.Location = new Point((int)(pageSize.Width - fontSize.Width) / 2, (int)pageSize.Height - 45);
//ドキュメント内のページをループ
for (int i = 0; i < doc.Pages.Count; i++)
{
//特定のページを取得
PdfPageBase page = doc.Pages[i];
//画像を下部の空白領域に描画
page.Canvas.DrawImage(footerImage, 55, pageSize.Height - 65, pageSize.Width - 110, 50);
//複合フィールドを下部の空白領域に描画
compositeField.Draw(page.Canvas);
}
//ファイルに保存
doc.SaveToFile("output/PDFにフッターを挿入.pdf");
doc.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ドキュメントにおけるブックマークの展開・折りたたみ機能は、より整理されたナビゲーションを提供し、ドキュメントの構造を簡単に理解できるようにします。ブックマークが展開されている場合、階層全体が一度に表示され、ドキュメントの構成を包括的に把握できます。一方で、ブックマークを折りたたむことで、詳細を表示せず、特定の部分に集中しやすくなり、全体の階層に気を取られることなく閲覧が可能です。この記事では、C# で Spire.PDF for .NET を使用して、PDF 内のブックマークを展開・折りたたむ方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PdfBookmark.ExpandBookmark プロパティを使用して、指定されたブックマークを展開または折りたたむことができます。以下は詳細な手順です。
using Spire.Pdf;
using Spire.Pdf.Bookmarks;
namespace ExpandOrCollapseABookmark
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
// PDFファイルをロード
pdf.LoadFromFile("Sample.pdf");
// 指定されたブックマークを取得
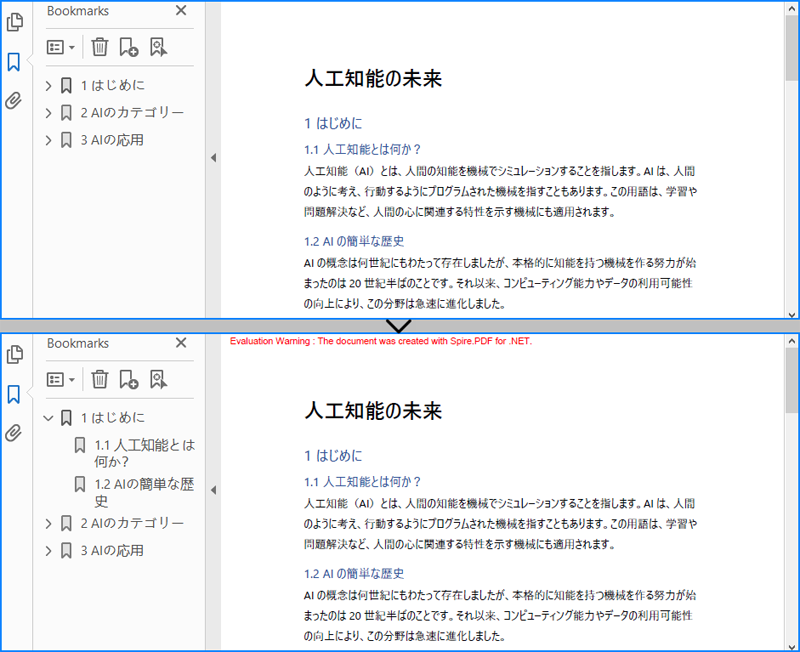
PdfBookmark bookmarks = pdf.Bookmarks[0];
// ブックマークを展開
bookmarks.ExpandBookmark = true;
// ブックマークを折りたたむ
// bookmarks.ExpandBookmark = false;
// 結果ファイルを保存
pdf.SaveToFile("output/特定のPDFブックマークを展開.pdf");
pdf.Close();
}
}
}
PDF ファイル内のすべてのブックマークを順次処理し、それぞれのブックマークを PdfBookmark.ExpandBookmark プロパティを使用して展開または折りたたむことも可能です。以下はその詳細な手順です。
using Spire.Pdf;
using Spire.Pdf.Bookmarks;
namespace ExpandOrCollapsePDFBookmarks
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
// PDFファイルをロード
pdf.LoadFromFile("Sample.pdf");
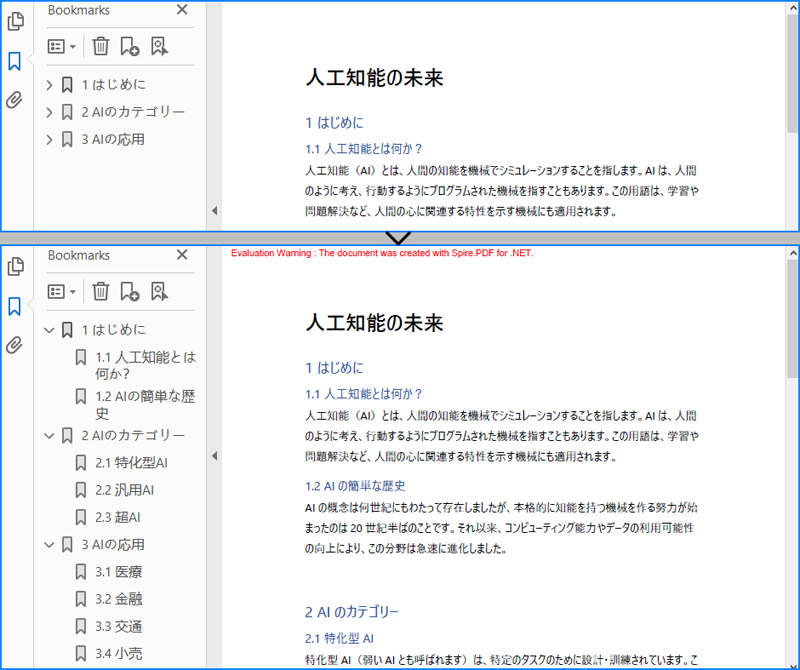
// すべてのブックマークをループして展開
foreach (PdfBookmark bookmark in pdf.Bookmarks)
{
bookmark.ExpandBookmark = true;
}
// 結果ファイルを保存
pdf.SaveToFile("output/すべてのPDFブックマークを展開.pdf");
pdf.Close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
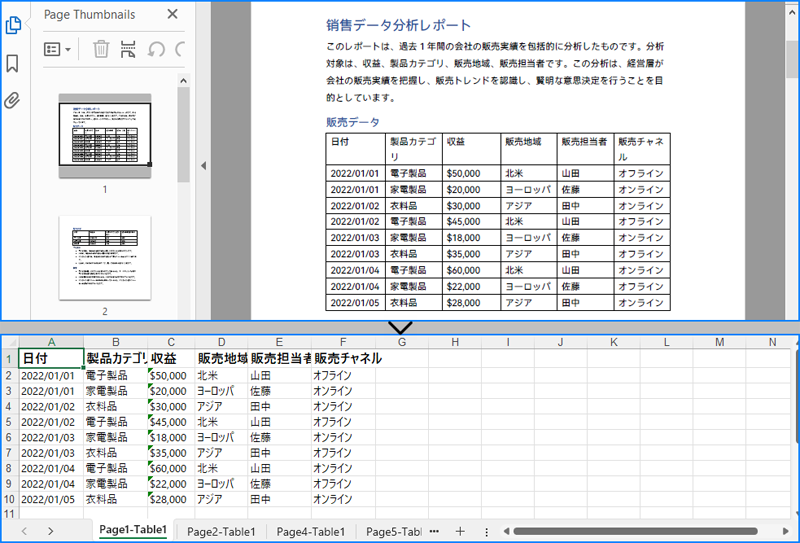
PDF は、データの共有や記録に広く使われる人気のあるドキュメント形式です。特に PDF に含まれる表のデータを抽出する必要がある場面に出くわすことがあります。例えば、請求書の PDF に保存された表の中に有用な情報があり、そのデータを分析や計算に利用したい場合です。本記事では、Spire.PDF for .NET を使用して、PDF の表からデータを抽出し、それをテキストファイルや Excel ワークシートに保存する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
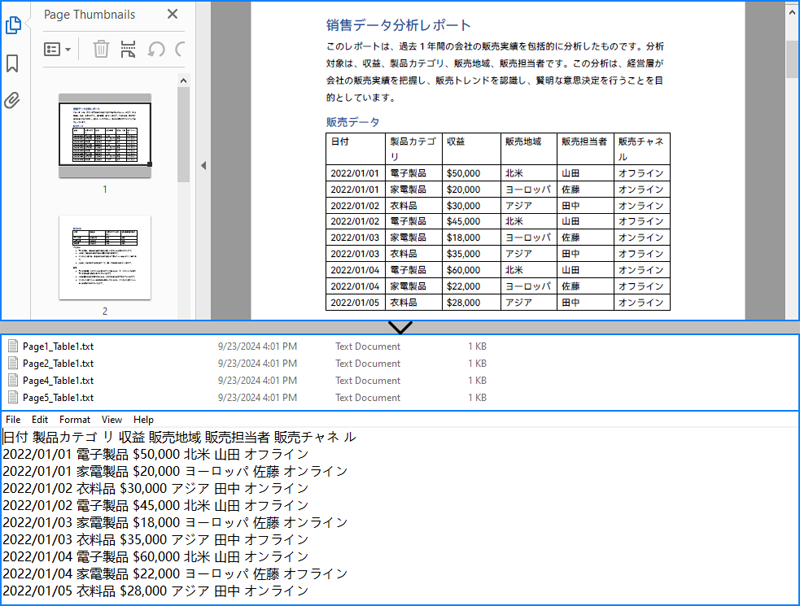
PM> Install-Package Spire.PDFSpire.PDF for .NET には、PdfTableExtractor.ExtractTable() メソッドがあり、PDF ページ上のすべての表を抽出することができます。このメソッドを使用して PDF ドキュメントから表を抽出した後、PdfTable.GetText() メソッドを使用して表の値を取得し、それをテキストファイルに書き出すことができます。PDF表データをテキストファイルに抽出する手順は以下の通りです:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Text;
namespace PDFTableToText
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成し、PDFドキュメントをロード
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// 読み込んだPDFのためのテーブルエクストラクターを初期化
PdfTableExtractor tableExtractor = new PdfTableExtractor(pdf);
// PDFの各ページを繰り返し処理
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
// 現在のページからテーブルを抽出
PdfTable[] tables = tableExtractor.ExtractTable(pageIndex);
if (tables != null)
{
// 抽出された各テーブルを繰り返し処理
for (int tableIndex = 0; tableIndex < tables.Length; tableIndex++)
{
// StringBuilderオブジェクトを作成
StringBuilder stringBuilder = new StringBuilder();
// テーブルの各行と列を繰り返し処理
for (int rowIndex = 0; rowIndex < tables[tableIndex].GetRowCount(); rowIndex++)
{
for (int columnIndex = 0; columnIndex < tables[tableIndex].GetColumnCount(); columnIndex++)
{
// テーブルのセルテキストを取得し、改行を削除
string cellText = tables[tableIndex].GetText(rowIndex, columnIndex);
string text = cellText.Replace("\n", " ");
// StringBuilderオブジェクトにセルテキストを追加
if (columnIndex < tables[tableIndex].GetColumnCount() - 1)
{
stringBuilder.Append(text + "");
}
else
{
stringBuilder.Append(text);
}
}
// 各テーブル行のために行を切り替え
if (rowIndex < tables[tableIndex].GetRowCount() - 1)
{
stringBuilder.AppendLine();
}
}
// テーブル内容をテキストファイルに書き込み
string outputFilePath = $"output/Page{pageIndex + 1}_Table{tableIndex + 1}.txt";
File.WriteAllText(outputFilePath, stringBuilder.ToString());
}
}
}
}
}
}
PDF 表のセルの値を上記と同様に取得し、Spire.XLS for .NET を使用して Excel ファイルに書き出すことができます。最初に Spire.XLS for .NET をインストールする必要があります:
PM> Install-Package Spire.XLSPDF 表データを Excel ファイルに抽出する手順は以下の通りです:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using Spire.Xls;
using System.Text;
namespace PDFTableToText
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成し、PDFドキュメントをロード
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Workbookオブジェクトを作成
Workbook workbook = new Workbook();
// デフォルトのワークシートをクリア
workbook.Worksheets.Clear();
// 読み込んだPDFのためのテーブルエクストラクターを初期化
PdfTableExtractor tableExtractor = new PdfTableExtractor(pdf);
// PDFの各ページを繰り返し処理
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
// 現在のページからテーブルを抽出
PdfTable[] tables = tableExtractor.ExtractTable(pageIndex);
if (tables != null)
{
// ページ上の各抽出されたテーブルを繰り返し処理
for (int tableIndex = 0; tableIndex < tables.Length; tableIndex++)
{
// ワークブックにワークシートを追加
Worksheet sheet = workbook.Worksheets.Add($"Page{pageIndex + 1}-Table{tableIndex + 1}");
// テーブル内の各行と列を繰り返し処理
for (int rowIndex = 0; rowIndex < tables[tableIndex].GetRowCount(); rowIndex++)
{
for (int columnIndex = 0; columnIndex < tables[tableIndex].GetColumnCount(); columnIndex++)
{
// テーブルからセルテキストを取得し、改行を削除
string cellText = tables[tableIndex].GetText(rowIndex, columnIndex);
string text = cellText.Replace("\n", "");
// ワークシートの対応する位置にセルテキストを挿入
sheet.Range[rowIndex + 1, columnIndex + 1].Text = text;
}
}
// テーブルヘッダのフォーマットを設定
sheet.Rows[0].Style.Font.FontName = "Yu Gothic UI";
sheet.Rows[0].Style.Font.Size = 12;
sheet.Rows[0].Style.Font.IsBold = true;
sheet.Rows[0].Style.HorizontalAlignment = HorizontalAlignType.Center;
// データ行のフォーマットを設定
for (int rowIndex = 1; rowIndex < sheet.Rows.Length; rowIndex++)
{
sheet.Rows[rowIndex].Style.Font.FontName = "Yu Gothic UI";
sheet.Rows[0].Style.Font.Size = 12;
sheet.Rows[0].Style.HorizontalAlignment = HorizontalAlignType.Left;
}
// 各列を自動調整
for (int columnIndex = 1; columnIndex <= sheet.Columns.Length; columnIndex++)
{
sheet.AutoFitColumn(columnIndex);
}
}
}
}
// ワークブックを保存
workbook.SaveToFile("PDFTableToExcel.xlsx", Spire.Xls.FileFormat.Version2016);
pdf.Close();
workbook.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
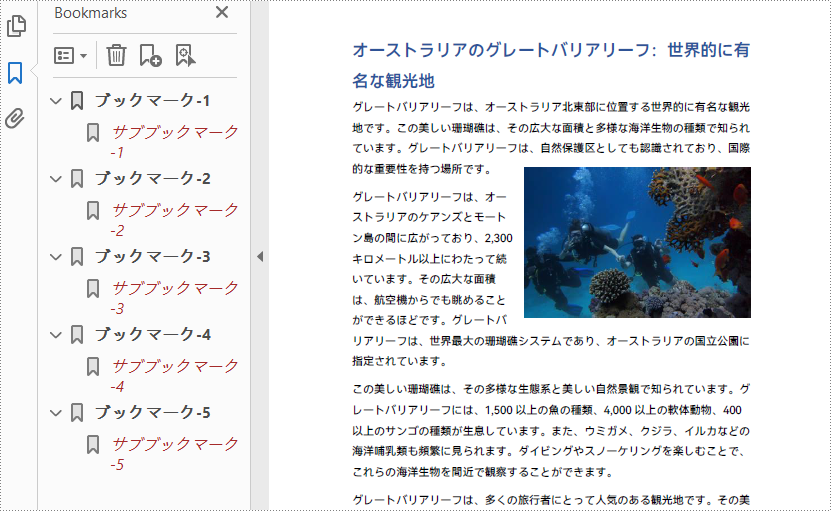
PDF のブックマークは、ユーザーが特定のセクションやページに素早く移動できるナビゲーション機能です。ワンクリックで目的の場所にジャンプでき、長い文書を手動でスクロールしたり、特定の内容を探す手間を省くことができます。この記事では、Spire.PDF for .NET を使用して、プログラムで PDF 文書にブックマークを追加、編集、削除する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PdfDocument.Bookmarks.Add() メソッドを提供しており、これを使って PDF 文書にブックマークを追加できます。ブックマークを作成した後、PdfBookmark.Add() メソッドを使用して、サブブックマークも追加できます。以下に、詳細な手順を示します。
using System.Drawing;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Actions;
using Spire.Pdf.Bookmarks;
using Spire.Pdf.General;
namespace AddBookmark
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
//サンプルPDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
//PDFファイルのページをループする
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
//ブックマークを追加
PdfBookmark bookmark = pdf.Bookmarks.Add(string.Format("ブックマーク-{0}", i + 1));
//ブックマークの目的のページと位置を設定
PdfDestination destination = new PdfDestination(page, new PointF(0, 0));
bookmark.Action = new PdfGoToAction(destination);
//ブックマークのテキストの色とスタイルを設定
bookmark.Color = new PdfRGBColor(Color.Black);
bookmark.DisplayStyle = PdfTextStyle.Bold;
//子ブックマークを追加
PdfBookmark childBookmark = bookmark.Add(string.Format("サブブックマーク-{0}", i + 1));
//子ブックマークの目的のページと位置を設定
PdfDestination childDestination = new PdfDestination(page, new PointF(0, 100));
childBookmark.Action = new PdfGoToAction(childDestination);
//子ブックマークのテキストの色とスタイルを設定
childBookmark.Color = new PdfRGBColor(Color.Brown);
childBookmark.DisplayStyle = PdfTextStyle.Italic;
}
//結果ファイルを保存
pdf.SaveToFile("output/ブックマークを追加.pdf");
pdf.Close();
}
}
}
using Spire.Pdf;
using Spire.Pdf.Bookmarks;
using System.Drawing;
namespace ModifyBookmarks
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
//サンプルPDFファイルを読み込む
pdf.LoadFromFile("output/ブックマークを追加.Pdf");
//最初のブックマークを取得
PdfBookmark bookmark = pdf.Bookmarks[0];
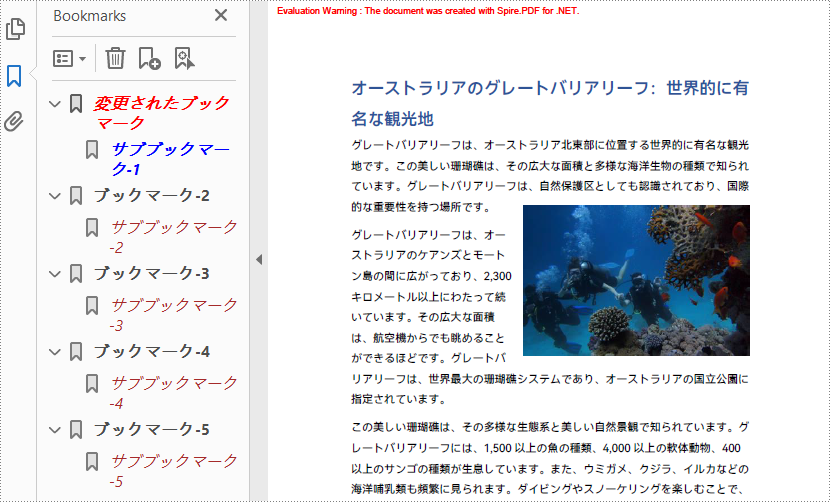
//ブックマークのタイトルを変更
bookmark.Title = "変更されたブックマーク";
//ブックマークのテキストの色とスタイルを変更
bookmark.Color = Color.Red;
bookmark.DisplayStyle = PdfTextStyle.Italic;
//最初のブックマークのサブブックマークを編集
foreach (PdfBookmark childBookmark in bookmark)
{
childBookmark.Color = Color.Blue;
childBookmark.DisplayStyle = PdfTextStyle.Bold;
}
//結果ファイルを保存
pdf.SaveToFile("output/ブックマークを編集.Pdf");
pdf.Close();
}
}
}
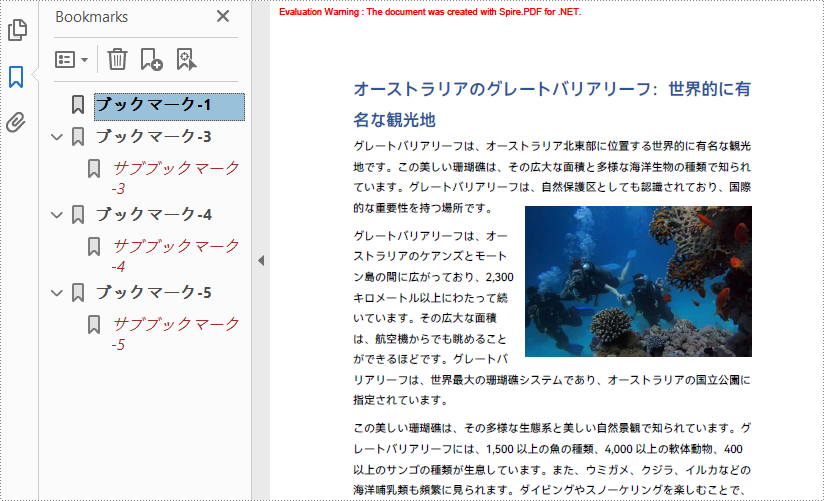
Spire.PDF for .NET では、特定のブックマークだけでなく、PDF ファイル内のすべてのブックマークを削除することが可能です。また、特定のサブブックマークだけを削除することもできます。以下に、詳細な手順を示します。
using Spire.Pdf;
using Spire.Pdf.Bookmarks;
namespace DeleteBookmarks
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
//サンプルPDFファイルを読み込む
pdf.LoadFromFile("output/ブックマークを追加.Pdf");
//最初のブックマークを取得
PdfBookmark bookmark = pdf.Bookmarks[0];
//最初のブックマークの最初のサブブックマークを削除
bookmark.RemoveAt(0);
//2番目のブックマークとそのサブブックマークを削除
pdf.Bookmarks.RemoveAt(1);
//すべてのブックマークを削除
//pdf.Bookmarks.Clear();
//結果ファイルを保存
pdf.SaveToFile("output/ブックマークを削除.pdf");
pdf.Close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF 文書のテキストを置換する必要がある場合は多々あります。誤字脱字の修正、古い情報の更新、特定の読者や目的に合わせた内容のカスタマイズ、または法的・規制上の要件に準拠するためなどが考えられます。PDF 内のテキストを置換することで、正確性を確保し、文書の整合性を保ち、提供される情報の品質と関連性を向上させることができます。
本記事では、C# を使用して Spire.PDF for .NET ライブラリを使い、PDF 文書のテキストを置換する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PdfTextReplacer.ReplaceAllText() メソッドを提供しており、ページ内のターゲットテキストのすべての一致箇所を新しいテキストに置換することが可能です。以下は、C# で特定のページ内の一致するテキストを置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceTextInPage
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// テキスト置換のオプションを指定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.IgnoreCase;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.WholeWord;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.AutofitWidth;
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// ターゲットテキストを新しいテキストに全て置換
textReplacer.ReplaceAllText("Spire.PDF for .NET", "Spire.Pdf for .Net");
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("PDFページのテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}
文書全体のすべての一致するテキストを新しいテキストに置換するには、文書内のページを繰り返し処理し、それぞれのページで PdfTextReplacer.ReplaceAllText() メソッドを使用してテキストを置換する必要があります。
以下は、C# で PDF 文書全体の一致するテキストを置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceInEntireDocument
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// テキスト置換のオプションを指定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.IgnoreCase;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.WholeWord;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.AutofitWidth;
for (int i = 0; i < doc.Pages.Count; i++)
{
// 特定のページを取得
PdfPageBase page = doc.Pages[i];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// ターゲットテキストを新しいテキストに全て置換
textReplacer.ReplaceAllText("Spire.PDF for .NET", "Spire.Pdf for .Net");
}
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("PDF文書のテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}ページ内のすべての一致するテキストを置換する代わりに、PdfTextReplacer クラスの ReplaceText() メソッドを使用して、ターゲットテキストの最初の一致箇所のみを置換することができます。
以下は、C# でターゲットテキストの最初の一致箇所を置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceFirstOccurance
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// テキスト置換のオプションを指定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.IgnoreCase;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.WholeWord;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.AutofitWidth;
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// ターゲットテキストの最初の出現を新しいテキストに置換
textReplacer.ReplaceText("Spire.PDF for .NET", "Spire.Pdf for .Net");
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("PDF内の最初の一致するテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}
正規表現は、テキストのパターンをマッチングし操作するための強力で柔軟な手段です。Spire.PDF では、正規表現を使用して PDF 内の特定のテキストパターンを検索し、新しい文字列に置換することが可能です。
以下は、正規表現を使用して PDF 内のテキストを置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceUsingRegularExpression
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample1.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// 置換タイプを正規表現に設定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.Regex;
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// 正規表現を指定
string regularExpression = @"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b";
// 正規表現に一致するすべての出現を新しいテキストに置換
textReplacer.ReplaceAllText(regularExpression, "manager @system.com");
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("正規表現を使ってテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
バーコードと QR コードは、アイテムを迅速かつ効率的に識別・追跡するための重要な手段であり、多くの業界で不可欠なものとなっています。PDF にバーコードを追加することで、企業は文書管理プロセスを強化し、PDF ファイルの処理や追跡をより効率的に行えるようになります。さらに、この操作により、従来のテキストや画像に加えて、バーコードの機能を統合した動的でインタラクティブな PDF 文書を作成することも可能です。本記事では、C# を使用して Spire.PDF for .NET と Spire.Barcode for .NET を利用し、PDF にバーコードと QR コードを追加する方法をご紹介します。
まず、Spire.PDF for .NET および Spire.Barcode for .NET ライブラリをダウンロードし、両方の製品パッケージに含まれる DLL ファイルを .NET プロジェクトの参照として追加する必要があります。または、NuGet 経由でインストールすることも可能です。
PM> Install-Package Spire.PDF
PM> Install-Package Spire.BarcodeSpire.PDF for .NET は、PdfCodabarBarcode、PdfCode128ABarcode、PdfCode32Barcode、PdfCode39Barcode、PdfCode93Barcode など、さまざまなクラスによって表される複数の 1D バーコードタイプをサポートしています。
各クラスは、バーコードのテキスト、サイズ、色などを設定するための対応するプロパティを提供しています。以下は、一般的な Codabar、Code128、Code39、Code93 バーコードを PDF ページの指定された位置に描画するための手順です。
using Spire.Pdf;
using Spire.Pdf.Barcode;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace PDFBarcode
{
class Program
{
static void Main(string[] args)
{
// PDFドキュメントを作成
PdfDocument pdf = new PdfDocument();
// ページを追加
PdfPageBase page = pdf.Pages.Add(PdfPageSize.A4);
// y座標を初期化
float y = 20;
// TrueTypeフォントを作成
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Gothic UI", 14f, FontStyle.Bold), true);
// ページにテキストを描画
PdfTextWidget text = new PdfTextWidget();
text.Font = font;
text.Text = "コーダバー";
PdfLayoutResult result = text.Draw(page, 0, y);
page = result.Page;
y = result.Bounds.Bottom + 2;
// ページにCodabarバーコードを描画
PdfCodabarBarcode Codabar = new PdfCodabarBarcode("00:12-3456/7890");
Codabar.BarcodeToTextGapHeight = 1f;
Codabar.TextDisplayLocation = TextLocation.Bottom;
Codabar.TextColor = Color.Blue;
Codabar.Draw(page, new PointF(0, y));
// ページにテキストを描画
text.Text = "Code128-A:";
result = text.Draw(page, 240, 20);
page = result.Page;
y = result.Bounds.Bottom + 2;
// ページにCode128-Aバーコードを描画
PdfCode128ABarcode Code128 = new PdfCode128ABarcode("HELLO 00-123");
Code128.BarcodeToTextGapHeight = 1f;
Code128.TextDisplayLocation = TextLocation.Bottom;
Code128.TextColor = Color.Blue;
Code128.Draw(page, new PointF(240, y));
// ページにテキストを描画
text.Text = "Code39:";
result = text.Draw(page, 0, Codabar.Bounds.Bottom + 8);
page = result.Page;
y = result.Bounds.Bottom + 2;
// ページにCode39バーコードを描画
PdfCode39Barcode Code39 = new PdfCode39Barcode("16-273849");
Code39.BarcodeToTextGapHeight = 1f;
Code39.TextDisplayLocation = TextLocation.Bottom;
Code39.TextColor = Color.Blue;
Code39.Draw(page, new PointF(0, y));
// ページにテキストを描画
text.Text = "Code93:";
result = text.Draw(page, 240, Code128.Bounds.Bottom + 8);
page = result.Page;
y = result.Bounds.Bottom + 2;
// ページにCode93バーコードを描画
PdfCode93Barcode Code93 = new PdfCode93Barcode("16-273849");
Code93.BarcodeToTextGapHeight = 1f;
Code93.TextDisplayLocation = TextLocation.Bottom;
Code93.TextColor = Color.Blue;
Code93.QuietZone.Bottom = 5;
Code93.Draw(page, new PointF(240, y));
// ドキュメントを保存
pdf.SaveToFile("PDFでバーコードを作成.pdf");
pdf.Close();
}
}
}
PDF ファイルに 2D バーコードを追加するには、まず Spire.Barcode for .NET ライブラリを使用して QR コードを生成し、その後、Spire.PDF for .NET ライブラリを使用して PDF ファイルに QR コード画像を追加する必要があります。
以下は、PDF 文書に QR コードを追加するための詳細な手順です。
using System.Drawing;
using Spire.Barcode;
using Spire.Pdf;
using Spire.Pdf.Graphics;
namespace PDFQRcode
{
class Program
{
static void Main(string[] args)
{
// PDFドキュメントを作成
PdfDocument pdf = new PdfDocument();
// ページを追加
PdfPageBase page = pdf.Pages.Add();
// BarcodeSettingsオブジェクトを作成
BarcodeSettings settings = new BarcodeSettings();
// バーコードタイプをQRコードに設定
settings.Type = BarCodeType.QRCode;
// QRコードのデータを設定
settings.Data = "E-iceblue";
settings.Data2D = "E-iceblue";
// QRコードの幅を設定
settings.X = 2.5f;
// QRコードのエラー訂正レベルを設定
settings.QRCodeECL = QRCodeECL.Q;
// QRコードのテキストを下部に表示
settings.ShowTextOnBottom = true;
// 設定に基づいてQRコード画像を生成
BarCodeGenerator generator = new BarCodeGenerator(settings);
Image QRimage = generator.GenerateImage();
// y座標を初期化
float y = 20;
// TrueTypeフォントを作成
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Gothic UI", 14f, FontStyle.Bold), true);
// PDFページにテキストを描画
PdfTextWidget text = new PdfTextWidget();
text.Font = font;
text.Text = "QRコード";
PdfLayoutResult result = text.Draw(page, 0, y);
y = result.Bounds.Bottom + 2;
// PDFページにQRコード画像を描画
PdfImage pdfImage = PdfImage.FromImage(QRimage);
page.Canvas.DrawImage(pdfImage, 0, y);
// ドキュメントを保存
pdf.SaveToFile("PDFでQRコードを作成.pdf");
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ページ内のテキストや画像の座標を取得することは、ドキュメント内の特定の要素を正確に参照し、操作するために有用です。座標を抽出することで、各ページ上のテキストや画像の位置を正確に特定できます。この情報は、データ抽出、テキスト認識、特定の領域のハイライトなどに役立ちます。本記事では、C# で Spire.PDF for .NET を使用して、PDF ページ内のテキストや画像の座標情報を取得する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF が提供する PdfTextFinder.Find() メソッドを使用すると、検索可能な PDF ドキュメント内で指定した文字列のすべてのインスタンスを検索できます。特定のインスタンスの座標情報は、PdfTextFragment.Positions プロパティから取得可能です。Spire.PDF for .NET を使って PDF 内の指定されたテキストの (X, Y) 座標を取得する手順は次の通りです:
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Drawing;
namespace GetCoordinatesOfText
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// すべてのページをループ
foreach (PdfPageBase page in doc.Pages)
{
// PdfTextFinderオブジェクトを作成
PdfTextFinder finder = new PdfTextFinder(page);
// 検索オプションを設定
PdfTextFindOptions options = new PdfTextFindOptions();
options.Parameter = TextFindParameter.IgnoreCase;
finder.Options = options;
// 特定のテキストのすべてのインスタンスを検索
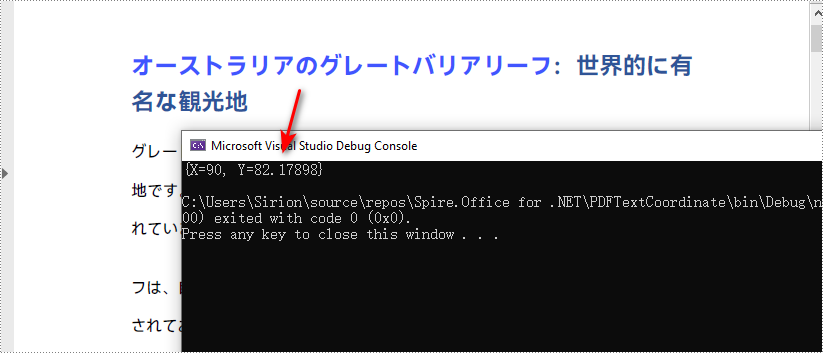
var fragments = finder.Find("オーストラリアのグレートバリアリーフ");
// インスタンスをループ
foreach (PdfTextFragment fragment in fragments)
{
// 特定のインスタンスの位置を取得
PointF found = fragment.Positions[0];
Console.WriteLine(found);
}
}
}
}
}
Spire.PDF は、PdfImageHelper.GetImagesInfo() メソッドを提供しており、指定されたページ内のすべての画像情報を取得できます。特定の画像の座標情報は、PdfImageInfo.Bounds プロパティを通じて取得可能です。Spire.PDF for .NET を使って PDF ドキュメント内の画像の座標を取得する手順は次の通りです:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System;
namespace GetCoordinatesOfImage
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// PdfImageHelperオブジェクトを作成
PdfImageHelper helper = new PdfImageHelper();
// ページから画像情報を取得
PdfImageInfo[] images = helper.GetImagesInfo(page);
// 特定の画像のX,Y座標を取得
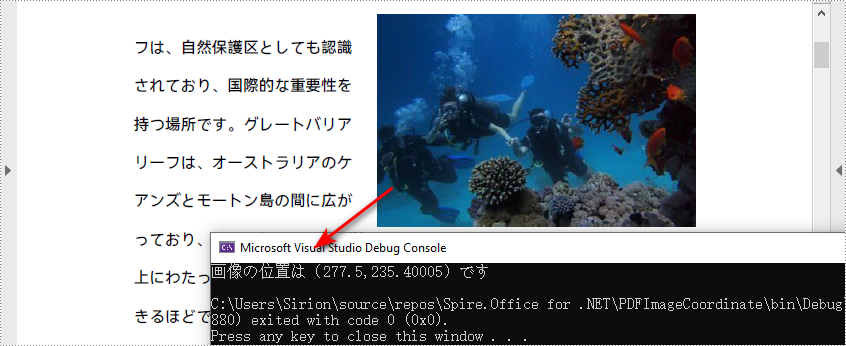
float xPos = images[0].Bounds.X;
float yPos = images[0].Bounds.Y;
Console.WriteLine("画像の位置は({0},{1})です", xPos, yPos);
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ドキュメントには、情報を分かりやすく伝えるために画像がよく使用されます。場合によっては、PDF ドキュメントから画像を抽出する必要があります。例えば、プレゼンテーションや他のドキュメントで、PDF レポートのチャート画像を使用したい場合です。本記事では、C# で Spire.PDF for .NET を使用して PDF から画像を抽出する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
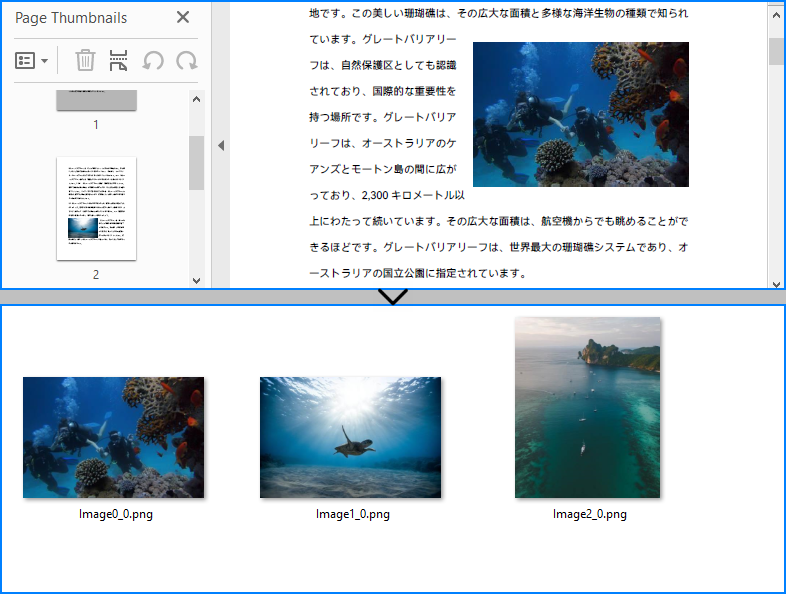
PM> Install-Package Spire.PDFPdfPageBase.ExtractImages() メソッドを使用すると、1ページ内のすべての画像を抽出できます。開発者は、PDF ドキュメント内のすべてのページを繰り返し処理し、このメソッドを使用して画像を抽出することができます。詳細な手順は以下の通りです:
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.LoadFromFile("Sample.pdf");
int i = 0;
// Iterate through the pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
// Extract the images from the page and save them to file
int j = 0;
foreach (Image image in page.ExtractImages())
{
image.Save("Images/Image" + i + "_" + j + ".png");
j++;
}
i++;
}
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ドキュメントのページサイズ、向き、および回転角度を確認することは、品質管理プロセスの一環として必要になる場合があります。たとえば、文書を公開または配布する前に、すべてのページが正しく表示されているかどうかを確認する必要があるかもしれません。本記事では、C# で Spire.PDF for .NET を使い、PDF ページのサイズ、向き、回転角度を取得する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PDF ページの幅と高さをポイント単位で取得するために、PdfPageBase.Size.Width および PdfPageBase.Size.Height プロパティを提供しています。デフォルトの単位を他の単位に変換したい場合は、PdfUnitConvertor クラスを使用できます。以下に詳細な手順を示します。
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Graphics;
namespace GetPDFPageSize
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
// ディスクからPDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
// 最初のページを取得
PdfPageBase page = pdf.Pages[0];
// ページの幅と高さをポイントで取得
float pointWidth = page.Size.Width;
float pointHeight = page.Size.Height;
// PdfUnitConvertorを作成して単位を変換
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// ポイントをピクセルに変換
float pixelWidth = unitCvtr.ConvertUnits(pointWidth, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pixelHeight = unitCvtr.ConvertUnits(pointHeight, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
// ポイントをインチに変換
float inchWidth = unitCvtr.ConvertUnits(pointWidth, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchHeight = unitCvtr.ConvertUnits(pointHeight, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// ポイントをセンチメートルに変換
float centimeterWidth = unitCvtr.ConvertUnits(pointWidth, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float centimeterHeight = unitCvtr.ConvertUnits(pointHeight, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// StringBuilderインスタンスを作成
StringBuilder content = new StringBuilder();
// ページサイズ情報をStringBuilderインスタンスに追加
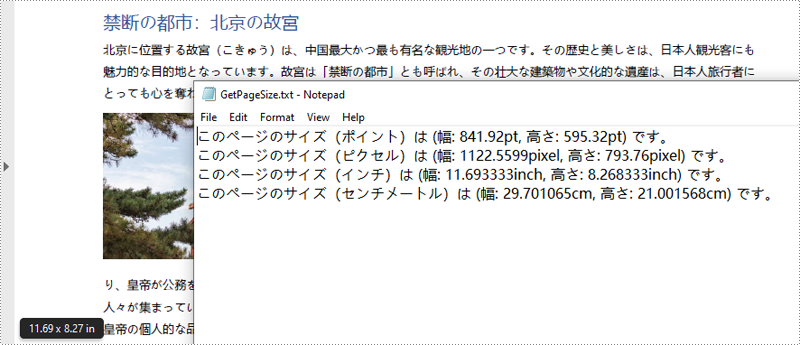
content.AppendLine("このページのサイズ(ポイント)は (幅: " + pointWidth + "pt, 高さ: " + pointHeight + "pt) です。");
content.AppendLine("このページのサイズ(ピクセル)は (幅: " + pixelWidth + "pixel, 高さ: " + pixelHeight + "pixel) です。");
content.AppendLine("このページのサイズ(インチ)は (幅: " + inchWidth + "inch, 高さ: " + inchHeight + "inch) です。");
content.AppendLine("このページのサイズ(センチメートル)は (幅: " + centimeterWidth + "cm, 高さ: " + centimeterHeight + "cm) です。");
// テキストファイルに保存
File.WriteAllText("GetPageSize.txt", content.ToString());
}
}
}
PDF ページの向きを検出するには、ページの幅と高さを比較します。ページの幅が高さより大きい場合、そのページは横向き(ランドスケープ)であり、それ以外の場合は縦向き(ポートレート)です。以下に詳細な手順を示します。
using Spire.Pdf;
namespace GetPDFPageOrientation
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
// ディスクからPDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
// 最初のページを取得
PdfPageBase page = pdf.Pages[0];
// ページの幅と高さを取得
float width = page.Size.Width;
float height = page.Size.Height;
// ページの幅と高さを比較
if (width > height)
{
Console.WriteLine("\r\n\r\nページの向きは横向きです。");
}
else
{
Console.WriteLine("\r\n\r\nページの向きは縦向きです。");
}
}
}
}
PDF ページの回転角度は、PdfPageBase.Rotation プロパティを通じて取得できます。以下に詳細な手順を示します。
using Spire.Pdf;
namespace GetPDFPageRotationAngle
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
// ディスクからPDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
// 最初のページを取得
PdfPageBase page = pdf.Pages[1];
// 現在のページの回転角度を取得
PdfPageRotateAngle rotationAngle = page.Rotation;
string rotation = rotationAngle.ToString();
// ページの回転角度情報を出力
Console.WriteLine("\r\n\r\n現在のページの回転角度は: " + rotation);
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ファイルのページ数を数えることは、ドキュメントの長さを把握したり、内容を整理したり、印刷要件を評価したりするために重要です。PDF ビューアでページ数を確認するだけでなく、プログラムによってこの作業を自動化することも可能です。本記事では、C# で Spire.PDF for .NET を使い、PDF ファイルのページ数を取得する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PDF ファイルを開かずに素早くページ数を数えるために、PdfDocument.Pages.Count プロパティを提供しています。以下に詳細な手順を示します。
using Spire.Pdf;
namespace GetNumberOfPages
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument pdf = new PdfDocument();
// サンプルPDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
// PDFのページ数を数える
int PageNumber = pdf.Pages.Count;
Console.WriteLine("\r\n\r\nこのPDFファイルには{0}ページあります。", PageNumber);
// PDFを閉じる
pdf.Close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





