チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション
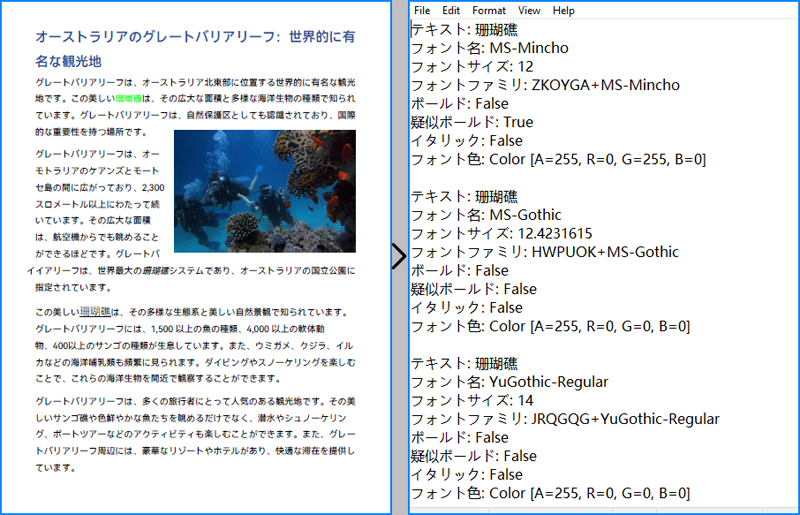
PDF のフォント情報を取得するとは、PDF ドキュメント内で使用されているフォントの詳細を抽出するプロセスを指します。この情報には、通常、フォント名、サイズ、種類、色、その他の属性が含まれます。これらの詳細を把握することで、一貫性や著作権の遵守、美観を確保するのに役立ちます。本記事では、C# で Spire.PDF for .NET を使用して PDF のフォント情報を取得する方法を解説します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET を使用すると、指定したテキストを検索し、フォント名、サイズ、スタイル、色といったフォントフォーマット情報を PdfTextFragment クラスのプロパティから取得できます。以下に詳細な手順を示します。
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Drawing;
using System.Text;
namespace GetTextFont
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentインスタンスを作成
PdfDocument pdf = new PdfDocument();
// PDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
// 最初のページを取得
PdfPageBase page = pdf.Pages[0];
// PdfTextFinderインスタンスを作成
PdfTextFinder finds = new PdfTextFinder(page);
// ページ内の指定テキストを検索
finds.Options.Parameter = TextFindParameter.None;
List result = finds.Find("珊瑚礁");
// StringBuilderインスタンスを作成
StringBuilder str = new StringBuilder();
// 検索結果を反復処理
foreach (PdfTextFragment find in result)
{
// 見つかったテキストを取得
string text = find.Text;
// フォント名を取得
string FontName = find.TextStates[0].FontName;
// フォントサイズを取得
float FontSize = find.TextStates[0].FontSize;
// フォントファミリを取得
string FontFamily = find.TextStates[0].FontFamily;
// ボールドまたはイタリックであるかを確認
bool IsBold = find.TextStates[0].IsBold;
bool IsSimulateBold = find.TextStates[0].IsSimulateBold;
bool IsItalic = find.TextStates[0].IsItalic;
// フォント色を取得
Color color = find.TextStates[0].ForegroundColor;
// フォント情報をStringBuilderに追加
str.AppendLine("テキスト: " + text);
str.AppendLine("フォント名: " + FontName);
str.AppendLine("フォントサイズ: " + FontSize);
str.AppendLine("フォントファミリ: " + FontFamily);
str.AppendLine("ボールド: " + IsBold);
str.AppendLine("疑似ボールド: " + IsSimulateBold);
str.AppendLine("イタリック: " + IsItalic);
str.AppendLine("フォント色: " + color);
str.AppendLine();
}
// 情報をテキストファイルに書き込む
File.WriteAllText("PDFフォント.txt", str.ToString());
pdf.Dispose();
}
}
} 
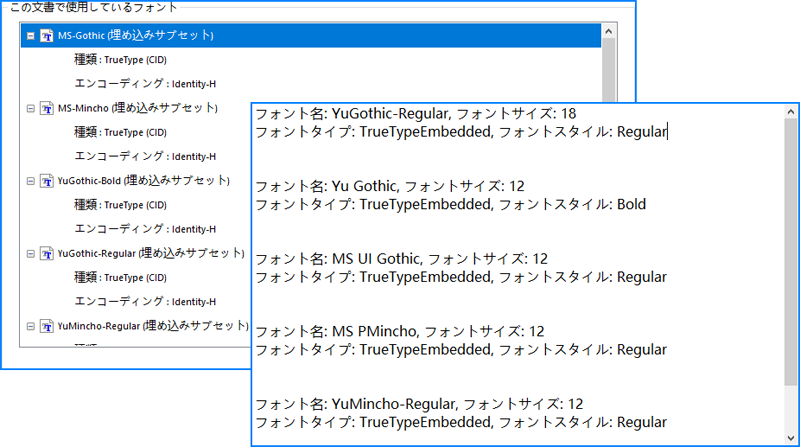
Spire.PDF for .NET は、PDF ドキュメント内で使用されているフォントを表す PdfUsedFont クラスを提供しています。すべての使用フォントのフォーマットを取得するには、各フォントを反復処理して、対応するプロパティからフォント名、サイズ、種類、スタイルを取得します。以下に詳細な手順を示します。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Graphics.Fonts;
using System.IO;
using System.Text;
namespace GetPdfFont
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentインスタンスを作成
PdfDocument pdf = new PdfDocument();
// PDFファイルを読み込む
pdf.LoadFromFile("Sample.pdf");
// PDFファイルで使用されているフォントを取得
PdfUsedFont[] fonts = pdf.UsedFonts;
// StringBuilderインスタンスを作成
StringBuilder str = new StringBuilder();
// 使用フォントを反復処理
foreach (PdfUsedFont font in fonts)
{
// フォント名を取得
string name = font.Name;
// フォントサイズを取得
float size = font.Size;
// フォントタイプを取得
PdfFontType type = font.Type;
// フォントスタイルを取得
PdfFontStyle style = font.Style;
// フォント情報をStringBuilderに追加
str.AppendLine($"フォント名: {name}, フォントサイズ: {size}\nフォントタイプ: {type}, フォントスタイル: {style}\n\n");
}
// 情報をテキストファイルに書き込む
File.WriteAllText("PDFフォント情報.txt", str.ToString());
pdf.Close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF 文書のテキストを置換する必要がある場合は多々あります。誤字脱字の修正、古い情報の更新、特定の読者や目的に合わせた内容のカスタマイズ、または法的・規制上の要件に準拠するためなどが考えられます。PDF 内のテキストを置換することで、正確性を確保し、文書の整合性を保ち、提供される情報の品質と関連性を向上させることができます。
本記事では、C# を使用して Spire.PDF for .NET ライブラリを使い、PDF 文書のテキストを置換する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PdfTextReplacer.ReplaceAllText() メソッドを提供しており、ページ内のターゲットテキストのすべての一致箇所を新しいテキストに置換することが可能です。以下は、C# で特定のページ内の一致するテキストを置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceTextInPage
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// テキスト置換のオプションを指定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.IgnoreCase;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.WholeWord;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.AutofitWidth;
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// ターゲットテキストを新しいテキストに全て置換
textReplacer.ReplaceAllText("Spire.PDF for .NET", "Spire.Pdf for .Net");
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("PDFページのテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}
文書全体のすべての一致するテキストを新しいテキストに置換するには、文書内のページを繰り返し処理し、それぞれのページで PdfTextReplacer.ReplaceAllText() メソッドを使用してテキストを置換する必要があります。
以下は、C# で PDF 文書全体の一致するテキストを置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceInEntireDocument
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// テキスト置換のオプションを指定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.IgnoreCase;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.WholeWord;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.AutofitWidth;
for (int i = 0; i < doc.Pages.Count; i++)
{
// 特定のページを取得
PdfPageBase page = doc.Pages[i];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// ターゲットテキストを新しいテキストに全て置換
textReplacer.ReplaceAllText("Spire.PDF for .NET", "Spire.Pdf for .Net");
}
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("PDF文書のテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}ページ内のすべての一致するテキストを置換する代わりに、PdfTextReplacer クラスの ReplaceText() メソッドを使用して、ターゲットテキストの最初の一致箇所のみを置換することができます。
以下は、C# でターゲットテキストの最初の一致箇所を置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceFirstOccurance
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// テキスト置換のオプションを指定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.IgnoreCase;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.WholeWord;
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.AutofitWidth;
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// ターゲットテキストの最初の出現を新しいテキストに置換
textReplacer.ReplaceText("Spire.PDF for .NET", "Spire.Pdf for .Net");
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("PDF内の最初の一致するテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}
正規表現は、テキストのパターンをマッチングし操作するための強力で柔軟な手段です。Spire.PDF では、正規表現を使用して PDF 内の特定のテキストパターンを検索し、新しい文字列に置換することが可能です。
以下は、正規表現を使用して PDF 内のテキストを置換する手順です。
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ReplaceUsingRegularExpression
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample1.pdf");
// PdfTextReplaceOptionsオブジェクトを作成
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// 置換タイプを正規表現に設定
textReplaceOptions.ReplaceType = PdfTextReplaceOptions.ReplaceActionType.Regex;
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// ページに基づいてPdfTextReplacerオブジェクトを作成
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// 置換オプションを設定
textReplacer.Options = textReplaceOptions;
// 正規表現を指定
string regularExpression = @"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b";
// 正規表現に一致するすべての出現を新しいテキストに置換
textReplacer.ReplaceAllText(regularExpression, "manager @system.com");
// ドキュメントを別のPDFファイルに保存
doc.SaveToFile("正規表現を使ってテキストを置換.pdf");
// リソースを解放
doc.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
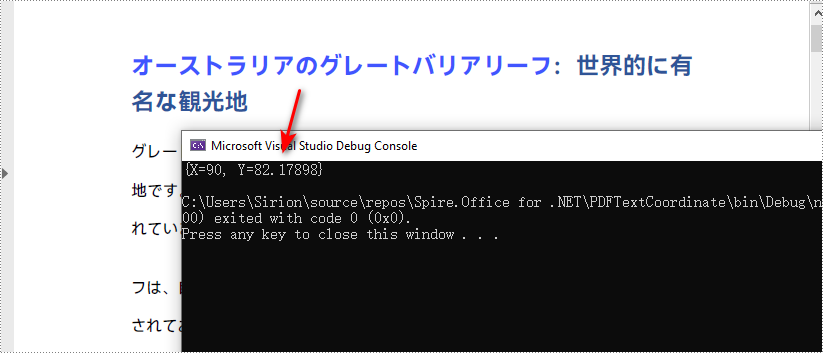
PDF ページ内のテキストや画像の座標を取得することは、ドキュメント内の特定の要素を正確に参照し、操作するために有用です。座標を抽出することで、各ページ上のテキストや画像の位置を正確に特定できます。この情報は、データ抽出、テキスト認識、特定の領域のハイライトなどに役立ちます。本記事では、C# で Spire.PDF for .NET を使用して、PDF ページ内のテキストや画像の座標情報を取得する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF が提供する PdfTextFinder.Find() メソッドを使用すると、検索可能な PDF ドキュメント内で指定した文字列のすべてのインスタンスを検索できます。特定のインスタンスの座標情報は、PdfTextFragment.Positions プロパティから取得可能です。Spire.PDF for .NET を使って PDF 内の指定されたテキストの (X, Y) 座標を取得する手順は次の通りです:
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Drawing;
namespace GetCoordinatesOfText
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// すべてのページをループ
foreach (PdfPageBase page in doc.Pages)
{
// PdfTextFinderオブジェクトを作成
PdfTextFinder finder = new PdfTextFinder(page);
// 検索オプションを設定
PdfTextFindOptions options = new PdfTextFindOptions();
options.Parameter = TextFindParameter.IgnoreCase;
finder.Options = options;
// 特定のテキストのすべてのインスタンスを検索
var fragments = finder.Find("オーストラリアのグレートバリアリーフ");
// インスタンスをループ
foreach (PdfTextFragment fragment in fragments)
{
// 特定のインスタンスの位置を取得
PointF found = fragment.Positions[0];
Console.WriteLine(found);
}
}
}
}
}
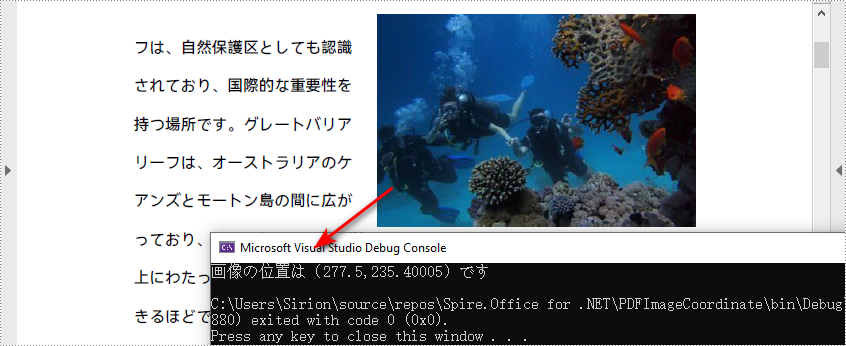
Spire.PDF は、PdfImageHelper.GetImagesInfo() メソッドを提供しており、指定されたページ内のすべての画像情報を取得できます。特定の画像の座標情報は、PdfImageInfo.Bounds プロパティを通じて取得可能です。Spire.PDF for .NET を使って PDF ドキュメント内の画像の座標を取得する手順は次の通りです:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System;
namespace GetCoordinatesOfImage
{
class Program
{
static void Main(string[] args)
{
// PdfDocumentオブジェクトを作成
PdfDocument doc = new PdfDocument();
// PDFファイルを読み込む
doc.LoadFromFile("Sample.pdf");
// 特定のページを取得
PdfPageBase page = doc.Pages[0];
// PdfImageHelperオブジェクトを作成
PdfImageHelper helper = new PdfImageHelper();
// ページから画像情報を取得
PdfImageInfo[] images = helper.GetImagesInfo(page);
// 特定の画像のX,Y座標を取得
float xPos = images[0].Bounds.X;
float yPos = images[0].Bounds.Y;
Console.WriteLine("画像の位置は({0},{1})です", xPos, yPos);
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF 文書では、テキストをハイライトすることで、読者に文書内の特定のコンテンツにもっと注意を向けさせることができます。キーワードや 文をハイライトすることで、読者に文書内の重要な情報を促し、読者がその情報を探してアクセスすることを容易にし、読書効率や読書体験を向上させることができるのです。この記事では、Spire.PDF for .NET を使用して、プログラムで PDF ドキュメント内の特定のテキストを検索してハイライトする方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPdfTextFinder.Find() メソッドで指定したテキストを検索し、PdfTextFragment.Highlight() メソッドで検索したテキストを強調表示すればいいのです。 詳しい操作手順は以下の通りです。
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
using System.Drawing;
namespace HighlightTextInPdf
{
internal class Program
{
static void Main(string[] args)
{
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.LoadFromFile("C:/サンプル.pdf");
//PdfTextFindOptionsのオブジェクトを作成する
PdfTextFindOptions findOptions = new PdfTextFindOptions();
//テキスト検索のパラメータを設定する
findOptions.Parameter = TextFindParameter.WholeWord;
//文書内のページをループする
foreach (PdfPageBase page in pdf.Pages)
{
//PdfTextFinderのオブジェクトを作成する
PdfTextFinder finder = new PdfTextFinder(page);
//テキスト検索のオプションを設定する
finder.Options = findOptions;
//指定したテキストを検索する
List results = finder.Find("時間を超越した宇宙");
//指定したテキストをすべて強調表示する
foreach (PdfTextFragment text in results)
{
text.HighLight(Color.GreenYellow);
}
}
//ドキュメントを保存する
pdf.SaveToFile("テキストの強調表示.pdf");
}
}
} Imports Spire.Pdf
Imports Spire.Pdf.Texts
Imports System.Drawing
Namespace HighlightTextInPdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'PDFドキュメントを読み込む
pdf.LoadFromFile("C:/サンプル.pdf")
'PdfTextFindOptionsのオブジェクトを作成する
Dim findOptions As PdfTextFindOptions = New PdfTextFindOptions()
'テキスト検索のパラメータを設定する
findOptions.Parameter = TextFindParameter.WholeWord
'文書内のページをループする
Dim page As PdfPageBase
For Each page In pdf.Pages
'PdfTextFinderのオブジェクトを作成する
Dim finder As PdfTextFinder = New PdfTextFinder(page)
'テキスト検索のオプションを設定する
finder.Options = findOptions
'指定したテキストを検索する
Dim results As List= finder.Find("時間を超越した宇宙")
'指定したテキストをすべて強調表示する
Dim text As PdfTextFragment
For Each text In results
text.HighLight(Color.GreenYellow)
Next
Next
'ドキュメントを保存する
pdf.SaveToFile("テキストの強調表示.pdf")
End Sub
End Class
End Namespace 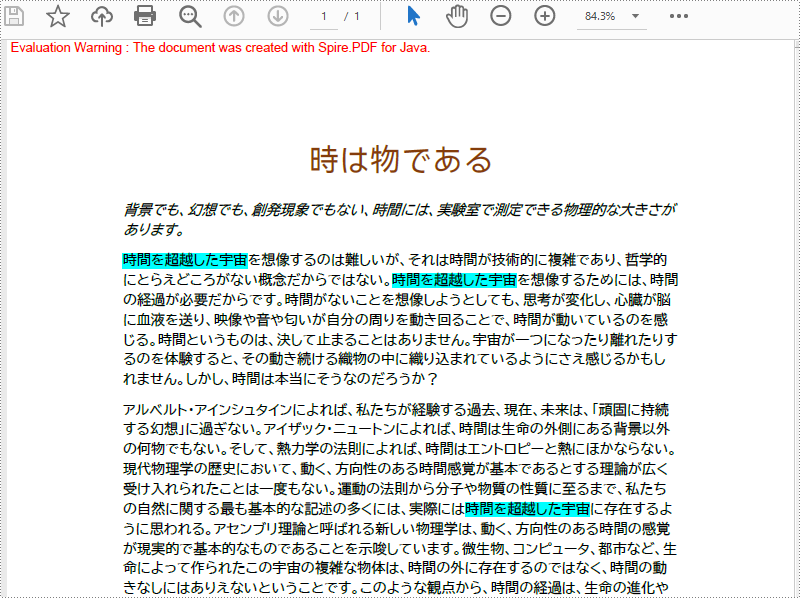
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
雑誌や新聞をデザインする際には、PDF の1ページに複数列のコンテンツをデザインすることができます。この操作は、ドキュメントの外観を豊かにするだけでなく、可読性を高めることもできます。この記事では、Spire.PDF for .NET を使用して複数列の PDF を作成する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PDF ページの2つの独立した長方形領域にテキストを描画して、複数列の PDF ドキュメントを作成するのに役立ちます。以下に詳細な操作手順を示します。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace CreateTwoColumnPDF
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentインスタンスを作成する
PdfDocument doc = new PdfDocument();
//新しいページを追加する
PdfPageBase page = doc.Pages.Add();
//段落テキストを定義する
string s1 = "Spire.PDF for .NET は、開発者が .NETプラットホームで PDF のドキュメント"
+ "を迅速かつ高品質で作成・編集・変換・印刷するために設計された専門的な PDF"
+ "処理 API です。これは完全に独立したスタンドアロン API であり、Adobe Acrobat"
+ "を実行環境にインストールする必要はありません。";
string s2 = "Spire.PDF for .NET は、タイムスタンプ付き電子署名を含むデジタル署名"
+ "などのセキュリティ設定、PDF ファイルからテキスト/添付ファイル/画像を"
+ "抽出、PDF ポートフォリオを作成、PDF ファイルを結合・分割、メタデー"
+ "タを更新、セクションを設定、グラフ/画像を挿入、図表を作成と編集、"
+ "データをインポートなど、パワフルな機能を搭載しています。";
//ページの幅と高さを取得する
float pageWidth = page.GetClientSize().Width;
float pageHeight = page.GetClientSize().Height;
//PdfSolidBrushインスタンスを作成する
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.Black));
//PdfTrueTypeFont インスタンスを作成する
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Mincho", 12f), true);
//PdfStringFormatクラスでテキストの揃え方を設定する
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Left);
//テキストを描画する
page.Canvas.DrawString(s1, font, brush, new RectangleF(0, 20, pageWidth / 2 - 8f, pageHeight), format);
page.Canvas.DrawString(s2, font, brush, new RectangleF(pageWidth / 2 + 8f, 20, pageWidth / 2, pageHeight), format);
//結果文書を保存する
doc.SaveToFile("CreateTwoColumnPDF.pdf.pdf");
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Graphics
Imports System.Drawing
Namespace CreateTwoColumnPDF
Class Program
Private Shared Sub Main(ByVal args As String)
'PdfDocumentインスタンスを作成する
Dim doc As PdfDocument = New PdfDocument()
'新しいページを追加する
Dim page As PdfPageBase = doc.Pages.Add()
'段落テキストを定義する
Dim s1 = "Spire.PDF for .NET は、開発者が .NETプラットホームで PDF のドキュメント" & "を迅速かつ高品質で作成・編集・変換・印刷するために設計された専門的な PDF" & "処理 API です。これは完全に独立したスタンドアロン API であり、Adobe Acrobat" & "を実行環境にインストールする必要はありません。"
Dim s2 = "Spire.PDF for .NET は、タイムスタンプ付き電子署名を含むデジタル署名" & "などのセキュリティ設定、PDF ファイルからテキスト/添付ファイル/画像を" & "抽出、PDF ポートフォリオを作成、PDF ファイルを結合・分割、メタデー" & "タを更新、セクションを設定、グラフ/画像を挿入、図表を作成と編集、" & "データをインポートなど、パワフルな機能を搭載しています。"
'ページの幅と高さを取得する
Dim pageWidth As Single = page.GetClientSize().Width
Dim pageHeight As Single = page.GetClientSize().Height
'PdfSolidBrushインスタンスを作成する
Dim brush As PdfSolidBrush = New PdfSolidBrush(New PdfRGBColor(Color.Black))
'PdfTrueTypeFont インスタンスを作成する
Dim font As PdfTrueTypeFont = New PdfTrueTypeFont(New Font("Yu Mincho", 12F), True)
'PdfStringFormatクラスでテキストの揃え方を設定する
Dim format As PdfStringFormat = New PdfStringFormat(PdfTextAlignment.Left)
'テキストを描画する
page.Canvas.DrawString(s1, font, brush, New RectangleF(0, 20, pageWidth / 2 - 8F, pageHeight), format)
page.Canvas.DrawString(s2, font, brush, New RectangleF(pageWidth / 2 + 8F, 20, pageWidth / 2, pageHeight), format)
'結果文書を保存する
doc.SaveToFile("CreateTwoColumnPDF.pdf.pdf")
End Sub
End Class
End Namespace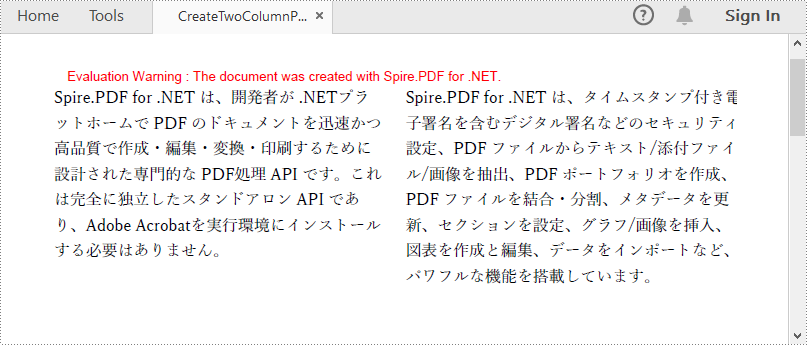
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





