チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション
Markdown は、そのシンプルさと読みやすさから、ライターや開発者に人気のフォーマットです。プレーンテキストの構文を使って簡単にコンテンツをフォーマットすることができます。しかし、Markdown ファイルを Word ドキュメントや PDF ファイルなどの汎用的なフォーマットに変換することは、ドキュメントを他のユーザーと共有したり、複雑なフォーマットを可能にしたり、デバイスやプラットフォーム間で互換性と一貫性を確保したりするために不可欠です。この記事では、Spire.Doc for Java を使って、Markdown ファイルを Word と PDF ファイルに変換する方法を紹介します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.4.14</version>
</dependency>
</dependencies>Spire.Doc for Java は、Document.loadFromFile(String: fileName, FileFormat.Markdown) メソッドを使って Markdown ファイルを読み込み、Document.saveToFile(String: fileName, FileFormat: fileFormat) メソッドを使って Word ドキュメントとして保存することで、Markdown 形式を Word ドキュメント形式と PDF ドキュメント形式に変換する簡単な方法を提供しています。
Markdown ファイルには画像がリンクとして格納されているため、変換後に画像を保持したい場合は、さらに処理する必要があることに注意してください。
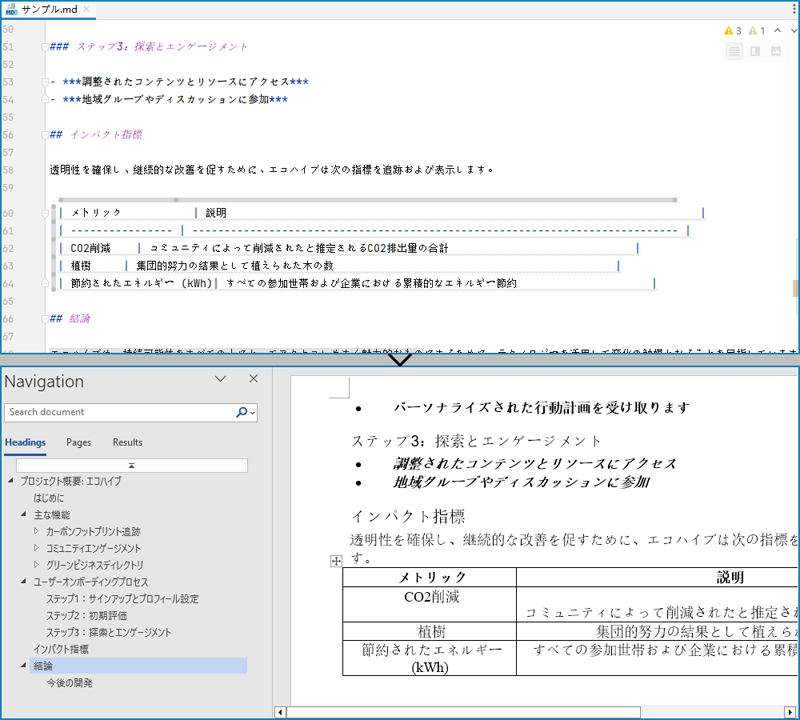
Markdown ファイルを Word ドキュメントに変換する手順は以下のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class MarkdownToWord {
public static void main(String[] args) {
// Documentクラスのインスタンスを作成します。
Document doc = new Document();
// Markdownファイルを読み込みます。
doc.loadFromFile("サンプル.md", FileFormat.Markdown);
// MarkdownファイルをWordドキュメントとして保存します。
doc.saveToFile("output/MarkdownをWordに変換.docx", FileFormat.Docx);
// リソースを解放します。
doc.dispose();
}
}
Document.saveToFile() メソッドのフォーマットパラメータとして FileFormat.PDF Enum を使用することで、Markdown ファイルを直接 PDF ドキュメントに変換することができます。
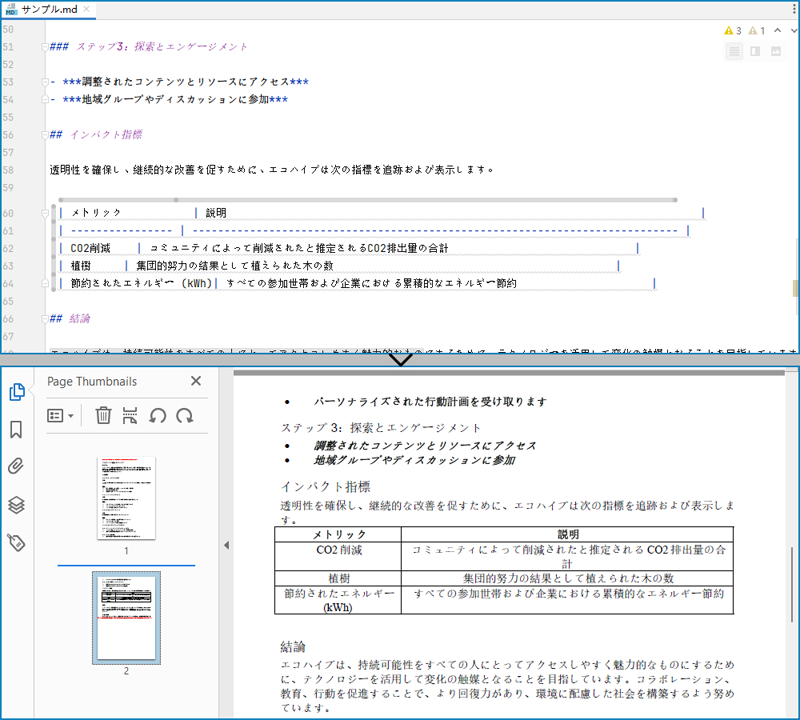
Markdown ファイルを PDF ドキュメントに変換する手順は以下のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class MarkdownToPDF {
public static void main(String[] args) {
// Documentクラスのインスタンスを作成します。
Document doc = new Document();
// Markdownファイルを読み込みます。
doc.loadFromFile("サンプル.md");
// MarkdownファイルをPDFファイルとして保存します。
doc.saveToFile("output/MarkdownをPDFに変換.pdf", FileFormat.PDF);
// リソースを解放します。
doc.dispose();
}
}
Spire.Doc for Java は、PageSetup クラスに、変換前にページ設定を行うためのメソッドを提供しています。これにより、変換後のドキュメントのページ余白やページサイズなどのページ設定を制御することができます。
変換後のドキュメントのページ設定をカスタマイズする手順は以下のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.PageSetup;
import com.spire.doc.Section;
import com.spire.doc.documents.MarginsF;
import com.spire.doc.documents.PageOrientation;
import com.spire.doc.documents.PageSize;
public class PageSettingMarkdown {
public static void main(String[] args) {
// Documentクラスのインスタンスを作成します。
Document doc = new Document();
// Markdownファイルを読み込みます。
doc.loadFromFile("サンプル.md");
// 最初のセクションを取得します。
Section section = doc.getSections().get(0);
// ページ設定を取得します。
PageSetup pageSetup = section.getPageSetup();
// ページサイズ、向き、余白を設定します。
pageSetup.setPageSize(PageSize.Letter);
pageSetup.setOrientation(PageOrientation.Landscape);
pageSetup.setMargins(new MarginsF(100, 100, 100, 100));
// MarkdownファイルをPDFファイルとして保存します。
doc.saveToFile("output/MarkdownをPDFに変換.pdf", FileFormat.PDF);
// リソースを解放します。
doc.dispose();
}
}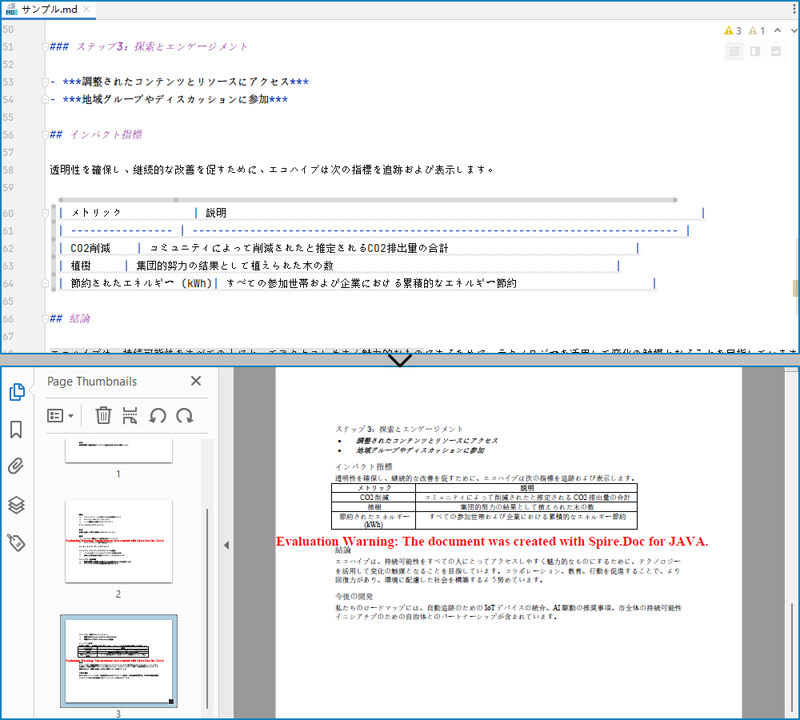
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word と Excel ファイルは、使用目的と機能において異なります。Word はエッセイ、メール、手紙、書籍、履歴書、学術論文などのテキスト文書を作成するために主に使用され、テキストのフォーマットが重要です。Excel はデータの保存、テーブルやグラフの作成、複雑な計算を行うために使用されます。
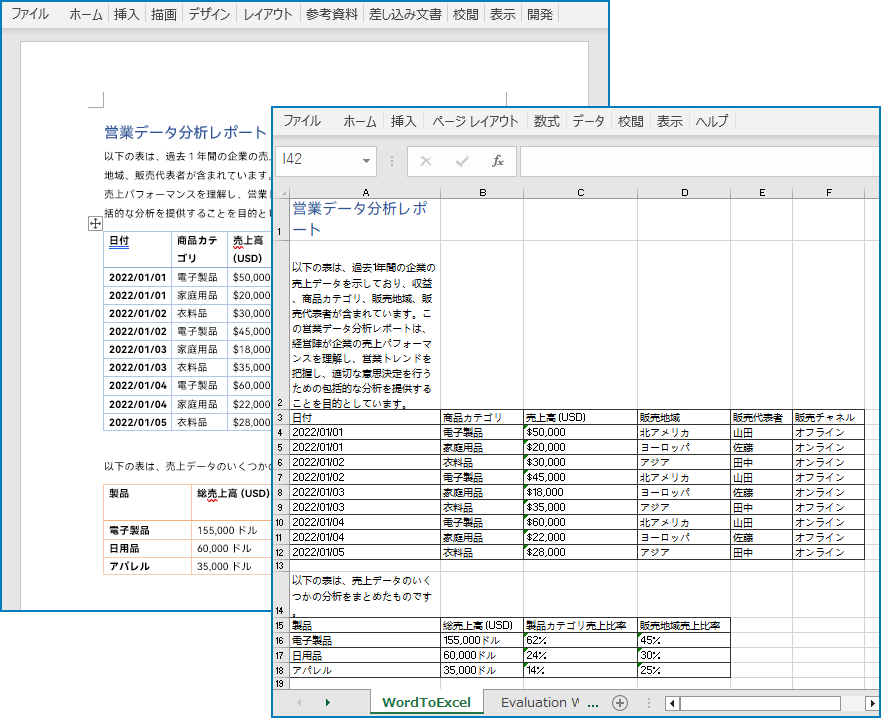
複雑な Word ファイルを Excel スプレッドシートに変換することはお勧めできません。なぜなら、Excel は Word と同じように内容を表示することができないからです。ただし、Wordドキュメントが主にテーブルで構成されており、Excel でテーブルデータを分析したい場合は、Spire.Office for Java を使用して Word を Excel に変換することができます。このコード例では、良好な読みやすさを保ちながら、Word ドキュメントを Excel ファイルに変換します。
まず、Spire.Office for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>8.12.0</version>
</dependency>
</dependencies>このシナリオでは、Spire.Office パッケージ内の2つのライブラリ、Spire.Doc for Java と Spire.XLS for Java を使用します。前者は Word ドキュメントからコンテンツを読み取り、抽出するために使用され、後者は Excel ドキュメントを作成し、特定のセルにデータを書き込むために使用されます。このコード例を理解しやすくするために、次の3つのカスタムメソッドを作成しました。
以下の手順は、Spire.Office for Java を使用して Word ドキュメントからワークシートにデータをエクスポートする方法を示しています。
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextRange;
import com.spire.xls.*;
import java.awt.*;
public class ConvertWordToExcel {
public static void main(String[] args) {
// ドキュメントオブジェクトを作成します
Document doc = new Document();
// Wordファイルをロードします
doc.loadFromFile("サンプル.docx");
// ワークブックオブジェクトを作成します
Workbook wb = new Workbook();
// デフォルトのワークシートを削除します
wb.getWorksheets().clear();
// "WordToExcel"という名前のワークシートを作成します
Worksheet worksheet = wb.createEmptySheet("WordToExcel");
int row = 1;
int column = 1;
// Wordドキュメント内のセクションをループします
for (int i = 0; i < doc.getSections().getCount(); i++) {
// 特定のセクションを取得します
Section section = doc.getSections().get(i);
// 特定のセクションの下にあるドキュメントオブジェクトをループします
for (int j = 0; j < section.getBody().getChildObjects().getCount(); j++) {
// 特定のドキュメントオブジェクトを取得します
DocumentObject documentObject = section.getBody().getChildObjects().get(j);
// オブジェクトが段落かどうかを判断します
if (documentObject instanceof Paragraph) {
CellRange cell = worksheet.getCellRange(row, column);
Paragraph paragraph = (Paragraph) documentObject;
// Wordから特定のセルに段落をコピーします
copyTextAndStyle(cell, paragraph);
row++;
}
// オブジェクトがテーブルかどうかを判断します
if (documentObject instanceof Table) {
Table table = (Table) documentObject;
// WordからExcelにテーブルデータをエクスポートします
int currentRow = exportTableInExcel(worksheet, row, table);
row = currentRow;
}
}
}
// セル内のテキストを折り返します
worksheet.getAllocatedRange().isWrapText(true);
// 行の高さと列の幅を自動調整します
worksheet.getAllocatedRange().autoFitRows();
worksheet.getAllocatedRange().autoFitColumns();
worksheet.setColumnWidth(1, 30);
// ワークブックをExcelファイルに保存します
wb.saveToFile("output/WordをExcelに変換.xlsx", ExcelVersion.Version2016);
}
// WordのテーブルからExcelのセルにデータをエクスポートします
private static int exportTableInExcel(Worksheet worksheet, int row, Table table) {
CellRange cell;
int column;
for (int i = 0; i < table.getRows().getCount(); i++) {
column = 1;
TableRow tbRow = table.getRows().get(i);
for (int j = 0; j < tbRow.getCells().getCount(); j++) {
TableCell tbCell = tbRow.getCells().get(j);
cell = worksheet.getCellRange(row, column);
cell.borderAround(LineStyleType.Thin, Color.BLACK);
copyContentInTable(tbCell, cell);
column++;
}
row++;
}
return row;
}
// WordのテーブルセルからExcelのセルにコンテンツをコピーします
private static void copyContentInTable(TableCell tbCell, CellRange cell) {
Paragraph newPara = new Paragraph(tbCell.getDocument());
for (int i = 0; i < tbCell.getChildObjects().getCount(); i++) {
DocumentObject documentObject = tbCell.getChildObjects().get(i);
if (documentObject instanceof Paragraph) {
Paragraph paragraph = (Paragraph) documentObject;
for (int j = 0; j < paragraph.getChildObjects().getCount(); j++) {
DocumentObject cObj = paragraph.getChildObjects().get(j);
newPara.getChildObjects().add(cObj.deepClone());
}
if (i < tbCell.getChildObjects().getCount() - 1) {
newPara.appendText("\n");
}
}
}
copyTextAndStyle(cell, newPara);
}
// 段落のテキストとスタイルをセルにコピーします
private static void copyTextAndStyle(CellRange cell, Paragraph paragraph) {
RichText richText = cell.getRichText();
richText.setText(paragraph.getText());
int startIndex = 0;
for (int i = 0; i < paragraph.getChildObjects().getCount(); i++) {
DocumentObject documentObject = paragraph.getChildObjects().get(i);
if (documentObject instanceof TextRange) {
TextRange textRange = (TextRange) documentObject;
String fontName = textRange.getCharacterFormat().getFontName();
boolean isBold = textRange.getCharacterFormat().getBold();
Color textColor = textRange.getCharacterFormat().getTextColor();
float fontSize = textRange.getCharacterFormat().getFontSize();
String textRangeText = textRange.getText();
int strLength = textRangeText.length();
ExcelFont font = new ExcelFont(cell.getWorksheet().getWorkbook().createFont());
font.setColor(textColor);
font.isBold(isBold);
font.setSize(fontSize);
font.setFontName(fontName);
int endIndex = startIndex + strLength;
richText.setFont(startIndex, endIndex, font);
startIndex += strLength;
}
if (documentObject instanceof DocPicture) {
DocPicture picture = (DocPicture) documentObject;
cell.getWorksheet().getPictures().add(cell.getRow(), cell.getColumn(), picture.getImage());
cell.getWorksheet().setRowHeightInPixels(cell.getRow(), 1, picture.getImage().getHeight());
}
}
switch (paragraph.getFormat().getHorizontalAlignment()) {
case Left:
cell.setHorizontalAlignment(HorizontalAlignType.Left);
break;
case Center:
cell.setHorizontalAlignment(HorizontalAlignType.Center);
break;
case Right:
cell.setHorizontalAlignment(HorizontalAlignType.Right);
break;
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PostScript(ポストスクリプト)は、1984 年に Adobe が設計したページ記述言語であり、印刷のために使用されます。PostScript 言語で記述されたファイルには、テキスト、ラスター/ベクターグラフィックスが含まれることがあり、PostScript をサポートするどのプリンターでも、アプリケーションで開くことなく印刷することができます。一部の場合では、Word 文書を PostScript に変換する必要があるかもしれません。この記事では、Spire.Doc for Java を使用して、Java で Word 文書を PostScript ファイルに変換する方法を説明します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.1.0</version>
</dependency>
</dependencies>以下は、Word ドキュメントを PostScript ファイルに変換する手順です:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class ConvertWordToPostScript {
public static void main(String[] args) {
// Documentクラスのオブジェクトを作成する
Document doc = new Document();
// Word文書をロードする
doc.loadFromFile("サンプル.docx");
// 文書をPostScriptに変換して保存する
doc.saveToFile("output/WordからPostScriptへの変換.ps", FileFormat.Post_Script);
doc.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
HTML(Hypertext Markup Language) は、インターネット上で最も一般的に使用されるテキストマークアップ言語の1つとなり、ほぼすべてのウェブページは HTML を使用して作成されます。HTML には多くのタグや書式情報が含まれていますが、最も価値のあるコンテンツは通常、表示されるテキストです。テキストを HTML ファイルから抽出する方法を知っておくことは重要です。これを利用して編集、AI のトレーニング、またはデータベースへの保存などのタスクに使用するユーザーがいる場合です。この記事では、Java プログラム内で Spire.Doc for Java を使用して HTML からテキストを抽出する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.12.1</version>
</dependency>
</dependencies>Spire.Doc for Java では、Document.loadFromFile(filename, FileFormat.Html) メソッドを使用して HTML ファイルを読み込むことができます。その後、Document.getText() メソッドを使用してブラウザで表示されるテキストを取得し、それを TXT ファイルに書き込むことができます。具体的な手順は以下の通りです:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromHTML {
public static void main(String[] args) throws IOException {
// Documentクラスのオブジェクトを作成します
Document doc = new Document();
// HTMLファイルを読み込みます
doc.loadFromFile("サンプル.html", FileFormat.Html);
// HTMLファイルからテキストを取得します
String text = doc.getText();
// テキストをTXTファイルに書き込みます
FileWriter fileWriter = new FileWriter("HTMLのテキスト.txt");
fileWriter.write(text);
fileWriter.close();
}
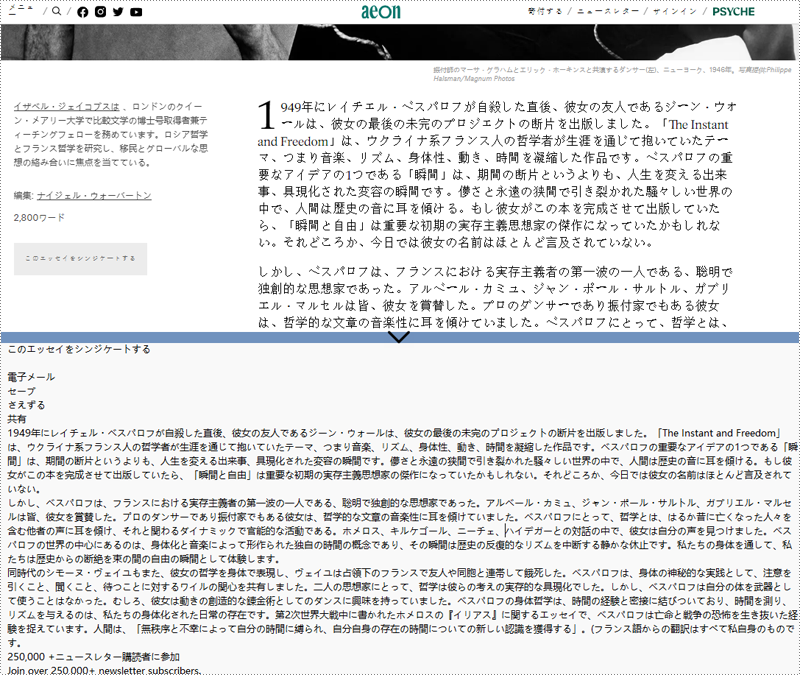
}
URL からテキストを抽出するには、ユーザーは HTML ファイルを URL から取得し、その後テキストを抽出するためにカスタムメソッドを作成する必要があります。具体的な手順は以下の通りです:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
public class ExtractTextFromURL {
public static void main(String[] args) throws IOException {
// Documentクラスのオブジェクトを作成します
Document doc = new Document();
// カスタムメソッドを呼び出してURLからHTMLファイルを読み込みます
doc.loadFromFile(readHTML("https://aeon.co/essays/for-rachel-bespaloff-philosophy-was-a-sensual-activity", "output.html"), FileFormat.Html);
// HTMLファイルからテキストを取得します
String urlText = doc.getText();
// テキストをTXTファイルに書き込みます
FileWriter fileWriter = new FileWriter("URLのテキスト.txt");
fileWriter.write(urlText);
fileWriter.close();
}
public static String readHTML(String urlString, String saveHtmlFilePath) throws IOException {
// URLクラスのオブジェクトを作成します
URL url = new URL(urlString);
// URLを開きます
URLConnection connection = url.openConnection();
// URLをHTMLファイルとして保存します
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(saveHtmlFilePath), "UTF-8"));
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
reader.close();
writer.close();
// 保存されたHTMLファイルのファイルパスを返します
return saveHtmlFilePath;
}
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
EPUB は人気の電子書籍ファイルフォーマットです。このフォーマットは、ほとんどの電子リーダー、スマートフォン、タブレット、パソコンで読むことをサポートしています。時には、読みやすいように Word ドキュメントを EPUB ファイルに変換するのも良い選択です。この記事では、Spire.Doc for Java を使用して Word を EPUB 変換する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.11.6</version>
</dependency>
</dependencies>Spire.Doc for Java が提供する Document.saveToFile() メソッドは、Word を EPUB に変換することをサポートしています。次に、具体的な変換手順を示します。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class ConvertWordToEpub {
public static void main(String[] args){
//Documentインスタンスを作成する
Document doc = new Document();
//Wordドキュメントをロードする
doc.loadFromFile("Sample.docx");
//WordをEPUBに保存する
doc.saveToFile("ToEpub.epub", FileFormat.E_Pub);
}
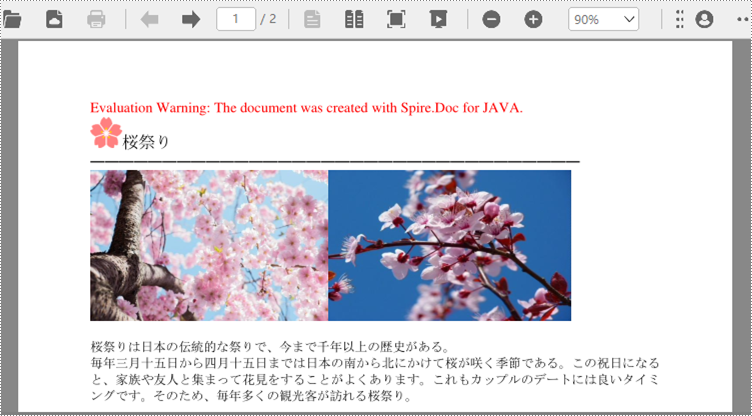
}
Spire.Doc for Java が提供する Document.saveToEpub(String, DocPicture) メソッドは、Word を表紙付き EPUB に変換することをサポートしています。次に、具体的な変換手順を示します。
import com.spire.doc.Document;
import com.spire.doc.fields.DocPicture;
public class ConvertWordToEpubWithCoverImage {
public static void main(String[] args){
//Documentインスタンスを作成する
Document doc = new Document();
//Wordドキュメントをロードする
doc.loadFromFile("Sample.docx");
//DocPictureインスタンスを作成する
DocPicture picture = new DocPicture(doc);
//画像をロードする
picture.loadImage("Cover.png");
// Wordを表紙付きEPUBに保存する
doc.saveToEpub("ToEpubWithCoverImage.epub", picture);
}
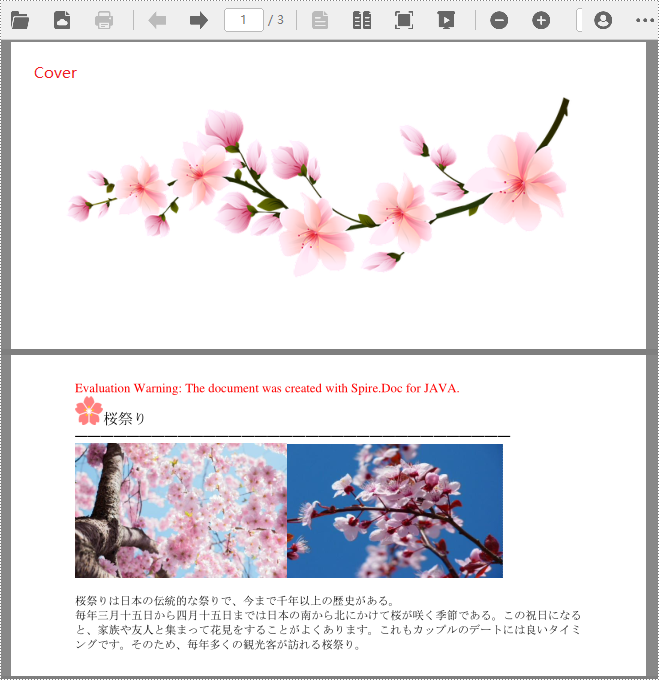
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
契約書などの機密文書を保存または転送する必要がある場合は、Word をパスワードで保護された PDF 文書形式に変換することができます。この方法により、ドキュメントのフォーマットが変更されないようにするだけでなく、ドキュメントの内容が漏れるのを防ぐことができます。この記事では、Spire.Doc for Java を使用して Word をパスワードで保護された PDF に変換する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.11.6</version>
</dependency>
</dependencies>Spire.Doc for Java を使用すると、開発者は Document.saveToFile(String, ToPdfParameterList) メソッドを使用して Word ドキュメントをパスワードで保護された PDF ドキュメントに変換することができます。ToPdfParameterList パラメータは、変換時に文書を暗号化するかどうかなど、Word 文書が PDF に変換される方法をコントロールします。次は詳細な操作手順です。
import com.spire.doc.Document;
import com.spire.doc.ToPdfParameterList;
import com.spire.pdf.security.PdfEncryptionKeySize;
import com.spire.pdf.security.PdfPermissionsFlags;
public class ConvertWordToPasswordProtectedPDF {
public static void main(String[] args){
//Documentインスタンスを作成する
Document document = new Document(false);
//Wordドキュメントをロードする
document.loadFromFile("Sample.docx");
//ToPdfParameterListインスタンスを作成する
ToPdfParameterList toPdf = new ToPdfParameterList();
//PDFのオープンパスワードとパーミッションパスワードを設定する
String password = "password";
toPdf.getPdfSecurity().encrypt(password, password, PdfPermissionsFlags.None, PdfEncryptionKeySize.Key_128_Bit);
//Wordをパスワードで保護されたPDFとして保存する
document.saveToFile("ToPdfWithPassword.pdf", toPdf);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
多くの理由で、Word ドキュメントをイメージに変換する必要がある場合があります。例えば、多くのデバイスは、特別なソフトウェアを必要とせずにイメージを直接開いて表示することができます。また、イメージ伝送は、コンテンツが他の人によって変更されないようにすることもできます。この記事では、Spire.Doc for Java を使用して Word をイメージに変換する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.9.8</version>
</dependency>
</dependencies>Spire.Doc for Java が提供する Document.saveToImages() メソッドは、Word 文書のページを Bitmap または Metafile に変換します。その後、Bitmap または Metafile は、BMP、EMF、JPEG、PNG、GIF または WMF 書式のイメージとして保存することができます。以下は Word を JPG に変換するための詳細な手順です。
import com.spire.doc.Document;
import com.spire.doc.documents.ImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertWordToJPG {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成する
Document doc = new Document();
//Word文書をロードする
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\ConvertTemplate.docx");
//文書全体のページをイメージに変換する
BufferedImage[] images = doc.saveToImages(ImageType.Bitmap);
//イメージをループする
for (int i = 0; i < images.length; i++) {
//指定されたイメージを取得する
BufferedImage image = images[i];
//異なる色空間でイメージを再書き込み
BufferedImage newImg = new BufferedImage(image.getWidth(), image.getHeight(), BufferedImage.TYPE_INT_RGB);
newImg.getGraphics().drawImage(image, 0, 0, null);
//JPGファイルに書き込む
File file = new File("C:\\Users\\Administrator\\Desktop\\Images\\" + String.format(("Image-%d.jpg"), i));
ImageIO.write(newImg, "JPEG", file);
}
}
}Spire.Doc for Java を使用して Word 文書を一連のバイト配列として保存し、SVG 文書にそれぞれ書き込むことができます。Word を SVG に変換するための詳細な手順は次のとおりです。
import com.spire.doc.Document;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
public class ConvertWordToSVG {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成する
Document doc = new Document();
//Word文書をロードする
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\ConvertTemplate.docx");
//新しいエンジンを使用して変換する
doc.setUseNewEngine(true);
//文書をバイト配列キューとして保存する
List svgBytes = doc.saveToSVG();
//すべてのアイテムをループする
for (int i = 0; i < svgBytes.size(); i++)
{
//指定されたバイト配列を取得する
byte[] byteArray = svgBytes.get(i);
//出力ファイル名を指定する
String outputFile = String.format("Image-%d.svg", i);
//SVGファイルにバイト配列を書き込む
try (FileOutputStream stream = new FileOutputStream("C:\\Users\\Administrator\\Desktop\\Images\\" + outputFile)) {
stream.write(byteArray);
}
}
}
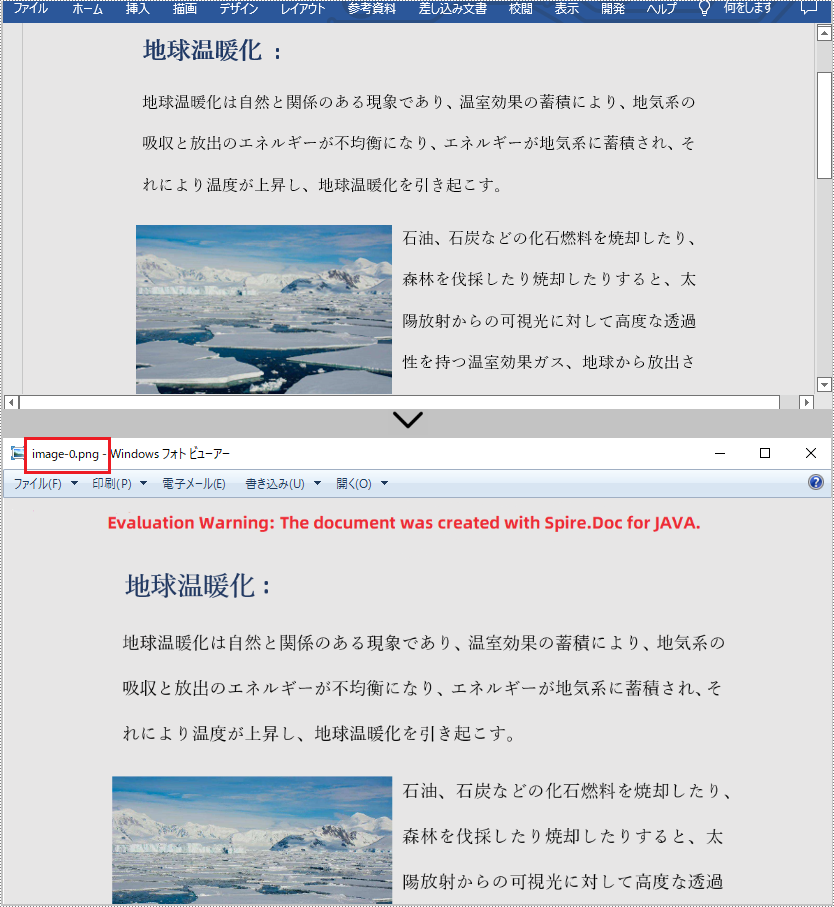
} より解像度の高いイメージはコンテンツをより明確に表示することができます。以下の手順に従って、Word を PNG に変換するときに、イメージ解像度を設定することができます。
import com.spire.doc.Document;
import com.spire.doc.documents.ImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertWordToPNG {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成する
Document doc = new Document();
//Word文書をロードする
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\ConvertTemplate.docx");
//文書全体のページをイメージに変換する
BufferedImage[] images = doc.saveToImages(0, doc.getPageCount(), ImageType.Bitmap, 150, 150);
//イメージをループする
for (int i = 0; i < images.length; i++) {
//指定されたイメージを取得する
BufferedImage image = images[i];
//PNGファイルに書き込む
File file = new File("C:\\Users\\Administrator\\Desktop\\Images\\" + String.format(("Image-%d.png"), i));
ImageIO.write(image, "PNG", file);
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
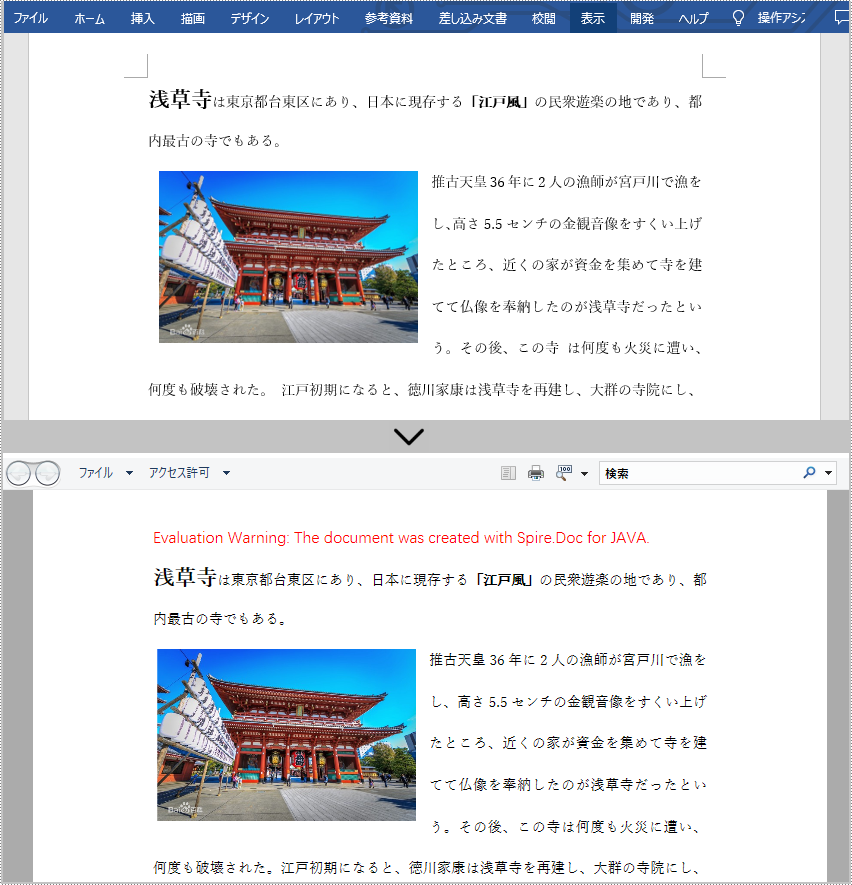
日常的な仕事では、Word ドキュメントを他のファイル形式に変換するのは非常に一般的な機能です。たとえば、Word ドキュメントを XML に変換してデータを保存し、整理する必要がある場合があります。あるいは場合によっては、インターネット上でグラフィックコンテンツを共有するために Word を SVG に変換する必要がある場合もあります。この記事では、Spire.Doc for Java を使用して Word を XPS、XML、RTF、TXT、SVG に変換する方法を説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.3.0</version>
</dependency>
</dependencies>詳細な手順は次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.ImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertWordToOtherFormats {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成する
Document doc = new Document();
//サンプルドキュメントをロードする
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\sample.docx");
//ドキュメントをSVGとして保存する
doc.saveToFile("output/ToSVG.svg",FileFormat.SVG);
//ドキュメントをRTFとして保存する
doc.saveToFile("output/ToRTF.rtf",FileFormat.Rtf);
//ドキュメントをXPSとして保存する
doc.saveToFile("output/ToXPS.xps",FileFormat.XPS);
//ドキュメントをXMLとして保存する.
doc.saveToFile("output/ToXML.xml",FileFormat.Xml);
//ドキュメントをTXTとして保存する
doc.saveToFile("output/ToTXT.txt",FileFormat.Txt);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
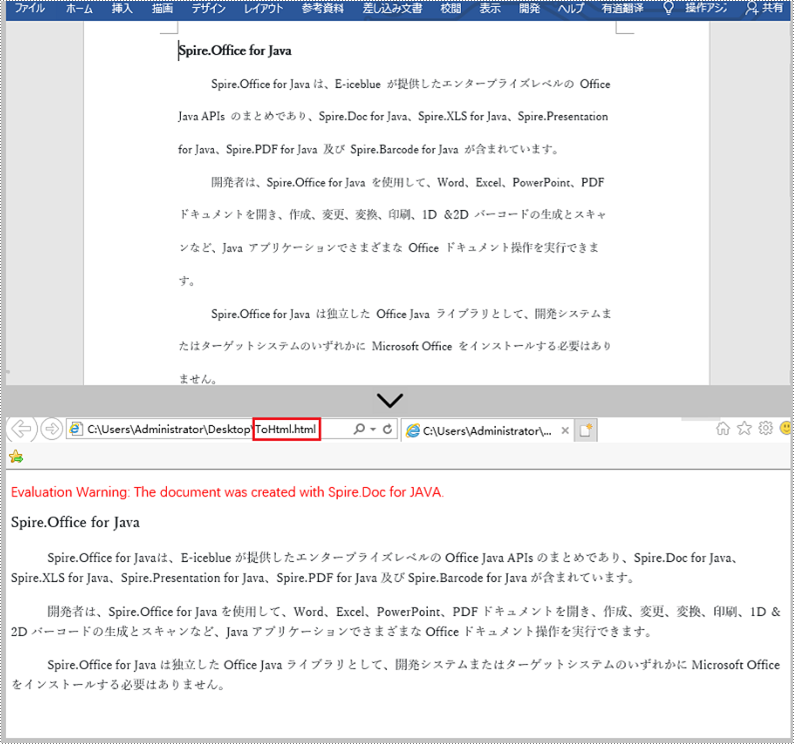
HTML ドキュメントは HTML でエンコードされた Web ページで、Web ブラウザで表示できます。ほとんどの静的なページには .html 拡張子があるため、Web 上で広く使用されています。時々、Word を HTML に変換する必要があります。この記事では、Spire.Doc for Java を使用して Word を HTML に変換する方法を説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>以下の手順に従って、Word ドキュメントを HTML 形式に変換できます。
import com.spire.doc.*;
public class WordToHtml {
public static void main(String[] args) {
// Documentクラスのインスタンスを作成する
Document document = new Document();
// Word ドキュメントをロードする
document.loadFromFile("Sample.docx");
// Html形式で保存する
document.saveToFile("ToHtml.html", FileFormat.Html);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
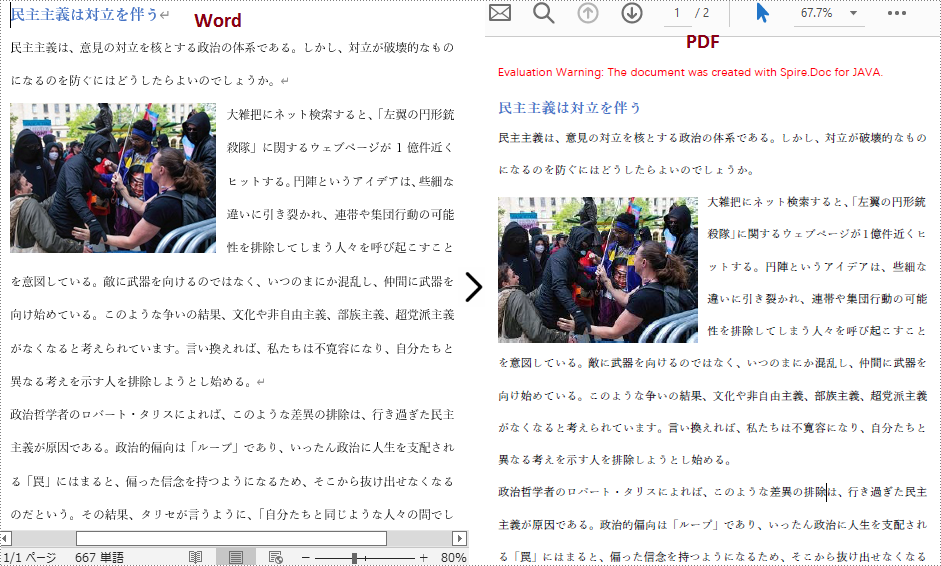
Spire.Doc for Java は、Word を PDF、XPS、SVG、HTML などの他のドキュメント形式に変換するための Document.saveToFile() メソッドを提供しています。この記事では、Spire.Doc for Java を使用して Word を PDF に変換する方法について紹介します。さらに、Word ドキュメントをどのように PDF に変換するかを制御するために、ToPdfParameterList クラスを導入しています。例えば、生成される PDF ドキュメント内のハイパーリンクを無効にするかどうかなどです。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>以下は、Word を PDF に変換するための詳細な手順です。
import com.spire.doc.Document;
import com.spire.doc.ToPdfParameterList;
public class WordToPDF {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("実例.docx");
//ToPdfParameterListクラスのインスタンスを作成する
ToPdfParameterList ppl=new ToPdfParameterList();
//PDFドキュメントにすべての書体を埋め込む
ppl.isEmbeddedAllFonts(true);
//ハイパーリンクを削除し、文字の書式を維持する
ppl.setDisableLink(true);
//出力画質を原画の40%に設定します。80%は初期設定です。
doc.setJPEGQuality(40);
//ドキュメントをPDFで保存する
doc.saveToFile("WordToPDF.pdf", ppl);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





