チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション
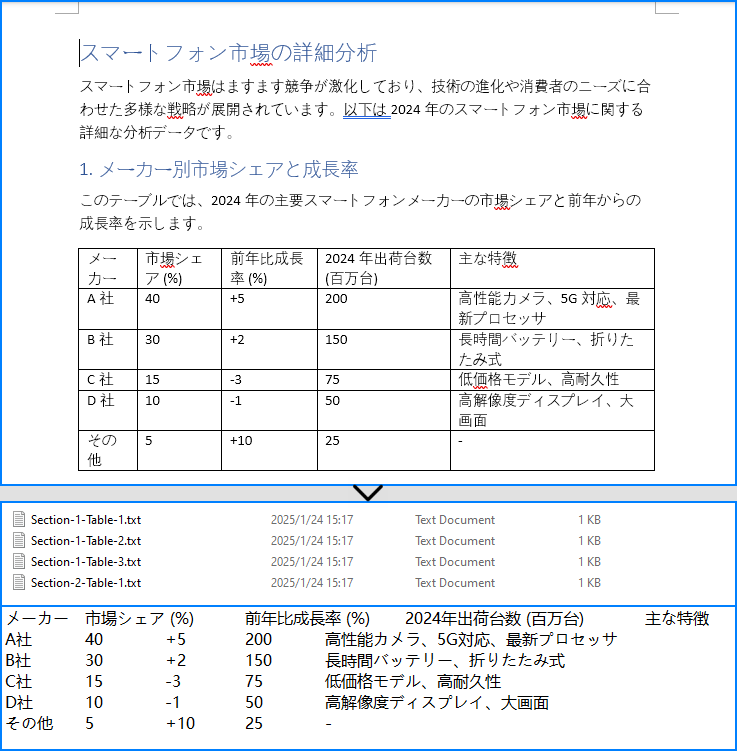
Word 文書には重要なデータを含む表がよくあります。この表からデータを抽出することは、さらなる分析やレポート作成、コンテンツの再作成など、さまざまなシナリオで使用できます。Java を使用して Word 文書から表を自動的に抽出することで、開発者は効率的にこの構造化データにアクセスし、データベースやスプレッドシートなどに適した形式に変換することができ、このデータをさまざまなシナリオで活用できます。本記事では、Spire.Doc for Java を使用して、Java プロジェクトで Word 文書から表を抽出する方法を紹介します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.1.3</version>
</dependency>
</dependencies>Spire.Doc for Java を使用すると、開発者は Section.getTables() メソッドを利用して Word 文書から表を抽出できます。表のデータは、行とセルを繰り返し処理することでアクセスできます。表抽出の手順は以下の通りです:
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractWordTable {
public static void main(String[] args) {
// Documentオブジェクトを作成します
Document doc = new Document();
try {
// Wordドキュメントを読み込みます
doc.loadFromFile("Sample.docx");
// ドキュメント内のセクションを繰り返し処理します
for (int i = 0; i < doc.getSections().getCount(); i++) {
// セクションを取得します
Section section = doc.getSections().get(i);
// セクション内のテーブルを繰り返し処理します
for (int j = 0; j < section.getTables().getCount(); j++) {
// テーブルを取得します
Table table = section.getTables().get(j);
// テーブルの内容を収集します
StringBuilder tableText = new StringBuilder();
for (int k = 0; k < table.getRows().getCount(); k++) {
// 行を取得します
TableRow row = table.getRows().get(k);
// 行内のセルを繰り返し処理します
StringBuilder rowText = new StringBuilder();
for (int l = 0; l < row.getCells().getCount(); l++) {
// セルを取得します
TableCell cell = row.getCells().get(l);
// セル内の段落を繰り返し処理してテキストを取得します
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
cellText += paragraph.getText() + " ";
}
if (l < row.getCells().getCount() - 1) {
rowText.append(cellText).append("\t");
} else {
rowText.append(cellText).append("\n");
}
}
tableText.append(rowText);
}
// try-with-resourcesを使用して、テーブルの内容をファイルに書き込みます
try (FileWriter writer = new FileWriter("output/Tables/Section-" + (i + 1) + "-Table-" + (j + 1) + ".txt")) {
writer.write(tableText.toString());
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
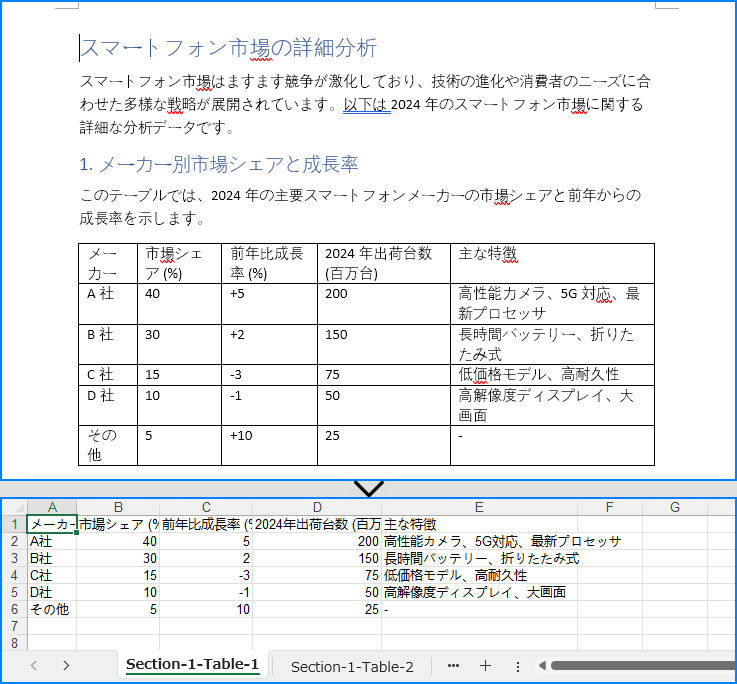
開発者は Spire.Doc for Java と Spire.XLS for Java を組み合わせて、Word 文書から表データを抽出し、Excel ワークシートに書き込むことができます。まず、Spire.XLS for Java をダウンロードするか、以下の Maven 設定を追加します:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>15.1.3</version>
</dependency>
</dependencies>Word 文書から Excel ワークブックに表を抽出する詳細な手順は以下の通りです:
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractWordTableToExcel {
public static void main(String[] args) {
// Documentオブジェクトを作成します
Document doc = new Document();
// Workbookオブジェクトを作成します
Workbook workbook = new Workbook();
// デフォルトのワークシートを削除します
workbook.getWorksheets().clear();
try {
// Wordドキュメントを読み込みます
doc.loadFromFile("Sample.docx");
// ドキュメント内のセクションを繰り返し処理します
for (int i = 0; i < doc.getSections().getCount(); i++) {
// セクションを取得します
Section section = doc.getSections().get(i);
// セクション内のテーブルを繰り返し処理します
for (int j = 0; j < section.getTables().getCount(); j++) {
// テーブルを取得します
Table table = section.getTables().get(j);
// 各テーブル用のワークシートを作成します
Worksheet sheet = workbook.getWorksheets().add("Section-" + (i + 1) + "-Table-" + (j + 1));
for (int k = 0; k < table.getRows().getCount(); k++) {
// 行を取得します
TableRow row = table.getRows().get(k);
for (int l = 0; l < row.getCells().getCount(); l++) {
// セルを取得します
TableCell cell = row.getCells().get(l);
// セル内の段落を繰り返し処理してテキストを取得します
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
if (m > 0 && m < cell.getParagraphs().getCount() - 1) {
cellText += paragraph.getText() + "\n";
} else {
cellText += paragraph.getText();
}
// セルのテキストを対応するワークシートのセルに書き込みます
sheet.getRange().get(k + 1, l + 1).setValue(cellText);
}
// 列の自動調整を行います
sheet.autoFitColumn(l + 1);
}
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
// Excelファイルとして保存します
workbook.saveToFile("output/WordTableToExcel.xlsx", FileFormat.Version2016);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
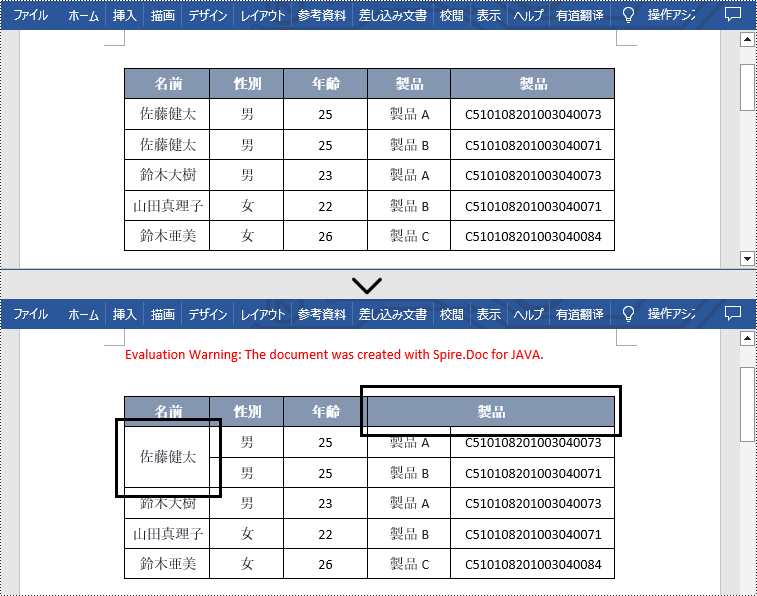
Spire.Doc for Java で提供される Table.applyVerticalMerge() メソッドと Table.applyHorizontalMerge() メソッドは、それぞれ表のセルを垂直に結合するときと水平に結合するときに使用されます。デフォルトでは、結合するセルに同じ値が複数含まれている場合、結合後のセルにもこれらの重複した値が含まれます。表をより明瞭にするために、重複した値を削除することができます。この記事では、Spire.Doc for Java を使用して Word でセルを結合する際に重複した値を削除する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>セルを結合するときに重複した値を削除するには、mergeCell(Table table, boolean isHorizontalMerge, int index, int start, int end) のカスタムメソッドを作成します。このメソッドでは、結合された範囲内の最初のセルの値が範囲内の他のセルの値と同じかどうかを判断します。それらが同じである場合は、他のセルの値を削除してからセルを結合します。詳細な手順は次のとおりです。
import com.spire.doc.*;
public class MergeCells {
public static void main(String[] args) throws Exception {
//Documentクラスのオブジェクトを作成し、サンプルドキュメントを読み込む
Document document = new Document();
document.loadFromFile("Sample.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//最初のテーブルを取得する
Table table = section.getTables().get(0);
//セルを垂直方向に結合する
mergeCell(table, false, 0, 1, 2);
//セルを水平方向に結合する
mergeCell(table, true, 0, 3, 4);
//結果ファイルを保存する
document.saveToFile("MergeTable.docx",FileFormat.Docx_2013);
document.dispose(); }
//セルを結合する際に重複した値を削除する
public static void mergeCell(Table table, boolean isHorizontalMerge, int index, int start, int end) {
if (isHorizontalMerge) {
//テーブルから特定のセルを取得する
TableCell firstCell = table.get(index, start);
//セルからテキストを取得する
String firstCellText = getCellText(firstCell);
for (int i = start + 1; i <= end; i++) {
TableCell cell1 = table.get(index, i);
//テキストが最初のセルと同じかどうかを確認する
if (firstCellText.equals(getCellText(cell1))) {
//「はい」の場合、セル内のすべての段落をクリアする
cell1.getParagraphs().clear(); }
}
//セルを水平方向に結合する
table.applyHorizontalMerge(index, start, end); }
else {
TableCell firstCell = table.get(start, index);
String firstCellText = getCellText(firstCell);
for (int i = start + 1; i <= end; i++) {
TableCell cell1 = table.get(i, index);
if (firstCellText.equals(getCellText(cell1))) {
cell1.getParagraphs().clear();
}
}
//セルを垂直方向に結合する
table.applyVerticalMerge(index, start, end);
}
}
public static String getCellText(TableCell cell) {
StringBuilder text = new StringBuilder();
//セルのすべての段落をループする
for (int i = 0; i < cell.getParagraphs().getCount(); i++) {
//すべての段落のテキストを取得し、StringBuilder に追加する
text.append(cell.getParagraphs().get(i).getText().trim()); }
return text.toString();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
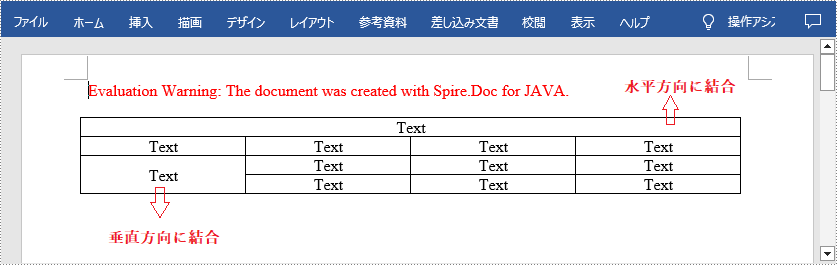
Word の表は、データの整理や表示に便利な機能です。デフォルトの表は、各列や行に同じ数のセルがありますが、ヘッダーを作成するために複数のセルを結合したり、追加のデータを収容するためにセルを分割したりする必要がある場合もあります。この記事では、Spire.Doc for Java を使用して Word で表のセルを結合または分割する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.7.0</version>
</dependency>
</dependencies>Spire.Doc for .NET では、Table.applyHorizontalMerge() メソッドまたは Table.applyVerticalMerge() メソッドを使用して、隣接する 2 つ以上のセルを水平方向または垂直方向に結合できます。詳細な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.HorizontalAlignment;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.VerticalAlignment;
public class MergeTableCell {
public static void main(String[] args) throws Exception {
//Documentインスタンスを作成する
Document document = new Document();
//Word文書をロードする
document.loadFromFile("input.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//セクションに4 x 4の表を追加する
Table table = section.addTable(true);
table.resetCells(4, 4);
//最初の行のセルを水平方向に結合する
table.applyHorizontalMerge(0, 0, 3);
//最初の列のセル3と4を垂直方向に結合する
table.applyVerticalMerge(0, 2, 3);
//表にデータを追加する
for (int row = 0; row < table.getRows().getCount(); row++) {
for (int col = 0; col < table.getRows().get(row).getCells().getCount(); col++) {
TableCell cell = table.get(row, col);
cell.getCellFormat().setVerticalAlignment(VerticalAlignment.Middle);
Paragraph paragraph = cell.addParagraph();
paragraph.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
paragraph.setText("Text");
}
}
//結果文書を保存する
document.saveToFile("MergeTableCells.docx", FileFormat.Docx);
}
}
Word セルを複数のセルに分割するために、Spire.Doc for .NET には TableCell.splitCell(int columnNum, int rowNum) メソッドが用意されています。詳細な手順は次のとおりです。
import com.spire.doc.*;
public class SplitTableCell {
public static void main(String[] args) throws Exception {
//Documentインスタンスを作成する
Document document = new Document();
//Word文書をロードする
document.loadFromFile("MergeTableCells.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//セクションの最初の表を取得する
Table table = section.getTables().get(0);
//指定されたセルを取得する
TableCell cell1 = table.getRows().get(3).getCells().get(3);
//セルを2列2行に分割する
cell1.splitCell(2, 2);
//結果文書を保存する
document.saveToFile("SplitTableCells.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
表は、Word 文書で表の形式のデータを表示するための一般的な方法の一つです。これは、大量の情報を整理するのに大いに役立ちます。この記事では、Spire.Doc for Java を使用して、表を作成する方法、表にデータを入力する方法、および表のセルに書式を適用する方法をご紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>4.9.0</version>
</dependency>
</dependencies>次のテーブルに、表の作成とフォーマットを担当するコアクラスとメソッドの一部を示します。
| 名前 | 説明 |
| Table Class | Word文書の表を表します。 |
| TableRow Class | テーブルの行を表します。 |
| TableCell Class | テーブル内の特定のセルを表します。 |
| Section.addTbale() Method | 指定されたセクションに新しいテーブルを追加します。 |
| Table.resetCells() Method | 行番号と列番号をリセットします。 |
| Table.getRows() Method | テーブルの行を取得します。 |
| TableRow.setHeight() Method | 指定した行の高さを設定します。 |
| TableRow.getCells() Method | セルコレクションを返します。 |
| TableRow.getFormat() Method | 指定された行の形式を取得します。 |
以下は、Word文書に簡単な表を作成する手順です。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.TextRange;
import java.awt.*;
public class CreateTable {
public static void main(String[] args) {
//Documentオブジェクトを作成する
Document document = new Document();
//セクションを追加する
Section section = document.addSection();
//表のデータを定義する
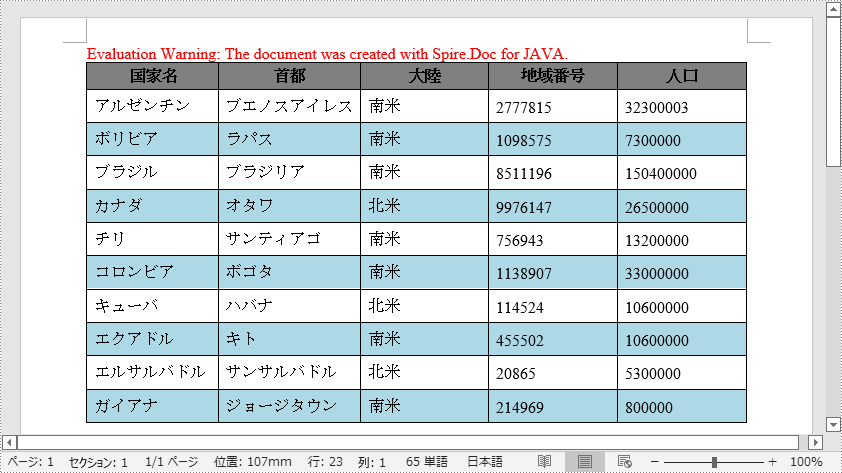
String[] header = {"国家名", "首都", "大陸", "地域番号", "人口"};
String[][] data =
{
new String[]{"アルゼンチン", "ブエノスアイレス", "南米", "2777815", "32300003"},
new String[]{"ボリビア", "ラパス", "南米", "1098575", "7300000"},
new String[]{"ブラジル", "ブラジリア", "南米", "8511196", "150400000"},
new String[]{"カナダ", "オタワ", "北米", "9976147", "26500000"},
new String[]{"チリ", "サンティアゴ", "南米", "756943", "13200000"},
new String[]{"コロンビア", "ボゴタ", "南米", "1138907", "33000000"},
new String[]{"キューバ", "ハバナ", "北米", "114524", "10600000"},
new String[]{"エクアドル", "キト", "南米", "455502", "10600000"},
new String[]{"エルサルバドル", "サンサルバドル", "北米", "20865", "5300000"},
new String[]{"ガイアナ", "ジョージタウン", "南米", "214969", "800000"},
};
//表を追加する
Table table = section.addTable(true);
table.resetCells(data.length + 1, header.length);
//最初の行を表ヘッダーとして設定する
TableRow row = table.getRows().get(0);
row.isHeader(true);
row.setHeight(20);
row.setHeightType(TableRowHeightType.Exactly);
row.getRowFormat().setBackColor(Color.gray);
for (int i = 0; i < header.length; i++) {
row.getCells().get(i).getCellFormat().setVerticalAlignment(VerticalAlignment.Middle);
Paragraph p = row.getCells().get(i).addParagraph();
p.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
TextRange txtRange = p.appendText(header[i]);
txtRange.getCharacterFormat().setBold(true);
}
//残りの行にデータを追加する
for (int r = 0; r < data.length; r++) {
TableRow dataRow = table.getRows().get(r + 1);
dataRow.setHeight(25);
dataRow.setHeightType(TableRowHeightType.Exactly);
dataRow.getRowFormat().setBackColor(Color.white);
for (int c = 0; c < data[r].length; c++) {
dataRow.getCells().get(c).getCellFormat().setVerticalAlignment(VerticalAlignment.Middle);
dataRow.getCells().get(c).addParagraph().appendText(data[r][c]);
}
}
//セルの背景色を設定する
for (int j = 1; j < table.getRows().getCount(); j++) {
if (j % 2 == 0) {
TableRow row2 = table.getRows().get(j);
for (int f = 0; f < row2.getCells().getCount(); f++) {
row2.getCells().get(f).getCellFormat().setBackColor(new Color(173, 216, 230));
}
}
}
//ファイルに保存する
document.saveToFile("output/CreateTable.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





