チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション
テキストと画像は、Word 文書のコンテンツを豊かにする重要な要素です。文書内のテキストや画像を個別に処理する必要がある場合、プログラムで Word 文書から抽出することができます。テキストを手動でコピーするよりも、テキストを抽出することで大規模な文書をより便利かつ効率的に処理することができます。また、画像を抽出することで文書内の画像を編集したり、他人と簡単に共有することができます。この記事では、Spire.Doc for Java を使用して Word 文書からテキストと画像を抽出する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.6.0</version>
</dependency>
</dependencies>Spire.Doc for Java は、Word 文書からテキストを抽出し、txt ファイル形式として保存することをサポートしています。これにより、ユーザーはデバイス制限なしにテキストコンテンツを表示できます。以下は、Word 文書からテキストを抽出するための詳細な手順です。
import com.spire.doc.Document;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractText {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成してWord文書をロードする
Document document = new Document();
document.loadFromFile("sample1.docx");
//文書から文字列としてテキストを取得する
String text=document.getText();
//文字列を.txtファイルに書き込む
writeStringToTxt(text,"ExtractedText.txt");
}
public static void writeStringToTxt(String content, String txtFileName) throws IOException{
FileWriter fWriter= new FileWriter(txtFileName,true);
try {
fWriter.write(content);
}catch(IOException ex){
ex.printStackTrace();
}finally{
try{
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
画像を抽出することにより、ユーザーは簡単に他のアプリケーションに画像データをインポートしてさらなる処理ができます。Spire.Doc for Java では、Word 文書から画像を抽出し、指定されたパスに保存することができます。以下は詳細な手順です。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import com.spire.doc.interfaces.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.*;
public class ExtractImage {
public static void main(String[] args) throws IOException {
//Documentオブジェクトを作成してWord文書をロードする
Document document = new Document();
document.loadFromFile("Sample2.docx");
//キューを作成し、ルートドキュメントの要素を追加する
Queue nodes = new LinkedList<>();
nodes.add(document);
//抽出された画像を保存するためのArrayListオブジェクトを作成する
List images = new ArrayList<>();
//ドキュメントツリーをループする
while (nodes.size() > 0) {
ICompositeObject node = nodes.poll();
for (int i = 0; i < node.getChildObjects().getCount(); i++)
{
IDocumentObject child = node.getChildObjects().get(i);
if (child instanceof ICompositeObject)
{
nodes.add((ICompositeObject) child);
}
else if (child.getDocumentObjectType() == DocumentObjectType.Picture)
{
DocPicture picture = (DocPicture) child;
images.add(picture.getImage());
}
}
}
//画像を特定のフォルダに保存する
for (int i = 0; i < images.size(); i++) {
File file = new File(String.format("output/extractImage-%d.png", i));
ImageIO.write(images.get(i), "PNG", file);
}
}
} 
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ドキュメントの外観は、ドキュメントのメッセージを伝えるだけでなく、作成者の情報を明らかにするものです。スペルミスや文法ミスがなく、一貫した書式のコンテンツと適切な画像を含み、よく整理されたドキュメントは、製品やサービスを提供する能力に対する信頼を高めてくれます。
Spire.Doc for Java を使用すると、段落全体だけでなく、個々の単語やフレーズを書式設定することができます。本稿では、Spire.Doc for Java を使用して、Java で Word ドキュメントの文字に様々な書式を適用する方法を紹介します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.4.2</version>
</dependency>
</dependencies>テキストに書式を適用するには、テキストを TextRange で取得し、CharacterFormat クラスのメソッドを使って TextRange 内の文字に書式を設定する必要があります。以下は、Spire.Doc for Java を使用して Word ドキュメントに文字書式を設定する手順です。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.BorderStyle;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.SubSuperScript;
import com.spire.doc.documents.UnderlineStyle;
import com.spire.doc.fields.TextRange;
import com.spire.doc.fields.shape.Emphasis;
import java.awt.*;
public class ApplyFormattingToCharacters {
public static void main(String[] args) {
//Documentのオブジェクトを作成する
Document document = new Document();
//セクションを追加する
Section sec = document.addSection();
//段落を追加する
Paragraph paragraph = sec.addParagraph();
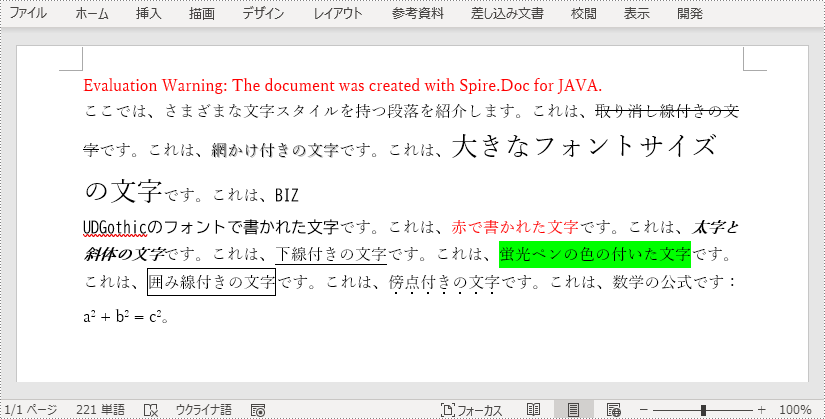
paragraph.appendText("ここでは、さまざまな文字スタイルを持つ段落を紹介します。これは、");
paragraph.getStyle().getCharacterFormat().setFontName("Yu Mincho");
//段落に文字を追加し、TextRangeオブジェクトを返す
TextRange tr = paragraph.appendText("取り消し線付きの文字");
//TextRangeオブジェクトで文字書式を取り消し線に設定する
tr.getCharacterFormat().isStrikeout(true);
//文字に網かけを付ける
paragraph.appendText("です。これは、");
tr = paragraph.appendText("網かけ付きの文字");
tr.getCharacterFormat().isShadow (true);
//フォントサイズを設定する
paragraph.appendText("です。これは、");
tr = paragraph.appendText("大きなフォントサイズの文字");
tr.getCharacterFormat().setFontSize(20);
//フォントを設定する
paragraph.appendText("です。これは、");
tr = paragraph.appendText("BIZ UDGothicのフォントで書かれた文字");
tr.getCharacterFormat().setFontName("BIZ UDGothic");
//フォントの色を設定する
paragraph.appendText("です。これは、");
tr = paragraph.appendText("赤で書かれた文字");
tr.getCharacterFormat().setTextColor(Color.red);
//文字に太字と斜体を適用する
paragraph.appendText("です。これは、");
tr = paragraph.appendText("太字と斜体の文字");
tr.getCharacterFormat().setBold(true);
tr.getCharacterFormat().setItalic(true);
//文字に下線を引く
paragraph.appendText("です。これは、");
tr = paragraph.appendText("下線付きの文字");
tr.getCharacterFormat().setUnderlineStyle(UnderlineStyle.Single);
//文字に背景色をつける
paragraph.appendText("です。これは、");
tr = paragraph.appendText("蛍光ペンの色の付いた文字");
tr.getCharacterFormat().setHighlightColor(Color.green);
//文字に囲み線を適用する
paragraph.appendText("です。これは、");
tr = paragraph.appendText("囲み線付きの文字");
tr.getCharacterFormat().getBorder().setBorderType(BorderStyle.Single);
tr.getCharacterFormat().getBorder().setColor(Color.black);
//文字に傍点を付ける
paragraph.appendText("です。これは、");
tr = paragraph.appendText("傍点付きの文字");
tr.getCharacterFormat().setEmphasisMark(Emphasis.Dot_Below);
//文字に上付き文字を適用する
paragraph.appendText("です。これは、数学の公式です: a");
tr = paragraph.appendText("2");
tr.getCharacterFormat().setSubSuperScript(SubSuperScript.Super_Script);
paragraph.appendText(" + b");
tr = paragraph.appendText("2");
tr.getCharacterFormat().setSubSuperScript(SubSuperScript.Super_Script);
paragraph.appendText(" = c");
tr = paragraph.appendText("2");
tr.getCharacterFormat().setSubSuperScript(SubSuperScript.Super_Script);
paragraph.appendText("。");
//ドキュメントを保存する
document.saveToFile("文字書式の設定.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書を扱う過程で、しばしば困った事態が発生します。例えば、大きな Word 文書を完成させたとき、何度も出てくる名称や専門用語の中に間違いがあることが判明した。間違っている言葉を一つずつ変えていくとなると、作業量が多すぎて大変です。幸いなことに、このような問題を素早く解決する簡単な方法がいくつかあります。MS Word には、検索と置換という機能があり、ユーザーは置き換えたいものを素早く見つけて、新しいテキストに置き換えることができます。プロフェッショナル向け開発コンポーネント Spire.Doc for Java は、コードを通じて単語の検索と置換を行う機能を開発者に提供します。この記事では、Spire.Doc for Java を使って、Word 文書内のテキストを素早く検索し、新しいテキストや画像に置き換える方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Spire.Doc for Java が提供する Document.replace() メソッドを使うだけで、素早くテキストを検索し、新しいテキストに置き換えることができます。 このメソッドは、すべてのマッチを新しいテキストに置き換えます。大文字と小文字を区別するかどうか、検索語を完全に検索するかどうかの設定に対応しています。
テキストを検索し、一致するものをすべて置き換える詳細な手順は次のとおりです。
import com.spire.doc.Document;
public class replaceAll {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("洞窟芸術.docx");
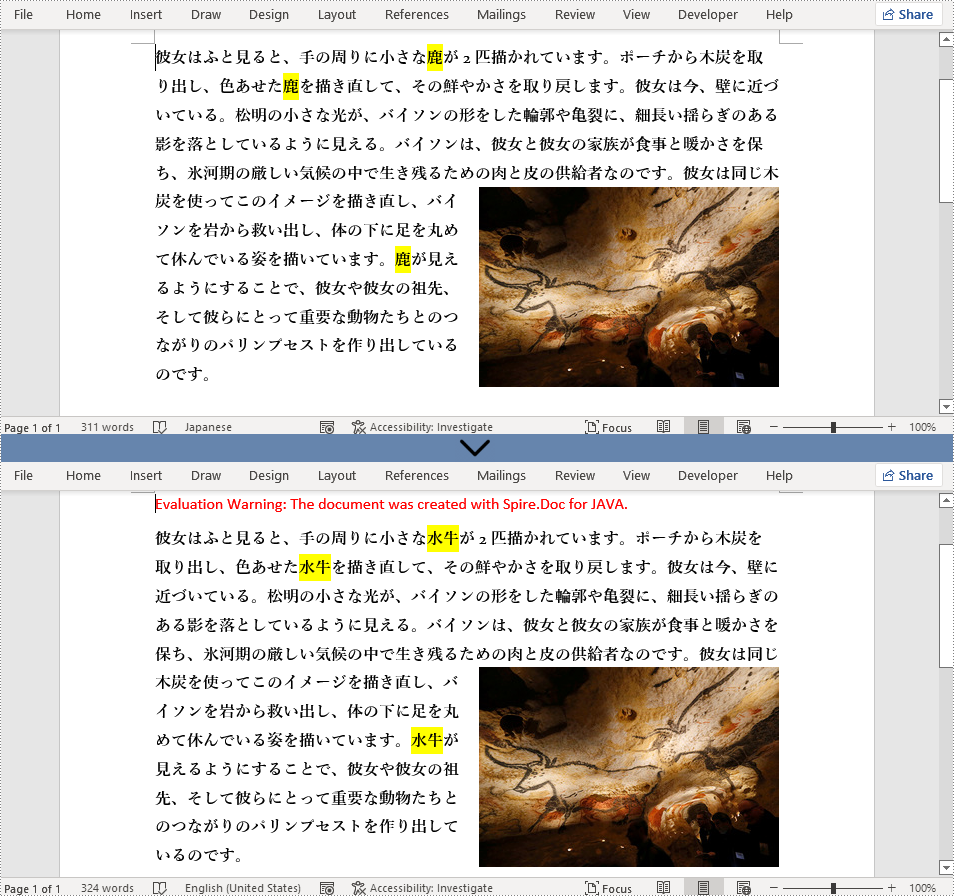
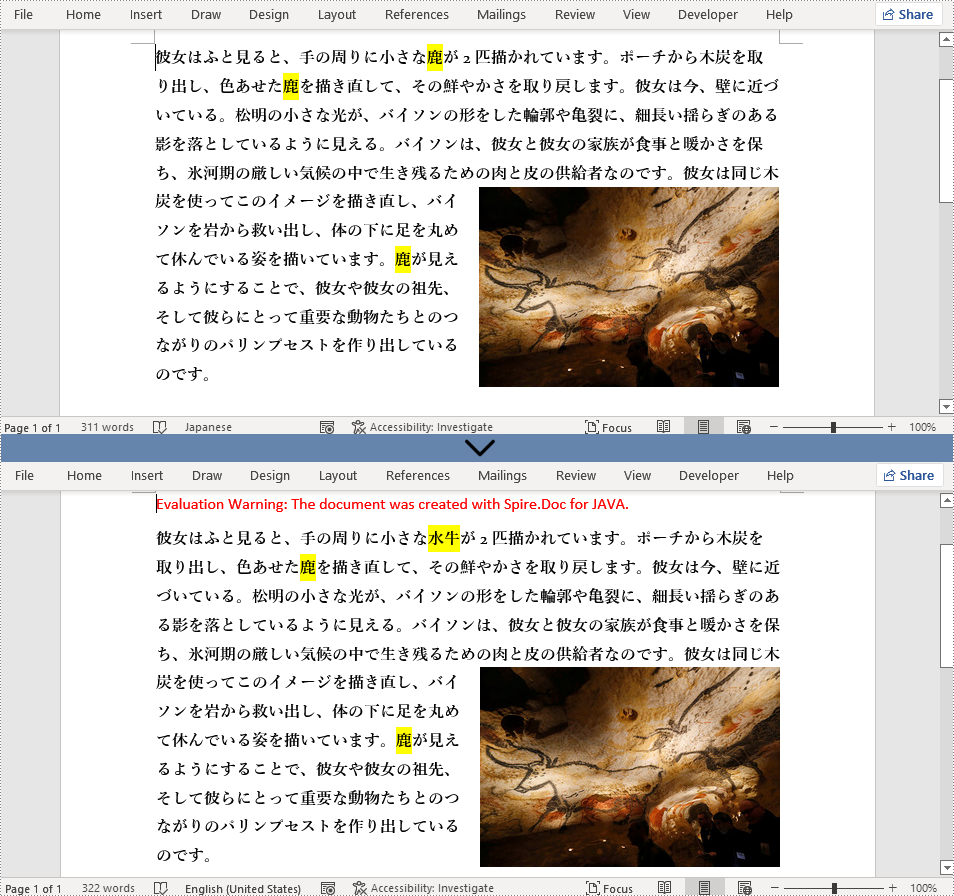
//「鹿」のマッチングをすべて「水牛」に置き換える
document.replace("鹿", "水牛", false, true);
//結果ファイルを保存する
document.saveToFile("すべて置き換える.docx");
}
}
Doc for Java には、Document.setReplaceFirst() メソッドもあり、Document.replace() メソッドの置換モードを、最初の一致を置換するか、すべての一致を置換するかを変更することができます。
テキストを検索し、最初に一致したものを置き換えるには、次のように操作します。
import com.spire.doc.Document;
public class replaceFirst {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("洞窟芸術.docx");
//置換モードを最初のマッチを置換するモードに変更する
document.setReplaceFirst(true);
//「テキスト「鹿」の最初のマッチを新しいテキスト「水牛」に置き換える
document.replace("鹿", "水牛", false, true);
//結果ファイルを保存する
document.saveToFile("最初のマッチを置き換える.docx");
}
}
Spire.Doc for Java は、テキストを検索し、一致したものをすべて画像として置き換えることもサポートしています。そのためには、テキストを検索して、マッチしたものを全て取得する必要があります。次に、画像をドキュメントのオブジェクトとして読み込み、マッチしたテキストがある場所に挿入し、テキストを削除します。
詳細な手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.TextSelection;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextRange;
public class replaceTextWithImage {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("洞窟芸術.docx");
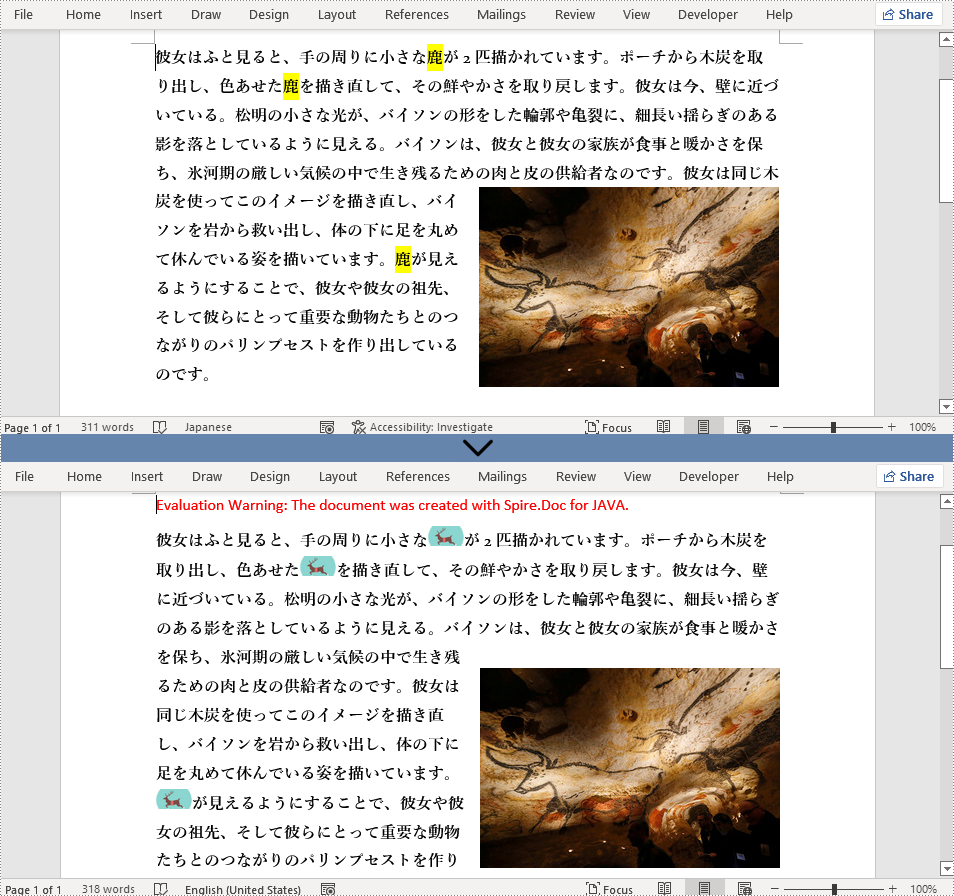
//ドキュメント内の「鹿」にマッチするすべてのテキストを検索する
TextSelection[] selections = document.findAllString("鹿", true, true);
//一致したテキストをループして、すべて画像に置き換える
int index = 0;
TextRange range = null;
for (Object obj : selections) {
TextSelection textSelection = (TextSelection)obj;
//DocPictureクラスのオブジェクトを作成し、画像を読み込む
DocPicture pic = new DocPicture(document);
pic.loadImage("鹿.png");
range = textSelection.getAsOneRange();
index = range.getOwnerParagraph().getChildObjects().indexOf(range);
range.getOwnerParagraph().getChildObjects().insert(index,pic);
range.getOwnerParagraph().getChildObjects().remove(range);
}
//指定されたマッチを画像に置き換える
//DocPictureクラスのオブジェクトを作成し、画像を読み込む
//DocPicture pic = new DocPicture(document);
//pic.loadImage("鹿.png");
//Object object = selections[1];
//TextSelection selection = (TextSelection) object;
//TextRange textRange = selection.getAsOneRange();
//int i = textRange.getOwnerParagraph().getChildObjects().indexOf(textRange);
//textRange.getOwnerParagraph().getChildObjects().insert(i,pic);
//textRange.getOwnerParagraph().getChildObjects().remove(textRange);
//結果ファイルを保存する
document.saveToFile("テキストを検索して画像に置き換える.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
MS Word の「検索」機能により、ユーザーはドキュメント内の特定のテキストやフレーズをすばやく検索することができ、ユーザーは見つけたテキストを黄色やその他の明るい色で強調表示することもでき、読者を一目で見ることができます。この記事では、Spire.Doc for Java を使用して Word ドキュメント内のテキストを検索してハイライトする方法を説明します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.9.8</version>
</dependency>
</dependencies>以下に詳細な操作方法を示します。
import com.spire.doc.*;
import com.spire.doc.documents.TextSelection;
import java.awt.*;
public class FindAndHighlight {
public static void main(String[] args){
//Documentインスタンスを作成する
Document document = new Document();
//サンプルドキュメントをロードする
document.loadFromFile("E:\\Files\\input1.docx");
//ドキュメント内のすべての一致するテキストを検索する
TextSelection[] textSelections = document.findAllString("東京ディズニーランド", false, true);
//ドキュメント内のすべての一致するテキストをループする
for (TextSelection selection : textSelections) {
//特定のテキスト範囲を取得して、ハイライトのカラーを設定する
selection.getAsOneRange().getCharacterFormat().setHighlightColor(Color.YELLOW);
}
//結果文書を保存する
document.saveToFile("FindAndHighlight.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





