

C# アプリケーションにおいて、UI コントロールに表示されている表形式データを Excel にエクスポートすることは、非常に一般的な要件です。WinForms や ASP.NET プロジェクトでは、DataGrid、DataGridView、GridView に現在表示されているデータを、レポート作成や共有、後続処理のために Excel ファイルとして出力したいケースが多くあります。
実際の業務では、エクスポートされた Excel ファイルは単なる生データとして使われることはほとんどありません。読みやすいレイアウト、表ヘッダーの書式、適切な列幅、数値や日付の表示形式などが求められるのが一般的です。
本記事では、Spire.XLS for .NET を使用し、Microsoft Office Interop を使用せずに、C# で DataGridView および GridView / DataGrid のデータを Excel にエクスポートする方法を解説します。表示中のデータを正確に出力しつつ、実装をシンプルに保ち、Excel 側で一貫した書式設定を行うことに重点を置いています。
目次
Microsoft Office Interop を使用して Excel ファイルを生成することも可能ですが、DataGrid、DataGridView、GridView からデータを出力する場合、プログラムによるエクスポートには以下のような明確な利点があります。
コードベースで直接 Excel を生成することで、安定性・保守性・拡張性に優れたエクスポート機能を、さまざまなアプリケーションで一貫して提供できます。
DataGrid、DataGridView、GridView はいずれも UI コントロールですが、本質的には行と列で構成された構造化データを表示するためのものです。これらのコントロールを直接エクスポートしようとすると、UI に依存したロジックになりやすく、保守性が低下します。
そこで推奨されるのが、次のようなワークフローです。
画面表示データ → DataTable → Excel ファイル
この設計では、
DataTable は最終的な出力先ではなく、中間データ構造として機能します。Spire.XLS for .NET を使用すれば、DataTable を書式付きの Excel ファイルとして簡単にエクスポートできます。
最初のステップでは、UI コントロールに 現在表示されているデータ を取得し、DataTable に変換します。ここでは元のデータソースを再構築するのではなく、表示内容そのものを取得することが重要です。
WinForms アプリケーションでは、ユーザーは画面に表示されている DataGridView の内容と同じデータがエクスポートされることを期待します。以下のメソッドは、表示中の DataGridView データを DataTable に変換します。
DataTable ConvertDataGridViewToDataTable(DataGridView dgv)
{
DataTable dt = new DataTable();
foreach (DataGridViewColumn column in dgv.Columns)
{
dt.Columns.Add(column.HeaderText, column.ValueType ?? typeof(string));
}
foreach (DataGridViewRow row in dgv.Rows)
{
if (row.IsNewRow) continue;
DataRow dr = dt.NewRow();
for (int i = 0; i < dgv.Columns.Count; i++)
{
dr[i] = row.Cells[i].Value ?? DBNull.Value;
}
dt.Rows.Add(dr);
}
return dt;
}
この方法により、列ヘッダー、列順、表示されている値を保持したまま、DataGridView のデータを Excel にエクスポートできます。
ASP.NET アプリケーションでは、GridView コントロールが表形式データの表示に使用されます。表示中の GridView データをエクスポートする場合、以下のようにレンダリングされた行を DataTable に変換できます。
DataTable ConvertGridViewToDataTable(GridView gv)
{
DataTable dt = new DataTable();
foreach (TableCell cell in gv.HeaderRow.Cells)
{
dt.Columns.Add(cell.Text);
}
foreach (GridViewRow row in gv.Rows)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < row.Cells.Count; i++)
{
dr[i] = row.Cells[i].Text;
}
dt.Rows.Add(dr);
}
return dt;
}
この方法を使えば、UI に依存した処理を増やすことなく、C# で GridView のデータを Excel にエクスポートするための共通データ構造を用意できます。
なお、データベースから直接 Excel に出力したい場合は、こちらの記事も参考にしてください: C# でデータベースを Excel にエクスポートする方法
表示データを DataTable に変換できたら、あとは UI に依存しない形で Excel ファイルを生成するだけです。
ここでは Spire.XLS for .NET を使用し、Microsoft Excel をインストールせずに Excel ファイルを作成します。
NuGet を使用してインストールできます。
Install-Package Spire.XLS
または、Spire.XLS for .NET をダウンロードして、手動でプロジェクトに追加することも可能です。
using Spire.Xls;
Workbook workbook = new Workbook();
Worksheet worksheet = workbook.Worksheets[0];
// 列ヘッダーを含めて DataTable を Excel に挿入
worksheet.InsertDataTable(exportTable, true, 1, 1);
// Excel ファイルを保存
workbook.SaveToFile("ExportedData.xlsx", ExcelVersion.Version2016);
エクスポート結果の Excel ファイルは以下のようになります。
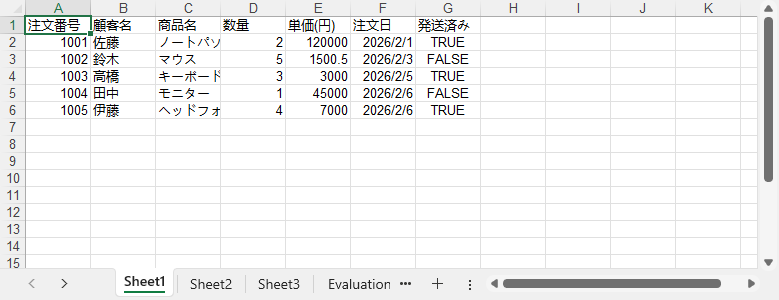
このエクスポート処理は、DataGrid、DataGridView、GridView のいずれにもそのまま再利用できます。
Excel へのエクスポートでは、データの出所に関わらず、書式設定が重要になります。スタイルの適用、列幅の調整、数値書式の設定により、ファイルの可読性と実用性が大きく向上します。
以下は、エクスポートしたワークシートに対して適用できる代表的な書式設定の例です。
CellStyle headerStyle = workbook.Styles.Add("HeaderStyle");
headerStyle.Font.IsBold = true;
headerStyle.Font.FontName = "Yu Gothic UI";
headerStyle.Font.Size = 12f;
headerStyle.HorizontalAlignment = HorizontalAlignType.Center;
headerStyle.VerticalAlignment = VerticalAlignType.Center;
CellStyle dataStyle = workbook.Styles.Add("DataStyle");
dataStyle.Font.FontName = "Yu Gothic UI";
dataStyle.Font.Size = 11f;
// ヘッダーのスタイルを適用
CellRange headerRange = worksheet.Range[1, 1, 1, ordersTable.Columns.Count];
headerRange.Style = headerStyle;
// データ行のスタイルを適用
worksheet.Range[2, 1, worksheet.LastRow, worksheet.LastColumn].Style = dataStyle;
// 列幅と行高を自動調整
worksheet.AllocatedRange.AutoFitColumns();
worksheet.AllocatedRange.AutoFitRows();
// 日付と通貨の書式を設定
worksheet.Range[$"D2:D{worksheet.LastRow}"].NumberFormat = "#,##0";
worksheet.Range[$"E2:E{worksheet.LastRow}"].NumberFormat = "¥#,##0.00";
worksheet.Range[$"F2:G{worksheet.LastRow}"].NumberFormat = "yyyy-mm-dd";
書式適用後の Excel ファイルの例は以下のとおりです。
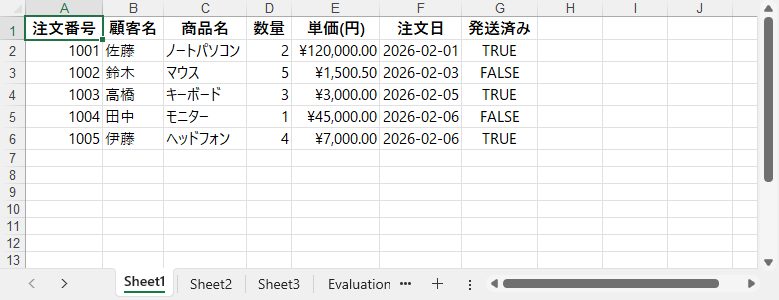
これらの書式設定は、レポート要件に応じて自由に組み合わせたり拡張したりできますが、データ抽出ロジックを変更する必要はありません。
Spire.XLS for .NET は、条件付き書式やグラフなど、さらに高度な Excel 機能にも対応しています。詳しくは、C# で Excel ファイルを作成する方法をご参照ください。
大量の DataGrid または GridView データをエクスポートする場合は、以下の点に注意するとよいでしょう。
エクスポート処理は UI コントロールではなく DataTable を基盤としているため、データ量が増えても保守性・拡張性を維持できます。
C# で DataGrid、DataGridView、GridView のデータを Excel にエクスポートする際、Microsoft Office Interop は必須ではありません。表示中のデータを DataTable に変換し、プログラムから Excel ファイルを生成することで、安定性と再利用性の高いエクスポート機能を実装できます。
UI とエクスポート処理を明確に分離し、書式設定にも柔軟に対応できるこの方法は、デスクトップアプリケーションおよび Web アプリケーションの実務的なレポート作成に適しています。ライブラリの評価や動作確認を行う場合は、一時ライセンスを申請することも可能です。
A1:表示中の DataGridView データを DataTable に変換し、Spire.XLS for .NET を使用してプログラムから Excel ファイルを生成すれば、Microsoft Excel に依存せずにエクスポートできます。
A2:はい。Spire.XLS を使用すれば、スタイルの適用、列幅の調整、数値書式の設定などを行い、読みやすく実用的な Excel レポートを作成できます。
A3:いいえ。Spire.XLS のようなライブラリを使用すれば、DataTable から直接 Excel ファイルを生成できるため、Excel をインストールする必要はありません。サーバー環境やクラウド環境にも適しています。
データ主導の業務が一般化している現在、Python 開発者にとって「リスト(Python の基本データ構造)を Excel へ変換する」作業は非常に一般的です。Excel は多くの業界で、データの可視化・共有・レポート作成の標準ツールとして広く利用されています。
レポート生成、分析前の前処理、非エンジニアへのデータ共有など、Python のリストを Excel に出力するスキルは欠かせません。
pandas のような軽量ライブラリでも基本的な出力は可能ですが、Spire.XLS for Python は Excel の書式設定、スタイル、ファイル生成を細かく制御でき、Microsoft Excel のインストールも不要です。このガイドでは、さまざまなリスト構造を Excel へ変換する方法を、実例とベストプラクティスとともに解説します。
Python のリストは柔軟にデータを保持できますが、Excel には次のような利点があります:
売上データ、ユーザー情報、アンケート結果など、Excel に書き出すことでデータの共有性と実用性が大幅に向上します。
Spire.XLS for Python を使用するには、pip でインストールします:
pip install Spire.XLS
Excel(.xls/.xlsx)形式の読み書きに対応し、太字、列幅、色などの書式設定が自由に行えます。 本番レベルの Excel 出力に最適なライブラリです。
さらに多くの機能を試すには、30日間の無料評価ライセンスを取得できます。
一次元リストを Excel に書き込む場合、リストをループし、1 列に順番に挿入します。
以下のコード例では、文字列のリストを 1 列に書き込みます。 数値リストの場合は、保存前に数値書式を設定できます。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("シンプルなリスト")
# サンプルデータ(文字列のリスト)
data_list = ["佐藤", "鈴木", "高橋", "田中", "伊藤"]
# リストの内容を Excel セルに書き込みます(1行目・1列目から開始)
for index, value in enumerate(data_list):
worksheet.Range[index + 1, 1].Value = value
# 表示を見やすくするため、列幅を設定します
worksheet.Range[1, 1].ColumnWidth = 15
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("SimpleListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
1 行に並べたい場合は以下のようにします:
for index, value in enumerate(data_list):
worksheet.Range[1, index + 1].Value = value
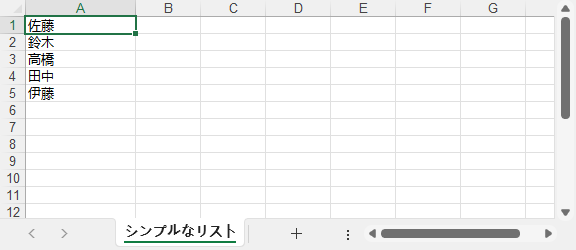
出力結果: きれいに整った 1 列の Excel になります。
ネストされたリスト(2D リスト)は、行列形式のデータで、Excel シートに直接マッピングできます。 以下は、従業員データ(名前・年齢・部署)を Excel テーブルへ変換する例です。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("社員データ")
# ネストされたリスト(各行:[氏名、年齢、部署])
employee_data = [
["氏名", "年齢", "部署"], # ヘッダー行
["佐藤 太郎", 30, "人事部"],
["鈴木 一郎", 28, "開発部"],
["高橋 花子", 35, "マーケティング部"],
["田中 美咲", 29, "経理部"]
]
# ネストされたリストの内容を Excel に書き込みます
for row_idx, row_data in enumerate(employee_data):
for col_idx, value in enumerate(row_data):
if isinstance(value, int):
worksheet.Range[row_idx + 1, col_idx + 1].NumberValue = value
else:
worksheet.Range[row_idx + 1, col_idx + 1].Value = value
# ヘッダー行の書式を設定します
worksheet.Range["A1:C1"].Style.Font.IsBold = True
worksheet.Range["A1:C1"].Style.Color = Color.get_Yellow()
# 列幅を設定します
worksheet.Range[1, 1].ColumnWidth = 10
worksheet.Range[1, 2].ColumnWidth = 6
worksheet.Range[1, 3].ColumnWidth = 15
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("NestedListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
ポイント
出力結果: ヘッダーが太字・黄色で、型が正しく保持された Excel テーブル。
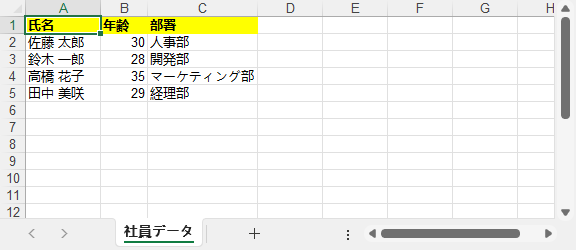
Excel ファイルをよりプロフェッショナルな仕上がりにするために、Spire.XLS for Python を使用して、セルの罫線を追加したり、条件付き書式を設定したり、その他の書式設定オプションを適用したりできます。
辞書型のリストは、フィールド名付きのデータ構造を扱う際に一般的です。 以下の例では、顧客情報のリストを Excel に書き出します。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("顧客データ")
# 辞書のリスト
customers = [
{"ID": 101, "氏名": "山田 太郎", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"},
{"ID": 102, "氏名": "佐藤 花子", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"},
{"ID": 103, "氏名": "鈴木 一郎", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"}
]
# 辞書のキーからヘッダーを取得します
headers = list(customers[0].keys())
# ヘッダーを 1 行目に書き込みます
for col, header in enumerate(headers):
worksheet.Range[1, col + 1].Value = header
worksheet.Range[1, col + 1].Style.Font.IsBold = True # ヘッダーを太字に設定します
# データ行を書き込みます
for row, customer in enumerate(customers, start=2): # 2 行目から開始します
for col, key in enumerate(headers):
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row, col + 1].NumberValue = value
else:
worksheet.Range[row, col + 1].Value = value
# 列幅を自動調整します
worksheet.AutoFitColumn(2)
worksheet.AutoFitColumn(3)
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("CustomerDataToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
メリット
出力結果:ヘッダーが自動生成され、データ型が保持され、列幅が自動調整された Excel ファイル。
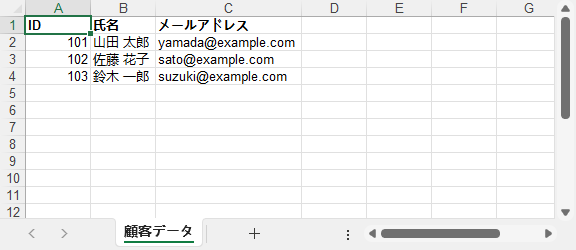
Python のリストを Excel に変換する作業はデータ処理の基本スキルです。 Spire.XLS を利用することで、簡単なリストから複雑な入れ子構造、辞書型データまで、きれいで実用的な Excel ファイルを簡単に生成できます。
より高度な操作(グラフ、数式追加など)については、公式ドキュメントをご覧ください。
A: pandas は素早い基本出力に適していますが、書式設定の自由度は低めです。 Spire.XLS は以下の用途に向いています:
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016)
workbook.SaveToFile("output.xls", ExcelVersion.Version97to2003)
A: Workbook を作成すると空のシートが自動生成されるため、
Workbook.Worksheets.Clear() を呼ばないと不要なシートが残ります。
A: 主な原因は次の通りです:
PDFファイルを受け取ったりダウンロードしたりした際、一部のページが横向きや上下逆など、正しくない向きで表示されることがあります。そのような場合、PDFページを回転させることで、読みやすく適切な表示に修正できます。
本記事では、Spire.PDF for Python を使用して、PDFページをプログラムから回転する方法を紹介します。
この機能を使用するには、Spire.PDF for Python と plum-dispatch v1.7.4 が必要です。Windows 環境では、以下の pip コマンドで簡単にインストールできます。
pip install Spire.PDF
または、Spire.PDF for Pythonのダウンロードページから直接ダウンロードして、プロジェクトに追加することもできます。
PDFページの回転は 90 度単位で行われ、0/90/180/270 度を指定できます。以下は、PDF内の特定ページを回転する手順です。
Pythonコード:PDF内の特定ページを回転
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成します
pdf = PdfDocument()
# PDFファイルを読み込みます
pdf.LoadFromFile("Sample.pdf")
# 1ページ目を取得します
page = doc.Pages.get_Item(0)
# 現在の回転角度を取得します
rotation = int(page.Rotation.value)
# 元の角度を基準に、時計回りに180度回転します
rotation += int(PdfPageRotateAngle.RotateAngle180.value)
if rotation >= 4:
rotation -= 4
# PdfPageRotateAngle は 0~3 の循環する列挙型(0/90/180/270度)のため、
# 値が範囲を超えた場合は回り込み処理を行います
page.Rotation = PdfPageRotateAngle(rotation)
# 結果を保存します
pdf.SaveToFile("RotatePDFPage.pdf")
pdf.Close()
以下は、処理後のPDFファイルのプレビューです。

Spire.PDF for Python を使用すると、PDFファイル内のすべてのページをループ処理し、一括で回転させることもできます。手順は以下のとおりです。
Pythonコード:PDF内のすべてのページを回転
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成します
pdf = PdfDocument()
# PDFファイルを読み込みます
pdf.LoadFromFile("Sample.pdf")
# すべてのページをループ処理します
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
# 現在の回転角度を取得します
rotation = int(page.Rotation.value)
# 元の角度を基準に、時計回りに180度回転します
rotation += int(PdfPageRotateAngle.RotateAngle180.value)
rotation += int(PdfPageRotateAngle.RotateAngle180.value)
if rotation >= 4:
rotation -= 4
page.Rotation = PdfPageRotateAngle(rotation)
# 結果を保存します
pdf.SaveToFile("RotatePDF.pdf")
pdf.Close()
生成されたドキュメントから評価版のメッセージを削除したい場合や、機能制限を解除したい場合は、30日間の試用ライセンス を申請できます。
既存の PDF ドキュメントにページ番号を追加することは、資料の可読性や実用性を高めるうえで非常に重要です。レポートやマニュアル、帳票など、複数ページにわたる PDF では、ページ番号があることで閲覧・管理が格段にしやすくなります。
本記事では、Spire.PDF for .NET を使用して、C# から既存の PDF にページ番号を追加する方法を解説します。左寄せ・中央揃え・右寄せといった配置の違いを、PDF の座標系とあわせて分かりやすく説明します。
目次
はじめに、Spire.PDF for .NET を .NET プロジェクトに追加します。Spire.PDF for .NET を手動でダウンロードし、DLL を参照に追加するか、NuGet を使用してインストールできます。以下は NuGet インストールコードです。
PM> Install-Package Spire.PDF
インストールが完了したら、PDF 操作に必要なクラスを使用できるようになります。
Spire.PDF for .NET で PDF を操作する際は、座標系の考え方を理解しておくことが重要です。
以下は、Spire.PDFにおける座標系を示す画像です。
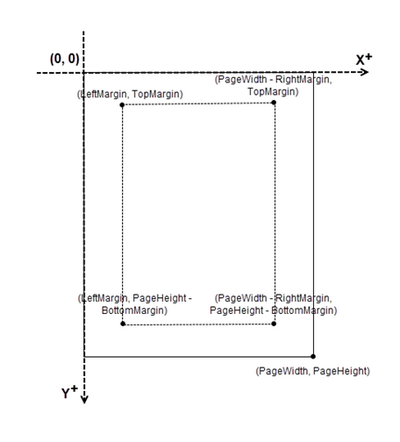
ページ番号は通常、ヘッダーまたはフッターに配置します。そのため、ページサイズや余白を考慮しながら、描画位置(特に X 座標)を調整する必要があります。
本記事で紹介する左寄せ・中央揃え・右寄せの違いは、すべて X 座標の計算方法の違いによって実現します。
まずは、ページ番号を追加するための共通的な実装を確認します。
Spire.PDF for .NET では、以下のクラスを使用します。
これらを組み合わせることで、「X ページ/全 Y ページ」という形式のページ番号を作成できます。
PDFのページの左隅にページ番号を追加するC#コード例
using Spire.Pdf;
using Spire.Pdf.AutomaticFields;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace AddPageNumbers
{
class Program
{
static void Main(string[] args)
{
// 1. PDF ドキュメントを読み込む
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Sample.pdf");
// 2. ページ番号用のフォントと描画スタイルを定義
PdfTrueTypeFont font = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 12, FontStyle.Regular), true);
PdfBrush brush = PdfBrushes.Black;
PdfPen pen = new PdfPen(brush, 1.0f);
// 3. ページ番号と総ページ数のフィールドを作成
PdfPageNumberField pageNumberField = new PdfPageNumberField();
PdfPageCountField pageCountField = new PdfPageCountField();
// 4. 表示形式を定義(例:1 ページ/全 10 ページ)
PdfCompositeField compositeField = new PdfCompositeField(
font, brush, "{0} ページ/全 {1} ページ",
pageNumberField, pageCountField);
// 5. ページ番号の描画位置
SizeF pageSize = doc.Pages[0].Size;
compositeField.Location = new PointF(72, pageSize.Height - 45);
// 6. 各ページにページ番号を描画
for (int i = 0; i < doc.Pages.Count; i++)
{
PdfPageBase page = doc.Pages[i];
// 補助線(フッターの区切り線)
page.Canvas.DrawLine(
pen, 72, pageSize.Height - 50,
pageSize.Width - 72, pageSize.Height - 50);
compositeField.Draw(page.Canvas);
}
// 7. PDF を保存
doc.SaveToFile("AddPageNumbers.pdf");
doc.Dispose();
}
}
}
以下は、ページ番号付きの生成済みPDFファイルのプレビューです。
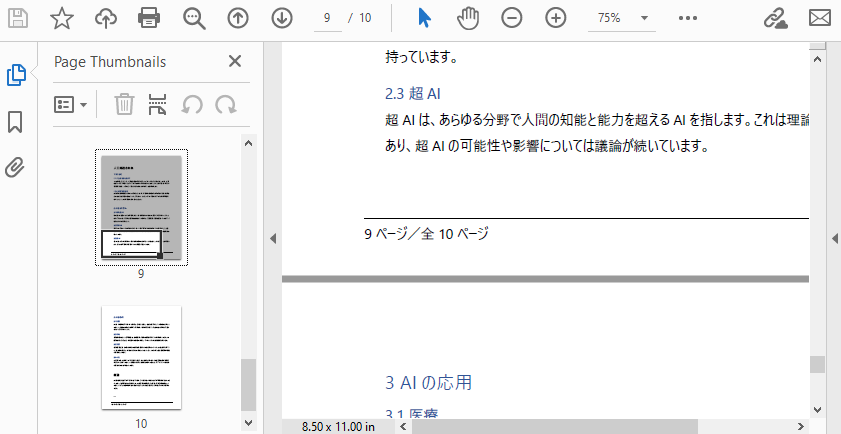
この共通処理をベースに、次の章では配置方法ごとの違いを説明します。
新しいPDF文書を作成し、そこにページ番号を追加したい場合は、「C#でPDF文書を作成する方法」も併せてご確認ください。
左寄せの場合は、X 座標を固定値に設定します。これにより、すべてのページで左端から一定の位置にページ番号が表示されます。
compositeField.Location = new PointF(72, pageSize.Height - 45);
この方法は、帳票やビジネス文書など、レイアウトが厳密に決まっている PDF に適しています。
中央揃えにする場合は、ページ番号文字列の幅を動的に計算する必要があります。
SizeF pageNumberSize = font.MeasureString(
string.Format("{0} ページ/全 {1} ページ", i + 1, doc.Pages.Count));
compositeField.Location = new PointF(
(pageSize.Width - pageNumberSize.Width) / 2,
pageSize.Height - 45);
ページ幅から文字列幅を引き、その半分を X 座標として指定することで、正確に中央配置できます。
右寄せの場合も文字列幅を考慮します。ページの右端から余白分を引いた位置に配置します。
SizeF pageNumberSize = font.MeasureString(
string.Format("{0} ページ/全 {1} ページ", i + 1, doc.Pages.Count));
compositeField.Location = new PointF(
pageSize.Width - pageNumberSize.Width - 72,
pageSize.Height - 45);
この方法は、書籍や報告書など、右下にページ番号を配置したい場合によく使用されます。
本記事では、Spire.PDF for .NET を使用して、C# から既存の PDF にページ番号を追加する方法を解説しました。
用途に応じて、左寄せ・中央揃え・右寄せを使い分けてみてください。
評価版の制限や透かしを解除したい場合は、30 日間の試用ライセンスを申請できます。詳細は公式サイトをご確認ください。

多くの .NET ベースの業務システムでは、構造化データが DataTable 形式で管理されています。これらのデータを配布、アーカイブ、あるいは読み取り専用のレポートとして提供する場合、C# で DataTable を PDF に出力することは非常に一般的かつ実用的な要件です。
Excel や CSV などのフォーマットと比べ、PDF は版面の安定性、視覚的一貫性、文書の完全性が重要な場面に適しています。データの編集性よりも、レポート、請求書、監査記録、システム自動生成の公式文書などで特に有用です。
本記事では、コード中心のアプローチで C# で DataTable を PDF に変換する方法 を解説します。例は Spire.PDF for .NET を使用し、PdfGrid コンポーネントで DataTable の内容を構造化された表として PDF にレンダリングします。
目次
本質的には、DataTable を PDF に出力することは、データバインディング + レンダリング の問題であり、低レベルの描画処理ではありません。
つまり、各行の位置や列幅を手動で計算したり、ページ分割のロジックを自分で処理する必要はありません。合理的な方法は、既存の DataTable を直接 PDF 表コンポーネントにバインドし、レンダリングエンジンにレイアウトとページ分割を自動で行わせることです。
Spire.PDF for .NET では、この役割を PdfGrid クラスが担います。
PdfGrid は Spire.PDF for .NET のクラスで、PDF ドキュメント内に構造化表データを表示するためのものです。行、列、ヘッダー、ページ分割などの概念を中心に扱い、単なるグラフィック描画ではありません。
技術的には、PdfGrid は以下の重要な機能を提供します:
つまり、DataTable の PDF 出力は 宣言的操作 のように扱えます。どのデータをレンダリングするかを指定するだけで、ページ内での配置やページ分割 は PDF エンジンが自動で処理します。
次章以降では、この考え方に基づき、具体的な実装方法や実務での最適化テクニックを解説します。
本記事のサンプルコードは .NET Framework および最新 .NET(6 以上) プロジェクトで共通して使用可能です。
実装はすべてマネージコードで行うため、プラットフォーム固有の追加設定は不要です。
NuGet を使用して Spire.PDF for .NET をインストールできます:
Install-Package Spire.PDF
または、Spire.PDF for .NET を直接ダウンロード して、手動でプロジェクトに追加することも可能です。
インストール完了後、PDF ドキュメント作成、ページ管理、表レンダリング、スタイル制御のための API が利用可能になります。
環境準備が整ったら、DataTable の PDF 出力は 線形で実装指向 のプロセスになります。
基本的な考え方は:既存の DataTable を PdfGrid にバインドし、レイアウト、ページ分割、表描画の責任を PDF エンジンに任せることで、行や列、罫線を手動で描画する必要はありません。
実装フローは一般的に次のステップで構成されます:
注意:DataTable に日本語や中国語などの文字が含まれる場合、デフォルトフォントでは正しく表示されず空白になることがあります。 レンダリング前に「メイリオ」や「MS ゴシック」などの日本語対応フォントを PdfTrueTypeFont を通して表スタイルに適用する必要があります。
実際のプロジェクトでは、これらのステップを同一コードフロー内で順次実行することが多いです。以下に、すぐに使える完全サンプルを示します。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Grid;
using System.Data;
using System.Drawing;
DataTable dataTable = new DataTable();
dataTable.Columns.Add("OrderId", typeof(int));
dataTable.Columns.Add("CustomerName", typeof(string));
dataTable.Columns.Add("OrderDate", typeof(DateTime));
dataTable.Columns.Add("TotalAmount", typeof(decimal));
// 実務に近い日本向けサンプルデータ
dataTable.Rows.Add(1001, "楽天市場", DateTime.Today, 15800.75m);
dataTable.Rows.Add(1002, "Amazonジャパン", DateTime.Today, 8900.50m);
dataTable.Rows.Add(1003, "ヨドバシカメラ", DateTime.Today, 23400.00m);
dataTable.Rows.Add(1004, "ビックカメラ", DateTime.Today, 17600.20m);
dataTable.Rows.Add(1005, "メルカリ", DateTime.Today, 11200.00m);
dataTable.Rows.Add(1006, "LOHACO", DateTime.Today, 9800.30m);
PdfDocument document = new PdfDocument();
PdfPageBase page = document.Pages.Add();
PdfGrid grid = new PdfGrid();
grid.DataSource = dataTable;
// 日本語対応フォントを設定(文字化け防止)
PdfGridCellStyle cellStyle = new PdfGridCellStyle();
// メイリオフォントを使用し、第二引数 true でフォントを PDF に埋め込む
cellStyle.Font = new PdfTrueTypeFont(new Font("メイリオ", 9f), true);
grid.Rows.ApplyStyle(cellStyle);
// 表格をページ上に描画(ページ上端から40fの位置)
grid.Draw(page, new PointF(0, 40f));
// PDF保存
document.SaveToFile("DataTableToPDF.pdf");
document.Close();
以下は生成されたPDFファイルの効果プレビューです。
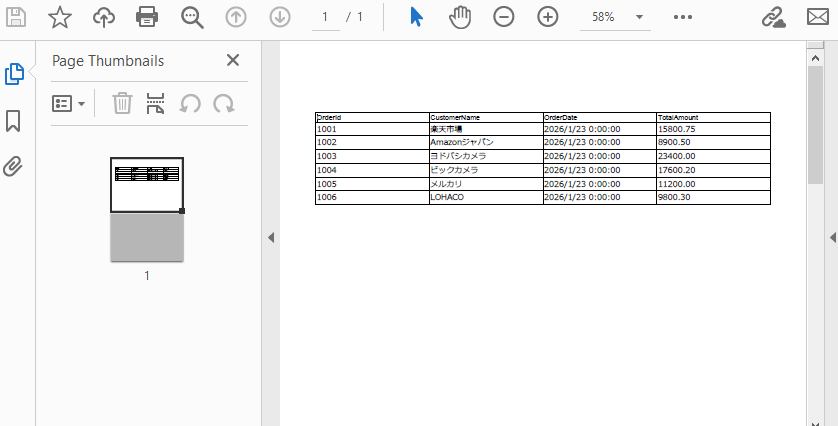
このコードで DataTable → PDF の完全な出力が実現できます。 生成される PDF は構造が明確で、ページ分割にも対応しており、多くの実務シナリオでそのまま利用可能です。
もちろん、実際のプロジェクトでは、通常、表の位置、ページサイズ、方向、スタイルに対してより高い要求が課されます。 次の章では、コアのエクスポートロジックを変更せずに、レイアウト、ページ分割、視覚効果を細かく制御する方法に焦点を当てて説明します。
実務文書では、表は通常ページの一部に過ぎません。ページサイズ、表の開始位置、ページ分割方法が、1ページまたは複数ページにわたる表の表示に影響します。
PdfGrid では、これらは表自体が管理するのではなく、ページ作成時や Draw メソッド呼び出し時に解決されます。 PdfGrid は絶対位置指定やページ切り替えを直接担当せず、ページ設定や描画パラメータが実際に機能します。
以下は、実務レポートでよく使われるレイアウトとページ分割の設定例です。
PdfDocument document = new PdfDocument();
// A4ページを作成し、マージンを設定
PdfPageBase page = document.Pages.Add(
PdfPageSize.A4,
new PdfMargins(40),
PdfPageRotateAngle.RotateAngle0, // ページ座標系の回転角度
PdfPageOrientation.Landscape // ページ方向:横向き
);
PdfGrid grid = new PdfGrid();
grid.DataSource = dataTable;
// 複数ページにわたる場合、ヘッダーを繰り返し表示
grid.RepeatHeader = true;
// 表の描画開始位置を指定
float startX = 40f;
float startY = 80f;
// 日本語対応フォントを適用
PdfGridCellStyle cellStyle = new PdfGridCellStyle();
cellStyle.Font = new PdfTrueTypeFont(new Font("メイリオ", 9f), true);
grid.Rows.ApplyStyle(cellStyle);
// 表を描画
grid.Draw(page, new PointF(startX, startY));
この設定で生成される PDF の例:
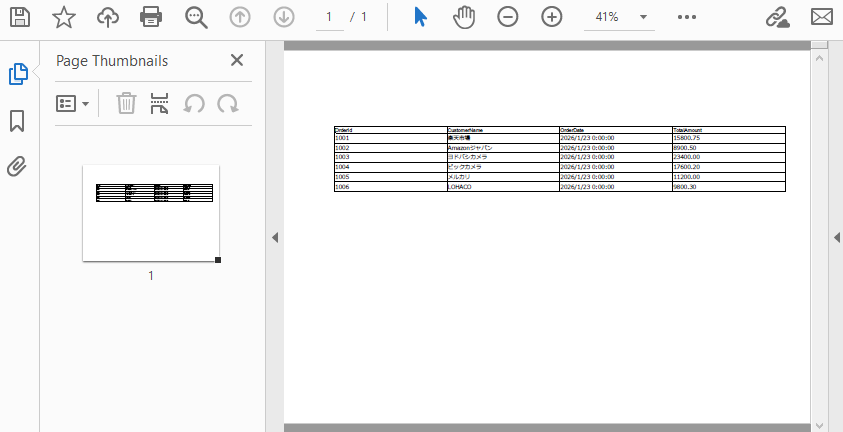
PdfPageBase
RepeatHeader
Draw メソッド
ページの幾何設定、表の開始位置、ページ分割ルールを統一することで、PdfGrid は手動でページ分割や行ごとのレイアウトを制御することなく、安定した複数ページ表を生成できます。
レイアウトが安定したら、次は表の外観制御です。PdfGrid は集中型スタイルモデルを提供しており、データバインディングやページ分割に影響を与えず、表全体や列、行のスタイルを設定できます。
以下は、レポートでよく使われるスタイル設定例です。
PdfDocument document = new PdfDocument();
PdfPageBase page = document.AppendPage();
PdfGrid grid = new PdfGrid();
grid.DataSource = dataTable;
// ヘッダースタイルの作成と適用
PdfGridCellStyle headerStyle = new PdfGridCellStyle();
headerStyle.Font =
new PdfFont(PdfFontFamily.Helvetica, 10f, PdfFontStyle.Bold);
headerStyle.BackgroundBrush =
new PdfSolidBrush(Color.FromArgb(60, 120, 200));
headerStyle.TextBrush = PdfBrushes.White;
grid.Headers.ApplyStyle(headerStyle);
// 行スタイル
PdfGridCellStyle defaultStyle = new PdfGridCellStyle();
defaultStyle.Font = new PdfTrueTypeFont(new Font("メイリオ", 9f), true);
PdfGridCellStyle alternateStyle = new PdfGridCellStyle();
alternateStyle.BackgroundBrush =
new PdfSolidBrush(Color.LightSkyBlue);
alternateStyle.Font = new PdfTrueTypeFont(new Font("メイリオ", 10f), true);
// 行の交互色適用
for (int rowIndex = 0; rowIndex < grid.Rows.Count; rowIndex++)
{
if (rowIndex % 2 == 0)
{
grid.Rows[rowIndex].ApplyStyle(defaultStyle);
}
else
{
grid.Rows[rowIndex].ApplyStyle(alternateStyle);
}
}
// 列幅を明示的に設定
grid.Columns[0].Width = 60f; // OrderId
grid.Columns[1].Width = 140f; // CustomerName
grid.Columns[2].Width = 90f; // OrderDate
grid.Columns[3].Width = 90f; // TotalAmount
// 表を描画
grid.Draw(page, new PointF(40f, 80f));
適用後の PDF の例:
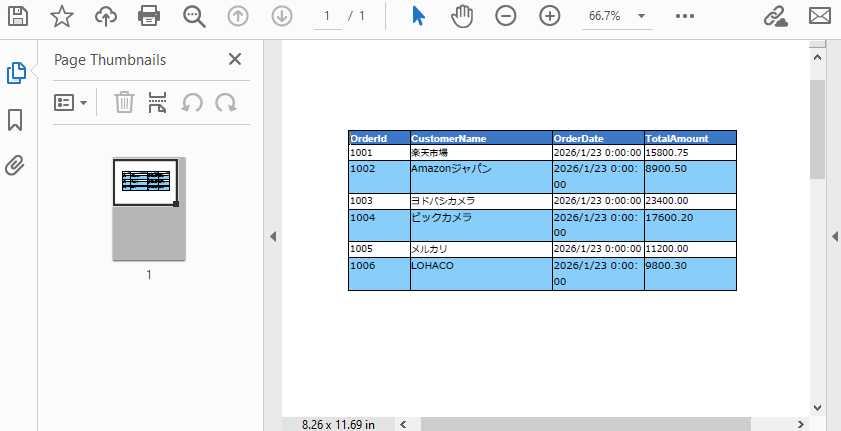
ヘッダースタイル
データ行スタイル
列幅制御
注意:スタイルは grid.Draw(...) を呼ぶ前に設定してください。 すべてのスタイルは描画前に解析され、ページ分割やデータバインディングに影響せず適用されます。
より複雑な表のスタイル制御(枠線、配置、条件付きスタイルなど)が必要な場合は、C# を使用した PDF 表の作成と装飾 を参照してください。
表の描画が完了したら、最後に PDF を出力します。 ファイル出力でもメモリストリーム出力でも、表の生成・描画ロジックは同一です。違いは出力先だけです。
PDF を直接ファイルに保存。デスクトップアプリやバッチ処理向け。
document.SaveToFile("DataTableReport.pdf");
document.Close();
適用例:
Web 系では、PDF をディスクに書き込まず、メモリ上で処理しそのままクライアントに返すことが可能。
using (MemoryStream stream = new MemoryStream())
{
document.SaveToStream(stream);
document.Close();
byte[] pdfBytes = stream.ToArray();
// pdfBytes を HTTP レスポンスとして返す
}
ASP.NET コントローラや Minimal API との統合も容易で、テンポラリファイル不要です。 参考:ASP.NET で PDF を生成して返す
PdfGrid はデータを文字列としてレンダリングします。 フォーマット指定が必要な場合、バインド前に統一処理します。
例:
データレイヤで処理するのが推奨です。
DataTable に DBNull.Value があると、セルが空白になったりレイアウトが崩れる場合があります。
バインド前に正規化すると安全です:
row["TotalAmount"] =
row["TotalAmount"] == DBNull.Value ? 0m : row["TotalAmount"];
列が多い、内容が長い場合、表がページ幅を超えることがあります。
対策:
これらは レイアウト層 で処理するのが正しい方法です。
数百~数千行の DataTable では性能差が顕著になります。
推奨:
例:大規模データで grid.Rows[rowIndex].ApplyStyle(...) をループで繰り返すと負荷増。 不要であれば grid.Rows.ApplyStyle(...) で一括適用が最適。
Web 環境では、PDF生成をリクエストスレッド外で処理すると、応答のブロックを回避できます。
C# で DataTable を PDF に出力 する際、手動で表を構築したり低レベル描画を行う必要はありません。 PdfGrid に DataTable を直接バインドするだけで、自動ページ分割対応の PDF 表を生成でき、レイアウトや外観も容易に制御可能です。
この記事では、実務視点で導出プロセス、レイアウト、スタイル設定、データ準備などの重要ポイントを解説しました。 この方法はシンプルなレポートから、複数ページ・大規模データを含む複雑な文書まで拡張可能です。
試用したい場合は E-ICEBLUE から 一時ライセンス を取得して、フル機能を制限なくテストできます。
構造が明確で、ページ分割に対応し、版面が安定した表型 PDF 文書 を作る場合に最適です。 列生成、ヘッダー、ページ分割を自動で処理するため、手動描画よりもレポートや請求書、監査用文書に適しています。
日付形式、数値精度、空値処理などのデータ規格化はバインド前に行います。 PdfGrid はレイアウトやスタイル担当であり、データ変換には使用しません。
可能です。PdfGrid は自動ページ分割とヘッダー繰り返し表示をサポートします。大規模データでは、行・セル単位のスタイル適用を避け、表や列単位のスタイルを使用するとパフォーマンスが維持できます。
Spire.Presentation 11.1.1 がリリースされました。本バージョンでは、正規表現の一致結果に基づいてテキストを強調表示する機能が新たに追加されました。また、PPTX から PDF への変換時に発生していた、コンテンツ欠落や既定フォントが適用されない問題も修正されました。詳細は以下のとおりです。
| カテゴリー | ID | 説明 |
| 新機能 | - | 正規表現の一致結果に基づいてテキストを強調表示する機能を追加しました。
// 簡単な単語マッチング Regex regex = new Regex(@"\bhello\b"); IAutoShape shape = (IAutoShape)ppt.Slides[0].Shapes[0]; TextHighLightingOptions options = new TextHighLightingOptions(); shape.TextFrame.HighLightRegex(regex, Color.Red, options); |
| 不具合修正 | SPIREPPT-3051 | PPTX を PDF に変換する際、一部の内容が欠落する問題を修正しました。 |
| 不具合修正 | SPIREPPT-3058 | PPTX を PDF に変換する際、設定した既定フォントが適用されない問題を修正しました。 |





