

Word ドキュメントを OFD(Open Fixed-layout Document)に変換する処理は、特に中国市場向けの C++ アプリケーションではよく求められます。例えば、公文書の提出、アーカイブ、またはレイアウトを厳密に維持する必要がある帳票出力などです。ただし、この変換を安定して実装するのは意外と簡単ではありません。従来の Microsoft Office(COM)に依存する方法は、サーバー環境では不安定になりやすく、デプロイや運用の負担も大きくなります。
本記事では、Spire.Doc for C++ を使用して、プログラムで Word を OFD に変換する方法を解説します。基本的な文書変換から、特定のページのみを OFD 形式で書き出すといった高度なシナリオまでカバーします。
Word は編集には便利ですが、中国向けの公文書やアーカイブ用途では OFD が標準として広く採用されています。Word を OFD に変換することで、次のようなメリットがあります。
特にバックエンド処理や自動化されたドキュメント生成のシナリオでは、OFD 形式への変換は実用的かつ重要なステップになります。
C++ で Word を OFD に変換する方法には、COM 自動化、外部ツールの呼び出し、または .docx フォーマットの手動解析など、いくつかのアプローチがあります。しかし、それぞれにプラットフォームの制約、環境依存、あるいは膨大な実装コストといったデメリットがあります。
Spire.Doc for C++ は、これらの問題の大部分を解決します。
変換を始める前に、開発環境とプロジェクトが適切に構成されていることを確認してください。
Include ディレクトリのパスを追加し、lib ディレクトリをリンクするように設定します。DLL ファイルが実行ファイルと同じディレクトリ、またはシステムパスにあることを確認してください。詳細な手順については、C++ アプリケーションに Spire.Doc for C++ を統合する方法を参照してください。
インストール後、コードを記述する前に以下の準備を行ってください。
ヘッダーのインクルード:
#include "Spire.Doc.o.h"
必要な名前空間の追加:
using namespace Spire::Doc;
プロジェクトの準備ができれば、Word を OFD に変換する処理は、わずか数行のコードで実現できます。
以下に完全な C++ の例を示します。
#include "Spire.Doc.o.h"
#include <iostream>
using namespace Spire::Doc;
int main()
{
// Document オブジェクトを作成
Document* document = new Document();
try {
// Word ファイルを読み込む
document->LoadFromFile(L"C:\\Users\\Tommy\\Desktop\\Sample.docx");
// OFD 形式で保存
document->SaveToFile(L"C:\\Users\\Tommy\\Desktop\\Sample.ofd", FileFormat::OFD);
// ドキュメントを閉じる
document->Close();
std::cout << "変換に成功しました!" << std::endl;
}
catch (const std::exception& ex) {
// エラーハンドリング
std::cerr << "エラーが発生しました: " << ex.what() << std::endl;
delete document;
return -1;
}
// メモリの解放
delete document;
return 0;
}

コードの解説:
Spire.Doc for C++ では、特定のページのみを書き出したり、画像の圧縮率やフォントの埋め込みを調整したりすることで、変換プロセスを詳細に制御できます。
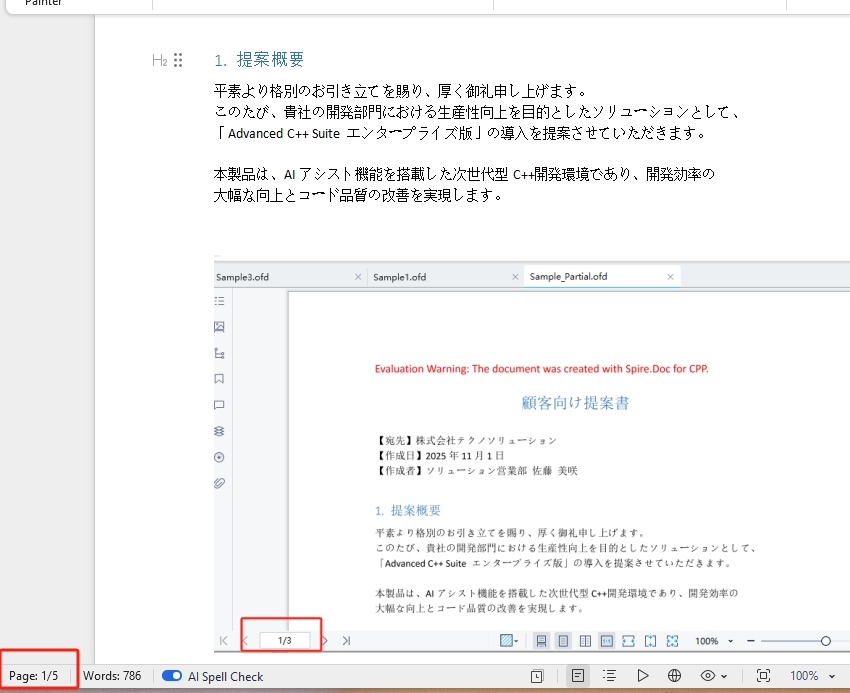
Word ドキュメントの特定のページだけを OFD 形式に変換したい場合があります。以下の例では、特定のページを抽出して別個の OFD ファイルとして保存する方法を示します。
#include "Spire.Doc.o.h"
#include <iostream>
using namespace Spire::Doc;
int main()
{
// スマートポインタを使用して Document オブジェクトを作成
intrusive_ptr<Document> document = new Document();
try {
document->LoadFromFile(L"C:\\Users\\Tommy\\Desktop\\Sample.docx");
// 1ページ目から3ページ目までを抽出(インデックスは0から始まります)
intrusive_ptr<Document> newDoc = document->ExtractPages(0, 3);
// 抽出したページを OFD として保存
newDoc->SaveToFile(L"C:\\Users\\Tommy\\Desktop\\Sample_Partial.ofd", FileFormat::OFD);
document->Close();
newDoc->Close();
std::cout << "特定ページの抽出と変換に成功しました!" << std::endl;
}
catch (const std::exception& ex) {
std::cerr << "エラーが発生しました: " << ex.what() << std::endl;
return -1;
}
return 0;
}
コードの解説:
生成される OFD のファイルサイズを小さくしたり、異なる環境でもフォントが正しく表示されるようにしたりするために、変換設定を調整できます。
#include "Spire.Doc.o.h"
#include <iostream>
using namespace Spire::Doc;
int main()
{
intrusive_ptr<Document> document = new Document();
try {
document->LoadFromFile(L"C:\\Users\\Tommy\\Desktop\\Sample.docx");
// JPEG 画像の品質を75%に設定(0-100の範囲)
document->SetJPEGQuality(75);
// フォント埋め込み設定用のリストを作成
intrusive_ptr<ToPdfParameterList> parameters = new ToPdfParameterList();
// すべてのフォントをドキュメントに埋め込む
parameters->SetIsEmbeddedAllFonts(true);
document->SaveToFile(L"C:\\Users\\Tommy\\Desktop\\Sample.ofd", FileFormat::OFD);
document->Close();
std::cout << "カスタマイズ設定での変換に成功しました" << std::endl;
}
catch (const std::exception& ex) {
std::cerr << "エラー: " << ex.what() << std::endl;
return -1;
}
return 0;
}
A: いいえ、必要ありません。Spire.Doc for C++ は独立して動作し、システムに Word がインストールされていなくても変換が可能です。
A: 前述の通り、ExtractPages() メソッドを使用して必要なページを新しい Document オブジェクトとして抽出し、それを OFD 形式で保存してください。
A: これは通常、必要なフォントがシステムにインストールされていない場合に発生します。保存前に SetIsEmbeddedAllFonts(true) を呼び出してフォントを埋め込むことで解決できます。
A: 画像の圧縮を有効にするか、SetJPEGQuality() を使用して画質を下げることでファイルサイズを削減できます。
A: OFD は中国の電子文書国家標準であり、PDF は国際標準です。OFD は中国の電子政府や公式ワークフローで広く採用されています。どちらの形式もドキュメントのレイアウトと書式を保持します。
C++ で Word ドキュメントを OFD に変換する機能は、信頼性の高い文書共有や中国国家標準への準拠が必要なアプリケーションにとって不可欠です。Spire.Doc for C++ を使用すれば、Microsoft Office に依存することなく、プログラムで簡単にこの変換を実装できます。本ガイドで紹介したように、全文書の変換だけでなく、特定ページの抽出や詳細なカスタマイズも可能であり、実務における C++ ドキュメント処理の強力なソリューションとなります。
TIFF は、高品質であり、幅広いカラースペースをサポートしているため、スキャンやアーカイブで使用される一般的な画像形式です。一方、PDF は、ファイルサイズを圧縮しながらドキュメントのレイアウトと書式を保持するため、ドキュメント交換に広く使用されています。これらの形式間の変換は、アーカイブ、編集、またはドキュメント共有など、さまざまな目的で役立ちます。
この記事では、Spire.PDF for Python と Pillow ライブラリを使用して、PDF を TIFF に変換する方法と、TIFF を PDF に変換する方法を学びます。
この方法は、Spire.PDF for Python と Pillow(PIL)の組み合わせに依存します。Spire.PDF は PDF ドキュメントの読み取り、作成、および変換に使用され、PIL ライブラリは TIFF ファイルの処理およびそのフレームへのアクセスに使用されます。
これらのライブラリは、以下の pip コマンドを使用して簡単にデバイスにインストールできます。
pip install Spire.PDF
pip install pillow
PDF を TIFF に変換するには、まず Spire.PDF を使用して PDF ドキュメントを読み込み、各ページを画像ストリームに変換する必要があります。その後、これらの画像ストリームを PIL ライブラリの機能を使用して結合し、1 つの TIFF 画像にまとめます。
以下は、Python を使用して PDF を TIFF に変換する手順です。
from spire.pdf.common import *
from spire.pdf import *
from PIL import Image
from io import BytesIO
# PdfDocumentオブジェクトを作成
doc = PdfDocument()
# PDFファイルを読み込む
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# PIL画像を格納するリスト
images = []
# すべてのページをループ処理
for i in range(doc.Pages.Count):
# ページを画像ストリームに変換
with doc.SaveAsImage(i) as imageData:
# PIL画像として読み込む
img = Image.open(BytesIO(imageData.ToArray()))
# リストに追加
images.append(img)
# マルチページTIFFとして保存
images[0].save("Output/ToTIFF.tiff", save_all=True, append_images=images[1:])
# リソース解放
doc.Dispose()
PIL ライブラリの助けを借りて、TIFF ファイルを読み込み、各フレームを個別の PNG ファイルに変換できます。その後、Spire.PDF を使用して、これらの PNG ファイルを PDF ドキュメント内のページに描画できます。
Python を使用して TIFF 画像を PDF ドキュメントに変換するには、以下の手順に従います。
PdfDocument オブジェクトを作成する。
TIFF 画像を読み込む。
TIFF 画像内のフレームを繰り返し処理する。
ドキュメントを PDF ファイルとして保存する。
from spire.pdf.common import *
from spire.pdf import *
from PIL import Image
import io
# PdfDocumentオブジェクトを作成
doc = PdfDocument()
# ページ余白を0に設定
doc.PageSettings.SetMargins(0.0)
# TIFF画像を読み込む
tiff_image = Image.open("C:\\Users\\Administrator\\Desktop\\TIFF.tiff")
for i in range(tiff_image.n_frames):
# フレームを選択
tiff_image.seek(i)
# フレーム画像をコピー
frame_image = tiff_image.copy()
# PNGとして保存
frame_image.save(f"temp/output_frame_{i}.png")
# PdfImageとして読み込む
image = PdfImage.FromFile(f"temp/output_frame_{i}.png")
# 画像サイズを取得
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# ページを追加
page = doc.Pages.Add(SizeF(width, height))
# 画像を描画
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# PDFとして保存
doc.SaveToFile("Output/TiffToPdf.pdf", FileFormat.PDF)
# リソース解放
doc.Dispose()
この記事では、Spire.PDF for Python と Pillow の機能を組み合わせることで、Python を使用して PDF と TIFF 形式の間で変換する方法を説明しました。Spire.PDF の強力な PDF 処理機能と Pillow の柔軟な画像処理を活用することで、PDF から TIFF への変換および TIFF から PDF への変換の両方を効率的に実行できます。
評価メッセージの削除や機能制限の解除をご希望の場合は、営業担当者までお問い合わせのうえ、30日間有効な一時ライセンスを取得してください。

Python で Excel ファイルをインポートする場合、単にファイルを読み込むだけでは不十分なことがほとんどです。多くのケースでは、データをリストや辞書など、アプリケーションで直接利用できる Python のデータ構造へ変換する必要があります。
この変換ステップは非常に重要です。なぜなら、Excel のデータは通常表形式で保存されているのに対し、Python アプリケーションでは処理・統合・保存のために構造化されたデータが求められるからです。用途に応じて、データは順次処理用のリスト、フィールド単位でアクセスするための辞書、構造化モデルとしてのカスタムオブジェクト、あるいは永続化のためのデータベースとして表現されます。
本ガイドでは、Spire.XLS for Python を使用して、Excel ファイルを Python にインポートし、データを複数の構造に変換する方法を実用的な例とともに解説します。
目次
Python に Excel データをインポートする処理は、基本的に以下の 2 ステップで構成されます。
この分離は重要です。実際のアプリケーションでは、単に Excel を読み込むだけでは不十分であり、データを処理・保存・システム統合に適した形式へ変換する必要があるためです。
Spire.XLS for Python を使用して Excel データをインポートする場合、以下のコンポーネントが関与します。
一般的なワークフローは次のとおりです。
Excel ファイル → Workbook → Worksheet → CellRange → Python データ構造
このパイプラインを理解することで、さまざまなシナリオに対応できる柔軟なインポートロジックを設計できます。
以下の例を実行する前に、pip で Spire.XLS for Python をインストールします。
pip install spire.xls
必要に応じて、Spire.XLS for Python をダウンロード してプロジェクトに組み込むこともできます。
次の例は、Excel データを Python にインポートする最もシンプルな方法を示しています。
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
data = []
sheet = workbook.Worksheets[0]
# 使用されているセル範囲を取得
cellRange = sheet.AllocatedRange
# 1 行目のデータを取得
for col in range(cellRange.Columns.Count):
data.append(sheet.Range[1, col +1].Value)
print(data)
workbook.Dispose()
以下は、Excel ファイルからインポートされたデータのプレビューです。
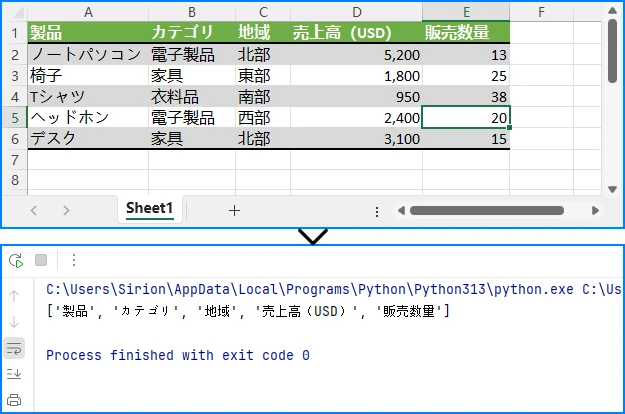
この最小限の例では、基本的なワークフローを示しています。すなわち、Workbook の初期化、Excel ファイルの読み込み、Worksheet およびセルデータへのアクセス、そしてリソース解放のための Dispose 処理です。
Python で Excel データをインポートする最もシンプルな方法の一つは、行単位のリストとして変換することです。この構造は、反復処理や基本的なデータ処理に適しています。
from spire.xls import *
# Workbook を読み込み
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
# 最初のワークシートの使用範囲を取得
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
# データ格納用リストを作成
data = []
for row_index in range(cellRange.RowCount):
row_data = []
for cell_index in range(cellRange.ColumnCount):
row_data.append(cellRange[row_index + 1, cell_index + 1].Value)
data.append(row_data)
workbook.Dispose()
リストとしてインポートする場合、ワークシートの各行が Python のリストとして扱われ、元の行順が保持されます。
コードの仕組み:
+1 のオフセットを適用しますこの設計の利点:
この構造は、順次処理や簡単な変換、または辞書やオブジェクトへの変換前の基盤データとして最適です。
Excel ファイルにヘッダー行が含まれている場合、辞書としてインポートすることで、より整理されたデータ管理と列名ベースのアクセスが可能になります。
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
rows = list(cellRange.Rows)
headers = [cellRange[1, cell_index + 1].Value for cell_index in range(cellRange.ColumnCount)]
data_dict = []
for row in rows[1:]:
row_dict = {}
for i, cell in enumerate(row.Cells):
row_dict[headers[i]] = cell.Value
data_dict.append(row_dict)
workbook.Dispose()
辞書としてインポートする場合、各行は列ヘッダーをキーとするキー・バリュー構造に変換されます。
コードの仕組み:
この設計の利点:
この方法は、構造化データの処理や、JSON、API 連携、ラベル付きデータセットに適しています。
構造化されたアプリケーションでは、型安全性を維持しつつビジネスロジックをカプセル化するために、Excel データを Python オブジェクトとしてインポートする必要がある場合があります。
class Employee:
def __init__(self, name, age, department):
self.name = name
self.age = age
self.department = department
from spire.xls import *
from spire.xls.common import *
workbook = Workbook()
workbook.LoadFromFile("EmployeeData.xlsx")
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
employees = []
for row in list(cellRange.Rows)[1:]:
name = row.Cells[0].Value
age = int(row.Cells[1].Value) if row.Cells[1].Value else None
department = row.Cells[2].Value
emp = Employee(name, age, department)
employees.append(emp)
workbook.Dispose()
オブジェクトとしてインポートする場合、各行は構造化されたクラスインスタンスへマッピングされます。
コードの仕組み:
この設計の利点:
この方法は、バックエンドシステムやビジネスロジック層など、明確なデータモデルを持つアプリケーションに適しています。
多くのアプリケーションでは、Excel データを永続的に保存し、クエリ可能にするためにデータベースへ格納する必要があります。
import sqlite3
from spire.xls import *
# SQLite データベースに接続
conn = sqlite3.connect("sales.db")
cursor = conn.cursor()
# Excel 構造に対応したテーブルを作成
cursor.execute("""
CREATE TABLE IF NOT EXISTS sales (
product TEXT,
category TEXT,
region TEXT,
sales REAL,
units_sold INTEGER
)
""")
# Excel ファイルを読み込み
workbook = Workbook()
workbook.LoadFromFile("Sales.xlsx")
# 最初のワークシートにアクセス
sheet = workbook.Worksheets[0]
rows = list(sheet.AllocatedRange.Rows)
# 各行を処理(ヘッダー行はスキップ)
for row in rows[1:]:
product = row.Cells[0].Value
category = row.Cells[1].Value
region = row.Cells[2].Value
# 桁区切りを削除して float に変換
sales_text = row.Cells[3].Value
sales = float(str(sales_text).replace(",", "")) if sales_text else 0
# 販売数を整数に変換
units_text = row.Cells[4].Value
units_sold = int(units_text) if units_text else 0
# データベースに挿入
cursor.execute(
"INSERT INTO sales VALUES (?, ?, ?, ?, ?)",
(product, category, region, sales, units_sold)
)
# 変更を確定して接続を閉じる
conn.commit()
conn.close()
# Excel リソースを解放
workbook.Dispose()
以下は、Excel データおよび SQLite データベース構造のプレビューです。
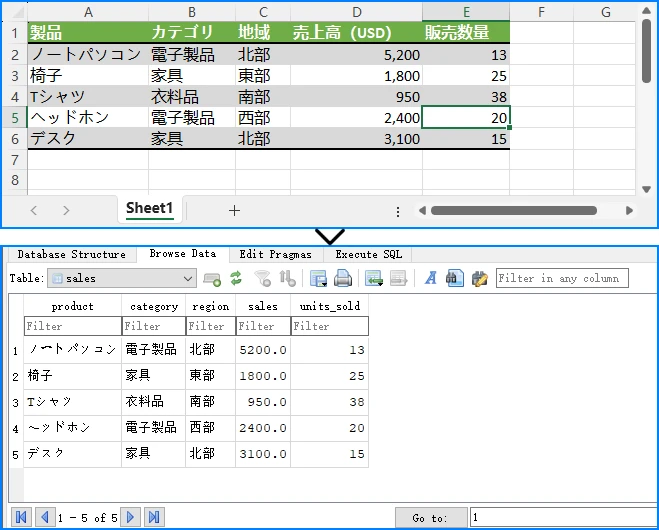
データベースへのインポートでは、各行が永続的なレコードとして保存されます。
コードの仕組み:
この設計の利点:
この方法が適しているケース:
データの保存、検索、大規模データパイプラインへの統合に適しています。
より詳細な手順については、Excel ファイルとデータベース間でデータを転送する方法 を参照してください。
本ガイドで Spire.XLS for Python を使用しているのは、Excel データへのアクセスと変換をシンプルかつ一貫した方法で実現できるためです。主な利点は以下のとおりです。
構造化されたオブジェクトモデル Workbook、Worksheet、CellRangeなど、Excel の構造に対応したコンポーネントを提供します。これにより、データフローの理解と実装が容易になります。 詳細は Spire.XLS for Python API Reference を参照してください。
データアクセスに特化したレイヤー 低レベルのファイル解析を意識する必要がなく、セル値や範囲に直接アクセスできます。そのため、ファイル構造ではなくデータ変換ロジックに集中できます。
フォーマット互換性 XLS や XLSX に加え、CSV、ODS、OOXML などのスプレッドシート形式をサポートしており、異なるファイル形式でも同じロジックを適用できます。
外部依存なし Microsoft Excel をインストールすることなく処理可能なため、バックエンドサービスや自動化環境に適しています。
Excel ファイルのパスが正しく、スクリプトからアクセス可能であることを確認してください。絶対パスの使用、または作業ディレクトリの確認が重要です。
import os
print(os.getcwd()) # 現在のディレクトリを確認
辞書としてインポートする場合、1 行目にヘッダーが存在することを確認してください。存在しない場合、キーが不正になります。
特に大規模ファイルを扱う場合、処理後は必ず Workbook を解放してください。
workbook.Dispose()
Excel セルの値は、期待する型と異なる場合があります。アプリケーションに応じて適切に検証・変換してください。
Python において、Excel ファイルの「読み込み(Read)」と「インポート(Import)」は関連していますが、異なる概念です。
読み込み(Read) は、ファイルから生データを取得することに焦点を当てます。セル値や行、特定範囲を取得しますが、データ構造自体は変更しません。
インポート(Import) は、読み込みに加えて変換も含みます。取得したデータを、リスト、辞書、オブジェクト、またはデータベースレコードなどに変換し、アプリケーションで直接利用できる形にします。
つまり、読み込みはインポートの一部であり、違いは目的にあります。読み込みはデータ取得、インポートは実用化のための準備です。
Python で Excel ファイルをインポートするとは、単にデータを読み込むことではなく、アプリケーションで活用できる構造へ変換することを意味します。本ガイドでは、Excel データをリストとして扱う方法、辞書へ変換する方法、オブジェクトへマッピングする方法、さらにデータベースへインポートする方法を解説しました。
Spire.XLS for Python を使用すれば、少ないコードで Excel データをさまざまな構造へ変換できます。一貫した API により、多様な Excel 形式や複雑なデータ処理にも対応可能です。
機能を評価するには、30 日間の試用ライセンスを申請 することができます。
Excel データをリスト、辞書、データベースなどの Python 構造に変換し、処理や統合に利用できるようにすることです。
Spire.XLS for Python などのライブラリを使用して、Workbook の読み込み、Worksheet へのアクセス、セルデータの取得を行い、必要な構造へ変換します。
はい。Excel データを読み取り、SQLite、MySQL、PostgreSQL などのデータベースへ挿入できます。データ移行やバックエンド連携でよく利用されます。
用途によって異なります。リストは単純処理、辞書は列名ベースのアクセス、オブジェクトは型安全性とロジック、データベースは永続化と検索に適しています。
不要です。Spire.XLS for Python のようなライブラリは、Excel をインストールせずに処理できます。
PDF ドキュメントは、クロスプラットフォームでの互換性が高く、元のレイアウトや書式を保持できることから、情報共有の手段として広く利用されています。しかし、Web 技術の進化に伴い、Web サイトや各種オンラインプラットフォームに簡単に統合できるコンテンツへの需要が高まっています。このような背景から、PDF を HTML 形式に変換することの価値がますます高まっています。PDF ファイルをより柔軟でアクセスしやすい HTML に変換することで、ユーザーは Web 環境において PDF の情報をより効果的に活用、共有、再利用できるようになります。本記事では、Spire.PDF for .NET を使用して、C# で PDF ファイルを HTML 形式に変換する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを、.NET プロジェクトの参照として追加する必要があります。これらの DLL ファイルは、このリンクからダウンロードするか、NuGet からインストールすることもできます。
PM> Install-Package Spire.PDF
PDF ドキュメントを HTML 形式に変換するには、Spire.PDF for .NET が提供する PdfDocument.SaveToFile(string fileName, FileFormat.HTML) メソッドを使用できます。具体的な手順は次のとおりです。
using Spire.Pdf;
namespace ConvertPdfToHtml
{
internal class Program
{
static void Main(string[] args)
{
// PdfDocumentクラスのインスタンスを作成する
PdfDocument doc = new PdfDocument();
// PDF ドキュメントをロードする
doc.LoadFromFile("Sample.pdf");
// PDF ドキュメントを HTML 形式で保存する
doc.SaveToFile("PdfToHtml.html", FileFormat.HTML);
doc.Close();
}
}
}
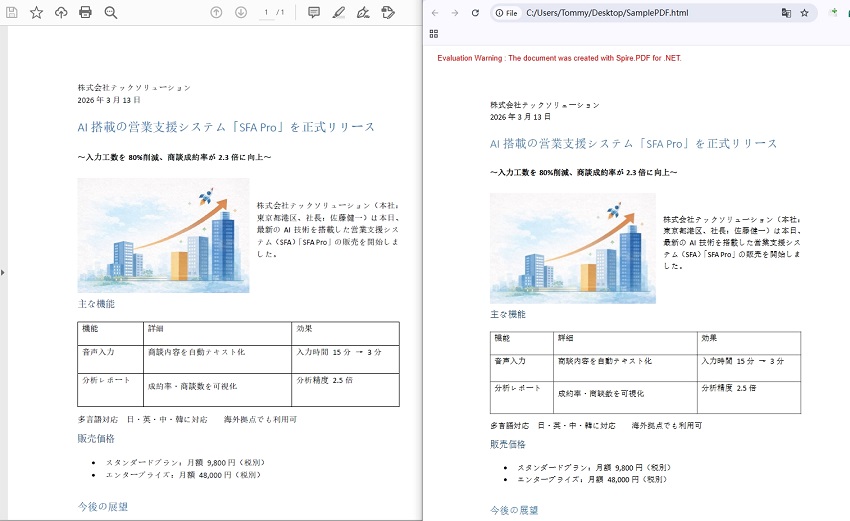
PdfConvertOptions.SetPdfToHtmlOptions() メソッドを使用すると、PDFファイルをHTMLに変換する際の変換オプションをカスタマイズできます。このメソッドには複数のパラメーターがあり、変換プロセスを設定するために使用できます。主なパラメーターは次のとおりです。
以下の手順では、Spire.PDF for .NET を使用して PDF を HTML に変換する際に、変換オプションをカスタマイズする方法を説明します。
using Spire.Pdf;
namespace ConvertPdfToHtmlWithCustomOptions
{
internal class Program
{
static void Main(string[] args)
{
// PdfDocumentクラスのインスタンスを作成する
PdfDocument doc = new PdfDocument();
// PDF ドキュメントをロードする
doc.LoadFromFile("Sample.pdf");
// 変換オプションを設定して、結果の HTML に画像を埋め込み、HTML ファイルごとに 1 ページに制限します。
PdfConvertOptions pdfToHtmlOptions = doc.ConvertOptions;
pdfToHtmlOptions.SetPdfToHtmlOptions(false, true, 1);
// PDF ドキュメントを HTML 形式で保存する
doc.SaveToFile("PdfToHtmlWithCustomOptions.html", FileFormat.HTML);
doc.Close();
}
}
}
PDF ドキュメントを HTML ファイルとして保存する代わりに、PdfDocument.SaveToStream(Stream stream, FileFormat.HTML) メソッドを使用して、HTML ストリームとして保存することもできます。具体的な手順は次のとおりです。
using Spire.Pdf;
using System.IO;
namespace ConvertPdfToHtmlStream
{
internal class Program
{
static void Main(string[] args)
{
// PdfDocumentクラスのインスタンスを作成する
PdfDocument doc = new PdfDocument();
// PDF ドキュメントをロードする
doc.LoadFromFile("Sample.pdf");
// PDF ドキュメントをHTMLストリームに保存する
using (var fileStream = new MemoryStream())
{
doc.SaveToStream(fileStream, FileFormat.HTML);
// HTML ストリームを使ってファイルに書き込むなどの操作ができるようになりました。
using (var outputFile = new FileStream("PdfToHtmlStream.html", FileMode.Create))
{
fileStream.Seek(0, SeekOrigin.Begin);
fileStream.CopyTo(outputFile);
}
}
doc.Close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、について営業担当者 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。

開発者は、技術ドキュメント、チュートリアル、コードレビュー、社内レポート、またはクライアント向け資料のために、Word ドキュメント内に Python コードを含める必要がよくあります。小さなコードスニペットであれば手動のコピー&ペーストでも対応できますが、長いスクリプトや複数のファイルを扱う場合は、自動化された方法のほうが一貫性、フォーマット制御、拡張性の面で優れています。
このチュートリアルでは、Python を使用して Python コードを Word ドキュメントにエクスポートする複数の実用的な方法を紹介します。各方法にはそれぞれ利点があり、フォーマット、自動化、構文ハイライト、可読性など、どの要素を重視するかによって選択できます。
このページの内容
例を実行する前に、必要な依存関係をインストールします。
pip install spire.doc pygments
ライブラリ概要
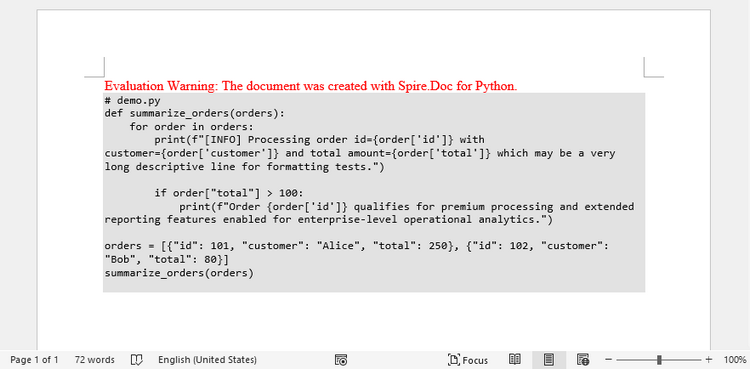
プレーンテキストの挿入は、 Word にコードを埋め込む最もシンプルな方法です。インデントや改行などのフォーマットを保持しながら、コードを編集可能な状態で挿入できます。
この方法では .py ファイルを読み込み、等幅フォントを適用して Word に直接挿入します。
from pathlib import Path
from spire.doc import *
# Pythonファイルを読み込む
code_string = Path("demo.py").read_text(encoding="utf-8")
# Wordドキュメントを作成
doc = Document()
# セクションを追加
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# 段落を追加
paragraph = section.AddParagraph()
# コード文字列を段落に挿入
paragraph.AppendText(code_string)
# 段落スタイルを作成
style = ParagraphStyle(doc)
style.Name = "code"
style.CharacterFormat.FontName = "Consolas"
style.CharacterFormat.FontSize = 12
style.ParagraphFormat.LineSpacing = 12
doc.Styles.Add(style)
# 段落にスタイルを適用
paragraph.ApplyStyle("code")
# ドキュメントを保存
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
仕組み
この方法では Python コードをプレーンテキストとして扱い、そのまま Word の段落に挿入します。スクリプトは .py ファイルを Path.read_text() で読み込み、インデント、空行、全体構造を保持します。
テキスト挿入後、カスタム段落スタイルを作成して適用します。Consolas のような等幅フォントを使用することで、コードの整列と可読性が向上します。また、固定の行間を設定することで、行ごとのフォーマットを安定させます。
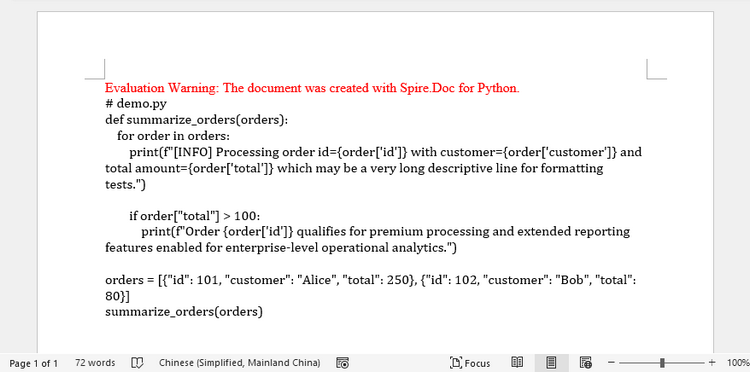
中間フォーマットを使用しないため、この方法は最もシンプルで高速です。ただし、構文ハイライトやセマンティックスタイルは適用されず、 Word では単なるフォーマット済みテキストとして表示されます。
効果図:
あなたはこれも好きかもしれません:Python を使用して構造化された Word 文書を作成する方法
Markdown を既に使用しているワークフローでは、フェンス付きコードブロックを使用すると、スクリプトを Word ドキュメントへ構造的に変換できます。
from pathlib import Path
from spire.doc import *
# Pythonファイルを読み込む
code = Path("demo.py").read_text(encoding="utf-8")
# Markdown形式に変換
md_content = f"```python\n{code}\n```"
Path("temp.md").write_text(md_content, encoding="utf-8")
# MarkdownファイルをWordに読み込む
doc = Document()
doc.LoadFromFile("temp.md")
# ページ設定を更新
doc.Sections[0].PageSetup.Margins.All = 60
# DOCX形式で保存
doc.SaveToFile("Output.docx", FileFormat.Docx)
doc.Dispose()
仕組み
この方法ではテキストを直接挿入する代わりに、 Python コードを Markdown のコードブロック(```python)でラップします。その後、生成した Markdown ファイルを Spire.Doc の Markdown 解析機能を使用して Word に読み込みます。
Word が Markdown をインポートすると、インデントや改行などのコードフォーマットは自動的に保持されます。この方法は、 Markdown ベースのドキュメントや、見出し・リスト・説明文とコードを一緒に管理するワークフローに適しています。
ただし、Markdown 自体は Word 内で自動的に構文カラーリングを適用しないため、結果としてはプレーンコードのフォーマットになります。ただし、ドキュメントパイプラインの管理はより簡単になります。
効果図:
構文ハイライトを使用すると、コードの可読性と理解しやすさが向上します。Pygments を統合することで、 Python スクリプトを Word に埋め込む前にスタイル付きフォーマットへ変換できます。
このセクションでは、RTF、HTML、画像レンダリングの3つの方法を紹介します。それぞれフォーマット目的によって適した用途があります。
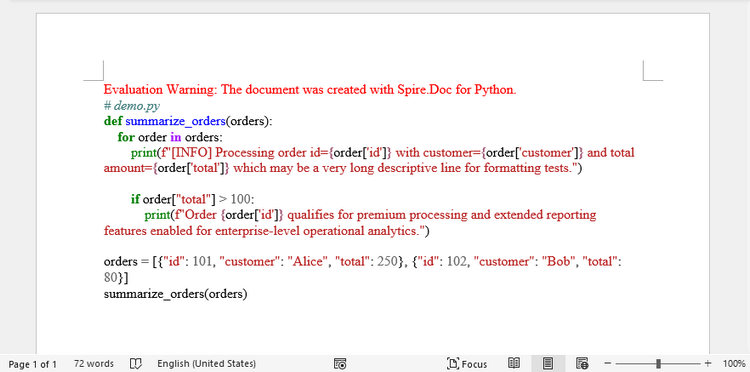
RTF を使用すると、構文ハイライト付きコードを Word 内で編集可能な状態のまま保持できます。
from pathlib import Path
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import RtfFormatter
from spire.doc import *
# Pythonファイルを読み込む
code = Path("demo.py").read_text(encoding="utf-8")
# フォントを設定
formatter = RtfFormatter(fontface="Consolas")
# レキサー(構文解析器)を指定
rtf_text = highlight(code, PythonLexer(), formatter)
# フォントサイズを設定(24 = 12pt)
rtf_text = rtf_text.replace(r"\f0", r"\f0\fs24")
# Wordドキュメントを作成
doc = Document()
# セクションを追加
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# 段落を追加
paragraph = section.AddParagraph()
# RTF形式の構文ハイライトコードを挿入
paragraph.AppendRTF(rtf_text)
# ドキュメントを保存
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
仕組み
Pygments は lexer(字句解析器) を使用して Python 構文を解析し、キーワード、文字列、コメントなどのトークンを識別します。RTFフォーマッタは、それらのトークンに対応する色やフォントを RTF 制御コードとして出力します。
生成されたRTF文字列は AppendRTF() を使用して Word に直接挿入されます。RTF は Word ネイティブ互換フォーマットのため、追加のレンダリング処理なしでフォント、色、行間などが保持されます。
フォントサイズは RTF 制御コード(例:\fs24)を変更することで制御でき、外観を細かく調整できます。この方法では、Word 内で編集可能かつ選択可能な構文ハイライト付きコードを作成できます。
効果図:
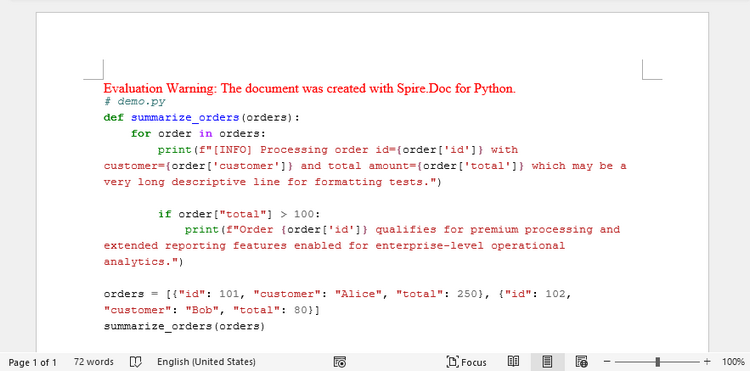
HTML レンダリングでは、よりリッチな構文ハイライトと自動テキスト折り返しが可能です。
from pathlib import Path
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import HtmlFormatter
from spire.doc import *
# Pythonファイルを読み込む
code = Path("demo.py").read_text(encoding="utf-8")
# 構文ハイライト付きHTMLを生成
html_text = highlight(code, PythonLexer(), HtmlFormatter(full=True))
# Wordドキュメントを作成
doc = Document()
# セクションを追加
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# 段落を追加
paragraph = section.AddParagraph()
# HTMLをWordに挿入
paragraph.AppendHTML(html_text)
# ドキュメントを保存
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
仕組み
ここでは、Pygments の HtmlFormatter を使用して Python コードをスタイル付き HTML へ変換します。HTML には構文色やフォーマットを表すCSSまたはインラインスタイルが含まれます。
Spire.Doc はこの HTML を解析し、Word ドキュメント内のフォーマットへ変換します。HTML 要素は Word のスタイル構造へ変換されるため、Web 上のコードブロックに近い見た目を再現できます。
この方法は、Web コンテンツ、静的ドキュメントサイト、または Markdown → HTML ワークフローから生成されたコードを Word へ取り込む場合に特に適しています。
効果図:
あなたはこれも好きかもしれません:Python:HTML を Word に変換する方法
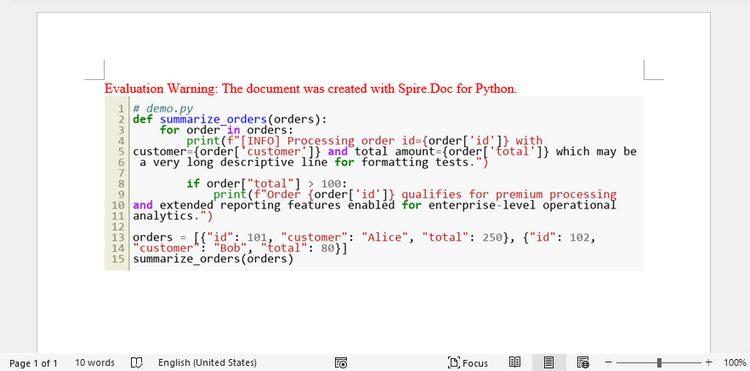
編集可能性よりも見た目の一貫性を重視する場合、コードを画像としてレンダリングして挿入する方法があります。
from pathlib import Path
import textwrap
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import ImageFormatter
from spire.doc import *
# Pythonファイルを読み込む
code = Path("demo.py").read_text(encoding="utf-8")
# 長い行を手動で折り返す関数
def wrap_code_lines(code_text, max_width=75):
wrapped_lines = []
for line in code_text.splitlines():
if len(line) > max_width:
wrapped_lines.extend(textwrap.wrap(
line,
width=max_width,
replace_whitespace=False,
drop_whitespace=False
))
else:
wrapped_lines.append(line)
return "\n".join(wrapped_lines)
code = wrap_code_lines(code, max_width=75)
# 画像生成の設定
formatter = ImageFormatter(
font_name="Consolas",
font_size=18,
scale=2,
image_pad=10,
line_pad=2,
background_color="#ffffff"
)
# 構文ハイライト画像を生成
img_bytes = highlight(code, PythonLexer(), formatter)
with open("code.png", "wb") as f:
f.write(img_bytes)
# Wordドキュメントを作成
doc = Document()
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# Wordに画像を挿入
paragraph = section.AddParagraph()
picture = paragraph.AppendPicture("code.png")
# 画像をページ幅に合わせる
page_width = (
section.PageSetup.PageSize.Width
- section.PageSetup.Margins.Left
- section.PageSetup.Margins.Right
)
picture.Width = page_width
# ドキュメントを保存
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
仕組み
この方法では、コードをテキストではなく画像として生成します。Pygments の ImageFormatter を使用すると、フォント、色、余白、解像度などを完全に制御した構文ハイライト画像を作成できます。
画像生成では自動折り返しが行われないため、Python の textwrap モジュールを使用して長いコード行を事前に折り返します。これにより、ページ幅を超える大きな画像が生成されるのを防ぎます。
Word に挿入した後、画像の幅をページの印刷可能領域に合わせて自動調整します。コードはグラフィックとして埋め込まれるため、プラットフォーム間で見た目が完全に一致しますが、テキストとしての編集はできなくなります。
効果図:
Python コードを Word ドキュメントに変換する方法はいくつかあり、目的に応じて選択できます。プレーンテキストはシンプルで柔軟性が高く、RTF や HTML は構文ハイライト付きの読みやすいドキュメントを作成できます。画像ベースのコードブロックは、視覚的なフォーマットを完全に固定したい場合に適しています。
一般的なドキュメント作成ワークフローでは次の使い分けが推奨されます。
チュートリアルに最適な方法はどれですか?
HTML または RTF 方式が、選択可能なテキストと明確な構文ハイライトを提供します。
インデントや空行を保持するには?
.read_text() を使用して .py ファイルをそのまま読み込み、行を削除・変更しないようにします。
画像として挿入したコードが小さくなるのはなぜですか?
Word はページ幅に合わせて画像を縮小するためです。画像のスケールや折り返し幅を調整すると読みやすくなります。
Word 内のコードをコピーできますか?
可能です。ただし、コードを画像として挿入した場合はコピーできません。
Markdown は必須ですか?
必須ではありません。Markdown はドキュメントパイプラインを利用する場合に便利なオプションです。
生成したドキュメントをPDFとして出力できますか?
はい。Document.SaveToFile() メソッドで出力形式を PDF に指定するだけです。
評価版の制限なく Spire.Doc for Python の機能をすべて体験するには、30日間の無料トライアルライセンスをリクエスト してください。

C++ で画像を OFD(Open Fixed-layout Document)形式に変換する処理は、ドキュメント処理システムにおいてよくある要件の一つです。特に中国語圏では、OFD は公式文書のアーカイブ、交換、配布に広く使用される標準フォーマットとなっています。実際の開発では、スキャンした文書や画像ファイルを OFD ドキュメントに変換し、統一的に保存・管理したり、電子文書管理システムや自動化ワークフローに統合したりするケースが多くあります。
画像から OFD への変換処理を低レベルから実装する場合、画像形式の解析、ページサイズの設定、ドキュメント構造の構築など、複雑な処理を実装する必要があります。また、生成されるファイルが OFD 仕様に準拠していることを保証する必要もあります。
Spire.PDF for C++ を使用すれば、シンプルな API を利用して画像を OFD に簡単に変換できます。このライブラリは PNG、JPG、BMP、TIFF、EMF などの一般的な画像形式をサポートしており、ドキュメント構造の生成や描画処理も自動的に行われます。
本記事では、C++ で画像を OFD ドキュメントへ変換する方法を解説し、単一画像の変換、複数画像を用いた複数ページ OFD の生成、さらにバッチ変換の実装例も紹介します。
クイックナビゲーション
OFD は XML ベースの固定レイアウト文書形式であり、PDF と似た機能を持ちながら、中国語環境における文字セットや政府文書規格に対応するよう最適化されています。
画像を OFD に変換する処理は、本質的には OFD 仕様に準拠したドキュメント構造を作成し、そのページ内に画像を埋め込むことを意味します。
画像を OFD に変換する代表的な利用シナリオには以下があります。
一般的な実装フローは以下の通りです。
C++ で画像を OFD に変換する前に、まず Spire.PDF for C++ をインストールして設定する必要があります。
Spire.PDF を C++ プロジェクトに追加する最も簡単な方法は NuGet を利用することです。
NuGet を使用すると、ライブラリファイルと依存関係が自動的にダウンロード・設定されます。
インストール手順:
インストール後、コードでライブラリを読み込みます。
#include "Spire.Pdf.o.h"
または、
Spire.PDF for C++ をダウンロード し、include と lib ディレクトリをプロジェクトに設定して手動で統合することも可能です。
詳細は以下のガイドを参照してください。
C++ アプリケーションに Spire.PDF for C++ を統合する方法
以下のサンプルコードは、単一の画像ファイルを OFD ドキュメントへ変換する方法を示しています。コードではまず PDF ドキュメントオブジェクトを作成し、画像を読み込み、ページに描画した後、最終的に OFD 形式で保存します。
#include "Spire.Pdf.o.h"
using namespace Spire::Pdf;
int main()
{
// 新しい PDF ドキュメントを作成します
PdfDocument* ofd = new PdfDocument();
// 画像ファイルを読み込みます
auto image = PdfImage::FromFile(L"Sample.jpg");
// 画像のサイズに基づいてページサイズを計算します
float pageWidth = image->GetWidth();
float pageHeight = image->GetHeight();
// 画像サイズに一致するページを追加します
auto page = ofd->GetPages()->Add(new SizeF(pageWidth, pageHeight));
// ページ上に画像を描画します
page->GetCanvas()->DrawImage(image, 0, 0, pageWidth, pageHeight);
// OFD ファイルとして保存します
ofd->SaveToFile(L"ImageToOfd.ofd", FileFormat::OFD);
// リソースを解放します
delete ofd;
return 0;
}
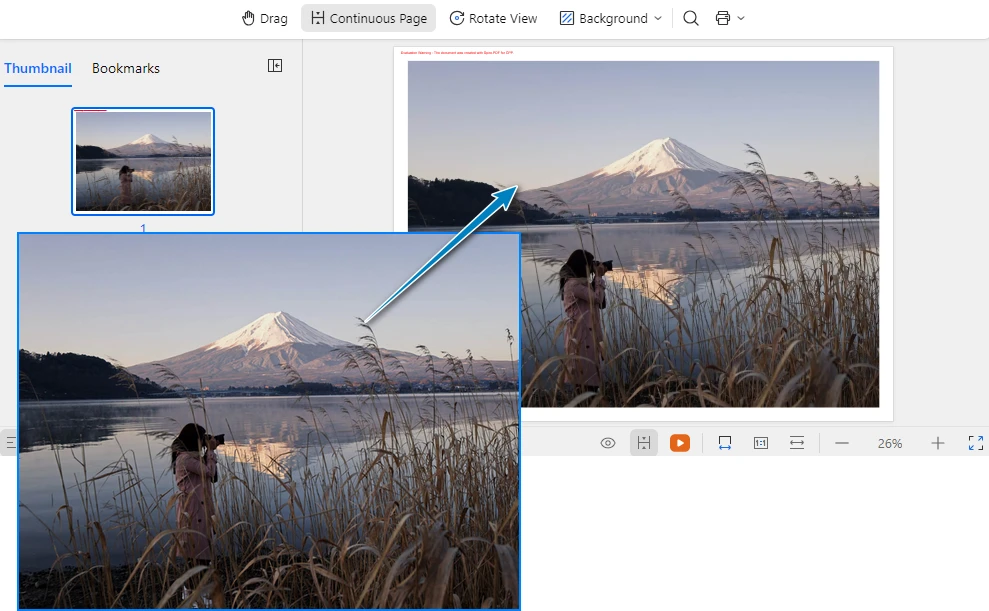
以下の図は、元画像から生成された OFD ドキュメントの表示例です。
PdfDocument ドキュメントオブジェクトを表し、ページの作成や最終的な OFD ファイルの出力を行います。
PdfImage::FromFile() 指定パスから画像ファイルを読み込み、ページ上に描画可能な画像オブジェクトを作成します。
PdfDocument::GetPages()->Add() ドキュメントに新しいページを追加します。本例では画像サイズに合わせてページサイズを設定しています。
PdfCanvas::DrawImage() 指定された位置とサイズで画像をページキャンバスに描画します。
SaveToFile()
ドキュメントをディスクに保存し、FileFormat::OFD を指定することで OFD 形式で出力します。
この方法により、画像を正しい比率のまま OFD ページ内に表示でき、元画像の品質を維持できます。
ofd->GetPageSettings()->SetMargins(0.0);
余白を残す場合:
ofd->GetPageSettings()->SetMargins(10.0);
ページの余白を適切に設定することで、ページレイアウトの見栄えをコントロールできます。
注意:コード実行時に C++ のバージョン互換性の問題が発生する場合、以下の方法で対応できます。
_SILENCE_CXX17_CODECVT_HEADER_DEPRECATION_WARNING を追加ISO C++14 標準 (/std:c++14) に設定文書のアーカイブやバッチ処理のシナリオでは、複数の画像を 1 つの OFD ファイルに統合する必要があることがよくあります。以下の例では、複数ページからなる OFD 文書を作成し、各ページに異なる画像を配置する方法を示します。
コードは画像ファイルのリストを順に処理し、各画像に対して個別のページを作成します。ページサイズは画像の寸法に基づいて設定され、画像は対応するページに描画されます。
#include "Spire.Pdf.o.h"
#include <vector>
#include <filesystem>
#include <algorithm>
using namespace Spire::Pdf;
namespace fs = std::filesystem;
int main()
{
// 新しい PDF ドキュメントを作成します(OFD として保存するため)
PdfDocument* ofd = new PdfDocument();
// 画像フォルダを指定します
std::wstring folderPath = L"./images";
// フォルダを走査します
for (const auto& entry : fs::directory_iterator(folderPath))
{
if (!entry.is_regular_file())
continue;
std::wstring path = entry.path().wstring();
std::wstring ext = entry.path().extension().wstring();
// 比較しやすいように小文字へ変換します
std::transform(ext.begin(), ext.end(), ext.begin(), ::towlower);
// 対応している画像形式かどうかを判定します
if (ext == L".png" || ext == L".jpg" || ext == L".jpeg" || ext == L".bmp")
{
// 画像を読み込みます
auto image = PdfImage::FromFile(path.c_str());
// 画像サイズを取得します
float pageWidth = image->GetWidth();
float pageHeight = image->GetHeight();
// ページを作成します
auto page = ofd->GetPages()->Add(new SizeF(pageWidth, pageHeight));
// 画像を描画します
page->GetCanvas()->DrawImage(image, 0, 0, pageWidth, pageHeight);
}
}
// OFD ファイルとして保存します
ofd->SaveToFile(L"multi_page_document.ofd", FileFormat::OFD);
// リソースを解放します
delete ofd;
return 0;
}
生成された OFD ドキュメントでは、各画像が独立したページに配置されます。
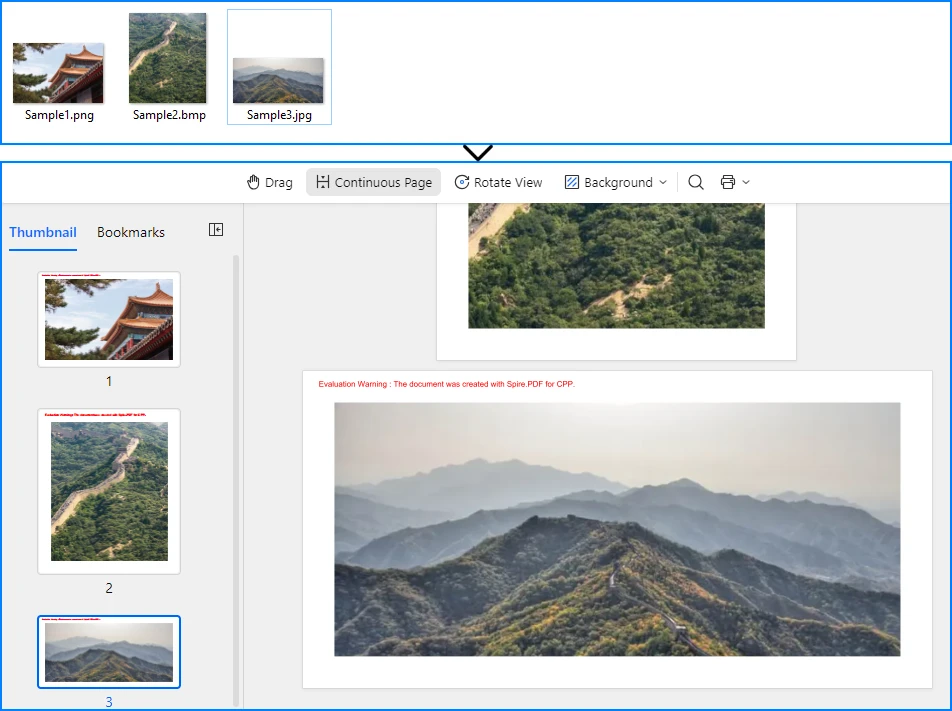
この実装では、画像ファイルのコレクションを順に処理し、各画像ごとに独立したページを作成して適切なサイズで描画します。生成された OFD 文書は、1 つのファイル内にすべての元画像の順序とレイアウトを保持します。
注意:#include <filesystem> は C++17 以降の標準でのみ使用可能です。
多くの実務的な文書ワークフローでは、ページは通常 標準ページサイズ に従う必要があり、画像の元のサイズをそのまま使用することはありません。たとえば、スキャンした契約書、表、報告書などは、A4 や Letter などの標準ページフォーマットに統一することが求められます。
これを実現するには、まず固定サイズのページを作成し、画像を縦横比を維持したままスケーリングして、ページ内に適切に収めます。
以下の例では、縦横比を保持しつつ、画像を固定ページサイズに合わせて縮小・拡大する方法を示します。
#define NOMINMAX
#include "Spire.Pdf.o.h"
#include <algorithm>
using namespace Spire::Pdf;
int main()
{
// 新しい PDF ドキュメントを作成します
PdfDocument* ofd = new PdfDocument();
// 固定サイズのページ(例:A4)を追加します
PdfPageBase* page = ofd->GetPages()->Add(PdfPageSize::A4);
// 画像を読み込みます
auto image = PdfImage::FromFile(L"Sample.jpg");
// ページのサイズを取得します
float pageWidth = page->GetCanvas()->GetClientSize().GetWidth();
float pageHeight = page->GetCanvas()->GetClientSize().GetHeight();
// 画像のサイズを取得します
float imgWidth = image->GetWidth();
float imgHeight = image->GetHeight();
// アスペクト比を維持したスケーリング比率を計算します
float scale = std::min(pageWidth / imgWidth, pageHeight / imgHeight);
float scaledWidth = imgWidth * scale;
float scaledHeight = imgHeight * scale;
// ページ上にスケーリング後の画像を描画します
page->GetCanvas()->DrawImage(image, 0, 0, scaledWidth, scaledHeight);
// OFD ファイルとして保存します
ofd->SaveToFile(L"FixedPageSize.ofd", FileFormat::OFD);
// リソースを解放します
delete ofd;
return 0;
}
以下のスクリーンショットは、画像が固定ページサイズ(A4)に合わせてスケーリングされ、縦横比が保持される様子を示しています。
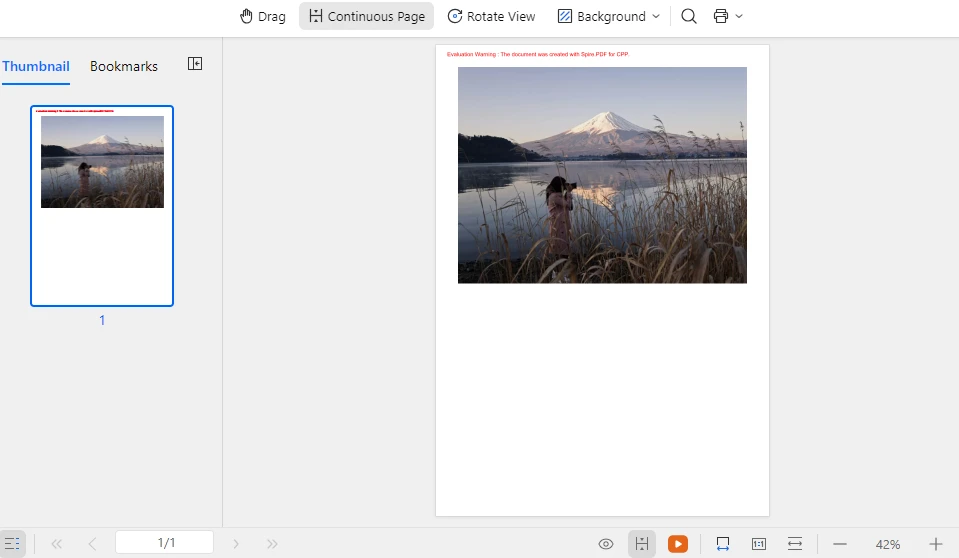
この方法により、異なるサイズの画像であっても標準化された文書レイアウト内に統一して配置でき、元の比率を維持して画像の歪みを防ぐことができます。同じ技術は、複数の画像から多ページの OFD 文書を生成する場合にも適用可能です。
自動化文書処理システムでは、多数の画像ファイルを一括で OFD 文書に変換する必要があることがよくあります。コードの再利用性を高めるため、変換処理のロジックを独立した関数としてカプセル化し、複数のファイルをループで処理する方法が有効です。
以下の例では、基本的なエラー処理と進捗表示を含む、シンプルなバッチ処理の実装方法を示しています。
#include "Spire.Pdf.o.h"
#include <vector>
#include <iostream>
#include <filesystem>
#include <algorithm>
using namespace Spire::Pdf;
namespace fs = std::filesystem;
void ConvertImageToOFD(const std::wstring& inputPath, const std::wstring& outputPath)
{
// 新しい PDF ドキュメントを作成します(OFD を生成するため)
PdfDocument* ofd = new PdfDocument();
try
{
// 画像ファイルを読み込みます
auto image = PdfImage::FromFile(inputPath.c_str());
// ページサイズを計算します(画像サイズと一致させます)
float pageWidth = image->GetWidth();
float pageHeight = image->GetHeight();
// 画像サイズに一致するページを追加します
auto page = ofd->GetPages()->Add(new SizeF(pageWidth, pageHeight));
// ページ上に画像を描画します
page->GetCanvas()->DrawImage(image, 0, 0, pageWidth, pageHeight);
// OFD ファイルとして保存します
ofd->SaveToFile(outputPath.c_str(), FileFormat::OFD);
std::wcout << L"変換完了:" << inputPath << L" -> " << outputPath << std::endl;
}
catch (const std::exception& ex)
{
std::wcout << L"変換中にエラーが発生しました:" << inputPath << L" : " << ex.what() << std::endl;
}
// ドキュメントを解放します
delete ofd;
}
int main()
{
// 走査する画像フォルダを定義します
std::wstring folderPath = L"./images";
// フォルダ内のすべてのファイルを走査し、自動的に変換を実行します
for (const auto& entry : fs::directory_iterator(folderPath))
{
// 通常のファイルのみ処理します
if (!entry.is_regular_file())
continue;
fs::path filePath = entry.path();
std::wstring ext = filePath.extension().wstring();
// 拡張子を小文字に変換して比較しやすくします
std::transform(ext.begin(), ext.end(), ext.begin(), ::towlower);
// 対応している画像形式かどうかを判定します
if (ext == L".png" || ext == L".jpg" || ext == L".jpeg" || ext == L".bmp")
{
// 入力画像のパスを取得します
std::wstring inputPath = filePath.wstring();
// 対応する OFD の出力パスを生成します(画像と同じ名前)
fs::path outputPath = filePath.parent_path() / (filePath.stem().wstring() + L".ofd");
// 変換を実行します
ConvertImageToOFD(inputPath, outputPath.wstring());
}
}
std::wcout << L"一括変換が完了しました。" << std::endl;
return 0;
}
このバッチ処理方式は、以下の利点を提供します:
この実装では、各画像を独立して処理するため、個別の変換失敗が全体のバッチ処理を中断することはありません。
画像ファイルのパスが正しくアクセス可能であることを確認してください。画像を読み込む際は、絶対パスを使用するか、作業ディレクトリを確認することを推奨します:
// 信頼性を高めるために絶対パスを使用
auto image = PdfImage::FromFile(L"C:\\Documents\\scanned_invoice.png");
PdfDocument や PdfImage オブジェクトは適切に解放し、メモリリークを防いでください。使用後は動的に割り当てたオブジェクトを必ず削除します:
delete ofd;
Spire.PDF は PNG、JPEG、BMP、EMF、TIFF などの一般的な画像形式をサポートしています。入力ファイルがサポート対象であることを確認してください。サポートされていない形式の場合は、事前に画像処理ライブラリで対応形式に変換してください。
画像のサイズに基づいてページを作成する場合、大きすぎる画像は OFD 文書の閲覧や印刷に問題を引き起こす可能性があります。大きな画像にはサイズ制限や縮小処理を行うことを推奨します:
#define NOMINMAX
#include <algorithm>
// 最大ページサイズの制限を適用
const float MAX_WIDTH = 1000.0f;
const float MAX_HEIGHT = 1400.0f;
float pageWidth = std::min(static_cast<float>(image->GetWidth()), MAX_WIDTH);
float pageHeight = std::min(static_cast<float>(image->GetHeight()), MAX_HEIGHT);
中文文字や特殊文字を含むファイルパスを扱う場合は、std::wstring のようなワイド文字列を使用し、正しいエンコーディングを保証してください。これにより、ファイル操作での文字化けやエラーを防げます。
一部の環境でコンパイル問題が発生する場合、以下の方法で対応可能です:
_SILENCE_CXX17_CODECVT_HEADER_DEPRECATION_WARNING を追加ISO C++14 標準 (/std:c++14) に設定本記事では、Spire.PDF for C++ を使用して画像を OFD 文書に変換する方法を紹介しました。シンプルな API 呼び出しにより、単一画像の変換、多数画像からの多ページ文書生成、さらにはバッチ処理による変換などを容易に実現できます。
この技術は、スキャン文書のデジタル化、電子文書管理、そして自動化された文書処理ワークフローにおいて幅広く応用可能です。
OFD 変換に加えて、Spire.PDF for C++ は PDF 文書の作成、編集、変換、さまざまな形式への出力など、豊富な機能を提供します。本ライブラリを利用することで、開発者は複雑な文書処理タスクを効率的に実行しつつ、生成される文書が業界標準に準拠していることを保証できます。
フル機能を体験したい場合は、30 日間無料ライセンスを申請 してください。
必要ありません。Spire.PDF は、画像から OFD への変換を単独で実行でき、Adobe Acrobat やその他の外部 PDF ソフトウェアに依存する必要はありません。
Spire.PDF は、PNG、JPEG、BMP、EMF、TIFF などの一般的な画像形式に対応しています。
はい。Spire.PDF はサーバー環境向けに最適化されており、大量の画像変換タスクを効率的に処理できます。
可能です。Spire.PDF では、ページキャンバス上にテキストや画像を描画できるため、OFD にエクスポートする前に透かしを追加することができます。
関連チュートリアル:
影響ありません。変換プロセス中、元の画像の解像度と品質は保持され、ページサイズも画像の大きさに応じて自動で調整されます。

CSV(Comma-Separated Values)ファイルは、データ分析からバックエンドシステムまで、さまざまな業界におけるデータ交換の基盤となるファイル形式です。軽量で人が読みやすく、Excel、Google スプレッドシート、データベースなど、ほぼすべてのツールと互換性があります。Python で CSV ファイルを作成する方法 を探している開発者にとって、Spire.XLS for Python はその処理を大幅に簡素化できる強力なライブラリです。
本記事では、Spire.XLS を使用して Python で CSV ファイルを生成する方法 を詳しく解説します。基本的な CSV 作成から、リストや辞書データの変換、Excel から CSV への変換といった実践的なユースケースまで幅広くカバーします。
本記事で学べること
Spire.XLS for Python の導入は非常に簡単です。以下の手順で環境を準備します。
ステップ 1: Python 3.6 以上がインストールされていることを確認します。
ステップ 2: pip(Python の公式パッケージマネージャー)でライブラリをインストールします。
pip install Spire.XLS
ステップ 3(任意): すべての機能を制限なく試用するには、一時的な無料ライセンスを申請 します。
まずは、静的なデータ(例:売上レポート)から CSV ファイルを作成するシンプルな例を見ていきます。以下のコードでは、新しいワークブックを作成し、データを入力して CSV ファイルとして保存します。
from spire.xls import *
# 1. 新しいワークブックを作成
workbook = Workbook()
# 2. 先頭のワークシートを取得(既定のシート)
worksheet = workbook.Worksheets[0]
# 3. セルにデータを入力
# ヘッダー行
worksheet.Range["A1"].Text = "商品ID"
worksheet.Range["B1"].Text = "商品名"
worksheet.Range["C1"].Text = "単価"
worksheet.Range["D1"].Text = "販売数量"
worksheet.Range["A2"].NumberValue = 101
worksheet.Range["B2"].Text = "ワイヤレスイヤホン"
worksheet.Range["C2"].NumberValue = 7980
worksheet.Range["D2"].NumberValue = 250
worksheet.Range["A3"].NumberValue = 102
worksheet.Range["B3"].Text = "Bluetoothスピーカー"
worksheet.Range["C3"].NumberValue = 4980
worksheet.Range["D3"].NumberValue = 180
# CSV として保存
worksheet.SaveToFile("BasicSalesReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Workbook() で新しい Excel ワークブックを作成し、Worksheets[0] で対象のワークシートにアクセスします。.Text、数値には .NumberValue を使用し、適切なデータ型を保持します。SaveToFile() で CSV にエクスポートし、Dispose() でメモリリークを防止します。出力結果:
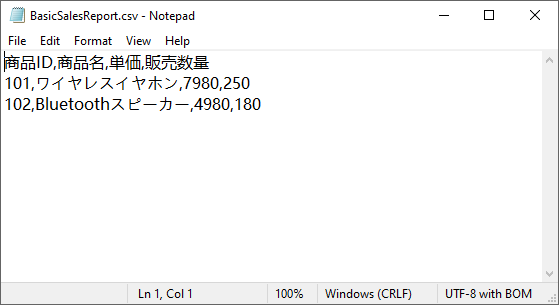
生成された BasicSalesReport.csv は次のようになります。
実際の業務では、データは API やデータベースから取得した辞書形式(JSON など)で扱われることが一般的です。以下の例では、辞書のリストを CSV に変換します。
from spire.xls import *
# サンプルデータ(データベースや API から取得した想定)
customer_data = [
{"顧客ID": 1, "氏名": "山田 太郎", "メールアドレス": "taro.yamada@ example.co.jp", "国名": "日本"},
{"顧客ID": 2, "氏名": "佐藤 花子", "メールアドレス": "hanako.sato@ example.co.jp", "国名": "日本"},
{"顧客ID": 3, "氏名": "鈴木 一郎", "メールアドレス": "ichiro.suzuki@ example.co.jp", "国名": "日本"}
]
# 1. ワークブックとワークシートを作成
workbook = Workbook()
worksheet = workbook.Worksheets[0]
# 2. ヘッダー行を書き込み(最初の辞書のキーを取得)
headers = list(customer_data[0].keys())
for col_idx, header in enumerate(headers, start=1):
worksheet.Range[1, col_idx].Text = header # 1 行目 = ヘッダー
# 3. データ行を書き込み
for row_idx, customer in enumerate(customer_data, start=2): # 2 行目から開始
for col_idx, key in enumerate(headers, start=1):
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row_idx, col_idx].NumberValue = value
else:
worksheet.Range[row_idx, col_idx].Text = value
# 4. CSV として保存
worksheet.SaveToFile("CustomerData.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
この方法は、JSON から CSV への変換、データベースのダンプ、REST API データのエクスポートなどに最適です。主な利点は以下のとおりです。
生成された CSV ファイル:
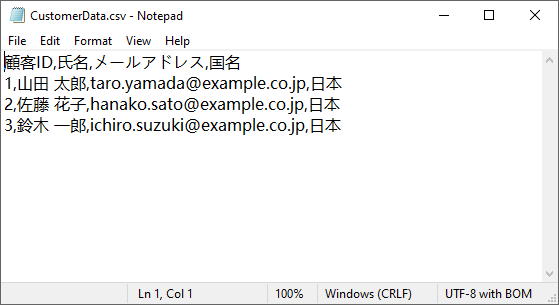
Spire.XLS は、Python で Excel(XLS/XLSX)を CSV に変換する処理にも優れています。Excel レポートをデータパイプラインや外部ツール向けに CSV として出力する場合に便利です。
from spire.xls import *
# 1. ワークブックを初期化
workbook = Workbook()
# 2. xlsx ファイルを読み込み
workbook.LoadFromFile("Sample.xlsx")
# 3. Excel を CSV として保存
workbook.SaveToFile("XLSXToCSV.csv", FileFormat.CSV)
workbook.Dispose()
変換結果:
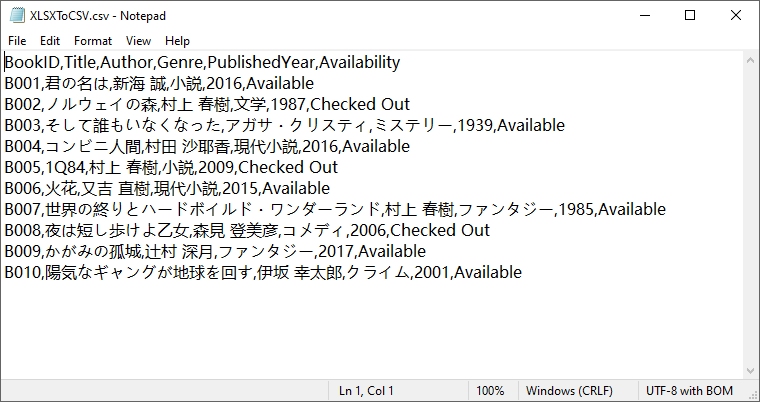
注意: SaveToFile() は既定では最初のワークシートのみを変換します。
堅牢で実務に耐える CSV を生成するために、以下のポイントを意識してください。
Encoding.get_UTF8() を明示的に指定し、多言語文字に対応します。Dispose() を呼び出してワークブック/ワークシートのリソースを解放し、メモリリークを防ぎます。Spire.XLS を活用すれば、Python での CSV ファイル生成を効率的かつ柔軟に実装できます。ゼロからのレポート作成、Excel ブックの変換、API やデータベースから取得した動的データの処理まで、幅広いシナリオに対応可能です。
本ガイドで紹介した方法を応用すれば、区切り文字やエンコーディング(UTF-8 など)の指定、データ型の適切な管理を行いながら、正確で互換性の高い CSV ファイルを作成できます。さらに高度な機能については、Spire.XLS for Python チュートリアル を参照してください。
A: Python 標準の csv モジュールは基本的な読み書きには適していますが、Spire.XLS には以下の利点があります。
A: はい。Spire.XLS は CSV ファイルの解析とデータ抽出をサポートしています。
A: はい。Spire.XLS は双方向変換をサポートしています。簡単な例は以下のとおりです。
from spire.xls import *
# ワークブックを作成
workbook = Workbook()
# CSV ファイルを読み込み
workbook.LoadFromFile("sample.csv", ",", 1, 1)
# Excel 形式で保存
workbook.SaveToFile("CSVToExcel.xlsx", ExcelVersion.Version2016)
A: SaveToFile() メソッドの第 2 引数で区切り文字を指定します。
# セミコロン(ヨーロッパ地域向け)
worksheet.SaveToFile("EU.csv", ";", Encoding.get_UTF8())
# タブ区切り(TSV)
worksheet.SaveToFile("TSV_File.csv", "\t", Encoding.get_UTF8())

Excelファイルは、レポート、ユーザー入力フォーム、他システムからエクスポートされたデータなど、構造化された情報の保存・共有に広く利用されています。多くのJavaアプリケーションでは、これらのExcelファイルを読み込み、データを抽出して後続処理に活用する必要があります。
Javaにおいて「Excelファイルを解析する」とは、通常 .xls または .xlsx ファイルを読み込み、ワークシートを取得し、セルの値を文字列・数値・日付などのJavaで扱いやすい形式に変換することを指します。
本記事では、Spire.XLS for Java を使用し、基本的なテキスト読み取りからデータ型を意識した解析方法まで、実践的な例を交えて段階的に解説します。
目次
Excelファイルを解析する前に、プロジェクトへ Spire.XLS for Java を追加します。本ライブラリは .xls と .xlsx の両形式に対応しており、Microsoft Excelをインストールする必要はありません。
Mavenを使用している場合は、pom.xml に以下の依存関係を追加します。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.1.3</version>
</dependency>
依存関係を追加すれば、JavaでExcelファイルの読み込みおよび解析を開始できます。
Mavenを使用しない場合は、Spire.XLS for Java をダウンロードし、手動でプロジェクトに追加することも可能です。
Excelファイルを解析する最初のステップは、ファイルを Workbook オブジェクトに読み込み、対象となるワークシートへアクセスすることです。
import com.spire.xls.*;
public class ParseExcel {
public static void main(String[] args) {
Workbook workbook = new Workbook();
workbook.loadFromFile("data.xlsx");
Worksheet sheet = workbook.getWorksheets().get(0);
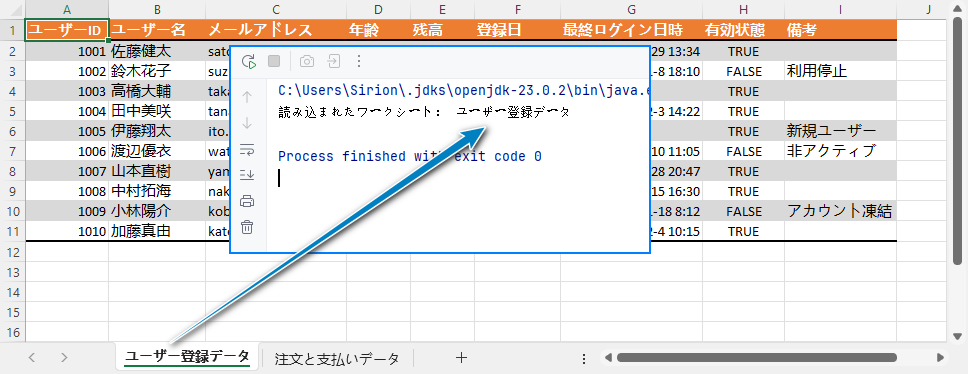
System.out.println("読み込まれたワークシート: " + sheet.getName());
}
}
読み込み結果のプレビュー:
このコードは .xls と .xlsx の両方に対応しています。ワークシートを取得した後、行やセルを順に読み取ることができます。
多くの場合、特定のデータ型を意識せずに、Excelの内容をそのまま文字列として取得できれば十分です。この方法は、ログ出力、画面表示、簡易インポートなどに適しています。
for (int i = 1; i <= sheet.getLastRow(); i++) {
for (int j = 1; j <= sheet.getLastColumn(); j++) {
String cellText = sheet.getCellRange(i, j).getValue();
System.out.print(cellText + "\t");
}
System.out.println();
}
テキスト読み取り結果のプレビュー:
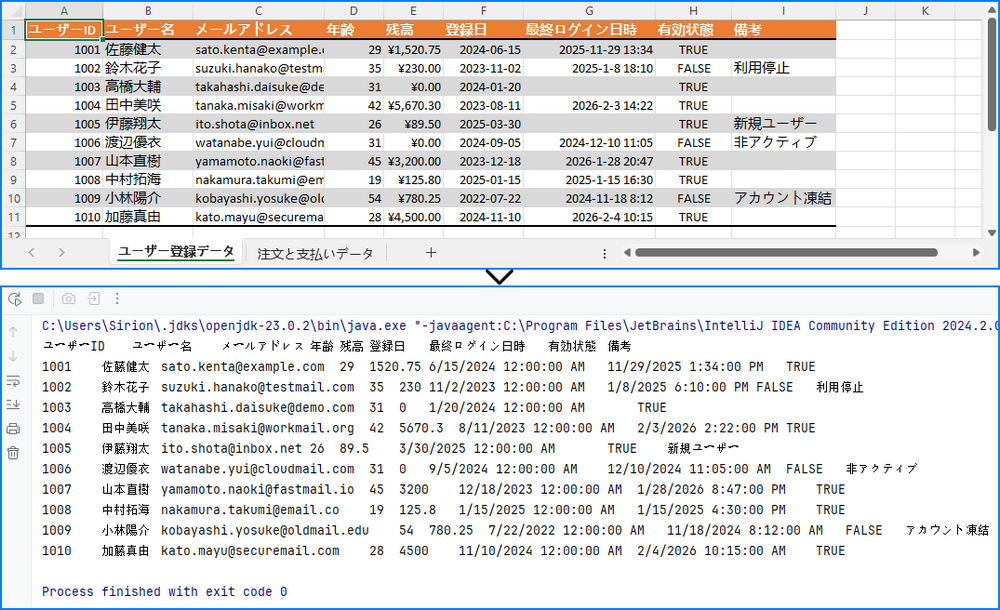
getValue() は、Excel上で表示されている形式に基づいた値を返します。精度や型変換を厳密に扱う必要がない場合、最も手軽な方法です。
読み取りだけでなく編集も行いたい場合は、JavaでSpire.XLSを使用してExcelドキュメントを編集する方法 を参照してください。
データ処理、検証、計算を行う場合、すべてを文字列として扱うだけでは不十分です。このようなケースでは、セルの値を適切なJavaデータ型へ変換する必要があります。
Excelでは、日付・通貨・パーセンテージとして表示されていても、内部的には数値として保存されている場合が多くあります。
Spire.XLS for Java では getNumberValue() を使用して、セルの内部数値を直接取得できます。
CellRange usedRange = sheet.getAllocatedRange();
System.out.println("Raw number values:");
for (int i = usedRange.getRow(); i <= usedRange.getLastRow(); i++) {
for (int j = usedRange.getColumn(); j <= usedRange.getLastColumn(); j++) {
CellRange cell = sheet.getRange().get(i, j);
if (!(Double.isNaN(cell.getNumberValue())))
{
System.out.print(cell.getNumberValue() + "\t");
}
}
System.out.println();
}
数値読み取り結果のプレビュー:
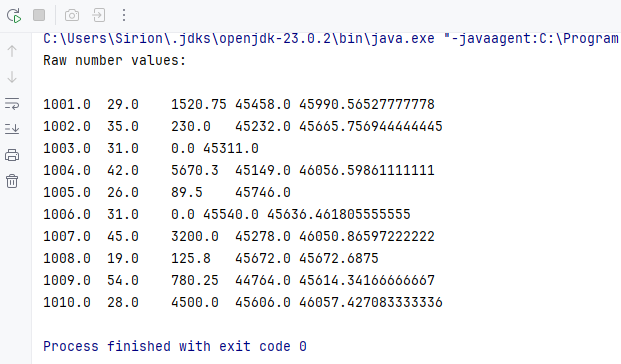
このメソッドは、表示形式に関係なく、セルに格納されている実際の数値を返します。
用途に応じた型変換
取得した数値は、業務要件に応じて適切な型へ変換できます。
double numberValue = cell.getNumberValue();
// intに変換
int intValue = (int) numberValue;
// floatに変換
float floatValue = (float) numberValue;
// doubleのまま使用
double doubleValue = numberValue;
例えば、IDや数量は int、価格や残高は double や float が適しています。
注意:Excelの日付も内部的には数値です。日付や時刻を扱う場合は、数値として処理するのではなく、専用のAPIを使用することを推奨します。
Excelでは日付・時刻は数値として保存され、表示形式によって見た目が決まります。
Spire.XLS for Java の getDateTimeValue() を使用すると、Date オブジェクトとして直接取得できます。
CellRange usedRange = sheet.getAllocatedRange();
System.out.println("Date values:");
for (int i = 0; i < usedRange.getRowCount(); i++) {
// 例:G列(日付列)を読み取る
CellRange cell = usedRange.get(String.format("G%d", i + 1));
java.util.Date date = cell.getDateTimeValue();
System.out.println(date);
}
第7列の日付読み取り結果:
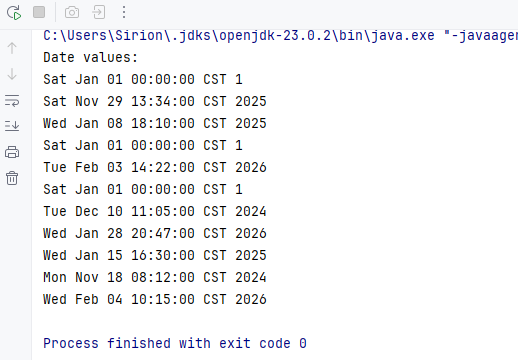
getDateTimeValue() は、内部数値を Date オブジェクトへ変換します。レポート処理やデータインポートなどで広く利用されます。
実際のExcelファイルでは、1列に文字列・数値・日付・真偽値・空白などが混在することがあります。 その場合、複数のAPIを組み合わせ、業務ロジックに応じて最適な形式を選択します。
CellRange cell = sheet.getRange().get(2, 1); // B2
// 表示されているテキスト
String text = cell.getText();
// 文字列値
String value = cell.getValue();
// 内部値(数値・日付・真偽値など)
Object rawValue = cell.getValue2();
// 数式
String formula = cell.getFormula();
// 数式の計算結果
String evaluated = cell.getEnvalutedValue();
// 数値
double numberValue = cell.getNumberValue();
// 日付
java.util.Date dateValue = cell.getDateTimeValue();
// 真偽値
boolean booleanValue = cell.getBooleanValue();
実務では、表示用途やログ出力には getText() を使用し、計算や条件分岐には getNumberValue() や getDateTimeValue() を利用することが一般的です。
この柔軟な方法は、ユーザー生成ファイルや構造が一定でないExcelにも有効で、堅牢な解析ロジックを実現します。
各行をDTOやエンティティクラスにマッピングする方法が一般的です。 例えば、1行を1件のレコードとして扱い、各列をフィールドに対応させます。解析後はListへ格納し、データベース保存や後続処理に利用できます。
List<List<Object>> などの構造へ格納する方法もよく使われます。バッチ処理やデータ検証、変換処理に適しています。
Spire.XLS for Java では、行・列の走査が容易で、列の意味に応じた型取得が可能です。
JavaでExcelを解析する際、Spire.XLS for Javaには次の利点があります。
これらの特長により、実務プロジェクトでのExcel解析に適した選択肢となります。
データの書き込みについては、JavaでExcelファイルにデータを書き込む方法 をご覧ください。
JavaでExcelファイルを解析することは、多くの業務アプリケーションにおいて重要な要件です。単純な文字列取得から、型を考慮した構造化データの抽出まで、目的に応じた方法を選択する必要があります。
Spire.XLS for Java を利用すれば、少ないコードでExcelファイルを読み込み、セル値をテキスト・数値・日付として安全かつ効率的に取得できます。
用途に応じて基本的なテキスト解析と型対応解析を使い分けることで、ExcelデータをJavaアプリケーションへスムーズに統合できます。
すべての機能を制限なく利用するには、無料トライアルライセンス を申請できます。
はい。Spire.XLS for Javaは同一APIで .xls と .xlsx の両形式をサポートしています。
テキスト読み取りは表示形式の値を返します。一方、型解析は数値や日付の本来のデータ型を保持するため、計算やロジック処理に適しています。
いいえ。Spire.XLS for JavaはMicrosoft Excelに依存しません。
平素よりE-ICEBLUE製品をご利用いただき、誠にありがとうございます。
誠に勝手ながら、春節期間に伴い、下記の期間を休業とさせていただきます。
2026年2月15日(日)~2月23日(月)【GMT+8】
2026年2月24日(火)
ご購入に関するお問い合わせ、一時ライセンスのご申請、その他緊急のご用件は、休業期間中もメールにて受け付けております。
当番担当者が対応いたしますので、通常よりご返信までにお時間をいただく場合がございます。
あらかじめご了承ください。
引き続きE-ICEBLUEをよろしくお願い申し上げます。

C# を使用してリストデータを Excel にエクスポートすることは、現代の .NET アプリケーションにおいて一般的な要件です。デスクトップアプリケーション、Web システム、バックグラウンドサービスのいずれを開発する場合でも、開発者はメモリ上のコレクション、特に List<T> を、ユーザーがダウンロード・分析・共有できる構造化された Excel ファイルに変換する必要があります。
本チュートリアルでは、Spire.XLS for .NET を使用し、Excel Interop を使わずに C# でオブジェクトのリストを Excel にエクスポートする方法を解説します。本ソリューションは .NET Core および最新の .NET バージョンに完全対応しており、一般的な業務データモデルで利用でき、Microsoft Excel のインストールも不要です。
目次
リストデータを Excel にエクスポートすることは、構造化された情報を、広く利用されている分かりやすい形式で提供する有効な方法です。実際の業務では、次のような場面でよく利用されます。
従来、多くの開発者は Excel ファイルの生成に Excel Interop を使用してきました。しかし、Interop には以下のような制約があります。
このため、近年の .NET アプリケーションでは、Interop を使用しない Excel エクスポートが主流となっています。Spire.XLS for .NET のようなライブラリを使用すれば、Microsoft Office に依存することなく、List<T> を直接 Excel ファイルとして安全かつ確実に出力できます。
実際のアプリケーションでは、単純な値ではなく、業務オブジェクトのリストとしてデータを扱うことがほとんどです。本セクションでは、現実的な帳票出力シナリオを想定し、再利用可能で Interop に依存しない方法で List<T> を Excel にエクスポートする手順を説明します。
リストを Excel にエクスポートする前に、プロジェクトに Spire.XLS for .NET をインストールしてください。
NuGet から次のコマンドでインストールできます。
Install-Package Spire.XLS
インストール後、追加の設定なしで List<T> の Excel 出力を開始できます。
オブジェクトのリストを Excel にエクスポートする基本的な流れは、次のとおりです。
List<T> として準備する以下のサンプルでは、これらの処理をすべて含めた実装例を示します。
using Spire.Xls;
using System;
using System.Collections.Generic;
using System.Reflection;
public class OrderReport
{
public int OrderId { get; set; }
public string CustomerName { get; set; }
public DateTime OrderDate { get; set; }
public decimal TotalAmount { get; set; }
public string Status { get; set; }
}
class Program
{
static void Main()
{
// サンプル業務データの準備
List<OrderReport> orders = new List<OrderReport>
{
new OrderReport { OrderId = 20240101, CustomerName = "サンプル株式会社A", OrderDate = new DateTime(2024, 1, 5), TotalAmount = 1250000m, Status = "完了" },
new OrderReport { OrderId = 20240102, CustomerName = "テスト法人B", OrderDate = new DateTime(2024, 1, 8), TotalAmount = 860000m, Status = "処理中" },
new OrderReport { OrderId = 20240103, CustomerName = "デモ企業C", OrderDate = new DateTime(2024, 1, 12), TotalAmount = 430500m, Status = "キャンセル" }
};
// ワークブックとワークシートを作成
Workbook workbook = new Workbook();
Worksheet sheet = workbook.Worksheets[0];
// リフレクションでプロパティ情報を取得
PropertyInfo[] properties = typeof(OrderReport).GetProperties();
// 列見出しを書き込み
for (int i = 0; i < properties.Length; i++)
{
sheet.Range[1, i + 1].Text = properties[i].Name;
}
// データ行を書き込み
for (int row = 0; row < orders.Count; row++)
{
for (int col = 0; col < properties.Length; col++)
{
object value = properties[col].GetValue(orders[row]);
sheet.Range[row + 2, col + 1].Value2 = value;
}
}
// Excel ファイルを保存
workbook.SaveToFile("OrderReport.xlsx", ExcelVersion.Version2016);
}
}
生成された Excel ファイルのプレビューは次のとおりです。
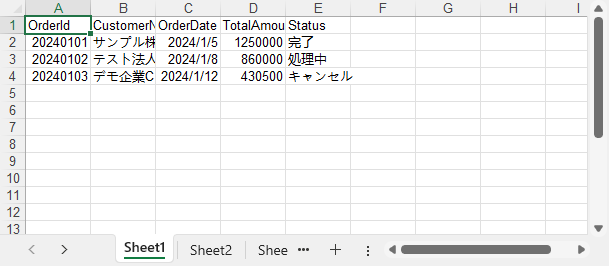
この実装パターンは、再利用可能なエクスポート処理や帳票生成機能の構築に適しています。
なお、List<T> ではなく DataTable としてデータを取得する場合も、Spire.XLS for .NET には効率的なエクスポート手段が用意されています。詳細は C# で DataTable を Excel にエクスポートする方法 を参照してください。
Spire.XLS for .NET では、基本的なデータ出力に加えて、Excel ファイルの可読性や実用性を高めるための書式設定も行えます。
代表的な書式設定には、次のようなものがあります。
using System.Drawing;
// 見出し行の書式設定
CellStyle headerStyle = workbook.Styles.Add("HeaderStyle");
headerStyle.Font.FontName = "Yu Gothic UI";
headerStyle.Font.Size = 12f;
headerStyle.Font.IsBold = true;
headerStyle.Color = Color.LightGray;
headerStyle.HorizontalAlignment = HorizontalAlignType.Center;
sheet.Range[1, 1, 1, sheet.LastColumn].Style = headerStyle;
// 日付列と金額列の表示形式を設定
sheet.Range[2, 3, orders.Count + 1, 3].NumberFormat = "yyyy-mm-dd";
sheet.Range[2, 4, orders.Count + 1, 4].NumberFormat = "#,##0.00";
// 行の高さと列幅を自動調整
sheet.AllocatedRange.AutoFitRows();
sheet.AllocatedRange.AutoFitColumns();
書式設定後の Excel シートのプレビューは以下のとおりです。
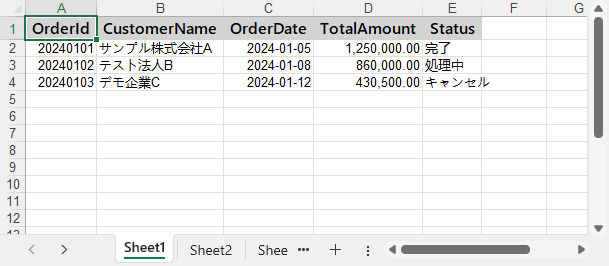
書式を適用することで、生成された Excel ファイルはより業務向けで、そのまま利用可能な品質になります。
スタイル設定、セル結合、条件付き書式、数式など、より高度な操作については、C# で Excel ワークシートを作成・書式設定する方法 を参照してください。
Spire.XLS for .NET は .NET Core および最新の .NET バージョンに完全対応しており、以下のような環境で利用できます。
Excel Interop に依存しないため、サーバーサイドや本番環境でも安全に利用できます。
ASP.NET Core や Web API プロジェクトで Excel ファイルを生成し、クライアントへ返却する方法については、次の記事を参照してください。 C# を使用して ASP.NET Core で Excel ファイルをエクスポートする
C# で List を Excel にエクスポートする処理は、Excel Interop に依存する必要はありません。Spire.XLS for .NET を使用すれば、List<T> を構造化された Excel ファイルへ効率的に変換でき、.NET Framework と .NET Core の両環境で安定して動作します。
Interop を使用しないことで、デプロイの複雑さを軽減し、アプリケーションの安定性を向上させ、業務データのエクスポートにおける柔軟性も高まります。
複雑な帳票からシンプルなリスト出力まで、Spire.XLS は現代的な C# アプリケーションに適した、信頼性と拡張性の高いソリューションです。評価目的や試用制限の解除には、30 日間の一時ライセンス を利用できます。
はい。Spire.XLS for .NET はサーバーサイド利用を前提として設計されており、大規模な List<T> データも効率的に処理できます。さらに大量の場合は、バッチ処理や分割出力によってパフォーマンスを向上させることが可能です。
いいえ。Spire.XLS for .NET は Microsoft Excel に依存せず、Excel Interop も使用しないため、サーバー環境やクラウド環境でも利用できます。
はい。列見出しは手動でカスタマイズでき、日付・数値・スタイルなどの書式もプログラムから指定できます。高度な書式設定については、C# Excel 書式設定ガイド を参照してください。
はい。本エクスポート処理は ASP.NET Core、Web API、バックグラウンドサービスなど、あらゆるサーバーサイドの .NET 環境で問題なく動作します。





