チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Word 文書のコメント機能は、コラボレーションやフィードバックにおいて非常に重要な役割を果たします。コメントを活用することで、意見の共有、提案、説明、議論をスムーズに行うことができます。アイデアを伝えたり、既存のコメントに返信したり、不要なコメントを削除したりすることで、ドキュメントの作業効率を大幅に向上させることができます。本記事では、Spire.Doc for Python を使用して Python で Word 文書のコメントを追加、削除、返信する方法について解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python では、Paragraph.AppendComment() メソッドを使用して、指定した段落にコメントを追加できます。コメント対象のテキスト範囲は、コメントの開始マークと終了マークを設定することで制御します。以下の手順で段落にコメントを追加します。
from spire.doc import Document, CommentMark, CommentMarkType
# Document クラスのオブジェクトを作成し、Word 文書を読み込みます
doc = Document()
doc.LoadFromFile("Sample.docx")
# 最初のセクションを取得します
section = doc.Sections.get_Item(0)
# 4 番目の段落を取得します
paragraph = section.Paragraphs.get_Item(3)
# 段落にコメントを追加します
comment = paragraph.AppendComment("この部分はさらに説明が必要です。")
# コメントの著者を設定します
comment.Format.Author = "大輝"
# コメントの開始マークと終了マークを作成し、作成したコメントの開始マークと終了マークとして設定します
commentStart = CommentMark(doc, CommentMarkType.CommentStart)
commentEnd = CommentMark(doc, CommentMarkType.CommentEnd)
commentStart.CommentId = comment.Format.CommentId
commentEnd.CommentId = comment.Format.CommentId
# コメントの開始マークと終了マークを段落の先頭と末尾に挿入します
paragraph.ChildObjects.Insert(0, commentStart)
paragraph.ChildObjects.Add(commentEnd)
# 文書を保存します
doc.SaveToFile("output/段落へのコメント.docx")
doc.Close()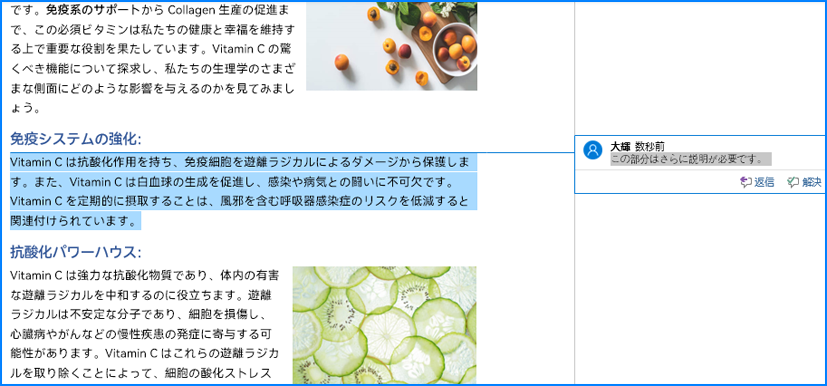
Spire.Doc for Python では、指定したテキストを検索し、その部分にコメントを追加することも可能です。以下の手順で、特定のテキストにコメントを追加します。
from spire.doc import Document, Comment, CommentMark, CommentMarkType
# Document クラスのオブジェクトを作成し、Word 文書を読み込みます
doc = Document()
doc.LoadFromFile("Sample.docx")
# コメントを追加するテキストを検索します
text = doc.FindString("抗酸化作用", True, True)
# コメントを作成し、コメントの内容と著者を設定します
comment = Comment(doc)
comment.Body.AddParagraph().Text = "抗酸化作用について、さらに詳しく説明する必要があります。"
comment.Format.Author = "奈々"
# 検索したテキストをテキスト範囲として取得し、それが属する段落を取得します
range = text.GetAsOneRange()
paragraph = range.OwnerParagraph
# コメントを段落に追加します
paragraph.ChildObjects.Insert(paragraph.ChildObjects.IndexOf(range) + 1, comment)
# コメントの開始マークと終了マークを作成し、作成したコメントの開始マークと終了マークとして設定します
commentStart = CommentMark(doc, CommentMarkType.CommentStart)
commentEnd = CommentMark(doc, CommentMarkType.CommentEnd)
commentStart.CommentId = comment.Format.CommentId
commentEnd.CommentId = comment.Format.CommentId
# 作成したコメントの開始マークと終了マークを、検索したテキストの前後に挿入します
paragraph.ChildObjects.Insert(paragraph.ChildObjects.IndexOf(range), commentStart)
paragraph.ChildObjects.Insert(paragraph.ChildObjects.IndexOf(range) + 1, commentEnd)
# 文書を保存します
doc.SaveToFile("output/テキストへのコメント.docx")
doc.Close()
Spire.Doc for Python では、Document.Comments.RemoveAt() メソッドを使用して特定のコメントを削除できます。また、Document.Comments.Clear() メソッドを使用すれば、すべてのコメントを削除できます。以下の手順でコメントを削除します。
from spire.doc import Document
# Document クラスのオブジェクトを作成し、Word 文書を読み込みます
doc = Document()
doc.LoadFromFile("Sample1.docx")
# 2 番目のコメントを削除します
doc.Comments.RemoveAt(1)
# すべてのコメントを削除します
# doc.Comments.Clear()
# 文書を保存します
doc.SaveToFile("output/コメントの削除.docx")
doc.Close()
Spire.Doc for Python を使用すると、Comment.ReplyToComment(Comment) メソッドを利用して、特定のコメントに対して返信を追加できます。以下の手順でコメントに返信を追加します。
from spire.doc import Document, Comment
# Document クラスのオブジェクトを作成し、Word 文書を読み込みます
doc = Document()
doc.LoadFromFile("output/テキストへのコメント.docx")
# コメントを取得します
comment = doc.Comments.get_Item(0)
# 返信コメントを作成し、内容と著者を設定します
reply = Comment(doc)
reply.Body.AddParagraph().Text = "これは次のバージョンに追加されます。"
reply.Format.Author = "優花"
# 取得したコメントへの返信として作成したコメントを設定します
comment.ReplyToComment(reply)
# 文書を保存します
doc.SaveToFile("output/コメントへの返信.docx")
doc.Close()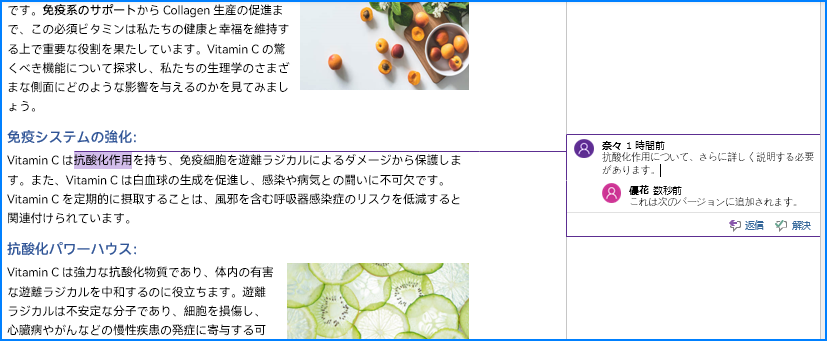
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書にブックマークを追加すると、特定の位置をマークしてすばやく参照したり移動したりできるようになります。ブックマークは仮想的な目印として機能し、長い文書内の重要なセクションを簡単に見つけるのに役立ちます。本記事では、Spire.Doc for Python を使用して Word 文書にブックマークを追加する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python では、BookmarkStart クラスがブックマークの開始位置を、BookmarkEnd クラスがブックマークの終了位置を表します。段落をブックマークするには、段落の先頭に BookmarkStart オブジェクトを挿入し、末尾に BookmarkEnd オブジェクトを追加します。具体的な手順は次のとおりです。
from spire.doc import Document
# Document オブジェクトを作成します
doc = Document()
# サンプルの Word ファイルを読み込みます
doc.LoadFromFile('Sample.docx')
# 2 番目の段落を取得します
paragraph = doc.Sections.get_Item(0).Paragraphs.get_Item(1)
# ブックマークの開始を作成します
start = paragraph.AppendBookmarkStart('ブックマーク 1')
# 段落の先頭に挿入します
paragraph.Items.Insert(0, start)
# 段落の末尾にブックマークの終了を追加します
paragraph.AppendBookmarkEnd('ブックマーク 1')
# ファイルを保存します
doc.SaveToFile('output/段落にブックマークを追加.docx')
doc.Dispose()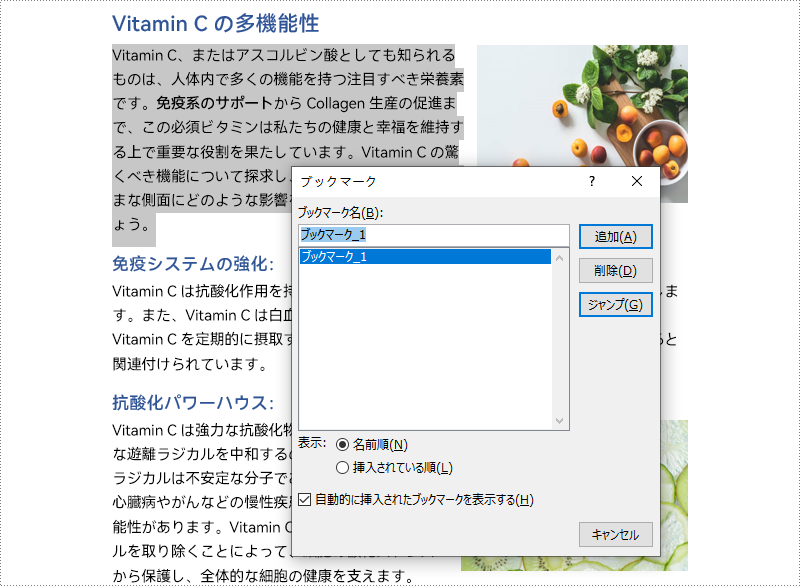
特定のテキストをブックマークするには、まず文書内で該当するテキストを見つけ、その段落内の位置を取得します。次に、そのテキストの前に BookmarkStart を、後に BookmarkEnd を挿入します。具体的な手順は次のとおりです。
from spire.doc import Document
# Document オブジェクトを作成します
doc = Document()
# サンプルの Word ファイルを読み込みます
doc.LoadFromFile('Sample.docx')
# 検索する文字列を指定します
stringToFind = '抗酸化作用'
# 文書内で指定した文字列を検索します
finds = doc.FindAllString(stringToFind, False, True)
specificText = finds[0]
# 検索した文字列が含まれる段落を取得します
paragraph = specificText.GetAsOneRange().OwnerParagraph
# 段落内での文字列のインデックスを取得します
index = paragraph.ChildObjects.IndexOf(specificText.GetAsOneRange())
# ブックマークの開始を作成します
start = paragraph.AppendBookmarkStart("ブックマーク 2")
# 指定したインデックスの位置にブックマークの開始を挿入します
paragraph.ChildObjects.Insert(index, start)
# ブックマークの終了を作成します
end = paragraph.AppendBookmarkEnd("ブックマーク 2")
# 検索した文字列の末尾にブックマークの終了を挿入します
paragraph.ChildObjects.Insert(index + 2, end)
# 文書を別のファイルとして保存します
doc.SaveToFile("output/テキストにブックマークを挿入.docx")
doc.Dispose()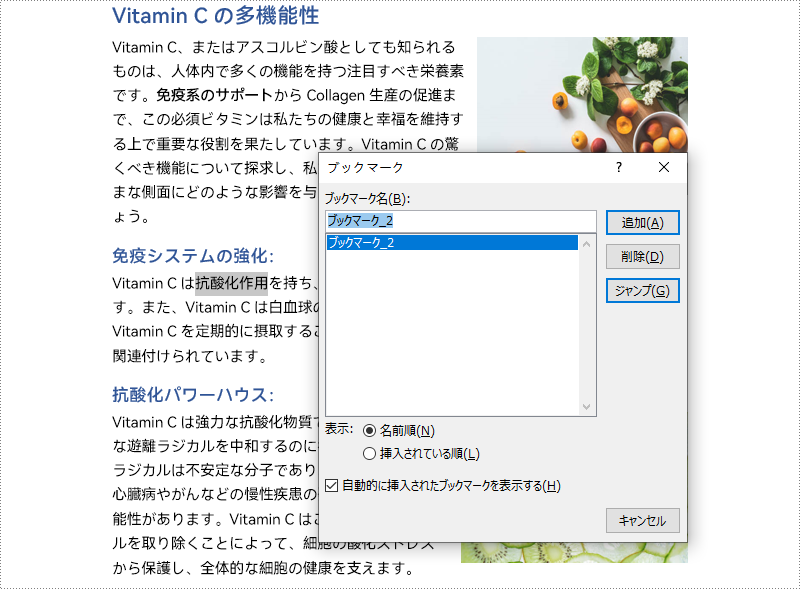
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書の表に行や列を追加・削除することで、データの構造を適切に調整できます。行や列を追加することで、データの増加に対応し、必要な情報をすべて表示できるようになります。一方で、不必要な行や列を削除すれば、表を整理し、文書の冗長な情報を削減できます。本記事では、Spire.Doc for Python を使用して、Python で Word 文書の表に行や列を追加・削除する方法を解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocWord の表に行を追加するには、表の末尾に追加する方法と、特定の位置に挿入する方法があります。これには Table.AddRow() または Table.InsertRow() メソッドを使用します。以下の手順で実装できます。
from spire.doc import Document, Table, HorizontalAlignment, VerticalAlignment
# Document オブジェクトを作成します。
document = Document()
# Word 文書を読み込みます。
document.LoadFromFile("Sample.docx")
# 文書の最初のセクションを取得します。
section = document.Sections[0]
# 最初のセクションの最初のテーブルを取得します。
table = section.Tables[0] if isinstance(section.Tables[0], Table) else None
# テーブルの 3 行目として新しい行を挿入します。
table.Rows.Insert(2, table.AddRow())
# 挿入された行を取得します。
insertedRow = table.Rows[2]
# 行にデータを追加します。
for i in range(insertedRow.Cells.Count):
cell = insertedRow.Cells[i]
paragraph = cell.AddParagraph()
textRange = paragraph.AppendText("挿入された行")
textRange.CharacterFormat.FontName = "Yu Gothic UI"
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Left
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
# テーブルの末尾に新しい行を追加します。
addedRow = table.AddRow()
# 行にデータを追加します。
for i in range(addedRow.Cells.Count):
cell = addedRow.Cells[i]
paragraph = cell.AddParagraph()
textRange = paragraph.AppendText("終了行")
textRange.CharacterFormat.FontName = "Yu Gothic UI"
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Left
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
# 変更後の文書を保存します。
document.SaveToFile("output/Wordの表に行を追加・挿入.docx")
document.Close()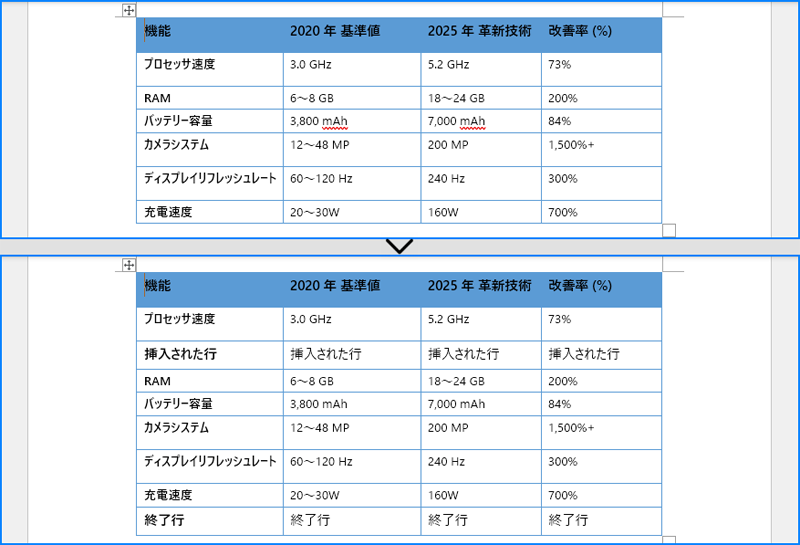
Spire.Doc for Python には、Word の表に直接列を追加・挿入するメソッドはありません。しかし、各行の特定の位置にセルを追加・挿入することで実現できます。TableRow.Cells.Add() または TableRow.Cells.Insert() メソッドを使用し、以下の手順で実装します。
from spire.doc import Document, TableCell, Table, HorizontalAlignment, VerticalAlignment, AutoFitBehaviorType
# Document オブジェクトを作成します。
document = Document()
# Word 文書を読み込みます。
document.LoadFromFile("Sample.docx")
# 文書の最初のセクションを取得します。
section = document.Sections[0]
# 最初のセクションの最初のテーブルを取得します。
table = section.Tables[0] if isinstance(section.Tables[0], Table) else None
# テーブルの各行をループ処理します。
for i in range(table.Rows.Count):
row = table.Rows[i]
# TableCell オブジェクトを作成します。
cell = TableCell(document)
# 行の 3 列目にセルを挿入し、セルの幅を設定します。
row.Cells.Insert(2, cell)
cell.Width = row.Cells[0].Width
# セルにデータを追加します。
paragraph = cell.AddParagraph()
textRange = paragraph.AppendText("挿入された列")
textRange.CharacterFormat.FontName = "Yu Gothic UI"
# テキストの配置を設定します。
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Left
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
# 行の末尾にセルを追加し、セルの幅を設定します。
cell = row.AddCell()
cell.Width = row.Cells[1].Width
# セルにデータを追加します。
paragraph = cell.AddParagraph()
textRange = paragraph.AppendText("終了列")
textRange.CharacterFormat.FontName = "Yu Gothic UI"
# テキストの配置を設定します。
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Left
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
# 列を自動調整する
table.AutoFit(AutoFitBehaviorType.AutoFitToContents)
# 変更後の文書を保存します。
document.SaveToFile("output/Wordの表に列を追加・挿入.docx")
document.Close()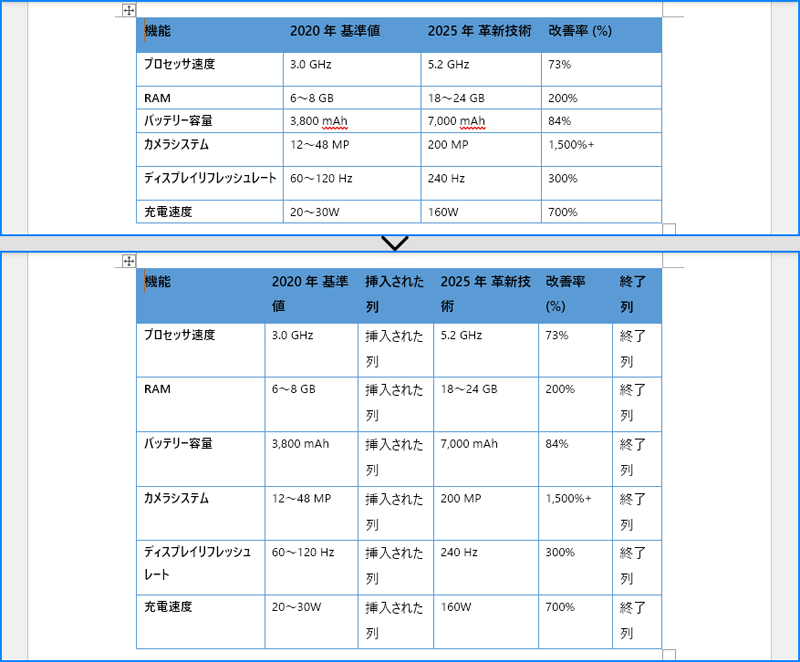
Word の表から特定の行を削除するには、Table.Rows.RemoveAt() メソッドを使用します。以下の手順で実装します。
from spire.doc import Document, Table
# Document オブジェクトを作成します。
document = Document()
# Word 文書を読み込みます。
document.LoadFromFile("Sample.docx")
# 文書の最初のセクションを取得します。
section = document.Sections[0]
# 最初のセクションの最初のテーブルを取得します。
table = section.Tables[0] if isinstance(section.Tables[0], Table) else None
# 行を削除します。
table.Rows.RemoveAt(1)
# 変更後の文書を保存します。
document.SaveToFile("output/Wordの表から行を削除.docx")
document.Close()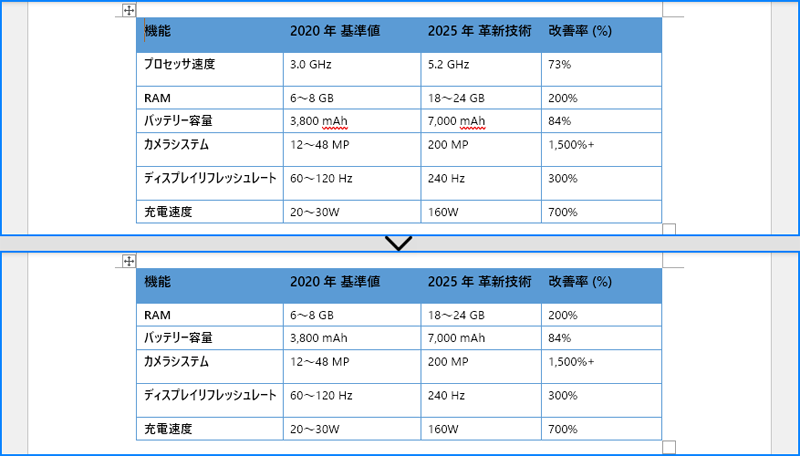
Word の表から特定の列を削除するには、各行から対応するセルを削除する必要があります。これには TableRow.Cells.RemoveAt() メソッドを使用します。以下の手順で実装します。
from spire.doc import Document, Table
# Document オブジェクトを作成します。
document = Document()
# Word 文書を読み込みます。
document.LoadFromFile("Sample.docx")
# 文書の最初のセクションを取得します。
section = document.Sections[0]
# 最初のセクションの最初のテーブルを取得します。
table = section.Tables[0] if isinstance(section.Tables[0], Table) else None
# テーブルの各行をループ処理します。
for i in range(table.Rows.Count):
row = table.Rows[i]
# 列のセルを削除します。
row.Cells.RemoveAt(2)
# 変更後の文書を保存します。
document.SaveToFile("output/Wordの表から列を削除.docx")
document.Close()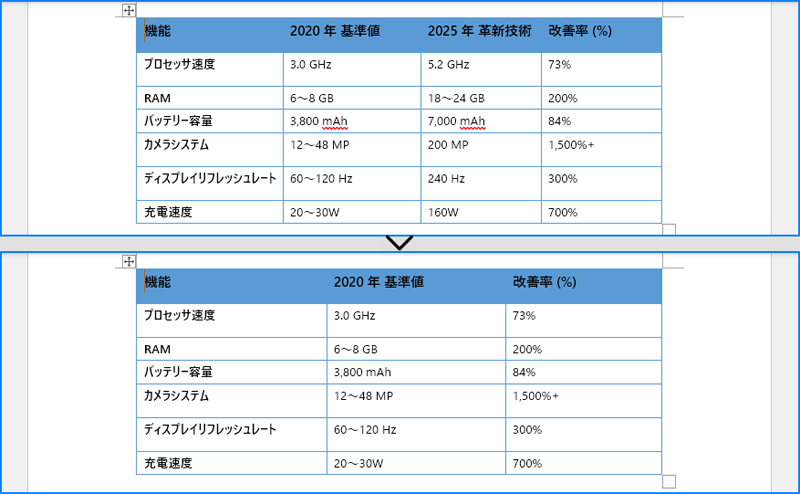
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ハイパーリンクは、動的でインタラクティブな Word 文書を作成するために欠かせない要素です。特定のテキストやオブジェクトを他の文書、ウェブページ、メールアドレス、または同じ文書内の特定の位置にリンクすることで、ユーザーは情報をシームレスに移動できます。本記事では、Spire.Doc for Python を使用して、Python で Word 文書にハイパーリンクを追加または削除する方法を学びます。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python は、段落内のテキストや画像にウェブリンク、メールリンク、ファイルリンク、またはブックマークリンクを追加するための Paragraph.AppendHyperlink() メソッドを提供します。以下に詳細な手順を示します。
from spire.doc import *
# Word文書を作成する
doc = Document()
# セクションを追加する
section = doc.AddSection()
section.PageSetup.Margins.All = 72.0
# 段落スタイルを作成する
style = ParagraphStyle(doc)
style.Name = "例のスタイル"
style.CharacterFormat.FontName = "Yu Gothic UI"
style.CharacterFormat.FontSize = 16.0
doc.Styles.Add(style)
# 段落を追加する
paragraph = section.AddParagraph()
paragraph.ApplyStyle(style.Name)
paragraph.AppendHyperlink("https://jp.e-iceblue.com/", "ホームページ", HyperlinkType.WebLink)
# 改行を挿入する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
# メールリンクを追加する
paragraph.AppendHyperlink("mailto:support @e-iceblue.com", "メールを送る", HyperlinkType.EMailLink)
# 改行を挿入する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
# ファイルリンクを追加する
filePath = "レポート.xlsx"
paragraph.AppendHyperlink(filePath, "レポートを開く", HyperlinkType.FileLink)
# 改行を挿入する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
# 別のセクションを追加し、ブックマークを作成する
section2 = doc.AddSection()
bookmarkParagraph = section2.AddParagraph()
bookmarkParagraph.AppendText("ここにブックマークがあります")
start = bookmarkParagraph.AppendBookmarkStart("myBookmark")
bookmarkParagraph.Items.Insert(0, start)
bookmarkParagraph.AppendBookmarkEnd("myBookmark")
# ブックマークへのリンクを追加する
paragraph.AppendHyperlink("myBookmark", "この文書内の場所へ移動", HyperlinkType.Bookmark)
# 改行を挿入する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
# 画像リンクを追加する
imagePath = "Logo.png"
picture = paragraph.AppendPicture(imagePath)
paragraph.AppendHyperlink("https://jp.e-iceblue.com/", picture, HyperlinkType.WebLink)
# ファイルに保存する
doc.SaveToFile("output/Wordでハイパーリンクを作成.docx", FileFormat.Docx2019)
doc.Dispose()
Word 文書内のすべてのハイパーリンクを一度に削除するには、文書内のすべてのハイパーリンクを見つけて、それらをフラット化するカスタムメソッド FlattenHyperlinks() を作成する必要があります。以下に詳細な手順を示します。
from spire.doc import *
from spire.doc.common import *
# ドキュメント内のすべてのハイパーリンクを検索する関数
def FindAllHyperlinks(document):
hyperlinks = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
for j in range(section.Body.ChildObjects.Count):
sec = section.Body.ChildObjects.get_Item(j)
if sec.DocumentObjectType == DocumentObjectType.Paragraph:
for k in range((sec if isinstance(sec, Paragraph) else None).ChildObjects.Count):
para = (sec if isinstance(sec, Paragraph)
else None).ChildObjects.get_Item(k)
if para.DocumentObjectType == DocumentObjectType.Field:
field = para if isinstance(para, Field) else None
if field.Type == FieldType.FieldHyperlink:
hyperlinks.append(field)
return hyperlinks
# ハイパーリンクフィールドを平坦化する関数
def FlattenHyperlinks(field):
ownerParaIndex = field.OwnerParagraph.OwnerTextBody.ChildObjects.IndexOf(
field.OwnerParagraph)
fieldIndex = field.OwnerParagraph.ChildObjects.IndexOf(field)
sepOwnerPara = field.Separator.OwnerParagraph
sepOwnerParaIndex = field.Separator.OwnerParagraph.OwnerTextBody.ChildObjects.IndexOf(
field.Separator.OwnerParagraph)
sepIndex = field.Separator.OwnerParagraph.ChildObjects.IndexOf(
field.Separator)
endIndex = field.End.OwnerParagraph.ChildObjects.IndexOf(field.End)
endOwnerParaIndex = field.End.OwnerParagraph.OwnerTextBody.ChildObjects.IndexOf(
field.End.OwnerParagraph)
FormatFieldResultText(field.Separator.OwnerParagraph.OwnerTextBody,
sepOwnerParaIndex, endOwnerParaIndex, sepIndex, endIndex)
field.End.OwnerParagraph.ChildObjects.RemoveAt(endIndex)
for i in range(sepOwnerParaIndex, ownerParaIndex - 1, -1):
if i == sepOwnerParaIndex and i == ownerParaIndex:
for j in range(sepIndex, fieldIndex - 1, -1):
field.OwnerParagraph.ChildObjects.RemoveAt(j)
elif i == ownerParaIndex:
for j in range(field.OwnerParagraph.ChildObjects.Count - 1, fieldIndex - 1, -1):
field.OwnerParagraph.ChildObjects.RemoveAt(j)
elif i == sepOwnerParaIndex:
for j in range(sepIndex, -1, -1):
sepOwnerPara.ChildObjects.RemoveAt(j)
else:
field.OwnerParagraph.OwnerTextBody.ChildObjects.RemoveAt(i)
# フィールドをテキスト範囲に変換し、テキストの書式設定をクリアする関数
def FormatFieldResultText(ownerBody, sepOwnerParaIndex, endOwnerParaIndex, sepIndex, endIndex):
for i in range(sepOwnerParaIndex, endOwnerParaIndex + 1):
para = ownerBody.ChildObjects[i] if isinstance(
ownerBody.ChildObjects[i], Paragraph) else None
if i == sepOwnerParaIndex and i == endOwnerParaIndex:
for j in range(sepIndex + 1, endIndex):
if isinstance(para.ChildObjects[j], TextRange):
FormatText(para.ChildObjects[j])
elif i == sepOwnerParaIndex:
for j in range(sepIndex + 1, para.ChildObjects.Count):
if isinstance(para.ChildObjects[j], TextRange):
FormatText(para.ChildObjects[j])
elif i == endOwnerParaIndex:
for j in range(0, endIndex):
if isinstance(para.ChildObjects[j], TextRange):
FormatText(para.ChildObjects[j])
else:
for j, unusedItem in enumerate(para.ChildObjects):
if isinstance(para.ChildObjects[j], TextRange):
FormatText(para.ChildObjects[j])
# テキストをフォーマットする関数
def FormatText(tr):
tr.CharacterFormat.TextColor = Color.get_Black()
tr.CharacterFormat.UnderlineStyle = UnderlineStyle.none
# ドキュメントオブジェクトを作成
doc = Document()
# Wordファイルを読み込む
doc.LoadFromFile("output/Wordでハイパーリンクを作成.docx")
# すべてのハイパーリンクを取得
hyperlinks = FindAllHyperlinks(doc)
# すべてのハイパーリンクを平坦化
for i in range(len(hyperlinks) - 1, -1, -1):
FlattenHyperlinks(hyperlinks[i])
# 異なるファイルに保存
doc.SaveToFile("output/Wordからハイパーリンクを削除.docx")
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書に画像を挿入すると、大量のテキストを分割し、内容を視覚的にわかりやすくすることができます。また、複雑な概念や説明しにくい内容を効果的に伝える手段にもなります。本記事では、Spire.Doc for Python を使用してプログラムで Word 文書に画像を追加する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python では、Paragraph.AppendPicture() メソッドを使用して Word 文書に画像を挿入できます。以下の手順で実装できます。
from spire.doc import Document, TextWrappingStyle, FileFormat
# Documentオブジェクトを作成
document = Document()
# セクションを追加
section = document.AddSection()
section.PageSetup.Margins.All = 50
# 段落を追加
paragraph1 = section.AddParagraph()
# 段落にテキストを追加し、フォーマットを設定
tr = paragraph1.AppendText("Spire.Doc for Pythonは、開発者が高速かつ高品質なパフォーマンスでWord文書を作成、読み取り、書き込み、変換、および比較するために特別に設計されたプロフェッショナルなWord Python APIです。")
tr.CharacterFormat.FontName = "Yu Gothic UI"
tr.CharacterFormat.FontSize = 11
paragraph1.Format.LineSpacing = 18
paragraph1.Format.BeforeSpacing = 10
paragraph1.Format.AfterSpacing = 10
# 別の段落を追加
paragraph2 = section.AddParagraph()
tr = paragraph2.AppendText("Spire.Doc for Pythonは、多くのWord文書処理タスクを実行することを可能にします。Word 97-2003 / 2007 / 2010 / 2013 / 2016 / 2019をサポートしており、XML、RTF、TXT、XPS、EPUB、EMF、HTMLなどの一般的に使用されるファイル形式への変換やその逆も可能です。さらに、Pythonを使用してWord Doc/DocxをPDFに変換したり、WordをSVGやPostScriptに高品質で変換することをサポートしています。")
# 段落にテキストを追加し、フォーマットを設定
tr.CharacterFormat.FontName = "Yu Gothic UI"
tr.CharacterFormat.FontSize = 11
paragraph2.Format.LineSpacing = 18
# 指定した段落に画像を追加
picture = paragraph1.AppendPicture("Spire.Doc for Python.png")
# 画像の幅と高さを設定
picture.Width = 100
picture.Height = 100
# 画像のテキスト折り返しスタイルを設定
picture.TextWrappingStyle = TextWrappingStyle.Square
# 結果の文書を保存
document.SaveToFile("output/Wordに画像を挿入.docx", FileFormat.Docx)
document.Close()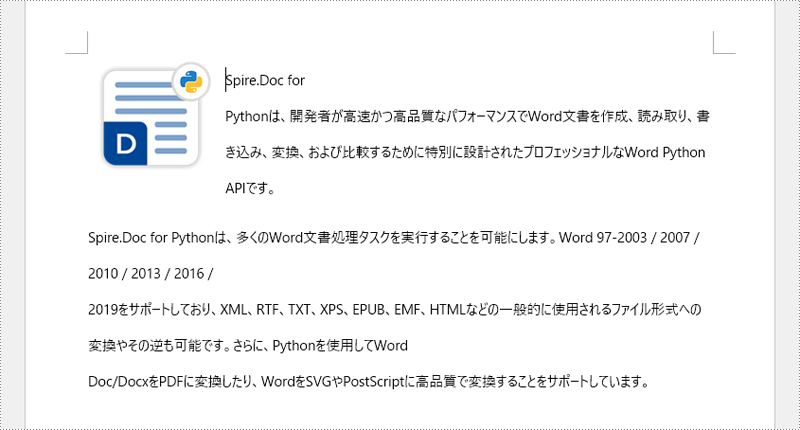
画像を Word 文書の特定の位置に配置したい場合は、DocPicture.HorizontalPosition および DocPicture.VerticalPosition プロパティを設定することで調整できます。以下の手順で実装できます。
from spire.doc import Document, FileFormat, TextWrappingStyle, Color
# Document オブジェクトを作成します。
doc = Document()
# セクションを追加します。
section = doc.AddSection()
section.PageSetup.Margins.All = 50
# セクションに段落を追加します。
paragraph = section.AddParagraph()
# 段落にテキストを追加し、書式を設定します。
textRange = paragraph.AppendText("このサンプルは、Word 文書の指定した位置に画像を挿入する方法を示します。")
textRange.CharacterFormat.FontName = "Yu Gothic UI"
textRange.CharacterFormat.FontSize = 14
textRange.CharacterFormat.TextColor = Color.get_BlueViolet()
# 段落に画像を追加します。
picture = paragraph.AppendPicture("Image.jpg")
# 画像の位置を設定します。
picture.HorizontalPosition = 150.0
picture.VerticalPosition = 80.0
# 画像のサイズを設定します。
picture.Width = 100.0
picture.Height = 160.0
# 画像の折り返しスタイルを設定します。
# (テキストの折り返しスタイルが「インライン」の場合、位置設定は適用されません。)
picture.TextWrappingStyle = TextWrappingStyle.Through
# 文書を保存します。
doc.SaveToFile("output/Wordに画像を挿入.docx", FileFormat.Docx)
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書に背景色や画像を追加することで、視覚的な魅力を高め、読者の関心を引くことができます。プロフェッショナルなレポート、クリエイティブなチラシ、個人的な招待状など、適切な背景色や画像を取り入れることで、通常の文書を魅力的な作品へと変えることが可能です。本記事では、Spire.Doc for Python を使用して、Word 文書に背景色や背景画像を追加する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocWord 文書の背景色を設定するには、背景の種類を「Color」に変更し、背景色を指定します。具体的な手順は以下のとおりです。
from spire.doc import Document, BackgroundType, Color
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample.docx")
# 文書の背景を取得します
background = document.Background
# 背景の種類をカラーに設定します
background.Type = BackgroundType.Color
# 背景色を設定します
background.Color = Color.get_AliceBlue()
# 処理結果の文書を保存します
document.SaveToFile("output/背景色の追加.docx")
document.Close()
グラデーション背景とは、2 色以上の色が滑らかに移り変わる背景スタイルです。グラデーション背景を追加するには、背景の種類を「Gradient」に変更し、グラデーションの色、シェーディングのバリエーション、スタイルを指定します。具体的な手順は以下のとおりです。
from spire.doc import Document, BackgroundType, Color, GradientShadingStyle, GradientShadingVariant
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample.docx")
# 文書の背景を取得します
background = document.Background
# 背景の種類をグラデーションに設定します
background.Type = BackgroundType.Gradient
# 2 色のグラデーションを設定します
background.Gradient.Color1 = Color.get_White()
background.Gradient.Color2 = Color.get_LightBlue()
# グラデーションのシェーディングのバリアントとスタイルを設定します
background.Gradient.ShadingVariant = GradientShadingVariant.ShadingDown
background.Gradient.ShadingStyle = GradientShadingStyle.Horizontal
# 処理結果の文書を保存します
document.SaveToFile("output/グラデーション背景の追加.docx")
document.Close()
Word 文書の背景に画像を追加するには、背景の種類を「Picture」に変更し、画像を設定します。具体的な手順は以下のとおりです。
from spire.doc import Document, BackgroundType
# Document オブジェクトを作成します
document = Document()
# Word 文書を読み込みます
document.LoadFromFile("Sample.docx")
# 文書の背景を取得します
background = document.Background
# 背景の種類を画像に設定します
background.Type = BackgroundType.Picture
# 背景画像を設定します
background.SetPicture("BackgroundImage.jpg")
# 処理結果の文書を保存します
document.SaveToFile("output/背景画像の追加.docx")
document.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ページサイズとは、文書のページの寸法を指します。これは印刷可能領域の幅と高さを決定し、文書のレイアウトやデザインにおいて重要な役割を果たします。例えば、ビジネス文書には標準的なレターサイズ(8.5 x 11インチ)、国際的な文書には A4 サイズ(210 x 297mm)が使用されることが一般的です。ページサイズを適切に設定することで、目的の出力形式やプレゼンテーション媒体に適合した文書を作成できます。本記事では、Spire.Doc for Python を使用して、Word 文書のページサイズを調整する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python を使用すると、A3、A4、A5、A6、B4、B5、B6、レター、リーガル、タブロイドなど、さまざまな標準ページサイズに簡単に変更できます。以下の手順で、Word 文書のページサイズを標準サイズに変更する方法を説明します。
from spire.doc import Document, PageSize
# Document クラスのインスタンスを作成します
doc = Document()
# Word 文書を読み込みます
doc.LoadFromFile("Sample.docx")
# 文書内のセクションを順に処理します
for i in range(doc.Sections.Count):
section = doc.Sections.get_Item(i)
# 各セクションのページサイズを A4 に変更します
section.PageSetup.PageSize = PageSize.A4()
# 処理結果の文書を保存します
doc.SaveToFile("output/標準ページサイズ.docx")
doc.Close()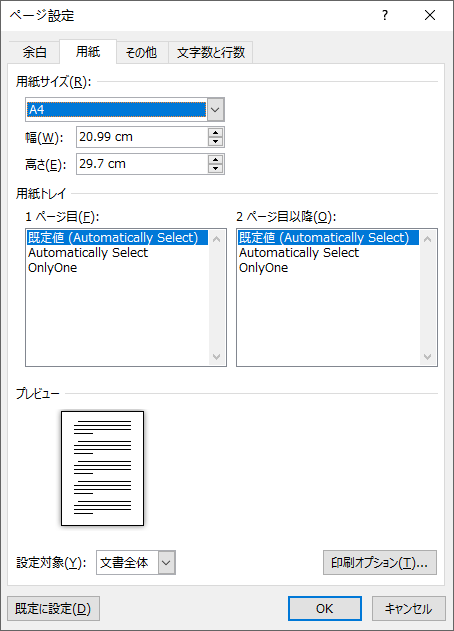
標準の用紙サイズに合わない独自の寸法で印刷する場合、カスタムページサイズを設定できます。以下の手順で、Spire.Doc for Python を使用して Word 文書のページサイズをカスタムサイズに変更する方法を説明します。
from spire.doc import Document, SizeF
# Document クラスのインスタンスを作成します
doc = Document()
# Word 文書を読み込みます
doc.LoadFromFile("Sample.docx")
# 指定した寸法で SizeF クラスのインスタンスを作成します
customSize = SizeF(600.0, 800.0)
# 文書内のセクションを順に処理します
for i in range(doc.Sections.Count):
section = doc.Sections.get_Item(i)
# 各セクションのページサイズを指定した寸法に変更します
section.PageSetup.PageSize = customSize
# 処理結果の文書を保存します
doc.SaveToFile("output/カスタムページサイズ.docx")
doc.Close()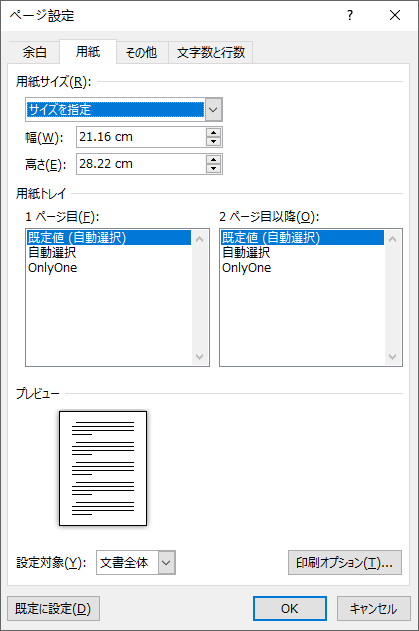
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ドキュメント作成の過程で、空白行が多く見られることがあります。これらの空白は、内容の流れを妨げ、レイアウトを散らかし、ドキュメントの全体的な美的印象を損なう可能性があります。読みやすさを最適化し、構造的に整ったドキュメントを維持するためには、空白行を削除することが重要です。本記事では、Spire.Doc for Python を使用して、Python で Word ドキュメントから空白行を削除する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocWord ドキュメント内の空白行は、セクションの子オブジェクトである空の段落として表示されます。したがって、空白行を削除するには、セクションを繰り返し処理し、その中の空の段落を特定して削除する必要があります。具体的な手順は以下の通りです:
from spire.doc import Document, DocumentObjectType, Paragraph
# Documentクラスのオブジェクトを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("Sample.docx")
# 文書内の各セクションを繰り返し処理
for i in range(doc.Sections.Count):
section = doc.Sections.get_Item(i)
j = 0
# セクション内の各子オブジェクトを繰り返し処理
while j < section.Body.ChildObjects.Count:
# 子オブジェクトがParagraph型かどうかをチェック
if section.Body.ChildObjects[j].DocumentObjectType == DocumentObjectType.Paragraph:
objItem = section.Body.ChildObjects[j]
# 子オブジェクトがParagraphクラスのインスタンスかどうかをチェック
if isinstance(objItem, Paragraph):
paraObj = Paragraph(objItem)
# 段落のテキストが空かどうかをチェック
if len(paraObj.Text) == 0:
# テキストが空の場合、セクションの子オブジェクトリストから削除
section.Body.ChildObjects.Remove(objItem)
j -= 1
j += 1
# 文書を保存
doc.SaveToFile("output/空白行の削除.docx")
doc.Close()
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
機密情報を不正アクセスから守ることは、個人や組織にとって重要な課題です。財務記録、法的文書、個人情報などの機密性の高い Word 文書を共有したり保存したりする場合、文書を暗号化することでそのセキュリティと機密性を強化できます。さらに、Python を使用すると、多数の Word 文書を簡単に暗号化することができます。この記事では、Spire.Doc for Python を使って Python プログラムで Word 文書を暗号化復号化する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python が提供する Document.Encrypt(password: str) メソッドを使用することで、Word 文書にオープンパスワードを設定し、許可された人物のみが文書を開いて閲覧できるようにすることができます。パスワードで Word 文書を暗号化する詳細な手順は以下の通りです。
from spire.doc import Document
# Documentクラスのインスタンスを作成
doc = Document()
# Wordドキュメントを読み込む
doc.LoadFromFile("Sample.docx")
# ドキュメントを暗号化する
doc.Encrypt("password")
# ドキュメントを保存する
doc.SaveToFile("output/暗号化されたWord文書.docx")
doc.Close()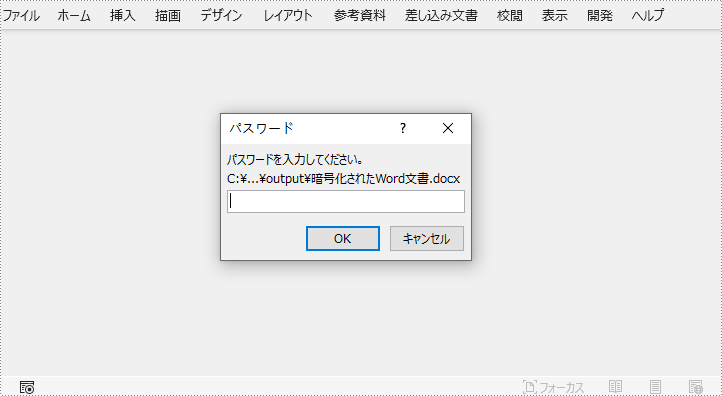
暗号化された文書をロードする際に、パスワードをパラメータとして渡すことで、Document.LoadFromFile(fileName: str, fileFormat: FileFormat, password: str) メソッドを使用して文書を読み込むことができます。文書を読み込んだ後、Document.Encrypt() メソッドを使用して、新しいパスワードを設定できます。詳細な手順は以下の通りです。
from spire.doc import Document, FileFormat
# Documentクラスのインスタンスを作成
doc = Document()
# 暗号化されたWordドキュメントを読み込む
doc.LoadFromFile("output/暗号化されたWord文書.docx", FileFormat.Docx, "password")
# パスワードを変更する
doc.Encrypt("password1")
# ドキュメントを保存する
doc.SaveToFile("output/Word文書のパスワード変更.docx")
doc.Close()暗号化された Word 文書を読み込んだ後、Document.RemoveEncryption() メソッドを使用して、文書から暗号化を削除することもできます。これにより、すべてのユーザーが文書を利用できるようになります。詳細な手順は以下の通りです。
from spire.doc import Document, FileFormat
# Documentクラスのインスタンスを作成
doc = Document()
# 暗号化されたWordドキュメントを読み込む
doc.LoadFromFile("output/暗号化されたWord文書.docx", FileFormat.Auto, "password")
# パスワードを削除する
doc.RemoveEncryption()
# ドキュメントを保存する
doc.SaveToFile("output/Word文書パスワードの削除.docx", FileFormat.Auto)
doc.Close()結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書の編集制限機能は、ユーザーが編集可能な範囲や編集内容を制御・制限できる機能です。この機能は、機密性の高い文書や重要な文書を不正または不適切な変更から保護するためによく使用されます。編集制限を適用することで、文書の所有者は、どの種類の変更が可能か、文書のどの部分を編集できるかを指定でき、文書の保護や共同作業、情報収集の効率化などに役立ちます。
本記事では、Spire.Doc for Python を使用して Word 文書の編集制限を設定および解除する方法を紹介します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocWord 文書の編集制限には以下の 4 種類があります。
Spire.Doc for Python では、Document.Protect() メソッドを使用して編集制限を設定でき、ProtectionType 列挙型で制限の種類を指定できます。
以下に ProtectionType 列挙型と対応する編集制限を示します。
| Enum | 編集制限 | 説明 |
| ProtectionType.AllowOnlyReading | 変更不可 (読み取り専用) | 読み取りのみ許可 |
| ProtectionType.AllowOnlyRevisions | 変更履歴の記録のみ許可 | 変更履歴の記録のみ許可 |
| ProtectionType.AllowOnlyComments | コメントの追加のみ許可 | コメントのみ許可 |
| ProtectionType.AllowOnlyFormFields | フォームの入力のみ許可 | フォームの入力のみ許可 |
| ProtectionType.NoProtection | 制限なし | 制限なし |
Word 文書にパスワード付きの編集制限を設定する手順は以下のとおりです。
from spire.doc import Document, ProtectionType
# Documentクラスのオブジェクトを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("Sample.docx")
# 編集制限タイプを「変更不可(読み取り専用)」に設定
doc.Protect(ProtectionType.AllowOnlyReading, "password")
# 編集制限タイプを「変更履歴」に設定
# doc.Protect(ProtectionType.AllowOnlyRevisions, "password")
# 編集制限タイプを「コメント」に設定
# doc.Protect(ProtectionType.AllowOnlyComments, "password")
# 編集制限タイプを「フォーム入力」に設定
# doc.Protect(ProtectionType.AllowOnlyFormFields, "password")
# 文書を保存
doc.SaveToFile("output/編集の制限.docx")
doc.Close()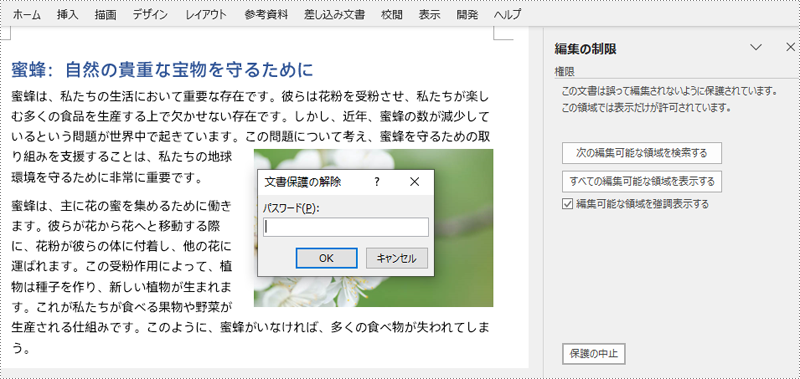
Word 文書に編集制限を設定する際、一部の範囲を例外として許可することができます。そのためには、許可範囲の開始タグと終了タグを挿入します。
手順は以下のとおりです。
from spire.doc import Document, PermissionStart, PermissionEnd, ProtectionType
# Documentクラスのオブジェクトを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("Sample.docx")
# 最初のセクションを取得
section = doc.Sections.get_Item(0)
# 権限開始タグと終了タグを作成
start = PermissionStart(doc, "exception1")
end = PermissionEnd(doc, "exception1")
# 権限開始タグと終了タグを最初のセクションに挿入
paragraph = section.Paragraphs.get_Item(1)
paragraph.ChildObjects.Insert(0, start)
paragraph.ChildObjects.Add(end)
# 編集制限を設定
doc.Protect(ProtectionType.AllowOnlyReading, "password")
# 文書を保存
doc.SaveToFile("output/例外による編集の制限.docx")
doc.Close()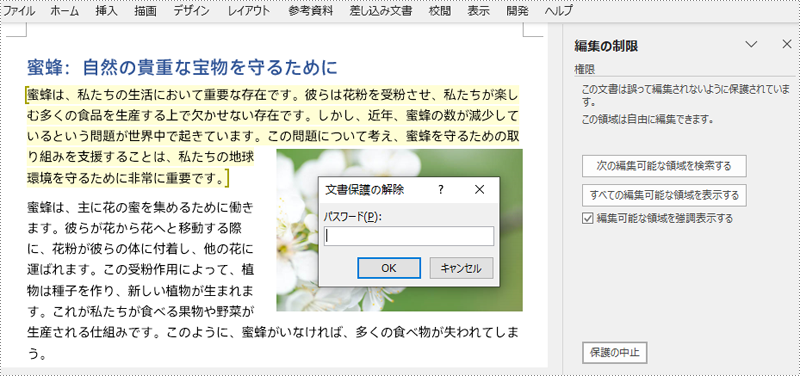
文書の編集制限を解除するには、Document.Protect() メソッドを使用し、編集制限の種類を「制限なし」に設定するだけです。
手順は以下のとおりです。
from spire.doc import Document, ProtectionType
# Documentクラスのオブジェクトを作成
doc = Document()
# Word文書を読み込む
doc.LoadFromFile("output/編集の制限.docx")
# 編集制限を削除するために制限タイプを「保護なし」に設定
doc.Protect(ProtectionType.NoProtection)
# 文書を保存
doc.SaveToFile("output/編集制限の解除.docx")
doc.Close()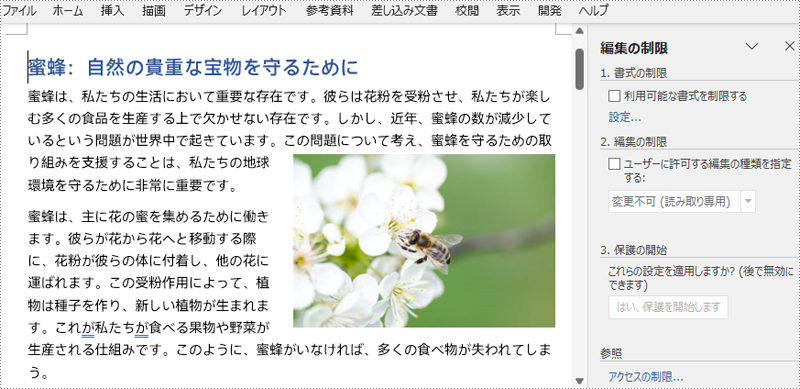
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





