チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

HTML はオンライン閲覧向けに設計されていますが、Word 文書は印刷や物理的な文書として一般的に使用されます。HTML を Word に変換することで、ページ区切りやヘッダー、フッターなどの要素が適切に処理され、印刷に最適化された形式でコンテンツを整えることができます。本記事では、Spire.Doc for Python を使用して Python で HTML を Word に変換する方法を説明します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python の Document.SaveToFile() メソッドを使用すると、HTML ファイルを簡単に Word 形式に変換できます。手順は以下のとおりです。
from spire.doc import Document, FileFormat, XHTMLValidationType
# Document のインスタンスを作成します
doc = Document()
# HTML ファイルを読み込みます
doc.LoadFromFile("Sample.html", FileFormat.Html, XHTMLValidationType.none)
# HTML ファイルを Word 文書として保存します
doc.SaveToFile("output/HTMLToWord.docx", FileFormat.Docx)
doc.Close()
HTML ファイルだけでなく、HTML 形式の文字列も Word に変換できます。その場合、Paragraph.AppendHTML() メソッドを使用します。手順は以下のとおりです。
from spire.doc import Document, FileFormat
# Document のインスタンスを作成する
doc = Document()
# 文書にセクションを追加する
section = doc.AddSection()
# セクションに段落を追加する
paragraph = section.AddParagraph()
# HTML 文字列を指定する
htmlString = """
<h1 style=")color: #4682b4;">夢幻都市の軌跡</h1>
<p style="font-size: 14px; text-align: justify;">
この文書は、HTML文字列をWord文書に挿入する例です。<strong>強調</strong>や<em>斜体</em>のスタイルが含まれています。
</p>
<table style="width: 100%; border-collapse: collapse; margin: 10px 0;">
<thead>
<tr>
<th style="border: 1px solid #ccc; padding: 8px; background-color: #87cefa; color: #fff;">項目</th>
<th style="border: 1px solid #ccc; padding: 8px; background-color: #87cefa; color: #fff;">内容</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ccc; padding: 8px;">施設</td>
<td style="border: 1px solid #ccc; padding: 8px;">未来文化センター</td>
</tr>
<tr>
<td style="border: 1px solid #ccc; padding: 8px;">状態</td>
<td style="border: 1px solid #ccc; padding: 8px;">進行中</td>
</tr>
</tbody>
</table>
<ul style="margin-left: 20px;">
<li>最新技術の導入</li>
<li>環境に優しい設計</li>
</ul>
<blockquote style="border-left: 4px solid #ccc; margin: 10px 0; padding-left: 10px;">
<p style="font-style: italic;">「都市の未来は我々の手の中にある。」</p>
</blockquote>
"""
# HTML 文字列を段落に挿入する
paragraph.AppendHTML(htmlString)
# 文書を保存する
doc.SaveToFile("output/InsertHTMLStringToWord.docx", FileFormat.Docx)
doc.Close()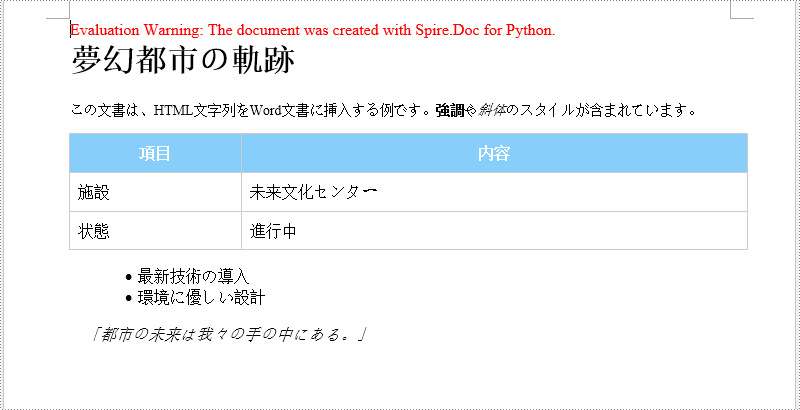
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書を HTML に変換することで、コンテンツをオンラインで簡単に共有・公開できます。また、HTML は検索エンジンに優しい形式であるため、検索エンジンがコンテンツをより効果的にインデックス化し、検索結果での可視性を向上させることができます。本記事では、Spire.Doc for Python を使用して、Word 文書をプログラムで HTML に変換する方法を解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python は、Document.SaveToFile(fileName string, FileFormat.Html) メソッドを提供しており、Word 文書(doc/docx 形式)を HTML ファイルとして簡単に保存できます。以下に、詳細な手順を示します。
from spire.doc import Document, FileFormat
# Documentクラスのインスタンスを作成します
doc = Document()
# Word文書を読み込みます
doc.LoadFromFile("Sample.docx")
# 文書をHTML形式で保存します
doc.SaveToFile("output/WordToHTML.html", FileFormat.Html)
doc.Close()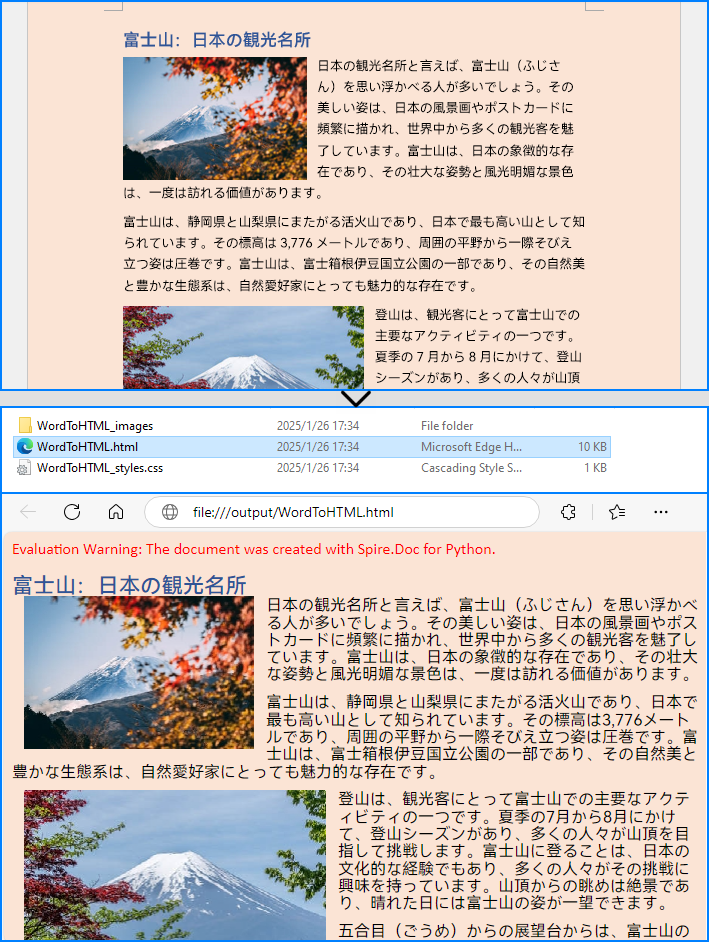
Spire.Doc for Python は、変換時にエクスポートオプションを設定できる HtmlExportOptions クラスも提供しています。これにより、CSS スタイルや画像の埋め込み、フォームフィールドをプレーンテキストとしてエクスポートするかどうかなどを設定できます。以下は、HtmlExportOptions クラスを通して設定できるエクスポート・オプションの表です。
| プロパティ | 説明 |
| CssStyleSheetType | HTML の CSS スタイルシートの種類を指定します(外部または内部)。 |
| CssStyleSheetFileName | HTML の CSS スタイルシートファイルの名前を指定します。 |
| ImageEmbedded | Data URI スキームを使用してHTMLコード内に画像を埋め込むかどうかを指定します。 |
| ImagesPath | エクスポートされた HTML 内の画像フォルダを指定します。 |
| UseSaveFileRelativePath | 画像ファイルパスを HTML ファイルパスに対して相対パスとして使用するかどうかを指定します。 |
| HasHeadersFooters | エクスポートされた HTML にヘッダーとフッターを含めるかどうかを指定します。 |
| IsTextInputFormFieldAsText | テキスト入力フォームフィールドを HTML でテキストとしてエクスポートするかどうかを指定します。 |
| IsExportDocumentStyles | 文書スタイルを HTML の <head> にエクスポートするかどうかを指定します。 |
以下に、詳細な手順を示します。
from spire.doc import *
# Documentクラスのインスタンスを作成します
document = Document()
# Word文書を読み込みます
document.LoadFromFile("Sample.docx")
# CSSスタイルを埋め込みます
document.HtmlExportOptions.CssStyleSheetFileName = "Sample.css"
document.HtmlExportOptions.CssStyleSheetType = CssStyleSheetType.External
# 画像を埋め込むかどうかを設定します
document.HtmlExportOptions.ImageEmbedded = False
document.HtmlExportOptions.ImagesPath = "Images/"
# フォームフィールドをプレーンテキストとしてエクスポートするかどうかを設定します
document.HtmlExportOptions.IsTextInputFormFieldAsText = True
# 文書をHTMLファイルとして保存します
document.SaveToFile("ToHtmlExportOption.html", FileFormat.Html)
document.Close()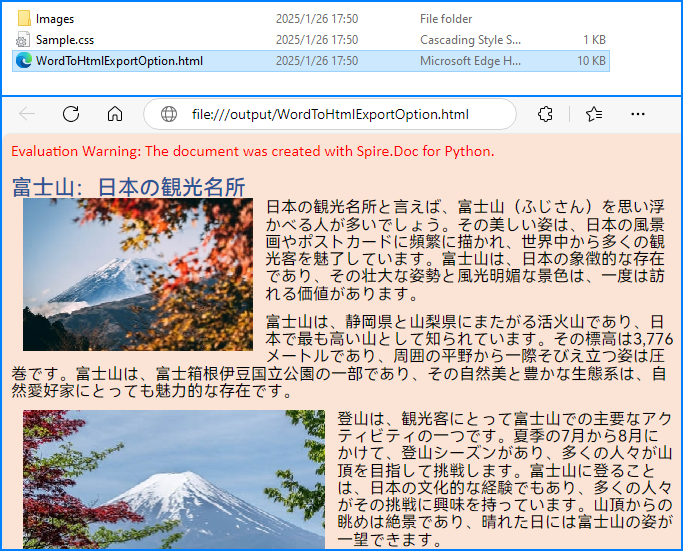
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
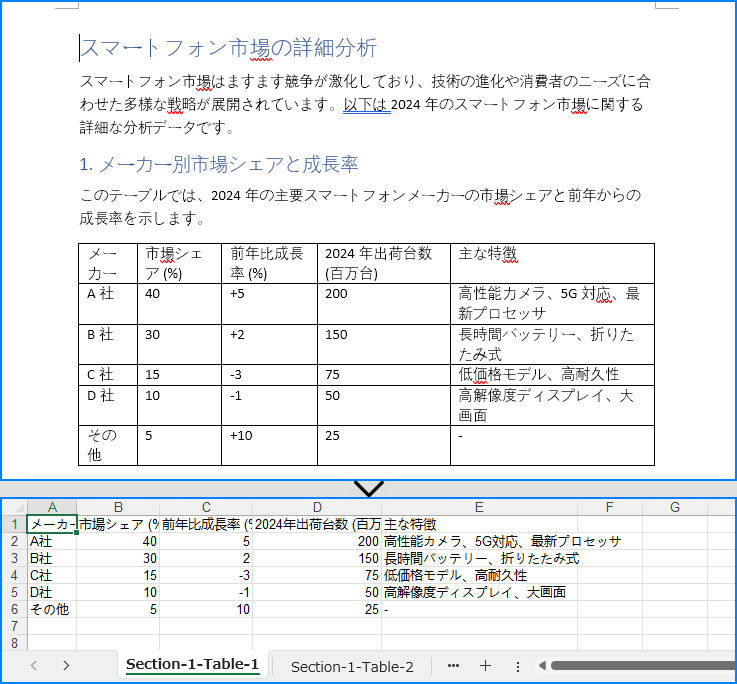
Word 文書には重要なデータを含む表がよくあります。この表からデータを抽出することは、さらなる分析やレポート作成、コンテンツの再作成など、さまざまなシナリオで使用できます。Java を使用して Word 文書から表を自動的に抽出することで、開発者は効率的にこの構造化データにアクセスし、データベースやスプレッドシートなどに適した形式に変換することができ、このデータをさまざまなシナリオで活用できます。本記事では、Spire.Doc for Java を使用して、Java プロジェクトで Word 文書から表を抽出する方法を紹介します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.1.3</version>
</dependency>
</dependencies>Spire.Doc for Java を使用すると、開発者は Section.getTables() メソッドを利用して Word 文書から表を抽出できます。表のデータは、行とセルを繰り返し処理することでアクセスできます。表抽出の手順は以下の通りです:
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractWordTable {
public static void main(String[] args) {
// Documentオブジェクトを作成します
Document doc = new Document();
try {
// Wordドキュメントを読み込みます
doc.loadFromFile("Sample.docx");
// ドキュメント内のセクションを繰り返し処理します
for (int i = 0; i < doc.getSections().getCount(); i++) {
// セクションを取得します
Section section = doc.getSections().get(i);
// セクション内のテーブルを繰り返し処理します
for (int j = 0; j < section.getTables().getCount(); j++) {
// テーブルを取得します
Table table = section.getTables().get(j);
// テーブルの内容を収集します
StringBuilder tableText = new StringBuilder();
for (int k = 0; k < table.getRows().getCount(); k++) {
// 行を取得します
TableRow row = table.getRows().get(k);
// 行内のセルを繰り返し処理します
StringBuilder rowText = new StringBuilder();
for (int l = 0; l < row.getCells().getCount(); l++) {
// セルを取得します
TableCell cell = row.getCells().get(l);
// セル内の段落を繰り返し処理してテキストを取得します
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
cellText += paragraph.getText() + " ";
}
if (l < row.getCells().getCount() - 1) {
rowText.append(cellText).append("\t");
} else {
rowText.append(cellText).append("\n");
}
}
tableText.append(rowText);
}
// try-with-resourcesを使用して、テーブルの内容をファイルに書き込みます
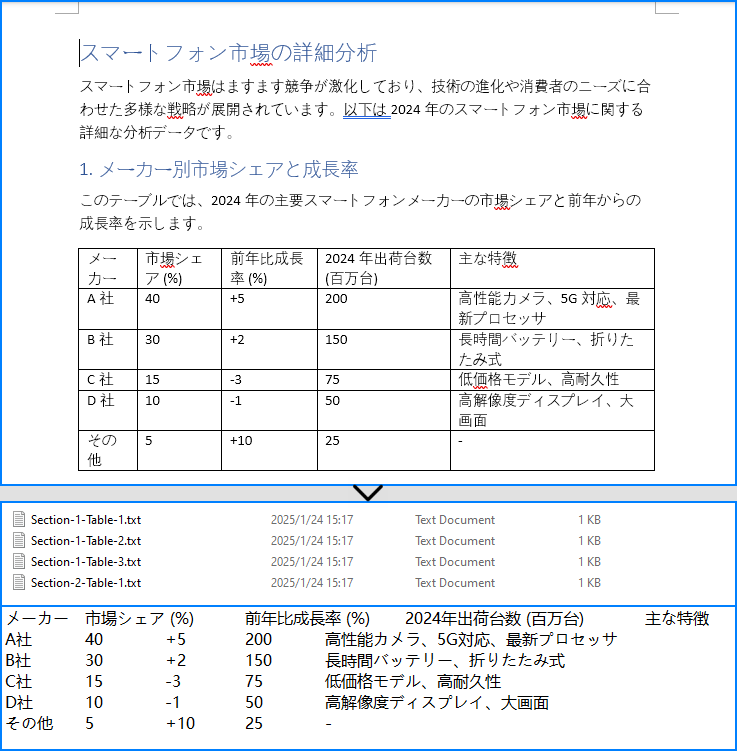
try (FileWriter writer = new FileWriter("output/Tables/Section-" + (i + 1) + "-Table-" + (j + 1) + ".txt")) {
writer.write(tableText.toString());
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
開発者は Spire.Doc for Java と Spire.XLS for Java を組み合わせて、Word 文書から表データを抽出し、Excel ワークシートに書き込むことができます。まず、Spire.XLS for Java をダウンロードするか、以下の Maven 設定を追加します:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>15.1.3</version>
</dependency>
</dependencies>Word 文書から Excel ワークブックに表を抽出する詳細な手順は以下の通りです:
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractWordTableToExcel {
public static void main(String[] args) {
// Documentオブジェクトを作成します
Document doc = new Document();
// Workbookオブジェクトを作成します
Workbook workbook = new Workbook();
// デフォルトのワークシートを削除します
workbook.getWorksheets().clear();
try {
// Wordドキュメントを読み込みます
doc.loadFromFile("Sample.docx");
// ドキュメント内のセクションを繰り返し処理します
for (int i = 0; i < doc.getSections().getCount(); i++) {
// セクションを取得します
Section section = doc.getSections().get(i);
// セクション内のテーブルを繰り返し処理します
for (int j = 0; j < section.getTables().getCount(); j++) {
// テーブルを取得します
Table table = section.getTables().get(j);
// 各テーブル用のワークシートを作成します
Worksheet sheet = workbook.getWorksheets().add("Section-" + (i + 1) + "-Table-" + (j + 1));
for (int k = 0; k < table.getRows().getCount(); k++) {
// 行を取得します
TableRow row = table.getRows().get(k);
for (int l = 0; l < row.getCells().getCount(); l++) {
// セルを取得します
TableCell cell = row.getCells().get(l);
// セル内の段落を繰り返し処理してテキストを取得します
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
if (m > 0 && m < cell.getParagraphs().getCount() - 1) {
cellText += paragraph.getText() + "\n";
} else {
cellText += paragraph.getText();
}
// セルのテキストを対応するワークシートのセルに書き込みます
sheet.getRange().get(k + 1, l + 1).setValue(cellText);
}
// 列の自動調整を行います
sheet.autoFitColumn(l + 1);
}
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
// Excelファイルとして保存します
workbook.saveToFile("output/WordTableToExcel.xlsx", FileFormat.Version2016);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
テキストファイルは、書式やスタイルが適用されていないプレーンテキストのみを含む一般的なファイル形式です。もしテキストファイルに書式を適用したり、画像やグラフ、表、その他のメディア要素を追加したい場合は、Word ファイルに変換することをおすすめします。
逆に、Word 文書の内容を効率的に抽出したり、ファイルサイズを減らしたい場合は、テキスト形式に変換する方法が役立ちます。本記事では、Spire.Doc for Python を使用して、テキストファイルを Word 形式に変換する方法と、Word ファイルをテキスト形式に変換する方法を解説します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocTXT から Word ドキュメントへの変換は、数行のコードで簡単に実現できます。以下は詳細な手順です。
from spire.doc import *
# ドキュメントオブジェクトを作成
document = Document()
# TXTファイルを読み込む
document.LoadFromFile("Sample.txt")
# TXTファイルをWord形式で保存
document.SaveToFile("output/テキストをWordに変換.docx", FileFormat.Docx2016)
document.Close()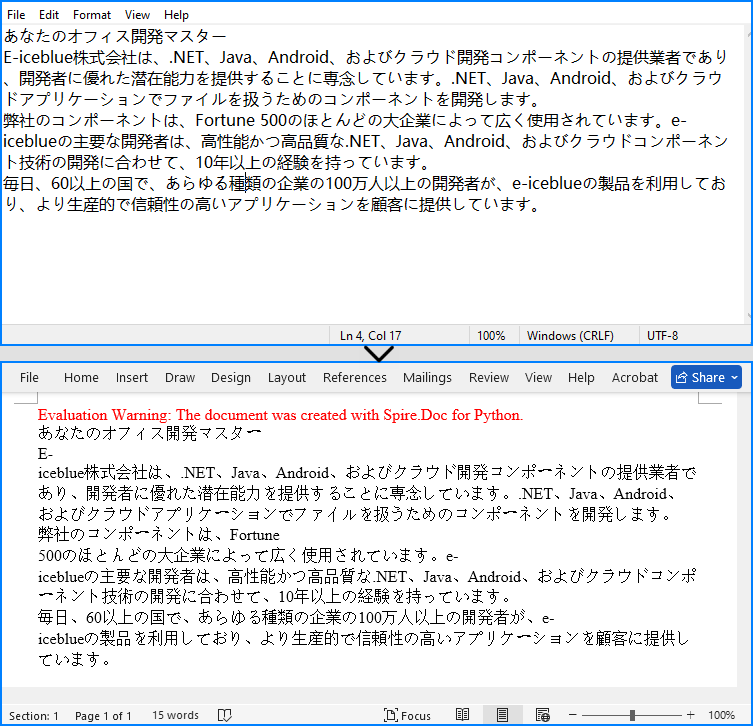
Spire.Doc for Python が提供する Document.SaveToFile(string fileName, FileFormat.Txt) メソッドを使用すると、Word ファイルをテキスト形式にエクスポートできます。以下は詳細な手順です。
from spire.doc import *
# ドキュメントオブジェクトを作成
document = Document()
# ディスクからWordファイルを読み込む
document.LoadFromFile("Sample.docx")
# Wordファイルをtxt形式で保存
document.SaveToFile("output/Wordをテキストに変換.txt", FileFormat.Txt)
document.Close()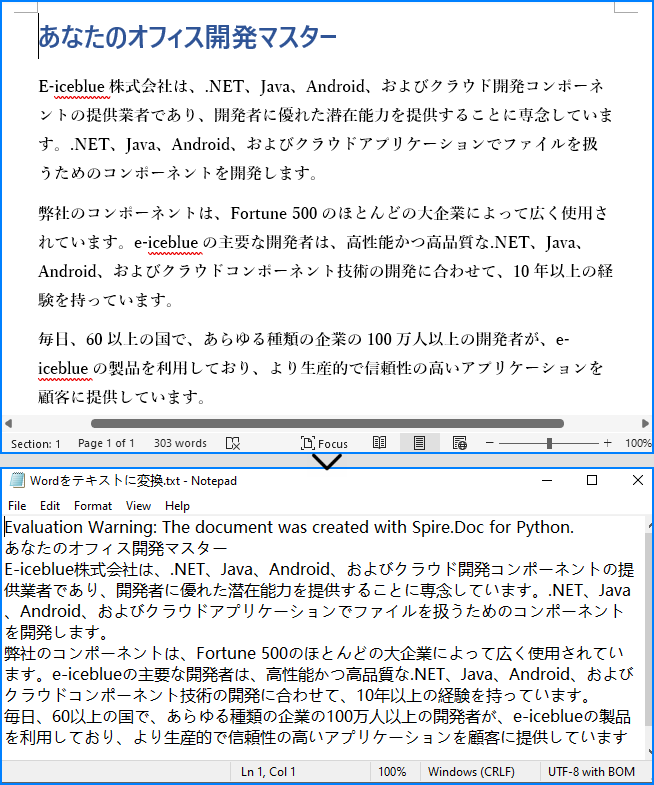
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書を画像に変換することは、フォーマットの問題やデバイス間の互換性を気にせずにコンテンツを共有または提示したい場合に便利で実用的なオプションです。Word 文書を画像に変換することで、テキスト、画像、フォーマットがそのまま保持されるため、ソーシャルメディア、ウェブサイト、またはメールでの文書共有に最適な方法となります。本記事では、Spire.Doc for Python を使用して Python で Word ドキュメントを PNG、JPEG、または SVG 形式に変換する方法について説明します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python には、特定のページをビットマップ画像に変換するための Document.SaveImageToStream() メソッドがあります。その後、このビットマップ画像を PNG、JPEG、または BMP などの一般的な画像フォーマットに保存できます。詳細な手順は以下の通りです。
from spire.doc import *
# ドキュメントオブジェクトを作成
document = Document()
# Wordファイルを読み込む
document.LoadFromFile("Sample.docx")
# ドキュメント内のページをループ処理
for i in range(document.GetPageCount()):
# 特定のページをビットマップ画像に変換
imageStream = document.SaveImageToStreams(i, ImageType.Bitmap)
# ビットマップをPNGファイルとして保存
with open('Output/Images/Image-{0}.png'.format(i),'wb') as imageFile:
imageFile.write(imageStream.ToArray())
document.Close()
Word ドキュメントを複数の SVG ファイルに変換するには、Document.SaveToFile() メソッドを使用するだけです。手順は以下の通りです。
from spire.doc import *
from spire.doc.common import *
# ドキュメントオブジェクトを作成
document = Document()
# Wordファイルを読み込む
document.LoadFromFile("Sample.docx")
# SVGファイルとして保存
document.SaveToFile("output/SVGs/WordをSVGに変換.svg", FileFormat.SVG)
document.Close()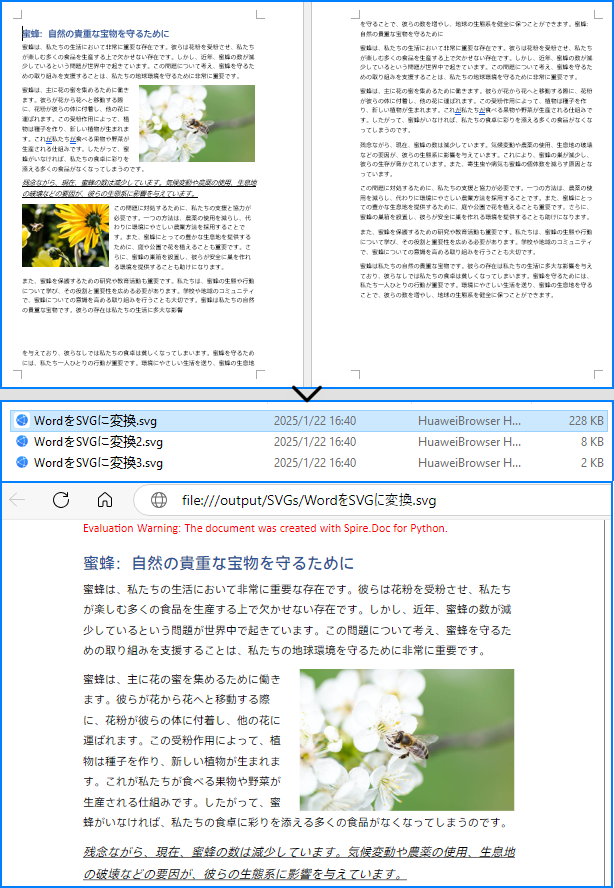
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
デジタルドキュメントは、個人および業務において重要な役割を果たしています。その中でよく使用される形式の 1 つが Microsoft Word です。これは、テキストドキュメントの作成や編集に使われます。しかし、Word ファイルをより普遍的に利用可能な形式、例えば PDF に変換する必要が生じることがあります。PDF は、フォーマットの維持、互換性の確保、異なるデバイスやオペレーティングシステム間での文書の完全性の保持といった利点を提供します。この記事では、Spire.Doc for Python を使って Word から PDF に変換する方法を説明します。
この操作には、Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.DocSpire.Doc for Python には、Document.SaveToFile(string fileName, FileFormat fileFormat) メソッドが用意されており、これを使用して Word を PDF、XPS、HTML、RTF などの形式で保存できます。追加設定をせずに Word 文書を通常の PDF として保存したい場合は、以下の手順に従ってください。
from spire.doc import *
from spire.doc.common import *
# Word文書を作成
document = Document()
# docまたはdocxファイルを読み込む
document.LoadFromFile("Sample.docx")
# 文書をPDFとして保存
document.SaveToFile("output/WordからPDFへの変換.pdf", FileFormat.PDF)
document.Close()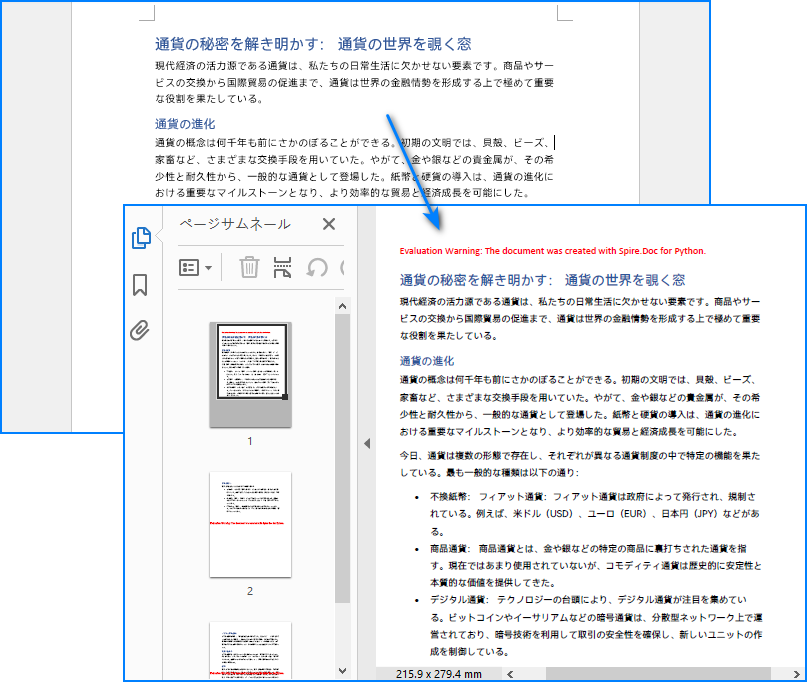
Word をパスワード保護付きPDFに変換するには、Document.SaveToFile(string fileName, ToPdfParameterList paramList) メソッドを使用します。この ToPdfParameterList パラメータにより、Word 文書を PDF に変換する際の設定を制御できます。以下の手順で実行します。
from spire.doc import *
from spire.doc.common import *
# Documentオブジェクトを作成
document = Document()
# Wordファイルを読み込む
document.LoadFromFile("Sample.docx")
# ToPdfParameterListオブジェクトを作成
parameter = ToPdfParameterList()
# オープンパスワードと許可パスワードを指定
openPsd = "abc-123"
permissionPsd = "permission"
# 生成されるPDFをオープンパスワードと許可パスワードで保護
parameter.PdfSecurity.Encrypt(openPsd, permissionPsd, PdfPermissionsFlags.Default, PdfEncryptionKeySize.Key128Bit)
# Word文書をPDFとして保存
document.SaveToFile("output/パスワードを付けてWordをPDFに変換.pdf", parameter)
document.Close()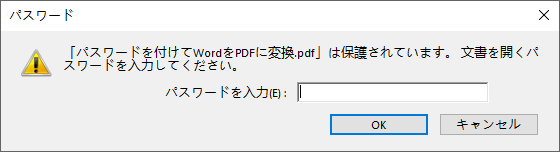
ドキュメントにブックマークを追加すると、可読性が向上します。Word から PDF を作成する際に、既存のブックマークを保持したり、見出しに基づいて新しいブックマークを作成したりすることが可能です。以下の手順で、ブックマーク付きの PDF に変換します。
from spire.doc import *
from spire.doc.common import *
# Documentオブジェクトを作成
document = Document()
# Wordファイルを読み込む
document.LoadFromFile("Sample.docx")
# ToPdfParameterListオブジェクトを作成
parames = ToPdfParameterList()
# Wordの見出しを使ってブックマークを作成
#parames.CreateWordBookmarksUsingHeadings = True
# Wordの既存のブックマークを使ってPDFにブックマークを作成
parames.CreateWordBookmarks = True
# 文書をPDFとして保存
document.SaveToFile("output/ブックマーク付きWordをPDFに変換.pdf", FileFormat.PDF)
document.Close()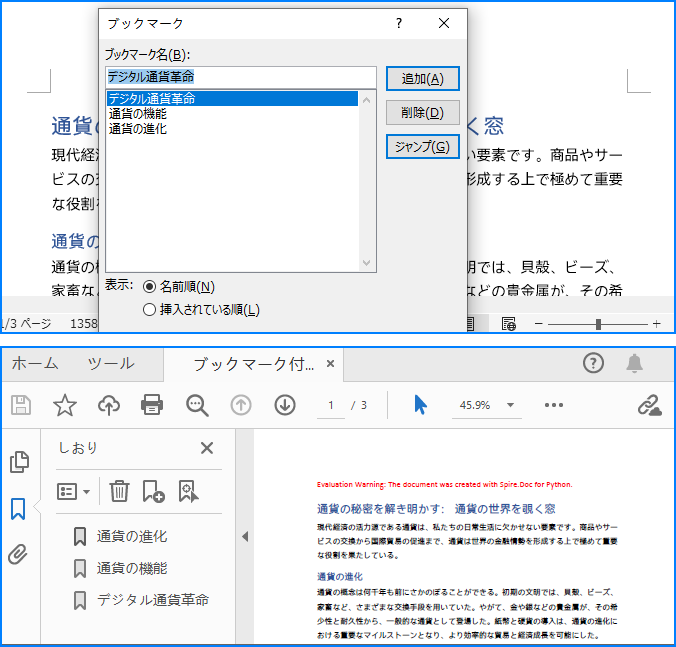
PDF 文書がどのデバイスでも一貫して表示されるようにするためには、生成された PDF 文書にフォントを埋め込む必要があります。以下は、Word 文書で使用されているフォントを PDF に埋め込む手順です。
from spire.doc import *
from spire.doc.common import *
# Documentオブジェクトを作成
document = Document()
# Wordファイルを読み込む
document.LoadFromFile("Sample.docx")
# ToPdfParameterListオブジェクトを作成
parameter = ToPdfParameterList()
# PDFにフォントを埋め込む
parameter.IsEmbeddedAllFonts = True
# Word文書をPDFとして保存
document.SaveToFile("output/フォントを埋め込んだWordからPDFへの変換.pdf", parameter)
document.Close()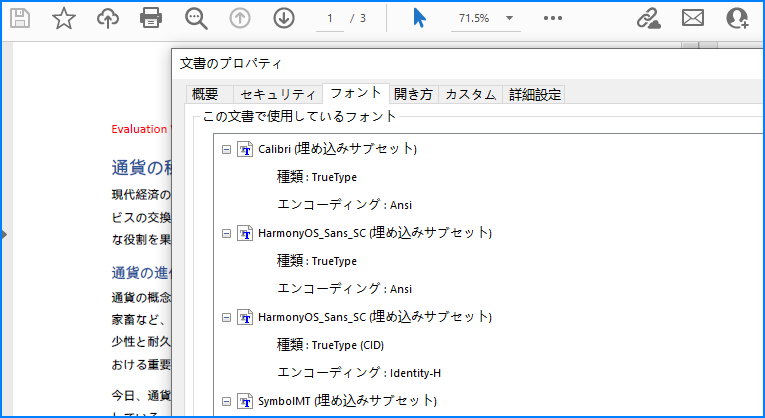
Word 文書を PDF に変換する際、多くの高品質画像が含まれている場合は、生成されるファイルのサイズが重要です。変換プロセス中に画像の品質を圧縮することができます。以下の手順に従ってください。
from spire.doc import *
# Documentオブジェクトを作成
document = Document()
# Wordファイルを読み込む
document.LoadFromFile("Sample.docx")
# 画像を元の品質の40%に圧縮
document.JPEGQuality = 40
# 元の画像品質を保持
# document.JPEGQuality = 100
# Word文書をPDFとして保存
document.SaveToFile("output/画質の設定.pdf", FileFormat.PDF)
document.Close()結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
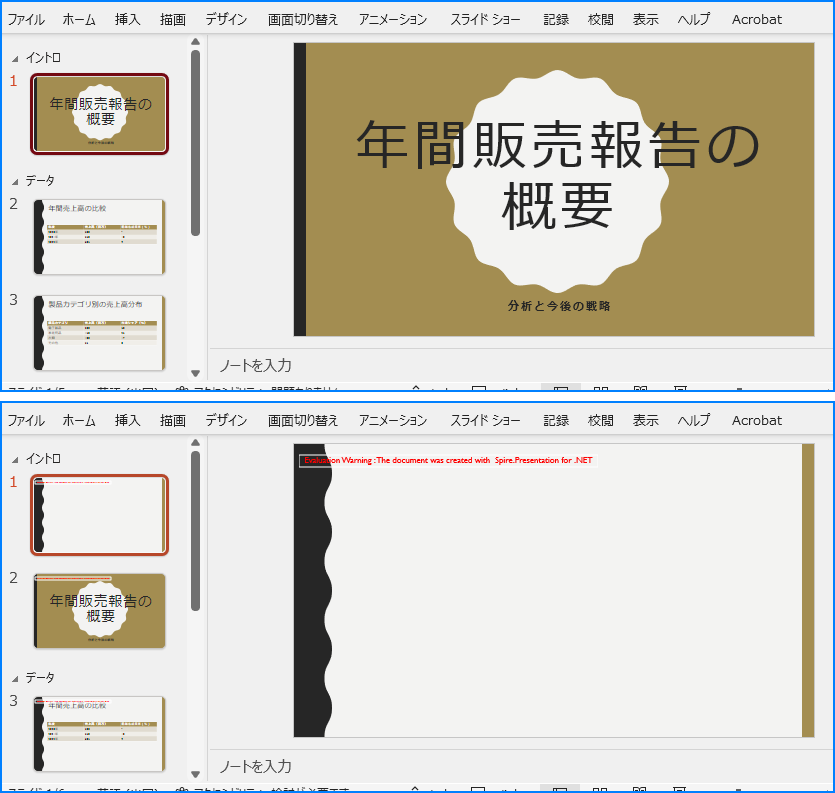
PowerPoint のセクションは、関連するスライドをグループ化することで、トピックや章、その他の論理構造に基づいてプレゼンテーションをセグメント化するのに役立ちます。大規模で複数のセクションを含むプレゼンテーションを扱う場合、スライド操作(挿入、取得、並べ替え、削除)を自動化することで生産性を大幅に向上させることができます。この記事では、C# で Spire.Presentation for .NET を使用して、PowerPoint セクション内でスライドを挿入、取得、並べ替え、削除する方法を説明します。
まず、Spire.Presentation for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.Presentationスライドを挿入する操作は、セクションに新しいコンテンツを追加する必要がある場合に頻繁に行われます。Spire.Presentation for .NET を使用すると、Section.Insert() メソッドでスライドをセクションに挿入できます。詳細な手順は以下の通りです。
using Spire.Presentation;
namespace InsertSlidesInSection
{
internal class Program
{
static void Main(string[] args)
{
// Presentation クラスのインスタンスを作成します
using (Presentation presentation = new Presentation())
{
// PowerPoint プレゼンテーションを読み込みます
presentation.LoadFromFile("Sample.pptx");
// 最初のセクションにアクセスします
Section firstSection = presentation.SectionList[0];
// プレゼンテーションに新しいスライドを追加し、そのセクションの先頭に挿入します
ISlide slide = presentation.Slides.Append();
firstSection.Insert(0, slide);
// プレゼンテーションから追加したスライドを削除します
presentation.Slides.Remove(slide);
// 修正されたプレゼンテーションを保存します
presentation.SaveToFile("セクションにスライドを追加.pptx", FileFormat.Auto);
}
}
}
}
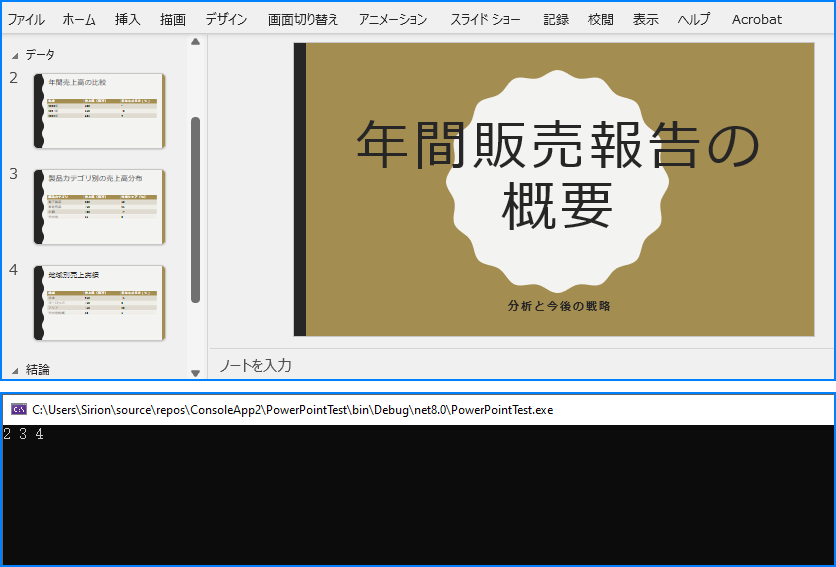
特定のセクションからスライドを抽出することで、スライドの並べ替えや特定のフォーマット適用など、対象を絞った操作が可能になります。Spire.Presentation for .NET の Section.GetSlides() メソッドを使用すると、指定したセクション内のすべてのスライドを簡単に取得できます。詳細な手順は以下の通りです。
using Spire.Presentation;
namespace RetrieveSlidesInSection
{
internal class Program
{
static void Main(string[] args)
{
// Presentation クラスのインスタンスを作成します
using (Presentation presentation = new Presentation())
{
// PowerPoint プレゼンテーションを読み込みます
presentation.LoadFromFile("Sample.pptx");
// 3 番目のセクション内のスライドを取得します
Section section = presentation.SectionList[1];
ISlide[] slides = section.GetSlides();
// セクション内の各スライドのスライド番号を出力します
foreach (ISlide slide in slides)
{
Console.Write(slide.SlideNumber + " ");
}
Console.ReadKey();
}
}
}
}
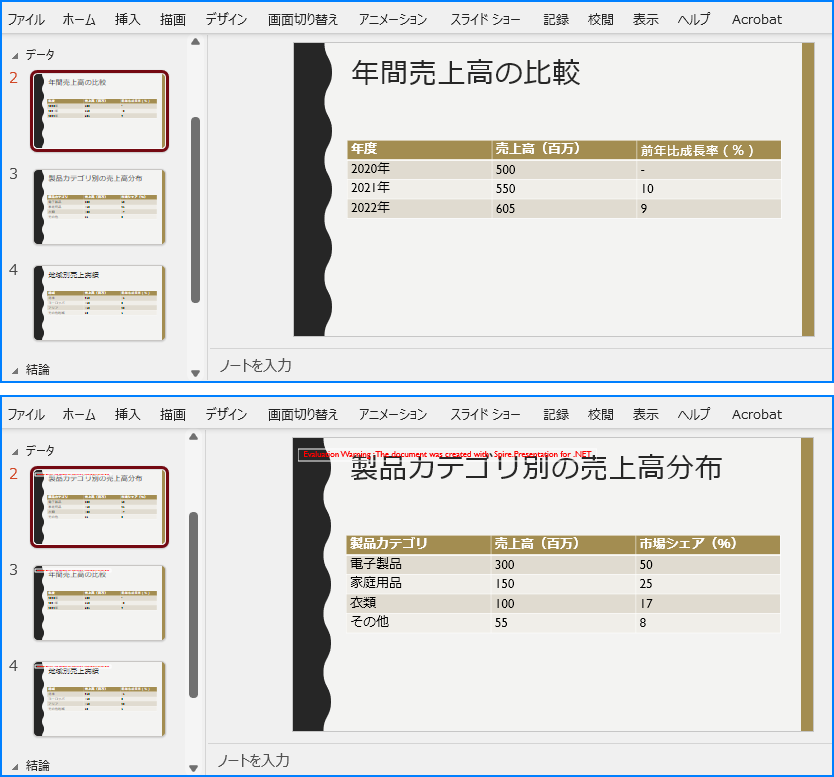
スライドを並べ替えることは、関連するコンテンツが論理的な順序で続くようにするために重要です。Spire.Presentation for .NET では、Section.Move() メソッドを使用して、セクション内のスライドを別の位置に移動できます。詳細な手順は以下の通りです。
using Spire.Presentation;
namespace ReorderSlidesInSection
{
internal class Program
{
static void Main(string[] args)
{
// Presentation クラスのインスタンスを作成します
using (Presentation presentation = new Presentation())
{
// PowerPoint プレゼンテーションを読み込みます
presentation.LoadFromFile("Sample.pptx");
// 3 番目のセクションにアクセスします
Section section = presentation.SectionList[1];
// セクション内のスライドを取得します
ISlide[] slides = section.GetSlides();
// セクション内の最初のスライドを指定した位置に移動します
section.Move(2, slides[0]);
// 修正されたプレゼンテーションを保存します
presentation.SaveToFile("セクションのスライドの並べ替え.pptx", FileFormat.Pptx2016);
}
}
}
}
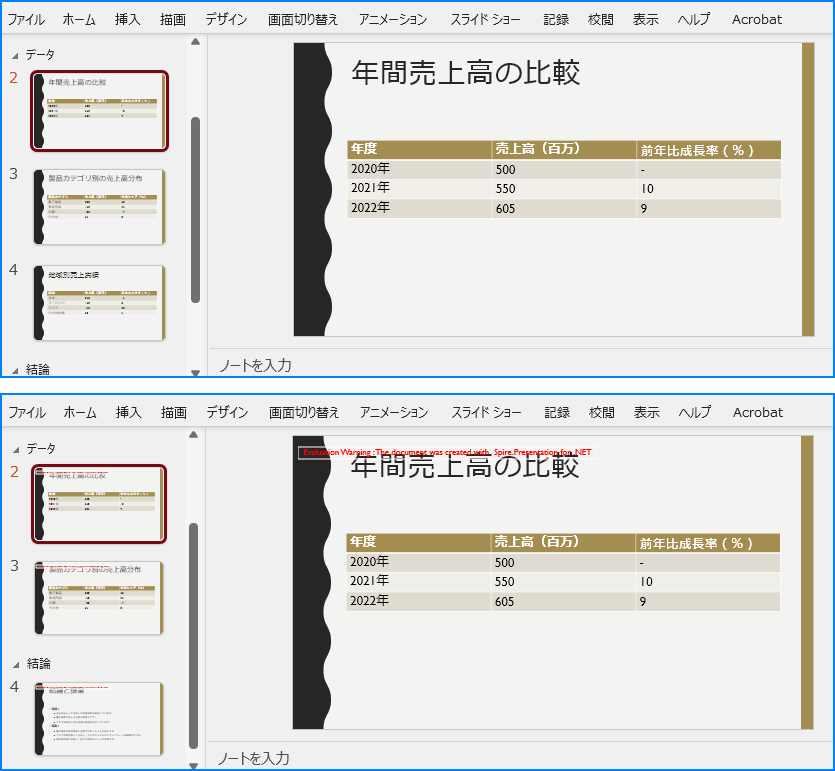
セクションからスライドを削除することで、プレゼンテーションを簡素化でき、古くなったスライドや関連性のないスライドを除外するのに役立ちます。Spire.Presentation for .NET の Section.RemoveAt() または Section.RemoveRange() メソッドを使用すると、個々のスライドやスライドの範囲を簡単に削除できます。詳細な手順は以下の通りです。
using Spire.Presentation;
namespace RemoveSlidesInSection
{
internal class Program
{
static void Main(string[] args)
{
// Presentation クラスのインスタンスを作成します
using (Presentation presentation = new Presentation())
{
// PowerPoint プレゼンテーションを読み込みます
presentation.LoadFromFile("Sample.pptx");
// 3 番目のセクションにアクセスします
Section section = presentation.SectionList[1];
// セクションから最初のスライドを削除します
section.RemoveAt(2);
// または、セクションから複数のスライドを範囲指定で削除します
//section.RemoveRange(0, 2);
// 修正されたプレゼンテーションを保存します
presentation.SaveToFile("セクション内のスライドの削除.pptx", FileFormat.Pptx2016);
}
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
C# で Excel を操作する際、行、列、セルをコピーするのは一見簡単そうに思えますが、元の書式を維持するとなると一筋縄ではいかないことがあります。レポート用のデータ整理やプレゼンテーション作成、またはスプレッドシートを見栄えよく整える場合でも、元の見た目を維持することは重要です。本記事では、Spire.XLS for .NET を使用して、C# で Excel の行、列、セルを元の書式を保持したままコピーする方法を解説します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
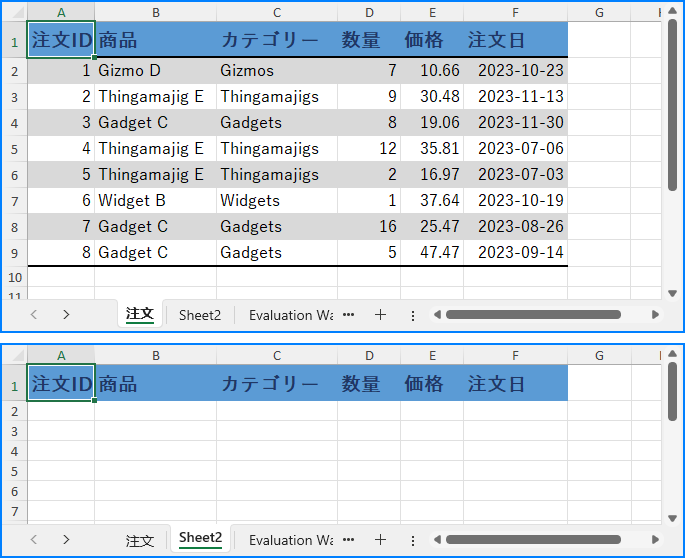
PM> Install-Package Spire.XLSExcel で行をコピーする際に書式を維持するには、Worksheet.CopyRow(CellRange sourceRow, Worksheet destSheet, int destRowIndex, CopyRangeOptions copyOptions) メソッドを使用すると効率的です。このメソッドを使用すると、同じワークシート内または異なるワークシート間で行を正確にコピーできます。また、CopyRangeOptions パラメーターを使用して、すべての書式、条件付き書式、データ検証、スタイル、または数式の値のみをコピーするなど、コピー動作を制御することも可能です。
以下は、Spire.XLS を使用して異なるワークシート間で書式付きで行をコピーする手順です。
using Spire.Xls;
namespace CopyRows
{
internal class Program
{
static void Main(string[] args)
{
// Workbookオブジェクトを作成します
Workbook workbook = new Workbook();
// Excelファイルを読み込みます
workbook.LoadFromFile("Sample.xlsx");
// ソースワークシートを取得します
Worksheet sheet1 = workbook.Worksheets[0];
// 新しいワークシートを作成します
Worksheet sheet2 = workbook.Worksheets.Add("Sheet2");
// コピーしたい行を取得します
CellRange row = sheet1.Rows[0];
// ソースワークシートの行を宛先ワークシートの1行目にコピーします
sheet1.CopyRow(row, sheet2, 1, CopyRangeOptions.All);
int columns = sheet1.Columns.Length;
// ソース行内のセルの列幅を宛先行内の対応するセルにコピーします
for (int i = 0; i < columns; i++)
{
double columnWidth = row.Columns[i].ColumnWidth;
sheet2.Rows[0].Columns[i].ColumnWidth = columnWidth;
}
// ワークブックをファイルに保存します
workbook.SaveToFile("output/行のコピー.xlsx");
workbook.Dispose();
}
}
}
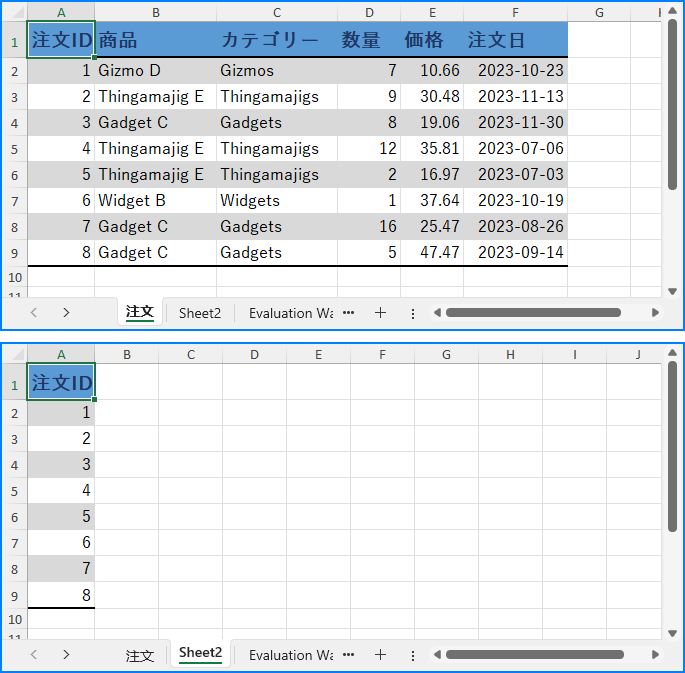
同様に、列を書式付きでコピーするには、Worksheet.CopyColumn(CellRange sourceColumn, Worksheet destSheet, int destColIndex, CopyRangeOptions copyOptions) メソッドを使用できます。詳細な手順は以下の通りです。
using Spire.Xls;
namespace CopyColumns
{
internal class Program
{
static void Main(string[] args)
{
// Workbookオブジェクトを作成します
Workbook workbook = new Workbook();
// Excelファイルを読み込みます
workbook.LoadFromFile("Sample.xlsx");
// ソースワークシートを取得します
Worksheet sheet1 = workbook.Worksheets[0];
// 宛先ワークシートを取得します
Worksheet sheet2 = workbook.Worksheets.Add("Sheet2");
// コピーしたい列を取得します
CellRange column = sheet1.Columns[0];
// ソースワークシートの列を宛先ワークシートの1列目にコピーします
sheet1.CopyColumn(column, sheet2, 1, CopyRangeOptions.All);
int rows = column.Rows.Length;
// ソース列内のセルの行高さを宛先列内の対応するセルにコピーします
for (int i = 0; i < rows; i++)
{
double rowHeight = column.Rows[i].RowHeight;
sheet2.Columns[0].Rows[i].RowHeight = rowHeight;
}
// ワークブックをファイルに保存します
workbook.SaveToFile("output/列のコピー.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
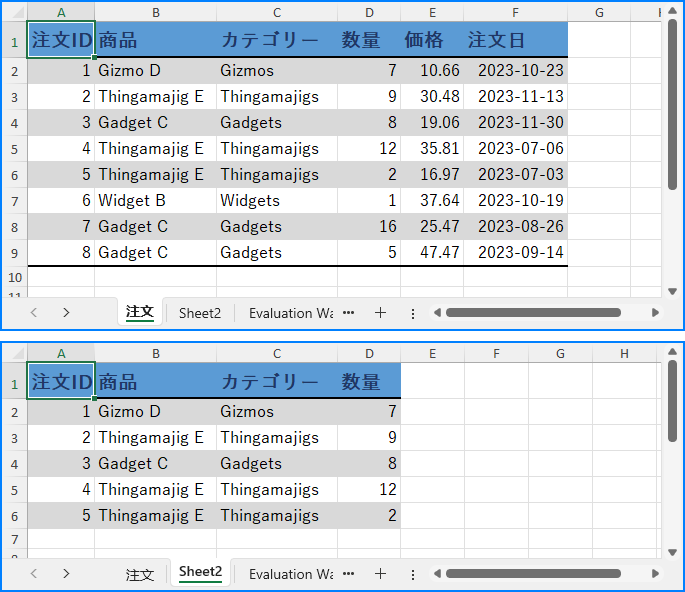
行や列のコピーに加え、Spire.XLS for .NETを使用すると、CellRange.Copy(CellRange destRange, CopyRangeOptions copyOptions) メソッドを利用してセル範囲を書式付きでコピーすることも可能です。手順は以下の通りです。
using Spire.Xls;
namespace CopyCells
{
internal class Program
{
static void Main(string[] args)
{
// Workbookオブジェクトを作成します
Workbook workbook = new Workbook();
// Excelファイルを読み込みます
workbook.LoadFromFile("Sample.xlsx");
// ソースワークシートを取得します
Worksheet sheet1 = workbook.Worksheets[0];
// 宛先ワークシートを取得します
Worksheet sheet2 = workbook.Worksheets.Add("Sheet2");
// ソースセル範囲を取得します
CellRange range1 = sheet1.Range["A1:D6"];
// 宛先セル範囲を取得します
CellRange range2 = sheet2.Range["A1:D6"];
// ソースワークシートのセル範囲を宛先ワークシートのセル範囲にコピーします
range1.Copy(range2, CopyRangeOptions.All);
// ソースセル範囲の行高さと列幅を宛先セル範囲にコピーします
for (int i = 0; i < range1.Rows.Length; i++)
{
CellRange row = range1.Rows[i];
for (int j = 0; j < row.Columns.Length; j++)
{
CellRange column = row.Columns[j];
range2.Rows[i].Columns[j].ColumnWidth = column.ColumnWidth;
range2.Rows[i].RowHeight = row.RowHeight;
}
}
// ワークブックをファイルに保存します
workbook.SaveToFile("output/セルのコピー.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
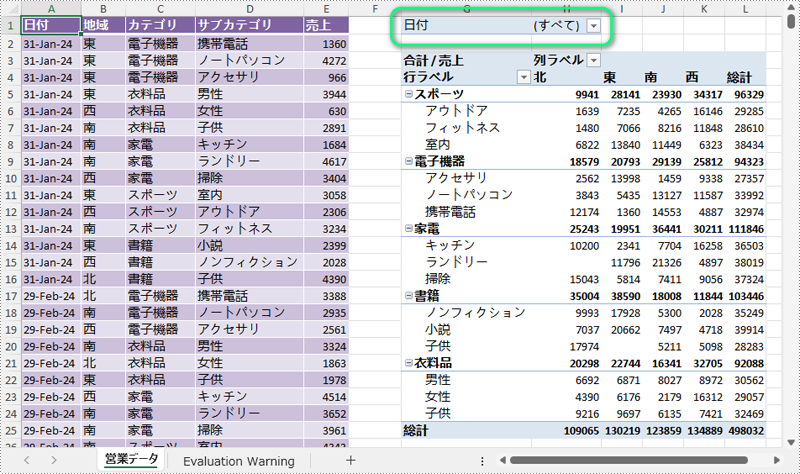
ピボットテーブルにフィルターを追加することで、ユーザーは特定の基準に基づいて表示するデータを絞り込むことができます。フィルターを使用することで、分析に最も関連性のあるデータのサブセットに焦点を当て、効率的なデータ探索が可能になります。本記事では、Spire.XLS for .NET を使用して、C# で Excel のピボットテーブルにフィルターを追加する方法を示します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSSpire.XLS for .NET では、XlsPivotTable.ReportFilters.Add() メソッドを使用して、ピボットテーブルにレポートフィルターを追加できます。詳細な手順は以下の通りです。
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace AddReportFilter
{
internal class Program
{
static void Main(string[] args)
{
// Workbookクラスのオブジェクトを作成
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
// 最初のワークシートを取得
Worksheet sheet = workbook.Worksheets[0];
// 最初のピボットテーブルを取得
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
// レポートフィルターを作成
PivotReportFilter reportFilter = new PivotReportFilter("日付", true);
// レポートフィルターをピボットテーブルに追加
pt.ReportFilters.Add(reportFilter);
// 結果のファイルを保存
workbook.SaveToFile("レポートフィルター.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
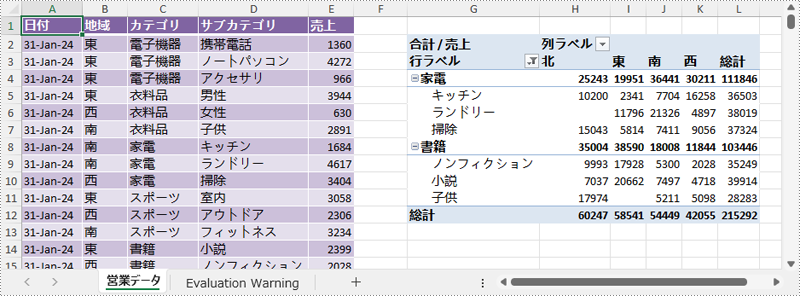
XlsPivotTable.RowFields[index].AddValueFilter() または XlsPivotTable.RowFields[index].AddLabelFilter() メソッドを使用して、ピボットテーブルの特定の行フィールドに値フィルターまたはラベルフィルターを追加できます。詳細な手順は以下の通りです。
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace AddRowFilter
{
internal class Program
{
static void Main(string[] args)
{
// Workbookクラスのオブジェクトを作成
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
// 最初のワークシートを取得
Worksheet sheet = workbook.Worksheets[0];
// 最初のピボットテーブルを取得
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
// ピボットテーブルの最初の行フィールドに値フィルターを追加
pt.RowFields[0].AddValueFilter(PivotValueFilterType.GreaterThan, pt.DataFields[0], 100000, null);
// または、ピボットテーブルの最初の行フィールドにラベルフィルターを追加
// pt.RowFields[0].AddLabelFilter(PivotLabelFilterType.Equal, "電子機器", null);
// ピボットテーブルのデータを計算
pt.CalculateData();
// 結果のファイルを保存
workbook.SaveToFile("行フィルター.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
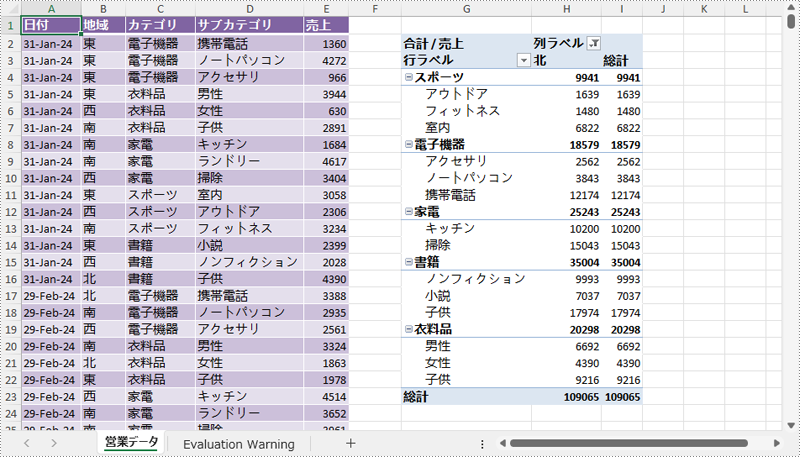
XlsPivotTable.ColumnFields[index].AddValueFilter() または XlsPivotTable.ColumnFields[index].AddLabelFilter() メソッドを使用して、ピボットテーブルの特定の列フィールドに値フィルターまたはラベルフィルターを追加できます。詳細な手順は以下の通りです。
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace AddColumnFilter
{
internal class Program
{
static void Main(string[] args)
{
// Workbookクラスのオブジェクトを作成
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
// 最初のワークシートを取得
Worksheet sheet = workbook.Worksheets[0];
// 最初のピボットテーブルを取得
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
// ピボットテーブルの最初の列フィールドにラベルフィルターを追加
pt.ColumnFields[0].AddLabelFilter(PivotLabelFilterType.Equal, "北", null);
// または、ピボットテーブルの最初の列フィールドに値フィルターを追加
// pt.ColumnFields[0].AddValueFilter(PivotValueFilterType.Between, pt.DataFields[0], 5000, 10000);
// ピボットテーブルのデータを計算
pt.CalculateData();
// 結果のファイルを保存
workbook.SaveToFile("列フィルター.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
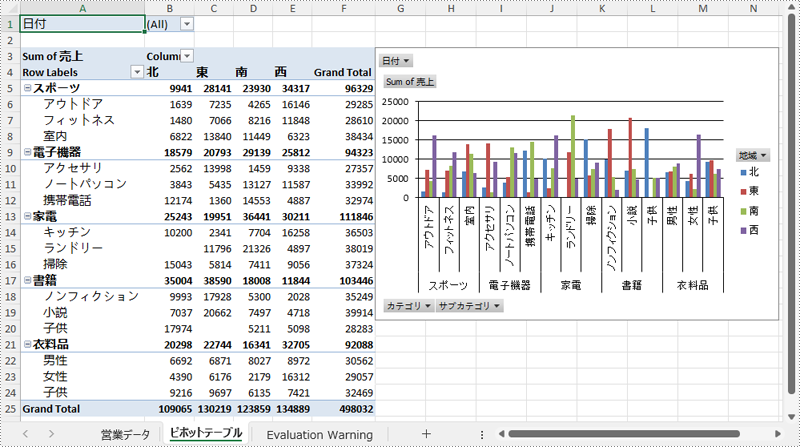
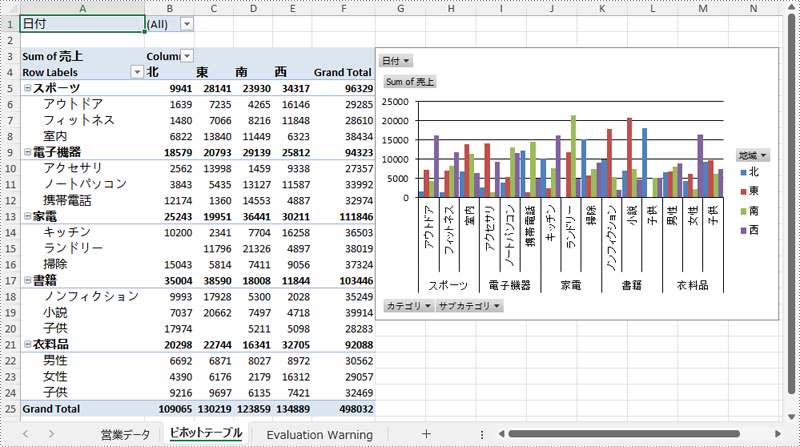
ピボットグラフは、ピボットテーブルを視覚的に表現したグラフです。ピボットテーブルはデータを要約し、分析のために操作することができますが、ピボットグラフはその要約データを視覚的に表現します。ピボットテーブルのデータが変更されると、ピボットグラフも簡単に更新できるため、レポート作成やデータ分析において欠かせないツールです。本記事では、C# で Spire.XLS for .NET を使用して Excel でピボットグラフを作成する方法を説明します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSSpire.XLS for .NET を使用すると、既存のピボットテーブルからピボットグラフを簡単に作成できます。Worksheet.Charts.Add(ExcelChartType pivotChartType, IPivotTable pivotTable) メソッドを使った手順は以下の通りです。
using Spire.Xls;
using Spire.Xls.Core;
namespace CreatePivotChart
{
internal class Program
{
static void Main(string[] args)
{
// Workbookオブジェクトを作成
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
// ワークシートを取得
Worksheet sheet = workbook.Worksheets[1];
// ワークシート内の最初のピボットテーブルを取得
IPivotTable pivotTable = sheet.PivotTables[0];
// ピボットテーブルに基づいて集合縦棒グラフを作成
Chart pivotChart = sheet.Charts.Add(ExcelChartType.ColumnClustered, pivotTable);
// グラフの位置を設定
pivotChart.TopRow = 3;
pivotChart.LeftColumn = 7;
pivotChart.RightColumn = 15;
pivotChart.BottomRow = 20;
// グラフのタイトルを空に設定
pivotChart.ChartTitle = "";
// 結果のファイルを保存
workbook.SaveToFile("Excelでピボットグラフを作成.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}
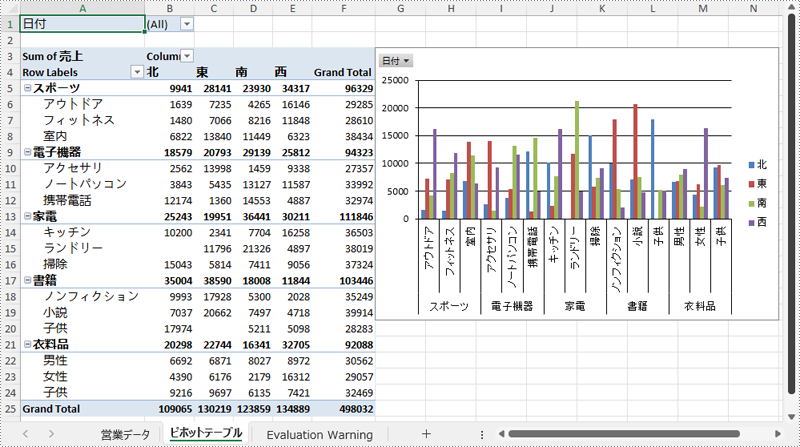
Spire.XLS for .NET を使用すれば、ピボットグラフの外観をカスタマイズするために、さまざまな種類のフィールドボタンを簡単に表示または非表示にできます。制御できるフィールドボタンは以下の通りです。
手順は以下の通りです。
using Spire.Xls;
using Spire.Xls.Core;
namespace ShowOrHideFieldButtons
{
internal class Program
{
static void Main(string[] args)
{
// Workbookオブジェクトを作成
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
// ワークシートを取得
Worksheet sheet = workbook.Worksheets[1];
// ワークシート内の最初のピボットテーブルを取得
IPivotTable pivotTable = sheet.PivotTables[0];
// ピボットテーブルに基づいて集合縦棒グラフを作成
Chart pivotChart = sheet.Charts.Add(ExcelChartType.ColumnClustered, pivotTable);
// グラフの位置を設定
pivotChart.TopRow = 3;
pivotChart.LeftColumn = 7;
pivotChart.RightColumn = 15;
pivotChart.BottomRow = 20;
// グラフのタイトルを空に設定
pivotChart.ChartTitle = "";
// 特定のフィールドボタンを非表示に設定
pivotChart.DisplayAxisFieldButtons = false; // 軸フィールドボタンを非表示
pivotChart.DisplayValueFieldButtons = false; // 値フィールドボタンを非表示
pivotChart.DisplayLegendFieldButtons = false; // 凡例フィールドボタンを非表示
// pivotChart.ShowReportFilterFieldButtons = false; // レポートフィルターフィールドボタンを非表示
// pivotChart.DisplayEntireFieldButtons = false; // すべてのフィールドボタンを非表示
// 結果のファイルを保存
workbook.SaveToFile("Excelのフィールドボタンを隠す.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}
Spire.XLS for .NET を使用してピボットテーブルから Excel でピボットグラフを作成する際、グラフの系列は自動生成されません。そのため、系列を手動で追加し、希望する形式にフォーマットする必要があります。手順は以下の通りです。
using Spire.Xls;
using Spire.Xls.Charts;
using Spire.Xls.Core;
namespace FormatChartSeries
{
internal class Program
{
static void Main(string[] args)
{
// Workbookオブジェクトを作成
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
// ワークシートを取得
Worksheet sheet = workbook.Worksheets[1];
// ワークシート内の最初のピボットテーブルを取得
IPivotTable pivotTable = sheet.PivotTables[0];
// ピボットテーブルに基づいて集合縦棒グラフを作成
Chart pivotChart = sheet.Charts.Add(ExcelChartType.ColumnClustered, pivotTable);
// グラフの位置を設定
pivotChart.TopRow = 3;
pivotChart.LeftColumn = 7;
pivotChart.RightColumn = 15;
pivotChart.BottomRow = 20;
// グラフのタイトルを空に設定
pivotChart.ChartTitle = "";
// グラフ系列を追加
ChartSerie series = pivotChart.Series.Add(ExcelChartType.ColumnClustered);
// 棒の幅を設定
series.GetCommonSerieFormat().GapWidth = 10;
// 棒の重なりを設定(以下の行を有効化することで設定可能)
// series.GetCommonSerieFormat().Overlap = 100;
// 結果のファイルを保存
workbook.SaveToFile("Excelのグラフシリーズの書式設定.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





