チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Excel は、データ分析や財務管理、予算などに広く使用される人気のあるスプレッドシートソフトウェアです。しかし、他のファイルに Excel ファイルを埋め込んだり、他の人と共有する場合、Excel 形式に互換性の問題が生じることがあります。そのような場合には、Excel をイメージに変換することが代替オプションとなります。この記事では、Spire.XLS for C++ を使用して C++ で Excel を画像に変換する方法について説明します。
Spire.XLS for C++ をアプリケーションに組み込むには、2つの方法があります。一つは NuGet 経由でインストールする方法、もう一つは当社のウェブサイトからパッケージをダウンロードし、ライブラリをプログラムにコピーする方法です。NuGet 経由のインストールの方が便利で、より推奨されます。詳しくは、以下のリンクからご覧いただけます。
Spire.XLS for C++ を C++ アプリケーションに統合する方法
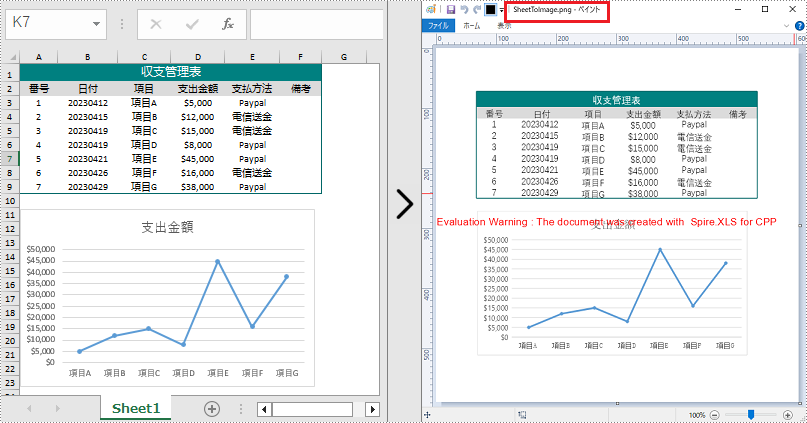
Spire.XLS for C++ では、Worksheet->ToImage() メソッドを使用して特定のワークシートを画像に変換します。次に、Image->Save() メソッドを使用して画像を PNG、JPG、または BMP 形式で保存できます。以下が詳細な手順です。
#include "Spire.Xls.o.h"
#include <iostream>
using namespace Spire::Xls;
int main() {
//入出力ファイルパスを指定する
std::wstring inputFile = L"sample.xlsx";
std::wstring outputFile = L"SheetToImage.png";
//Workbookオブジェクトを作成する
intrusive_ptr<Workbook> workbook = new Workbook();
//ディスクからExcel文書を読み込む
workbook->LoadFromFile(inputFile.c_str());
//最初のワークシートを取得する
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//画像をPNGファイルとして保存する
sheet->ToImage(sheet->GetFirstRow(), sheet->GetFirstColumn(), sheet->GetLastRow(), sheet->GetLastColumn())->Save(outputFile.c_str());
workbook->Dispose();
}
Spire.XLS for C++ では、Worksheet->ToImage(int firstRow, int firstColumn, int lastRow, int lastColumn) メソッドを使用して指定されたセル範囲を画像に変換することもできます。以下が詳細な手順です。
#include "Spire.Xls.o.h"
#include <iostream>
using namespace Spire::Xls;
int main() {
std::wstring inputFile = L"sample.xlsx";
std::wstring outputFile = L"Output";
//Workbookオブジェクトを作成する
intrusive_ptr<Workbook> workbook = new Workbook();
//ディスクからExcelドキュメントをロードする
workbook->LoadFromFile(inputFile.c_str());
//最初のシートを取得する
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//セル範囲を指定して特定の画像形式として保存する
sheet->ToImage(1, 1, 9, 6)->Save(L"Output//SpecificCellsToImage.png", ImageFormat::GetPng());
sheet->ToImage(1, 1, 9, 6)->Save(L"Output//SpecificCellsToImage.jpg", ImageFormat::GetJpeg());
sheet->ToImage(1, 1, 9, 6)->Save(L"Output//SpecificCellsToImage.bmp", ImageFormat::GetBmp());
//ファイルに保存する
workbook->Dispose();
}
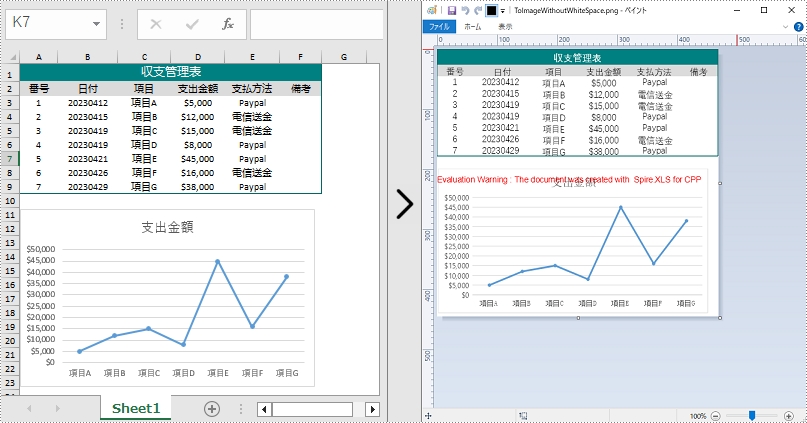
ワークシートを直接画像に変換する場合、変換された画像の周りには余白があります。これらの余白を削除したい場合は、変換時にワークシートの左、右、上、下のマージンをゼロに設定することができます。以下が詳細な手順です。
#include "Spire.Xls.o.h"
#include <iostream>
using namespace Spire::Xls;
int main() {
std::wstring inputFile =L"sample.xlsx";
std::wstring outputFile = L"ToImageWithoutWhiteSpace.png";
//Workbookオブジェクトを作成する
intrusive_ptr<Workbook> workbook = new Workbook();
//ディスクからExcelドキュメントをロードする
workbook->LoadFromFile(inputFile.c_str());
//最初のシートを取得する
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//マージンを0に設定して画像の余白を削除する
sheet->GetPageSetup()->SetLeftMargin(0);
sheet->GetPageSetup()->SetBottomMargin(0);
sheet->GetPageSetup()->SetTopMargin(0);
sheet->GetPageSetup()->SetRightMargin(0);
intrusive_ptr<Image> image = sheet->ToImage(sheet->GetFirstRow(), sheet->GetFirstColumn(), sheet->GetLastRow(), sheet->GetLastColumn());
//ファイルに保存する
image->Save(outputFile.c_str());
workbook->Dispose();
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ハイパーリンクは、デジタル文書において、2つのものを結びつけるために使用する最も重要なツールです。読者が Word ドキュメント内のハイパーリンクをクリックすると、ドキュメント内の別の場所、別のファイルやウェブサイト、または新しい電子メールメッセージに移動することができます。この記事では、Spire.Doc for Java を使用して、Java で Word ドキュメントにハイパーリンクを追加する方法について紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.4.2</version>
</dependency>
</dependencies>Spire.Doc for Java では、段落内のテキストや画像に Web リンク、メールリンク、ファイルリンク、ブックマークリンクを追加する Paragraph.appendHyperlink() メソッドを提供しています。以下は、その詳細な手順です。
import com.spire.doc.BookmarkStart;
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.BreakType;
import com.spire.doc.documents.HyperlinkType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.fields.DocPicture;
public class AddHyperlinks {
public static void main(String[] args) {
//Wordドキュメントを作成する
Document doc = new Document();
//セクションを追加する
Section section = doc.addSection();
//段落を追加する
Paragraph paragraph = section.addParagraph();
paragraph.getStyle().getCharacterFormat().setFontName("BIZ UDGothic");
paragraph.appendBreak(BreakType.Line_Break);
paragraph.appendHyperlink("https://www-iceblue.com/", "ホーム ページ", HyperlinkType.Web_Link);
//改行を追加する
paragraph.appendBreak(BreakType.Line_Break);
paragraph.appendBreak(BreakType.Line_Break);
//メールリンクを追加する
paragraph.appendHyperlink("mailto:このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。", "メールで問い合わせる。", HyperlinkType.E_Mail_Link);
//改行を追加する
paragraph.appendBreak(BreakType.Line_Break);
paragraph.appendBreak(BreakType.Line_Break);
//ファイルリンクを追加する
String filePath = "C:/報告.xlsx";
paragraph.appendHyperlink(filePath, "クリックすると報告が開きます。", HyperlinkType.File_Link);
//改行を追加する
paragraph.appendBreak(BreakType.Line_Break);
paragraph.appendBreak(BreakType.Line_Break);
//別のセクションを追加し、ブックマークを作成する
Section section2 = doc.addSection();
Paragraph bookmarkParagraph = section2.addParagraph();
bookmarkParagraph.appendText("ここにブックマークがあります。");
BookmarkStart start = bookmarkParagraph.appendBookmarkStart("myBookmark");
bookmarkParagraph.getItems().insert(0, start);
bookmarkParagraph.appendBookmarkEnd("myBookmark");
//ブックマークにリンクする
paragraph.appendHyperlink("myBookmark", "このドキュメント内の場所にジャンプします。", HyperlinkType.Bookmark);
//改行を追加する
paragraph.appendBreak(BreakType.Line_Break);
paragraph.appendBreak(BreakType.Line_Break);
//画像リンクを追加する
String imagePath = "C:/ロゴ.png";
DocPicture picture = paragraph.appendPicture(imagePath);
paragraph.appendHyperlink("https://www.e-iceblue.com/", picture, HyperlinkType.Web_Link);
//ドキュメントを保存する
doc.saveToFile("ハイパーリンクの追加.docx", FileFormat.Docx_2013);
}
}
ドキュメント内の既存のテキストにハイパーリンクを追加するのは、少し複雑です。まず対象となる文字列を見つけ、段落内の文字列をハイパーリンクフィールドに置き換える必要があります。以下はその手順です。
import com.spire.doc.Document;
import com.spire.doc.FieldType;
import com.spire.doc.FileFormat;
import com.spire.doc.Hyperlink;
import com.spire.doc.documents.*;
import com.spire.doc.fields.Field;
import com.spire.doc.fields.FieldMark;
import com.spire.doc.fields.TextRange;
import com.spire.doc.interfaces.IParagraphBase;
import com.spire.doc.interfaces.ITextRange;
import java.awt.*;
public class AddHyperlinksToExistingText {
public static void main(String[] args) {
//Documentのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("C:/サンプル.docx");
//ドキュメント内で「二酸化炭素」という文字列が出現する箇所をすべて探す
TextSelection[] selections = document.findAllString("二酸化炭素", true, true);
//最初の出現を得る
TextRange range = selections[0].getAsOneRange();
//そのテキストが含まれる段落を取得する
Paragraph paragraph = range.getOwnerParagraph();
//このテキストの段落内での位置を取得する
int index = paragraph.getItems().indexOf(range);
//このテキストを段落から削除する
paragraph.getItems().remove(range);
//ハイパーリンク フィールドを作成する
Field field = new Field(document);
field.setType(FieldType.Field_Hyperlink);
Hyperlink hyperlink = new Hyperlink(field);
hyperlink.setType(HyperlinkType.Web_Link);
hyperlink.setUri("https://ja.wikipedia.org/wiki/%E4%BA%8C%E9%85%B8%E5%8C%96%E7%82%AD%E7%B4%A0");
paragraph.getItems().insert(index, field);
//段落にフィールドマーク「start」を挿入する
IParagraphBase item = document.createParagraphItem(ParagraphItemType.Field_Mark);
FieldMark start = (FieldMark)item;
start.setType(FieldMarkType.Field_Separator);
paragraph.getItems().insert(index + 1, start);
//2つのフィールドマークの間にテキスト範囲を挿入する
ITextRange textRange = new TextRange(document);
textRange.setText("二酸化炭素");
textRange.getCharacterFormat().setFontName(range.getCharacterFormat().getFontName());
textRange.getCharacterFormat().setFontSize(range.getCharacterFormat().getFontSize());
textRange.getCharacterFormat().setBold(range.getCharacterFormat().getBold());
textRange.getCharacterFormat().setTextColor(Color.blue);
textRange.getCharacterFormat().setUnderlineStyle(UnderlineStyle.Single);
paragraph.getItems().insert(index + 2, textRange);
//段落にフィールドマーク「end」を挿入する
IParagraphBase item2 = document.createParagraphItem(ParagraphItemType.Field_Mark);
FieldMark end = (FieldMark)item2;
end.setType(FieldMarkType.Field_End);
paragraph.getItems().insert(index + 3, end);
//ドキュメントを保存する
document.saveToFile("既存のテキストにハイパーリンクの挿入.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ファイル形式は、デバイス間で文書の表示を一貫させることができます。しかし、PDF ドキュメントを Web ページに掲載する必要がある場合は、HTML ファイルに変換するのがよいでしょう。こうすることで、ファイルをダウンロードする必要がなく、ドキュメントのすべての内容を直接ブラウザで表示することができます。また、大きな PDF ドキュメントの読み込みには長い時間がかかりますが、HTML ファイルは非常に速くブラウザに表示させることができます。さらに、PDF ファイルに比べ、検索エンジンが HTML の Web ページをクロールして情報を取得することが容易であるため、Web サイトの露出が多くなります。本記事では、Spire.PDF for Java を使用して、Java で PDF ドキュメントを HTML ファイルに変換する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.4.9</version>
</dependency>
</dependencies>PDF ドキュメントから HTML ファイルへの変換は、Spire.PDF for Java が提供する PdfDocument.saveToFile(String filename, FileFormat.HTML) メソッドを使用して PDF ドキュメントを読み込み、HTML ファイルとして保存すれば直接行うことができます。詳細な手順は以下の通りです。
import com.spire.pdf.*;
public class convertPDFToHTML {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.loadFromFile("C:/自分を見失う.pdf");
//PDFファイルをHTMLファイルとして保存する
pdf.saveToFile("PDFからHTMLへの変換.html",FileFormat.HTML);
pdf.close();
}
}また、Spire.PDF for Java では、PdfDocument.getConvertOptions().setPdfToHtmlOptions(true) メソッドで、変換時に SVG を埋め込むことができるようにしています。PDF ファイルを SVG を埋め込んだ HTML ファイルに変換するための詳しい手順は以下の通りです。
import com.spire.pdf.*;
public class convertPDFToHTMLEmbeddingSVG {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("C:/自分を見失う.pdf");
//SVGの埋め込みを有効にする
doc.getConvertOptions().setPdfToHtmlOptions(true);
//PDFファイルをHTMLファイルとして保存する
doc.saveToFile("PDFからSVGを埋め込んだHTMLへの変換.html", FileFormat.HTML);
doc.close();
}
}Spire.PDF for Java は、PDF ドキュメントを HTML ストリームに変換することもサポートしています。詳しい手順は以下の通りです。
import com.spire.pdf.*;
import java.io.*;
public class convertPDFToHTMLStream {
public static void main(String[] args) throws FileNotFoundException {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.loadFromFile("C:/自分を見失う.pdf");
//PDFファイルをHTMLストリームとして保存する
File outFile = new File("PDFからHTMLストリームへの変換.html");
OutputStream outputStream = new FileOutputStream(outFile);
pdf.saveToStream(outputStream, FileFormat.HTML);
pdf.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF for Java 9.5.6のリリースを発表できることをうれしく思います。今回の更新では、OFDからPDFへの変換機能が強化されました。また、セルを埋める際に文字が切り捨てられるなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5976 | セルを埋める際に、文字が切り捨てられる問題が修正されました。 |
| Bug | SPIREPDF-5984 | OFDをPDFに変換する際にアプリケーションが「NullPointerException」をスローする問題が修正されました。 |
Spire.PDF 9.5.4のリリースを発表できることを嬉しく思います。このバージョンでは、PDFドキュメントの圧縮機能が最適化されました。PDFからWord、OFD、および画像への変換機能も強化されました。また、テキストをハイライトすることができない問題など、多くの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5840 | PDFドキュメントの圧縮機能が最適化されました。
PdfCompressor compressor = new PdfCompressor("input.pdf");
compressor.Options.TextCompressionOptions.UnembedFonts = true;
compressor.Options.ImageCompressionOptions.CompressImage = true;
compressor.Options.ImageCompressionOptions.ResizeImages = true;
compressor.Options.ImageCompressionOptions.ImageQuality = ImageQuality.Low;
compressor.CompressToFile("output.pdf"); |
| Bug | SPIREPDF-5170 | <ul> タグなどを含むHTMLコードを挿入しても機能しない問題が修正されました。 |
| Bug | SPIREPDF-5601 | PDFページをコピーした後にAdobeツールで結果文書を開くことができない問題が修正されました。 |
| Bug | SPIREPDF-5883 | PDFをWordに変換した後、テキストの改行が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5897 | PDFを画像に変換する際に、単語間のスペースが消失する問題が修正されました。 |
| Bug | SPIREPDF-5903 | テキストをハイライトすることができない問題が修正されました。 |
| Bug | SPIREPDF-5923 | フォームフィールドのフラット化後、文書を保存する際にアプリケーションが「NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5938 | 注釈付きのPDFファイルを印刷する際に注釈が失われていた問題が修正されました。 |
| Bug | SPIREPDF-5939 | PDFからテーブルを抽出する際に結果が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5950 | PDFをOFDに変換する際に、アプリケーションが「System.InvalidOperationException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5951 | 抽出されたテキストが表の範囲を超えていた問題が修正されました。 |
| Bug | SPIREPDF-5952 | PdfAnnotationBorder border = new PdfAnnotationBorder() {Width = 20f} メソッドを使用して幅を設定しても効果がない問題が修正されました。 |
| Bug | SPIREPDF-5968 | XFA Formフィールドの値の充填に失敗した問題が修正されました。 |
| Bug | SPIREPDF-5970 | OFDをPDFに変換する際に、アプリケーションが「System.ArgumentException」をスローする問題が修正されました。 |
PowerPoint 文書内に多くのメディアファイルや画像が含まれており、他者にテキスト校正のために送信する場合、大きなファイルサイズのため転送速度が遅いことがあります。そのような場合は、まず PowerPoint からテキストを Word 文書またはメモ帳に抽出し、テキスト内容のみを送信することが良いです。また、抽出されたテキスト内容は、将来の参照のためにアーカイブまたはバックアップすることもできます。この記事では、Spire.Presentation for .NET を使用して、C# および VB.NET で PowerPoint プレゼンテーションからテキストを抽出する方法を示します。
まず、Spire.Presentation for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PresentationPowerPoint プレゼンテーション内のテキスト情報を共有または配信する必要がある場合があります。その際には、テキスト抽出操作が必要です。以下は、すべてのスライドからテキストを抽出して TXT ファイルに保存する手順です。
using Spire.Presentation;
using System.IO;
using System.Text;
namespace ExtractText
{
class Program
{
static void Main(string[] args)
{
//Presentationクラスのインスタンスを初期化する
Presentation presentation = new Presentation();
//サンプル PowerPoint 文書を読み込む
presentation.LoadFromFile("sample.pptx");
//StringBuilderインスタンスを作成する
StringBuilder sb = new StringBuilder();
//文書内の各スライドをループする
foreach (ISlide slide in presentation.Slides)
{
//各スライド内のすべての図形をループする
foreach (IShape shape in slide.Shapes)
{
//図形が IAutoShape タイプであるかどうかを判断する
if (shape is IAutoShape)
{
//各図形のすべての段落をループする
foreach (TextParagraph tp in (shape as IAutoShape).TextFrame.Paragraphs)
{
//抽出したテキストを StringBuilder インスタンスに追加する
sb.AppendLine(tp.Text);
}
}
}
}
//抽出されたテキストを保存するための新しいtxtファイルを作成する
File.WriteAllText("ExtractText.txt", sb.ToString());
//ドキュメントを閉じる
presentation.Dispose();
}
}
}Imports Spire.Presentation
Imports System.IO
Imports System.Text
Namespace ExtractText
Class Program
Private Shared Sub Main(ByVal args() As String)
'Presentationクラスのインスタンスを初期化する
Dim presentation As Presentation = New Presentation
'サンプル PowerPoint 文書を読み込む
presentation.LoadFromFile("sample.pptx")
'StringBuilderインスタンスを作成する
Dim sb As StringBuilder = New StringBuilder
'文書内の各スライドをループする
For Each slide As ISlide In presentation.Slides
'各スライド内のすべての図形をループする
For Each shape As IShape In slide.Shapes
'図形が IAutoShape タイプであるかどうかを判断する
If (TypeOf shape Is IAutoShape) Then
'各図形のすべての段落をループする
For Each tp As TextParagraph In CType(shape, IAutoShape).TextFrame.Paragraphs
'抽出したテキストを StringBuilder インスタンスに追加する
sb.AppendLine(tp.Text)
Next
End If
Next
Next
'抽出されたテキストを保存するための新しいtxtファイルを作成する
File.WriteAllText("ExtractText.txt", sb.ToString)
'ドキュメントを閉じる
presentation.Dispose()
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Email 6.5.7のリリースを発表できることを嬉しく思います。このリリースでは、NetFrameworkアプリケーションで使用するときにImapサーバとPop3サーバに接続できない問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREEMAIL-76 | NetFrameworkアプリケーションで使用するときにImapサーバとPop3サーバに接続できない問題が修正されました。 |
Open XML は、Microsoft が開発した XML ベースのファイル形式で、文書処理、スプレッドシート、プレゼンテーション、チャート、図解など、さまざまな種類のファイルを保存および交換することができます。この文書形式は、多くの種類のアプリケーションで広く認知され、サポートされており、データを長期保存するための良い選択です。
場合によっては、Excel ファイルを Open XML 形式に変換することで、他のソフトウェアで開いて読み取ることができることを保証できます。一方、Open XML ファイルを Excel 形式に変換することで、データ分析ツール(例えばピボットテーブルやチャート)を使用してデータを処理することもできます。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET でプログラムによって Open XML を Exce にまたは Excel を Open XML に変換する方法を紹介します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSExcel ファイルを Open XML に変換するには、Workbook.LoadFromFile(string fileName) メソッドを使用して Excel ファイルを読み込みます。Workbook.SaveAsXml(string fileName) メソッドを使用して Open XML 形式で保存します。次の手順は、Excel ファイルを Open XML に変換する方法を示しています。
using Spire.Xls;
namespace ConvertExcelToOpenXML
{
internal class Program
{
static void Main(string[] args)
{
//Workbookクラスのインスタンスを初期化する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx");
//Excel ファイルをOpen XML 形式で保存する
workbook.SaveAsXml("ExcelToXML.xml");
//ドキュメントを閉じる
workbook.Dispose();
}
}
}Imports Spire.Xls
Namespace ConvertExcelToOpenXML
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Workbookクラスのインスタンスを初期化する
Dim workbook As Workbook = New Workbook()
'Excelファイルを読み込む
workbook.LoadFromFile("Sample.xlsx")
'Excel ファイルをOpen XML 形式で保存する
workbook.SaveAsXml("ExcelToXML.xml")
'ドキュメントを閉じる
workbook.Dispose()
End Sub
End Class
End Namespace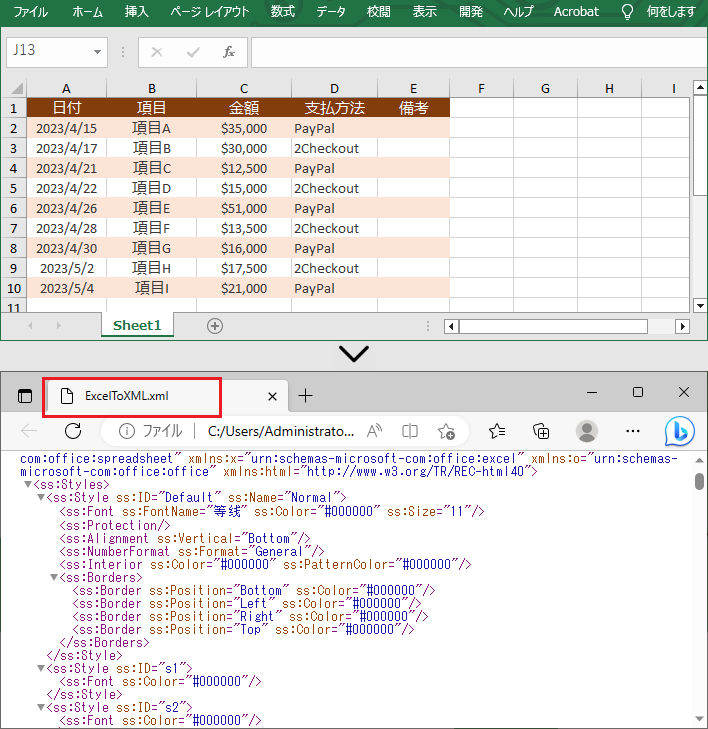
Open XML ファイルを Excel に変換するには、Workbook.LoadFromXml(string fileName) メソッドを使用して Open XML ファイルを読み込みます。Workbook.SaveToFile(string fileName, ExcelVersion version) メソッドを使用して Excel 形式で保存します。Open XML ファイルを Excel に変換する手順は次のとおりです。
using Spire.Xls;
namespace ConvertOpenXMLToExcel
{
internal class Program
{
static void Main(string[] args)
{
//Workbookクラスのインスタンスを初期化する
Workbook workbook = new Workbook();
//Open XMLファイルを読み込む
workbook.LoadFromXml("ExcelToXML.xml");
//Open XML ファイルを Excel 形式で保存する
workbook.SaveToFile("XMLToExcel.xlsx", ExcelVersion.Version2016);
//ドキュメントを閉じる
workbook.Dispose();
}
}
}Imports Spire.Xls
Namespace ConvertOpenXMLToExcel
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Workbookクラスのインスタンスを初期化する
Dim workbook As Workbook = New Workbook()
'Open XMLファイルを読み込む
workbook.LoadFromXml("ExcelToXML.xml")
'Open XML ファイルを Excel 形式で保存する
workbook.SaveToFile("XMLToExcel.xlsx", ExcelVersion.Version2016)
'ドキュメントを閉じる
workbook.Dispose()
End Sub
End Class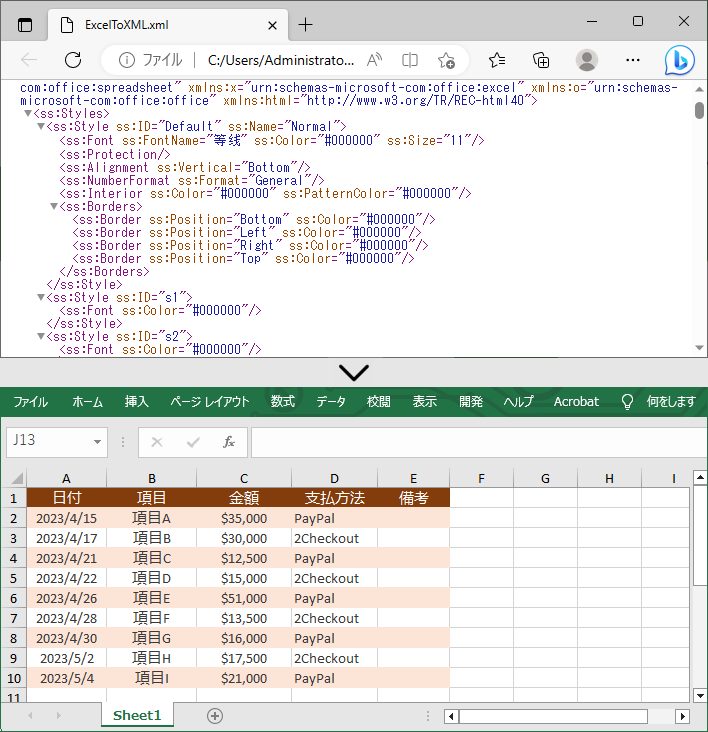
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
余白とは、ページの端からコンテンツ領域までの距離のことです。ドキュメントの見栄えを整え、専門的にするのに役立ちます。Microsoft Word でドキュメントを作成する場合、ドキュメントの見栄えをよくするために余白を設定する必要がある場合があります。この記事では、C# と VB.NET で Spire.Doc for .NET を使用して Word ドキュメントの余白を設定する方法を説明します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET では、Section.PageSetup.Margins プロパティの下に、Word ドキュメントの上下左右の余白を設定するプロパティを用意しています。Word ドキュメントの余白を設定するための詳細な手順は以下の通りです。
using Spire.Doc;
namespace PageMargins
{
class Program
{
static void Main(string[] args)
{
//Documentのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.LoadFromFile("C:/サンプル.docx");
//最初のセクションを取得する
Section section = document.Sections[0];
//セクションの上下左右の余白を設定する
section.PageSetup.Margins.Top = 17.9f;
section.PageSetup.Margins.Bottom = 17.9f;
section.PageSetup.Margins.Left = 17.9f;
section.PageSetup.Margins.Right = 17.9f;
//ドキュメントを保存する
document.SaveToFile("余白の設定.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Namespace PageMargins
Class Program
Shared Sub Main(ByVal args() As String)
'Documentのインスタンスを作成する
Dim document As Document = New Document()
'Wordドキュメントを読み込む
document.LoadFromFile("C:/サンプル.docx")
'最初のセクションを取得する
Dim section As Section = document.Sections(0)
'セクションの上下左右の余白を設定する
section.PageSetup.Margins.Top = 17.9F
section.PageSetup.Margins.Bottom = 17.9F
section.PageSetup.Margins.Left = 17.9F
section.PageSetup.Margins.Right = 17.9F
'ドキュメントを保存する
document.SaveToFile("余白の設定.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
テキストファイルは、どんなテキスト編集プログラムでも簡単に編集することができます。他の人がファイルを閲覧する際に変更を防ぎたい場合は、PDF に変換することができます。今回は、Spire.PDF for Java を使用して、Java でテキストファイルを PDF に変換する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.4.9</version>
</dependency>
</dependencies>Spire.PDF for Java を使ってテキストファイルを PDF に変換するには、TXT ファイルからテキストを読み込み、PdfTextWidget.draw() メソッドを使って PDF ドキュメントにテキストを描画する必要があります。詳しい手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class textToPDF {
public static void main(String[] args) throws IOException {
//テキストファイルからテキストを読み込む
String text = readTextFromFile("C:/Spire.PDF for Java.txt");
//PdfDocumentのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//ページを追加する
PdfPageBase page = pdf.getPages().add();
//PdfTrueTypeFontのインスタンスを作成する
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("BIZ UDGothic", Font.PLAIN, 12));
//PdfTextLayoutのインスタンスを作成する
PdfTextLayout textLayout = new PdfTextLayout();
textLayout.setBreak(PdfLayoutBreakType.Fit_Page);
textLayout.setLayout(PdfLayoutType.Paginate);
//PdfStringFormatのインスタンスを作成する
PdfStringFormat format = new PdfStringFormat();
format.setLineSpacing(20f);
//テキストからPdfTextWidgetのインスタンスを作成する
PdfTextWidget textWidget = new PdfTextWidget(text, font, PdfBrushes.getBlack());
//文字列の書式を設定する
textWidget.setStringFormat(format);
//ページ内の指定された位置にテキストを描画する
Rectangle2D.Float bounds = new Rectangle2D.Float();
bounds.setRect(0, 25, page.getCanvas().getClientSize().getWidth(), page.getCanvas().getClientSize().getHeight());
textWidget.draw(page, bounds, textLayout);
//結果ファイルを保存する
pdf.saveToFile("テキストからPDFへの変換.pdf", FileFormat.PDF);
}
public static String readTextFromFile(String fileName) throws IOException {
StringBuffer sb = new StringBuffer();
BufferedReader br = new BufferedReader(new FileReader(fileName));
String content = null;
while ((content = br.readLine()) != null) {
sb.append(content);
sb.append("\n");
}
return sb.toString();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





