チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Excel にはデータを記録する以外に計算機能があり、データの分析や加工を効率的かつ簡単に行うことができます。Excel の計算ツールには、数式と関数の2つがあります。数式はユーザーが定義した計算文であり、関数はあらかじめ定義された数式です。ユーザーは、セルに自分の数式を入力するか、関数を呼び出すだけで計算することができます。この記事では、Spire.XLS for Java を使用して、Excel ワークブックに数式や関数を挿入したり、読み込んだりする方法を紹介します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.12.4</version>
</dependency>
</dependencies>Spire.XLS for Java では、特定のセルに数式や関数を追加するための Worksheet.getCellRange().setFormula() メソッドを用意しています。ワークシートに数式や関数を挿入する詳細な手順は以下の通りです。
import com.spire.xls.*;
public class insertFormulas {
public static void main(String[] args) {
//Workbookのオブジェクトを作成する
Workbook workbook = new Workbook();
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
//currentRow、currentFormulaの2つの変数を宣言する
int currentRow = 1;
String currentFormula = null;
//列の幅を設定する
sheet.setColumnWidth(1, 32);
sheet.setColumnWidth(2, 16);
//セルにデータを書き込む
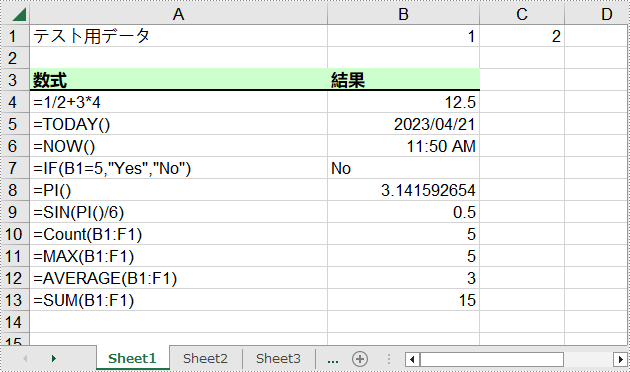
sheet.getCellRange(currentRow,1).setValue("テスト用データ");
sheet.getCellRange(currentRow,2).setNumberValue(1);
sheet.getCellRange(currentRow,3).setNumberValue(2);
sheet.getCellRange(currentRow,4).setNumberValue(3);
sheet.getCellRange(currentRow,5).setNumberValue(4);
sheet.getCellRange(currentRow,6).setNumberValue(5);
//セルにテキストを書き込む
currentRow += 2;
sheet.getCellRange(currentRow,1).setValue("数式") ; ;
sheet.getCellRange(currentRow,2).setValue("結果");
//セルの書式を設定する
CellRange range = sheet.getCellRange(currentRow,1,currentRow,2);
range.getStyle().getFont().isBold(true);
range.getStyle().setKnownColor(ExcelColors.LightGreen1);
range.getStyle().setFillPattern(ExcelPatternType.Solid);
range.getStyle().getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Medium);
//算術演算
currentFormula = "=1/2+3*4";
sheet.getCellRange(++currentRow,1).setText("'"+ currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//日付関数
currentFormula = "=TODAY()";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
sheet.getCellRange(currentRow,2).getStyle().setNumberFormat("YYYY/MM/DD");
//時間関数
currentFormula = "=NOW()";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
sheet.getCellRange(currentRow,2).getStyle().setNumberFormat("H:MM AM/PM");
//IF関数
currentFormula = "=IF(B1=5,\"Yes\",\"No\")";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//PI関数
currentFormula = "=PI()";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//三角関数
currentFormula = "=SIN(PI()/6)";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//計数関数
currentFormula = "=Count(B1:F1)";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//最大値関数
currentFormula = "=MAX(B1:F1)";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//平均関数
currentFormula = "=AVERAGE(B1:F1)";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//和算関数
currentFormula = "=SUM(B1:F1)";
sheet.getCellRange(++currentRow,1).setText("'"+currentFormula);
sheet.getCellRange(currentRow,2).setFormula(currentFormula);
//ワークブックを保存する
workbook.saveToFile("数式の挿入.xlsx",FileFormat.Version2013);
}
}
Excel のワークシートで数式を読み込むには、CellRange.hasFormula() メソッドを使用して、セルに数式が含まれているかどうかを検出することができます。そして、CellRange.getFormula() メソッドを使用して、数式がある場合はその数式を取得します。詳しい手順は以下の通りです。
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class readFormulas {
public static void main(String[] args) {
//Workbookのオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.loadFromFile("数式の挿入.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
//B1:B13内のセルをループする
for (Object cell: sheet.getCellRange("B1:B13")
) {
CellRange cellRange = (CellRange)cell;
//セルに数式があるかどうかを検出する
if (cellRange.hasFormula()){
//数式を出力する
String certainCell = String.format("セル[%d, %d]に数式がある。",cellRange.getRow(),cellRange.getColumn());
System.out.println(certainCell + cellRange.getFormula());
}
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
MS Word では、重複するコンテンツや主題に関係のない情報を含む段落を削除することが非常に重要です。そうすることで、ドキュメントを簡素化し、情報の正確性を確保できます。この記事では、Spire.Doc for Java を使用して Word 文書で段落を削除する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.3.11</version>
</dependency>
</dependencies>すべての段落を削除するには、文書内すべてのセクションをループします。そして、Section.getParagraphs().clear() メソッドを使用して各セクションのすべての段落を削除できます。詳細な手順は次のとおりです。
import com.spire.doc.*;
public class removeAllParagraphs {
public static void main(String[] args) {
//Documentインスタンスを作成する
Document document = new Document();
//ディスクからWord 文書をロードする
document.loadFromFile("sample.docx");
//各セクション内のすべての段落を削除する
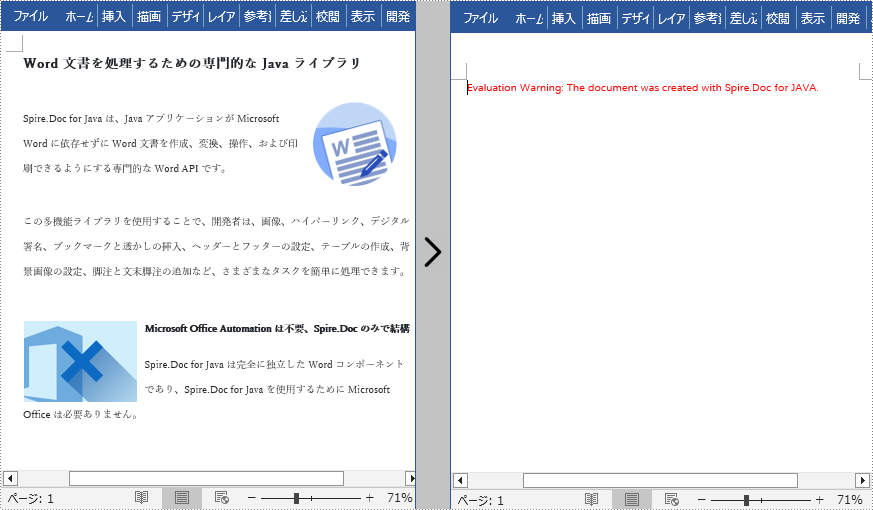
for ( Object sectionObj: document.getSections()) {
Section section = (Section)sectionObj;
section.getParagraphs().clear();
}
//結果文書を保存する
document.saveToFile("removeAllParagraphs.docx", FileFormat.Docx_2013);
}
}
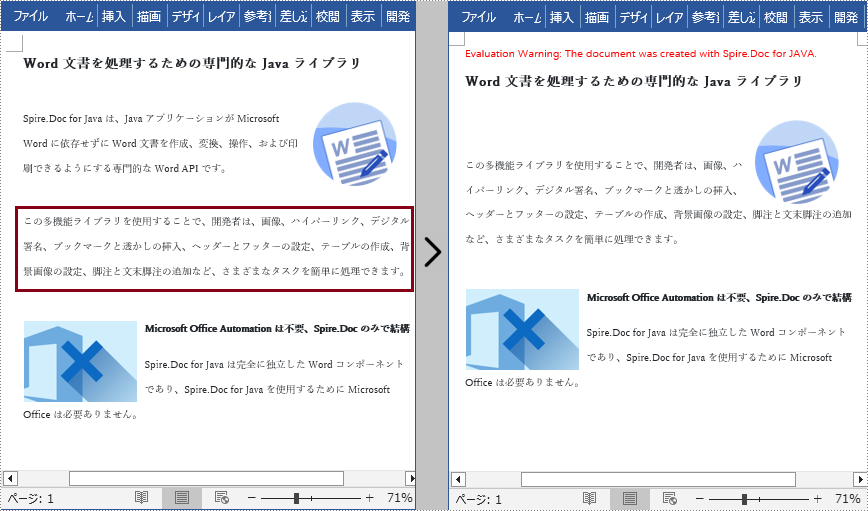
重複した情報や役に立たない情報を含む段落を見つけた場合、Spire.Doc for Java では、Section.getParagraphs().removeAt() メソッドを使用して指定された段落を削除できます。詳細な手順は次のとおりです。
import com.spire.doc.*;
public class removeSpecificParagraph {
public static void main(String[] args) {
//Documentインスタンスを作成する
Document document = new Document();
//ディスクからWord 文書をロードする
document.loadFromFile("sample.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//セクションの3番目の段落を削除する
section.getParagraphs().removeAt(2);
//結果文書を保存する
document.saveToFile("removeSpecificParagraph.docx", FileFormat.Docx_2013);
}
}
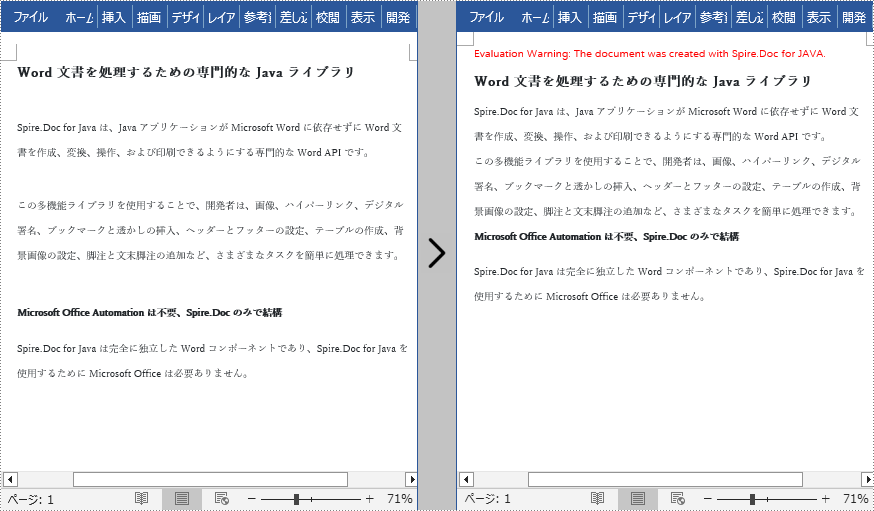
文書に空の段落/行が多数ある場合は、読みやすくするためにそれらを削除すできます。以下は、Word 文書内のすべての空白の段落/行を削除する手順です。
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class removeEmptyLines {
public static void main(String[] args) {
//Documentインスタンスを作成する
Document document = new Document();
//ディスクからWord 文書をロードする
document.loadFromFile("sample.docx");
//文書の各段落をループする
for (Object sectionObj : document.getSections()) {
Section section=(Section)sectionObj;
for (int i = 0; i < section.getBody().getChildObjects().getCount(); i++) {
if ((section.getBody().getChildObjects().get(i).getDocumentObjectType().equals(DocumentObjectType.Paragraph) )) {
String s= ((Paragraph)(section.getBody().getChildObjects().get(i))).getText().trim();
//段落が空白段落かどうかを判断する
if (s.isEmpty()) {
//空白段落を削除する
section.getBody().getChildObjects().remove(section.getBody().getChildObjects().get(i));
i--;
}
}
}
}
//結果文書を保存する
document.saveToFile("removeEmptyLines.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
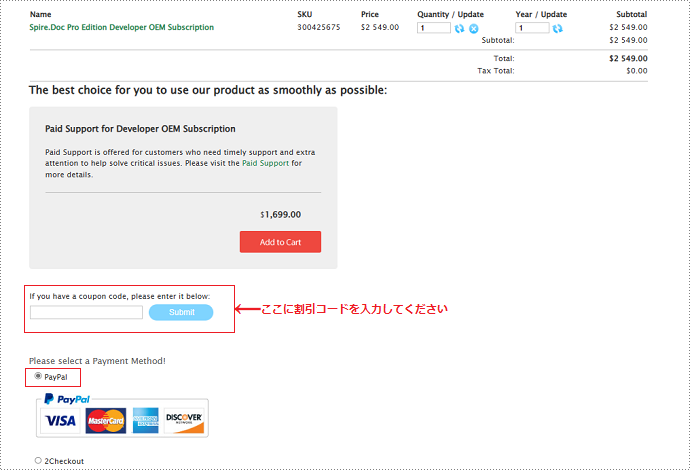
お支払い方法として「PayPal」を選択し、割引コードを指定された場所に入力してください。「Submit」をクリックします。
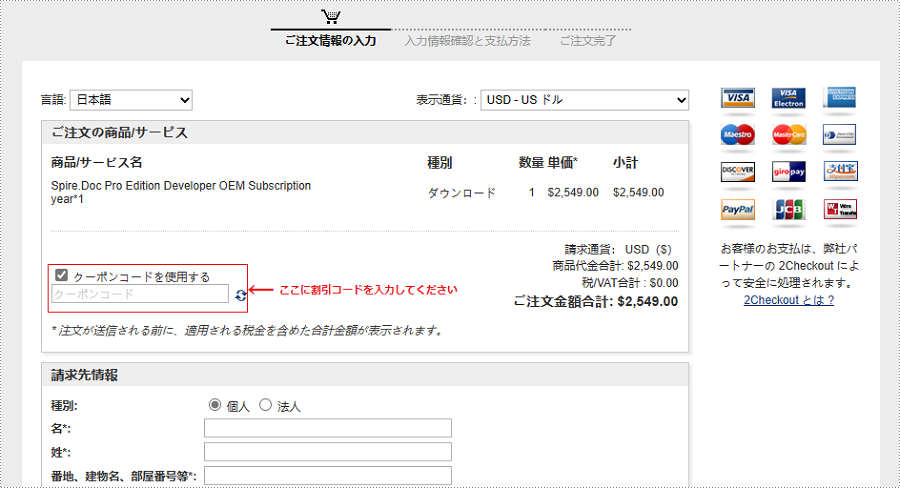
お支払い方法として「2Checkout」を選択し、割引コードを指定された場所に入力してください。「Next」をクリックします。
その他のご質問は、このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。までお気軽にお問い合わせください。
Spire.Office for Java 8.4.5のリリースを発表できることをうれしく思います。このリリースでは、Spire.Doc for Java はDocx2016およびDocx2019ファイルフォーマットをサポートしています。Spire.Presentation for Javaはカスタムレイアウトを使用した新しいスライドの追加をサポートしています。Spire.PDF for Javaは画像を圧縮する際にメモリの消費量が最適化されました。Spire.XLS for JavaはExcelからHTMLとPDFへの変換機能が強化されました。さらに、多くの既知のバグが正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-6422 | Docx2016およびDocx2019ファイルフォーマットをサポートしています。
Spire.Doc.FileFormat.Docx2016 Spire.Doc.FileFormat.Docx2019 |
| New feature | SPIREDOC-6913 | 目次のページ番号のみを更新する機能をサポートしています。
document.updateTOCPageNumbers(); document.updateTOCPageNumbers(TableOfContent toc); |
| New feature | SPIREDOC-9216 | コメントの返信項目を取得する機能をサポートしています。
Document doc = new Document();
doc.loadFromFile(inputFile);
Comment comment = doc.getComments().get(0);
CommentsCollection comCollect = comment.getReplyCommentItems();
String author = comCollect.get(0).getFormat().getAuthor();
Date dateTime = comCollect.get(0).getFormat().getDateTime();
String replayContent = "";
IDocumentObjectCollection objCollect = comCollect.get(0).getBody().getChildObjects();
for (int i = 0; i < objCollect.getCount(); i++) {
DocumentObject obj = objCollect.get(i);
if (obj.getDocumentObjectType() == DocumentObjectType.Paragraph) {
replayContent = ((Paragraph) obj).getText();
}
} |
| Bug | SPIREDOC-8680 | 修正を受けたページが縦向きから横向きに変わる問題が修正されました。 |
| Bug | SPIREDOC-8786 SPIREDOC-9159 |
WordをPDFに変換した後にレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8789 | WordをPDFに変換した後にフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-9019 | 目次ページ番号の更新が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9097 | RTFドキュメントをロードする際にアプリケーションが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9099 SPIREDOC-9123 SPIREDOC-9124 SPIREDOC-9177 |
WordをPDFに変換した後にテキストの改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9130 | WordをPDFに変換する際にアプリケーションが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9151 | ドキュメントのマージ後に数式を編集できない問題が修正されました。 |
| Bug | SPIREDOC-9153 | ドキュメントをロードして保存した後、フォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-9181 | WordをHTMLに変換した後に文字間隔のスケーリングスタイルが失われていた問題が修正されました。 |
| Bug | SPIREDOC-9196 | ドキュメントをロードする際にアプリケーションが「Cannot find stream '1Table' in the storage」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9227 | 2つのWordドキュメントを比較した後、PDFに変換すると、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9251 | WordをOFDに変換した後改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9260 | DOCドキュメントをロードする際にアプリケーションが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9280 | 2つのWordドキュメントを比較する際にアプリケーションが「java.lang.IllegalArgumentException」をスローした問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2213 | テキスト幅による表の列幅の調整がサポートされています。
Presentation ppt = new Presentation(); ppt.loadFromFile(inputFile); ITable table = (ITable) ppt.getSlides().get(0).getShapes().get(0); table.getColumnsList().get(2).adjustColumnByTextWidth(); ppt.saveToFile(outputFile, FileFormat.AUTO); |
| New feature | SPIREPPT-2220 | 形状のラウンド半径の設定がサポートされています。
IAutoShape autoShape=iSlide.getShapes().appendShape(ShapeType.ROUND_CORNER_RECTANGLE,new Rectangle2D.Float(50,50,150,150)); IAutoShape autoShape1=iSlide.getShapes().appendShape(ShapeType.ONE_ROUND_CORNER_RECTANGLE,new Rectangle2D.Float(250,50,150,150)); IAutoShape autoShape2=iSlide.getShapes().appendShape(ShapeType.ONE_SNIP_ONE_ROUND_CORNER_RECTANGLE,new Rectangle2D.Float(450,50,150,150)); IAutoShape autoShape3=iSlide.getShapes().appendShape(ShapeType.TWO_DIAGONAL_ROUND_CORNER_RECTANGLE,new Rectangle2D.Float(50,250,150,150)); IAutoShape autoShape4=iSlide.getShapes().appendShape(ShapeType.TWO_SAMESIDE_ROUND_CORNER_RECTANGLE,new Rectangle2D.Float(250,250,150,150)); autoShape.setRoundRadius(autoShape.getWidth()/3); autoShape1.setRoundRadius(autoShape1.getWidth()/3); autoShape2.setRoundRadius(autoShape2.getWidth()/3); autoShape3.setRoundRadius(autoShape3.getWidth()/3); autoShape4.setRoundRadius(autoShape4.getWidth()/3); |
| New feature | SPIREPPT-2228 | カスタムレイアウトを使用した新しいスライドの追加がサポートされています。
Presentation presentation = new Presentation(); presentation.loadFromFile(intputFile); //カスタムレイアウトを取得する ILayout iLayout = presentation.getMasters().get(0).getLayouts().get(1); //新しいスライドを追加する presentation.getSlides().append(iLayout); //新しいスライドを挿入する presentation.getSlides().insert(0, iLayout); presentation.saveToFile(outputFile, FileFormat.PPTX_2016); presentation.dispose(); |
| New feature | SPIREPPT-2231 | SmartArtを追加する際に、SmartArtLayoutType.PICTURE_ORGANIZATION_CHART and SmartArtLayoutType.NAME_AND_TITLE_ORGANIZATION_CHARTの設定がサポートされています。
ppt.getSlides().get(0).getShapes().appendSmartArt(50, 50, 250, 250, SmartArtLayoutType.PICTURE_ORGANIZATION_CHART); ppt.getSlides().append().getShapes().appendSmartArt(50, 50, 250, 250, SmartArtLayoutType.NAME_AND_TITLE_ORGANIZATION_CHART); |
| Bug | SPIREPPT-2071 | SeriesLinesColorを設定した後、ドキュメントを開いたときにエラーメッセージが表示された問題が修正されました。 |
| Bug | SPIREPPT-2209 | HtmlをPPTに変換した際にファイルが出力されなかった問題が修正されました。 |
| Bug | SPIREPPT-2216 | PPTを画像に変換する際に、アプリケーションが「OutOfMemoryError」をスローする問題が修正されました。 |
| Bug | SPIREPPT-2226 | PPTをSVGに変換する際に、プログラムが長時間ハングアップしていた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5221 | 画像を圧縮する際にメモリ消費量を最適化しました。 |
| Bug | SPIREPDF-5727 | 透かしを追加すると文書のサイズが大幅に増大する問題が修正されました。 |
| Bug | SPIREPDF-5828 | 変換されたPDF/A 1 AドキュメントがveraPDFで検証に失敗する問題が修正されました。 |
| Bug | SPIREPDF-5842 | PDFをHtmlに変換する際にプログラムが「NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5861 | PDFをSVGに変換する際に文字が重なる問題が修正されました。 |
| Bug | SPIREPDF-5880 | PDF編集権限の削除が無効だった問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4512 | 画像を挿入した後に画像の高さが変化する問題が修正されました。 |
| Bug | SPIREXLS-4562 | 1行のデータ範囲を指定する際にフィルタが機能しない問題が修正されました。 |
| Bug | SPIREXLS-4563 | ExcelをHTMLに変換する際にアプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4574 | ExcelをPDFに変換する際にアプリケーションが「Invalid formula」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4576 | ExcelをPDFに変換する際にアプリケーションが「String index out of range」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4577 | ExcelをPDFに変換する際にアプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
Word ドキュメントのブックマークは、ページを移動することなく、ドキュメント内の特定の場所に移動することができます。これは、ドキュメントのセクション間の内部リンクと同じように機能します。ブックマークは、特に長い文書のナビゲーションに便利です。この記事では、Spire.Doc for C++ を使用して、C++ で Word ドキュメントにブックマークを追加または削除する方法を説明します。
Spire.Doc for C++ をアプリケーションに組み込むには、2つの方法があります。一つは NuGet 経由でインストールする方法、もう一つは当社のウェブサイトからパッケージをダウンロードし、ライブラリをプログラムにコピーする方法です。NuGet 経由のインストールの方が便利で、より推奨されます。詳しくは、以下のリンクからご覧いただけます。
Spire.Doc for C++ を C++ アプリケーションに統合する方法
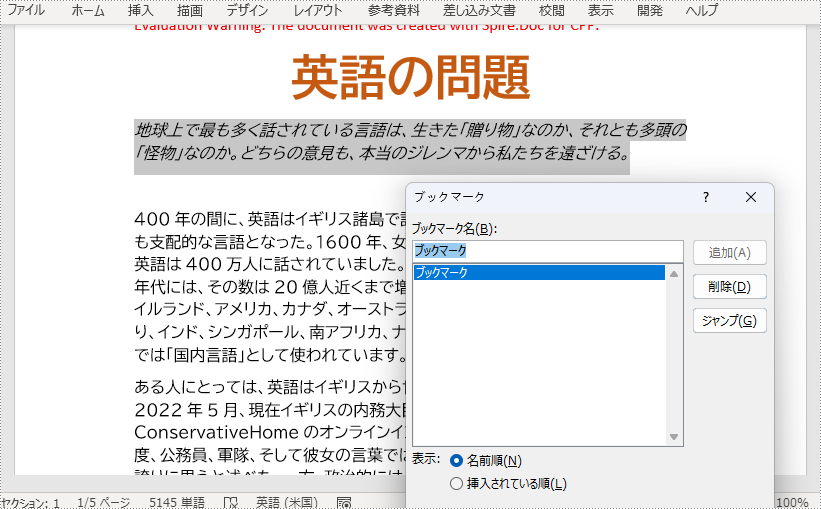
ブックマークは通常、段落全体に基づいて作成され、特に段落自体が見出しになっている場合は、そのようになります。以下は、Spire.Doc for C++ を使用して、段落にブックマークを追加する手順です。
#include "Spire.Doc.o.h";
using namespace Spire::Doc;
int main() {
//Documentのオブジェクトを作成する
Document* document = new Document();
//Wordファイルを読み込む
document->LoadFromFile(L"C:/英語の問題.docx");
//特定の段落を取得する
Paragraph* paragraph = document->GetSections()->GetItem(0)->GetParagraphs()->GetItem(1);
//ブックマークの開始を作成する
BookmarkStart* start = new BookmarkStart(document, L"ブックマーク");
//選択したテキストの前にブックマークの開始を挿入する
paragraph->GetChildObjects()->Insert(0, start);
//段落の末尾にブックマークの末尾を挿入する
paragraph->AppendBookmarkEnd(L"ブックマーク");
//ドキュメントを保存する
document->SaveToFile(L"段落へのブックマーク追加.docx", FileFormat::Docx2013);
document->Close();
delete document;
}
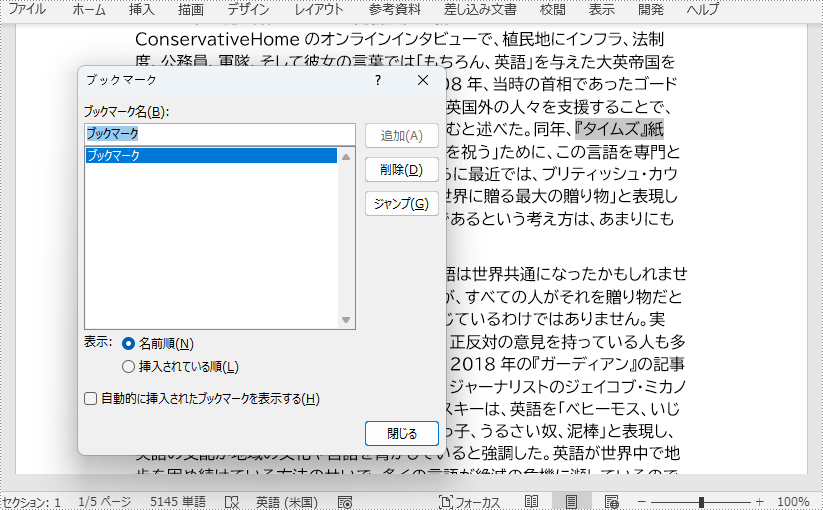
また、ブックマークは、段落内の特定の位置に挿入することもできます。以下は、Spire.Doc for C++ を使用して、選択したテキストにブックマークを追加する手順です。
#include "Spire.Doc.o.h";
using namespace Spire::Doc;
using namespace std;
int main() {
//Documentのオブジェクトを作成する
Document* document = new Document();
//Wordファイルを読み込む
document->LoadFromFile(L"C:/英語の問題.docx");
//検索するテキストを指定する
wstring stringToFind = L"『タイムズ』紙";
//ドキュメントからテキストを検索する
vector<TextSelection*> finds = document->FindAllString(stringToFind.c_str(), false, true);
TextSelection* specificText = finds[0];
//テキストがある段落を探す
Paragraph* para = specificText->GetAsOneRange()->GetOwnerParagraph();
//段落内のテキストのインデックスを取得する
int index = para->GetChildObjects()->IndexOf(specificText->GetAsOneRange());
//ブックマークの開始を作成する
BookmarkStart* start = new BookmarkStart(document, L"ブックマーク");
//選択したテキストの前にブックマークの開始を挿入する
para->GetChildObjects()->Insert(index, start);
//ブックマークの末尾を作成する
BookmarkEnd* end = new BookmarkEnd(document, L"ブックマーク");
//選択したテキストの後にブックマークの末尾を挿入する
para->GetChildObjects()->Insert(index + 2, end);
//ドキュメントを保存する
document->SaveToFile(L"テキストへのブックマーク追加.docx", FileFormat::Docx2013);
document->Close();
delete document;
}
Spire.Doc for C++ を使用すると、Word ドキュメントからすべてのブックマークまたは特定のブックマークを簡単に取得および削除することができます。以下はその詳細な手順です。
#include "Spire.Doc.o.h";
using namespace Spire::Doc;
int main() {
//Documentのオブジェクトを作成する
Document* document = new Document();
//Wordファイルを読み込む
document->LoadFromFile(L"段落へのブックマーク追加.docx");
//特定のブックマークをインデックスで取得する
Bookmark* bookmark = document->GetBookmarks()->GetItem(0);
//ブックマークを削除する
document->GetBookmarks()->Remove(bookmark);
//すべてのブックマークを削除する
//document->GetBookmarks()->Clear();
//ドキュメントを保存する
document->SaveToFile(L"ブックマークの削除.docx", FileFormat::Docx2013);
document->Close();
delete document;
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
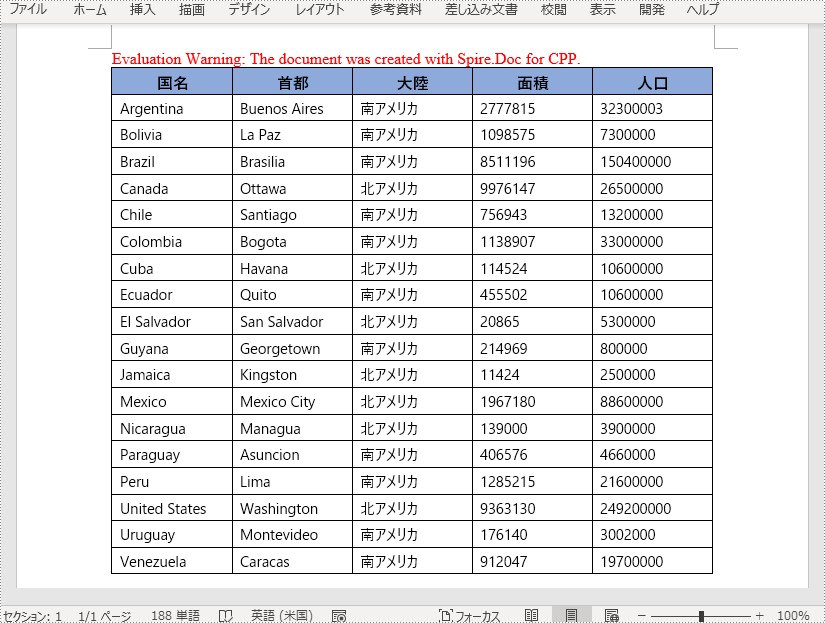
表は、データを整理して表示するための強力なツールです。データを行と列に並べることで、著者は異なるデータ区分間の関係を説明し、読者は複雑なデータを理解し分析することが容易になります。この記事では、Spire.Doc for C++ を使用して、プログラムで Word ドキュメントに表を作成する方法について説明します。
Spire.Doc for C++ をアプリケーションに組み込むには、2つの方法があります。一つは NuGet 経由でインストールする方法、もう一つは当社のウェブサイトからパッケージをダウンロードし、ライブラリをプログラムにコピーする方法です。NuGet 経由のインストールの方が便利で、より推奨されます。詳しくは、以下のリンクからご覧いただけます。
Spire.Doc for C++ を C++ アプリケーションに統合する方法
Spire.Doc for C++ では、Word ドキュメントのセクションに表を追加するための Section->AddTable() メソッドを用意しています。詳しい手順は以下の通りです。
#include "Spire.Doc.o.h"
using namespace Spire::Doc;
using namespace std;
int main()
{
//Documentのインスタンスを作成する
intrusive_ptr<Document> doc = new Document();
//ドキュメントにセクションを追加する
intrusive_ptr<Section> section = doc->AddSection();
//セクションのページ余白を設定する
section->GetPageSetup()->GetMargins()->SetAll(72);
//ヘッダー行のデータを定義する
vector<wstring> header = { L"国名", L"首都", L"大陸", L"面積", L"人口" };
//残りの行のデータを定義する
vector<vector<wstring>> data =
{
{L"Argentina", L"Buenos Aires", L"南アメリカ", L"2777815", L"32300003"},
{L"Bolivia", L"La Paz", L"南アメリカ", L"1098575", L"7300000"},
{L"Brazil", L"Brasilia", L"南アメリカ", L"8511196", L"150400000"},
{L"Canada", L"Ottawa", L"北アメリカ", L"9976147", L"26500000"},
{L"Chile", L"Santiago", L"南アメリカ", L"756943", L"13200000"},
{L"Colombia", L"Bogota", L"南アメリカ", L"1138907", L"33000000"},
{L"Cuba", L"Havana", L"北アメリカ", L"114524", L"10600000"},
{L"Ecuador", L"Quito", L"南アメリカ", L"455502", L"10600000"},
{L"El Salvador", L"San Salvador", L"北アメリカ", L"20865", L"5300000"},
{L"Guyana", L"Georgetown", L"南アメリカ", L"214969", L"800000"},
{L"Jamaica", L"Kingston", L"北アメリカ", L"11424", L"2500000"},
{L"Mexico", L"Mexico City", L"北アメリカ", L"1967180", L"88600000"},
{L"Nicaragua", L"Managua", L"北アメリカ", L"139000", L"3900000"},
{L"Paraguay", L"Asuncion", L"南アメリカ", L"406576", L"4660000"},
{L"Peru", L"Lima", L"南アメリカ", L"1285215", L"21600000"},
{L"United States", L"Washington", L"北アメリカ", L"9363130", L"249200000"},
{L"Uruguay", L"Montevideo", L"南アメリカ", L"176140", L"3002000"},
{L"Venezuela", L"Caracas", L"南アメリカ", L"912047", L"19700000"}
};
//セクションに表を追加する
intrusive_ptr<Table> table = section->AddTable(true);
//表の行数、列数を指定する
table->ResetCells(data.size() + 1, header.size());
//最初の行をヘッダー行として設定する
intrusive_ptr<TableRow> row = table->GetRows()->GetItemInRowCollection(0);
row->SetIsHeader(true);
//ヘッダー列の高さと背景色を設定する
row->SetHeight(20);
row->SetHeightType(TableRowHeightType::Exactly);
row->GetRowFormat()->SetBackColor(Color::FromArgb(142, 170, 219));
//ヘッダー行にデータを追加し、書式を設定する
for (int i = 0; i < header.size(); i++)
{
//段落を追加する
intrusive_ptr<Paragraph> p1 = row->GetCells()->GetItemInCellCollection(i)->AddParagraph();
//配置を設定する
p1->GetFormat()->SetHorizontalAlignment(HorizontalAlignment::Center);
row->GetCells()->GetItemInCellCollection(i)->GetCellFormat()->SetVerticalAlignment(VerticalAlignment::Middle);
//データを追加する
intrusive_ptr<TextRange> tR1 = p1->AppendText(header[i].c_str());
//データの書式を設定する
tR1->GetCharacterFormat()->SetFontName(L"Yu Gothic UI");
tR1->GetCharacterFormat()->SetFontSize(12);
tR1->GetCharacterFormat()->SetBold(true);
}
//残りの行にデータを追加し、書式を設定する
for (int r = 0; r < data.size(); r++)
{
//残りの行の高さを設定する
intrusive_ptr<TableRow> dataRow = table->GetRows()->GetItemInRowCollection(r + 1);
dataRow->SetHeight(20);
dataRow->SetHeightType(TableRowHeightType::Exactly);
for (int c = 0; c < data[r].size(); c++)
{
//段落を追加する
intrusive_ptr<Paragraph> p2 = dataRow->GetCells()->GetItemInCellCollection(c)->AddParagraph();
//配置を設定する
dataRow->GetCells()->GetItemInCellCollection(c)->GetCellFormat()->SetVerticalAlignment(VerticalAlignment::Middle);
//データを追加する
intrusive_ptr<TextRange> tR2 = p2->AppendText(data[r][c].c_str());
//データの書式を設定する
tR2->GetCharacterFormat()->SetFontName(L"Yu Gothic UI");
tR2->GetCharacterFormat()->SetFontSize(11);
}
}
//ドキュメントを保存する
doc->SaveToFile(L"表の作成.docx", FileFormat::Docx2013);
doc->Close();
}
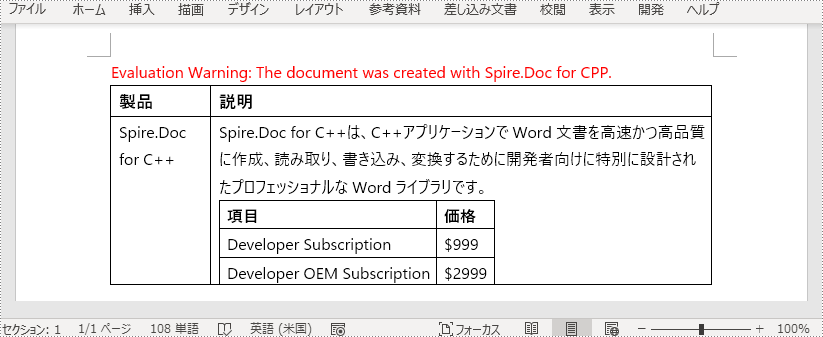
Spire.Doc for C++ では、特定の表セルにネストした表を追加する TableCell->AddTable() メソッドを用意しています。詳しい手順は以下の通りです。
#include "Spire.Doc.o.h"
using namespace Spire::Doc;
using namespace std;
int main()
{
//Documentのインスタンスを作成する
intrusive_ptr<Document> doc = new Document();
//ドキュメントにセクションを追加する
intrusive_ptr<Section> section = doc->AddSection();
//セクションのページ余白を設定する
section->GetPageSetup()->GetMargins()->SetAll(72);
//セクションに表を追加する
intrusive_ptr<Table> table = section->AddTable(true);
//表の行数、列数を設定する
table->ResetCells(2, 2);
//表の幅をウィンドウに自動調整する
table->AutoFit(AutoFitBehaviorType::AutoFitToWindow);
//表の行を取得する
intrusive_ptr<TableRow> row1 = table->GetRows()->GetItemInRowCollection(0);
intrusive_ptr<TableRow> row2 = table->GetRows()->GetItemInRowCollection(1);
//表のセルにデータを追加する
intrusive_ptr<TableCell> cell1 = row1->GetCells()->GetItemInCellCollection(0);
intrusive_ptr<TextRange> tR = cell1->AddParagraph()->AppendText(L"製品");
tR->GetCharacterFormat()->SetFontSize(13);
tR->GetCharacterFormat()->SetBold(true);
intrusive_ptr<TableCell> cell2 = row1->GetCells()->GetItemInCellCollection(1);
tR = cell2->AddParagraph()->AppendText(L"説明");
tR->GetCharacterFormat()->SetFontSize(13);
tR->GetCharacterFormat()->SetBold(true);
intrusive_ptr<TableCell> cell3 = row2->GetCells()->GetItemInCellCollection(0);
cell3->AddParagraph()->AppendText(L"Spire.Doc for C++");
intrusive_ptr<TableCell> cell4 = row2->GetCells()->GetItemInCellCollection(1);
cell4->AddParagraph()->AppendText(L"Spire.Doc for C++は、C++アプリケーションで"
L"Word文書を高速かつ高品質に作成、読み取り、書き込み、変換するために"
L"開発者向けに特別に設計されたプロフェッショナルなWordライブラリです。");
//表の文字のフォントを設定する
for (int m = 0; m < table->GetRows()->GetCount(); m++)
{
intrusive_ptr<TableRow> tableRow = table->GetRows()->GetItemInRowCollection(m);
for (int n = 0; n < tableRow->GetCells()->GetCount(); n++)
{
intrusive_ptr<TableCell> nestedTableCell = tableRow->GetCells()->GetItemInCellCollection(n);
nestedTableCell->GetFirstParagraph()->GetStyle()->GetCharacterFormat()->SetFontName(L"Yu Gothic UI");
}
}
//4つ目のセルにネストした表を追加する
intrusive_ptr<Table> nestedTable = cell4->AddTable(true);
//ネストした表の行数、列数を設定する
nestedTable->ResetCells(3, 2);
//表の幅をコンテンツに自動調整する
nestedTable->AutoFit(AutoFitBehaviorType::AutoFitToContents);
//表の行を取得する
intrusive_ptr<TableRow> nestedRow1 = nestedTable->GetRows()->GetItemInRowCollection(0);
intrusive_ptr<TableRow> nestedRow2 = nestedTable->GetRows()->GetItemInRowCollection(1);
intrusive_ptr<TableRow> nestedRow3 = nestedTable->GetRows()->GetItemInRowCollection(2);
//ネストした表のセルにデータを追加する
intrusive_ptr<TableCell> nestedCell1 = nestedRow1->GetCells()->GetItemInCellCollection(0);
tR = nestedCell1->AddParagraph()->AppendText(L"項目");
tR->GetCharacterFormat()->SetBold(true);
intrusive_ptr<TableCell> nestedCell2 = nestedRow1->GetCells()->GetItemInCellCollection(1);
tR = nestedCell2->AddParagraph()->AppendText(L"価格");
tR->GetCharacterFormat()->SetBold(true);
intrusive_ptr<TableCell> nestedCell3 = nestedRow2->GetCells()->GetItemInCellCollection(0);
nestedCell3->AddParagraph()->AppendText(L"Developer Subscription");
intrusive_ptr<TableCell> nestedCell4 = nestedRow2->GetCells()->GetItemInCellCollection(1);
nestedCell4->AddParagraph()->AppendText(L"$999");
intrusive_ptr<TableCell> nestedCell5 = nestedRow3->GetCells()->GetItemInCellCollection(0);
nestedCell5->AddParagraph()->AppendText(L"Developer OEM Subscription");
intrusive_ptr<TableCell> nestedCell6 = nestedRow3->GetCells()->GetItemInCellCollection(1);
nestedCell6->AddParagraph()->AppendText(L"$2999");
//ドキュメントを保存する
doc->SaveToFile(L"ネストされた表の作成.docx", FileFormat::Docx2013);
doc->Close();
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation for Java 8.4.2のリリースを発表できることをうれしく思います。このバージョンでは、SmartArtから取得したノードの座標値が正しくない問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPPT-2236 | SmartArtから取得したノードの座標値が正しくない問題が修正されました |
PDF は人気があり広く使われているファイル形式ですが、会議や授業などの場面で他者にプレゼンテーションを行う際には、PowerPoint の方が人気が高いことがよくあります。というのは、PowerPoint にはより豊富なプレゼンテーション効果が含まれており、聴衆の注意を引きつけることができるためです。この記事では、Spire.PDF for Java を使用して PDF を PowerPoint プレゼンテーションに変換する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.3.11</version>
</dependency>
</dependencies>Spire.PDF for Java 9.2.1 から、PdfDocument.saveToFile() メソッドを使用して PDF を PPTX に変換することができます。このメソッドを使用すると、PDF の各ページが PowerPoint の単一のスライドに変換することができます。詳細な手順は次のとおりです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class PDFtoPowerPoint {
public static void main(String[] args) {
//PdfDocument インスタンスを作成する
PdfDocument pdfDocument = new PdfDocument();
//サンプル PDF ドキュメントをロードする
pdfDocument.loadFromFile("sample.pdf");
//PDF を PPTX に変換する
pdfDocument.saveToFile("PDFtoPowerPoint.pptx", FileFormat.PPTX);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc for Java 11.4.2のリリースを発表できることを嬉しく思います。このバージョンは、Docx2016およびDocx2019ファイルフォーマットをサポートしています。さらに、目次のページ番号のみを更新する機能や、コメントの返信項目を取得する機能もサポートしています。また、WordからPDF、HTML、およびOFDへの変換機能も強化されました。修正を受けたページが縦向きから横向きに変わる問題など、既知の多くの問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-6422 | Docx2016およびDocx2019ファイルフォーマットをサポートしています。
Spire.Doc.FileFormat.Docx2016 Spire.Doc.FileFormat.Docx2019 |
| New feature | SPIREDOC-6913 | 目次のページ番号のみを更新する機能をサポートしています。
document.updateTOCPageNumbers(); document.updateTOCPageNumbers(TableOfContent toc); |
| New feature | SPIREDOC-9216 | コメントの返信項目を取得する機能をサポートしています。
Document doc = new Document();
doc.loadFromFile(inputFile);
Comment comment = doc.getComments().get(0);
CommentsCollection comCollect = comment.getReplyCommentItems();
String author = comCollect.get(0).getFormat().getAuthor();
Date dateTime = comCollect.get(0).getFormat().getDateTime();
String replayContent = "";
IDocumentObjectCollection objCollect = comCollect.get(0).getBody().getChildObjects();
for (int i = 0; i < objCollect.getCount(); i++) {
DocumentObject obj = objCollect.get(i);
if (obj.getDocumentObjectType() == DocumentObjectType.Paragraph) {
replayContent = ((Paragraph) obj).getText();
}
} |
| Bug | SPIREDOC-8680 | 修正を受けたページが縦向きから横向きに変わる問題が修正されました。 |
| Bug | SPIREDOC-8786 SPIREDOC-9159 |
WordをPDFに変換した後にレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8789 | WordをPDFに変換した後にフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-9019 | 目次ページ番号の更新が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9097 | RTFドキュメントをロードする際にアプリケーションが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9099 SPIREDOC-9123 SPIREDOC-9124 SPIREDOC-9177 |
WordをPDFに変換した後にテキストの改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9130 | WordをPDFに変換する際にアプリケーションが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9151 | ドキュメントのマージ後に数式を編集できない問題が修正されました。 |
| Bug | SPIREDOC-9153 | ドキュメントをロードして保存した後、フォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-9181 | WordをHTMLに変換した後に文字間隔のスケーリングスタイルが失われていた問題が修正されました。 |
| Bug | SPIREDOC-9196 | ドキュメントをロードする際にアプリケーションが「Cannot find stream '1Table' in the storage」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9227 | 2つのWordドキュメントを比較した後、PDFに変換すると、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9251 | WordをOFDに変換した後改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9260 | DOCドキュメントをロードする際にアプリケーションが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-9280 | 2つのWordドキュメントを比較する際にアプリケーションが「java.lang.IllegalArgumentException」をスローした問題が修正されました。 |
Word 文書を編集する際には、特定の段落を削除する理由がたくさんあります。例えば、ドキュメントを再構成するために単純に削除する場合や、誤った情報や関連のない情報を削除して文書の正確性を確保する場合などが考えられます。この記事では、Spire.Doc for C++ を使用して C++ で Word 文書で段落を削除する方法について説明します。
Spire.Doc for C++ をアプリケーションに組み込むには、2つの方法があります。一つは NuGet 経由でインストールする方法、もう一つは当社のウェブサイトからパッケージをダウンロードし、ライブラリをプログラムにコピーする方法です。NuGet 経由のインストールの方が便利で、より推奨されます。詳しくは、以下のリンクからご覧いただけます。
Spire.Doc for C++ を C++ アプリケーションに統合する方法
すべての段落を削除するには、文書内のすべてのセクションをループします。そして、Section->GetParagraphs()->Clear()メソッドを使用して各セクションのすべての段落を削除できます。詳細な手順は次のとおりです。
#include "Spire.Doc.o.h"
using namespace Spire::Doc;
int main() {
//入出力ファイルパスを指定する
std::wstring inputFile = L"Data\\sample.docx";
std::wstring outputFile = L"Output\\RemoveAllParagraphs.docx";
//Documentインスタンスを作成する
Document* document = new Document();
//Word文書をディスクからロードする
document->LoadFromFile(inputFile.c_str());
//文書の各セクションの段落を削除する
for (int i = 0; i < document->GetSections()->GetCount(); i++)
{
Section* section = document->GetSections()->GetItem(i);
section->GetParagraphs()->Clear();
}
//結果文書を保存する
document->SaveToFile(outputFile.c_str(), FileFormat::Docx2013);
document->Close();
delete document;
}
重複または役に立たない情報が含まれている段落を見つけた場合、Spire.Doc for C++ では、Section->GetParagraphs()->RemoveAt() メソッドを使用して、指定された段落を削除することができます。以下は詳細な手順です。
#include "Spire.Doc.o.h"
using namespace Spire::Doc;
int main() {
//入出力ファイルパスを指定する
std::wstring inputFile = L"Data\\sample.docx";
std::wstring outputFile = L"Output\\RemoveSpecificParagraph.docx";
//Documentインスタンスを作成する
Document* document = new Document();
//Word文書をディスクからロードする
document->LoadFromFile(inputFile.c_str());
//最初のセクションを取得する
Section* sec = document->GetSections()->GetItem(0);
//セクションの3番目の段落を削除する
sec->GetParagraphs()->RemoveAt(2);
//結果文書を保存する
document->SaveToFile(outputFile.c_str(), FileFormat::Docx2013);
document->Close();
delete document;
}
文書に空の段落/行がたくさんある場合は、読みやすくするためにそれらを削除する必要があります。以下は、Word 文書内のすべての空白の段落/行を削除する手順です。
#include "Spire.Doc.o.h"
using namespace Spire::Doc;
int main() {
//入出力ファイルパスを指定する
std::wstring inputFile = L"Data\\sample.docx";
std::wstring outputFile = L"Output\\RemoveEmptyLines.docx";
//Documentインスタンスを作成する
Document* document = new Document();
//Word文書をディスクからロードする
document->LoadFromFile(inputFile.c_str());
//Word文書内の各段落をループする
for (int i = 0; i < document->GetSections()->GetCount(); i++)
{
Section* section = document->GetSections()->GetItem(i);
for (int j = 0; j < section->GetBody()->GetChildObjects()->GetCount(); j++)
{
DocumentObject* secChildObject = section->GetBody()->GetChildObjects()->GetItem(j);
if (secChildObject->GetDocumentObjectType() == DocumentObjectType::Paragraph)
{
Paragraph* para = dynamic_cast<Paragraph*>(secChildObject);
std::wstring paraText = para->GetText();
//段落が空白段落かどうかを判断する
if (paraText.empty())
{
//空白段落を削除する
section->GetBody()->GetChildObjects()->Remove(secChildObject);
j--;
}
}
}
}
//結果文書を保存する
document->SaveToFile(outputFile.c_str(), FileFormat::Docx2013);
document->Close();
delete document;
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





