チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Microsoft Word のブックマークは、ドキュメント内のテキスト、画像、位置を示すことができ、いくつかの段落やページをスクロールすることなく、目的のテキスト、画像、または場所に直接ジャンプすることができます。これは、多くのページを含む研究論文や契約書を閲覧する際に、特に便利な機能です。この記事では、Spire.Doc for Java を使用して、Word ドキュメントにブックマークを追加または削除する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>詳細な手順は以下の通りです。
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
public class insertBookmark {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("実例.docx");
//最初のセクションを取得する
Section section = doc.getSections().get(0);
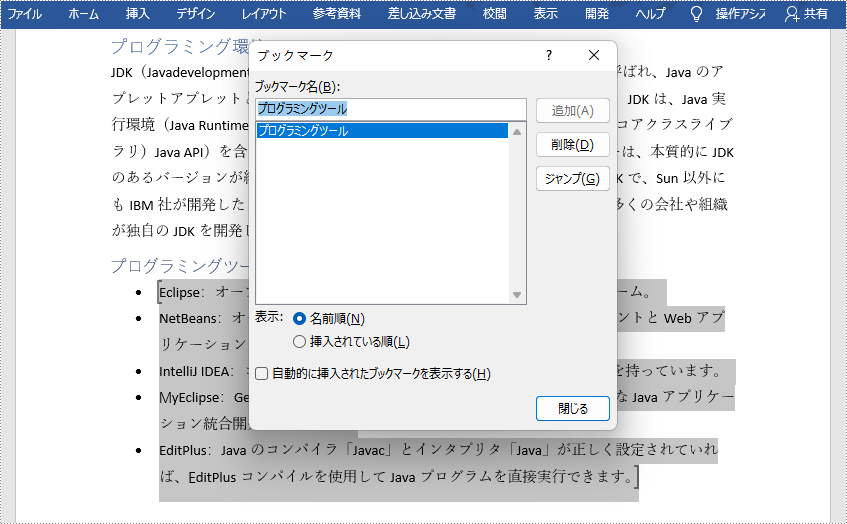
//ブックマークの先頭を挿入する
Paragraph paragraph = section.getParagraphs().get(6);
BookmarkStart bookmarkStart = paragraph.appendBookmarkStart("プログラミングツール");
paragraph.getItems().insert(0, bookmarkStart);
//ブックマークの末尾に挿入する
section.getParagraphs().get(10).appendBookmarkEnd("プログラミングツール");
//ドキュメントを保存する
doc.saveToFile("ブックマークの挿入.docx", FileFormat.Docx_2013);
}
}
詳細な手順は以下の通りです。
import com.spire.doc.*;
public class removeBookmark {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("ブックマークの挿入.docx");
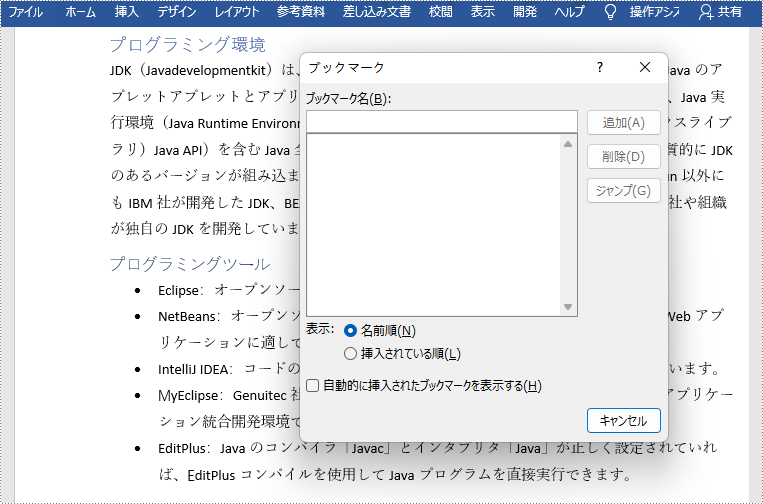
//特定のブックマークをインデックスで取得する
Bookmark bookmark = doc.getBookmarks().get(0);
//このブックマークを削除する
doc.getBookmarks().remove(bookmark);
//ドキュメントを保存する
doc.saveToFile("ブックマークの削除.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ハイパーリンクは通常テキストに表示されます。 ハイパーリンクをクリックすると、ウェブサイト、ドキュメント、電子メール、またはその他の要素にアクセスできます。Word ドキュメントの中には、特にインターネットから生成されたものには、広告のような不快なハイパーリンクが含まれていることがあります。この記事では、Spire.Doc for Java を使用して、Word ドキュメントから特定のハイパーリンクまたはすべてのハイパーリンクを削除する方法を説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Word ドキュメントから指定したハイパーリンクを削除する詳細な手順は以下のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.DocumentObjectType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.UnderlineStyle;
import com.spire.doc.fields.Field;
import com.spire.doc.fields.TextRange;
import java.awt.*;
import java.util.ArrayList;
public class removeOneHyperlink {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成し、Wordドキュメントを読み込む
String input = "実例.docx";
Document doc = new Document();
doc.loadFromFile(input);
//すべてのハイパーリンクを検索する
ArrayList hyperlinks = FindAllHyperlinks(doc);
//最初のハイパーリンクの形式を削除する
FlattenHyperlinks(hyperlinks.get(0));
//ドキュメントを保存する
String output = "ハイパーリンクの削除.docx";
doc.saveToFile(output, FileFormat.Docx);
}
//ドキュメントからすべてのハイパーリンクを取得するメソッド FindAllHyperlinks() を作成する
private static ArrayList FindAllHyperlinks(Document document)
{
ArrayList hyperlinks = new ArrayList();
//セクション内の項目をループして、すべてのハイパーリンクを検索する
for (Section section : (Iterable)document.getSections())
{
for (DocumentObject object : (Iterable)section.getBody().getChildObjects())
{
if (object.getDocumentObjectType().equals(DocumentObjectType.Paragraph))
{
Paragraph paragraph = (Paragraph) object;
for (DocumentObject cObject : (Iterable)paragraph.getChildObjects())
{
if (cObject.getDocumentObjectType().equals(DocumentObjectType.Field))
{
Field field = (Field) cObject;
if (field.getType().equals(FieldType.Field_Hyperlink))
{
hyperlinks.add(field);
}
}
}
}
}
}
return hyperlinks;
}
//ハイパーリンクの形式を削除するメソッドFlattenHyperlinks()を作成する
public static void FlattenHyperlinks(Field field)
{
int ownerParaIndex = field.getOwnerParagraph().ownerTextBody().getChildObjects().indexOf(field.getOwnerParagraph());
int fieldIndex = field.getOwnerParagraph().getChildObjects().indexOf(field);
Paragraph sepOwnerPara = field.getSeparator().getOwnerParagraph();
int sepOwnerParaIndex = field.getSeparator().getOwnerParagraph().ownerTextBody().getChildObjects().indexOf(field.getSeparator().getOwnerParagraph());
int sepIndex = field.getSeparator().getOwnerParagraph().getChildObjects().indexOf(field.getSeparator());
int endIndex = field.getEnd().getOwnerParagraph().getChildObjects().indexOf(field.getEnd());
int endOwnerParaIndex = field.getEnd().getOwnerParagraph().ownerTextBody().getChildObjects().indexOf(field.getEnd().getOwnerParagraph());
FormatFieldResultText(field.getSeparator().getOwnerParagraph().ownerTextBody(), sepOwnerParaIndex, endOwnerParaIndex, sepIndex, endIndex);
field.getEnd().getOwnerParagraph().getChildObjects().removeAt(endIndex);
for (int i = sepOwnerParaIndex; i >= ownerParaIndex; i--)
{
if (i == sepOwnerParaIndex && i == ownerParaIndex)
{
for (int j = sepIndex; j >= fieldIndex; j--)
{
field.getOwnerParagraph().getChildObjects().removeAt(j);
}
}
else if (i == ownerParaIndex)
{
for (int j = field.getOwnerParagraph().getChildObjects().getCount() - 1; j >= fieldIndex; j--)
{
field.getOwnerParagraph().getChildObjects().removeAt(j);
}
}
else if (i == sepOwnerParaIndex)
{
for (int j = sepIndex; j >= 0; j--)
{
sepOwnerPara.getChildObjects().removeAt(j);
}
}
else
{
field.getOwnerParagraph().ownerTextBody().getChildObjects().removeAt(i);
}
}
}
//ハイパーリンクの文字の色と下線を除去するメソッド FormatFieldResultText() を作成する
private static void FormatFieldResultText(Body ownerBody, int sepOwnerParaIndex, int endOwnerParaIndex, int sepIndex, int endIndex)
{
for (int i = sepOwnerParaIndex; i <= endOwnerParaIndex; i++)
{
Paragraph para = (Paragraph) ownerBody.getChildObjects().get(i);
if (i == sepOwnerParaIndex && i == endOwnerParaIndex)
{
for (int j = sepIndex + 1; j < endIndex; j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
else if (i == sepOwnerParaIndex)
{
for (int j = sepIndex + 1; j < para.getChildObjects().getCount(); j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
else if (i == endOwnerParaIndex)
{
for (int j = 0; j < endIndex; j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
else
{
for (int j = 0; j < para.getChildObjects().getCount(); j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
}
}
//テキストの色を黒に変更し、下線を除去するメソッドFormatText()を作成する
private static void FormatText(TextRange tr)
{
//文字色を黒に設定する
tr.getCharacterFormat().setTextColor(Color.black);
//テキストの下線スタイルを「None」にする
tr.getCharacterFormat().setUnderlineStyle(UnderlineStyle.None);
}
}
Word ドキュメントからすべてのハイパーリンクを削除する詳細な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.DocumentObjectType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.UnderlineStyle;
import com.spire.doc.fields.Field;
import com.spire.doc.fields.TextRange;
import java.awt.*;
import java.util.ArrayList;
public class removeAllHyperlinks {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成し、Wordドキュメントを読み込む
String input = "実例.docx";
Document doc = new Document();
doc.loadFromFile(input);
//すべてのハイパーリンクを検索する
ArrayList hyperlinks = FindAllHyperlinks(doc);
//ハイパーリンクをループして、削除します
for (int i = hyperlinks.size() -1; i >= 0; i--)
{
FlattenHyperlinks(hyperlinks.get(i));
}
//ドキュメントを保存する
String output = "すべてのハイパーリンクの削除.docx";
doc.saveToFile(output, FileFormat.Docx);
}
//ドキュメントからすべてのハイパーリンクを取得するメソッド FindAllHyperlinks() を作成する
private static ArrayList FindAllHyperlinks(Document document)
{
ArrayList hyperlinks = new ArrayList();
//セクション内の項目をループして、すべてのハイパーリンクを検索する
for (Section section : (Iterable)document.getSections())
{
for (DocumentObject object : (Iterable)section.getBody().getChildObjects())
{
if (object.getDocumentObjectType().equals(DocumentObjectType.Paragraph))
{
Paragraph paragraph = (Paragraph) object;
for (DocumentObject cObject : (Iterable)paragraph.getChildObjects())
{
if (cObject.getDocumentObjectType().equals(DocumentObjectType.Field))
{
Field field = (Field) cObject;
if (field.getType().equals(FieldType.Field_Hyperlink))
{
hyperlinks.add(field);
}
}
}
}
}
}
return hyperlinks;
}
//ハイパーリンクを削除するFlattenHyperlinks()メソッドを作成する
public static void FlattenHyperlinks(Field field)
{
int ownerParaIndex = field.getOwnerParagraph().ownerTextBody().getChildObjects().indexOf(field.getOwnerParagraph());
int fieldIndex = field.getOwnerParagraph().getChildObjects().indexOf(field);
Paragraph sepOwnerPara = field.getSeparator().getOwnerParagraph();
int sepOwnerParaIndex = field.getSeparator().getOwnerParagraph().ownerTextBody().getChildObjects().indexOf(field.getSeparator().getOwnerParagraph());
int sepIndex = field.getSeparator().getOwnerParagraph().getChildObjects().indexOf(field.getSeparator());
int endIndex = field.getEnd().getOwnerParagraph().getChildObjects().indexOf(field.getEnd());
int endOwnerParaIndex = field.getEnd().getOwnerParagraph().ownerTextBody().getChildObjects().indexOf(field.getEnd().getOwnerParagraph());
FormatFieldResultText(field.getSeparator().getOwnerParagraph().ownerTextBody(), sepOwnerParaIndex, endOwnerParaIndex, sepIndex, endIndex);
field.getEnd().getOwnerParagraph().getChildObjects().removeAt(endIndex);
for (int i = sepOwnerParaIndex; i >= ownerParaIndex; i--)
{
if (i == sepOwnerParaIndex && i == ownerParaIndex)
{
for (int j = sepIndex; j >= fieldIndex; j--)
{
field.getOwnerParagraph().getChildObjects().removeAt(j);
}
}
else if (i == ownerParaIndex)
{
for (int j = field.getOwnerParagraph().getChildObjects().getCount() - 1; j >= fieldIndex; j--)
{
field.getOwnerParagraph().getChildObjects().removeAt(j);
}
}
else if (i == sepOwnerParaIndex)
{
for (int j = sepIndex; j >= 0; j--)
{
sepOwnerPara.getChildObjects().removeAt(j);
}
}
else
{
field.getOwnerParagraph().ownerTextBody().getChildObjects().removeAt(i);
}
}
}
//テキスト形式を設定するメソッド FormatFieldResultText() を作成します。
private static void FormatFieldResultText(Body ownerBody, int sepOwnerParaIndex, int endOwnerParaIndex, int sepIndex, int endIndex)
{
for (int i = sepOwnerParaIndex; i <= endOwnerParaIndex; i++)
{
Paragraph para = (Paragraph) ownerBody.getChildObjects().get(i);
if (i == sepOwnerParaIndex && i == endOwnerParaIndex)
{
for (int j = sepIndex + 1; j < endIndex; j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
else if (i == sepOwnerParaIndex)
{
for (int j = sepIndex + 1; j < para.getChildObjects().getCount(); j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
else if (i == endOwnerParaIndex)
{
for (int j = 0; j < endIndex; j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
else
{
for (int j = 0; j < para.getChildObjects().getCount(); j++)
{
FormatText((TextRange)para.getChildObjects().get(j));
}
}
}
}
//テキストの色を黒に変更し、下線を削除するメソッドFormatText()を作成する
private static void FormatText(TextRange tr)
{
//文字色を黒に設定する
tr.getCharacterFormat().setTextColor(Color.black);
//テキストの下線スタイルを「None」に設定する
tr.getCharacterFormat().setUnderlineStyle(UnderlineStyle.None);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office for Java 7.8.0 のリリースを発表できることをうれしく思います。今回のアップデートには、いくつかの新機能が含まれています。Spire.XLS for Java はカスタムソートがサポートして、Excel 2016 で定義された Chart タイプを PDF と画像に変換がサポートしました。Spire.Presentation for Java は PPT ドキュメント内のすべてのスライドを 1 つの SVG ファイルに変換したり、PPTM フォーマット・ドキュメント内のマクロを削除したりすることがサポートしました。また、isSlideSizeAutoFit()メソッドを提供し、スライドをクローンするときに、スライドのサイズに合わせて内容を調整しました。Spire.Doc for Java は Word と HTML の PDF への変換機能を強化しました。Spire.PDF for Java は、PDF から画像、OFD、PDF/A3A、およびTiffから PDF への変換機能を強化しました。さらに、多くの既知のバグが正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-3704 | カスタムソートがサポートしました。
wb.getDataSorter().getSortColumns().add(0, new String[]
{"12345","Argentina", "Area", "Chile", "Capital","USA","Ecuador","Guyana"}
); wb.getDataSorter().sort(wb.getWorksheets().get(0).getRange().get("A1:A8")); |
| New feature | - | Excel 2016 で定義された Chart タイプをPDFと画像に変換がサポートしました。 |
| Bug | SPIREXLS-3524 | Excel を PDF に変換した後に、グラフの内容が間違っていた問題が修正されました。 |
| Bug | SPIREXLS-3862 | Excel をHtml に変換した後に、線の色を変更する問題が修正されました。 |
| Bug | SPIREXLS-3863 | Excel を Html に変換した後に、グラフがぼやけていた問題が修正されました。 |
| Bug | SPIREXLS-3975 | データシートを sheet にインポートした後に、データが正しくない問題を修正しました。 |
| Bug | SPIREXLS-3976 | トレンド線をグラフに追加した後に、線のスタイルが変更された問題が修正されました。 |
| Bug | SPIREXLS-3979 | グラフを画像に変換した後に、X軸の内容が正しく表示されない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-1983 | PPTM フォーマット・ドキュメント内のマクロの削除をサポートしました |
| New feature | SPIREPPT-1995 | isSlideSizeAutoFit() メソッドを提供し、スライドをクローンするときに、スライドのサイズに合わせて内容を調整しました。
Note: 現在は 4:3->16:9 のみサポートしました。
Presentation presentation1 =new Presentation(); presentation1.loadFromFile(inputFile_1); Presentation presentation2 =new Presentation(); presentation2.loadFromFile(inputFile_2); presentation1.isSlideSizeAutoFit(true); ILayout layout = presentation1.getSlides().get(0).getLayout(); presentation1.getSlides().append(presentation2.getSlides().get(0),layout); presentation1.saveToFile(outputFile, FileFormat.PPTX_2013); |
| New feature | SPIREPPT-1996 | PPT ドキュメント内のすべてのスライドを 1 つの SVG ファイルに変換することがサポートしました。
byte[] bytes=ppt.saveToOneSVG();
try(java.io.FileOutputStream stream = new java.io.FileOutputStream(outputFile)){
stream.write(bytes);
}
|
| Bug | SPIREPPT-1982 | PPT を画像に変換し、プログラムが「NullPointerException」および「Unsupported Image Type」をスローする問題を修正しました。 |
| Bug | SPIREPPT-1990 | スライドから PPT ドキュメントを分割した後、テキスト フォントが小さくなる問題を修正しました。 |
| Bug | SPIREPPT-1991 | setShowLoop(true) を設定してスライドをループ再生するときに、最初のスライドを再生した後に停止する問題が修正されました。 |
| Bug | SPIREPPT-1994 | PPT ファイルの読み込み速度が最適化されました。 |
| Bug | SPIREPPT-2000 | slide.SaveToFile() メソッド名を saveToFile()に、SaveToSVG() メソッド名を saveToSVG() に調整しました。 |
| Bug | SPIREPPT-2004 | PPT を画像に変換し、プログラムが「Java heap space」をスローする問題を修正しました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-4372 | WordからPDFへの変換でアプリケーションが保留になる問題を修正しました。 |
| Bug | SPIREDOC-6957 | HTMLをPDFに変換すると、アプリケーションが「IndexOutOfBoundException」をスローする問題を修正しました。 |
| Bug | SPIREDOC-7123 | パスワード保護されたドキュメントをロードするときに、パスワードが失われた問題が修正されました。 |
| Bug | SPIREDOC-7524 | WordをHTMLに変換すると、プロジェクト番号が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7620 SPIREDOC-7628 SPIREDOC-7732 SPIREDOC-7736 SPIREDOC-7737 SPIREDOC-7750 SPIREDOC-7751 SPIREDOC-7752 SPIREDOC-7907 SPIREDOC-8005 SPIREDOC-8009 SPIREDOC-8060 SPIREDOC-8062 |
WordをPDFに変換すると、ページ分けが正しくない問題を修正しました。 |
| Bug | SPIREDOC-7658 SPIREDOC-8043 |
WordをPDFに変換すると、テキストの改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7713 SPIREDOC-7741 SPIREDOC-7831 SPIREDOC-7999 |
WordをPDFに変換すると、内容が重なる問題が修正されました。 |
| Bug | SPIREDOC-7739 | WordをPDFに変換すると、横線の位置が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7748 | WordをPDFに変換すると、数字の位置が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7758 | WordをPDFに変換すると、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-7820 | WordをPDFに変換すると、表のテキストが中央に揃えされていない問題が修正されました。 |
| Bug | SPIREDOC-7851 | docPicture.setWidthScaleとdocPicture.setHeightScaleプロパティの設定が有効でない問題を修正しました。 |
| Bug | SPIREDOC-7913 | HTMLをPDFに変換すると、内容の表示が不完全で表の効果が悪い問題を修正した。 |
| Bug | SPIREDOC-7912 | HTMLを画像に変換すると、表形式が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7914 SPIREDOC-7926 SPIREDOC-7932 SPIREDOC-7942 |
WordをPDFに変換すると、小数点がカバーされていた問題が修正されました。 |
| Bug | SPIREDOC-7955 | WordをPDFに変換すると、内容が空白になっていた問題が修正されました。 |
| Bug | SPIREDOC-7966 | WordをPDFに変換すると、日付が重複していた問題が修正されました。 |
| Bug | SPIREDOC-7981 | WordをPDFに変換すると、表の枠線が失われた問題が修正されました。 |
| Bug | SPIREDOC-8011 | LatexMathCodeを追加した、結果が空になっていた問題が修正されました。 |
| Bug | SPIREDOC-8012 | LatexMathCodeを追加した、結果が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8039 | WordをPDFに変換すると、セルのテキスト順序が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8040 | WordをPDFに変換すると、セルのテキストの改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8065 | WordをPDFに変換すると、表の内容が混乱していた問題が修正されました。 |
| Bug | SPIREDOC-8078 | テーブルセルを削除した、アプリケーションが「IndexOutOfBoundException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8087 | WordをPDFに変換すると、テキストの改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8093 | HTMLをWordに挿入し、アプリケーションが「Unknow char:\ 」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8104 | 新しいエンジンでWordをPDFに変換した、テキスト文字化けの問題が修正されました。 |
| Bug | SPIREDOC-8155 | ドキュメントをロードすると、アプリケーションが「Unknown char: '」 |
| Bug | SPIREDOC-8172 | WordをPDFに変換すると、ドメインデータが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8201 | WordをPDFに変換すると、小数点が失われた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5248 | PDF/A3AにPDFを変換した後、一部のキャラクタが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5312 | PDFをTiffに変換するときに、アプリケーションが「Parameter is invalid」をスローした問題を修正しました。 |
| Bug | SPIREPDF-5322 | PDFを画像に変換した後、テキストの位置が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5327 | OFDにPDFを変換した後、Dotpoly OFDリーダで開いたコンテンツが失われる問題を修正しました。 |
| Bug | SPIREPDF-5332 | PDFを画像に変換した後、テキスト表示が間違っていた問題が修正されました。 |
| Bug | SPIREPDF-5337 | PDFにTiffを変換する際に、アプリケーションが「No have this TiffTag」をスローした問題を修正しました。 |
| Bug | SPIREPDF-5350 | PDFをOFDに変換した後、コンテンツが失われていた問題が修正されました。 |
| Bug | SPIREPDF-5362 | PDFドキュメントをロードする際に、アプリケーションが「NullPointerException」をスローした問題を修正しました。 |
Spire.PDF for Java 8.8.0 のリリースを発表できることをうれしく思います。このバージョンは、PDF から画像、OFD、PDF/A3A、および Tiff から PDF への変換機能を強化しました。また、このリリースでは、PDF ドキュメントをロードする際に、アプリケーションが「NullPointerException」をスローしたなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5248 | PDF/A3AにPDFを変換した後、一部のキャラクタが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5312 | PDFをTiffに変換するときに、アプリケーションが「Parameter is invalid」をスローした問題を修正しました。 |
| Bug | SPIREPDF-5322 | PDFを画像に変換した後、テキストの位置が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5327 | OFDにPDFを変換した後、Dotpoly OFDリーダで開いたコンテンツが失われる問題を修正しました。 |
| Bug | SPIREPDF-5332 | PDFを画像に変換した後、テキスト表示が間違っていた問題が修正されました。 |
| Bug | SPIREPDF-5337 | PDFにTiffを変換する際に、アプリケーションが「No have this TiffTag」をスローした問題を修正しました。 |
| Bug | SPIREPDF-5350 | PDFをOFDに変換した後、コンテンツが失われていた問題が修正されました。 |
| Bug | SPIREPDF-5362 | PDFドキュメントをロードする際に、アプリケーションが「NullPointerException」をスローした問題を修正しました。 |
Word 文書におけるハイパーリンクは、通常、青い書体に下線を付けて表示されます。実は、ハイパーリンクの既定のスタイルが気に入らない場合、リンクを維持したままハイパーリンクの色を変更したり、下線を削除して独自のハイパーリンクのスタイルにすることができます。この記事では、Spire.Doc for Java を使用して、Word のハイパーリンクの色を変更したり、下線を削除したりする方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>詳細な手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.*;
import com.spire.doc.fields.TextRange;
import java.awt.*;
public class ChangeHyperlink {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//セクションを追加する
Section section = document.addSection();
//段落を追加する
Paragraph para= section.addParagraph();
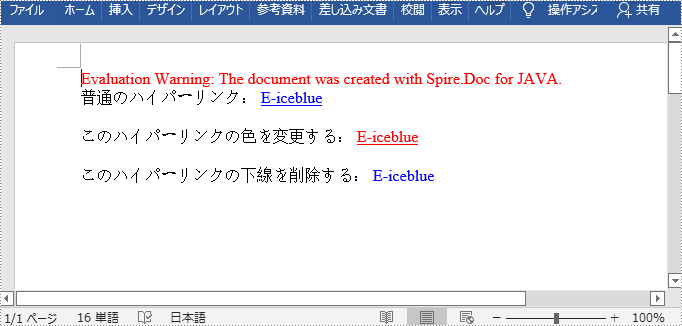
para.appendText("普通のハイパーリンク: ");
//ハイパーリンクを挿入する
TextRange textRange = para.appendHyperlink("www.e-iceblue.com", "E-iceblue", HyperlinkType.Web_Link);
textRange.getCharacterFormat().setFontName("Times New Roman");
textRange.getCharacterFormat().setFontSize(12f);
para.appendBreak(BreakType.Line_Break);
//段落を追加する
para = section.addParagraph();
para.appendText("このハイパーリンクの色を変更する: ");
//ハイパーリンクを挿入する
textRange = para.appendHyperlink("www.e-iceblue.com", "E-iceblue", HyperlinkType.Web_Link);
textRange.getCharacterFormat().setFontName("Times New Roman");
textRange.getCharacterFormat().setFontSize(12f);
//ハイパーリンクの色を赤に変更する
textRange.getCharacterFormat().setTextColor(Color.RED);
para.appendBreak(BreakType.Line_Break);
//段落を追加する
para = section.addParagraph();
para.appendText("このハイパーリンクの下線を削除する: ");
//ハイパーリンクを挿入する
textRange = para.appendHyperlink("www.e-iceblue.com", "E-iceblue", HyperlinkType.Web_Link);
textRange.getCharacterFormat().setFontName("Times New Roman");
textRange.getCharacterFormat().setFontSize(12f);
//ハイパーリンクの下線を削除する
textRange.getCharacterFormat().setUnderlineStyle(UnderlineStyle.None);
//ドキュメントを保存する
document.saveToFile("ハイパーリンクのスタイルの変更.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
脚注は、Word ドキュメントに追加情報や詳細な説明を提供するために一般的に使用されます。長くて複雑な単語やフレーズは、読者が文章を読みにくくします。しかし、本文に関連情報や説明を提供すると、文章の一貫性が損なわれ、文章が冗長になります。幸いなことに、脚注は、文章の流暢さと簡潔さを損なうことなく、ページの終わりに情報や説明を与えるために作者を助けることができます。この記事では、Spire.Doc for Java を使用して Word ドキュメントに脚注を挿入または削除する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>脚注を挿入する詳細な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.awt.*;
public class insertFootnote {
public static void main(String[] args) {
//Document クラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("実例.docx");
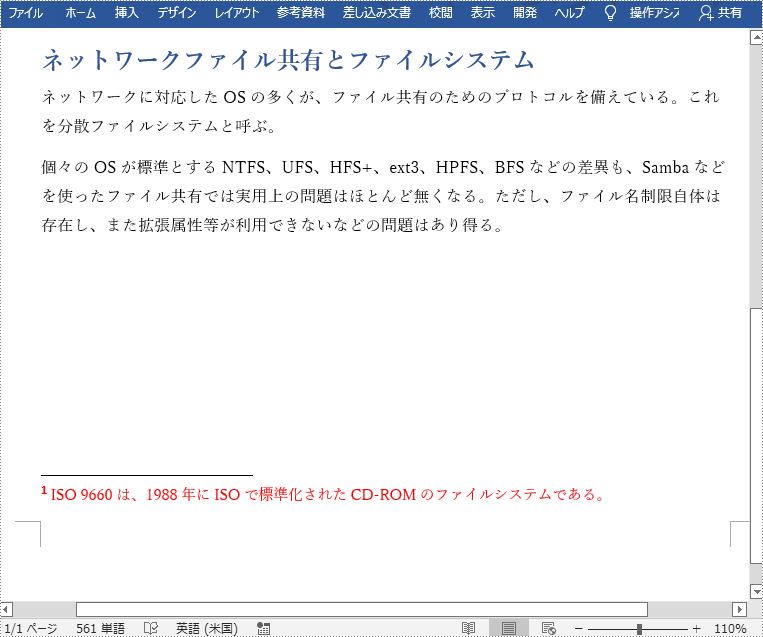
//注釈を付けるテキストを検索する
TextSelection selection = document.findString("ISO 9660", false, true);
//脚注を挿入する
TextRange textRange = selection.getAsOneRange();
Paragraph paragraph = textRange.getOwnerParagraph();
int index = paragraph.getChildObjects().indexOf(textRange);
Footnote footnote = paragraph.appendFootnote(FootnoteType.Footnote);
paragraph.getChildObjects().insert(index + 1, footnote);
//脚注に段落を追加する
Paragraph paragraph1 = footnote.getTextBody().addParagraph();
//追加された段落にテキストを追加する
textRange = paragraph1.appendText("ISO 9660は、1988年にISOで標準化されたCD-ROMのファイルシステムである。");
//脚注のテキスト書式を設定する
textRange.getCharacterFormat().setFontName("Yu Mincho");
textRange.getCharacterFormat().setFontSize(10);
textRange.getCharacterFormat().setTextColor(Color.RED);
//マーカーのテキスト書式を設定する
footnote.getMarkerCharacterFormat().setFontName("Calibri");
footnote.getMarkerCharacterFormat().setFontSize(12);
footnote.getMarkerCharacterFormat().setBold(true);
footnote.getMarkerCharacterFormat().setTextColor(Color.red);
//ドキュメントを保存する
String output = "脚注の挿入.docx";
document.saveToFile(output, FileFormat.Docx_2010);
}
}
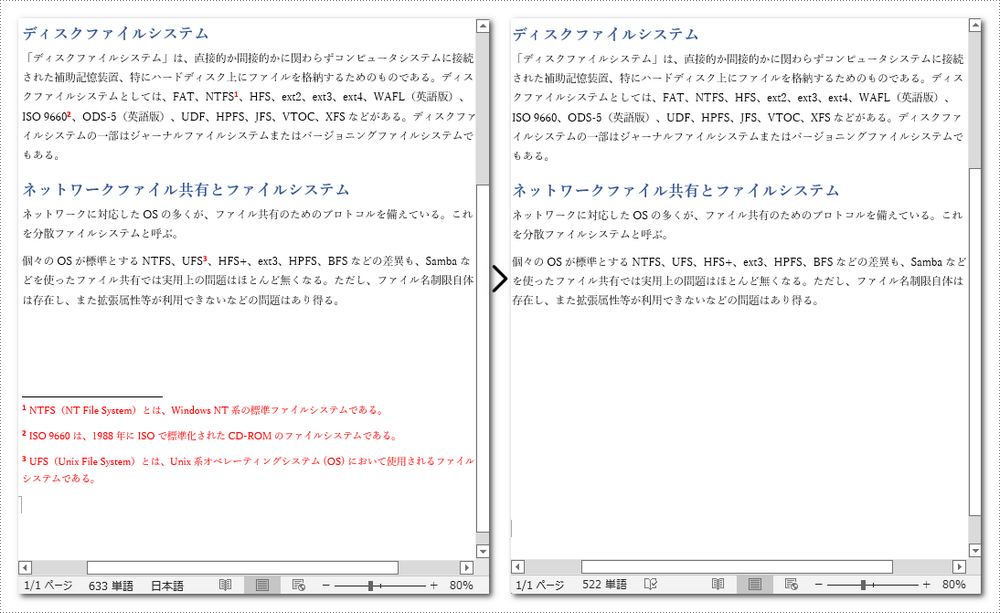
脚注を削除する詳細な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.fields.*;
import com.spire.doc.documents.*;
import java.util.*;
public class removeFootnote {
public static void main(String[] args) {
//Document クラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("実例.docx");
//セクションをループする
for (int i = 0; i < document.getSections().getCount(); i++) {
//特定のセクションを取得する
Section section = document.getSections().get(i);
//セクション内の段落をループする
for (int j = 0; j < section.getParagraphs().getCount(); j++)
{
//特定の段落を取得する
Paragraph para = section.getParagraphs().get(j);
//リストを作成する
List footnotes = new ArrayList<>();
//段落の中の子オブジェクトをループする
for (int k = 0, cnt = para.getChildObjects().getCount(); k < cnt; k++)
{
//特定の子オブジェクトを取得する
ParagraphBase pBase = (ParagraphBase)para.getChildObjects().get(k);
//子オブジェクトが脚注であるかどうかを判定する
if (pBase instanceof Footnote)
{
Footnote footnote = (Footnote)pBase;
//脚注をリストに追加する
footnotes.add(footnote);
}
}
if (footnotes != null) {
//リストにある脚注をループする
for (int y = 0; y < footnotes.size(); y++) {
//特定の脚注を削除する
para.getChildObjects().remove(footnotes.get(y));
}
}
}
}
//ドキュメントを保存する
document.saveToFile("脚注の削除.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc for Java は、Word を PDF、XPS、SVG、HTML などの他のドキュメント形式に変換するための Document.saveToFile() メソッドを提供しています。この記事では、Spire.Doc for Java を使用して Word を PDF に変換する方法について紹介します。さらに、Word ドキュメントをどのように PDF に変換するかを制御するために、ToPdfParameterList クラスを導入しています。例えば、生成される PDF ドキュメント内のハイパーリンクを無効にするかどうかなどです。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>以下は、Word を PDF に変換するための詳細な手順です。
import com.spire.doc.Document;
import com.spire.doc.ToPdfParameterList;
public class WordToPDF {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("実例.docx");
//ToPdfParameterListクラスのインスタンスを作成する
ToPdfParameterList ppl=new ToPdfParameterList();
//PDFドキュメントにすべての書体を埋め込む
ppl.isEmbeddedAllFonts(true);
//ハイパーリンクを削除し、文字の書式を維持する
ppl.setDisableLink(true);
//出力画質を原画の40%に設定します。80%は初期設定です。
doc.setJPEGQuality(40);
//ドキュメントをPDFで保存する
doc.saveToFile("WordToPDF.pdf", ppl);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
同じタイプまたはカテゴリの Excel ファイルをマージすることで、複数のファイルを同時に開くことを回避し、時間を節約できます。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET でプログラムによって Excel ファイルをマージする方法を紹介します。
まず、Spire.XLS for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLS以下は、複数の Excel ファイルを1つの Excel ファイルにマージする手順です。
using Spire.Xls;
namespace MergeExcelFiles
{
class Program
{
static void Main(string[] args)
{
//マージが必要なExcelファイルのパスを文字列配列に保存する
string[] inputFiles = new string[] { "2019.xlsx", "2020.xlsx", "2021.xlsx" };
//Workbookクラスのオブジェクトを初期化する
Workbook newWorkbook = new Workbook();
//ワークブック内のデフォルトのワークシートを消去する
newWorkbook.Worksheets.Clear();
//別の一時的なWorkbookクラスのオブジェクトを初期化する
Workbook tempWorkbook = new Workbook();
//文字列配列をループする
foreach (string file in inputFiles)
{
//現在のワークブックをロードする
tempWorkbook.LoadFromFile(file);
//現在のワークブック内のワークシートをループする
foreach (Worksheet sheet in tempWorkbook.Worksheets)
{
//各ワークシートを現在のワークブックから新しいワークブックにコピーする
newWorkbook.Worksheets.AddCopy(sheet, WorksheetCopyType.CopyAll);
}
}
//新しいワークブックをファイルに保存する
newWorkbook.SaveToFile("MergeWorkbooks.xlsx", ExcelVersion.Version2013);
}
}
}Imports Spire.Xls
Namespace MergeExcelFiles
Friend Class Program
Private Shared Sub Main(ByVal args As String())
' マージが必要なExcelファイルのパスを文字列配列に保存する
Dim inputFiles = New String() {"2019.xlsx", "2020.xlsx", "2021.xlsx"}
' Workbookクラスのオブジェクトを初期化する
Dim newWorkbook As Workbook = New Workbook()
'ワークブック内のデフォルトのワークシートを消去する
newWorkbook.Worksheets.Clear()
'別の一時的なWorkbookクラスのオブジェクトを初期化する
Dim tempWorkbook As Workbook = New Workbook()
'文字列配列をループする
For Each file In inputFiles
'現在のワークブックをロードする
tempWorkbook.LoadFromFile(file)
'現在のワークブック内のワークシートをループする
For Each sheet As Worksheet In tempWorkbook.Worksheets
'各ワークシートを現在のワークブックから新しいワークブックにコピーする
newWorkbook.Worksheets.AddCopy(sheet, WorksheetCopyType.CopyAll)
Next
Next
'新しいワークブックをファイルに保存する
newWorkbook.SaveToFile("MergeWorkbooks.xlsx", ExcelVersion.Version2013)
End Sub
End Class
End Namespace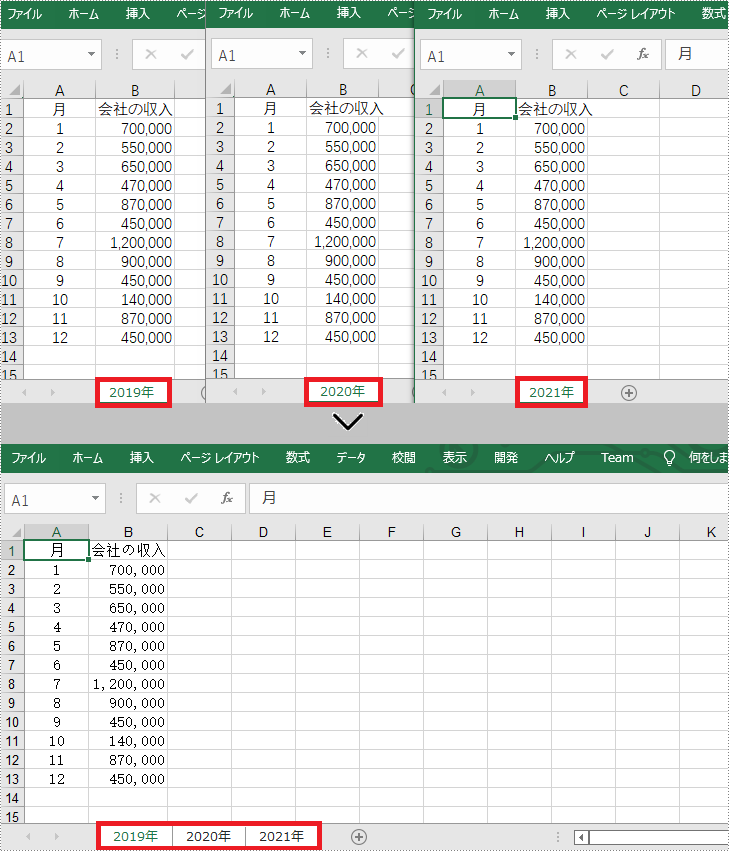
以下は、Excel ファイル内の複数のワークシートのデータを 1つのワークシートにマージする手順です。
using Spire.Xls;
namespace MergeExcelWorksheets
{
class Program
{
static void Main(string[] args)
{
//Workbookクラスのオブジェクトを初期化する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.LoadFromFile("Sample.xlsx");
//最初のワークシートを取得する
Worksheet sheet1 = workbook.Worksheets[0];
//2つ目のワークシートを取得する
Worksheet sheet2 = workbook.Worksheets[1];
//2つ目のワークシートの使用範囲を取得する
CellRange sourceRange = sheet2.AllocatedRange;
//最初のワークシートのターゲット範囲を指定する
CellRange destRange = sheet1.Range[sheet1.LastRow + 1, 1];
//2つ目のワークシートの使用範囲を1つ目のワークシートのターゲット範囲にコピーする
sourceRange.Copy(destRange);
//2番目のシートを削除する
sheet2.Remove();
//結果ファイルを保存する
workbook.SaveToFile("MergeWorksheets.xlsx", ExcelVersion.Version2013);
}
}
}Imports Spire.Xls
Namespace MergeExcelWorksheets
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Workbookクラスのオブジェクトを初期化する
Dim workbook As Workbook = New Workbook()
'Excelファイルをロードする
workbook.LoadFromFile("Sample.xlsx")
'最初のワークシートを取得する
Dim sheet1 As Worksheet = workbook.Worksheets(0)
'2つ目のワークシートを取得する
Dim sheet2 As Worksheet = workbook.Worksheets(1)
'2つ目のワークシートの使用範囲を取得する
Dim sourceRange As CellRange = sheet2.AllocatedRange
'最初のワークシートのターゲット範囲を指定する
Dim destRange As CellRange = sheet1.Range(sheet1.LastRow + 1, 1)
'2つ目のワークシートの使用範囲を1つ目のワークシートのターゲット範囲にコピーする
sourceRange.Copy(destRange)
'2番目のシートを削除する
sheet2.Remove()
'結果ファイルを保存する
workbook.SaveToFile("MergeWorksheets.xlsx", ExcelVersion.Version2013)
End Sub
End Class
End Namespace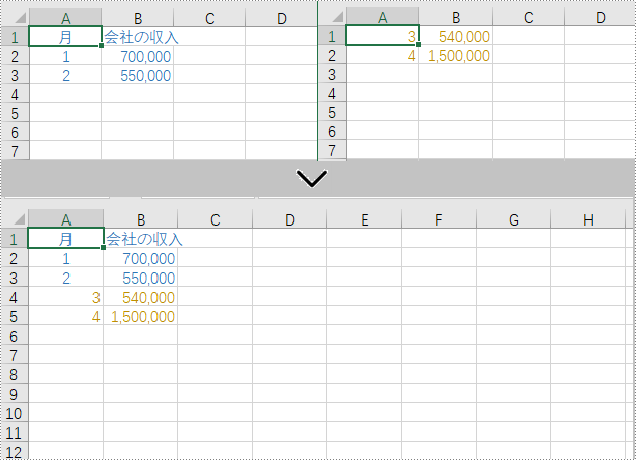
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word ドキュメントでは、画像とテキストが密接に関連することがよくあります。文字だけのドキュメントに比べ、画像を使ったドキュメントは、より分かりやすく、魅力的です。この記事では、Spire.Doc for .NET を使用して Word ドキュメントに画像を挿入する方法について説明します。このプロフェッショナルな Word ライブラリを使用すると、画像のサイズ、位置だけでなく、折り返しのスタイルも設定することができます。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET は、行内、四角形、狭く、内部、上下、背面、前面のような一般的な折り返しスタイルを提供しています。以下は、画像を挿入して、折り返しスタイルを設定する詳細な手順です。
using System.Drawing;
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
namespace WordImage
{
class InsertImage
{
static void Main(string[] args)
{
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.LoadFromFile(@"C:\実例.docx");
//最初のセクションを取得する
Section section = document.Sections[0];
//指定した2つの段落を取得する
Paragraph para1 = section.Paragraphs[3];
Paragraph para2 = section.Paragraphs[4];
//指定した段落に画像を挿入する
DocPicture Pic1 = para1.AppendPicture(Image.FromFile(@"C:\画像1.jpg"));
DocPicture Pic2 = para2.AppendPicture(Image.FromFile(@"C:\画像2.jpg"));
//テキストの折り返しスタイルをにそれぞ四角形と行内れ設定します。
Pic1.TextWrappingStyle = TextWrappingStyle.Square;
Pic2.TextWrappingStyle = TextWrappingStyle.Inline;
//ドキュメントを保存する
document.SaveToFile("画像の挿入.docx", FileFormat.Docx);
}
}
}Imports System.Drawing
Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Namespace WordImage
Class InsertImage
Private Shared Sub Main(ByVal args As String())
'Documentクラスのインスタンスを作成する
Dim document As Document = New Document()
'Wordドキュメントを読み込む
document.LoadFromFile("C:\実例.docx")
'最初のセクションを取得する
Dim section As Section = document.Sections(0)
'指定した2つの段落を取得する
Dim para1 As Paragraph = section.Paragraphs(5)
Dim para2 As Paragraph = section.Paragraphs(9)
'指定した段落に画像を挿入する
Dim Pic1 As DocPicture = para1.AppendPicture(Image.FromFile("C:\画像1.jpg"))
Dim Pic2 As DocPicture = para2.AppendPicture(Image.FromFile("C:\画像2.png"))
'テキストの折り返しスタイルをにそれぞ四角形と行内れ設定します。
Pic1.TextWrappingStyle = TextWrappingStyle.Square
Pic2.TextWrappingStyle = TextWrappingStyle.Inline
'ドキュメントを保存する
document.SaveToFile("画像の挿入.docx", FileFormat.Docx)
End Sub
End Class
End Namespace
Spire.Doc for .NET が提供する DocPicture.HorizontalPosition と DocPicture.VerticalPosition プロパティは、指定した位置に画像を挿入することを可能にします。詳細な手順は以下の通りです。
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using System.Drawing;
namespace InsertImageAtSpecificLoacation
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.LoadFromFile(@"C:\実例.docx");
//最初のセクションを取得する
Section section = document.Sections[0];
//画像を読み込み、ドキュメントに挿入する
DocPicture picture = section.Paragraphs[0].AppendPicture(Image.FromFile(@"C:\画像.jpg"));
//画像の位置を設定する
picture.HorizontalPosition = 120.0F;
picture.VerticalPosition = 200.0F;
//画像の大きさを設定する
picture.Width = 200;
picture.Height = 138;
//テキストの折り返しスタイルを背面に設定する
picture.TextWrappingStyle = TextWrappingStyle.Behind;
//ドキュメントを保存する
document.SaveToFile("指定した位置に画像の挿入.docx", FileFormat.Docx);
}
}
}Imports System.Drawing
Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Namespace InsertImage
Class Program
Private Shared Sub Main(ByVal args As String())
'Documentクラスのインスタンスを作成する
Dim document As Document = New Document()
'Wordドキュメントを読み込む
document.LoadFromFile("C:\実例.docx")
'最初のセクションを取得する
Dim section As Section = document.Sections(0)
'画像を読み込み、ドキュメントに挿入する
Dim picture As DocPicture = section.Paragraphs(0).AppendPicture(Image.FromFile("C:\画像.jpg"))
'画像の位置を設定する
picture.HorizontalPosition = 120.0F
picture.VerticalPosition = 200.0F
'画像の大きさを設定する
picture.Width = 200
picture.Height = 138
'テキストの折り返しスタイルを背面に設定する
picture.TextWrappingStyle = TextWrappingStyle.Behind
'ドキュメントを保存する
document.SaveToFile("指定した位置に画像の挿入.docx", FileFormat.Docx)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office 7.7.6 のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.Doc は新しいエンジンを使用して Word を PDF に変換する際に、テキストの方向を保持することをサポートしました。Spire.PDF はタグ PDF ファイルと PDF/UA ファイルの作成をサポートしました。Spire.XLS は DataTable のエクスポート時にデータを保持するかどうかを設定する数値フォーマットをサポートしました。Spire.Presentation はスライド画像の切り抜きをサポートしました。さらに、このバージョンでは、多くの既知の問題も修正しました。詳細は以下の内容を読んでください。
このバージョンでは、Spire.Doc,Spire.PDF,Spire.XLS,Spire.Email,Spire.DocViewer, Spire.PDFViewer,Spire.Presentation,Spire.Spreadsheet, Spire.OfficeViewer, Spire.DocViewer, Spire.Barcode, Spire.DataExport の最新バージョンが含まれています。
| カテゴリー | ID | 説明 |
| New feature | - | NewEngine を使用して Word を PDF に変換するときに、テキストの方向を保持しました。 |
| Adjustment | - | public IStyle FindById(int styleId) メソッドを放棄しました。 |
| Adjustment | - | public IStyle FindByIstd(int istd) メソッドを放棄しました。 |
| Adjustment | - | public IStyle FindByIdentifier(int sIdentifier) メソッドを公開しました。 |
| Bug | SPIREPDF-6923 | Word を PDF に変換し、改ページが正しくない問題を修正しました。 |
| Bug | SPIREPDF-7103 SPIREPDF-7796 |
Word を PDF に変換し、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREPDF-7591 | Word を PDF に変換し、改行が正しくない問題が修正されました。 |
| Bug | SPIREPDF-7601 | Word を PDF に変換し、表形式のテキストが不完全に表示される問題を修正しました。 |
| Bug | SPIREPDF-7660 | HTML をロードするときに、アプリケーションが「InvalidOperationException」 をスローする問題を修正しました。 |
| Bug | SPIREPDF-7793 | 画像を置換するときに、アプリケーションが「InvalidCastException」をスローする問題を修正しました。 |
| Bug | SPIREPDF-7821 | HTML をロードするときに、アプリケーションが「FileNotFoundException」 をスローする問題を修正しました。 |
| Bug | SPIREPDF-7826 | ドメイン値が正しく設定されていない問題を修正しました。 |
| Bug | SPIREPDF-7830 | Word を PDF に変換するときに、数式のずれの問題を修正しました。 |
| Bug | SPIREPDF-7892 | 新しいエンジン方式で Word を PDF に変換する際に、ヘッダーフッターを設定する連続していないと有効にならない問題を修正しました。 |
| Bug | SPIREPDF-7922 | Word から PDF への変換するときに、アプリケーションが「InvalidOperationException」をスローする問題を修正しました。 |
| Bug | - | Comment.CommentMarkEnd と Comment.CommentMarkStart の参照の問題を修正しました。 |
| Bug | SPIREDOC-7218 | 統計段落の文字数が正しくない問題を修正しました。 |
| Bug | SPIREDOC-7317 | セルをマージした後に、列が多くなる問題を修正しました。 |
| Bug | SPIREDOC-7467 | HTMLファイルをロードするときに、アプリケーションが 「NullReferenceException: オブジェクト参照をオブジェクトのインスタンスに設定しない」をスローする問題を修正しました。 |
| Bug | SPIREDOC-7604 | Word が PDF に変換した後、表に境界線が多く出る問題を修正しました。 |
| Bug | SPIREDOC-7833 | HTML から Word に変換した後、表の枠線が失われる問題を修正しました。 |
| Bug | SPIREDOC-7884 | HTML から Word に変換した後、表の場所が変更される問題を修正しました。 |
| Bug | SPIREDOC-7933 | Doc 形式のドキュメントを生成するときに、表のレイアウトが正しくない問題を修正しました。 |
| Bug | SPIREDOC-7967 | RTF から PDF に変換した後、画像が失われる問題を修正しました。 |
| Bug | SPIREDOC-7968 | 複数のコラムを作成し、WordからPDFに変換した後、複数のコラムが有効になっていない問題を修正しました。 |
| Bug | SPIREDOC-8002 | ブックマークにテキストを追加するとスペースが多くなる問題が修正されました。 |
| Bug | SPIREDOC-8033 | Word から PDFに変換するときに、アプリケーションがハングする問題を修正しました。 |
| Bug | SPIREDOC-8106 | Word から PDF に変換した後、画像が正しくない問題を修正しました。 |
| Bug | SPIREDOC-8125 | ドキュメントにカスタムのプロパティをNULLに設定すると、アプリケーションが「プロパティ値の型がサポートされていません」をスローする問題を修正しました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-3803 | タグPDFファイルの作成をサポートしました。
//Note:At present, in order to ensure the validity of the output tagged PDF file, it is necessary to add the valid license of Spire.PDF for .net to remove the red warning watermark.
//Spire.License.LicenseProvider.SetLicenseKey("valid license key");
//Create a pdf document
PdfDocument doc = new PdfDocument();
//Add page
doc.Pages.Add();
//Set tab order
doc.Pages[0].SetTabOrder(TabOrder.Structure);
//Create PdfTaggedContent
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
taggedContent.SetLanguage("en-US");
taggedContent.SetTitle("test");
//Set font
PdfTrueTypeFont font = new PdfTrueTypeFont(new System.Drawing.Font("Times New Roman", 10), true);
PdfSolidBrush brush = new PdfSolidBrush(Color.Black);
//Append elements
PdfStructureElement article = taggedContent.StructureTreeRoot.AppendChildElement(PdfStandardStructTypes.Document);
PdfStructureElement paragraph1 = article.AppendChildElement(PdfStandardStructTypes.Paragraph);
PdfStructureElement span1 = paragraph1.AppendChildElement(PdfStandardStructTypes.Span);
span1.BeginMarkedContent(doc.Pages[0]);
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Justify);
doc.Pages[0].Canvas.DrawString("Spire.PDF for .NET is a professional PDF API applied to creating, writing, editing, handling and reading PDF files.",
font, brush, new Rectangle(40, 0, 480, 80), format);
span1.EndMarkedContent(doc.Pages[0]);
PdfStructureElement paragraph2 = article.AppendChildElement(PdfStandardStructTypes.Paragraph);
paragraph2.BeginMarkedContent(doc.Pages[0]); doc.Pages[0].Canvas.DrawString("Spire.PDF for .NET can be applied to easily convert Text, Image, SVG, HTML to PDF and convert PDF to Excel with C#/VB.NET in high quality.",
font, brush, new Rectangle(40, 80, 480, 60), format);
paragraph2.EndMarkedContent(doc.Pages[0]);
PdfStructureElement figure1 = article.AppendChildElement(PdfStandardStructTypes.Figure);
//Set Alternate text
figure1.Alt = "replacement text1";
figure1.BeginMarkedContent(doc.Pages[0], null);
PdfImage image = PdfImage.FromFile(@"E-logo.png");
doc.Pages[0].Canvas.DrawImage(image, new PointF(40, 200), new SizeF(100, 100));
figure1.EndMarkedContent(doc.Pages[0]);
PdfStructureElement figure2 = article.AppendChildElement(PdfStandardStructTypes.Figure);
//Set Alternate text
figure2.Alt = "replacement text2";
figure2.BeginMarkedContent(doc.Pages[0], null);
doc.Pages[0].Canvas.DrawRectangle(PdfPens.Black, new Rectangle(300, 200, 100, 100));
figure2.EndMarkedContent(doc.Pages[0]);
//Save to file
String result = "CreateTaggedFile_result.pdf";
doc.SaveToFile(result);
doc.Close();
|
| New feature | SPIREPDF-4559 | PDF/UAファイルの作成をサポートしました。
//Note:At present, in order to ensure the validity of the output PDF/UA file, it is necessary to add the valid license of Spire.PDF for .net to remove the red warning watermark.
//Spire.License.LicenseProvider.SetLicenseKey("valid license key");
//Create a pdf document
PdfDocument doc = new PdfDocument();
//Add page
doc.Pages.Add();
//Set tab order
doc.Pages[0].SetTabOrder(TabOrder.Structure);
//Create PdfTaggedContent
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
taggedContent.SetLanguage("en-US");
taggedContent.SetTitle("test");
//Set PDF/UA1 identification
taggedContent.SetPdfUA1Identification();
//Set font
PdfTrueTypeFont font = new PdfTrueTypeFont(new System.Drawing.Font("Times New Roman", 10), true);
PdfSolidBrush brush = new PdfSolidBrush(Color.Black);
//Append elements
PdfStructureElement article = taggedContent.StructureTreeRoot.AppendChildElement(PdfStandardStructTypes.Document);
PdfStructureElement paragraph1 = article.AppendChildElement(PdfStandardStructTypes.Paragraph);
PdfStructureElement span1 = paragraph1.AppendChildElement(PdfStandardStructTypes.Span);
span1.BeginMarkedContent(doc.Pages[0]);
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Justify);
doc.Pages[0].Canvas.DrawString("Spire.PDF for .NET is a professional PDF API applied to creating, writing, editing, handling and reading PDF files.",
font, brush, new Rectangle(40, 0, 480, 80), format);
span1.EndMarkedContent(doc.Pages[0]);
PdfStructureElement paragraph2 = article.AppendChildElement(PdfStandardStructTypes.Paragraph);
paragraph2.BeginMarkedContent(doc.Pages[0]);
doc.Pages[0].Canvas.DrawString("Spire.PDF for .NET can be applied to easily convert Text, Image, SVG, HTML to PDF and convert PDF to Excel with C#/VB.NET in high quality.",
font, brush, new Rectangle(40, 80, 480, 60), format);
paragraph2.EndMarkedContent(doc.Pages[0]);
PdfStructureElement figure1 = article.AppendChildElement(PdfStandardStructTypes.Figure);
//Set Alternate text
figure1.Alt = "replacement text1";
figure1.BeginMarkedContent(doc.Pages[0], null);
PdfImage image = PdfImage.FromFile(@"E-logo.png");
doc.Pages[0].Canvas.DrawImage(image, new PointF(40, 200), new SizeF(100, 100));
figure1.EndMarkedContent(doc.Pages[0]);
PdfStructureElement figure2 = article.AppendChildElement(PdfStandardStructTypes.Figure);
//Set Alternate text
figure2.Alt = "replacement text2";
figure2.BeginMarkedContent(doc.Pages[0], null);
doc.Pages[0].Canvas.DrawRectangle(PdfPens.Black, new Rectangle(300, 200, 100, 100));
figure2.EndMarkedContent(doc.Pages[0]);
//Save to file
String result = "CreatePDFUAFile_result.pdf";
doc.SaveToFile(result);
doc.Close();
|
| Bug | SPIREPDF-4227 | タイムスタンプサーバを使用して、PDFドキュメントに署名する際に、アプリケーションが「System.NotSupportedException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-4596 | PDFからExcelファイルに変化した後、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5214 | PDFをSVGに変換する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5247 | PDFファイルを印刷した後、スタンプのコンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5266 | PDFファイルのテキストを検索するのに時間がかかる問題を最適化しました。 |
| Bug | SPIREPDF-5277 | ReplaceAllText()関数が有効でない問題が修正されました。 |
| Bug | SPIREPDF-5292 | Html文字列を描画するためにDrawString()メソッドを最適化しました。 |
| Bug | SPIREPDF-5314 | RemoveCustomProperty()関数の効果が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5317 | PDF画像を圧縮するときに、アプリケーションが「System.OutOfMemoryException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5318 | u3dファイルからPDFへ変換した後、PDFを開くことができなかった問題が修正されました。 |
| Bug | SPIREPDF-5319 | 圧縮画像のサイズが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5330 | PDFを画像に変換した後、PDFファイルのQRコードが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5331 | PDF/Aファイルからテキストを抽出する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5333 | PDFファイルからテキストが見つからない問題が修正されました。 |
| Bug | SPIREPDF-5336 | PDFファイルをロードして直接保存した後に、アプリケーションが「Invalid year in date string」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5351 | PDFファイルを印刷した後、内容が失われる問題が修正されました。 |
| Bug | SPIREPDF-5305 | PDFファイルをマージする際に、アプリケーションが「System.IndexOutOfRangeException」をスローする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDFVIEWER-492 | ドキュメントの読み込み時間を最適化しました。 |
| Bug | SPIREPDFVIEWER-542 | ドキュメントをプレビューする際に、内容が空白になっていた問題が修正されました。 |
| Bug | SPIREPDFVIEWER-547 | PDFを回転させた際に、 アプリケーションが「value can not be null」をスローする問題を修正しました。 |
| Bug | SPIREPDFVIEWER-551 | ドキュメントをプレビューする際に、スタンプが失われていた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-3944 | DataTable のエクスポート時にデータを保持するかどうかを設定する数値フォーマットをサポートしました。 ExportTableOptions options = new ExportTableOptions();
ExportTableOptions options = new ExportTableOptions(); options.KeepDataFormat = false; DataTable table = sheet.ExportDataTable(1, 1, sheet.LastDataRow, sheet.LastDataColumn, options); |
| New feature | - | 「UNICODE」 数式の計算をサポートされていました。 |
| Bug | SPIREXLS-3902 | ExcelをPDF に変換した後、透視表の列名の位置がずれる問題を修正しました。 |
| Bug | SPIREXLS-3957 | HTML をロードするときに、アプリケーションが「System. FormatException:Input string was not in a correct format」をスローする問題を修正しました。 |
| Bug | SPIREXLS-3966 | 数式を挿入した後、数式が結果を計算しない問題を修正しました。 |
| Bug | SPIREXLS-3967 | 「CellRange.DisplayedText」プロパティが正しくない値を取得する問題を修正しまました。 |
| Bug | SPIREXLS-3971 | Excel を PDF に変換するときに、アプリケーションが「System.FormatException: この文字列は有効なDateTimeとして認識されない」をスローする問題を修正しました。 |
| Bug | SPIREXLS-3972 | 連続していない範囲を取得するネームマネージャが null ポインター例外をスローする問題を修正しました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-1965 | スライド画像の切り抜きをサポートしました。
SlidePicture slidePicture = (SlidePicture)presentation.Slides[0].Shapes[0]; slidePicture.Crop(float x, float y, float width, float height); |
| New feature | SPIREPPT-1984 | ファイルストリームからスライドに画像を挿入するInsertPicture(stream)メソッドを提供しました。
presentation.Slides[0].Shapes[0].InsertPicture(Stream stream) |
| New feature | - | PowerPoint 2016の新たに追加されたグラフ・タイプの作成をサポートしました、すなわちWaterfall、Treemap、Boxandwhisker、SunBurst、ヒストグラム、パレート。
public void CreateWaterFall(Presentation ppt)
{
IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.WaterFall, new RectangleF(50, 50, 500, 400), false);
chart.ChartData[0, 1].Text = "Series 1";
string[] categories = { "Category 1", "Category 2", "Category 3", "Category 4", "Category 5", "Category 6", "Category 7" };
for (int i = 0; i < categories.Length; i++)
{
chart.ChartData[i + 1, 0].Text = categories[i];
}
double[] values = { 100, 20, 50, -40, 130, -60, 70 };
for (int i = 0; i < values.Length; i++)
{
chart.ChartData[i + 1, 1].NumberValue = values[i];
}
chart.Series.SeriesLabel = chart.ChartData[0, 1, 0, 1];
chart.Categories.CategoryLabels = chart.ChartData[1, 0, categories.Length, 0];
chart.Series[0].Values = chart.ChartData[1, 1, values.Length, 1];
ChartDataPoint chartDataPoint = new ChartDataPoint(chart.Series[0]);
chartDataPoint.Index = 2;
chartDataPoint.SetAsTotal = true;
chart.Series[0].DataPoints.Add(chartDataPoint);
ChartDataPoint chartDataPoint2 = new ChartDataPoint(chart.Series[0]);
chartDataPoint2.Index = 5;
chartDataPoint2.SetAsTotal = true;
chart.Series[0].DataPoints.Add(chartDataPoint2);
chart.Series[0].ShowConnectorLines = true;
chart.Series[0].DataLabels.LabelValueVisible = true;
chart.ChartLegend.Position = ChartLegendPositionType.Right;
chart.ChartTitle.TextProperties.Text = "WaterFall";
}
public void CreateTreeMap(Presentation ppt)
{
IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.TreeMap, new RectangleF(50, 50, 500, 400), false);
chart.ChartData[0, 3].Text = "Series 1";
string[,] categories = {{"Branch 1","Stem 1","Leaf 1"},{"Branch 1","Stem 1","Leaf 2"},{"Branch 1","Stem 1", "Leaf 3"},
{"Branch 1","Stem 2","Leaf 4"},{"Branch 1","Stem 2","Leaf 5"},{"Branch 1","Stem 2","Leaf 6"},{"Branch 1","Stem 2","Leaf 7"},
{"Branch 2","Stem 3","Leaf 8"},{"Branch 2","Stem 3","Leaf 9"},{"Branch 2","Stem 4","Leaf 10"},{"Branch 2","Stem 4","Leaf 11"},
{"Branch 2","Stem 5","Leaf 12"},{"Branch 3","Stem 5","Leaf 13"},{"Branch 3","Stem 6","Leaf 14"},{"Branch 3","Stem 6","Leaf 15"}};
for (int i = 0; i < 15; i++)
{
for (int j = 0; j < 3; j++)
chart.ChartData[i + 1, j].Text = categories[i, j];
}
double[] values = { 17, 23, 48, 22, 76, 54, 77, 26, 44, 63, 10, 15, 48, 15, 51 };
for (int i = 0; i < values.Length; i++)
{
chart.ChartData[i + 1, 3].NumberValue = values[i];
}
chart.Series.SeriesLabel = chart.ChartData[0, 3, 0, 3];
chart.Categories.CategoryLabels = chart.ChartData[1, 0, values.Length, 2];
chart.Series[0].Values = chart.ChartData[1, 3, values.Length, 3];
chart.Series[0].DataLabels.CategoryNameVisible = true;
chart.Series[0].TreeMapLabelOption = TreeMapLabelOption.Banner;
chart.ChartTitle.TextProperties.Text = "TreeMap";
chart.HasLegend = true;
chart.ChartLegend.Position = ChartLegendPositionType.Top;
}
public void CreateSunBurs(Presentation ppt)
{
IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.SunBurst, new RectangleF(50, 50, 500, 400), false);
chart.ChartData[0, 3].Text = "Series 1";
string[,] categories = {{"Branch 1","Stem 1","Leaf 1"},{"Branch 1","Stem 1","Leaf 2"},{"Branch 1","Stem 1", "Leaf 3"},
{"Branch 1","Stem 2","Leaf 4"},{"Branch 1","Stem 2","Leaf 5"},{"Branch 1","Leaf 6",null},{"Branch 1","Leaf 7", null},
{"Branch 2","Stem 3","Leaf 8"},{"Branch 2","Leaf 9",null},{"Branch 2","Stem 4","Leaf 10"},{"Branch 2","Stem 4","Leaf 11"},
{"Branch 2","Stem 5","Leaf 12"},{"Branch 3","Stem 5","Leaf 13"},{"Branch 3","Stem 6","Leaf 14"},{"Branch 3","Leaf 15",null}};
for (int i = 0; i < 15; i++)
{
for (int j = 0; j < 3; j++)
chart.ChartData[i + 1, j].Value = categories[i, j];
}
double[] values = { 17, 23, 48, 22, 76, 54, 77, 26, 44, 63, 10, 15, 48, 15, 51 };
for (int i = 0; i < values.Length; i++)
{
chart.ChartData[i + 1, 3].NumberValue = values[i];
}
chart.Series.SeriesLabel = chart.ChartData[0, 3, 0, 3];
chart.Categories.CategoryLabels = chart.ChartData[1, 0, values.Length, 2];
chart.Series[0].Values = chart.ChartData[1, 3, values.Length, 3];
chart.Series[0].DataLabels.CategoryNameVisible = true;
chart.ChartTitle.TextProperties.Text = "SunBurst";
chart.HasLegend = true;
chart.ChartLegend.Position = ChartLegendPositionType.Top;
}
public void CreatePareto(Presentation ppt)
{
IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.Pareto, new RectangleF(50, 50, 500, 400), false);
chart.ChartData[0, 1].Text = "Series 1";
string[] categories = { "Category 1", "Category 2", "Category 4", "Category 3", "Category 4", "Category 2", "Category 1",
"Category 1", "Category 3", "Category 2", "Category 4", "Category 2", "Category 3",
"Category 1", "Category 3", "Category 2", "Category 4", "Category 1", "Category 1",
"Category 3", "Category 2", "Category 4", "Category 1", "Category 1", "Category 3",
"Category 2", "Category 4", "Category 1"};
for (int i = 0; i < categories.Length; i++)
{
chart.ChartData[i + 1, 0].Text = categories[i];
}
double[] values = { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 };
for (int i = 0; i < values.Length; i++)
{
chart.ChartData[i + 1, 1].NumberValue = values[i];
}
chart.Series.SeriesLabel = chart.ChartData[0, 1, 0, 1];
chart.Categories.CategoryLabels = chart.ChartData[1, 0, categories.Length, 0];
chart.Series[0].Values = chart.ChartData[1, 1, values.Length, 1];
chart.PrimaryCategoryAxis.IsBinningByCategory = true;
chart.Series[1].Line.FillFormat.FillType = FillFormatType.Solid;
chart.Series[1].Line.FillFormat.SolidFillColor.Color = Color.Red;
chart.ChartTitle.TextProperties.Text = "Pareto";
chart.HasLegend = true;
chart.ChartLegend.Position = ChartLegendPositionType.Bottom;
}
public void CreateHistogram(Presentation ppt)
{
IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.Histogram, new RectangleF(50, 50, 500, 400), false);
chart.ChartData[0, 0].Text = "Series 1";
double[] values = { 1, 1, 1, 3, 3, 3, 3, 5, 5, 5, 8, 8, 8, 9, 9, 9, 12, 12, 13, 13, 17, 17, 17, 19,
19, 19, 25, 25, 25, 25, 25, 25, 25, 25, 29, 29, 29, 29, 32, 32, 33, 33, 35, 35, 41, 41, 44, 45, 49, 49 };
for (int i = 0; i < values.Length; i++)
{
chart.ChartData[i + 1, 1].NumberValue = values[i];
}
chart.Series.SeriesLabel = chart.ChartData[0, 0, 0, 0];
chart.Series[0].Values = chart.ChartData[1, 0, values.Length, 0];
chart.PrimaryCategoryAxis.NumberOfBins = 7;
chart.PrimaryCategoryAxis.GapWidth = 20;
chart.ChartTitle.TextProperties.Text = "Histogram";
chart.ChartLegend.Position = ChartLegendPositionType.Bottom;
}
public void CreateBoxAndWhisker(Presentation ppt)
{
IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.BoxAndWhisker, new RectangleF(50, 50, 500, 400), false);
string[] seriesLabel = { "Series 1", "Series 2", "Series 3" };
for (int i = 0; i < seriesLabel.Length; i++)
{
chart.ChartData[0, i + 1].Text = "Series 1";
}
string[] categories = {"Category 1", "Category 1", "Category 1", "Category 1", "Category 1", "Category 1", "Category 1",
"Category 2", "Category 2", "Category 2", "Category 2", "Category 2", "Category 2",
"Category 3", "Category 3", "Category 3", "Category 3", "Category 3"};
for (int i = 0; i < categories.Length; i++)
{
chart.ChartData[i + 1, 0].Text = categories[i];
}
double[,] values = new double[18, 3]{{-7,-3,-24},{-10,1,11},{-28,-6,34},{47,2,-21},{35,17,22},{-22,15,19},{17,-11,25},
{-30,18,25},{49,22,56},{37,22,15},{-55,25,31},{14,18,22},{18,-22,36},{-45,25,-17},
{-33,18,22},{18,2,-23},{-33,-22,10},{10,19,22}};
for (int i = 0; i < seriesLabel.Length; i++)
{
for (int j = 0; j < categories.Length; j++)
{
chart.ChartData[j + 1, i + 1].NumberValue = values[j, i];
}
}
chart.Series.SeriesLabel = chart.ChartData[0, 1, 0, seriesLabel.Length];
chart.Categories.CategoryLabels = chart.ChartData[1, 0, categories.Length, 0];
chart.Series[0].Values = chart.ChartData[1, 1, categories.Length, 1];
chart.Series[1].Values = chart.ChartData[1, 2, categories.Length, 2];
chart.Series[2].Values = chart.ChartData[1, 3, categories.Length, 3];
chart.Series[0].ShowInnerPoints = false;
chart.Series[0].ShowOutlierPoints = true;
chart.Series[0].ShowMeanMarkers = true;
chart.Series[0].ShowMeanLine = true;
chart.Series[0].QuartileCalculationType = QuartileCalculation.ExclusiveMedian;
chart.Series[1].ShowInnerPoints = false;
chart.Series[1].ShowOutlierPoints = true;
chart.Series[1].ShowMeanMarkers = true;
chart.Series[1].ShowMeanLine = true;
chart.Series[1].QuartileCalculationType = QuartileCalculation.InclusiveMedian;
chart.Series[2].ShowInnerPoints = false;
chart.Series[2].ShowOutlierPoints = true;
chart.Series[2].ShowMeanMarkers = true;
chart.Series[2].ShowMeanLine = true;
chart.Series[2].QuartileCalculationType = QuartileCalculation.ExclusiveMedian;
chart.HasLegend = true;
chart.ChartTitle.TextProperties.Text = "BoxAndWhisker";
chart.ChartLegend.Position = ChartLegendPositionType.Top;
}
|





