チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

当社は、製品ごとに試用版を提供しています。登録ユーザーは、当社の Web サイトから製品を無料でダウンロードして試すことができます。試用版では、製品の機能に制限はありませんが、試用版では、結果ドキュメントに評価情報のワークシート(Spire.XLS)または警告の行という別の内容が追加されます。ライセンスを購入すると、.xml 形式のライセンスファイルがメールでお客様に届きます。このファイルを適用すると、警告メッセージが削除されます。
次は、ライセンスファイルおよびその使用方法について詳しく説明します。主に以下の点が含まれます。
ライセンスファイルは XML 形式のファイルであり、購入者のユーザー名、電子メールアドレス、組織、ライセンス日付、製品名、製品バージョン、ライセンスされた開発者とライセンスされた Web サイトの数などの情報が含まれています。ライセンスファイルはデジタル署名されているため、変更しないでください。
E-ICEBLUE 製品でさまざまな操作を行う前にライセンスを適用する必要がありますが、各アプリケーションまたはプロセスごとに 1 回だけです。
E-ICEBLUE 製品を使用して操作を行うと、ライセンスモジュールは、ライセンスが既にロードされているかどうかを検出します。ロードされていない場合、ライセンスモジュールはそれをロードしようと試します。ライセンスは、ファイル、ストリーム、または埋め込みリソースから明示的または暗黙的にロードできます、そしてデフォルトは暗黙的です。
ご注意:暗黙的または明示的な呼び出し方法に関係なく、E-ICEBLUE 製品を使用する前にライセンスファイルを適用するのが必要です。
暗黙的にロード
このモードでは、ライセンスモジュールは次の場所でライセンスファイルを検索しようとします。
E-ICEBLUE からライセンスを取得する場合、デフォルト名は license.elic.xml です。上記のどこの場所で置いても構いません。ライセンスモジュールは、アプリケーションから自動的にロードできます。そして、ライセンスファイルの名前を変更することもできます。変更する場合は、E-ICBLUE 製品で何かを行う前に、新しいファイル名をライセンスモジュールに通知する必要があります。例を挙げよう。
//ライセンスの名前をライセンスモジュールに通知する。
Spire.License.LicenseProvider.SetLicenseFileName("your-license-file-name");//ライセンスの名前をライセンスモジュールに通知する。
Spire.License.LicenseProvider.SetLicenseFileName("your-license-file-name");ライセンス名は、ライセンスモジュールを使用して検索することで取得できます。次に例を示します。
//ライセンスのデフォルト名を取得する
String fileName = Spire.License.LicenseProvider.GetLicenseFileName();//ライセンスのデフォルト名を取得する
Dim fileName As String = Spire.License.LicenseProvider.GetLicenseFileName()明示的にロード
このモードでは、ライセンスモジュールは、提供された特定のファイルまたはストリームからライセンスをロードしようとします。
フルパス名でライセンスファイルを明示的に指定します。
//ライセンスファイルのフルパス名を指定する
Spire.License.LicenseProvider.SetLicenseFileFullPath(@"D:\myApp\license.lic.xml");//ライセンスファイルのフルパス名を指定する
Spire.License.LicenseProvider.SetLicenseFileFullPath(@"D:\myApp\license.lic.xml");FileInfo オブジェクトを介してライセンスファイルを明示的に指定する
//FileInfoオブジェクトを介してライセンスファイルを指定する
FileInfo licenseFile = new FileInfo(@"D:\myApp\license.lic.xml");
Spire.License.LicenseProvider.SetLicenseFile(licenseFile);//FileInfoオブジェクトを介してライセンスファイルを指定する
Dim licenseFile As New FileInfo("D:\myApp\license.lic.xml")
Spire.License.LicenseProvider.SetLicenseFile(licenseFile)ライセンスデータフローを提供します
//ライセンスデータフローを介してライセンスを指定する
Stream stream = File.OpenRead(@"D:\myApp\license.lic.xml");
Spire.License.LicenseProvider.SetLicenseFileStream(stream);//ライセンスデータフローを介してライセンスを指定する
Dim stream As Stream = File.OpenRead("D:\myApp\license.lic.xml")
Spire.License.LicenseProvider.SetLicenseFileStream(stream)参照:ライセンスキーを介してライセンスを適用する方法
配布と展開を簡単にするため、ライセンスファイルを埋め込みリソースとして呼び出し元の E-ICEBLUE 製品アセンブリに含むのは良い方法です。ライセンスを失うことも一切ありません。次の手順に従って、ライセンスファイルを Visual Studio に埋め込みリソースとして含めることができます。
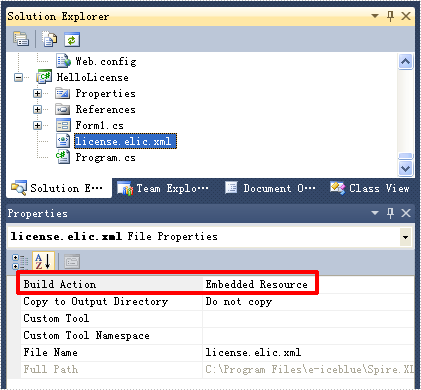
参照:ライセンスキーを介してライセンスを適用する方法
Web サイトでライセンスファイルを適用する場合は、Web サイトで参照されているアセンブリを含む Bin フォルダーにライセンスファイルをコピーするだけです。
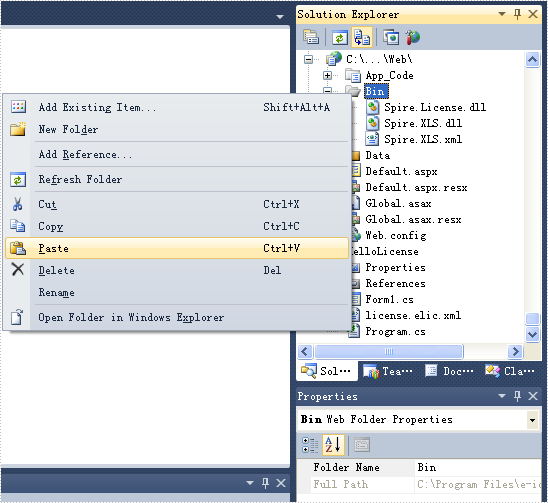
参照:ライセンスキーを介してライセンスを適用する方法
場合によっては、権限の不足やその他の理由でアプリケーションがライセンスファイルを読み取れないことがあります。その場合は、Spire.License.LicenseProvider.SetLicenseKey(String key)メソッドを呼び出してライセンスを適用できます。Key パラメーターは、xml ライセンスファイルの要素の Key 属性の値です。当社の製品で何かを行う前にライセンスが正常に適用されることを確認するために、entry メソッドの最初の行でこのメソッドを呼び出すことをお勧めします。
//ライセンスキーを登録する
Spire.License.LicenseProvider.SetLicenseKey("your license key");//ライセンスキーを登録する
Spire.License.LicenseProvider.SetLicenseKey("your license key")//ライセンスキーを登録する
com.spire.license.LicenseProvider.setLicenseKey("your license key");アプリケーションに 2 つ以上のライセンスを適用するのが必要です。それを実現するには 2 つの方法があります。
ライセンスキーを使用して 2 つ以上のライセンスを適用する場合は、メソッド全体の最初に次のメソッドを呼び出すことができます。
Spire.Doc.License.LicenseProvider.SetLicenseKey("your license key");
Spire.Doc.License.LicenseProvider.LoadLicense();
Spire.Xls.License.LicenseProvider.SetLicenseKey("your license key");
Spire.XLs.License.LicenseProvider.LoadLicense();
Spire.Pdf.License.LicenseProvider.SetLicenseKey("your license key");
Spire.Pdf.License.LicenseProvider.LoadLicense();
Spire.Presentation.License.LicenseProvider.SetLicenseKey("your license key");
Spire.Presentation.License.LicenseProvider.LoadLicense();com.spire.license.LicenseProvider.setLicenseKey("your license key1");
com.spire.license.LicenseProvider.loadLicense();
com.spire.license.LicenseProvider.setLicenseKey("your license key2");
com.spire.license.LicenseProvider.loadLicense();ライセンスファイルを介してライセンスを適用する場合は、次のメソッドを呼び出してください。
Spire.License.LicenseProvider.SetLicenseFileName("license1.elic.xml");
Spire.License.LicenseProvider.LoadLicense();
Spire.License.LicenseProvider.SetLicenseFileName("license2.elic.xml");
Spire.License.LicenseProvider.LoadLicense();Spire.Office for Java 5.4.5のリリースを発表できることを嬉しく思います。このバージョンはいくつかの新機能をもたらします。たとえば、Spire.XLS for Javaは、ExcelファイルをPDFに変換するときに変換する最大ページ数の設定をサポートし、ApplyStyle()を使用してセル範囲にスタイルを適用することをサポートしました。Spire.PDF for Javaは、署名画像を署名フィールドサイズに自動的に合わせるためのSignImageLayout.Stretchの設定をサポートしていました。さらに、Spire.Doc for Javaは、WordからPDFおよびWordからHTMLへの変換を強化しました。その他、多くのバグも正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | ExcelファイルをPDFに変換するときに変換する最大ページ数の設定をサポートしました。
//ファイルをロードする workbook.loadFromFile(inputFile); //ページに合わせる workbook.getConverterSetting().setSheetFitToPage(true); //変換する最大ページ数を設定する workbook.getConverterSetting().setMaxConvertPages(); //PDFファイルとして保存する workbook.saveToFile(outputFile, FileFormat.PDF); workbook.dispose(); |
| New feature | SPIREXLS-3763 | ApplyStyle()を使用してセル範囲にスタイルを適用することをサポートしました。
//ワークブックオブジェクトを作成する
Workbook workbook = new Workbook();
//サンプルExcelファイルをロードする
workbook.loadFromFile("in.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
// CellStyleオブジェクトを作成する
CellStyle fontStyle = workbook.getStyles().addStyle("headerFontStyle");
//フォントの色、サイズ、スタイルを設定します
fontStyle.getFont().setColor(Color.white);
fontStyle.getFont().isBold(true);
fontStyle.getFont().setSize(12);
fontStyle.setHorizontalAlignment(HorizontalAlignType.Center);
CellStyleFlag flag = new CellStyleFlag();
flag.setFontColor(true);
flag.setFontBold(true);
flag.setFontSize(true);
flag.setHorizontalAlignment(true);
//スタイルを適用する
sheet.getRange().get(1, 1, 1, 8).applyStyle(fontStyle, flag);
workbook.saveToFile("out.xlsx", ExcelVersion.Version2016);
|
| Bug | SPIREXLS-3730 | ExcelファイルをHtmlに変換するときに、アプリケーションが "Illegal characters in path" エラーをスローする問題を修正しました。 |
| Bug | SPIREXLS-3731 | ExcelファイルをPDFに変換した後にコンテンツが失われる問題を修正しました。 |
| Bug | SPIREXLS-3733 | openjdk17を使用してExcelファイルをPDFに変換するときに、アプリケーションが "java.lang.IllegalAccessError" をスローする問題を修正しました。 |
| Bug | SPIREXLS-3741 | ExcelファイルをPDFに変換するときにアプリケーションが長時間ハングする問題を修正しました。 |
| Bug | SPIREXLS-3671 | ExcelファイルをPDFに変換した後、数式が正しく計算されず、一部の中国語のテキストが文字化けする問題を修正しました。 |
| Bug | SPIREXLS-3755 | Excelファイルに透かしを追加した後に出力ファイルを開くことができなかった問題を修正しました。 |
| Bug | SPIREXLS-3761 | ExcelファイルをPDFAに変換し、Adobe PDFで飛行前チェックを行った後、透明度の検証が失敗する問題を修正しました。 |
| Bug | SPIREXLS-3766 | Excelファイルを保存するときにアプリケーションが "NullPointerException" をスローする問題を修正しました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-2425 | 署名画像を署名フィールドサイズに自動的に合わせるためのSignImageLayout.Stretchの設定をサポートしました。
signature.setSignImageLayout(SignImageLayout.Stretch); |
| Bug | SPIREPDF-3925 | 透かしを追加した後、画像の背景色が正しくなかった問題を修正しました。 |
| Bug | SPIREPDF-5016 | PDFをPDFA3Aに変換するときにアプリケーションが "NullPointerException" をスローする問題を修正しました。 |
| Bug | SPIREPDF-5030 | PDFをPDFA3Aに変換した後にコンテンツが正しくなかった問題を修正しました |
| Bug | SPIREPDF-5036 | ポリゴンを塗りつぶした後の出力効果が正しくなかった問題を修正しました。 |
| Bug | SPIREPDF-5040 | OFDをPDFに変換した後にコンテンツが失われる問題を修正しました。 |
| Bug | SPIREPDF-5042 SPIREPDF-5043 SPIREPDF-5048 SPIREPDF-5050 SPIREPDF-5051 |
PDFをWordに変換するときにアプリケーションが "NumberFormatException" をスローする問題を修正しました。 |
| Bug | SPIREPDF-5074 | PDFをWordに変換するときにアプリケーションが "NullPointerException" をスローする問題を修正しました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7062 SPIREDOC-7667 SPIREDOC-7702 |
WordをPDFに変換した後にコンテンツが正しくなかった問題を修正しました。 |
| Bug | SPIREDOC-7347 | WordをPDFに変換するときにアプリケーションが "java.awt.image.RasterFormatException" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7378 | WordをPDFに変換した後にコンテンツが失われる問題を修正しました。 |
| Bug | SPIREDOC-7396 | 保存されたWordファイルのテーブル形式が正しくなかった問題を修正しました。 |
| Bug | SPIREDOC-7520 | TextBoxの削除に失敗した問題を修正しました。 |
| Bug | SPIREDOC-7522 | NewEngineメソッドは、WordをPDFに変換した後のテキストの配置が正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7523 | NewEngineメソッドは、WordをPDFに変換した後の画像の位置が正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7536 | WordをPDFに変換するときにアプリケーションが "nullpointerexception" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7572 | NewEngineメソッドは、WordをPDFに変換した後にページ番号が正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7574 | NewEngineメソッドは、WordをPDFに変換した後にページ番号とコンテンツが正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7592 SPIREDOC-7629 |
WordをPDFに変換した後のコンテンツ形式が正しくなかった問題を修正します。 |
| Bug | SPIREDOC-7617 | WordをPDFに変換するときに、アプリケーションが "'wsp'は宣言されていない名前空間です" とスローする問題を修正しました。 |
| Bug | SPIREDOC-7619 | WordをPDFに変換した後にページ番号が失われる問題を修正しました。 |
| Bug | SPIREDOC-7627 | HtmlをWordに変換するときにアプリケーションが "'ConcurrentModificationException" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7666 | WordをHTMLに変換した後に一部のテキストが重複する問題を修正しました。 |
| Bug | SPIREDOC-7669 | Wordファイルストリームの読み込み時にアプリケーションが "IllegalStateException" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7675 | WordをHTMLに変換した後に画像が失われる問題を修正しました。 |
Spire.Doc for Java 5.4.10 のリリースを発表できることを嬉しく思います。このバージョンは、Word から PDF および Word から HTML への変換を強化しました。さらに、保存された Word ファイルのテーブル形式が正しくなかったなどの既知の問題を修正しました。 詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7062 SPIREDOC-7667 SPIREDOC-7702 |
WordをPDFに変換した後にコンテンツが正しくなかった問題を修正しました。 |
| Bug | SPIREDOC-7347 | WordをPDFに変換するときにアプリケーションが "java.awt.image.RasterFormatException" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7378 | WordをPDFに変換した後にコンテンツが失われる問題を修正しました。 |
| Bug | SPIREDOC-7396 | 保存されたWordファイルのテーブル形式が正しくなかった問題を修正しました。 |
| Bug | SPIREDOC-7520 | TextBoxの削除に失敗した問題を修正しました。 |
| Bug | SPIREDOC-7522 | NewEngineメソッドで、WordをPDFに変換した後のテキストの配置が正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7523 | NewEngineメソッドで、WordをPDFに変換した後の画像の位置が正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7536 | WordをPDFに変換するときにアプリケーションが "nullpointerexception" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7572 | NewEngineメソッドで、WordをPDFに変換した後にページ番号が正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7574 | NewEngineメソッドで、WordをPDFに変換した後にページ番号とコンテンツが正しくないという問題を修正しました。 |
| Bug | SPIREDOC-7592 SPIREDOC-7629 |
WordをPDFに変換した後のコンテンツ形式が正しくなかった問題を修正しました。 |
| Bug | SPIREDOC-7617 | WordをPDFに変換するときに、アプリケーションが "'ws'は宣言されていない名前空間です" とスローする問題を修正しました。 |
| Bug | SPIREDOC-7619 | WordをPDFに変換した後にページ番号が失われる問題を修正しました。 |
| Bug | SPIREDOC-7627 | HtmlをWordに変換するときにアプリケーションが "'ConcurrentModificationException" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7666 | WordをHTMLに変換した後に一部のテキストが重複する問題を修正しました。 |
| Bug | SPIREDOC-7669 | Wordファイルストリームの読み込み時にアプリケーションが "'IllegalStateException" をスローする問題を修正しました。 |
| Bug | SPIREDOC-7675 | WordをHTMLに変換した後に画像が失われる問題を修正しました。 |
今回の記事で Java を使用して HTML を PDF に変換する方法を紹介します。変換することには、以下の 2 点に注意する必要があります。
対応するプラグインは、さまざまなシステムに応じてダウンロードできます。ダウンロード先:windows-x86.zip、windows-x64.zip、macosx_x64.zip、および linux_x64.zip。ダウンロードした後、プラグインパッケージをローカルで指定されたフォルダパスに解凍します。
jar をインポートするには2つの方法があります。
最終的なjarファイルのインポート効果は次のとおりです。
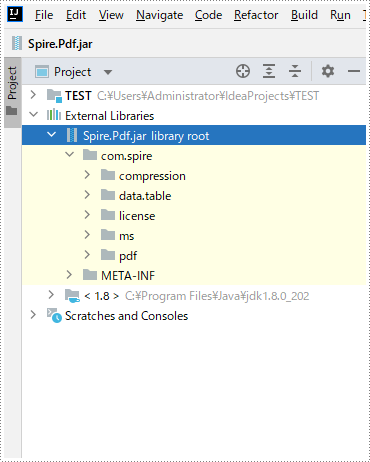
Java 変換コード一覧
port com.spire.pdf.graphics.PdfMargins;
import com.spire.pdf.htmlconverter.qt.HtmlConverter;
import com.spire.pdf.htmlconverter.qt.Size;
public class HtmlToPDF {
public static void main(String[] args) {
//変換したいHTMLを定義する
String url = "https://www.google.com/";
//変換された結果ドキュメント(結果ドキュメントはJavaプロジェクトプログラムファイルに保存されます)
String fileName = "HtmlToPDF.pdf";
//解凍されたプラグインのローカルアドレス
// (プラグインパッケージはJavaプロジェクトフォルダーに配置されます。他のローカルパスをカスタマイズすることもできます)
String pluginPath = "F:\\plugins-windows-x64";
HtmlConverter.setPluginPath(pluginPath);
//メソッドを呼び出してPDFに変換し、PDFサイズを設定する
HtmlConverter.convert(url, fileName, true, 1000, new Size(700f, 800f), new PdfMargins(0));
}Html を PDF に変換すると、元の html 形式、ハイパーリンクなどが保留され、次のようになります。
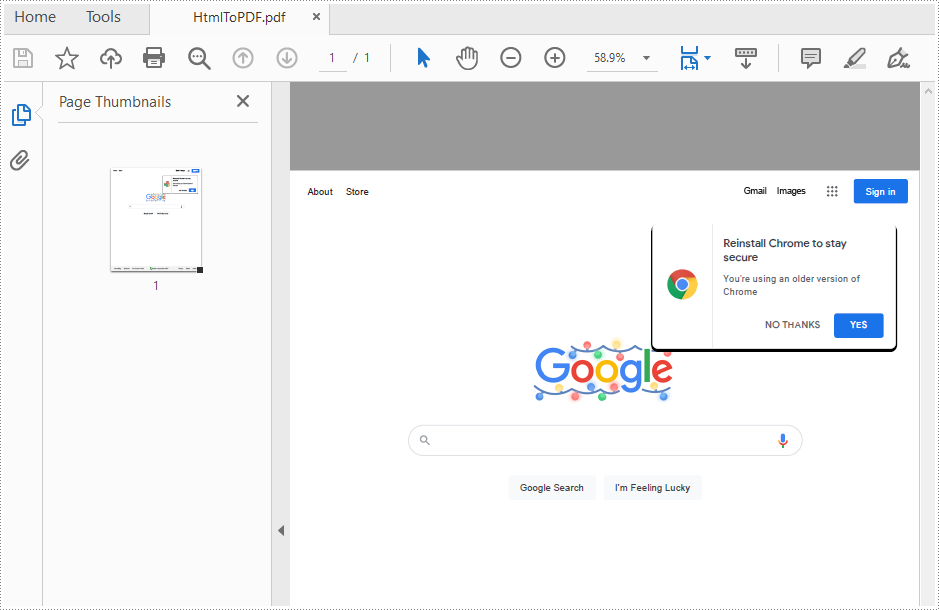
今回の記事は以上でした、最後まで読んでいただきありがとうございます。
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30日間有効な一時ライセンスを取得してください。
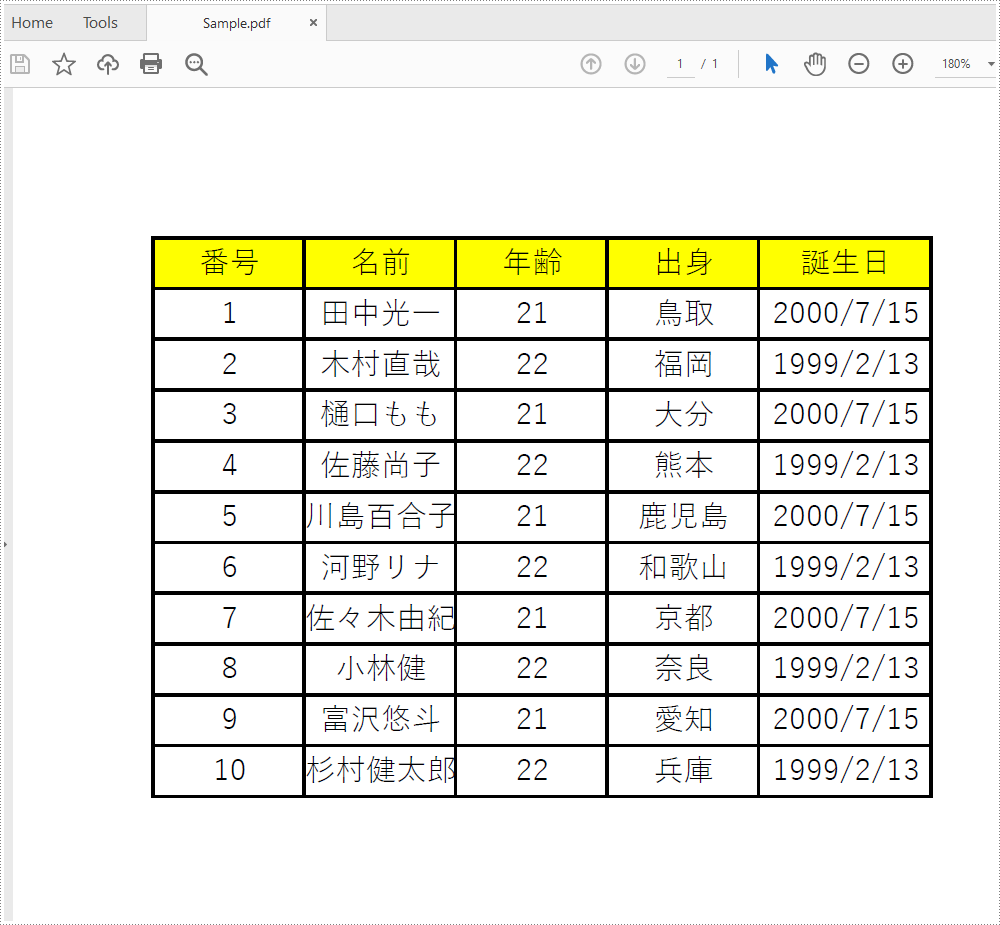
PDF ドキュメントはもっとも一般的に使われていて、便利な形式です、そのため、PDF ドキュメントにテーブルを使用するのもよくある場合です。しかし PDF ドキュメントは安全性を考慮して、簡単に編集できないです、この時テーブルの内容を抽出したいなら、どうやって操作しますか?この記事で、Spire.PDF for .NET によって提供されるテーブルを抽出するクラスとメソッドを呼び出して、テーブルセルのテキストコンテンツを取得する方法をご紹介します。
環境構成
方法一、NuGet からダウンロードしてインストールします
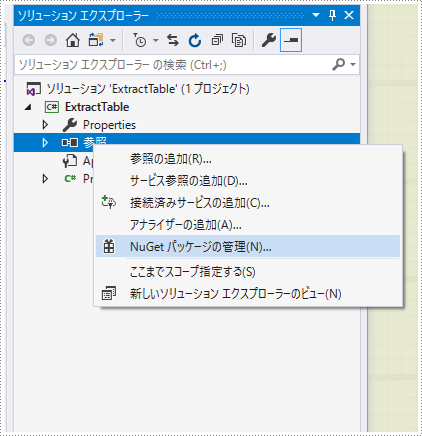
1、「参照」を右クリックして、「NuGet パッケージの管理」を選択します。
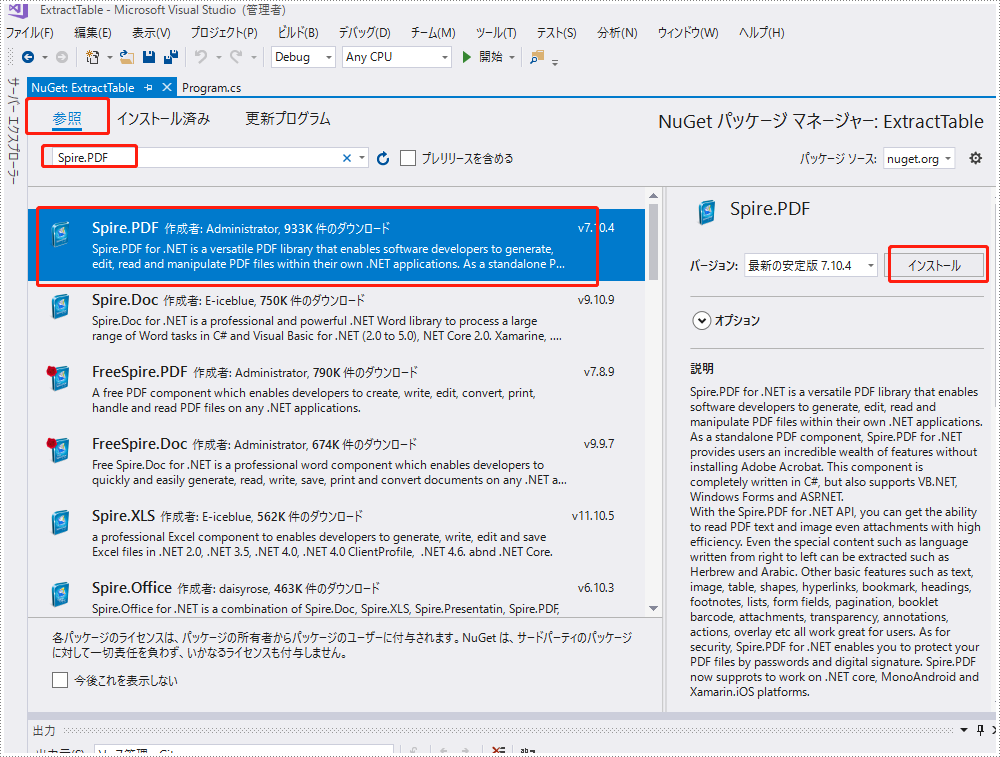
2、「参照」を選択し、検索バーに「Spire.PDF」を入力してインストールします。
方法二、手動で参照を追加します
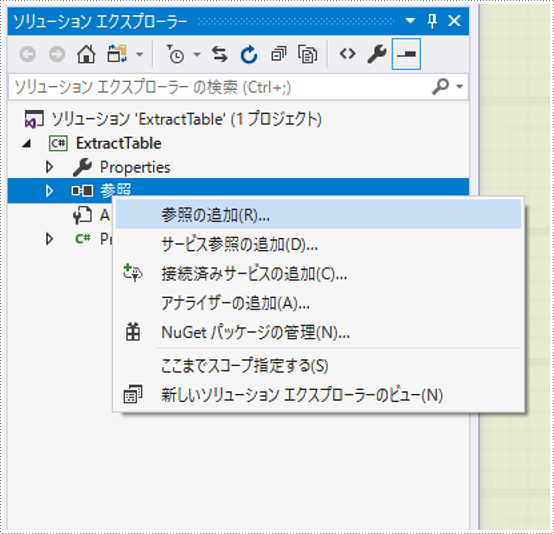
1、「参照」を右クリックして、「参照の追加」を選択します。
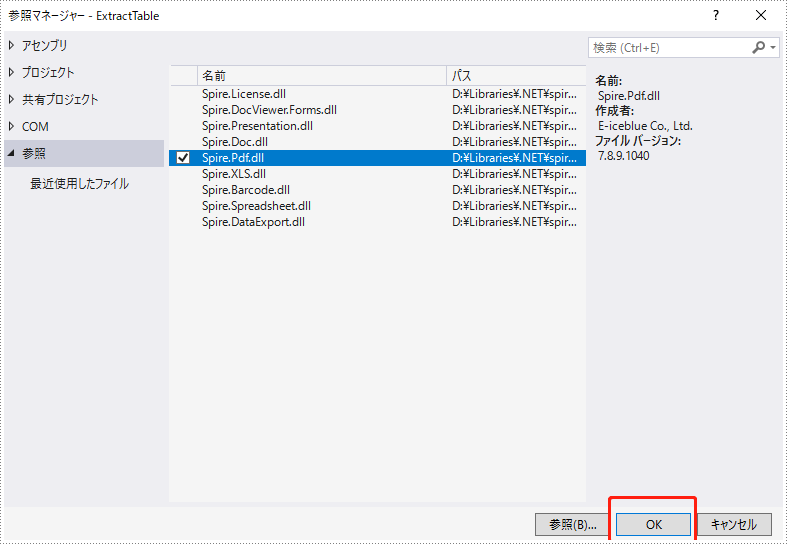
2、「参照」を選択し、「OK」ボタンをクリックします(事前に参照リストに追加する必要があります)
コードの表示:
using Spire.Pdf;
using Spire.Pdf.Tables;
using Spire.Pdf.Utilities;
using System.IO;
using System.Text;
namespace ExtractTable
{
class Program
{
static void Main(string[] args)
{
//PDFドキュメントをロードする
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("sample.pdf");
StringBuilder builder = new StringBuilder();
//テーブルを抽出する
PdfTableExtractor Extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = null;
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
tableLists = extractor.ExtractTable(pageIndex);
if (tableLists != null && tableLists.Length > 0)
{
foreach (PdfTable table in tableLists)
{
int row = table.GetRowCount();
int column = table.GetColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
string text = table.GetText(i, j);
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//抽出されたテーブルの内容をtxtドキュメントに保存する
File.WriteAllText("ExtractedTable.txt", builder.ToString());
}
}
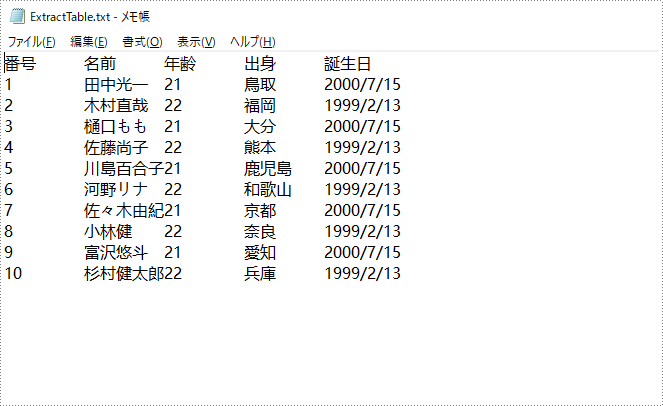
}抽出した結果は以下のように:
以上になりました、最後までお読みいただき、誠にありがとうございます。
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30日間有効な一時ライセンスを取得してください。
PowerPoint ドキュメントの中で、タイトルは不可欠な部分であり、適当にタイトルを使て、長い PowerPoint ドキュメントがちゃんと整理されたように見やすくなり、解説している人が次に大体何の内容を出すのかを聴衆たちにヒントになります。
操作を始める前に、先ずは一つの概念、つまりプレースホルダーを理解すべきです。PowerPoint ドキュメントには複数の図形が存在できることが分かっているでしょう、そして各図形には独自のプレースホルダー(placeholder)があります、各図形のプレースホルダのタイプもそれぞれ違います。例えば、テーブルのプレースホルダのタイプは table で、画像のプレースホルダのタイプは picture で、メディアファイルのプレースホルダのタイプは Media で、そしてタイトルのプレースホルダのタイプは title です。今回の記事で図形のプレースホルダのタイプを判断して、ドキュメント内のタイトルを取得する方法を紹介します。
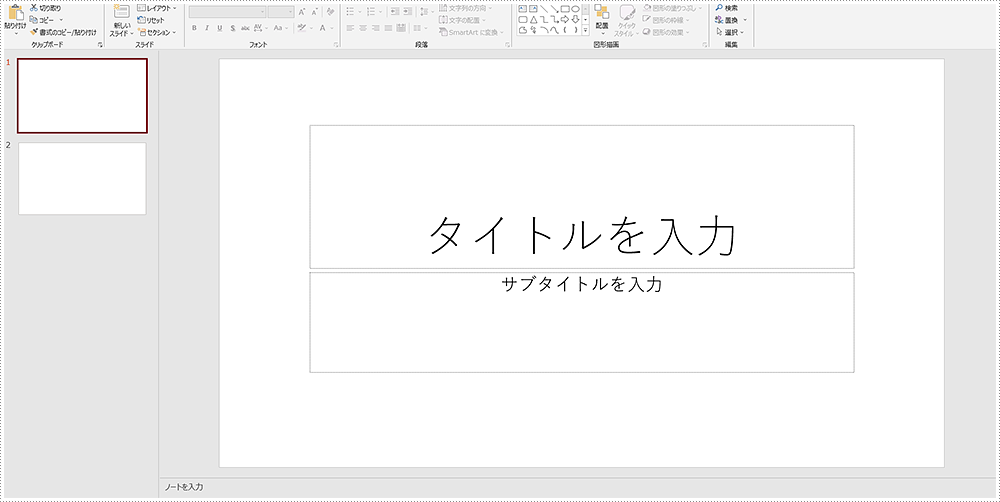
PowerPoint ドキュメントにはさまざまな種類のタイトルがあります。PowerPoint ドキュメントを作成してスライドを追加すると、中央タイトル(Centered title)、サブタイトル(Subtitle)、および他のスライドのタイトル(title)がスライドの中央に表示されます。以下の画像で直感的に見ましょう:
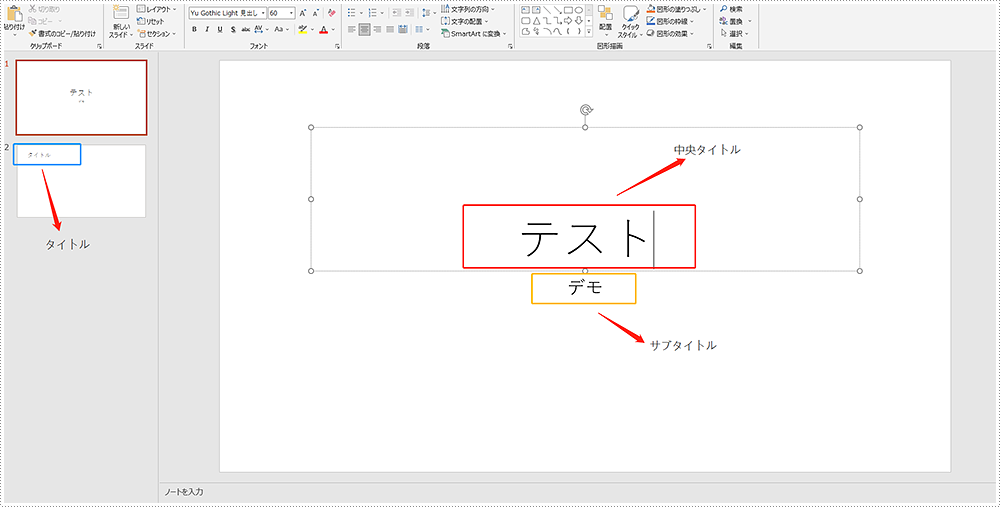
それからこの PowerPoint ドキュメントに何か内容を追加します:
必要なコンポーネント:
Visual Studio および無料版の PowerPoint コンポーネント、Free Spire.Presentation for .NET コンポーネントがインストール完了したら、Visual Studio を開き、新しいプロジェクトを作成して Spire.Presentation.dll を参照に追加します。すべてのコードは以下になります:
using System;
using System.Collections.Generic;
using Spire.Presentation;
namespace GetPresentationTitle
{
class Program
{
static void Main(string[] args)
{
// PowerPointのインスタントを作成してPowerPointドキュメントをロードする
Presentation ppt = new Presentation();
ppt.LoadFromFile("test.pptx");
//listのインスタントを作成する
List shapelist = new List();
// PowerPointドキュメントのすべてのスライドと各スライドのすべての図形をトラバースし、プレースホルダーの種類がタイトルである図形をリストに追加する
foreach (ISlide slide in ppt.Slides)
{
foreach (IShape shape in slide.Shapes)
{
if (shape.Placeholder != null)
{
switch (shape.Placeholder.Type)
{
case PlaceholderType.Title:
shapelist.Add(shape);
break;
case PlaceholderType.CenteredTitle:
shapelist.Add(shape);
break;
case PlaceholderType.Subtitle:
shapelist.Add(shape);
break;
}
}
}
}
//リストをトラバースして、リスト内のすべての形状の内部テキストを取得する
for (int i = 0; i < shapelist.Count; i++)
{
IAutoShape shape1 = shapelist[i] as IAutoShape;
Console.WriteLine(shape1.TextFrame.Text);
}
Console.ReadKey();
}
}
} 結果は以下のように:
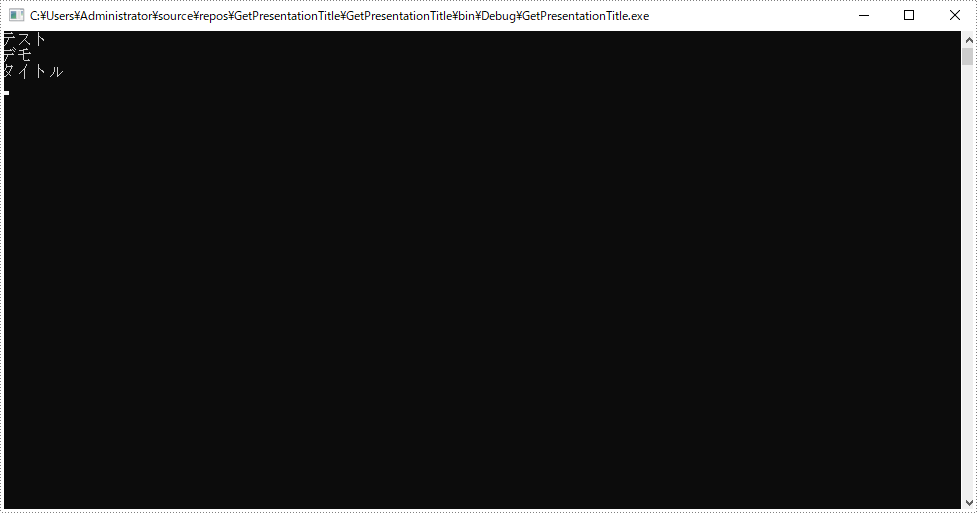
図形のプレースホルダーのタイプを判断するのはドキュメントのタイトルを取得できるだけではなく、また画像、動画、テーブルおよびフッターまでも取得できます。最後までお読みいただき、ありがとうございました、ではまた!
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30日間有効な一時ライセンスを取得してください。
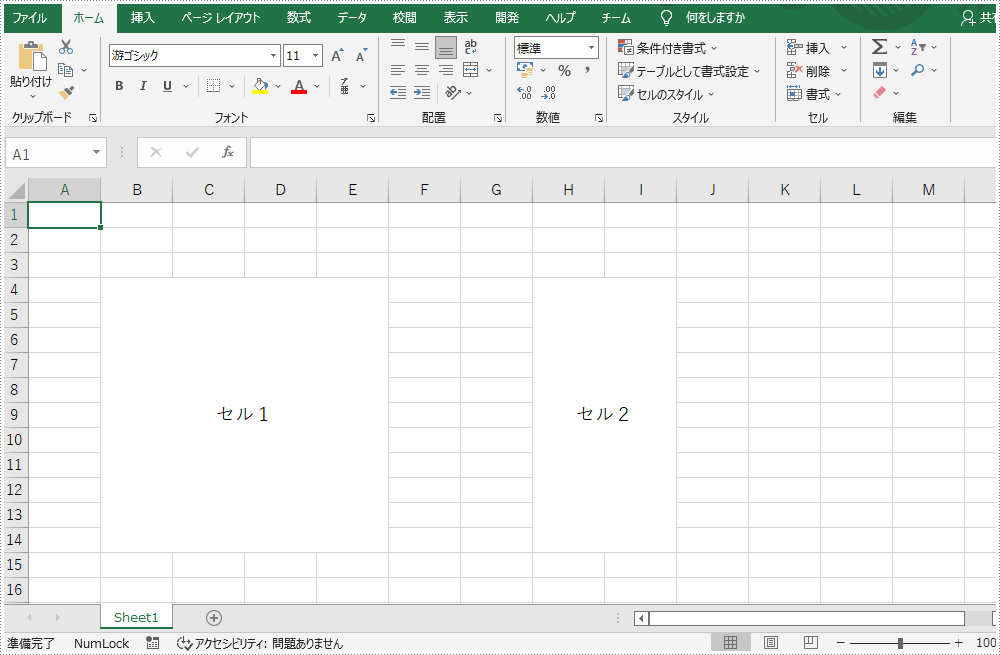
人々が Excel のテーブルを作るとき、いつもいくつかのセルを結合したり結合を解除したりする必要があります。セルをマージ解除したいと、1つずつ検索してキャンセルしなければならないからかなり面倒です。ゆえに、次は Excel で結合されたセルを識別する簡単な方法を紹介します。これを使って結合されたセルを識別した後また結合を解除したり、書式設定などの他の操作を実行することもできます。
より良く理解させるため、こちらはふたつの結語したエリアを含むドキュメントを例として、Spire.XLS for .NET というコンポーネントを使用して、詳しく説明します。
ステップ 1、Workbook オブジェクトをインスタンス化し、Excel ドキュメントを読み込みます。
Workbook workbook = new Workbook();
workbook.LoadFromFile("test.xlsx");ステップ 2、Excel ドキュメントの最初のシートを取得します。
Worksheet sheet = workbook.Worksheets[0];ステップ 3、マージされた領域を取得し、結果を CellRange 配列に保存します。
CellRange[] range = sheet.MergedCells;ステップ 4、配列をトラバースして、マージされた領域のセルをマージ解除します。
foreach (CellRange cell in range)
{
cell.UnMerge();
}ステップ 5、ドキュメントを保存します。
workbook.SaveToFile("result.xlsx");操作した画像は以下のように:
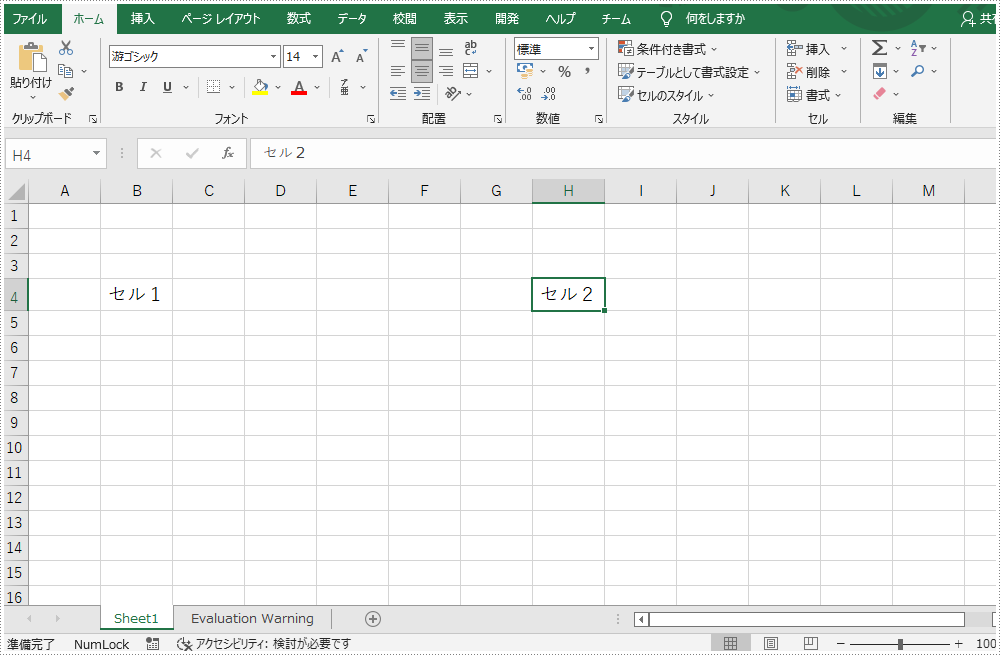
完全なるコード一覧:
using Spire.Xls;
namespace Detect_Merged_Cells
{
class Program
{
static void Main(string[] args)
{
Workbook workbook = new Workbook();
workbook.LoadFromFile("test.xlsx");
Worksheet sheet = workbook.Worksheets[0];
CellRange[] range = sheet.MergedCells;
foreach (CellRange cell in range)
{
cell.UnMerge();
}
workbook.SaveToFile("result.xlsx");
}
}
}今回の Excel で結合されたセルを取得する方法は以上でした、最後まで読んでいただきありがとうございました。
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30日間有効な一時ライセンスを取得してください。
この記事では、C# プログラムコードを例として取り上げ、txt ファイルのコンテンツを読み取って Word 文書を生成する方法を紹介します。コードを編集する前に、次のコード環境を参照して構成を確認できます。
1、NuGet を介して dll をインストールする方法
1.1、Visual Studio で「ソリューションエクスプローラー」を開き、「参照」、「NuGet パッケージの管理」を右クリックし、「無料のSpire.Doc」を検索して、「インストール」をクリックします。プログラムのインストールが完了するのを待ちます。
1.2、以下を PM コンソールのインストールにコピーします。
Install-Package FreeSpire.Doc -Version 9.9.7パッケージを手動でダウンロードして解凍し、BIN フォルダーで Spire.Doc.dll を見つけることができます。次に、Visual Studio で「ソリューションエクスプローラー」を開き、「参照」、「参照の追加」を右クリックして、プログラムへのローカルパスの BIN フォルダーにある dll ファイルへの参照を追加します。
using Spire.Doc;
using Spire.Doc.Documents;
using System.Drawing;
using System.IO;
using System.Text;
namespace CreateWordDocument_Doc
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのオブジェクトをインスタンス化し、sectionとparagraphを追加する
Document doc = new Document();
Section section = doc.AddSection();
Paragraph paragraph = section.AddParagraph();
//txtファイルを読み取る
StreamReader sr = new StreamReader("C:\\Users\\Administrator\\Desktop\\test.txt", Encoding.Default);
//段落スタイルを設定し、段落に適用する
ParagraphStyle style1 = new ParagraphStyle(doc);
style1.Name = "titleStyle";
style1.CharacterFormat.Bold = true;
style1.CharacterFormat.TextColor = Color.Purple;
style1.CharacterFormat.FontName = "Yu Mincho";
style1.CharacterFormat.FontSize = 12;
doc.Styles.Add(style1);
paragraph.ApplyStyle("titleStyle");
string line;
while ((line = sr.ReadLine()) != null)
{
paragraph.AppendText(line);//段落にtxtを書く
}
//docx形式でWordとして保存する
doc.SaveToFile("addTxttoWord.docx", FileFormat.Docx2013);
System.Diagnostics.Process.Start("addTxttoWord.docx");
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System.Drawing
Imports System.IO
Imports System.Text
Namespace CreateWordDocument_Doc
Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのオブジェクトをインスタンス化し、sectionとparagraphを追加する
Document doc = New Document()
Dim section As Section = doc.AddSection()
Dim paragraph As Paragraph = section.AddParagraph()
'txtファイルを読み取る
Dim sr As StreamReader =
New StreamReader("C:\\Users\\Administrator\\Desktop\\test.txt",Encoding.Default)
'段落スタイルを設定し、段落に適用する
Dim style1 As ParagraphStyle = New ParagraphStyle(doc)
style1.Name = "titleStyle"
style1.CharacterFormat.Bold = True
style1.CharacterFormat.TextColor = Color.Purple
style1.CharacterFormat.FontName = "Yu Mincho"
style1.CharacterFormat.FontSize = 12
doc.Styles.Add(style1)
paragraph.ApplyStyle("titleStyle")
Dim line As String
While Not(line = sr.ReadLine()) Is Nothing
paragraph.AppendText(line)'段落にtxtを書く
End While
'docx形式でWordとして保存する
doc.SaveToFile("addTxttoWord.docx", FileFormat.Docx2013)
System.Diagnostics.Process.Start("addTxttoWord.docx")
End Sub
End Class
End Namespace生成したドキュメントの効果は以下のようになります:

以上は今回の TXT を読み取って Word 文書を生成する記事でした、最後まで読んでいただきありがとうございます。
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30日間有効な一時ライセンスを取得してください。





