チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Java での PDF 解析は、PDFを単に画面表示するだけでなく、内部に含まれる情報をプログラムで抽出・活用したい場合によく必要とされます。代表的なユースケースとしては、ドキュメントのインデックス化、自動レポート処理、請求書分析、データ取り込みパイプラインなどが挙げられます。
JSON や XML のような構造化データ形式とは異なり、PDF は見た目の正確な再現(ビジュアル忠実度)を目的として設計されています。そのため、テキスト・表・画像といった要素は、論理構造としてではなく、描画位置を指定する命令の集合として格納されています。
このような特性から、Java で PDF を解析する際には、PDF内部のコンテンツ表現を理解し、それを Java ライブラリがどのように API として提供しているかを把握することが重要になります。
本記事では、Spire.PDF for Java を使用し、実際の Java アプリケーションで役立つ PDF 解析処理を実践的に解説します。PDF 解析を一連の単一フローとして扱うのではなく、テキスト・表・画像・メタデータといった目的別の抽出タスクごとに説明していきます。
目次
実装の観点から見ると、Java での PDF 解析は単一の処理ではなく、同一ドキュメントに対して実行される複数の抽出タスクの集合です。アプリケーションが必要とするデータの種類に応じて、実行すべき解析処理が決まります。
実際のシステムにおいて、PDF 解析は主に以下の情報を取得する目的で使用されます。
PDF 解析が複雑になる最大の理由は、PDF が論理構造を保持しない形式であることにあります。段落、行、表といった構造は明示的には保存されず、主に以下の要素として表現されています。
そのため、Java での PDF 解析は、あらかじめ定義されたデータ構造を読み取るのではなく、レイアウト情報から意味を再構築する処理になります。
このような理由から、実用的な Java 実装では、低レベルなページコンテンツへアクセスできるだけでなく、テキスト抽出や表検出といった高レベル機能も提供する専用 PDF 解析ライブラリを利用するのが一般的です。これにより、独自ロジックの実装量を大幅に削減できます。
本番環境では、PDF 解析を厳密なステップ型パイプラインとして設計するよりも、必要に応じて個別に適用可能な独立した解析処理の集合として設計する方が適しています。
この設計により、障害の切り分けが容易になり、アプリケーションは本当に必要な解析処理だけを選択的に実行できます。
ここでは、テキスト抽出、表検出、画像エクスポート、メタデータ取得などの API を提供する Java PDF ライブラリ Spire.PDF for Java を使用します。バックエンドサービス、バッチ処理、ドキュメント自動化システムなどに適しています。
ライブラリは Spire.PDF for Java ダウンロードページ から取得し、手動でプロジェクトに追加できます。
Maven を使用している場合は、以下の依存関係を追加することで簡単に導入できます。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
インストール後は、外部ツールに依存せず、Java コードだけで PDF ドキュメントの読み込み・解析が可能になります。
解析処理を行う前に、まず PDF ドキュメントを読み込み、安全に処理できるかどうかを検証する必要があります。このステップは、後続の解析ロジックとは独立した処理として扱うのが望ましいです。
import com.spire.pdf.PdfDocument;
public class loadPDF {
public static void main(String[] args) {
// PdfDocument インスタンスを作成
PdfDocument pdf = new PdfDocument();
// PDF ファイルを読み込み
pdf.loadFromFile("sample.pdf");
// ページ数を取得
int pageCount = pdf.getPages().getCount();
System.out.println("総ページ数: " + pageCount);
}
}
コンソール出力例
実装上、この段階で以下の重要な点が確認できます。
本番システムでは、この検証処理がゲートキーパーとして機能し、読み込みに失敗した PDF は早期に除外されます。
ドキュメント検証と抽出ロジックを分離することで、特にバッチ処理や自動解析フローにおいて、障害の連鎖を防ぐことができます。
テキスト解析は、Java における PDF 処理で最も一般的なタスクの一つです。PDF ページから可読なテキストを抽出・再構成する処理を指します。
Spire.PDF for Java では、単一の高レベル API に頼るのではなく、PdfTextExtractor クラスと PdfTextExtractOptions を組み合わせて実装することで、柔軟かつ制御しやすいテキスト抽出が可能です。
テキスト解析を独立した処理として設計することで、インデックス作成、分析、コンテンツ移行など、必要なタイミングで自由に利用できます。
一般的な Java 実装では、テキスト解析は以下の明確なステップで構成されます。
このページ単位の設計は、PDF の内部構造と自然に対応しており、複数ページの処理でも高い制御性を提供します。
以下は、Spire.PDF for Java の PdfTextExtractor と PdfTextExtractOptions を使用して、PDF ファイルからテキストを抽出する例です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
public class extractPdfText {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// 抽出結果を効率的に保持するため StringBuilder を使用
StringBuilder extractedText = new StringBuilder();
// テキスト抽出オプションを設定
PdfTextExtractOptions options = new PdfTextExtractOptions();
// シンプル抽出モードを有効化(可読性向上)
options.setSimpleExtraction(true);
// 各ページを順に処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// ページごとに PdfTextExtractor を作成
PdfTextExtractor extractor =
new PdfTextExtractor(pdf.getPages().get(i));
// オプションを指定してテキストを抽出
String pageText = extractor.extract(options);
extractedText.append(pageText).append("\n");
}
System.out.println(extractedText.toString());
}
}
コンソール出力例
PdfTextExtractor ページ単位で動作し、テキスト再構成を細かく制御できます。
PdfTextExtractOptions 抽出挙動を調整可能です。setSimpleExtraction(true) を有効にすると、レイアウト処理を簡略化し、読みやすいテキストが得られます。
ページ単位処理 大容量 PDF への対応や、問題のあるページの切り分けが容易になります。
この方法は、レポート、契約書など、比較的レイアウトが安定したテキスト中心の PDF に適しており、Spire.PDF for Java を使用した Java での PDF テキスト解析として推奨されるアプローチです。 その他のテキスト抽出の例については、「Javaを使用してPDFページからテキストを抽出する方法」を参照してください。
**表解析(テーブル抽出)**は、PDF 内の表構造を検出し、行と列を持つ構造化データとして再構築する高度な解析処理です。単純なテキスト抽出と異なり、セル間の意味的な関係を保持できるため、請求書、財務諸表、業務レポートなどで広く利用されます。
Java で PDF を解析する際、表解析を行うことで、視覚的に整列された情報をプログラムで扱いやすい構造化データへ変換できます。
表解析では、単純なテキスト抽出から、視覚的な配置とレイアウトの一貫性に基づく構造推定へと処理の焦点が移ります。
表解析は、テキストの位置関係をもとに構造を推定するため、行・列インデックスを用いたセル単位のアクセスが可能になります。
以下は、Spire.PDF for Java の PdfTableExtractor を使用して PDF ページから表を解析する例です。抽出された表は、行と列を持つ構造化データとして扱えます。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
public class extractPdfTable {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 表抽出器を作成
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// 1 ページ目から表を解析(インデックスは 0 から)
PdfTable[] tables = extractor.extractTable(0);
if (tables != null) {
for (PdfTable table : tables) {
int rowCount = table.getRowCount();
int columnCount = table.getColumnCount();
System.out.println("Rows: " + rowCount +
", Columns: " + columnCount);
StringBuilder tableData = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
tableData.append(table.getText(i, j));
if (j < columnCount - 1) {
tableData.append("\t");
}
}
if (i < rowCount - 1) {
tableData.append("\n");
}
}
System.out.println(tableData.toString());
}
}
}
}
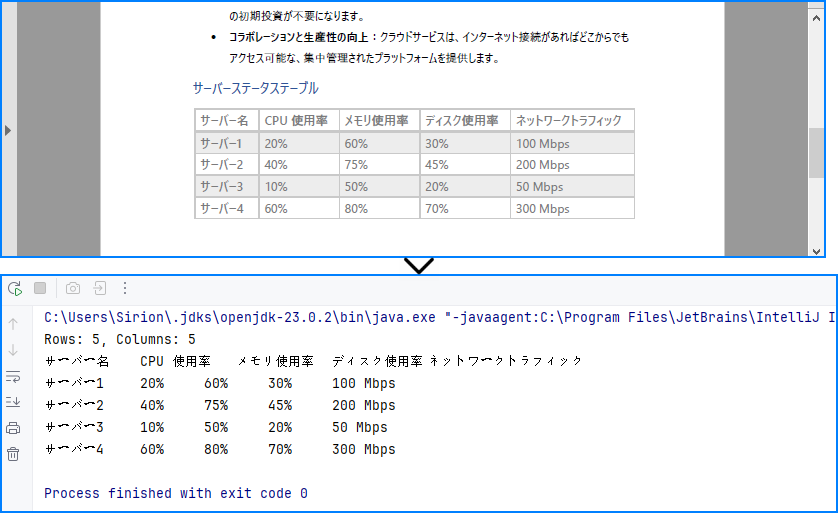
コンソール出力例
PdfTableExtractor ページコンテンツを解析し、視覚的な配置情報から表領域を検出します。
構造の再構築 テキスト要素の相対位置に基づいて行・列を推定し、セル単位でのアクセスを可能にします。
ページ単位解析 ページごとのレイアウト差異に対応しやすく、精度向上につながります。
制約はあるものの、表解析は Java における PDF 解析機能の中でも特に価値が高く、業務文書からのデータ自動抽出において重要な役割を果たします。
PDFページから表構造を解析した後、抽出されたデータは「JavaでPDF表をCSVに変換する」で示されているように、さらなる利用のためにCSVなどの構造化形式へエクスポートされることが多い。
画像解析(画像抽出)は、PDF ページ内に埋め込まれている画像リソースを抽出することに特化した PDF 解析機能です。テキストや表の解析がコンテンツストリームやレイアウト推定に基づくのに対し、画像解析はページレベルのリソース情報を解析し、画像オブジェクトを直接取得します。
Java ベースの PDF 処理システムでは、画像解析は以下のような用途でよく利用されます。
実装レベルでは、画像解析はテキスト解析とは異なり、ページのリソース情報を対象として処理が行われます。
画像はページの独立したリソースとして管理されているため、この処理はテキストフローやレイアウト再構築、表検出のロジックに依存しません。
以下の例では、Spire.PDF for Java の PdfImageHelper と PdfImageInfo を使用して、PDF ページに埋め込まれた画像を抽出し、PNG ファイルとして保存します。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class extractPdfImages {
public static void main(String[] args) throws IOException {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// PdfImageHelper を作成
PdfImageHelper imageHelper = new PdfImageHelper();
// 各ページを順に処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 現在のページに含まれる画像情報を取得
PdfImageInfo[] imageInfos =
imageHelper.getImagesInfo(pdf.getPages().get(i));
if (imageInfos != null) {
for (int j = 0; j < imageInfos.length; j++) {
// BufferedImage として画像を取得
BufferedImage image = imageInfos[j].getImage();
// 画像を PNG ファイルとして保存
File output = new File(
"output/images/page_" + i + "_image_" + j + ".png"
);
ImageIO.write(image, "PNG", output);
}
}
}
}
}
抽出された画像の例
PdfImageHelper / PdfImageInfo ページレベルのリソースを解析し、埋め込まれた画像を BufferedImage として取得できます。
ページ単位の解析 複数ページ PDF や、同一画像が再利用されている場合でも正確に抽出できます。
レイアウト非依存 テキスト配置や表構造に依存しないため、あらゆるビジュアル要素の抽出に適しています。
個別画像の抽出だけでなく、PDF ページ全体を画像として変換することも可能です。詳細は Java で PDF ページを画像に変換する方法 を参照してください。
メタデータ解析は、PDF の視覚コンテンツとは独立して保存されているドキュメントレベル情報を取得する基本的な PDF 解析機能です。ページレイアウトに依存しないため、ほぼすべての PDF に対して安定して適用できます。
Java ベースの PDF 処理システムでは、メタデータ解析は以下の目的で利用されることが多くあります。
メタデータ解析は、ページ単位の解析とは異なり、ドキュメント全体に対する処理として実装されます。
メタデータはレンダリング内容とは独立して保存されているため、高速かつ一貫性のある解析処理が可能です。
以下の例では、Spire.PDF for Java を使用して、一般的な PDF メタデータ項目を取得します。これらの情報は、検索・分類・ワークフロー制御などに利用できます。
import com.spire.pdf.PdfDocument;
public class ParsePdfMetadata {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// ドキュメントメタデータを取得
String title = pdf.getDocumentInformation().getTitle();
String author = pdf.getDocumentInformation().getAuthor();
String subject = pdf.getDocumentInformation().getSubject();
String keywords = pdf.getDocumentInformation().getKeywords();
String creator = pdf.getDocumentInformation().getCreator();
String producer = pdf.getDocumentInformation().getProducer();
String creationDate = pdf.getDocumentInformation()
.getCreationDate().toString();
String modificationDate = pdf.getDocumentInformation()
.getModificationDate().toString();
System.out.println(
"Title: " + title +
"\nAuthor: " + author +
"\nSubject: " + subject +
"\nKeywords: " + keywords +
"\nCreator: " + creator +
"\nProducer: " + producer +
"\nCreation Date: " + creationDate +
"\nModification Date: " + modificationDate
);
}
}
コンソール出力例
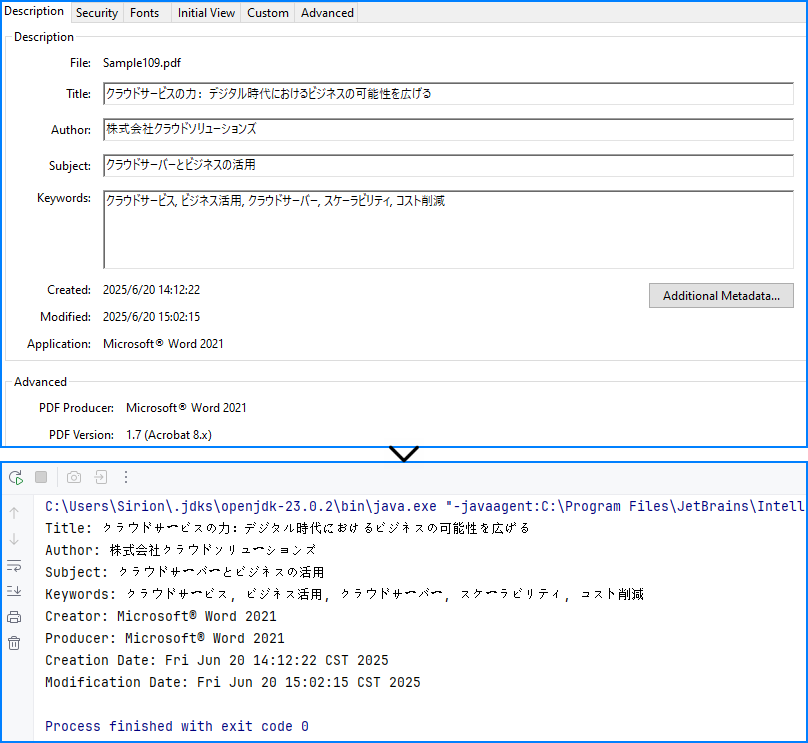
ドキュメント情報ディクショナリ メタデータは専用の構造に保存されており、ページ描画内容とは独立しています。
項目の有無に注意 すべての PDF に完全なメタデータが含まれているとは限らず、null や空文字になる場合があります。
低い処理コスト ページ走査が不要なため、高速な前処理として適しています。
メタデータ解析は、視覚レイアウトに依存しないため、複雑な PDF においても比較的安定した結果が得られます。
個々の解析処理は独立して実装できますが、実際の Java アプリケーションでは、複数の PDF 解析機能を組み合わせて同一パイプライン内で使用するケースが一般的です。
代表的な実装パターンには以下があります。
テキスト・表・画像・メタデータ解析を独立かつ組み合わせ可能な処理として設計することで、拡張性・テスト容易性・保守性が向上します。
高機能な Java PDF パーサーを使用しても、以下の制約は避けられません。
これらの制約を理解したうえで解析戦略を設計することで、本番環境での例外処理やエラー対応を簡素化できます。
Java での PDF 解析は、単一の線形処理としてではなく、目的別に分離された抽出処理の集合として設計することで、最も効果を発揮します。テキスト抽出、表解析、画像取得、メタデータアクセスをそれぞれ独立した関心事として扱うことで、PDF ドキュメントを安定して実用データへ変換できます。
Spire.PDF for Java のような専用 PDF 解析ライブラリを活用することで、実運用に耐える、拡張性の高い Java ベースの PDF 処理システムを構築できます。
Spire.PDF for Java を使用した PDF 解析の可能性を最大限に引き出すには、無料トライアルライセンスの申請 をご利用ください。
A1: Spire.PDF for Java の PdfTextExtractor と PdfTextExtractOptions を使用することで、ページ単位のテキストを効率的に抽出できます。検索、分析、データ移行など、柔軟な用途に対応できます。
A2: PdfTableExtractor を使用すると、表領域を検出し、行・列構造を再構築できます。抽出結果は構造化データとして保存・変換・エクスポート可能です。
A3: はい。PdfImageHelper と PdfImageInfo を使用することで、各ページに埋め込まれた画像を抽出し、ファイルとして保存できます。PDFページ全体を画像に変換することも可能です。
A4: PDFドキュメントから PdfDocumentInformation を取得することで、タイトル、作成者、作成日時、キーワードなどの標準メタデータを高速に取得できます。
A5: あります。複雑なレイアウト、スキャンPDF、カスタムフォントは解析精度に影響します。スキャンPDFの場合は、OCR処理を先に行う必要があります。
PDF ドキュメントに四角形、楕円、線などの図形を描画することで、ドキュメントの視覚的効果を高め、重要なポイントを強調することができます。レポートやプレゼンテーション、論文を作成する際、文章だけでは表現が難しい概念やデータの関係性を図形で補足すると、情報をより明確に伝えられます。本記事では、Java で Spire.PDF for Java を使用して PDF ドキュメントに図形を描画する方法を説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
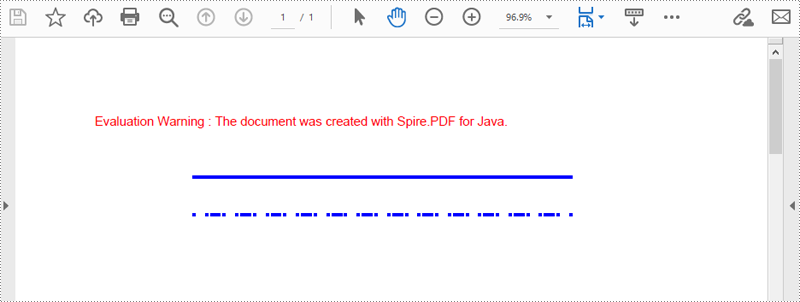
</dependencies>Spire.PDF for Java では、PdfPageBase.getCanvas().drawLine(PdfPen pen, float x1, float y1, float x2, float y2) メソッドを使用して、指定した位置に線を描画できます。また、PDF ペンのスタイルを変更することで、実線や点線などの異なる線を描画可能です。以下に詳細な手順を示します。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
public class drawLinePDF {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument pdf = new PdfDocument();
// ページを追加します
PdfPageBase page = pdf.getPages().add();
// 現在の描画状態を保存します
PdfGraphicsState state = page.getCanvas().save();
// 線の開始位置のXおよびY座標を指定します
float x = 100;
float y = 70;
// 線の長さを指定します
float width = 300;
// 青色で太さ2のPDFペンを作成します
PdfPen pen = new PdfPen(new PdfRGBColor(Color.BLUE), 2f);
// ペンを使用してページに実線を描画します
page.getCanvas().drawLine(pen, x, y, x + width, y);
// ペンのスタイルを点線に設定します
pen.setDashStyle(PdfDashStyle.Dash);
// 点線のパターンを設定します
pen.setDashPattern(new float[]{1, 4, 1});
// ペンを使用してページに点線を描画します
page.getCanvas().drawLine(pen, x, y+30, x + width, y+30);
// 保存した描画状態を復元します
page.getCanvas().restore(state);
// PDFドキュメントを保存します
pdf.saveToFile("output/PDFで線を描く.pdf");
// ドキュメントを閉じ、リソースを解放します
pdf.close();
pdf.dispose();
}
}
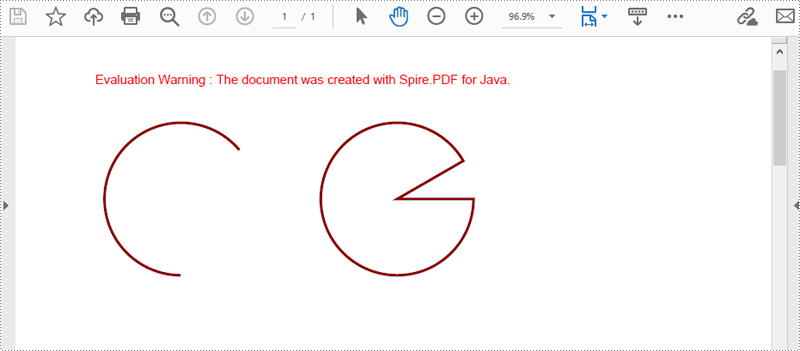
指定した位置に弧や扇形を描画するには、PdfPageBase.getCanvas().drawArc() および PdfPageBase.getCanvas().drawPie() メソッドを使用します。以下はその詳細手順です。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class drawArcAndPiePDF {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument pdf = new PdfDocument();
// ページを追加します
PdfPageBase page = pdf.getPages().add();
// 現在の描画状態を保存します
PdfGraphicsState state = page.getCanvas().save();
// 指定した色と太さ2のPDFペンを作成します
PdfPen pen = new PdfPen(new PdfRGBColor(new Color(139,0,0)), 2f);
// 弧の開始角度と掃引角度を指定します
float startAngle = 90;
float sweepAngle = 230;
// ペンを使用してページに弧を描画します
Rectangle2D.Float rect = new Rectangle2D.Float(30, 60, 120, 120);
page.getCanvas().drawArc(pen, rect, startAngle, sweepAngle);
// 扇形チャートの開始角度と掃引角度を指定します
float startAngle1 = 0;
float sweepAngle1 = 330;
// ペンを使用してページに扇形チャートを描画します
Rectangle2D.Float rect2 = new Rectangle2D.Float(200, 60, 120, 120);
page.getCanvas().drawPie(pen, rect2, startAngle1, sweepAngle1);
// 保存した描画状態を復元します
page.getCanvas().restore(state);
// PDFドキュメントを保存します
pdf.saveToFile("output/PDFに円弧や扇形を描画.pdf");
// ドキュメントを閉じ、リソースを解放します
pdf.close();
pdf.dispose();
}
}
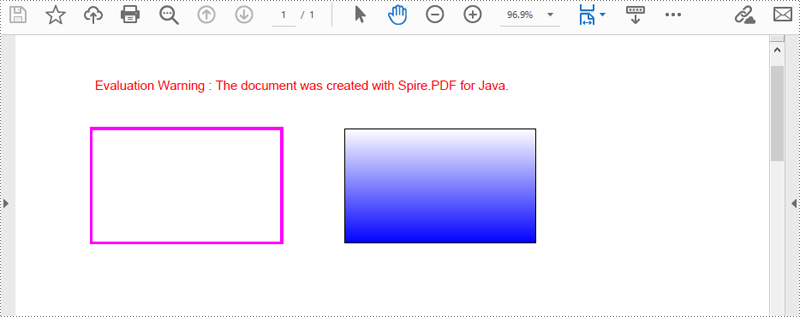
Spire.PDF for Java では、PdfPageBase.getCanvas().drawRectangle() メソッドを使用して PDF ページ上に長方形を描画できます。このメソッドに異なるパラメータを渡すことで、位置やサイズ、塗りつぶしの色を指定可能です。以下に詳細手順を示します。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class drawRectanglesPDF {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument pdf = new PdfDocument();
// ページを追加します
PdfPageBase page = pdf.getPages().add();
// 現在の描画状態を保存します
PdfGraphicsState state = page.getCanvas().save();
// 指定した色と太さ1.5のPDFペンを作成します
PdfPen pen = new PdfPen(new PdfRGBColor(Color.magenta), 1.5f);
// ペンを使用してページに長方形を描画します
page.getCanvas().drawRectangle(pen, new Rectangle(20, 60, 150, 90));
// 線形グラデーションブラシを作成します
Rectangle2D.Float rect = new Rectangle2D.Float(220, 60, 150, 90);
PdfLinearGradientBrush linearGradientBrush = new PdfLinearGradientBrush(
rect,
new PdfRGBColor(Color.white),
new PdfRGBColor(Color.blue),
PdfLinearGradientMode.Vertical
);
// 指定した色と太さ0.5の新しいPDFペンを作成します
PdfPen pen1 = new PdfPen(new PdfRGBColor(Color.black), 0.5f);
// 新しいペンと線形グラデーションブラシを使用して塗りつぶしの長方形を描画します
page.getCanvas().drawRectangle(pen1, linearGradientBrush, rect);
// 保存した描画状態を復元します
page.getCanvas().restore(state);
// PDFドキュメントを保存します
pdf.saveToFile("output/PDFで矩形を描く.pdf");
// ドキュメントを閉じ、リソースを解放します
pdf.close();
pdf.dispose();
}
}
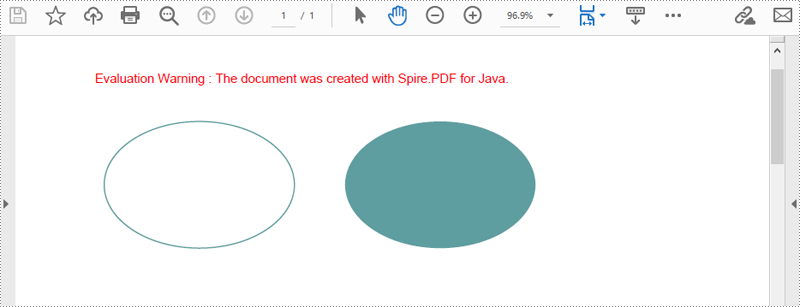
PdfPageBase.getCanvas().drawEllipse() メソッドを使用すると、PDF ページに楕円を描画できます。PDF ペンまたは塗りつぶし用ブラシを使用することで、異なるスタイルの楕円を描画可能です。以下に詳細手順を示します。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
public class drawEllipsesPDF {
public static void main(String[] args) {
// PdfDocumentオブジェクトを作成します
PdfDocument pdf = new PdfDocument();
// ページを追加します
PdfPageBase page = pdf.getPages().add();
// 現在の描画状態を保存します
PdfGraphicsState state = page.getCanvas().save();
// 指定した色と太さのPDFペンを作成します
PdfPen pen = new PdfPen(new PdfRGBColor(new Color(95, 158, 160)), 1f);
// ペンを使用してページに楕円を描画します
page.getCanvas().drawEllipse(pen, 30, 60, 150, 100);
// 塗りつぶし用の指定した色のブラシを作成します
PdfBrush brush = new PdfSolidBrush(new PdfRGBColor(new Color(95, 158, 160)));
// ブラシを使用してページに塗りつぶし楕円を描画します
page.getCanvas().drawEllipse(brush, 220, 60, 150, 100);
// 保存した描画状態を復元します
page.getCanvas().restore(state);
// PDFドキュメントを保存します
pdf.saveToFile("output/PDFで楕円を描く.pdf");
// ドキュメントを閉じ、リソースを解放します
pdf.close();
pdf.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
タグ付き PDF は、HTML コードによく似たタグを含む PDF ドキュメントです。タグは、PDF のコンテンツが支援技術によってどのように表示されるかを管理する論理構造を提供します。各タグは、見出しレベル1 <H1>、段落 <P>、画像 <Figure>、表 <Table> など、関連するコンテンツ要素を識別します。この記事では、Spire.PDF for Java を使って Java プログラムでタグ付き PDF ドキュメントを作成する方法を説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.9.6</version>
</dependency>
</dependencies>タグ付き PDF 文書に構造要素を追加するには、まず PdfTaggedContent クラスのオブジェクトを作成する必要があります。次に、PdfTaggedContent.getStructureTreeRoot().appendChildElement() メソッドを使用して、要素をルートに追加します。以下は、Spire.PDF for Java を使ってタグ付き PDF に「見出し」要素を追加する詳細な手順です。
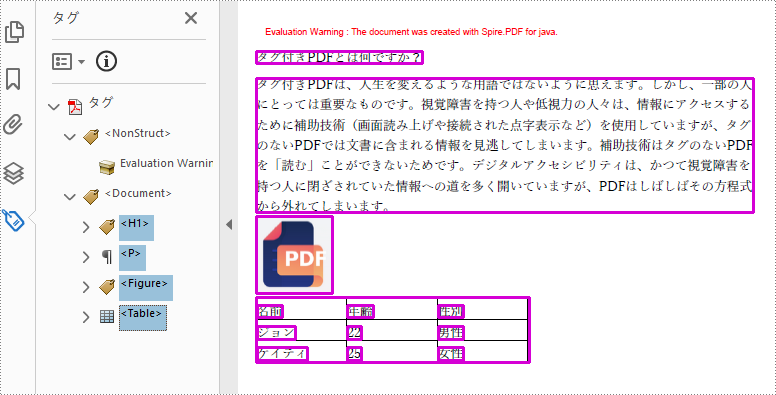
次のコード例は、Java でタグ付き PDF ドキュメントのドキュメント、見出し、段落、図、表などのさまざまな要素を作成する方法を示しています。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.interchange.taggedpdf.PdfStandardStructTypes;
import com.spire.pdf.interchange.taggedpdf.PdfStructureElement;
import com.spire.pdf.interchange.taggedpdf.PdfTaggedContent;
import com.spire.pdf.tables.PdfTable;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
public class createTaggedPDF {
public static void main(String[] args) throws Exception {
//PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
//ページを追加します
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(20));
//タブの順序を設定します
page.setTabOrder(TabOrder.Structure);
//PdfTaggedContentクラスのオブジェクトを作成します
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
//ドキュメントの言語とタイトルを設定します
taggedContent.setLanguage("ja-JP");
taggedContent.setTitle("Javaによるタグ付きPDFドキュメントの作成");
//PDF/UA1の識別情報を設定します
taggedContent.setPdfUA1Identification();
//フォントとブラシを作成します
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Mincho",Font.PLAIN,14), true);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//"ドキュメント"要素を追加します
PdfStructureElement document = taggedContent.getStructureTreeRoot().appendChildElement(PdfStandardStructTypes.Document);
// "見出し"要素を追加します
PdfStructureElement heading1 = document.appendChildElement(PdfStandardStructTypes.HeadingLevel1);
heading1.beginMarkedContent(page);
String headingText = "タグ付きPDFとは何ですか?";
page.getCanvas().drawString(headingText, font, brush, new Point2D.Float(0, 30));
heading1.endMarkedContent(page);
// "段落"要素を追加します
PdfStructureElement paragraph = document.appendChildElement(PdfStandardStructTypes.Paragraph);
paragraph.beginMarkedContent(page);
String paragraphText = "タグ付きPDFは、人生を変えるような用語ではないように思えます。しかし、一部の人にとっては重要なものです。視覚障害を持つ人や低視力の人々は、情報にアクセスするために補助技術(画面読み上げや接続された点字表示など)を使用していますが、タグのないPDFでは文書に含まれる情報を見逃してしまいます。補助技術はタグのないPDFを「読む」ことができないためです。デジタルアクセシビリティは、かつて視覚障害を持つ人に閉ざされていた情報への道を多く開いていますが、PDFはしばしばその方程式から外れてしまいます。";
Rectangle2D.Float rect = new Rectangle2D.Float(0, 60, (float) page.getCanvas().getClientSize().getWidth(), (float) page.getCanvas().getClientSize().getHeight());
page.getCanvas().drawString(paragraphText, font, brush, rect);
paragraph.endMarkedContent(page);
// "図"要素を追加します
PdfStructureElement figure = document.appendChildElement(PdfStandardStructTypes.Figure);
figure.beginMarkedContent(page);
PdfImage image = PdfImage.fromFile("PDF.png");
page.getCanvas().drawImage(image, new Point2D.Float(0, 220));
figure.endMarkedContent(page);
// "表"要素を追加します
PdfStructureElement table = document.appendChildElement(PdfStandardStructTypes.Table);
table.beginMarkedContent(page);
PdfTable pdfTable = new PdfTable();
pdfTable.getStyle().getDefaultStyle().setFont(font);
String[] data = {"名前;年齢;性別",
"ジョン;22;男性",
"ケイティ;25;女性"
};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
pdfTable.setDataSource(dataSource);
pdfTable.getStyle().setShowHeader(true);
pdfTable.draw(page.getCanvas(), new Point2D.Float(0, 310), 300f);
table.endMarkedContent(page);
// ドキュメントをファイルに保存します
doc.saveToFile("PDFUAの作成.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ドキュメントの比較は、効果的なドキュメント管理に不可欠です。PDF ドキュメントを比較することで、ユーザーはドキュメント内容の違いを簡単に識別し、より包括的に理解することができます。これにより、ユーザーは文書内容を変更したり統合したりすることが非常に容易になります。この記事では、Spire.PDF for Java を使用して PDF 文書を比較し、相違点を見つける方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.9.6</version>
</dependency>
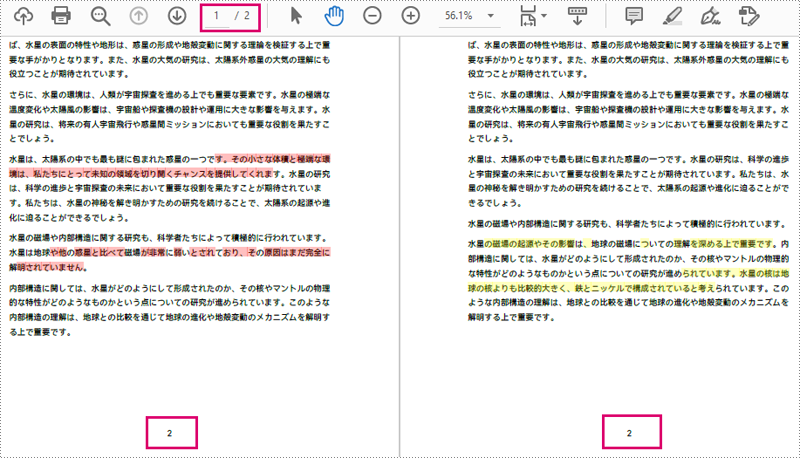
</dependencies>比較に使用する2つの PDF ドキュメント:
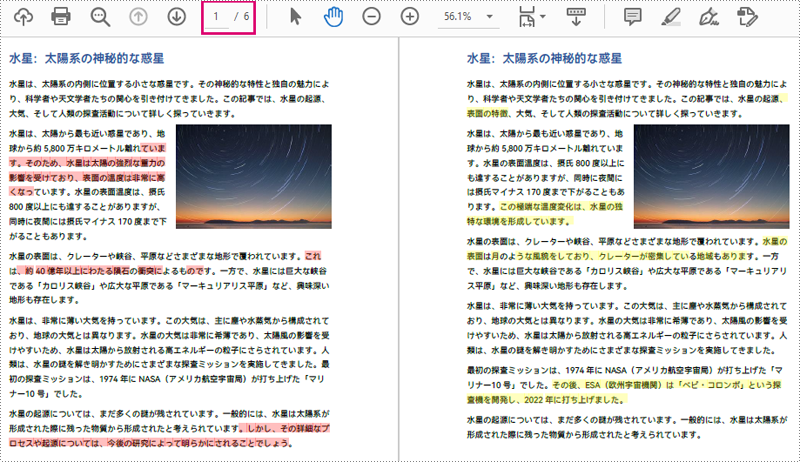
Spire.PDF for Java は、ユーザーが2つの PDF ドキュメントを比較するためのオブジェクトを作成するための PdfComparer クラスを提供します。PdfComparer オブジェクトを作成した後、ユーザーは PdfComparer.compare(String fileName) メソッドを使用して2つのドキュメントを比較し、結果を新しい PDF ファイルとして保存することができます。
できあがった PDF ドキュメントは、2つのオリジナルドキュメントを左と右に表示し、削除された項目は赤で、追加された項目は黄色で表示されます。
2つの PDF ドキュメントを比較する詳細な手順は以下のとおりです:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.comparison.PdfComparer;
public class ComparePDF {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成して、PDFドキュメントを読み込む
PdfDocument pdf1 = new PdfDocument();
pdf1.loadFromFile("例1.pdf");
//別のPdfDocumentクラスのオブジェクトを作成して、別のPDFドキュメントを読み込む
PdfDocument pdf2 = new PdfDocument();
pdf2.loadFromFile("例2.pdf");
//PdfComparerクラスのオブジェクトを作成する
PdfComparer comparer = new PdfComparer(pdf1, pdf2);
//2つのPDFドキュメントを比較し、比較結果を新しいドキュメントに保存する
comparer.compare("比較結果1.pdf");
}
}
比較する前に、ユーザーは PdfComparer.getOptions().setPageRanges() メソッドを使用して、比較するページ範囲を制限することができます。詳しい手順は以下のとおりです:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.comparison.PdfComparer;
public class ComparePDFPageRange {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成して、PDFドキュメントを読み込む
PdfDocument pdf1 = new PdfDocument();
pdf1.loadFromFile("例1.pdf");
//別のPdfDocumentクラスのオブジェクトを作成して、別のPDFドキュメントを読み込む
PdfDocument pdf2 = new PdfDocument();
pdf2.loadFromFile("例2.pdf");
//PdfComparerクラスのオブジェクトを作成する
PdfComparer comparer = new PdfComparer(pdf1, pdf2);
//比較するページ範囲を設定する
comparer.getOptions().setPageRanges(1, 1, 1, 1);
//2つのPDFドキュメントを比較し、比較結果を新しいドキュメントに保存する
comparer.compare("比較結果2.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ポートフォリオは、テキスト文書、スプレッドシート、プレゼンテーション、画像、ビデオ、オーディオファイルなど、複数のファイルを1つのインタラクティブな PDF コンテナに結合する機能をサポートしています。ユーザーは PDF ポートフォリオを作成することで、プロジェクトに関連するすべての資料を一緒に保存し、ファイルの管理や送信をより簡単に行うことができます。この記事では、Spire.PDF for Java を使用して PDF ポートフォリオを作成する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.7.8</version>
</dependency>
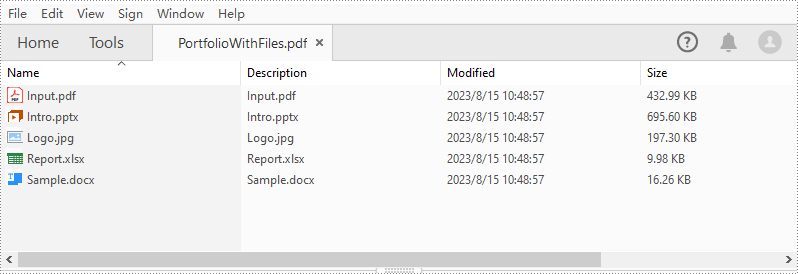
</dependencies>PDF ポートフォリオは、複数のファイルの集合です。Spire.PDF for Java の PdfDocument.getCollection() メソッドを使用して、PDF ポートフォリオを簡単に作成することができます。その後、PdfCollection.addFile() メソッドを使用してそこにファイルを追加することができます。具体的な手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class CreatePortfolioWithFiles {
public static void main(String []args){
//ファイルを指定する
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//PdfDocument インスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDF ポートフォリオを作成し、そこにファイルを追加する
for (int i = 0; i < files.length; i++)
{
pdf.getCollection().addFile(files[i]);
}
//結果ファイルを保存する
pdf.saveToFile("PortfolioWithFiles.pdf", FileFormat.PDF);
pdf.dispose();
}
}
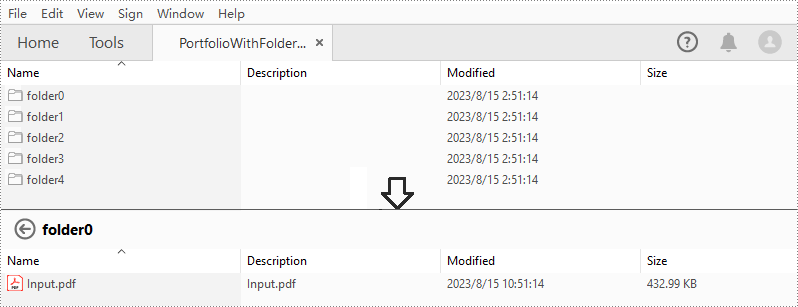
PDF ポートフォリオを作成した後、Spire.PDF for Java では、PDF ポートフォリオ内にフォルダを作成してファイルをさらに管理することも可能です。具体的な手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.collections.PdfFolder;
public class CreatePortfolioWithFolders {
public static void main(String []args){
//ファイルを指定する
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//PdfDocument インスタンスを作成する
PdfDocument pdf = new PdfDocument();
//ポートフォリオを作成し、そこにフォルダーを追加する
for (int i = 0; i < files.length; i++)
{
PdfFolder folder = pdf.getCollection().getFolders().createSubfolder("folder" + i);
//ファイルをフォルダーに追加する
folder.addFile(files[i]);
}
//結果ファイルを保存する
pdf.saveToFile("PortfolioWithFolders.pdf", FileFormat.PDF);
pdf.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF のレイヤーとは、ドキュメントのコンテンツをグループ化して階層化する方法であり、オプションコンテンツグループ(OCG)オブジェクトを使用してサポートされています。ユーザーは必要に応じて異なるレイヤーを選択的に表示または非表示にすることができます。PDF のレイヤーは通常、テキスト、画像、図形、注釈などのドキュメントの視覚要素を管理するために使用されます。これらの要素を異なるレイヤーに配置することで、ユーザーはドキュメントの可視性とレイアウトを簡単に制御することができます。この記事では、Spire.PDF for Java を使用して Java プログラムを介して PDF ドキュメントにレイヤーを追加、非表示にしたり削除したりする方法について説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.7.8</version>
</dependency>
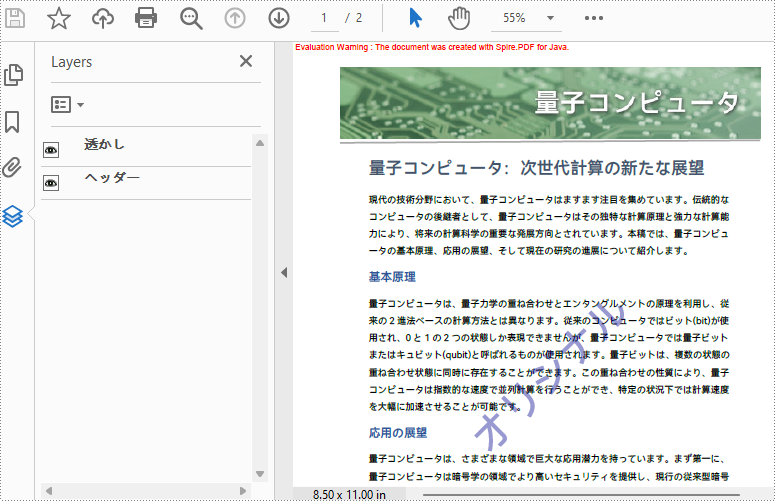
</dependencies>Spire.PDF for Java は、PDF ドキュメントにレイヤーを追加する PdfDocument.getLayers().addLayer() メソッドを提供します。 その具体的な手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import com.spire.pdf.graphics.layer.PdfLayer;
import java.awt.*;
import java.awt.geom.Dimension2D;
import java.io.IOException;
public class addLayersToPdf {
public static void main(String[] args) throws IOException {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("サンプル.pdf");
//AddLayerWatermarkメソッドを使用してウォーターマークのレイヤーを追加する
AddLayerWatermark(pdf);
//AddLayerHeaderメソッドを使用してヘッダーのレイヤーを追加する
AddLayerHeader(pdf);
//ドキュメントを保存する
pdf.saveToFile("レイヤーの追加.pdf");
pdf.dispose();
}
private static void AddLayerWatermark(PdfDocument doc) {
//"透かし"という名前のレイヤーを作成する
PdfLayer layer = doc.getLayers().addLayer("透かし");
//フォントを作成する
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("HarmonyOS Sans SC Medium", Font.PLAIN, 48), true);
//透かしのテキストを指定する
String watermarkText = "オリジナル";
//テキストのサイズを取得する
Dimension2D fontSize = font.measureString(watermarkText);
//オフセットを計算する
float offset1 = (float) (fontSize.getWidth() * Math.sqrt(2) / 4);
float offset2 = (float) (fontSize.getHeight() * Math.sqrt(2) / 4);
//ページ数を取得する
int pageCount = doc.getPages().getCount();
//2つの変数を宣言する
PdfPageBase page;
PdfCanvas canvas;
//すべてのページをループで処理する
for (int i = 0; i < pageCount; i++) {
page = doc.getPages().get(i);
//レイヤーにキャンバスを作成する
canvas = layer.createGraphics(page.getCanvas());
canvas.translateTransform(canvas.getSize().getWidth() / 2 - offset1 - offset2, canvas.getSize().getHeight() / 2 + offset1 - offset2);
canvas.setTransparency(0.4f);
canvas.rotateTransform(-45);
//テキストをレイヤーのキャンバスに描画する
canvas.drawString(watermarkText, font, PdfBrushes.getDarkBlue(), 0, 0);
}
}
private static void AddLayerHeader(PdfDocument doc) {
//"ヘッダー"という名前のレイヤーを作成する
PdfLayer layer = doc.getLayers().addLayer("ヘッダー");
//ページのサイズを取得する
Dimension2D size = doc.getPages().get(0).getSize();
//ページ数を取得する
int pageCount = doc.getPages().getCount();
//2つの変数を宣言する
PdfPageBase page;
PdfCanvas canvas;
//すべてのページをループで処理する
for (int i = 0; i < pageCount; i++) {
//レイヤーに画像を描画する
PdfImage pdfImage = PdfImage.fromFile("ヘッダー.jpg");
page = doc.getPages().get(i);
float width = pdfImage.getWidth();
float height = pdfImage.getHeight();
float x = (float) size.getWidth() / 2 - width / 2;
float y = 30;
canvas = layer.createGraphics(page.getCanvas());
canvas.drawImage(pdfImage, x, y, width, height);
//レイヤーに線を描画します
PdfPen pen = new PdfPen(PdfBrushes.getDarkGray(), 2f);
canvas.drawLine(pen, x, y + height + 5, size.getWidth() - x, y + height + 2);
}
}
}
既存の PDF レイヤーの可視性を設定するには、指定されたレイヤーのインデックスまたは名前を通して PdfDocument.getLayers().get() メソッドを使用し、PdfLayer.setVisibility(PdfVisibility value) メソッドを使用してレイヤーの表示または非表示を設定する必要があります。 その具体的な手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.layer.PdfVisibility;
public class setLayerVisibility {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("レイヤーの追加.pdf");
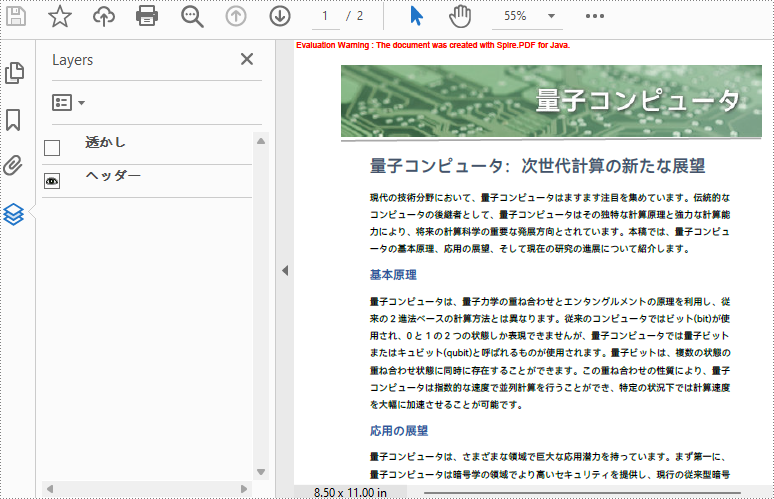
//最初のレイヤーの可視性をOffに設定する
pdf.getLayers().get(0).setVisibility(PdfVisibility.Off);
//ファイルを保存する
pdf.saveToFile("レイヤーの非表示.pdf", FileFormat.PDF);
pdf.dispose();
}
}
Spire.PDF for Java では、PdfDocument.getLayers().removeLayer(java.lang.String name) メソッドを使用して、既存のレイヤーを名前で削除することもできます。 しかし 、 PDF レイヤーの名前は一意でない可能性があり 、 このメソッドは同じ名前の PDF レイヤーをすべて削除しますので注意してください。 具体的な手順は以下のとおりです。
import com.spire.pdf.PdfDocument;
public class deleteLayers {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("レイヤーの追加.pdf");
//指定したレイヤーをその名前で削除する
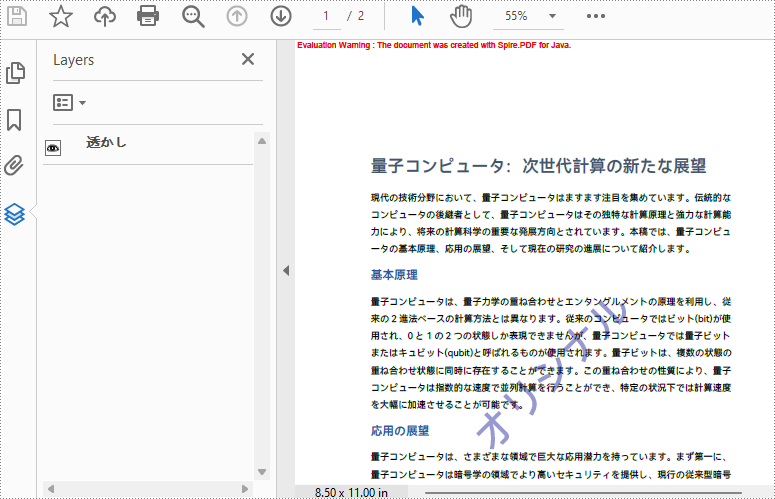
pdf.getLayers().removeLayer("ヘッダー");
//ファイルを保存する
pdf.saveToFile("レイヤーの削除.pdf");
pdf.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
コードによる PDF 生成にはさまざまな利点があります。リアルタイムデータ、データベースレコード、ユーザー入力などの動的コンテンツを容易に統合するのに役立ちます。この機能は、ユーザーにより優れたカスタマイズと自動化機能を提供し、面倒な手動操作も回避します。この記事では、Spire.PDF for Java を使用して PDF ドキュメントを作成する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.5.6</version>
</dependency>
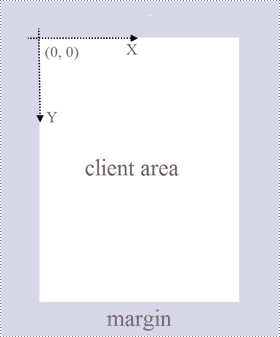
</dependencies>Spire.PDF for Java のページ(PdfPageBase クラスで表される)は、クライアント領域と周囲のマージンで構成されています。コンテンツ領域は、ユーザーがさまざまなコンテンツを記述するための領域であり、ページ余白は通常空白のエッジになります。
下図に示すように、ページ上の座標系の原点はクライアント領域の左上隅にあり、x 軸は水平に右に伸び、y 軸は垂直に下に伸びています。クライアント領域に追加するすべての要素は、指定された座標に基づいている必要があります。
さらに、次の表に重要なクラスと方法を示します。これは、以下のコードを理解しやすくするのに役立ちます。
| クラスと 方法 | 説明 |
| PdfDocument クラス | PDF ドキュメント モデルを表します。 |
| PdfPageBase クラス | PDF ドキュメント内のページを表します。 |
| PdfSolidBrush クラス | オブジェクトを単色で塗りつぶすブラシを表します。 |
| PdfTrueTypeFont クラス | True Typeフォントを表します。 |
| PdfStringFormat クラス | アライメント、文字間隔、インデントなどのテキスト書式情報を表します。 |
| PdfTextWidget クラス | 複数のページにまたがる機能を持つテキスト領域を表します。 |
| PdfTextLayout クラス | テキストのレイアウト情報を表します。 |
| PdfDocument.getPages().add() メソッド | PDF ドキュメントにページを追加します。 |
| PdfPageBase.getCanvas().drawString() メソッド | 指定したフォントとブラシオブジェクトを使用して、ページ上の指定した位置に文字列を描画します。 |
| PdfTextWidget.draw() メソッド | テキストウィジェットをページの指定した位置に描画します。 |
| PdfDocument.save() メソッド | ドキュメントを PDF ファイルに保存します。 |
Spire.PDF for Java では、PDF ドキュメントにさまざまな要素を追加できます。この記事では、プレーンテキストの PDF ドキュメントを作成する方法について説明します。詳細な手順は次のとおりです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
import java.io.*;
public class CreatePdfDocument {
public static void main(String[] args) throws IOException {
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(35f));
//タイトルのテキストの指定
String titleText = "ライセンス契約";
//Solid Brusheを作成する
PdfSolidBrush titleBrush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
PdfSolidBrush paraBrush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//True Typeフォントを作成する
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("Yu Mincho",Font.BOLD,18));
PdfTrueTypeFont paraFont = new PdfTrueTypeFont(new Font("Yu Mincho",Font.PLAIN,12));
//PdfStringFormatクラスによるテキストの配置を設定する
PdfStringFormat format = new PdfStringFormat();
format.setAlignment(PdfTextAlignment.Center);
//ページにタイトルを描画する
page.getCanvas().drawString(titleText, titleFont, titleBrush, new Point2D.Float((float)page.getClientSize().getWidth()/2, 20),format);
//.txtファイルから段落テキストを取得する
String paraText = readFileToString("content.txt");
//段落内容を保存するPdfTextWidgetオブジェクトを作成する
PdfTextWidget widget = new PdfTextWidget(paraText, paraFont, paraBrush);
//段落の内容を配置する長方形を作成する
Rectangle2D.Float rect = new Rectangle2D.Float(0, 50, (float)page.getClientSize().getWidth(),(float)page.getClientSize().getHeight());
//PdfLayoutTypeをPaginateに設定して内容を自動的にページング
PdfTextLayout layout = new PdfTextLayout();
layout.setLayout(PdfLayoutType.Paginate);
//ページに段落テキストを描画する
widget.draw(page, rect, layout);
//ファイルに保存する
doc.saveToFile("output/CreatePdfDocument.pdf");
doc.dispose();
}
//.txtファイルを文字列に変換する
private static String readFileToString(String filepath) throws FileNotFoundException, IOException {
StringBuilder sb = new StringBuilder();
String s ="";
BufferedReader br = new BufferedReader(new FileReader(filepath));
while( (s = br.readLine()) != null) {
sb.append(s + "\n");
}
br.close();
String str = sb.toString();
return str;
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
大きい PDF ドキュメントよりも小さいサイズのドキュメントの方が転送や保存に便利です。これが PDF を圧縮する最も一般的な理由の1つです。この記事では、Spire.PDF for Java を使用して PDF ドキュメントを圧縮する方法を紹介します。
ここでは、画像、フィールド、コメント、ブックマーク、添付ファイル、埋め込みフォントを削除することによって PDF サイズを小さくすることには触れません。ライブラリを使用してこれらの操作を実行したい場合は、チュートリアルに記載されている適切な記事を参照してください。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
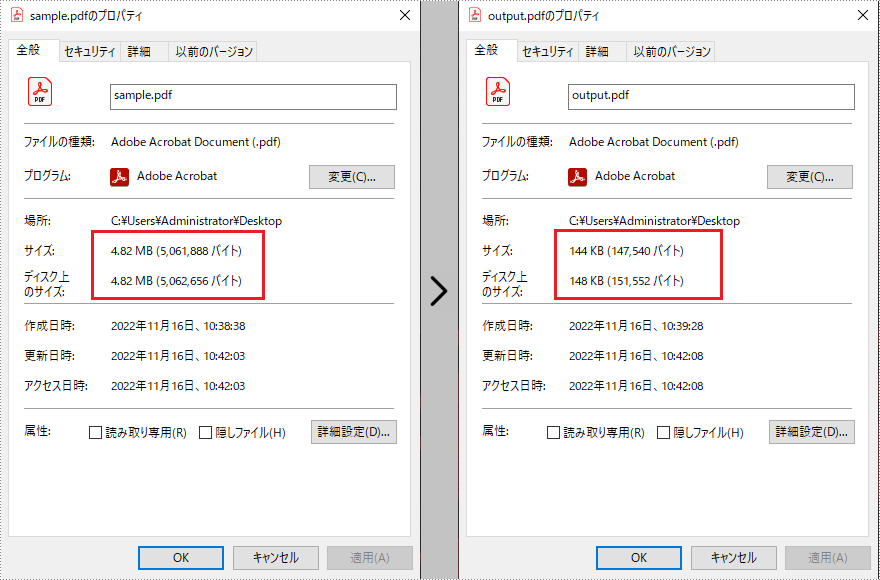
</dependencies>Spire.PDF for Java が提供する PdfDocument.setCompressionLevel() と PdfBitmap.setQuality() メソッドは、圧縮レベルの最適な設定と画像の品質の圧縮をサポートします。次に、PdfPageBase.replaceImage() メソッドを使用して圧縮された画像を元の画像に置き換えます。以下に詳細な圧縮手順を示します。
import com.spire.pdf.PdfCompressionLevel;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.exporting.PdfImageInfo;
import com.spire.pdf.graphics.PdfBitmap;
public class CompressPdfDocument {
public static void main(String[] args) {
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントをロードする
doc.loadFromFile("sample.pdf");
//増分更新を禁止する
doc.getFileInfo().setIncrementalUpdate(false);
//圧縮レベルを最適に設定する
doc.setCompressionLevel(PdfCompressionLevel.Best);
//ドキュメント内のページをループする
for (int i = 0; i < doc.getPages().getCount(); i++) {
//特定のページを取得する
PdfPageBase page = doc.getPages().get(i);
//ページの画像情報コレクションを取得する
PdfImageInfo[] images = page.getImagesInfo();
//コレクション内のすべてのアイテムをループする
if (images != null && images.length > 0)
for (int j = 0; j < images.length; j++) {
//特定の画像を取得する
PdfImageInfo image = images[j];
PdfBitmap bp = new PdfBitmap(image.getImage());
//圧縮品質を設定する
bp.setQuality(20);
//元の画像を圧縮された画像に替える
page.replaceImage(j, bp);
}
//文書を別のPDFファイルに保存する
doc.saveToFile("output.pdf");
doc.close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
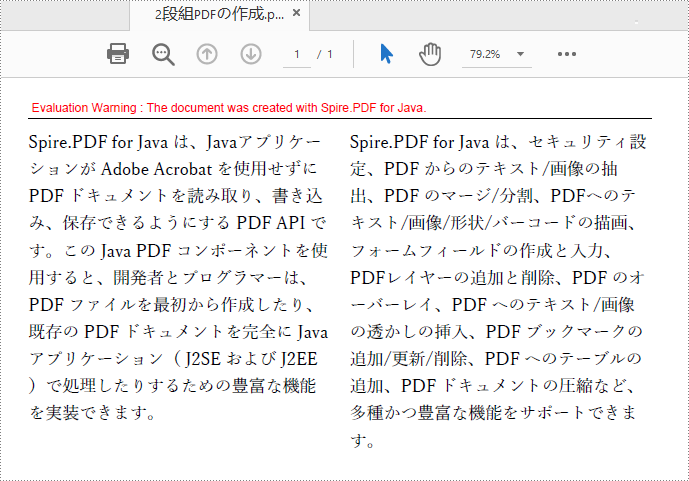
雑誌、新聞、研究論文などでは、多段組の PDF がよく使われます。Spire.PDF for Java を使えば、コードから簡単に多段組の PDF を作成することができます。この記事では、Java アプリケーションにおいて 2段組の PDF を作成する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>詳しい手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class createTwoColumnPDF {
public static void main(String[] args) throws Exception {
//PdfDocument クラスのオブジェクトを作成します
PdfDocument doc = new PdfDocument();
//新しいページを追加する
PdfPageBase page = doc.getPages().add();
//位置と幅を設定する
float x = 0;
float y = 15;
float width = 600;
//PdfPen クラスのオブジェクトを作成する
PdfPen pen = new PdfPen(new PdfRGBColor(Color.black), 1f);
//PDFページ上に線を描画する
page.getCanvas().drawLine(pen, x, y, x + width, y);
//段落テキストを定義する
String s1 = "Spire.PDF for Java は、Javaアプリケーションが Adobe Acrobat を使用せずに PDF ドキュメントを読み取り、"
+ "書き込み、保存できるようにする PDF API です。この Java PDF コンポーネントを使用すると、"
+ "開発者とプログラマーは、PDF ファイルを最初から作成したり、既存の PDF ドキュメント"
+ "を完全に Java アプリケーション( J2SE および J2EE )で処理したりするための豊富な機能を実装できます。";
String s2 = "Spire.PDF for Java は、セキュリティ設定、PDF からのテキスト/画像の抽出、PDF のマージ/分割、"
+ "PDFへのテキスト/画像/形状/バーコードの描画、フォームフィールドの作成と入力、"
+ "PDFレイヤーの追加と削除、PDF のオーバーレイ、PDF へのテキスト/画像の透かしの挿入、"
+ "PDF ブックマークの追加/更新/削除、PDF へのテーブルの追加、"
+ "PDF ドキュメントの圧縮など、多種かつ豊富な機能をサポートできます。";
//ページの幅と高さを取得する
double pageWidth = page.getClientSize().getWidth();
double pageHeight = page.getClientSize().getHeight();
//PdfSolidBrush クラスのオブジェクトを作成する
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//PdfTrueTypeFont クラスのオブジェクトを作成する
PdfTrueTypeFont font= new PdfTrueTypeFont(new Font("Yu Mincho",Font.PLAIN,14));
//PdfStringFormat クラスによるテキスト配置を設定する
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Left);
//テキストを描画する
page.getCanvas().drawString(s1, font, brush, new Rectangle2D.Double(0, 20, pageWidth / 2 - 8f, pageHeight), format);
page.getCanvas().drawString(s2, font, brush, new Rectangle2D.Double(pageWidth / 2 + 8f, 20, pageWidth / 2 - 8f, pageHeight), format);
//ドキュメントを保存する
String output = "2段組PDFの作成.pdf";
doc.saveToFile(output, FileFormat.PDF);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
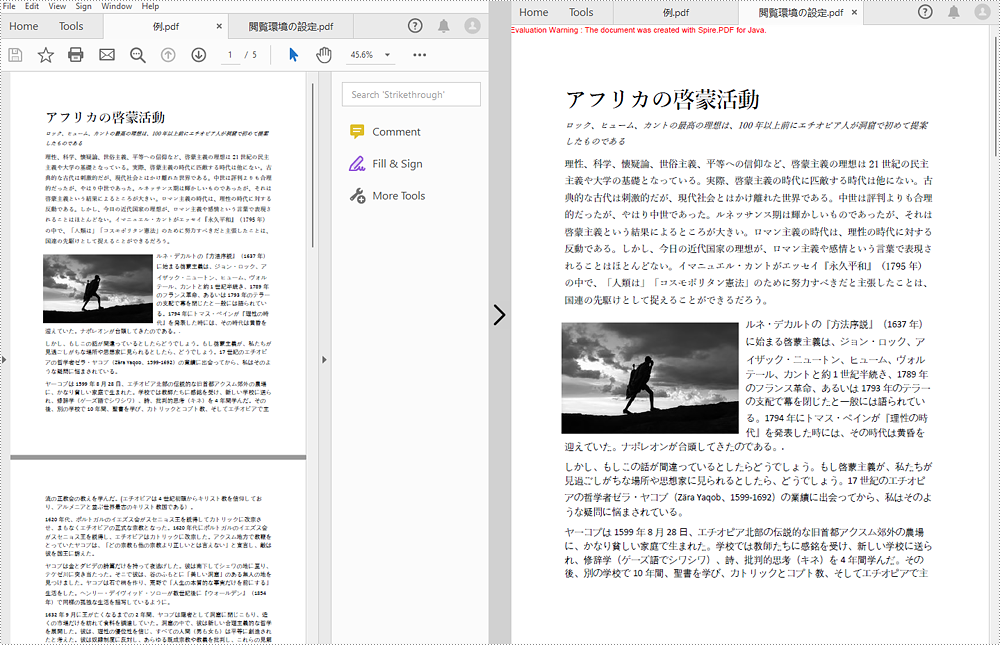
ドキュメントを正確に保存し、表示することは、PDF の主要な機能です。しかし、異なるデバイスやユーザーの閲覧環境設定が、PDF ドキュメントの表示に影響を与えることに変わりはありません。この問題を解決するために、PDF は、PDF ドキュメントが画面上に表示される方法を制御するために、ドキュメント内の閲覧環境設定エントリを提供します。これがないと、PDF ドキュメントは、現在のユーザーの環境設定に従って表示されます。この記事では、Spire.PDF for Java を使用したプログラミングによって、PDF の閲覧環境の設定を行う方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire.PDF for Java は、PdfViewerPreferences クラスの下に、ウィンドウの中央配置、タイトルの表示、ウィンドウのフィット、メニューバーやツールバーの非表示、ページレイアウト、ページモード、スケーリングモードなどを設定できるメソッドをいくつか備えています。以下は、閲覧環境の設定に関する詳細な手順である。
import com.spire.pdf.*;
public class setViewerPreference {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.loadFromFile("C:/例.pdf");
//ドキュメントの閲覧環境の設定を取得する
PdfViewerPreferences preferences = pdf.getViewerPreferences();
//閲覧環境を設定する
preferences.setCenterWindow(true);
preferences.setDisplayTitle(false);
preferences.setFitWindow(true);
preferences.setHideMenubar(true);
preferences.setHideToolbar(true);
preferences.setPageLayout(PdfPageLayout.Single_Page);
//preferences.setPageMode(PdfPageMode.Full_Screen);
//preferences.setPrintScaling(PrintScalingMode.App_Default);
//ファイルを保存する
pdf.saveToFile("閲覧環境の設定.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





