チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション
表は PDF の請求書や財務報告書によく見られます。MS Excel が提供するツールを使ってデータを分析できるように、PDF の表データを Excel にエクスポートする必要がある場面に遭遇するかもしれません。この記事では、Spire.Office for Java を使って PDF ページから表を抽出し、それを Excel ワークシートに書き込む方法を説明します。
実際には、PDF から表を抽出するために Spire.PDF for Java を使用し、Excel ファイルを生成するために Spire.XLS for Java を使用します。同じプロジェクトでこれらを使用するには、Java プログラムの依存関係として Spire.Office.jar ファイルを追加する必要があります。
JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>9.1.10</version>
</dependency>
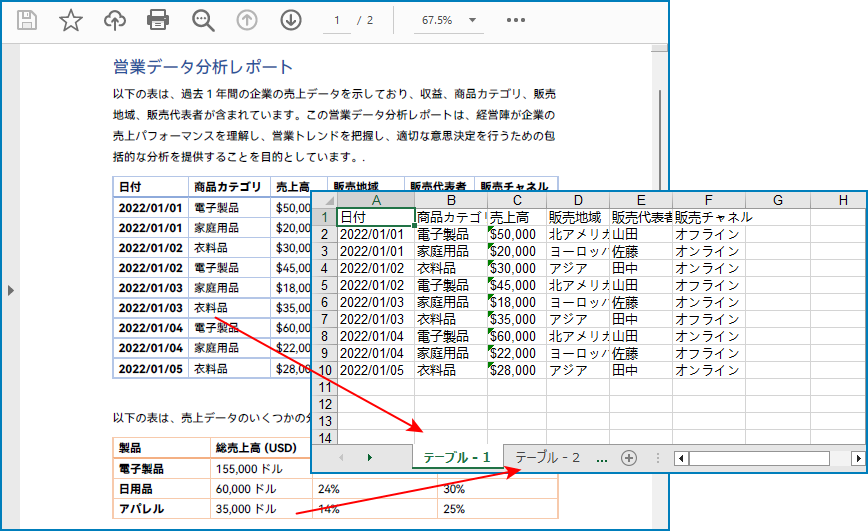
</dependencies>以下は、あるページからすべての表を抽出し、それぞれを独立したワークシートとして Excel ファイルに保存するための主な手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractTableDataAndSaveInExcel {
public static void main(String[] args) {
//PDFドキュメントをロードします
PdfDocument pdf = new PdfDocument("サンプル.pdf");
//PdfTableExtractorインスタンスを作成します
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//最初のページからテーブルを抽出します
PdfTable[] pdfTables = extractor.extractTable(0);
//Workbookオブジェクトを作成します
Workbook wb = new Workbook();
//デフォルトのワークシートを削除します
wb.getWorksheets().clear();
//テーブルが見つかった場合
if (pdfTables != null && pdfTables.length > 0) {
//テーブルをループします
for (int tableNum = 0; tableNum < pdfTables.length; tableNum++) {
//ワークシートをワークブックに追加します
String sheetName = String.format("テーブル - %d", tableNum + 1);
Worksheet sheet = wb.getWorksheets().add(sheetName);
//現在のテーブルの行をループします
for (int rowNum = 0; rowNum < pdfTables[tableNum].getRowCount(); rowNum++) {
//現在のテーブルの列をループします
for (int colNum = 0; colNum < pdfTables[tableNum].getColumnCount(); colNum++) {
//現在のテーブルセルからデータを抽出します
String text = pdfTables[tableNum].getText(rowNum, colNum);
//特定のセルにデータを挿入します
sheet.get(rowNum + 1, colNum + 1).setText(text);
}
}
//列幅を自動調整します
for (int sheetColNum = 0; sheetColNum < sheet.getColumns().length; sheetColNum++) {
sheet.autoFitColumn(sheetColNum + 1);
}
}
}
//ワークブックをExcelファイルに保存します
wb.saveToFile("output/PDFの表をExcelに書き出す.xlsx", ExcelVersion.Version2016);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
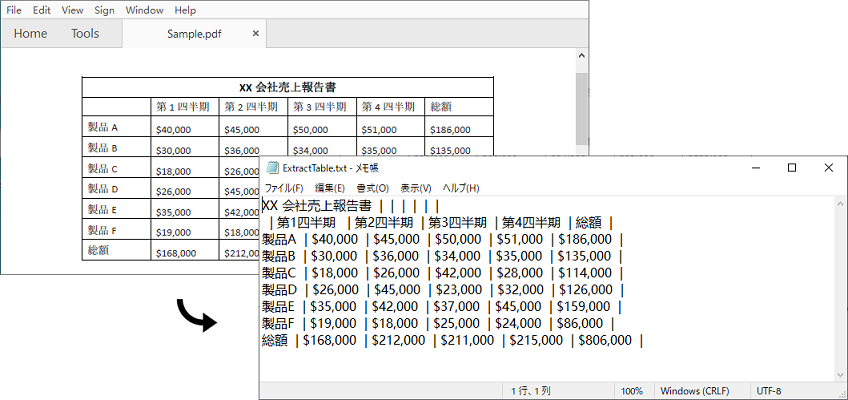
テーブルは、PDF で最もよく使用される書式設定要素の 1 つです。 場合によっては、さらに分析を行うために PDF のテーブルからデータを抽出する必要がある場合があります。この記事では、Spire.PDF for Java を使用して PDF からテーブルのデータを抽出する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.12.0</version>
</dependency>
</dependencies>Spire.PDF for Java は、PdfTableExtractor.extractTable(int pageIndex) メソッドを使用して、特定の PDF ページからテーブルを検出して抽出します。以下は、PDF ファイルからテーブルデータを抽出する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String []args) throws Exception {
//サンプルPDFファイルをロードする
PdfDocument pdf = new PdfDocument("Sample.pdf");
//StringBuilder インスタンスを作成する
StringBuilder builder = new StringBuilder();
//PdfTableExtractor インスタンスを作成する
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//PDFのページをループする
for (int pageIndex = 0; pageIndex < pdf.getPages().getCount(); pageIndex++) {
//現在のページからテーブルを PdfTable 配列に抽出する
PdfTable[] tableLists = extractor.extractTable(pageIndex);
//テーブルが見つかった場合
if (tableLists != null && tableLists.length > 0) {
//配列内のテーブルをループする
for (PdfTable table : tableLists) {
//現在のテーブルの行をループする
for (int i = 0; i < table.getRowCount(); i++) {
//現在のテーブルの列をループする
for (int j = 0; j < table.getColumnCount(); j++) {
//現在のテーブルのセルからデータを抽出し、StringBuilder に追加する
String text = table.getText(i, j);
builder.append(text + " | ");
}
builder.append("\r\n");
}
}
}
}
//データを .txt ファイルに書き込む
FileWriter fw = new FileWriter("ExtractTable.txt");
fw.write(builder.toString());
fw.flush();
fw.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
表は、情報やデータを水平方向の行と垂直方向の列の形で表現します。特にデータが数字で構成されていたり、サイズが大きい場合は、段落テキストにデータを入れるよりも表を作成した方が効果的です。表形式のデータ表示により、読みやすく、理解しやすくなります。この記事では、Spire.PDF for Java を使用して、Java で PDF 文書に表を作成する方法を説明します。
Spire.PDF for Java は、PDF ドキュメント内のテーブルを扱うために PdfTable と PdfGrid クラスを提供しています。PdfTable クラスは、あまり多くの書式を持たない簡単な、通常の表を素早く作成するために使用され、一方、PdfGrid クラスは、より複雑な表を作成するために使用されます。
下の表は、この2つのクラスの違いを示したものです。
| PdfTable | PdfGrid | |
| 書式設定 | ||
| 行 | イベントで設定可能。API は未対応。 | API で設定可能。 |
| 列 | API で設定可能。 | API で設定可能。 |
| セル | イベントで設定可能。API は未対応。 | API で設定可能。 |
| その他 | ||
| 列を跨ぐ | 対応していない。 | API で設定可能。 |
| 行を跨ぐ | イベントで設定可能。API は未対応。 | API で設定可能。 |
| ネストされた表 | イベントで設定可能。API は未対応。 | API で設定可能。 |
| イベント | BeginCellLayout, EndCellLayout, BeginRowLayout, EndRowLayout, BeginPageLayout, EndPageLayout. | BeginPageLayout, EndPageLayout. |
以下のセクションでは、PdfTable クラスと PdfGrid クラスを使って、それぞれ PDF に表を作成する方法を説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
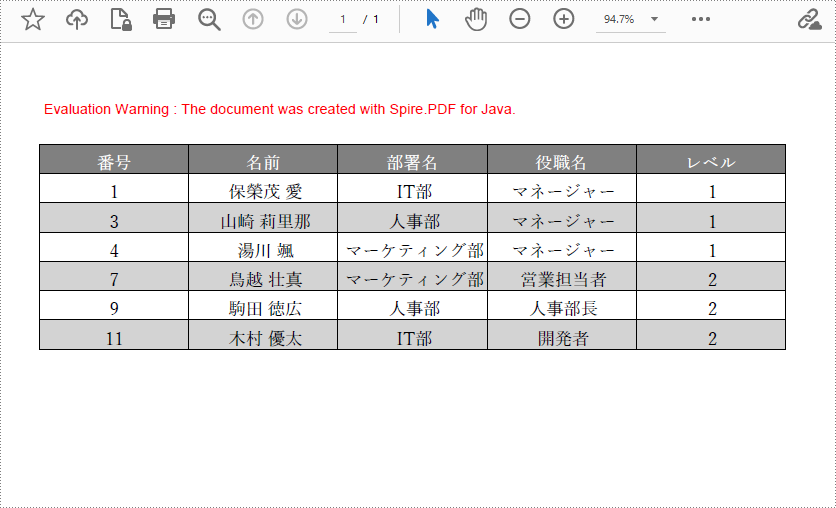
</dependencies>PdfTable クラスを使用して表を作成する手順を以下に示します。
import com.spire.data.table.DataTable;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.tables.*;
import java.awt.*;
import java.awt.geom.Point2D;
public class createTable {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(40));
//PdfTable クラスのオブジェクトを作成する
PdfTable table = new PdfTable();
//ヘッダーとそれ以外のセルのフォントを設定する
table.getStyle().getDefaultStyle().setFont(new PdfTrueTypeFont(new Font("Yu Mincho", Font.PLAIN, 12), true));
table.getStyle().getHeaderStyle().setFont(new PdfTrueTypeFont(new Font("Yu Mincho", Font.BOLD, 12), true));
//データを定義する
String[] data = {"番号;名前;部署名;役職名;レベル",
"1; 保榮茂 愛; IT部; マネージャー; 1",
"3; 山崎 莉里那; 人事部; マネージャー; 1",
"4; 湯川 颯; マーケティング部; マネージャー; 1",
"7; 鳥越 壮真; マーケティング部; 営業担当者; 2",
"9; 駒田 徳広; 人事部; 人事部長; 2",
"11; 木村 優太; IT部; 開発者; 2"};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
//データを表のデータとして設定する
table.setDataSource(dataSource);
//最初の行をヘッダー行として設定する
table.getStyle().setHeaderSource(PdfHeaderSource.Rows);
table.getStyle().setHeaderRowCount(1);
//ヘッダーの表示(デフォルトでは非表示)
table.getStyle().setShowHeader(true);
//ヘッダー列の文字色と背景色を設定する
table.getStyle().getHeaderStyle().setBackgroundBrush(PdfBrushes.getGray());
table.getStyle().getHeaderStyle().setTextBrush(PdfBrushes.getWhite());
//ヘッダー列のテキスト配置を設定する
table.getStyle().getHeaderStyle().setStringFormat(new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle));
//他のセルのテキスト配置を設定する
for (int i = 0; i < table.getColumns().getCount(); i++) {
table.getColumns().get(i).setStringFormat(new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle));
}
//BeginRowLayoutイベントに対応する
table.beginRowLayout.add(new BeginRowLayoutEventHandler() {
public void invoke(Object sender, BeginRowLayoutEventArgs args) {
Table_BeginRowLayout(sender, args);
}
});
//ページ上に表を描画する
table.draw(page, new Point2D.Float(0, 30));
//ドキュメントを保存する
doc.saveToFile("PDFの表.pdf");
}
//イベント処理
private static void Table_BeginRowLayout(Object sender, BeginRowLayoutEventArgs args) {
//行の高さを設定する
args.setMinimalHeight(20f);
//ヘッダー行以外の行の色を変更する
if (args.getRowIndex() == 0) {
return;
}
if (args.getRowIndex() % 2 == 0) {
args.getCellStyle().setBackgroundBrush(PdfBrushes.getLightGray());
} else {
args.getCellStyle().setBackgroundBrush(PdfBrushes.getWhite());
}
}
}
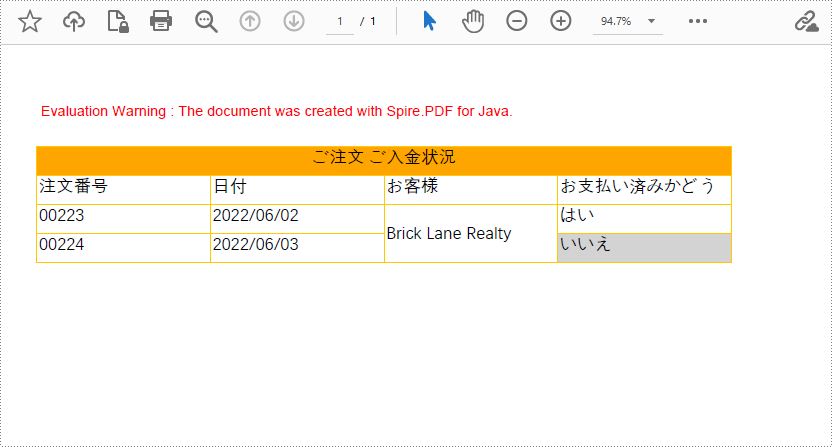
以下は、PdfGrid クラスを使用して PDF に表を作成する手順です。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.grid.PdfGrid;
import com.spire.pdf.grid.PdfGridRow;
import java.awt.*;
import java.awt.geom.Point2D;
public class createGrid {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4,new PdfMargins(40));
//PdfGrid クラスのオブジェクトを作成する
PdfGrid grid = new PdfGrid();
//セルの余白を設定する
grid.getStyle().setCellPadding(new PdfPaddings(1, 1, 1, 1));
//フォントを設定する
grid.getStyle().setFont(new PdfTrueTypeFont(new Font("等线", Font.PLAIN, 12), true));
//行と列を追加する
PdfGridRow row1 = grid.getRows().add();
PdfGridRow row2 = grid.getRows().add();
PdfGridRow row3 = grid.getRows().add();
PdfGridRow row4 = grid.getRows().add();
grid.getColumns().add(4);
//列の幅を設定する
for (int i = 0; i < grid.getColumns().getCount(); i++) {
grid.getColumns().get(i).setWidth(120);
}
//特定のセルにデータを書き込む
row1.getCells().get(0).setValue("ご注文・ご入金状況");
row2.getCells().get(0).setValue("注文番号");
row2.getCells().get(1).setValue("日付");
row2.getCells().get(2).setValue ("お客様");
row2.getCells().get(3).setValue("お支払い済みかどうか");
row3.getCells().get(0).setValue("00223");
row3.getCells().get(1).setValue("2022/06/02");
row3.getCells().get(2).setValue("Brick Lane Realty");
row3.getCells().get(3).setValue("はい");
row4.getCells().get(0).setValue("00224");
row4.getCells().get(1).setValue("2022/06/03");
row4.getCells().get(3).setValue("いいえ");
//列をまたぐセルを配置する
row1.getCells().get(0).setColumnSpan(4);
//行をまたいでセルを配置する
row3.getCells().get(2).setRowSpan(2);
//特定のセルのテキスト配置を設定する
row1.getCells().get(0).setStringFormat(new PdfStringFormat(PdfTextAlignment.Center));
row3.getCells().get(2).setStringFormat(new PdfStringFormat(PdfTextAlignment.Left, PdfVerticalAlignment.Middle));
//特定のセルの背景色を設定する
row1.getCells().get(0).getStyle().setBackgroundBrush(PdfBrushes.getOrange());
row4.getCells().get(3).getStyle().setBackgroundBrush(PdfBrushes.getLightGray());
//セルの罫線の書式を設定する
PdfBorders borders = new PdfBorders();
borders.setAll(new PdfPen(new PdfRGBColor(Color.ORANGE), 0.8f));
for (int i = 0; i < grid.getRows().getCapacity(); i++) {
PdfGridRow gridRow = grid.getRows().get(i);
gridRow.setHeight(20f);
for (int j = 0; j < gridRow.getCells().getCount(); j++) {
gridRow.getCells().get(j).getStyle().setBorders(borders);
}
}
//ページ上に表を描画する
grid.draw(page, new Point2D.Float(0, 30));
//ドキュメントを保存する
doc.saveToFile("PDFグリッド.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





