
C# 開発では、PDF をバイト配列として扱うケースがよくあります。たとえば、PDF 文書をデータベースに保存したり、API を通して送受信したり、ファイルシステムを使わずに完全にメモリ内で処理する必要がある場合です。このような場面では、C# で PDF とバイト配列を相互に変換する方法が重要になります。
本記事では、Spire.PDF for .NET を使用して、バイト配列から PDF を生成する方法、PDF をバイト配列に変換する方法、さらにはメモリ上で直接 PDF を編集する方法まで、手順を追って解説します。
読みたいところからジャンプ
- なぜ C# で PDF とバイト配列を扱うのか?
- C# でバイト配列を PDF に変換する方法
- C# で PDF をバイト配列に変換する方法
- バイト配列から直接 PDF を作成・編集する方法
- Spire.PDF for .NET を使う利点
- まとめ
- よくある質問
なぜ C# で PDF とバイト配列を扱うのか?
byte[] をデータの受け渡し形式として利用することで、一時ファイルを避けられ、クラウドやコンテナ環境にも適したコードが書けます。
- データベース保存(BLOB): PDF を生のバイトとして保存し、必要な時だけ復元。
- Web API: HTTP 経由でディスクを介さずに PDF を送受信。
- メモリ内処理: ストリーム上で変換や透かし挿入を完結。
- セキュリティ・分離: ファイル I/O を最小限にし、一時ファイルのリスクを軽減。
準備: サンプルコードを実行する前に、Spire.PDF for .NET の NuGet パッケージを追加してください。
Install-Package Spire.PDF
インストール後は、byte[] や Stream から読み込み、ページを編集し、出力をメモリやディスクに書き出せます。追加のコンバーターは不要です。
C# でバイト配列を PDF に変換する方法
API やメッセージキューから受け取った byte[] が PDF を表す場合、文書として展開し処理を行ったり、ディスクに保存したりする必要があります。Spire.PDF for .NET を使えば、一時ファイルを作成せずにメモリから直接ロードできます。
シナリオと手順: DB や API からの byte[] を受け取り、メモリ上で PdfDocument を構築し、必要なら基本情報を確認してから保存します。
using Spire.Pdf;
using System.IO;
class Program
{
static void Main()
{
// 例: DB や API から取得した byte[]
byte[] pdfBytes = File.ReadAllBytes("Sample.pdf");
// 1) バイト配列からメモリ上に PDF をロード
PdfDocument doc = new PdfDocument();
doc.LoadFromBytes(pdfBytes);
// 2) (任意)保存前にページ数などの基本情報を確認
// int pageCount = doc.Pages.Count;
// 3) ファイルに保存
doc.SaveToFile("Output.pdf");
doc.Close();
}
}
下図はバイト配列から PDF への変換フローです。
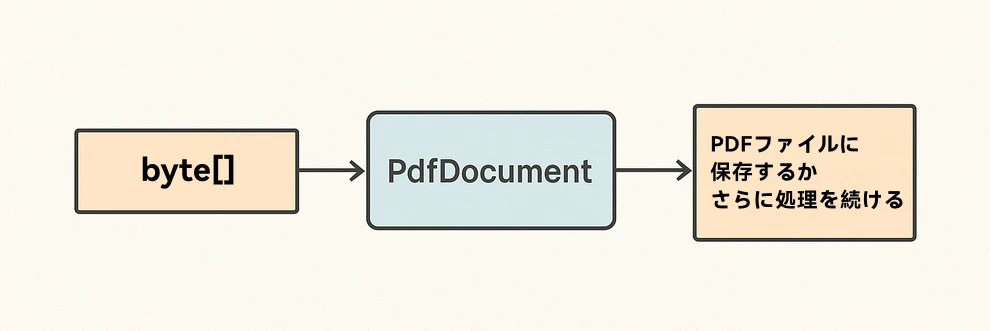
ポイント:
- LoadFromBytes(byte[]) で完全にメモリ上にロード。ファイル書き込み権限がない環境に最適。
- ロード後に分岐して、検証・編集・ルーティングなども可能。
- SaveToFile(string) で下流処理や保存用にディスクへ書き出し。
C# で PDF をバイト配列に変換する方法
逆方向として、PDF を byte[] に変換することで、データベース書き込み、キャッシュ、HTTP レスポンスでの送信が可能になります。Spire.PDF for .NET では、MemoryStream に直接書き込み、ToArray() でバイト配列に変換できます。
シナリオと手順: 既存の PDF を読み込み、MemoryStream に保存し、byte[] を抽出します。API のレスポンスや DB 保存に便利なパターンです。
using Spire.Pdf;
using System.IO;
class Program
{
static void Main()
{
// 1) PDF をロード(ローカル、ネットワーク、リソースなど)
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// 2) MemoryStream に保存してバイト配列を取得
byte[] pdfBytes;
using (var ms = new MemoryStream())
{
doc.SaveToStream(ms);
pdfBytes = ms.ToArray();
}
doc.Close();
// pdfBytes を DB 保存や API レスポンスとして利用可能
// 例: return File(pdfBytes, "application/pdf");
}
}
下図は PDF からバイト配列への変換フローです。
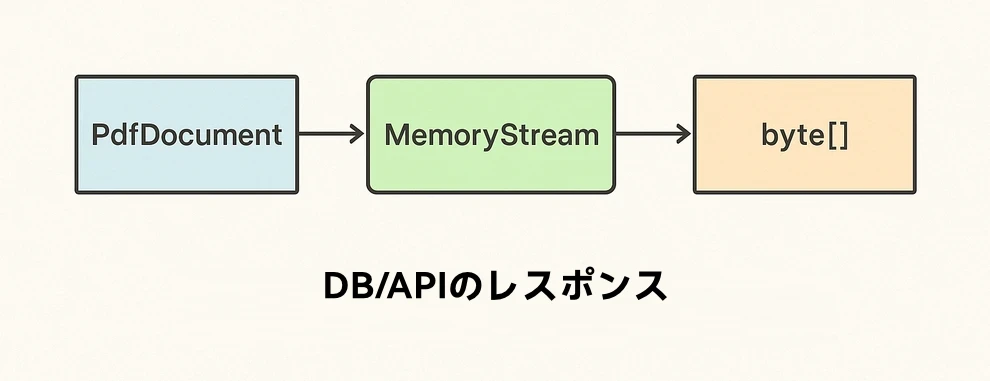
コードの要点:
- SaveToStream → ToArray が、C# で一時ファイルを作らずに PDF をバイト配列化する標準的な方法。
- 大きな PDF にも対応可能で、制約はメモリ量のみ。
- ASP.NET ではコントローラや API の戻り値として直接返せる。
バイト配列から直接 PDF を作成・編集する方法
真価は、PDF を完全にメモリ上で編集できる点にあります。byte[] からロードし、テキストや画像を追加、透かしやフォーム入力を行い、編集結果を新しい byte[] として保存できます。ファイルレスの処理フローやマイクロサービスに最適です。
シナリオと手順: バイト配列から PDF をロードし、1 ページ目に小さなテキストを追加して、編集済みの文書を新しいバイト配列として出力します。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;
class Program
{
static void Main()
{
// 入力ソース(DB、API、ファイルなど)を byte[] で受け取る
byte[] inputBytes = File.ReadAllBytes("Input.pdf");
// 1) メモリ上にロード
var doc = new PdfDocument();
doc.LoadFromBytes(inputBytes);
// 2) 編集: 1 ページ目に小さなテキストを追加
PdfPageBase page = doc.Pages[0];
page.Canvas.DrawString(
"Edited in memory",
new PdfTrueTypeFont(new Font("Yu Gothic UI", 14f), true),
PdfBrushes.DarkBlue,
new PointF(100, page.Size.Height - 100)
);
// 3) 編集済み PDF を新しい byte[] に保存
byte[] editedBytes;
using (var ms = new MemoryStream())
{
doc.SaveToStream(ms);
editedBytes = ms.ToArray();
}
doc.Close();
// editedBytes を DB 保存や API レスポンスとして利用可能
}
}
下図は編集済み PDF の例です。
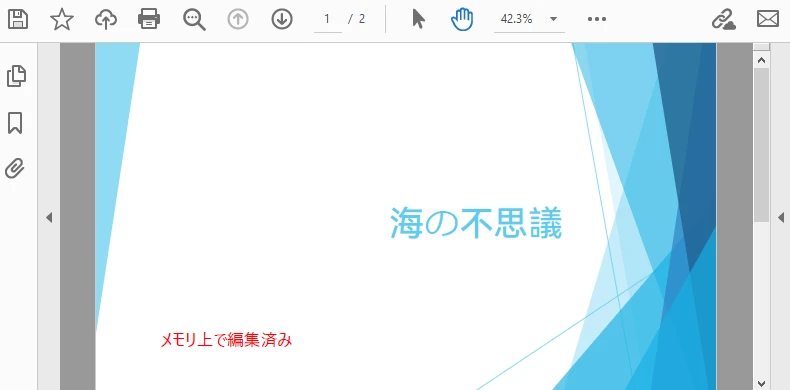
補足:
- このパターンは テキスト・画像・透かし・注釈・フォーム入力 にもそのまま使える。
- 再処理に備え、編集処理は冪等性を保つ(例: 透かしが重複しないようにチェック)。
- ASP.NET ではレスポンス返却前の オンザフライ編集 にも便利。
ゼロから PDF を構築する手順については、C# で PDF 文書を作成する方法 を参照ください。
Spire.PDF for .NET を使う利点
バイト配列ワークフローに適した特徴をまとめると以下の通りです。
| 課題 | Spire.PDF for .NET で得られるメリット |
|---|---|
| I/O の柔軟性 | ファイルパス・Stream・byte[] すべて同じ PdfDocument API で対応。 |
| メモリ内編集 | テキスト / 画像描画、注釈・フォーム管理、透かし追加など、一時ファイル不要。 |
| サービス親和性 | ASP.NET エンドポイントやバックグラウンド処理と簡潔に統合可能。 |
| 実運用対応 | 複数ページ PDF にも対応。ストリームでメモリ使用量を制御可能。 |
| シンプルなコード | ボイラープレート最小化。煩雑なバイト操作や脆弱な Interop を回避。 |
まとめ
本記事では、C# でバイト配列から PDF を生成する方法、PDF をバイト配列に変換する方法、そして メモリ上で直接 PDF を編集する方法 を紹介しました。ストリームとバイト配列を活用することで、API 設計がシンプルになり、レスポンスが高速化し、データベースやクラウド環境にも適した処理フローを実現できます。Spire.PDF for .NET を利用すれば、ファイルレスかつ拡張性の高いワークフローを簡潔に構築できます。
機能を制限なく試したい場合は、30 日間の無料一時ライセンスを申請 してください。軽量なタスクには、Free Spire.PDF for .NET も利用できます。
よくある質問
ディスクに保存せず、C# でバイト配列から PDF を作成できますか? はい。LoadFromBytes でロードし、MemoryStream に保存するか、API から直接返却すれば、ディスク不要で処理できます。
C# で PDF をバイト配列に変換してデータベースに保存する方法は? PdfDocument で SaveToStream を実行し、MemoryStream の ToArray() を呼び出します。その byte[] を BLOB として保存できます。
バイト配列として存在する PDF を編集できますか?
もちろん可能です。バイト配列からロードし、テキスト・画像・透かし・注釈・フォーム入力を行い、新しい byte[] に保存できます。
パフォーマンスや信頼性を高めるポイントは?
ストリームは早めに Dispose し、必要に応じてバッファを再利用します。操作やスレッドごとに新しい PdfDocument を生成してください。大きなファイルにはストリーム I/O を活用することで、メモリ使用量を安定させられます。





