チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

スプレッドシートを作成する際には、行の高さや列の幅を設定することで、レイアウトや外観を調整することができます。Microsoft Excel では、列の幅や行の高さを変更するためのさまざまな方法が提供されています。たとえば、列や行の枠線をドラッグして目的のサイズに調整したり、列幅ボックスや行高さボックスに特定の値を入力したりすることができます。ただし、開発者にとって、プログラミングを通じてこの機能を実現する方法を理解することが重要です。この記事では、Spire.XLS for .NET を使用して Excel で行の高さと列の幅を設定する方法について説明します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSSpire.XLS for .NET では、ユーザーが Worksheet.SetRowHeight() メソッドを呼び出すことによって、Excel で行の高さを設定することができます。以下は詳細な手順です。
using Spire.Xls;
namespace SetExcelRow
{
class Program
{
static void Main(string[] args)
{
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//ディスクからファイルをロードする
workbook.LoadFromFile(@"sample.xlsx");
//ファイルから最初のシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//最初の行の高さを設定する
sheet.SetRowHeight(1, 25);
//結果ファイルを保存する
workbook.SaveToFile("SetRow.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}Imports Spire.Xls
Namespace SetExcelRow
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookクラスのオブジェクトを作成する
Dim workbook As Workbook = New Workbook
'ディスクからファイルをロードする
workbook.LoadFromFile("sample.xlsx")
'ファイルから最初のシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'最初の行の高さを設定する
sheet.SetRowHeight(1, 25)
'結果ファイルを保存する
workbook.SaveToFile("SetRow.xlsx", ExcelVersion.Version2013)
workbook.Dispose
End Sub
End Class
End Namespace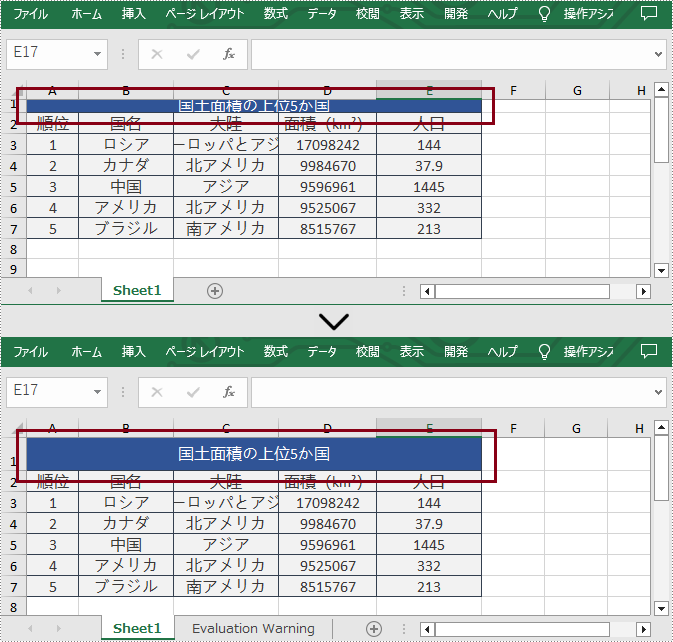
さらに、Spire.XLS for .NET では、ユーザーが Worksheet.SetColumnWidth() メソッドを呼び出すことによって、 Excel の列幅を設定することもできます。以下は詳細な手順です。
using Spire.Xls;
namespace SetExcelColumn
{
class Program
{
static void Main(string[] args)
{
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//ディスクからファイルをロードする
workbook.LoadFromFile(@"sample.xlsx");
//ファイルから最初のシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//4 番目の列の幅を設定する
sheet.SetColumnWidth(4, 15);
//結果ファイルを保存する
workbook.SaveToFile("SetColumn.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}Imports Spire.Xls
Namespace SetExcelColumn
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookクラスのオブジェクトを作成する
Dim workbook As Workbook = New Workbook
'ディスクからファイルをロードする
workbook.LoadFromFile("sample.xlsx")
'ファイルから最初のシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'4 番目の列の幅を設定する
sheet.SetColumnWidth(4, 15)
'結果ファイルを保存する
workbook.SaveToFile("SetColumn.xlsx", ExcelVersion.Version2013)
workbook.Dispose
End Sub
End Class
End Namespace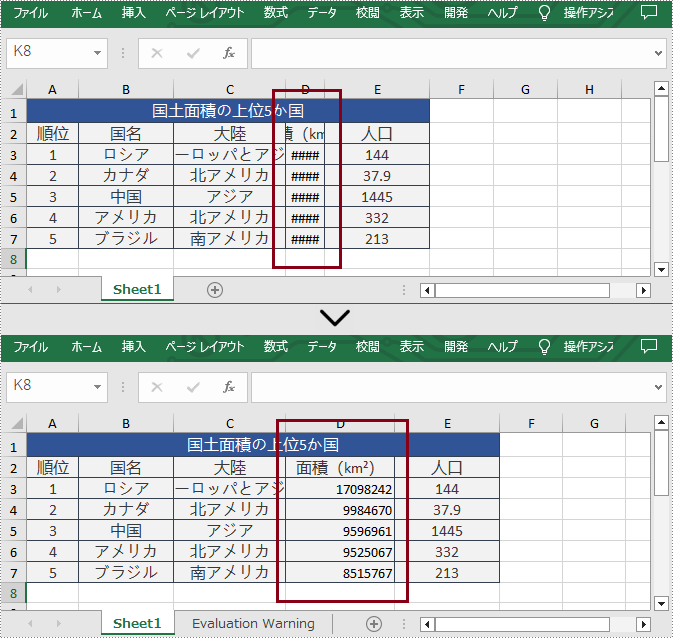
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.DocViewer 8.7.1のリリースを発表できることを嬉しく思います。このバージョンでは、Word文書のプレビュー時に画像の位置が正しく表示されない問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOCVIEWER-107 | Word文書のプレビュー時に画像の位置が正しく表示されない問題が修正されました。 |
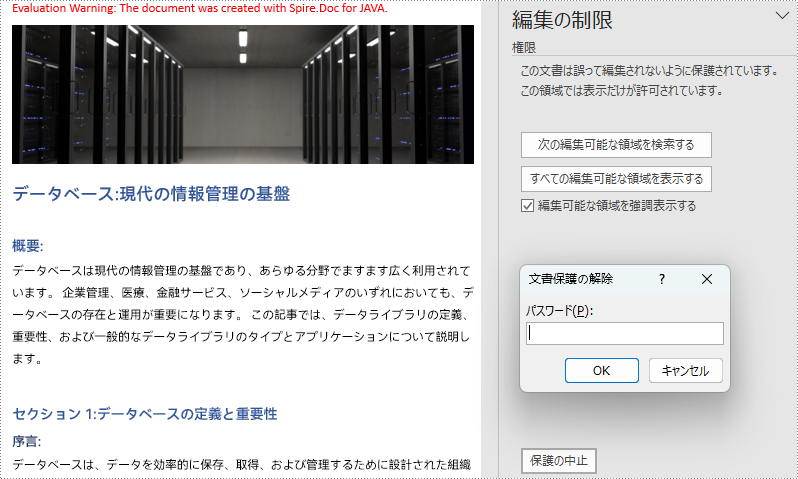
Word ドキュメントの編集制限は、ドキュメント上で実行可能な編集操作を制限するためにドキュメント上に配置することができるパスワード付き可能な保護です。編集制限を設定することで、ユーザーはドキュメントのどの部分を編集でき、どのような種類の編集を実行できるかを正確に制御することができます。この制限により、重要な情報が変更されないようにする一方で、ドキュメントの他の部分に対して指定された種類の編集を行うことができるため、共同編集や情報収集などの作業において非常に便利です。しかし、ドキュメント管理者が、ドキュメントの誤りを修正したり、ドキュメント情報を更新したり、新しい用途のためにドキュメントに変更を加えたりするために、編集制限を解除する必要がある場合があります。この記事では、Spire.Doc for Java を使用して、Java プログラムを通じて Word 文書の編集制限を設定および解除する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.4</version>
</dependency>
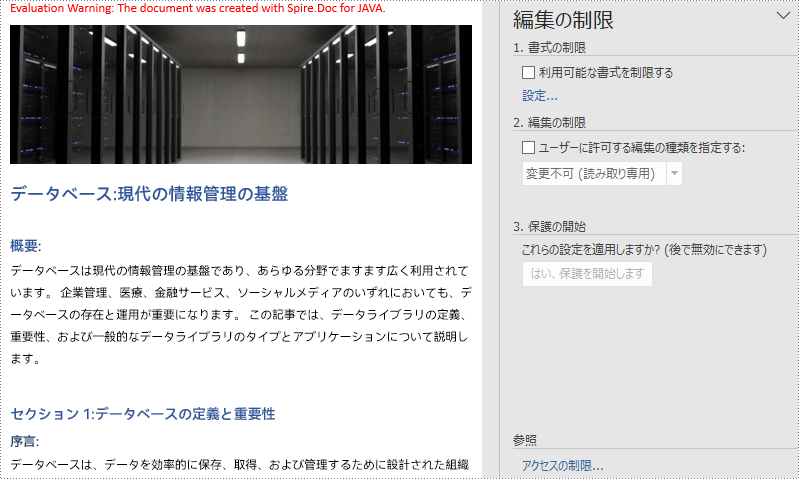
</dependencies>Spire.Doc for Java は、Word ドキュメントに4種類の編集制限を設定することをサポートしています:変更不可(読み取り専用)、変更履歴、コメント、フォームの入力。 これらの編集制限は、Document.protect() メソッドといくつかの列挙型を使用して設定することができます。
以下に、編集制限の設定に使用する列挙型の一覧とその説明を示します。
| 列挙型 | 制限種類 | 説明 |
| ProtectionType.Allow_Only_Reading | 変更不可(読み取り専用) | ドキュメントの閲覧のみを許可する。 |
| ProtectionType.Allow_Only_Revisions | 変更履歴 | ドキュメントへの変更履歴の追加のみを許可する。 |
| ProtectionType.Allow_Only_Comments | コメント | ドキュメントへのコメントの追加のみを許可する。 |
| ProtectionType.Allow_Only_Form_Fields | フォームの入力 | ドキュメントのフォームへの入力のみを許可する。 |
| ProtectionType.No_Protection | 無制限 | ドキュメントのあらゆる編集を許可する。 |
Word ドキュメントでパスワードによる編集制限を設定する具体的な手順は以下のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.ProtectionType;
public class setEditingRestriction {
public static void main(String[] args) {
//Documentオブジェクトを作成します
Document doc = new Document();
//Word文書を読み込みます
doc.loadFromFile("サンプル.docx");
//制限の種類を読み取り専用に設定し、パスワードを追加します
doc.protect(ProtectionType.Allow_Only_Reading, "password");
//制限の種類をコメントのみ追加可能に設定し、パスワードを追加します
//doc.protect(ProtectionType.Allow_Only_Comments, "パスワード");
//制限の種類をフォームフィールドの入力のみに設定し、パスワードを追加します
//doc.protect(ProtectionType.Allow_Only_Form_Fields, "パスワード");
//制限の種類を校閲のみに設定し、パスワードを追加します
//doc.protect(ProtectionType.Allow_Only_Revisions, "パスワード");
//文書を保存します
doc.saveToFile("編集の制限.docx", FileFormat.Auto);
}
}
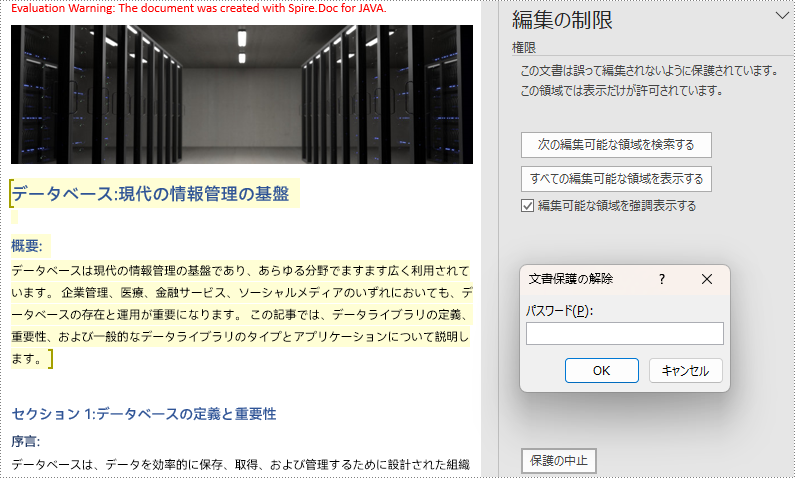
ユーザーは、Word ドキュメントの編集制限を設定する際に、許可の開始タグと終了タグを挿入することで、例外処理(制限のない領域)を追加することができます。詳しい手順は以下の通りです。
import com.spire.doc.*;
public class setRegionalEditingRestrictions {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//編集が許可される領域の開始と終了のマークを作成する
PermissionStart start = new PermissionStart(doc, "permission1");
PermissionEnd end = new PermissionEnd(doc, "permission1");
//ドキュメントの最初のセクションを取得する
Section section = doc.getSections().get(0);
//ドキュメントに編集を許可する領域の開始と終了のマークを挿入する
section.getParagraphs().get(1).getChildObjects().insert(0, start);
section.getParagraphs().get(5).getChildObjects().add(end);
//編集制限を設定し、パスワードを追加する
doc.protect(ProtectionType.Allow_Only_Reading, "password");
//ドキュメントを保存する
doc.saveToFile("例外処理.docx", FileFormat.Auto);
}
}
編集制限を解除するには、任意の編集を許可するように編集制限を設定します。詳しい手順は以下の通りです。
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
public class removeEditingRestriction {
public static void main(String[] args) {
//Documentオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("例外処理.docx");
//編集制限を削除する
doc.protect(ProtectionType.No_Protection);
//許可の開始と終了のタグを見つけて削除する
for(int j=0;j<doc.getSections().getCount();j++){
//セクションを取得する
Section section=doc.getSections().get(j);
for(int k=0;k<section.getParagraphs().getCount();k++){
//セクション内の段落を取得する
Paragraph paragraph=section.getParagraphs().get(k);
for(int i=0;i<paragraph.getChildObjects().getCount();){
//段落の子オブジェクトを取得する
DocumentObject obj=paragraph.getChildObjects().get(i);
//子オブジェクトがPermissionStartまたはPermissionEndのインスタンスか確認する
if(obj instanceof PermissionStart||obj instanceof PermissionEnd){
//そうであれば、その子オブジェクトを削除する
paragraph.getChildObjects().remove(obj);
}else{
i++;
}
}
}
}
//ドキュメントを保存する
doc.saveToFile("編集制限の取り消し.docx", FileFormat.Auto);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation 8.8.4のリリースを発表できることをうれしく思います。このバージョンでは、置き換えられたテキストをハイライトする機能をサポートしています。また、現代の注釈内容を含むPPTのページをコピーする際に失敗する問題など、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2311 | 置き換えられたテキストをハイライトする機能をサポートしています。
Presentation ppt = new Presentation();
ppt.LoadFromFile("input.pptx");
DefaultTextRangeProperties format = new DefaultTextRangeProperties();
format.IsBold = TriState.True;
format.Fill.FillType = Spire.Presentation.Drawing.FillFormatType.Solid;
format.Fill.SolidColor.Color = Color.Red;
format.FontHeight = 25;
ppt.ReplaceAndFormatText("Yuma", "AAAA", format);
ppt.SaveToFile("output.pptx", FileFormat.Pptx2016); |
| Bug | SPIREPPT-2286 | think-cellオブジェクトを含むPPTドキュメントを分割する際に、think-cellオブジェクトが失われる問題が修正されました。 |
| Bug | SPIREPPT-2292 | 現代の注釈内容を含むPPTページのコピーに失敗する問題が修正されました。 |
| Bug | SPIREPPT-2315 | 涙滴の形状の形状を取得する際に、「System.IndexOutOfRangeException」の例外が発生する問題が修正されました。 |
| Bug | SPIREPPT-2317 | ハイパーリンクの色を変更した後、PDFに変換する際に色が適用されない問題が修正されました。 |
SVG ファイルはベクターベースのグラフィックであり、品質を損なうことなく拡大縮小やサイズ調整が可能です。このファイル形式は特定の場合に非常に便利です。ただし、さらなる処理、共有、配布、印刷、アーカイブのために PDF など他の形式に変換する必要がある場合もあります。この記事では、Spire.PDF for Java を使用して SVG 画像を PDF ファイルに変換する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.7.8</version>
</dependency>
</dependencies>Spire.PDF for Java では、SVG ファイルを読み込むための PdfDocument.loadFromSvg() メソッドが提供されており、その後、PdfDocument.saveToFile() メソッドを使用して PDF ファイルに変換することができます。以下に詳細な手順を示します。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class SVGToPDF {
public static void main(String[] args) {
//PdfDocumentインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//SVGファイルを読み込む
pdf.loadFromSvg("sample.svg");
//SVGをPDFとして保存する
pdf.saveToFile("SVGToPDF.pdf", FileFormat.PDF);
pdf.close();
}
}
SVG を PDF に変換するだけでなく、Spire.PDF for Java は SVG 画像を PDF に追加することもサポートしています。このプロセスでは、SVG 画像の位置とサイズを設定することができます。以下に詳細な手順を示します。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfTemplate;
import java.awt.*;
import java.awt.geom.Point2D;
public class AddSVGImagetoPDF {
public static void main(String[] args) {
//PdfDocumentインスタンスを作成する
PdfDocument doc1 = new PdfDocument();
//SVGファイルを読み込む
doc1.loadFromSvg("sample.svg");
//SVGファイルの内容に基づいたテンプレートを作成する
PdfTemplate template = doc1.getPages().get(0).createTemplate();
//別のPdfDocumentインスタンスを作成する
PdfDocument doc2 = new PdfDocument();
//PDFファイルを読み込む
doc2.loadFromFile("Intro.pdf");
//PDFファイル内の指定された場所にカスタムサイズのテンプレートを描画する
doc2.getPages().get(0).getCanvas().drawTemplate(template, new Point2D.Float(100,200), new Dimension(400,280) );
//結果文書を保存する
doc2.saveToFile("AddSVGtoPDF.pdf", FileFormat.PDF);
doc1.close();
doc2.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc 11.8.9のリリースを発表できることを嬉しく思います。このバージョンでは、数学式を OfficeMathMLCode に変換する機能や、差し込み印刷時に画像にハイパーリンクを追加する機能が追加されました。さらに、Word から PDF や HTML への変換機能、および HTML から Word への変換機能も強化されました。また、多くの既知の問題も修正されました、例えば、ページ番号のフィールドを追加した後に、フィールドが自動的に更新されない問題などです。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-9057 | 数学式を OfficeMathMLCode に変換する機能が追加されました。
Document doc = new Document();
doc.LoadFromFile("1.docx");
StringBuilder stringBuilder = new StringBuilder();
foreach (Section section in doc.Sections)
{
foreach (Paragraph par in section.Body.Paragraphs)
{
foreach (DocumentObject obj in par.ChildObjects)
{
OfficeMath omath = obj as OfficeMath;
if (omath == null) continue;
string mathml = omath.ToOfficeMathMLCode();
stringBuilder.Append(mathml);
stringBuilder.Append("\r\n");
}
}
}
File.WriteAllText("1.txt", stringBuilder.ToString());
doc.Close(); |
| New feature | SPIREDOC-9710 | 差し込み印刷時に画像にハイパーリンクを追加する機能が追加されました。
Document doc = new Document();
doc.LoadFromFile("Test.docx");
var fieldNames = new string[] { "MyImage" };
var fieldValues = new string[] { "logo.png" };
doc.MailMerge.MergeImageField += new MergeImageFieldEventHandler(MailMerge_MergeImageField);
doc.MailMerge.Execute(fieldNames, fieldValues);
doc.SaveToFile("result.docx", FileFormat.Docx);
}
void MailMerge_MergeImageField(object sender, MergeImageFieldEventArgs field)
{
string filePath = field.FieldValue as string;
if (!string.IsNullOrEmpty(filePath))
{
field.Image = Image.FromFile(filePath);
field.ImageLink = "https://www.e-iceblue.com/";
}
} |
| Bug | SPIREDOC-6013 | Word文書を読み込む際に「System.InvalidOperationException」の例外が発生する問題が修正されました。 |
| Bug | SPIREDOC-8541 | WordをPDFに変換した後、ページ分割が一致しない問題が修正されました。 |
| Bug | SPIREDOC-8587 | WordをPDFに変換する際に「System.NullReferenceException」の例外が発生する問題が修正されました。 |
| Bug | SPIREDOC-9197 | SparrowからエクスポートされたDocxファイルをHTMLに変換できない問題が修正されました。 |
| Bug | SPIREDOC-9213 | ページ番号フィールドを追加した後、フィールドが自動的に更新されない問題が修正されました。 |
| Bug | SPIREDOC-9253 | HTMLをDocに変換した後、リストの文字が正しく表示されない問題が修正されました。 |
| Bug | SPIREDOC-9310 | HTMLをDocに変換した後、改行タグが無効になる問題が修正されました。 |
| Bug | SPIREDOC-9400 | DocxをPDFに変換した後、ロゴが欠落する問題が修正されました。 |
| Bug | SPIREDOC-9627 | RTF文書を読み込む際に「System.NullReferenceException」の例外が発生する問題が修正されました。 |
| Bug | SPIREDOC-9640 | Latexの数式中の「~」記号の解析が正しく行われない問題が修正されました。 |
| Bug | SPIREDOC-9641 | WordをPDFに変換した後、TOCが複数のページに分割される問題が修正されました。 |
| Bug | SPIREDOC-9684 | DocxをHTMLに変換した後、画像がぼやける問題が修正されました。 |
| Bug | SPIREDOC-9712 | WordをPDFに変換した後、余分なテキストが表示される問題が修正されました。 |
| Bug | SPIREDOC-9755 | ドキュメントを読み込んで新しいドキュメントとして保存した後、内容が一致しない問題が修正されました。 |
| Bug | SPIREDOC-9761 | HTML文字列を追加する際にプログラムが一時停止する問題が修正されました。 |
Spire.PDFViewer 7.12.0のリリースをお知らせいたします。このバージョンでは、PDFファイルを読み込み際に「System.ArgumentNullException」が発生する問題が修正されました。また、PDFファイルを読み込み際に「System.OutOfMemoryException」が発生する問題など、既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDFVIEWER-575 | PDFファイルを読み込み際に「System.ArgumentNullException」が発生する問題が修正されました。 |
| Bug | SPIREPDFVIEWER-576 | PDFファイルを読み込み際に「System.OutOfMemoryException」が発生する問題が修正されました。 |
PDF ポートフォリオは、テキスト文書、スプレッドシート、プレゼンテーション、画像、ビデオ、オーディオファイルなど、複数のファイルを1つのインタラクティブな PDF コンテナに結合する機能をサポートしています。ユーザーは PDF ポートフォリオを作成することで、プロジェクトに関連するすべての資料を一緒に保存し、ファイルの管理や送信をより簡単に行うことができます。この記事では、Spire.PDF for Java を使用して PDF ポートフォリオを作成する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.7.8</version>
</dependency>
</dependencies>PDF ポートフォリオは、複数のファイルの集合です。Spire.PDF for Java の PdfDocument.getCollection() メソッドを使用して、PDF ポートフォリオを簡単に作成することができます。その後、PdfCollection.addFile() メソッドを使用してそこにファイルを追加することができます。具体的な手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class CreatePortfolioWithFiles {
public static void main(String []args){
//ファイルを指定する
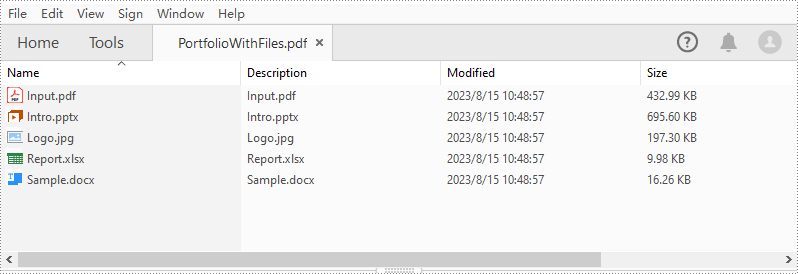
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//PdfDocument インスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDF ポートフォリオを作成し、そこにファイルを追加する
for (int i = 0; i < files.length; i++)
{
pdf.getCollection().addFile(files[i]);
}
//結果ファイルを保存する
pdf.saveToFile("PortfolioWithFiles.pdf", FileFormat.PDF);
pdf.dispose();
}
}
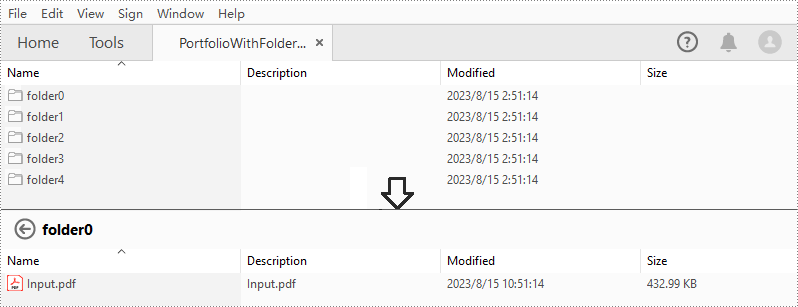
PDF ポートフォリオを作成した後、Spire.PDF for Java では、PDF ポートフォリオ内にフォルダを作成してファイルをさらに管理することも可能です。具体的な手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.collections.PdfFolder;
public class CreatePortfolioWithFolders {
public static void main(String []args){
//ファイルを指定する
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//PdfDocument インスタンスを作成する
PdfDocument pdf = new PdfDocument();
//ポートフォリオを作成し、そこにフォルダーを追加する
for (int i = 0; i < files.length; i++)
{
PdfFolder folder = pdf.getCollection().getFolders().createSubfolder("folder" + i);
//ファイルをフォルダーに追加する
folder.addFile(files[i]);
}
//結果ファイルを保存する
pdf.saveToFile("PortfolioWithFolders.pdf", FileFormat.PDF);
pdf.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
マイクロソフト株式会社によって開発された PowerPoint プレゼンテーションは、視覚的に魅力的でインタラクティブなコンテンツを作成するために使用される多目的なファイル形式です。テキストや画像などの豊富な機能と複数の要素を含んでおり、ビジネスの紹介や学術的なスピーチなど、さまざまなシナリオで強力なツールとなっています。PowerPoint のテキストを編集や操作する必要がある場合、プログラムでテキストを抽出し、新しいファイルに保存することは良い選択です。この記事では、Spire.Presentation for Java を使用して PowerPoint からテキストを抽出する方法を示します。
まず、Spire.Presentation for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>8.7.3</version>
</dependency>
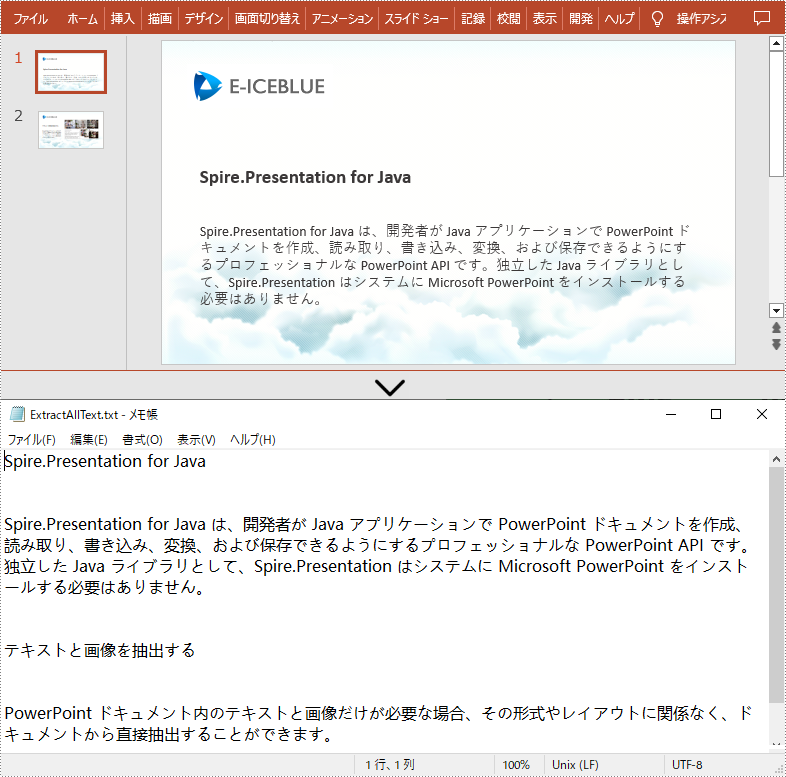
</dependencies>Spire.Presentation for Java では、ParagraphEx.getText() メソッドを使用して、すべてのスライドをループし、各スライドの段落からテキストを抽出することができます。詳細な手順は次のとおりです。
import com.spire.presentation.*;
import java.io.*;
public class ExtractText {
public static void main(String[] args) throws Exception {
//Presentationクラスのオブジェクトを作成する
Presentation presentation = new Presentation();
//PowerPointプレゼンテーションをロードする
presentation.loadFromFile("sample.pptx");
//StringBuilderオブジェクトを作成する
StringBuilder buffer = new StringBuilder();
//各スライドをループしてテキストを抽出する
for (Object slide : presentation.getSlides()) {
for (Object shape : ((ISlide) slide).getShapes()) {
if (shape instanceof IAutoShape) {
for (Object tp : ((IAutoShape) shape).getTextFrame().getParagraphs()) {
buffer.append(((ParagraphEx) tp).getText()+"\n");
}
}
}
}
//抽出したテキストを新しい.txtファイルに書き込む
FileWriter writer = new FileWriter("output/ExtractAllText.txt");
writer.write(buffer.toString());
writer.flush();
writer.close();
presentation.dispose();
}
}
Spire.Presentation for Java では、特定のスライドからテキストを抽出することもサポートしています。テキストを抽出する前に、Presentation.getSlides().get() メソッドを呼び出して、必要なスライドを取得してください。以下に詳細な手順を示します。
import com.spire.presentation.*;
import java.io.*;
public class ExtractText {
public static void main(String[] args) throws Exception {
//Presentationクラスのオブジェクトを作成する
Presentation presentation = new Presentation();
//PowerPointプレゼンテーションをロードする
presentation.loadFromFile("sample.pptx");
//StringBuilderオブジェクトを作成する
StringBuilder buffer = new StringBuilder();
//最初のスライドを取得する
ISlide Slide = presentation.getSlides().get(0);
//各形状の段落をループしてテキストを抽出する
for (Object shape : Slide.getShapes()) {
if (shape instanceof IAutoShape) {
for (Object tp : ((IAutoShape) shape).getTextFrame().getParagraphs()) {
buffer.append(((ParagraphEx) tp).getText()+"\n");
}
}
}
//抽出したテキストを新しい.txtファイルに書き込む
FileWriter writer = new FileWriter("output/ExtractSlideText.txt");
writer.write(buffer.toString());
writer.flush();
writer.close();
presentation.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
テキスト透かしとは、透明または半透明のロゴや情報をテキストの形式でドキュメント、画像、その他のメディアに追加することを指します。この機能は PowerPoint プレゼンテーションにも適用されます。スライドにテキスト透かしを挿入することで、ユーザーは著作権の所有権を識別したり、ドキュメントのセキュリティを保護したり、他の情報を伝えることができます。この記事では、Spire.Presentation for Java を使用して PowerPoint スライドにテキスト透かしを追加する方法を示します。
まず、Spire.Presentation for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>8.7.3</version>
</dependency>
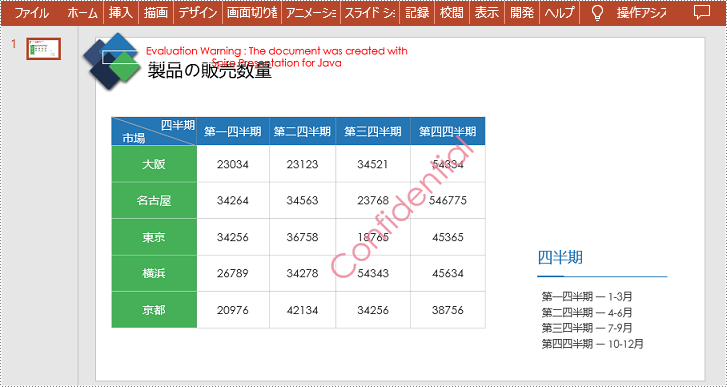
</dependencies>Spire.Presentation for Java では、Presentation.getSlides().get().getShapes().appendShape() メソッドを使用してスライドに形状を挿入することで、単一のテキスト透かしを追加できます。次に、IAutoShape.getTextFrame().setText() メソッドを呼び出してテキストを設定します。以下は詳細な手順です。
import com.spire.presentation.*;
import com.spire.presentation.drawing.FillFormatType;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class InsertSingleWatermark {
public static void main(String[] args) throws Exception {
//Presentationオブジェクトを作成し、サンプルファイルをロードする
Presentation presentation = new Presentation();
presentation.loadFromFile("sample.pptx");
//透かし文字列の幅と高さを設定する
int width= 400;
int height= 300;
//形状の位置とサイズを定義する
Rectangle2D.Double rect = new Rectangle2D.Double((presentation.getSlideSize().getSize().getWidth() - width) / 2,
(presentation.getSlideSize().getSize().getHeight() - height) / 2, width, height);
//最初のスライドに形状を追加する
IAutoShape shape = presentation.getSlides().get(0).getShapes().appendShape(ShapeType.RECTANGLE, rect);
//形状のスタイルを設定する
shape.getFill().setFillType(FillFormatType.NONE);
shape.getShapeStyle().getLineColor().setColor(Color.white);
shape.setRotation(-45);
shape.getLocking().setSelectionProtection(true);
shape.getLine().setFillType(FillFormatType.NONE);
//形状にテキストを追加する
shape.getTextFrame().setText("Confidential");
PortionEx textRange = shape.getTextFrame().getTextRange();
//テキスト範囲のスタイルを設定する
textRange.getFill().setFillType(FillFormatType.SOLID);
textRange.setFontHeight(50);
Color color = new Color(237,129,150,200);
textRange.getFill().getSolidColor().setColor(color);
//結果文書を保存する
presentation.saveToFile("output/SingleWatermark.pptx", FileFormat.PPTX_2010);
presentation.dispose();
}
}
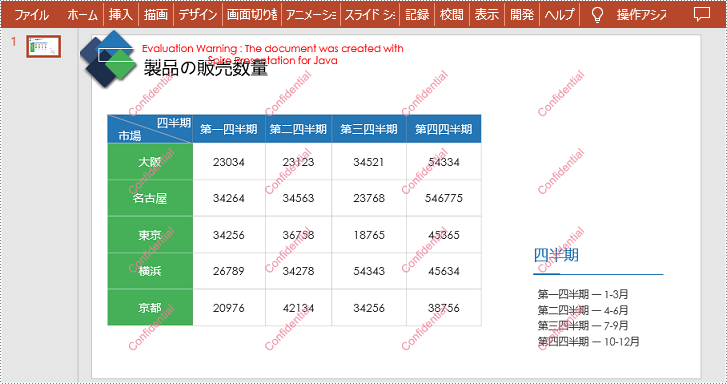
ループ内で、Presentation.getSlides().get().getShapes().appendShape() メソッドを複数回呼び出すことで、異なる位置に複数の長方形の形状を追加します。これにより、スライドに複数行のテキスト透かしを追加する効果が実現されます。以下は詳細な手順です。
import com.spire.pdf.graphics.PdfTrueTypeFont;
import com.spire.presentation.*;
import com.spire.presentation.drawing.FillFormatType;
import java.awt.*;
import java.awt.geom.Dimension2D;
import java.awt.geom.Rectangle2D;
public class InsertTiledWatermark {
public static void main(String[] args) throws Exception {
//Presentationオブジェクトを作成し、サンプルファイルをロードする
Presentation presentation = new Presentation();
presentation.loadFromFile("sample.pptx");
//透かしテキストを設定する
String watermarkText = "Confidential";
//透かしテキストのサイズを測定する
Font font = new java.awt.Font("Arial", java.awt.Font.BOLD, 20);
PdfTrueTypeFont trueTypeFont = new PdfTrueTypeFont(font);
Dimension2D strSize = trueTypeFont.measureString(watermarkText);
//x座標とy座標を初期化する
float x = 30;
float y = 80;
for (int rowNum = 0; rowNum < 4; rowNum++) {
for (int colNum = 0; colNum < 4; colNum++) {
//最初のスライドに長方形の形状を追加する
Rectangle2D rect = new Rectangle2D.Float(x, y, (float) strSize.getWidth() + 10, (float) strSize.getHeight());
IAutoShape shape = presentation.getSlides().get(0).getShapes().appendShape(ShapeType.RECTANGLE, rect);
//形状のスタイルを設定する
shape.getFill().setFillType(FillFormatType.NONE);
shape.getShapeStyle().getLineColor().setColor(new Color(1, 1, 1, 0));
shape.setRotation(-45);
shape.getLocking().setSelectionProtection(true);
shape.getLine().setFillType(FillFormatType.NONE);
//形状に透かしテキストを追加する
shape.getTextFrame().setText(watermarkText);
PortionEx textRange = shape.getTextFrame().getTextRange();
//テキスト範囲のスタイルを設定する
textRange.getFill().setFillType(FillFormatType.SOLID);
textRange.setLatinFont(new TextFont(trueTypeFont.getName()));
textRange.setFontMinSize(trueTypeFont.getSize());
Color color = new Color(237,129,150,200);
textRange.getFill().getSolidColor().setColor(color);
x += (100 + strSize.getWidth());
}
x = 30;
y += (100 + strSize.getHeight());
}
//結果文書を保存する
presentation.saveToFile("output/TiledWatermark.pptx", FileFormat.PPTX_2013);
presentation.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





