チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.PDF for Android via Java 9.7.1のリリースを発表できることを嬉しく思います。このリリースでは、PDFからPPTXへの変換機能や画像の圧縮機能が追加されました。Metadataデータの取得方法も変更されました。また、この更新には問題の修正も含まれています。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | PDFからPPTXへの変換機能がサポートされました。
String input = "data/JavaPDFSample_1.pdf"; String output = "output/toPPTX.pptx"; //PDF ドキュメントをロードする PdfDocument doc = new PdfDocument(); doc.loadFromFile(input); //PPTXファイルに変換する doc.saveToFile(output, FileFormat.PPTX); doc.close(); |
| New feature | - | 画像の圧縮機能が追加されました。
PdfCompressor compressor = new PdfCompressor(inputFile); compressor.getOptions().getImageCompressionOptions().setCompressImage(true); compressor.getOptions().getImageCompressionOptions().setResizeImages(true); compressor.getOptions().getImageCompressionOptions().setImageQuality(ImageQuality.High); compressor.compressToFile(outputFile); |
| New feature | - | Metadataデータを取得するためのpdf.getDocumentInformation()メソッドが追加されました。XmpMetadataは廃止されました。
PdfDocument doc = new PdfDocument();
doc.loadFromFile(inputFile);
StringBuilder builder = new StringBuilder();
builder.append("Author:" + doc.getDocumentInformation().getAuthor() + "\r\n");
builder.append("Title: " + doc.getDocumentInformation().getTitle() + "\r\n");
builder.append("Creation Date: " + doc.getDocumentInformation().getCreationDate() + "\r\n");
builder.append("Subject: " + doc.getDocumentInformation().getSubject() + "\r\n");
builder.append("Producer: " + doc.getDocumentInformation().getProducer() + "\r\n");
builder.append("Creator: " + doc.getDocumentInformation().getCreator() + "\r\n");
builder.append("Keywords: " + doc.getDocumentInformation().getKeywords() + "\r\n");
builder.append("Modify Date: " + doc.getDocumentInformation().getModificationDate() + "\r\n");
builder.append("Customed Property's value: " + doc.getDocumentInformation().getCustomProperty("Field1"));
FileWriter fw = new FileWriter(new File(outputFile), true);
BufferedWriter bw = new BufferedWriter(fw);
bw.write(builder.toString());
bw.flush();
bw.close();
fw.close(); |
| Bug | - | 開くパスワードとアクセス許可パスワードが一致している場合にエラーが表示されない問題が修正されました。 |
PDF 文書において、背景とはページのコンテンツの背後にある全体的な視覚的な外観を指します。背景は単純な均一な色であることもありますし、好みの画像であることもあります。PDF に背景を追加することで、ドキュメントに視覚的な魅力を加えることができ、読みやすさも向上するでしょう。この記事では、Spire.PDF for .NET を使用して PDF の背景色と背景画像を設定する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれているDLLファイルを.NETプロジェクトの参照として追加する必要があります。DLLファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET が提供する PdfPageBase.BackgroundColor プロパティを使用すると、PDF の背景として単色を設定できます。詳細な手順は次のとおりです。
using Spire.Pdf;
using System.Drawing;
namespace PDFBackgroundColor
{
class Program
{
static void Main(string[] args)
{
//PdfDocument インスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルをロードする
pdf.LoadFromFile("input.pdf");
//PDFのページをループする
foreach (PdfPageBase page in pdf.Pages)
{
//ページの背景色を設定する
page.BackgroundColor = Color.Yellow;
//背景の透明度を設定する
page.BackgroudOpacity = 0.1f;
}
//PDFファイルを保存する
pdf.SaveToFile("BackgroundColor.pdf");
pdf.Close();
}
}
}Imports Spire.PDF
Imports System.Drawing
Namespace PDFBackgroundColor
Class Program
Private Shared Sub Main(ByVal args() As String)
'PdfDocument インスタンスを作成する
Dim pdf As PdfDocument = New PdfDocument
'PDFファイルをロードする
pdf.LoadFromFile("input.pdf")
'PDFのページをループする
For Each page As PdfPageBase In pdf.Pages
'ページの背景色を設定する
page.BackgroundColor = Color.Yellow
'背景の透明度を設定する
page.BackgroudOpacity = 0.1!
Next
'PDFファイルを保存する
pdf.SaveToFile("BackgroundColor.pdf")
pdf.Close()
End Sub
End Class
End Namespace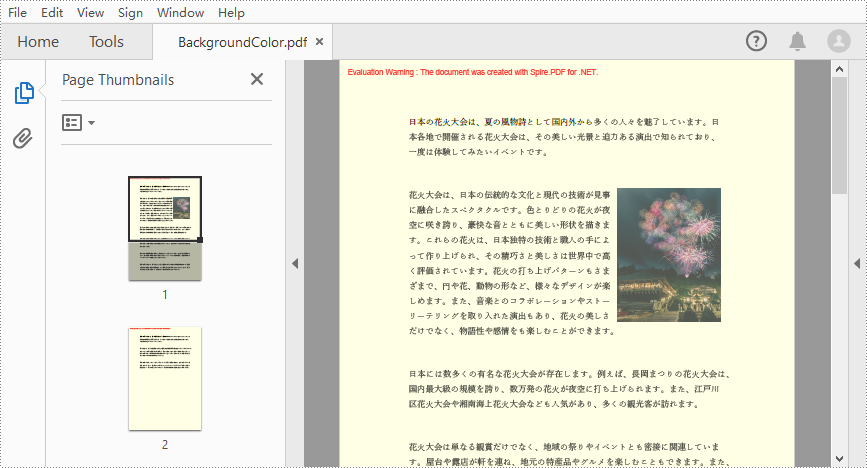
文書のテーマに合わせて背景として画像を追加する場合は、PdfPageBase.BackgroundImage プロパティを使用できます。詳細な手順は次のとおりです。
using Spire.Pdf;
using System.Drawing;
namespace PDFBackgroundImage
{
class Program
{
static void Main(string[] args)
{
//PdfDocument インスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルをロードする
pdf.LoadFromFile("input.pdf");
//画像をロードする
Image background = Image.FromFile("background.png");
//PDFのページをループする
foreach (PdfPageBase page in pdf.Pages)
{
//ロードされた画像をページの背景画像に設定する
page.BackgroundImage = background;
//背景の透明度を設定する
page.BackgroudOpacity = 0.2f;
}
// PDFファイルを保存する
pdf.SaveToFile("BackgroundImage.pdf");
pdf.Close();
}
}
}Imports Spire.PDF
Imports System.Drawing
Namespace PDFBackgroundImage
Class Program
Private Shared Sub Main(ByVal args() As String)
'PdfDocument インスタンスを作成する
Dim pdf As PdfDocument = New PdfDocument
'PDFファイルをロードする
pdf.LoadFromFile("input.pdf")
'画像をロードする
Dim background As Image = Image.FromFile("background.png")
'PDFのページをループする
For Each page As PdfPageBase In pdf.Pages
'ロードされた画像をページの背景画像に設定する
page.BackgroundImage = background
'背景の透明度を設定する
page.BackgroudOpacity = 0.2!
Next
'PDFファイルを保存する
pdf.SaveToFile("BackgroundImage.pdf")
pdf.Close()
End Sub
End Class
End Namespace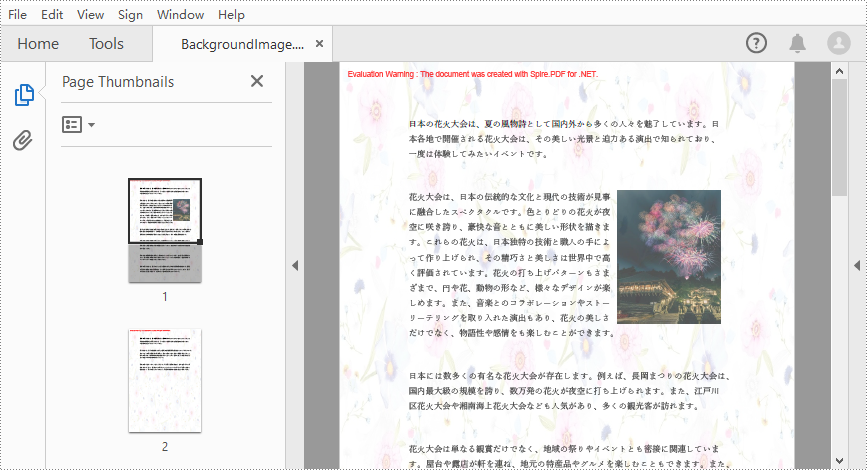
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation 8.7.2のリリースを発表できることをうれしく思います。このバージョンでは、文書変換のためのデフォルトフォントリストをリセットするメソッドが追加されました。システムにドキュメントで使用されるフォントがインストールされていない場合でも、PDFや画像などの形式を変換する際に、優先フォントの使用を設定する機能が追加されました。さらに、PowerPointから画像への変換機能も強化されています。また、チャートデータを操作した後に結果ファイルが開けないというなど、既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | 文書変換のためのデフォルトフォントリストをリセットする機能が追加されました。
presentation.setDefaultFontName("华文行楷"); |
| New feature | - | システムにドキュメントで使用されるフォントがインストールされていない場合でも、PDFや画像などの形式を変換する際に、優先フォントの使用を設定する機能が追加されました。
presentation.resetDefaultFontName(); |
| Bug | SPIREPPT-2300 | PowerPointドキュメントを画像に変換する際にグラフが失われていた問題が修正されました。 |
| Bug | SPIREPPT-2302 | グラフデータを操作した後、結果ファイルが開けない問題が修正されました。 |
| Bug | SPIREPPT-2303 | PPTドキュメントを読み込む際に、アプリケーションが「Spire.Presentation.DocumentUnkownFormatException」をスローする問題が修正されました。 |
| Bug | SPIREPPT-2304 | ハイパーリンクのテキストの色を変更しても効果がない問題を修正しました。 |
Spire.PDF 9.7.14のリリースを発表できることを嬉しく思います。このバージョンでは、PDFをWordに変換する際に同じフォント名を保持する機能と、PDFを暗号化する際に新しいインタフェースを使用して暗号化オプションを設定する機能が追加されました。PDFから画像への変換機能も強化されました。また、ファイルに透かしが追加された後に取得されたPDFページ数が正しくなくなったなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-3578 | PDFをWordに変換する際に同じフォント名を保持する機能がサポートされています。
PdfDocument doc = new PdfDocument();
//新しいページの追加
PdfPageBase page = doc.Pages.Add();
PdfGrid grid = new PdfGrid();
grid.Columns.Add(1);
PdfGridRow headerRow1 = grid.Headers.Add(1)[0];
//HEADER WITHOUT UNCICODE SUPPORT BUT VALID WORD FONT
headerRow1.Style.Font = new PdfTrueTypeFont(new Font("Arial", 11f, FontStyle.Regular), true);
headerRow1.Cells[0].Value = "Spire.PDF for .NET";
headerRow1.Cells[0].StringFormat = new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle);
grid.Draw(page, new PointF(0, 10));
//文書をストリームに保存する
MemoryStream stream = new MemoryStream();
doc.SaveToStream(stream, FileFormat.PDF);
stream.Position = 0L;
PdfToWordConverter converter = new PdfToWordConverter(stream);
converter.SaveToDocx(@"out.docx"); |
| New feature | SPIREPDF-4092 SPIREPDF-5734 |
PdfDocument doc = new PdfDocument(); doc.LoadFromFile(@"in.pdf"); PdfSecurityPolicy securityPolicy = new PdfPasswordSecurityPolicy(userPassword, ownerPassword); securityPolicy.EncryptMetadata = false; securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_128; securityPolicy.DocumentPrivilege = PdfDocumentPrivilege.AllowAll; securityPolicy.DocumentPrivilege.AllowPrint = false; doc.Encrypt(securityPolicy); doc.SaveToFile(@"out.pdf"); |
| Bug | SPIREPDF-2586 | PDFを画像に変換した後、コンテンツが失われる問題が修正されました。 |
| Bug | SPIREPDF-6013 | PDFファイルを印刷した後、テーブルの枠線が太くなる問題が修正されました。 |
| Bug | SPIREPDF-6057 | 変換後のPDFA3Bファイルを開いた際に、アプリケーションが「cannot extract the embedded font」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6072 | ファイルに透かしが追加された後に取得されたPDFページ数が正しくなくなった問題がが修正されました。 |
| Bug | SPIREPDF-6080 | PDFを画像に変換する際のメモリ消費が最適化されました。 |
| Bug | SPIREPDF-6086 | PDFファイルをロードする際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6088 | XPSファイルをロードする際に、アプリケーションが「System.IndexOutOfRangeException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6093 | PDFを画像に変換した後、結果が黒色になる問題が修正されました。 |
| Bug | SPIREPDF-6100 | PDFを画像に変換する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6126 | Formフィールドの削除メソッドが機能しない問題が修正されました。 |
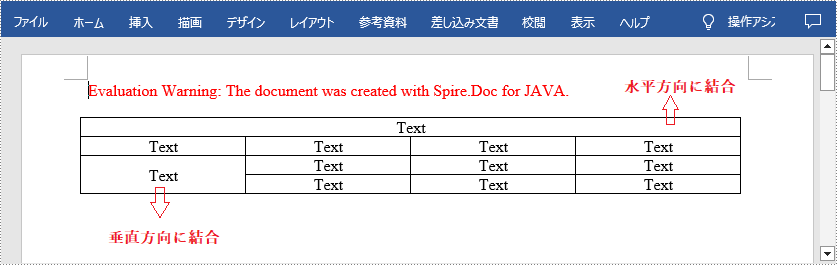
Word の表は、データの整理や表示に便利な機能です。デフォルトの表は、各列や行に同じ数のセルがありますが、ヘッダーを作成するために複数のセルを結合したり、追加のデータを収容するためにセルを分割したりする必要がある場合もあります。この記事では、Spire.Doc for Java を使用して Word で表のセルを結合または分割する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.7.0</version>
</dependency>
</dependencies>Spire.Doc for .NET では、Table.applyHorizontalMerge() メソッドまたは Table.applyVerticalMerge() メソッドを使用して、隣接する 2 つ以上のセルを水平方向または垂直方向に結合できます。詳細な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.HorizontalAlignment;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.VerticalAlignment;
public class MergeTableCell {
public static void main(String[] args) throws Exception {
//Documentインスタンスを作成する
Document document = new Document();
//Word文書をロードする
document.loadFromFile("input.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//セクションに4 x 4の表を追加する
Table table = section.addTable(true);
table.resetCells(4, 4);
//最初の行のセルを水平方向に結合する
table.applyHorizontalMerge(0, 0, 3);
//最初の列のセル3と4を垂直方向に結合する
table.applyVerticalMerge(0, 2, 3);
//表にデータを追加する
for (int row = 0; row < table.getRows().getCount(); row++) {
for (int col = 0; col < table.getRows().get(row).getCells().getCount(); col++) {
TableCell cell = table.get(row, col);
cell.getCellFormat().setVerticalAlignment(VerticalAlignment.Middle);
Paragraph paragraph = cell.addParagraph();
paragraph.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
paragraph.setText("Text");
}
}
//結果文書を保存する
document.saveToFile("MergeTableCells.docx", FileFormat.Docx);
}
}
Word セルを複数のセルに分割するために、Spire.Doc for .NET には TableCell.splitCell(int columnNum, int rowNum) メソッドが用意されています。詳細な手順は次のとおりです。
import com.spire.doc.*;
public class SplitTableCell {
public static void main(String[] args) throws Exception {
//Documentインスタンスを作成する
Document document = new Document();
//Word文書をロードする
document.loadFromFile("MergeTableCells.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//セクションの最初の表を取得する
Table table = section.getTables().get(0);
//指定されたセルを取得する
TableCell cell1 = table.getRows().get(3).getCells().get(3);
//セルを2列2行に分割する
cell1.splitCell(2, 2);
//結果文書を保存する
document.saveToFile("SplitTableCells.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office for Java 8.7.2のリリースを発表できることをうれしく思います。このリリースでは、Spire.Doc for JavaはPrivateFontPathオブジェクトをストリーム形式で作成する機能をサポートしています。Spire.PDF for Javaでは、PDFをWordに変換するための新しいインタフェースと、PDFをHTMLに変換するための新しい方法が追加されました。Spire.XLS for JavaではExcelからPDFや画像への変換機能が強化されました。Spire.Presentation for Javaではポリゴンの頂点数と位置を取得する機能をサポートしています。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-9004 | PrivateFontPathオブジェクトをストリーム形式で作成する機能がサポートされています。
//Constructor PrivateFontPath(String fontName,InputStream fontStream); PrivateFontPath(String fontName,int fontStyle,InputStream fontStream); //getter setter setFontStream(InputStream value); getFontStream(); |
| New feature | SPIREDOC-9423 | WordをPDFに変換した後、ユーザ情報の注釈表示を一貫して維持する機能をサポートしています。
ToPdfParameterList parms = new ToPdfParameterList(); parms.useAuthorNameToDisplayCommentLabel(true); |
| Bug | SPIREDOC-9044 | WordをPDFに変換した後、結果文書のページ分割が一致しない問題が修正されました。 |
| Bug | SPIREDOC-9053 | Wordの目次を更新した後、PDFに保存しても機能しない問題が修正されました。 |
| Bug | SPIREDOC-9129 | 文書をロードした後、保存された新しい文書の透かしが失われる問題が修正されました。 |
| Bug | SPIREDOC-9323 | WordをPDFに変換した後、1レベル見出しが消える問題が修正されました。 |
| Bug | SPIREDOC-9346 | Word文書を比較する際に、「Index is less than 0 or more than or equal to the list count」というエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-9347 | WordをHTMLに変換した後、再びWordに戻すとブックマークが消える問題が修正されました。 |
| Bug | SPIREDOC-9382 | 文書をクローンする際に、「An element with the same key already exists in the dictionary.」というエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-9386 | HTMLをWordに変換した後、段落に余分なインデントが発生する問題が修正されました。 |
| Bug | SPIREDOC-9431 | 文書を結合した後に、目次の更新が失敗する問題が修正されました。 |
| Bug | SPIREDOC-9435 | WordをPDFに変換した後、コンテンツが消失する問題が修正されました。 |
| Bug | SPIREDOC-9457 | WordをPDFに変換した後、レイアウトが一致しない問題が修正されました。 |
| Bug | SPIREDOC-9462 | 修正されたWord文書で変更を受け入れた後、余分な空白の段落が発生する問題が修正されました。 |
| Bug | SPIREDOC-9500 | Doc形式の文書をロードする際に、「No have this value 110」というエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-9509 SPIREDOC-9527 |
WordをPDFに変換した後、コンテンツが一致しない問題が修正されました。 |
| Bug | SPIREDOC-9520 | WordをPDFに変換した後、フォントが変更される問題が修正されました。 |
| Bug | SPIREDOC-9529 | WPSルールでWordをPDFに変換した後、ページ数が正しくない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | - | PDFをWordに変換するための新しいインタフェースが追加されました。
PdfToWordConverter converter(inputPath); converter.saveToDocx(OutputPath); converter.dispose(); |
| New feature | - | PDFをHTMLに変換するための新しい方法が追加されました。
pdfDocument.getConvertOptions().setPdfToHtmlOptions(bool useEmbeddedSvg, bool useEmbeddedImg) pdfDocument.getConvertOptions().setPdfToHtmlOptions(bool useEmbeddedSvg, bool useEmbeddedImg, int maxPageOneFile) |
| Bug | SPIREPDF-6008 | PDFをPPTXに変換した後に、フォントサイズが変更される問題が修正されました。 |
| Bug | SPIREPDF-6035 | クロップボックスの設定が機能しない問題が修正されました。 |
| Bug | SPIREPDF-6046 | キーワードの検索に失敗する問題が修正されました。 |
| Bug | SPIREPDF-6049 | キーワードを検索する際に、アプリケーションが「Parameter 'emSize' 0.0 is invalid」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6050 | PDFをHTMLに変換した後に、コンテンツが重なる問題が修正されました。 |
| Bug | SPIREPDF-6061 | 画像を追加する際に、アプリケーションが「No have this JpegTablesMode」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6073 | PDFを画像に変換した後に、画像の内容が切り取られる問題が修正されました。 |
| Bug | SPIREPDF-6083 | グリッドのテキストの垂直方向の揃えや下揃えが正しくない問題が修正されました。 |
| Bug | SPIREPDF-5885 | WPSツールで文書を開くと、追加されたテキストボックスが表示されない問題が修正されました。 |
| Bug | SPIREPDF-5966 | OFDをPDFに変換する際に、アプリケーションが「java.lang.ClassCastException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5979 | OFDをPDFに変換する際に、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6015 | PDFをExcelに変換した後、データが正しくない問題が修正されました。 |
| Bug | SPIREPDF-6026 | PDFをWordに変換した後、フォント名が正しくない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4691 | 透かしを追加した後にグラフの横軸が変更された問題が修正されました。 |
| Bug | SPIREXLS-4692 SPIREXLS-4735 |
「et」形式の文書を新しい文書として保存した後に内容が変更された問題が修正されました。 |
| Bug | SPIREXLS-4713 | ExcelをPDFに変換した後に内容が変更された問題が修正されました。 |
| Bug | SPIREXLS-4730 | ExcelをPDFに変換する際にアプリケーションが「Culture ID:14345 is not a supported culture」をスローした問題が修正されました。 |
| Bug | SPIREXLS-4732 | 透かしを追加した後に、文書がWPSとMicrosoft Excelで異なる表示される問題を修正しました。 |
| Bug | SPIREXLS-4739 | 文書をロードして新しい文書として保存した後に、画像が失われていた問題が修正されました。 |
| Bug | SPIREXLS-4758 | ブラジル・ポルトガルの地域設定で生成されたPDFがAdobeで開けない問題が修正されました。 |
| Bug | SPIREXLS-4759 | workbook.calculateAllValueメソッドを使用する際にアプリケーションが「NullPointerException」エラーが発生する問題が修正されました。 |
| Bug | SPIREXLS-4760 | Excelを画像に変換した後に内容が重なる問題が修正されました。 |
| Bug | SPIREXLS-4761 | 取得されたページ数が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4779 | ExcelをPDFに変換した後に余分な内容が表示される問題が修正されました。 |
| Bug | SPIREXLS-4780 | ExcelをPDFに変換した後に内容が失われていた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2152 | ポリゴンの頂点数と位置を取得する機能をサポートしています。
Presentation ppt = new Presentation();
ppt.loadFromFile(inputFile);
IAutoShape shape = (IAutoShape)ppt.getSlides().get(0).getShapes().get(0);
ArrayList<Point2D> points = shape.getPoints();
String text1 = "point count:" + " " + points.size() + "\r\n";
FileWriter writer1 = new FileWriter(outputFile, true);
writer1.append(text1);
writer1.close();
for (int i = 0; i < points.size(); i++)
{
String text2 = "point" + i + " " + points.get(i) + "\r\n";
FileWriter writer2 = new FileWriter(outputFile, true);
writer2.append(text2);
writer2.close();
} |
| Bug | SPIREPPT-2262 | 画像を追加したときに3 D回転効果を設定しても効果がない問題が修正されました。 |
| Bug | SPIREPPT-2263 | PPTファイルをロードするときに、アプリケーションが「CRC error:the file being extracted appears to be corrupted」をスローする問題が修正されました。 |
| Bug | SPIREPPT-2276 | 画像の組織図に画像を追加する順序が正しくなかった問題が修正されました。 |
| Bug | SPIREPPT-2277 | 保存されたPPTファイルがWPSツールでデータを編集すると、通貨記号が多くなる問題が修正されました。 |
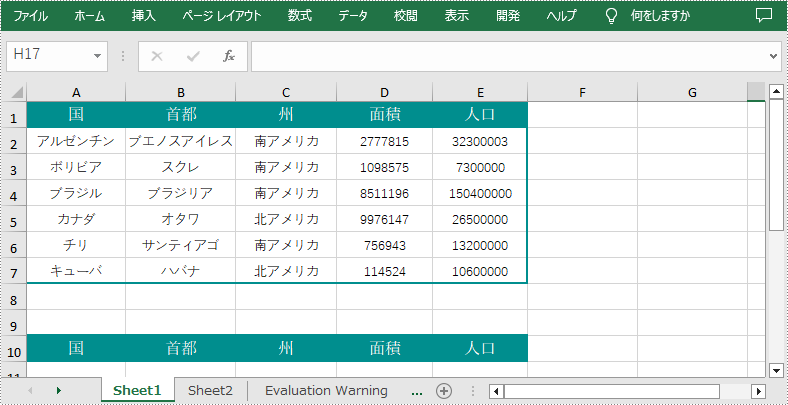
セル範囲の複製は、スプレッドシート管理の基本的で非常に役に立つ機能であり、ユーザーは簡単に指定した位置にデータ、書式設定、数式などのセルの範囲を複製できます。これにより、ユーザーはスプレッドシート全体で同一のコンテンツを効率的に複製しながら、入力エラーの可能性を減らすことができます。重要なのは、セル範囲を複製する際に、セル間の相対的な関係が保持され、複製されたデータと元のデータとの一貫性が確保されることです。そのため、この機能はファイルのバックアップやテンプレート作成などのタスクに非常に価値があり、スプレッドシートには欠かせないツールとなっています。この記事では、Spire.XLS for Java を使用して Excel でセル範囲を複製する方法を紹介します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.6.5</version>
</dependency>
</dependencies>Spire.XLS for Java には、同じワークシート内の特定のセル範囲の複製をサポートする Worksheet.copy() メソッドが用意されています。以下は詳細な手順です。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class CopyRow {
public static void main(String[] args) {
//Workbookオブジェクトを作成する
Workbook wb = new Workbook();
//ディスクからExcelファイルをロードする
wb.loadFromFile("sample.xlsx", ExcelVersion.Version2013);
//最初のシートを取得する
Worksheet sheet = wb.getWorksheets().get(0);
//ソース範囲とターゲット範囲を取得する
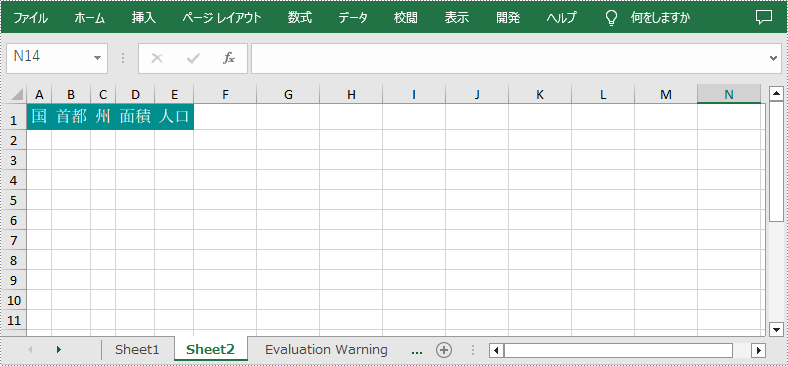
CellRange sourceRange = sheet.getCellRange("A1:E1");
CellRange destRange = sheet.getCellRange("A10:E10");
//特定のセル範囲をシートに複製する
sheet.copy (sourceRange,destRange,true);
//結果ファイルを保存する
wb.saveToFile("CopyRangeWithinSheet.xlsx", ExcelVersion.Version2013);
wb.dispose();
}
}
Spire.XLS for Java ライブラリを使用すると、セル範囲をあるシートから別のシートに簡単に複製することもできます。以下は、異なるワークシート間でセル範囲を複製する手順です。
import com.spire.xls.CellRange;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class CopyRow {
public static void main(String[] args) {
//Workbookオブジェクトを作成する
Workbook wb = new Workbook();
//ディスクからExcelファイルをロードする
wb.loadFromFile("sample.xlsx", ExcelVersion.Version2013);
//最初のシートを取得する
Worksheet sheet1 = wb.getWorksheets().get(0);
//2番目のシートを取得する
Worksheet sheet2 = wb.getWorksheets().get(1);
//ソース範囲とターゲット範囲を取得する
CellRange sourceRange = sheet1.getCellRange("A1:E1");
CellRange destRange = sheet2.getCellRange("A1:E1");
//特定のセル範囲をsheet1からsheet2に複製する
sheet1.copy (sourceRange,destRange,true);
//sheet2の列幅を自動調整する
for (int i = 0; i < 8; i++) {
sheet2.autoFitColumn(i+1);
}
//結果ファイルを保存する
wb.saveToFile("CopyRangeBetweenSheets.xlsx", ExcelVersion.Version2013);
wb.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS for Java 13.7.3のリリースを発表できることを嬉しく思います。このバージョンでは、ExcelからPDFや画像への変換機能が強化されました。ページ数の取得時間も最適化されました。また、取得されたページ数が正しくない問題など、既知の問題が修正されました。詳細は以下をお読みください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4745 | ページ数の取得時間が最適化されました。 |
| Bug | SPIREXLS-4758 | ブラジル・ポルトガルの地域設定で生成されたPDFがAdobeで開けない問題が修正されました。 |
| Bug | SPIREXLS-4759 | workbook.calculateAllValueメソッドを使用する際にアプリケーションが「NullPointerException」エラーが発生する問題が修正されました。 |
| Bug | SPIREXLS-4760 | Excelを画像に変換した後に内容が重なる問題が修正されました。 |
| Bug | SPIREXLS-4761 | 取得されたページ数が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4779 | ExcelをPDFに変換した後に余分な内容が表示される問題が修正されました。 |
| Bug | SPIREXLS-4780 | ExcelをPDFに変換した後に内容が失われていた問題が修正されました。 |
目次は Word ドキュメントのフィールドで、すべてのレベルのタイトルとそれに対応するページ番号を表示するために使用されます。ドキュメントの内容が変更された場合、目次フィールドを更新するだけで、新しいタイトルと対応するページ番号に従って新しい目次を生成することができます。 あなたがドキュメントを編集していても、ドキュメントを読んでいても、目次は大きな利便性を提供することができます。 同時に、目次はドキュメントをより専門的なものにすることもでき、これは科学、技術、学術、その他のドキュメントにとって重要な部分です。 今回は、Spire.Doc for Java を使って、Java プログラムを通して Word ドキュメントに目次を挿入する方法をご紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.7.0</version>
</dependency>
</dependencies>目次を作成する前に、目次フィールドが見出し、見出しレベル、および対応するページ番号に基づいて目次を生成できるように、各見出しの見出しレベルを設定する必要があります。 見出しレベルは、Paragraph.getListFormat().setListLevelNumber(int) メソッドを使用して設定できます。
Spire.Doc for Java には、ドキュメントの段落に目次を挿入する Paragraph.appendTOC() メソッドが用意されています。 Word ドキュメントにデフォルト形式の目次を挿入する詳細な手順は次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
public class insertTableOfContents {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//セクションを追加し、ドキュメントの表紙セクションの後に挿入する
Section section = doc.addSection();
doc.getSections().insert(1, section);
//セクションに段落を追加する
Paragraph paragraph = section.addParagraph();
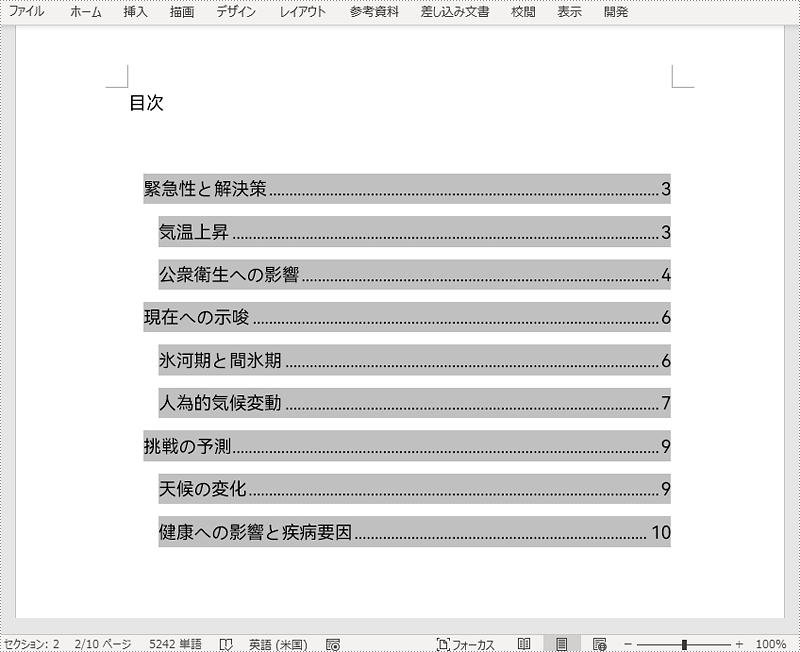
paragraph.appendText("目次\r\n");
paragraph.getStyle().getCharacterFormat().setFontSize(14f);
paragraph.getStyle().getCharacterFormat().setFontName("HarmonyOS Sans SC");
//この段落に2〜3レベルの見出しを表示するデフォルト形式の目次を作成する
paragraph.appendTOC(2, 3);
//目次を更新する
doc.updateTableOfContents();
//ファイルを保存する
doc.saveToFile("デフォルト形式の目次.docx");
doc.dispose();
}
}
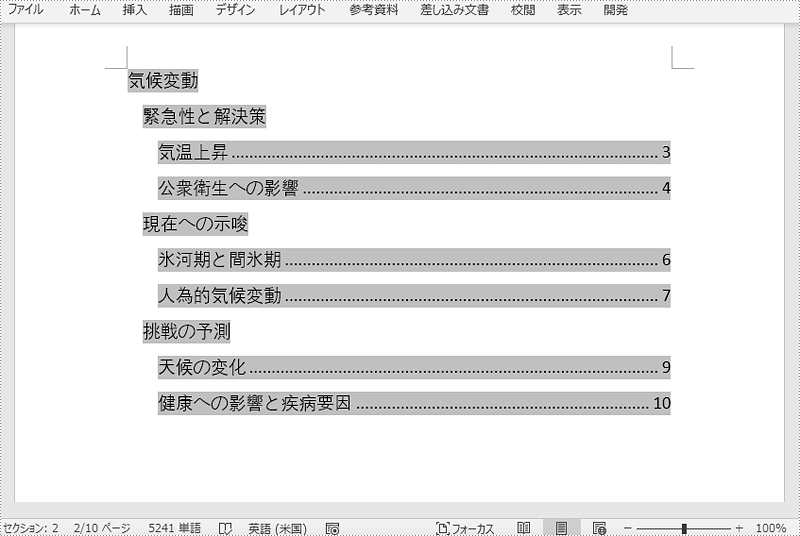
Spire.Doc for Java では、Word ドキュメントの目次を表現するために TableOfContent クラスを使用しています。 TableOfContent クラスのオブジェクトを作成する際に、スイッチによって目次に表示する内容をカスタマイズすることができます。 例えば、スイッチ "{\o \"1-3\" \\1-2}" は、目次に第1レベルから第3レベルまでの見出しを表示し、第1レベルと第2レベルの見出しのページ番号は表示しない。
Word ドキュメントでカスタム書式の目次を作成する詳細な手順は次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.Section;
import com.spire.doc.documents.FieldMarkType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.fields.TableOfContent;
public class insertTableOfContentsWithCustomizedStyle {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//表紙セクションの後にセクションを挿入し、そのセクションに段落を追加する
Section section = doc.addSection();
doc.getSections().insert(1, section);
Paragraph paragraph = section.addParagraph();
paragraph.getStyle().getCharacterFormat().setFontSize(14f);
//TableOfContentクラスのオブジェクトを作成する
TableOfContent toc = new TableOfContent(doc, "{\\o \"1-3\" \\n 1-2}");
//作成した目次をその段落に挿入する
paragraph.getItems().add(toc);
//フィールドの区切り記号と終了記号を挿入して、目次フィールドを終了させる
paragraph.appendFieldMark(FieldMarkType.Field_Separator);
paragraph.appendFieldMark(FieldMarkType.Field_End);
//作成した目次をこのドキュメントの目次に設定する
doc.setTOC(toc);
//目次を更新する
doc.updateTableOfContents();
//ファイルを保存する
doc.saveToFile("カスタム形式の目次.docx");
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF のハイパーリンクは、読者が特定のページに簡単にアクセスできるようにする重要な機能です。 PDF ドキュメントにハイパーリンクを追加することで、ドキュメントに関する追加情報をより簡単に読者に提供したり、関連リソースに移動させたりすることができます。 読者がハイパーリンクをクリックすると、対応するページがブラウザで開かれ、読書体験を大きく向上させることができます。 この記事では、Spire.PDF for .NET を使用して、.NET を使用して PDF 内の既存のテキストにハイパーリンクを追加する方法について説明します。
まず、Spire.PDF for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPDF ドキュメント内のハイパーリンクは、注釈要素としてページに挿入されます。PDF ドキュメント内の指定されたテキストにハイパーリンクを追加するには、まずテキストの位置を特定する必要があります。 テキストの位置を取得すると、指定されたテキストへのハイパーリンクの追加を実現するように、オブジェクトへの指定されたリンクを持つ PdfUriAnnotation を作成し、取得の位置に挿入することができます。 詳しい手順は以下のとおりです。
using Spire.Pdf;
using Spire.Pdf.Annotations;
using Spire.Pdf.Exporting.XPS.Schema;
using Spire.Pdf.General.Find;
using Spire.Pdf.Texts;
using System;
using System.Collections.Generic;
using System.Drawing;
using TextFindParameter = Spire.Pdf.Texts.TextFindParameter;
namespace ChangeHyperlink
{
internal class Program
{
static void Main(string[] args)
{
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.LoadFromFile("サンプル.pdf");
//ドキュメントの最初のページを取得する
PdfPageBase page = pdf.Pages[0];
//PdfTextFinderオブジェクトを作成し、ファインダーのオプションを設定する
PdfTextFinder finder = new PdfTextFinder(page);
finder.Options.Parameter = TextFindParameter.WholeWord;
//ページ上の指定されたテキストを検索し、2番目の結果を取得する
List collection = finder.Find("気候変動");
PdfTextFragment fragment = collection[1];
//2番目の検索結果のテキスト範囲をループする
foreach (RectangleF bounds in fragment.Bounds)
{
//PdfUriAnnotationのオブジェクトを作成する
PdfUriAnnotation url = new PdfUriAnnotation(bounds);
//リンクを設定する
url.Uri = "https://www.jma.go.jp/jma/kishou/know/whitep/3-1.html";
//枠線を設定する
url.Border = new PdfAnnotationBorder(1f);
//枠線の色を設定する
url.Color = Color.Blue;
//ページにハイパーリンクを挿入する
page.AnnotationsWidget.Add(url);
}
//PDFファイルを保存する
pdf.SaveToFile("ハイパーリンクの追加.pdf");
pdf.Dispose();
}
}
} Imports Spire.Pdf
Imports Spire.Pdf.Annotations
Imports Spire.Pdf.Exporting.XPS.Schema
Imports Spire.Pdf.General.Find
Imports Spire.Pdf.Texts
Imports System
Imports System.Collections.Generic
Imports System.Drawing
Imports TextFindParameter = Spire.Pdf.Texts.TextFindParameter
Namespace ChangeHyperlink
Friend Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'PDFファイルを読み込む
pdf.LoadFromFile("サンプル.pdf")
'ドキュメントの最初のページを取得する
Dim page As PdfPageBase = pdf.Pages(0)
'PdfTextFinderオブジェクトを作成し、ファインダーのオプションを設定する
Dim finder As PdfTextFinder = New PdfTextFinder(page)
finder.Options.Parameter = TextFindParameter.WholeWord
'ページ上の指定されたテキストを検索し、2番目の結果を取得する
Dim collection As List= finder.Find("気候変動")
Dim fragment As PdfTextFragment = collection(1)
'2番目の検索結果のテキスト範囲をループする
Dim bounds As RectangleF
For Each bounds In fragment.Bounds
'PdfUriAnnotationのオブジェクトを作成する
Dim url As PdfUriAnnotation = New PdfUriAnnotation(bounds)
'リンクを設定する
url.Uri = "https://www.jma.go.jp/jma/kishou/know/whitep/3-1.html"
'枠線を設定する
url.Border = New PdfAnnotationBorder(1.0F)
'枠線の色を設定する
url.Color = Color.Blue
'ページにハイパーリンクを挿入する
page.AnnotationsWidget.Add(url)
Next
'PDFファイルを保存する
pdf.SaveToFile("ハイパーリンクの追加.pdf")
pdf.Dispose()
End Sub
End Class
End Namespace 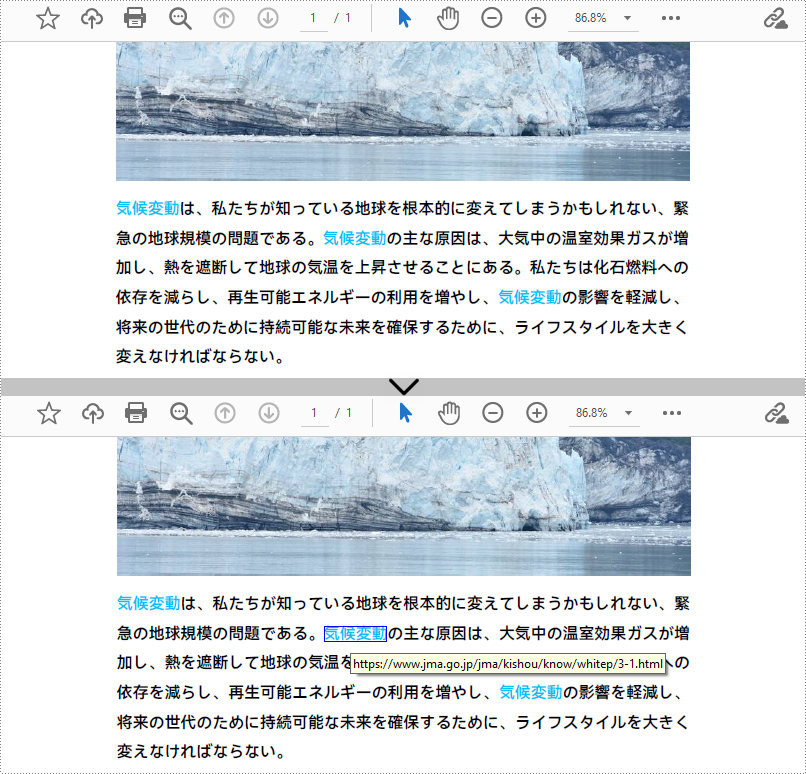
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





