チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Excel のワークシートを印刷すると、書式やレイアウトが完璧に整っているワークシートが、印刷後に非常に乱雑な状態になることがあります。これは、エクセルのワークシートはパソコンで内容を見たり編集したりしやすいように設計されており、直接印刷すると画面上の表示と大きく異なることがあるためです。したがって、ワークシートをそのままの書式とレイアウトで印刷するためには、印刷時に印刷オプションを設定する必要があります。この記事では、Spire.XLS for Java を使って Excel ファイルを印刷する方法と、印刷の設定について説明します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.8.4</version>
</dependency>
</dependencies>Excel のページ設定には、コメントを印刷するかどうか、グリッドラインを印刷するかどうか、1つのページにワークシートをレイアウトするかどうかなど、ワークシートの印刷方法を制御するオプションが用意されています。
XLS for Java では、これらの印刷オプションを設定するための PageSetup クラスが用意されています。 以下は、PageSetup クラスのメソッドを使って、Spire.XLS for Java で Excel の印刷オプションを設定する方法の説明です。
import com.spire.xls.*;
import java.awt.print.PageFormat;
import java.awt.print.Paper;
import java.awt.print.PrinterException;
import java.awt.print.PrinterJob;
public class setPrintOptions {
public static void main(String[] args) {
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.loadFromFile("貸借対照表.xlsx");
//1つ目のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//PageSetupクラスのオブジェクトを作成し、1つ目のワークシートからページ設定を取得する
PageSetup pageSetup = worksheet.getPageSetup();
//余白を設定する
pageSetup.setTopMargin(0.3);
pageSetup.setBottomMargin(0.3);
pageSetup.setLeftMargin(0.3);
pageSetup.setRightMargin(0.3);
//印刷する領域を指定する
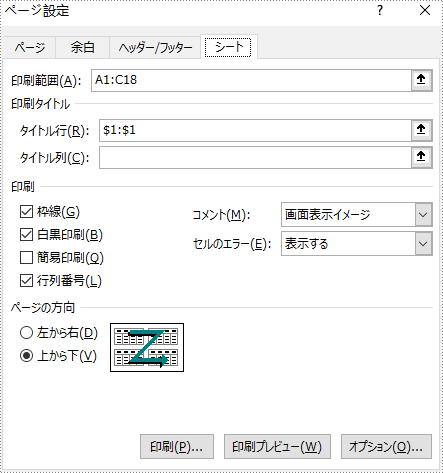
pageSetup.setPrintArea("A1:C18");
//ヘッダー列を指定する
pageSetup.setPrintTitleRows("$1:$1");
//ヘッダー列の印刷を許可する
pageSetup.isPrintHeadings(true);
//グリッド線の印刷を許可する
pageSetup.isPrintGridlines(true);
//コメントの印刷と表示を許可する
pageSetup.setPrintComments(PrintCommentType.InPlace);
//印刷品質(dpi)を設定する
pageSetup.setPrintQuality(300);
//白黒モードでの印刷を許可する
pageSetup.setBlackAndWhite(true);
//印刷順序を設定する
pageSetup.setOrder(OrderType.OverThenDown);
//ワークシートを1ページにレイアウトする
pageSetup.isFitToPage(true);
//Paperクラスのオブジェクトを作成する
PrinterJob printerJob = PrinterJob.getPrinterJob();
PageFormat pageFormat = printerJob.defaultPage();
Paper paper = pageFormat.getPaper();
//用紙の描画可能領域を設定する
paper.setImageableArea(0, 0, pageFormat.getWidth(), pageFormat.getHeight());
//印刷部数を設定する
printerJob.setCopies(1);
pageFormat.setPaper(paper);
//設定された書式でワークブックをレイアウトする
printerJob.setPrintable(workbook, pageFormat);
//印刷を実行する
try {
printerJob.print();
} catch (PrinterException e) {
e.printStackTrace();
}
}
}
印刷オプションの設定だけでなく、印刷時にネットワーク上のプリンターを指定する方法や、プリンターの設定方法についても知っておくことが重要です。 次のステップは、Spire.XLS for Java の PrinterJob クラスのメソッドを使用して、プリンタを設定し、Excel ファイルを印刷する方法を示しています。
import com.spire.xls.Workbook;
import javax.print.PrintService;
import java.awt.print.PageFormat;
import java.awt.print.Paper;
import java.awt.print.PrinterException;
import java.awt.print.PrinterJob;
public class specifyPrinterSettings {
public static void main(String[] args) throws PrinterException {
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.loadFromFile("貸借対照表.xlsx");
//PrinterJobクラスのオブジェクトを作成する
PrinterJob printerJob = PrinterJob.getPrinterJob();
//プリンター名を指定する
PrintService myPrintService = findPrintService("\\\\192.168.1.104\\HP LaserJet P1007");
printerJob.setPrintService(myPrintService);
//PageFormatクラスのオブジェクトを作成し、ページのサイズと向きをデフォルトに設定する
PageFormat pageFormat = printerJob.defaultPage();
//このページ設定を持つPaperクラスのオブジェクトを返す
Paper paper = pageFormat .getPaper();
//用紙の描画可能領域を設定する
paper.setImageableArea(0,0,pageFormat .getWidth(),pageFormat .getHeight());
//このPaperクラスのオブジェクトでページを設定する
pageFormat.setPaper(paper);
//印刷部数を設定する
printerJob .setCopies(1);
//ペインターを呼び出して、指定された書式でワークブックを描画する
printerJob .setPrintable(workbook,pageFormat);
//印刷を実行する
try {
printerJob.print();
} catch (PrinterException e) {
e.printStackTrace();
}
}
//プリンター名から印刷サービスを取得する
private static PrintService findPrintService(String printerName) {
PrintService[] printServices = PrinterJob.lookupPrintServices();
for (PrintService printService : printServices) {
if (printService.getName().equals(printerName)) {
return printService;
}
}
return null;
}
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30
Spire.Office for Java 8.1.2のリリースを発表できることをうれしく思います。今回のアップデートには、いくつかの新機能が含まれています。Spire.Doc for Javaはコンテンツコントロールの「コンテンツが編集された後にコンテンツコントロールを削除する」機能の設定をサポートしました。Spire.PDF for Javaは、PDFドキュメントを圧縮する方法が追加されました。Spire.XLS for JavaはFILTER関数をサポートしました。Spire.Presentation for Javaはツリーマップ、サンバースト、ヒストグラム、箱ひげ図、ウォーターフォール、パレート図、じょうごなどのグラフの種類をサポートしました。さらに、多くの既知のバグが正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-8961 | コンテンツコントロールの「コンテンツが編集された後にコンテンツコントロールを削除する」機能の設定をサポートしました。
Document doc = new Document();
doc.loadFromFile("1.docx");
StructureTags structureTags = GetAllTags(doc);
List tagInlines = structureTags.getM_tagInlines();
for (int i = 0; i<tagInlines.size(); i++)
{
StructureDocumentTagInline std = tagInlines.get(i);
std.getSDTProperties().isTemporary(true);
}
List<StructureDocumentTag> tags = structureTags.getM_tags();
for (int i = 0; i<tags.size(); i++) {
StructureDocumentTag std = tags.get(i);
std.getSDTProperties().isTemporary(true);
}
List<StructureDocumentTagRow> rowtags = structureTags.getM_rowtags();
for (int i = 0; i<rowtags.size(); i++) {
StructureDocumentTagRow std = rowtags.get(i);
std.getSDTProperties().isTemporary(true);
}
List<StructureDocumentTagCell> celltags = structureTags.getM_celltags();
for (int i = 0; i<celltags.size(); i++) {
StructureDocumentTagCell std = celltags.get(i);
std.getSDTProperties().isTemporary(true);
}
doc.saveToFile("tags.docx",FileFormat.Docx_2013); |
| Bug | SPIREDOC-8538 | WordをPDFに変換した後に表の枠線が失われていた問題が修正されました。 |
| Bug | SPIREDOC-8641 | ドキュメントをロードする際に、アプリケーションが「Value(11)does not exist in the<CellAlign>enumeration」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8689 | mavenからspringbootプロジェクトでspire.doc.jarをインポートする際に、アプリケーションが「java.lang.IllegalArgumentException:No enum constant com.spire.doc.packages.sprzny.spr」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8728 | テキストボックスの取得に失敗した問題が修正されました。 |
| Bug | SPIREDOC-8757 | HTMLをWordに変換した後に、表の先頭部分の背景色が失われていた問題が修正されました。 |
| Bug | SPIREDOC-8771 | 作成した参照フィールドの自動更新に失敗した問題が修正されました。 |
| Bug | SPIREDOC-8783 | RTFをWordに変換した文字化けの問題が修正されました。 |
| Bug | SPIREDOC-8784 | テキスト透かしを追加した後にドキュメントが開かなくなった問題が修正されました。 |
| Bug | SPIREDOC-8794 | VerticalAlignment.Topの設定が無効になっていた問題が修正されました。 |
| Bug | SPIREDOC-8798 | ドキュメントをロード時に、アプリケーションがハングする問題が修正されました。 |
| Bug | SPIREDOC-8801 | docをdocxに変換した後に、アプリケーションが「Value cannot be null」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8802 | ドキュメントをマージすると、アプリケーションが「An element with the same key already exists in the dictionary」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8829 SPIREDOC-8837 |
WordをPDFに変換した後、アプリケーションが「ArithmeticException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8846 | WordをPDFに変換した後、数字番号の等級が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8863 | 取得したリストのテキストが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8871 | 取得したハイパーリンクアドレスの不完全な問題が修正されました。 |
| Bug | SPIREDOC-8883 | WordをHTMLに変換した後の空白が失われていた問題が修正されました。 |
| Bug | SPIREDOC-8892 | WordをPDFに変換すると数字番号の後ろに背景色が多くなる問題が修正されました。 |
| Bug | SPIREDOC-8897 | WordをPDFに変換した後のテキストボックスの枠線スタイルが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8899 | html文字列を追加すると、アプリケーションが「Parameter'emSize'0.0 is invalid」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8901 | ブックマークの内容を置き換える際にアプリケーションが「NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8931 | ブックマークの内容を置き換えると、ヘッダーの背景スタイルが失われていた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | - | PDFドキュメントを圧縮する方法が追加されました。
PdfCompressor compressor = new PdfCompressor(fileName); compressor.compressToFile(outputName) |
| Bug | SPIREPDF-5667 | ドキュメントをマージすると、アプリケーションが「com.spire.pdf.packages.sprnsn cannot be cast to com.spire.pdf.packages.sprvqe」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5682 | PDFをPDFAに変換した後にフォームの内容が失われていた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4318 | FILTER関数をサポートしました。 |
| Bug | SPIREXLS-4321 | centos 7でExcelをPDFに変換した後にデータが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4324 | ExcelをPDFに変換した後に改ページが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4368 | ExcelをPDFに変換した後にテキストの位置が変更 する問題が修正されました。 |
| Bug | SPIREXLS-4377 | ExcelをPDFに変換した後に日付フォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4397 | sheet1.copyFrom(sheet2) を使用してコンテンツをコピーしたときに生成されたドキュメントが開かなくなる問題も修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | - | ツリーマップ、サンバースト、ヒストグラム、箱ひげ図、ウォーターフォール、パレート図、じょうごなどのグラフの種類をサポートしました。 |
Spire.XLS for Java 13.1.3のリリースを発表できることを嬉しく思います。このバージョンはFILTER関数をサポートし、ExcelからPDFへの変換機能も強化されました。sheet1.copyFrom(sheet2) を使用してコンテンツをコピーしたときに生成されたドキュメントが開かなくなるなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4318 | FILTER関数をサポートしました。 |
| Bug | SPIREXLS-4321 | centos 7でExcelをPDFに変換した後にデータが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4324 | ExcelをPDFに変換した後に改ページが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4368 | ExcelをPDFに変換した後にテキストの位置が変更 する問題が修正されました。 |
| Bug | SPIREXLS-4377 | ExcelをPDFに変換した後に日付フォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4397 | sheet1.copyFrom(sheet2) を使用してコンテンツをコピーしたときに生成されたドキュメントが開かなくなる問題も修正されました。 |
リストは、情報を整理するのに最適な方法です。テキストの塊と比較すると、通常、リストから重要なポイントを特定することは容易です。PDF のリストには、一般に、順序付きリストと順序なしリストの2つのタイプがあります。また、ネストされたリストで、これらの2つのタイプを混在させることができます。この記事では、Spire.PDF for Java を使用して、PDF ドキュメントに様々な種類のリストを作成する方法について説明します。
Spire.PDF for Java は、順序付きリストと順序なしリストを表現するために、それぞれ PdfSortedList クラスと PdfUnorderedList クラスを提供します。リストの内容、インデント、フォント、マーカーのスタイルやその他の属性を設定するには、これら2つのクラスの下のメソッドを使用します。次の表は、このチュートリアルに関係する主要なクラスとメソッドの一覧です。
| クラス・メソッド | 説明 |
| PdfSortedList クラス | PDFドキュメント内の順序付きリストを表します。 |
| PdfUnorderedList クラス | PDFドキュメント内の順序なしリストを表します。 |
| PdfListBase.setBrush() メソッド | リストのブラシを設定します。 |
| PdfListBase.setFont() メソッド | リストのフォントを設定します。 |
| PdfListBase.sertIndent() メソッド | リストのインデントを設定します。 |
| PdfListBase.setTextIndent() メソッド | マーカーからリスト項目のテキストまでのインデントを設定します。 |
| PdfListBase.getItems() メソッド | リストの項目を取得します。 |
| PdfListBase.setMarker() メソッド | リストのマーカーを設定します。 |
| PdfListBase.draw() メソッド | ページ上の指定された位置にリストを描画します。 |
| PdfOrderedMarker クラス | 数字、文字、ローマ数字など、順序付きリストのマーカスタイルを表します。 |
| PdfMarker クラス | 順序なしリストの箇条書きのスタイルを表します。 |
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>順序付きリストとは,一連のオブジェクトを格納するコンテナのことである.リスト内の各項目は、数字、文字、またはローマ数字でマークされます。以下は、Spire.PDF for Java を使用して、PDF に順序付きリストを作成する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfNumberStyle;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.lists.PdfOrderedMarker;
import com.spire.pdf.lists.PdfSortedList;
import java.awt.*;
public class createOrderedList {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//余白を設定する
PdfMargins margins = new PdfMargins(30);
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, margins);
//ブラシを作成する
PdfBrush brush = PdfBrushes.getBlack();
//フォントを作成する
PdfCjkStandardFont titleFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 14f);
PdfCjkStandardFont listFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 12f);
//順序付きリストのメーカーを作成する
PdfOrderedMarker marker = new PdfOrderedMarker(PdfNumberStyle.Lower_Latin, listFont);
//初期座標を指定する
float x = 10;
float y = 20;
//タイトルを描画する
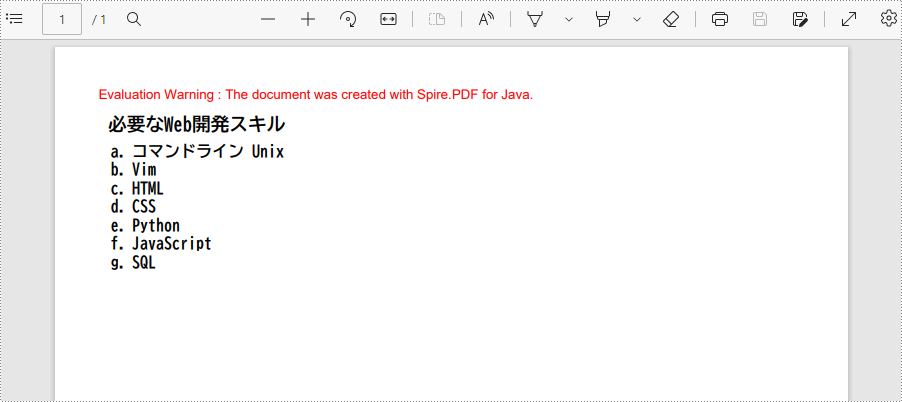
String title = "必要なWeb開発スキル";
page.getCanvas().drawString(title, titleFont, brush, x, y);
y = y + (float) titleFont.measureString(title).getHeight();
y = y + 5;
//番号付きリストを作成する
String listContent = "コマンドライン Unix\n"
+ "Vim\n"
+ "HTML\n"
+ "CSS\n"
+ "Python\n"
+ "JavaScript\n"
+ "SQL";
PdfSortedList list = new PdfSortedList(listContent);
//リストのフォント、インデント、テキストインデント、ブラシ、マーカーを設定する
list.setFont(listFont);
list.setIndent(2);
list.setTextIndent(4);
list.setBrush(brush);
list.setMarker(marker);
//ページ上の指定された位置にリストを描画する
list.draw(page, x, y);
//ドキュメントを保存する
doc.saveToFile("順序付きリスト.pdf");
}
}
順序無しリストは、箇条書きリストとも呼ばれ、特別な順序や順番を持たない関連項目の集合体である。リスト内の各項目は、箇条書きでマークされています。以下は、Spire.PDF for Java を使用して、PDF 内の順序無しリストを作成する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.lists.PdfMarker;
import com.spire.pdf.lists.PdfUnorderedList;
import com.spire.pdf.lists.PdfUnorderedMarkerStyle;
import java.awt.*;
public class createUnorderedList {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//余白を設定する
PdfMargins margin = new PdfMargins(30);
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, margin);
//フォントを作成する
PdfCjkStandardFont titleFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 14f);
PdfCjkStandardFont listFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 12f);
PdfCjkStandardFont markerFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 8f);
//ブラシを作成する
PdfBrush brush = PdfBrushes.getBlack();
//初期座標を指定する
float x = 10;
float y = 20;
//タイトルを描画する
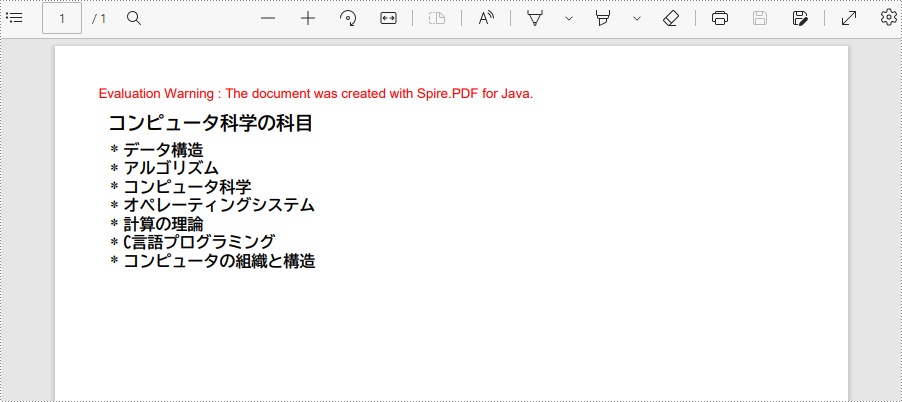
String title = "コンピュータ科学の科目";
page.getCanvas().drawString(title, titleFont, brush, x, y);
y = y + (float)titleFont.measureString(title).getHeight();
y = y + 5;
//マーカーのスタイルを指定する
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Asterisk);
marker.setFont(markerFont);
//順序なしリストを作成する
String listContent = "データ構造\n"
+ "アルゴリズム\n"
+ "コンピュータ科学\n"
+ "オペレーティングシステム\n"
+ "計算の理論\n"
+ "C言語プログラミング\n"
+"コンピュータの組織と構造";
PdfUnorderedList list = new PdfUnorderedList(listContent);
//リストのフォント、インデント、テキストインデント、ブラシ、マーカーを設定する
list.setFont(listFont);
list.setIndent(2);
list.setTextIndent(4);
list.setBrush(brush);
list.setMarker(marker);
//ページ上の指定された位置にリストを描画する
list.draw(page, x, y);
//ドキュメントを保存する
doc.saveToFile("順序なしリスト.pdf");
}
}
順序なしリストの箇条書きは、記号の他に画像も使用できます。画像の箇条書きリストを作成する手順は次のとおりです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.lists.PdfMarker;
import com.spire.pdf.lists.PdfUnorderedList;
import com.spire.pdf.lists.PdfUnorderedMarkerStyle;
import java.awt.*;
public class customizeBulletPointsWithImage {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//余白を設定する
PdfMargins margin = new PdfMargins(30);
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, margin);
//フォントを作成する
PdfCjkStandardFont titleFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 14f);
PdfCjkStandardFont listFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 12f);
//ブラシを作成する
PdfBrush brush = PdfBrushes.getBlack();
//初期座標を指定する
float x = 10;
float y = 20;
//タイトルを描画する
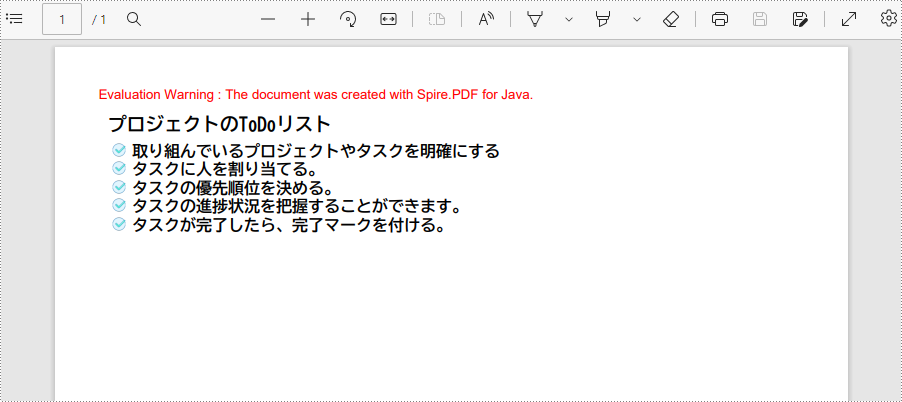
String title = "プロジェクトのToDoリスト";
page.getCanvas().drawString(title, titleFont, brush, x, y);
y = y + (float)titleFont.measureString(title).getHeight();
y = y + 5;
//マーカーのスタイルを画像に指定する
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_Image);
//マーカーに画像を設定する
marker.setImage(PdfImage.fromFile("C:/Users/Sirion/Desktop/確認マーク.png"));
//順序なしリストを作成する
String listContent = "取り組んでいるプロジェクトやタスクを明確にする\n"
+ "タスクに人を割り当てる。\n"
+ "タスクの優先順位を決める。\n"
+ "タスクの進捗状況を把握することができます。\n"
+ "タスクが完了したら、完了マークを付ける。";
PdfUnorderedList list = new PdfUnorderedList(listContent);
//リストのフォント、インデント、テキストインデント、ブラシ、メーカーを設定する
list.setFont(listFont);
list.setIndent(2);
list.setTextIndent(4);
list.setBrush(brush);
list.setMarker(marker);
//ページ上の指定された位置にリストを描画する
list.draw(page, x, y);
//ドキュメントを保存する
doc.saveToFile("画像の箇条書き.pdf");
}
}
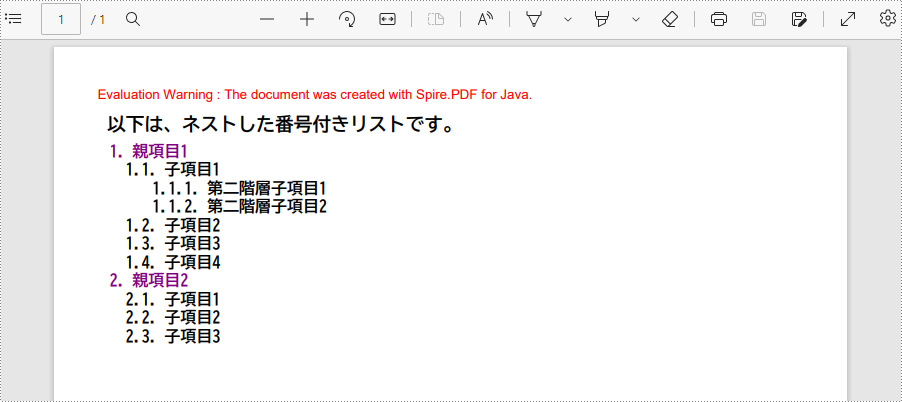
ネストされたリストとは、少なくとも1つのサブリストを含むリストのことです。 これは、階層構造でデータを表示するために使用されます。以下は、Spire.PDF for Java を使用して、PDF にネストした番号付きリストを作成する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfNumberStyle;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.lists.PdfListItem;
import com.spire.pdf.lists.PdfOrderedMarker;
import com.spire.pdf.lists.PdfSortedList;
import java.awt.*;
public class createMultiLevelList {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//余白を設定する
PdfMargins margin = new PdfMargins(30);
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, margin);
//初期座標を指定する
float x = 10;
float y = 20;
//2つのブラシを作成する
PdfBrush blackBrush = PdfBrushes.getBlack();
PdfBrush purpleBrush = PdfBrushes.getPurple();
//2つのフォントを作成する
PdfCjkStandardFont titleFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 14f);
PdfCjkStandardFont listFont = new PdfCjkStandardFont(PdfCjkFontFamily.Heisei_Kaku_Gothic_W_5, 12f);
//順序付きリストのメーカーを作成する
PdfOrderedMarker marker = new PdfOrderedMarker(PdfNumberStyle.Numeric, listFont);
//タイトルを描画する
String title = "以下は、ネストした番号付きリストです。";
page.getCanvas().drawString(title, titleFont, blackBrush, x, y);
y = y + (float)titleFont.measureString(title).getHeight();
y = y + 5;
//親リストを作成する
String parentListContent = "親項目1\n"
+ "親項目2";
PdfSortedList parentList = new PdfSortedList(parentListContent);
parentList.setFont(listFont);
parentList.setIndent(2);
parentList.setBrush(purpleBrush);
parentList.setMarker(marker);
//「subList_1」という子リストを作成する
String subListContent_1 = "子項目1\n"
+ "子項目2\n"
+ "子項目3\n"
+ "子項目4";
PdfSortedList subList_1 = new PdfSortedList(subListContent_1);
subList_1.setIndent(12);
subList_1.setFont(listFont);
subList_1.setBrush(blackBrush);
subList_1.setMarker(marker);
subList_1.setMarkerHierarchy(true);
//「subList_2」という子リストを作成する
String subListContent_2 = "子項目1\n"
+ "子項目2\n"
+ "子項目3";
PdfSortedList subList_2 = new PdfSortedList(subListContent_2);
subList_2.setIndent(12);
subList_2.setFont(listFont);
subList_2.setBrush(blackBrush);
subList_2.setMarker(marker);
subList_2.setMarkerHierarchy(true);
//「subList_2」という第二階層子リストを作成する
String subSubListContent_1 = "第二階層子項目1\n"
+ "第二階層子項目2";
PdfSortedList subSubList = new PdfSortedList(subSubListContent_1);
subSubList.setIndent(20);
subSubList.setFont(listFont);
subSubList.setBrush(blackBrush);
subSubList.setMarker(marker);
subSubList.setMarkerHierarchy(true);
//「subList_1」を親リストの1番目の項目のサブリストとして設定する
PdfListItem item_1 = parentList.getItems().get(0);
item_1.setSubList(subList_1);
//「subList_2」を親リストの2番目の項目のサブリストとして設定する
PdfListItem item_2 = parentList.getItems().get(1);
item_2.setSubList(subList_2);
//「subSubList」を「subList_1」の最初の項目の子リストとして設定する
PdfListItem item_1_1 = subList_1.getItems().get(0);
item_1_1.setSubList(subSubList);
//親リストを描画する
parentList.draw(page, x, y);
//ドキュメントを保存する
doc.saveToFile("多階層リスト.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation for Java 8.1.2のリリースを発表できることをうれしく思います。このリリースでは、ツリーマップ、サンバースト、ヒストグラム、箱ひげ図、ウォーターフォール、パレート図、じょうごなど、PowerPoint 2016に新たに追加されたグラフの種類の作成をサポートしました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | ツリーマップ、サンバースト、ヒストグラム、箱ひげ図、ウォーターフォール、パレート図、じょうごなどのグラフの種類をサポートしました。 |
Spire.PDF for Java 9.1.4のリリースを発表できることをうれしく思います。このバージョンでは、PDFドキュメントを圧縮する新しい方法が追加されました。PDFからPDFAへの変換機能も強化されました。また、このリリースでは既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | PDFドキュメントを圧縮する方法が追加されました。
PdfCompressor compressor = new PdfCompressor(fileName); compressor.compressToFile(outputName) |
| Bug | SPIREPDF-5667 | ドキュメントをマージすると、アプリケーションが「com.spire.pdf.packages.sprnsn cannot be cast to com.spire.pdf.packages.sprvqe」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5682 | PDFをPDFAに変換した後にフォームの内容が失われていた問題が修正されました。 |
Word のテーブルには、テキストや画像など、さまざまな要素を含めることができます。場合によっては、画像をテーブルに挿入して情報を表示したり、他のドキュメントで使用するためにテーブルから画像を抽出したりすることがあります。この記事では、Spire.Doc for .NET を使用して、C# および VB.NET でプログラムによって Word でテーブルに画像を挿入または抽出する方法を示します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET が提供する TableCell.Paragraphs[int].AppendPicture() メソッドは、特定のテーブルのセルに画像を追加することをサポートします。詳細な手順は次のとおりです。
using Spire.Doc;
using Spire.Doc.Fields;
using System.Drawing;
namespace InsertImagesIntoTable
{
class Program
{
static void Main(string[] args)
{
//Documentのインスタンスを初期化する
Document doc = new Document();
//Wordドキュメントをロードする
doc.LoadFromFile("Table.docx");
//最初のセクションを取得する
Section section = doc.Sections[0];
//セクションから最初のテーブルを取得する
Table table = (Table)section.Tables[0];
//テーブルの2行目の3番目のセルに画像を追加する
TableCell cell = table.Rows[1].Cells[2];
DocPicture picture = cell.Paragraphs[0].AppendPicture(Image.FromFile("doc.png"));
//画像の幅と高さを設定する
picture.Width = 100;
picture.Height = 100;
//テーブルの3行目の3番目のセルに画像を追加する
cell = table.Rows[2].Cells[2];
picture = cell.Paragraphs[0].AppendPicture(Image.FromFile("xls.png"));
//画像の幅と高さを設定する
picture.Width = 100;
picture.Height = 100;
//結果ドキュメントを保存する
doc.SaveToFile("AddImageToTable.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Imports Spire.Doc.Fields
Namespace InsertImagesIntoTable
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Documentのインスタンスを初期化する
Dim doc As Document = New Document()
'Wordドキュメントをロードする
doc.LoadFromFile("Table.docx")
' 最初のセクションを取得する
Dim section As Section = doc.Sections(0)
'セクションから最初のテーブルを取得する
Dim table As Table = CType(section.Tables(0), Table)
'テーブルの2行目の3番目のセルに画像を追加する
Dim cell As TableCell = table.Rows(1).Cells(2)
Dim picture As DocPicture = cell.Paragraphs(0).AppendPicture(Image.FromFile("doc.png"))
'画像の幅と高さを設定する
picture.Width = 100
picture.Height = 100
'テーブルの3行目の3番目のセルに画像を追加する
cell = table.Rows(2).Cells(2)
picture = cell.Paragraphs(0).AppendPicture(Image.FromFile("xls.png"))
'画像の幅と高さを設定する
picture.Width = 100
picture.Height = 100
'結果ドキュメントを保存する
doc.SaveToFile("AddImageToTable.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace
テーブルから画像を抽出するには、すべての行、各行のすべてのセル、各セルのすべての段落と各段落のすべてのサブオブジェクトをループします。次に、DocPicture タイプのオブジェクトを見つけ、DocPicture.Image.Save() メソッドを使用して指定したファイルパスに保存します。具体的な手順は次のとおりです。
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using System;
using System.Drawing.Imaging;
namespace ExtractImagesFromTable
{
class Program
{
static void Main(string[] args)
{
//Documentクラスを初期化する
Document doc = new Document();
//Wordドキュメントをロードする
doc.LoadFromFile("AddImageToTable.docx");
//最初のセクションを取得する
Section section = doc.Sections[0];
//セクションから最初のテーブルを取得する
Table table = (Table)section.Tables[0];
int index = 0;
string imageName = null;
//テーブル内のすべての行をループする
for (int i = 0; i < table.Rows.Count; i++)
{
//各行のすべてのセルをループする
for (int j = 0; j < table.Rows[i].Cells.Count; j++)
{
//各セル内のすべての段落をループする
foreach (Paragraph para in table[i, j].Paragraphs)
{
//各段落内のすべてのサブオブジェクトをループする
foreach (DocumentObject obj in para.ChildObjects)
{
//現在のサブオブジェクトがDocPictureタイプであるかどうかを確認する
if (obj is DocPicture)
{
//指定したファイルパスに画像を保存する
imageName = string.Format(@"images\TableImage-{0}.png", index);
(obj as DocPicture).Image.Save(imageName, ImageFormat.Png);
index++;
}
}
}
}
}
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Imports System.Drawing.Imaging
Namespace ExtractImagesFromTable
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Documentクラスを初期化する
Dim doc As Document = New Document()
' Wordドキュメントをロードする
doc.LoadFromFile("AddImageToTable.docx")
'ドキュメントの最初のセクションを取得する
Dim section As Section = doc.Sections(0)
'最初のセクションから最初のテーブルを取得する
Dim table As Table = CType(section.Tables(0), Table)
Dim index = 0
Dim imageName As String = Nothing
'テーブル内のすべての行をループする
For i As Integer = 0 To table.Rows.Count - 1
'各行のすべてのセルをループする
For j As Integer = 0 To table.Rows(i).Cells.Count - 1
'各セル内のすべての段落をループする
For Each para As Paragraph In table(i, j).Paragraphs
'各段落内のすべてのサブオブジェクトをループする
For Each obj As DocumentObject In para.ChildObjects
'現在のサブオブジェクトがDocPictureタイプであるかどうかを確認する
If TypeOf obj Is DocPicture Then
'指定したファイルパスに画像を保存する
imageName = string.Format("images\TableImage-{0}.png", index)
TryCast(obj, DocPicture).Image.Save(imageName, ImageFormat.Png)
index += 1
End If
Next
Next
Next
Next
End Sub
End Class
End Namespace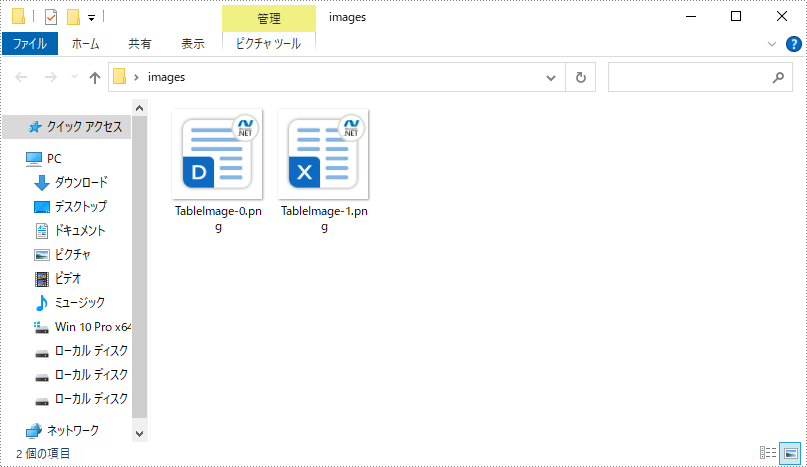
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF は、ページ上に文字と図形を表示することができ、また保存容器としても機能する多機能なファイル形式です。PDF にファイルを添付し、後で取り出すことも可能です。また、PDFに関連資料を添付することで、資料の一元管理と送信を容易にすることができます。
Spire.PDF for Java では、2つの方法でファイルを添付することができます。
この記事では、Spire.PDF for Java を使用して、Java でPDF ドキュメントにこれらの2つのタイプの添付ファイルを追加または削除する方法を示します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>PdfDocument.getAttachments().add() メソッドを使用すると、「添付ファイル」パネルに添付ファイルを簡単に追加することができます。以下は、その詳細な手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.attachments.PdfAttachment;
public class addAttachmentsToPdf {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("年次総会.pdf");
//外部ファイルを元にPdfAttachmentクラスのオブジェクトを作成する
PdfAttachment attachment = new PdfAttachment("出席者の一覧.xlsx");
//PDFに添付ファイルを追加する
doc.getAttachments().add(attachment);
//PDFファイルを保存する
doc.saveToFile("添付ファイル.pdf");
}
}
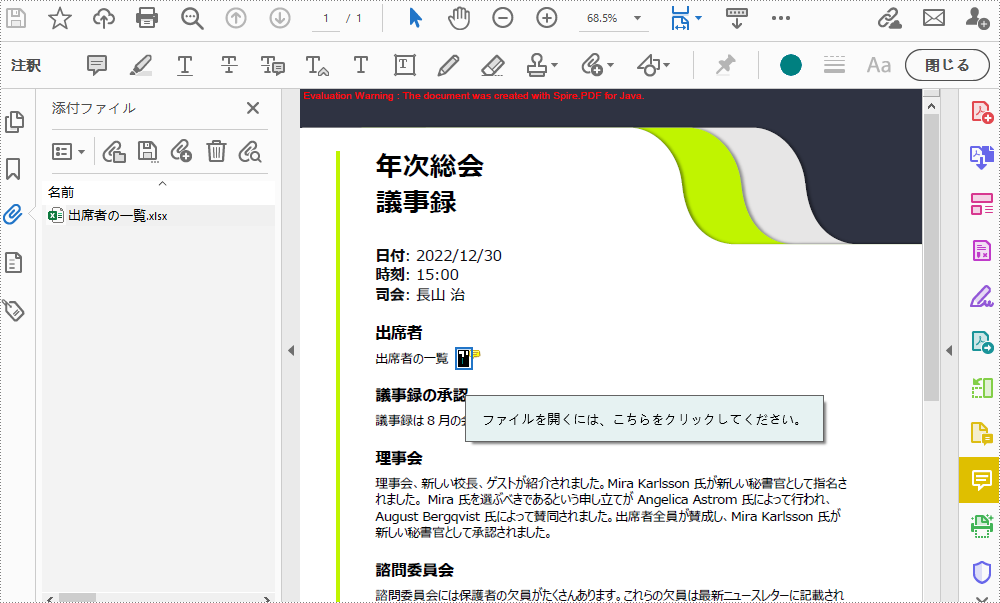
注釈の添付は、特定のページだけでなく「添付ファイル」パネルでも見つけることができます。以下は、Spire.PDF for Java を使用して PDF に注釈の添付ファイルを追加する手順です。
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.annotations.*;
import com.spire.pdf.general.find.PdfTextFind;
import com.spire.pdf.general.find.PdfTextFindCollection;
import com.spire.pdf.graphics.*;
import com.spire.pdf.PdfDocument;
import java.awt.*;
import java.awt.geom.Dimension2D;
import java.awt.geom.Rectangle2D;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class addAnnotationAttachment {
public static void main(String[] args) throws IOException {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("年次総会.pdf");
//指定のページを取得する
PdfPageBase page = doc.getPages().get(0);
//注釈を付けるテキストを探す
PdfTextFindCollection results = page.findText("出席者の一覧", true, false);
PdfTextFind[] findCollection = results.getFinds();
String find = findCollection[0].toString();
//注釈としてファイルを添付する
String filePath = "出席者の一覧.xlsx";
double x = findCollection[0].getPosition().getX();
double y = doc.getPages().get(0).getActualSize().getHeight() - 592;
byte[] data = toByteArray(filePath);
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Meiryo UI", Font.PLAIN, 13));
Dimension2D size = font.measureString(find);
Rectangle2D bound = new Rectangle2D.Float((float) (x + size.getWidth()/4), (float) y, 10, 15);
PdfAttachmentAnnotation annotation = new PdfAttachmentAnnotation(bound, filePath, data);
annotation.setColor(new PdfRGBColor(new Color(0, 128, 128)));
annotation.setFlags(PdfAnnotationFlags.Default);
annotation.setIcon(PdfAttachmentIcon.Graph);
annotation.setText("ファイルを開くには、こちらをクリックしてください。");
page.getAnnotationsWidget().add(annotation);
//PDFファイルを保存する
doc.saveToFile("注釈としての添付ファイル.pdf");
}
//ファイルをバイト配列に変換する
public static byte[] toByteArray(String filePath) throws IOException {
File file = new File(filePath);
long fileSize = file.length();
if (fileSize > Integer.MAX_VALUE) {
System.out.println("ファイルサイズが大きすぎる。");
return null;
}
FileInputStream fi = new FileInputStream(file);
byte[] buffer = new byte[(int) fileSize];
int offset = 0;
int numRead = 0;
while (offset < buffer.length
&& (numRead = fi.read(buffer, offset, buffer.length - offset)) >= 0) {
offset += numRead;
}
if (offset != buffer.length) {
throw new IOException("ファイルを完全に読み取ることができませんでした。"
+ file.getName());
}
fi.close();
return buffer;
}
}
PDF 文書の添付ファイルは、PdfDocument.getAttachments() メソッドでアクセスでき、PdfAttachmentCollection クラスのオブジェクト下の removeAt() メソッドまたは clear() メソッドを使用して削除することが可能です。詳細な手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.attachments.PdfAttachmentCollection;
public class removeAttachments {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("添付ファイル.pdf");
//注釈の添付ファイルを含まない添付ファイルコレクションを取得する
PdfAttachmentCollection attachments = doc.getAttachments();
//すべての添付ファイルを削除する
attachments.clear();
//指定した添付ファイルを削除する
//attachments.removeAt(0);
//PDFファイルを保存する
doc.saveToFile("添付ファイルの削除.pdf");
doc.close();
}
}注釈は、ページを基準にした要素です。文書からすべての注釈を取得するには、ページをたどり、各ページから注釈を取得する必要があります。次に、ある注釈が注釈添付であるかどうかを判断します。最後に、remove() メソッドを使用して、注釈コレクションから注釈としての添付ファイルを削除します。 以下はその詳細な手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.annotations.PdfAnnotation;
import com.spire.pdf.annotations.PdfAnnotationCollection;
import com.spire.pdf.annotations.PdfAttachmentAnnotationWidget;
public class removeAnnotationAttachments {
public static void main(String[] args) {
//PdfDocumentクラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("注釈としての添付ファイル.pdf");
//ページをループする
for (int i = 0; i < doc.getPages().getCount(); i++) {
//注釈コレクションを取得する
PdfAnnotationCollection annotationCollection = doc.getPages().get(i).getAnnotationsWidget();
//注釈をループする
for (Object annotation: annotationCollection) {
//注釈がPdfAttachmentAnnotationWidgetクラスのインスタンスであるかどうかを判定する
if (annotation instanceof PdfAttachmentAnnotationWidget){
//添付ファイルの注釈を削除する
annotationCollection.remove((PdfAnnotation) annotation);
}
}
}
//PDFファイルを保存する
doc.saveToFile("注釈としての添付ファイルの削除.pdf");
doc.close();
}
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS 13.1.1のリリースを発表できることを嬉しく思います。今回のアップデートでは、ExcelからPDF、XLSからXLSXへの変換機能が強化されました。また、グラフを画像に変換する際に棒グラフが座標軸の左側から飛び出してしまう問題や、XLSMドキュメントをロードして保存した後にマクロが失われてしまう問題など、多くの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-1105 | sheet1.CopyFrom(sheet2)メソッドを使用してsheetコンテンツをコピーすると、アプリケーションが「Maximum number of extended formats exceeded」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4310 | UTF 8エンコードされたHTMLをロードする際にアプリケーションが「System.ArgumentException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4320 | グラフを画像に変換するときに棒グラフが座標軸の左側から飛び出してしまう問題が修正されました。 |
| Bug | SPIREXLS-4334 | XLSをXLSXに変換する際にアプリケーションが「System.Xml.XmlException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4338 | 「CopyRangeOptions copyOptions = CopyRangeOptions.OnlyCopyFormulaValue;」の設定が機能しない問題が修正されました。 |
| Bug | SPIREXLS-4358 | sheetを削除する際にアプリケーションが「System.ArgumentOutOfRangeException」をスローした問題が修正されました。 |
| Bug | SPIREXLS-4365 | XLSMドキュメントをロードして保存した後にマクロが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4373 | ドキュメントを保護した後のメニューの機能が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4375 | 式の計算に失敗した問題が修正されました。 |
| Bug | SPIREXLS-4381 | 計算された式の値が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4384 | ExcelをPDFに変換した後の日付フォーマットが正しくない問題が修正されました。 |
チームメンバーと一緒に PowerPoint ドキュメントを作成する場合、コメントを追加することは、ドキュメントの内容についてフィードバックを提供したり、意見を交換したりするための最も効果的な方法です。また、既存のコメントの変更または削除が必要な場合もあります。この記事では、Spire.Presentation for Java を使用して PowerPoint でコメントを追加、変更、または削除する方法を紹介します。
まず、Spire.Presentation for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>7.12.4</version>
</dependency>
</dependencies>Spire.Presentation for Java が提供する ISlide.addComment() メソッドでは、指定したスライドにコメントを追加できます。詳細な手順は次のとおりです。
import com.spire.presentation.*;
import java.awt.geom.Point2D;
public class AddComment {
public static void main(String[] args) throws Exception{
//Presentationクラスのインスタンスを初期化する
Presentation ppt = new Presentation();
//PowerPointドキュメントをロードする
ppt.loadFromFile("Sample.pptx");
//コメントの作成者を追加する
ICommentAuthor author = ppt.getCommentAuthors().addAuthor("E-iceblue", "コメント:");
//指定されたスライドへにコメントを追加する
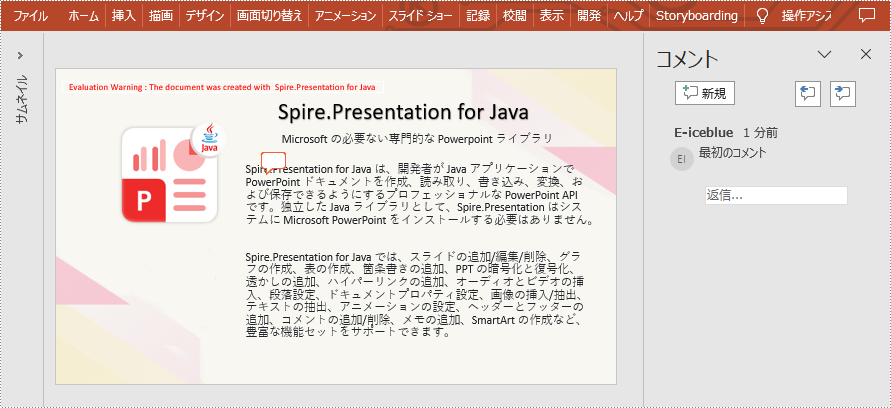
ppt.getSlides().get(0).addComment(author, "最初のコメント", new Point2D.Float(350, 140), new java.util.Date());
//結果ドキュメントを保存する
ppt.saveToFile("AddComment.pptx", FileFormat.PPTX_2013);
ppt.dispose();
}
}
Spire.Presentation for Java が提供する ISlide.getComments().setText() メソッドでは、スライドのコメントを変更できます。詳細な手順は次のとおりです。
import com.spire.presentation.*;
public class ReplaceComment {
public static void main(String[] args) throws Exception{
//Presentationクラスのインスタンスを初期化する
Presentation ppt = new Presentation();
//PowerPointドキュメントをロードする
ppt.loadFromFile("AddComment.pptx");
//最初のスライドを取得する
ISlide slide = ppt.getSlides().get(0);
//スライドの指定されたコメント置き換えます
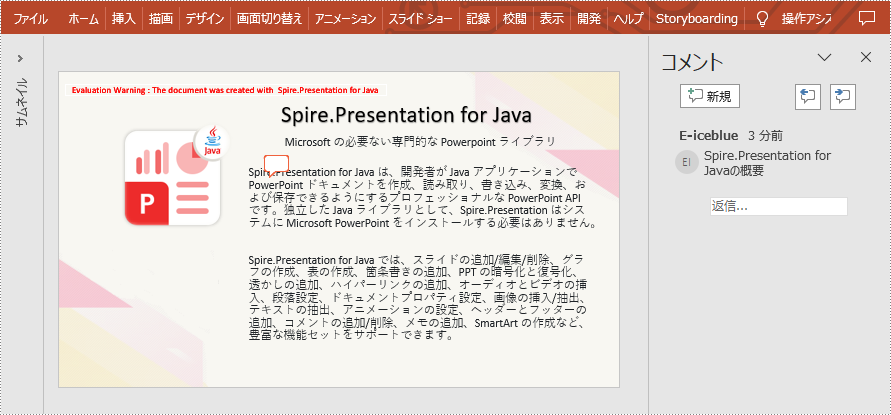
slide.getComments()[0].setText("Spire.Presentation for Javaの概要");
//結果ドキュメントを保存する
ppt.saveToFile("ReplaceComment.pptx", FileFormat.PPTX_2013);
ppt.dispose();
}
}
Spire.Presentation for Java が提供する ISlide.deleteComment() メソッドでは、スライドのコメントを削除できます。詳細な手順は次のとおりです。
import com.spire.presentation.*;
public class DeleteComment {
public static void main(String[] args) throws Exception{
//Presentationクラスのインスタンスを初期化する
Presentation ppt = new Presentation();
//PowerPointドキュメントをロードする
ppt.loadFromFile("AddComment.pptx");
//最初のスライドを取得する
ISlide slide = ppt.getSlides().get(0);
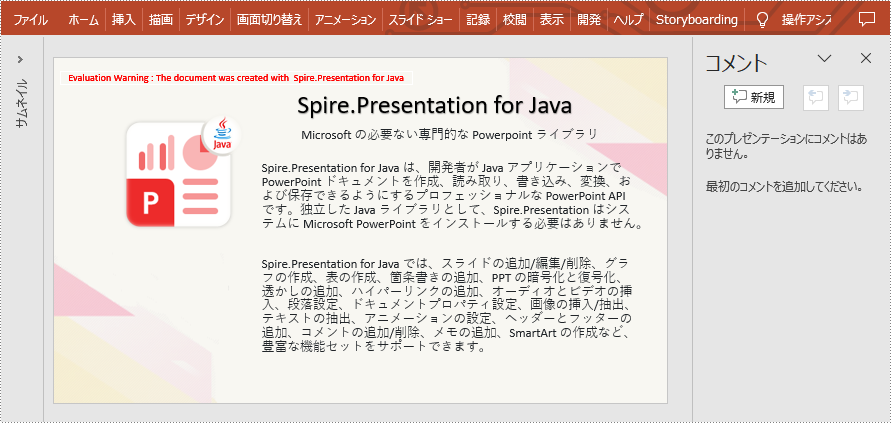
//指定したコメントをスライドから削除する
slide.deleteComment(slide.getComments()[0]);
//結果ドキュメントを保存する
ppt.saveToFile("DeleteComment.pptx", FileFormat.PPTX_2013);
ppt.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





