チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Office for Java 7.9.6 のリリースを発表できることをうれしく思います。今回のアップデートには、いくつかの新機能が含まれています。Spire.XLS for Java はカスタムソートがサポートして、Excel 2016 で定義された Chart タイプ を PDF と画像に変換がサポートしました。Spire.PDF for Java は、無秩序リストの作成をサポートします。Spire.Doc for Java は、Word から PDF への変換機能を強化します。さらに、多くの既知のバグが正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4002 | Worksheet.getMaxDispalyRange() メソッドを使用して画像、形状などのオブジェクトを含むすべてのセル範囲の取得をサポートしました。
Workbook workbook = new Workbook();
workbook.loadFromFile("TEST.xlsx");
Worksheet sheet1 = workbook.getWorksheets().get(0);
//copy all objects(such as text, shape, image...) from sheet2 to sheet1
for(int i=1;i<workbook.getWorksheets().getCount(); i++){
Worksheet sheet2 = workbook.getWorksheets().get(i);
sheet2.copy((CellRange) sheet2.getMaxDisplayRange(),sheet1,sheet1.getLastRow()+1,sheet2.getFirstColumn(),true);
}
workbook.saveToFile("output.xlsx", ExcelVersion.Version2013); |
| New feature | SPIREXLS-4026 | =Days() 式をサポートしました。
Workbook workbook = new Workbook();
workbook.loadFromFile("Test.xlsx");
Worksheet sheet = workbook.getWorksheets().get(0);
sheet.getCellRange("C4").setFormula("=DAYS(A8,A1)");
workbook.saveToFile(""RES.xlsx""); |
| Bug | SPIREXLS-3980 | XML から Excel に変換した後、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-3995 | Excel から SVG に変換した後、グラフのタイトルが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4014 | Excel から PDF に変換した後、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4020 | Excel から PDF に変換するときに、アプリケーションが「StringIndexOutOfBoundsException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4054 | グラフ DataRange を取得するときに、アプリケーションが「NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4070 | Files.deleteIfExists() を使用して isPasswordProtected() メソッドで検出されたファイルを削除するときに、アプリケーションが「FileSystemException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-2862 | Excel を PDF に変換する際に、改行位置が正しくない問題が修正されました。 |
| Bug | SPIREXLS-2986 SPIREXLS-3019 |
Excel を PDF に変換する際に、ページ余白が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4043 | Excel を HTML に変換する際に、テーブルレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4072 | ピボット・テーブルのフィルタの選択した値を変更すると、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4073 | Excel を PDF に変換する際に、セルの枠線が失われていた問題が修正されました。 |
| Bug | SPIREXLS-4075 | グラフを画像に変換した後、X軸テキストの方向が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4012 | ヘッダーとフッターの画像を削除しても、ドキュメントのサイズが小さくならなかった問題が修正されました。 |
| Bug | SPIREXLS-4105 | Excel をロードする際に、アプリケーションが「Unknown char:%」をスローする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | - | 無秩序リストの作成をサポートしました。
public void DrawMarker(PdfUnorderedMarkerStyle style, String outputFile) {
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(style);
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close();
}
public void PdfMarker_CustomImage() throws Exception {
String outputFile = "PdfMarker_CustomImage.pdf";
String inputFile_Img = "sample.png";
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_Image);
marker.setImage(PdfImage.fromFile(inputFile_Img));
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close();
}
public void PdfMarker_CustomTemplate() throws Exception {
String outputFile = "PdfMarker_CustomTemplate.pdf";
String inputFile_Img = "sample.png";
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_Template);
PdfTemplate template = new PdfTemplate(210, 210);
marker.setTemplate(template);
template.getGraphics().drawImage(PdfImage.fromFile(inputFile_Img), 0, 0);
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close();
}
public void PdfMarker_CustomString() throws Exception {
String outputFile = "PdfMarker_CustomString.pdf";
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_String);
marker.setText("AAA");
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close(); |
| Adjustment | - | 署名タイムスタンプの内部セキュリティが調整されました。 |
| Bug | SPIREPDF-4780 | PDF を Tiff に変換し、アプリケーションの実行時間が長く、メモリ消費が大きい問題が修正されました。 |
| Bug | SPIREPDF-5387 | PDF ドキュメントのロードするときに、アプリケーションが「Read failure」をスローした問題を修正しました。 |
| Bug | SPIREPDF-5390 | PDF を Excel に変換した後、文書のフォントが太くなって消えてしまった問題を修正しました。 |
| Bug | SPIREPDF-5402 | PDF を Excel に変換するときにメモリオーバーフローが発生する問題を修正しました。 |
| Bug | SPIREPDF-5419 | PDF を Excel に変換する際に、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5422 SPIREPDF-5435 |
抽出テーブルの内容が不完全であった問題が修正されました。 |
| Bug | SPIREPDF-5423 | 組み合わせ枠域が平坦化した後、コンテンツが重複する問題が修正されました。 |
| Bug | SPIREPDF-5438 | PDF を PDFA3A に変換した後、結果文書のアラビア文字の表示が正しくなかったことが修正されました。 |
| Bug | SPIREPDF-5446 | PDF を画像に変換する際に、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7704 | Word で PDF を変換する際に、otf形式のプライベートフォントを設定した後にアプリケーションが「IllegalArgumentException」をスローする問題を修正しました。 |
| Bug | SPIREDOC-7841 | Word を PDF に変換する際に、プライベートフォントを埋め込むことに失敗した問題が修正されました。 |
| Bug | SPIREDOC-8242 | DOC から DOCX 2007 に変換するときに、コンテンツの配置が不一致の問題を修正しました。 |
ハイパーリンクは通常、別のファイルやオブジェクトにリンクするアイコン、画像、テキストを基にしています。これは、文書を操作するために最も一般的に使用される機能の1つです。Spire.PDF for Java は、新しい PDF ドキュメントを作成し、そこに通常のリンク、ハイパーテキストリンク、メールリンク、ドキュメントリンクなど、様々なハイパーリンクを追加することをサポートしています。この記事では、既存の PDF に特定のテキストにハイパーリンクを追加する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire PDF for Java を使用すると、特定の PDF ページで一致する全てのテキストを検索し、それらにハイパーリンクを追加することができます。以下は、その詳細な手順です。
import com.spire.pdf.*;
import com.spire.pdf.annotations.*;
import com.spire.pdf.general.find.*;
import com.spire.pdf.graphics.PdfRGBColor;
import java.awt.*;
public class searchTextAndAddHyperlink {
public static void main(String[] args) {
//PdfDocument クラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/Sample.pdf");
//最初のページを表示する
PdfPageBase page = pdf.getPages().get(0);
//マッチした文字列をすべて検索し、PdfTextFindCollection クラスのオブジェクトを返す
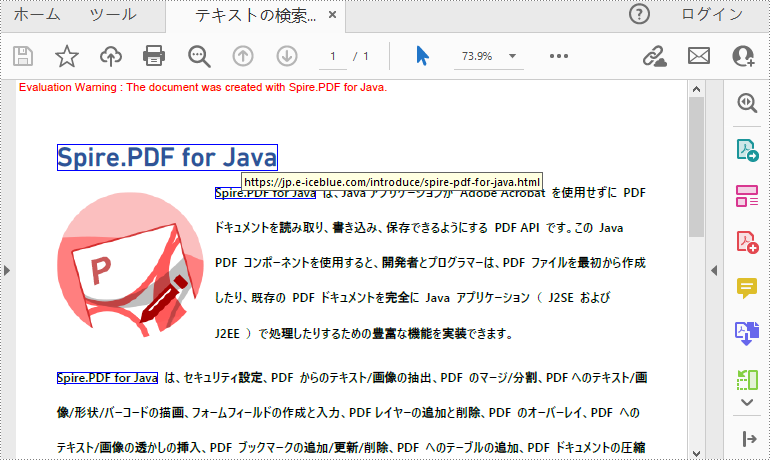
PdfTextFindCollection collection = page.findText("Spire.PDF for Java", false);
//検出されたコレクションをループする
for(PdfTextFind find : collection.getFinds())
{
//検索されたテキストにハイパーリンクを追加するための PdfUriAnnotation クラスのインスタンスを作成する
PdfUriAnnotation uri = new PdfUriAnnotation(find.getBounds());
uri.setUri("https://jp.e-iceblue.com/introduce/spire-pdf-for-java.html");
uri.setBorder(new PdfAnnotationBorder(1f));
uri.setColor(new PdfRGBColor(Color.blue));
page.getAnnotationsWidget().add(uri);
}
//ドキュメントを保存する
pdf.saveToFile("テキストの検索とハイパーリンクの追加.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS for Java 12.9.1 のリリースを発表できることを嬉しく思います。このリリースでは、Excel から PDF への変換機能が強化されました。ピボット・テーブルのフィルタの選択した値を変更すると、アプリケーションが「java.lang.NullPointerException」をスローするなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-2862 | Excel を PDF に変換する際に、改行位置が正しくない問題が修正されました。 |
| Bug | SPIREXLS-2986 SPIREXLS-3019 |
Excel を PDF に変換する際に、ページ余白が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4043 | Excel を HTML に変換する際に、テーブルレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4072 | ピボット・テーブルのフィルタの選択した値を変更すると、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4073 | Excel を PDF に変換する際に、セルの枠線が失われていた問題が修正されました。 |
| Bug | SPIREXLS-4075 | グラフを画像に変換した後、X軸テキストの方向が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4012 | ヘッダーとフッターの画像を削除しても、ドキュメントのサイズが小さくならなかった問題が修正されました。 |
| Bug | SPIREXLS-4105 | Excel をロードする際に、アプリケーションが「Unknown char:%」をスローする問題が修正されました。 |
Spire.PDF for Java 8.9.1 のリリースを発表できることをうれしく思います。このバージョンは、PDF から Excel と PDFA3A への変換機能が強化されました。また、このリリースでは、抽出テーブルの内容が不完全であるなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5390 | PDF を Excel に変換した後、文書のフォントが太くなって消えてしまった問題を修正しました。 |
| Bug | SPIREPDF-5402 | PDF を Excel に変換するときにメモリオーバーフローが発生する問題を修正しました。 |
| Bug | SPIREPDF-5419 | PDF を Excel に変換する際に、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5422 SPIREPDF-5435 |
抽出テーブルの内容が不完全であった問題が修正されました。 |
| Bug | SPIREPDF-5423 | 組み合わせ枠域が平坦化した後、コンテンツが重複する問題が修正されました。 |
| Bug | SPIREPDF-5438 | PDF を PDFA3A に変換した後、結果文書のアラビア文字の表示が正しくなかったことが修正されました。 |
| Bug | SPIREPDF-5446 | PDF を画像に変換する際に、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
PDF にテキストを描画する際、ページをより鮮やかにするために、色彩豊かなブラシやペンを定義することが必要な場合があります。この記事では、Spire.PDF for Java を使用して、PDF ドキュメント内の文字列の色スペースを設定する方法について説明します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire.PDF for Java は、テキストのブラシ色を設定するために PdfSolidBrush クラスを提供します。それは、特定の RGB の色スペースまたは HTML の色コードに基づいてブラシの色を定義する機能を備えています。
以下は、PDF ドキュメントに文字色を設定する詳細な手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfRGBColor;
import com.spire.pdf.graphics.PdfSolidBrush;
import com.spire.pdf.graphics.PdfTrueTypeFont;
import java.awt.*;
public class setPDFFontColor {
public static void main(String[] args) throws Exception {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add();
//位置を設定する
float y = 30;
//ソリッドブラシのオブジェクトを作成し、色を定義する
PdfRGBColor rgb1 = new PdfRGBColor(Color.green);
PdfSolidBrush brush1 = new PdfSolidBrush(rgb1);
//RGB色
PdfRGBColor rgb2 = new PdfRGBColor(0,197,205);
PdfSolidBrush brush2 = new PdfSolidBrush(rgb2);
//HTMLコード色
Color color = Color.decode("#A52A2A");
PdfSolidBrush brush3 = new PdfSolidBrush(new PdfRGBColor(color));
//トゥルータイプのフォントのオブジェクトを作成する
Font font = new Font("Yu Mincho", java.awt.Font.BOLD, 14);
PdfTrueTypeFont trueTypeFont = new PdfTrueTypeFont(font);
//テキストを描画する
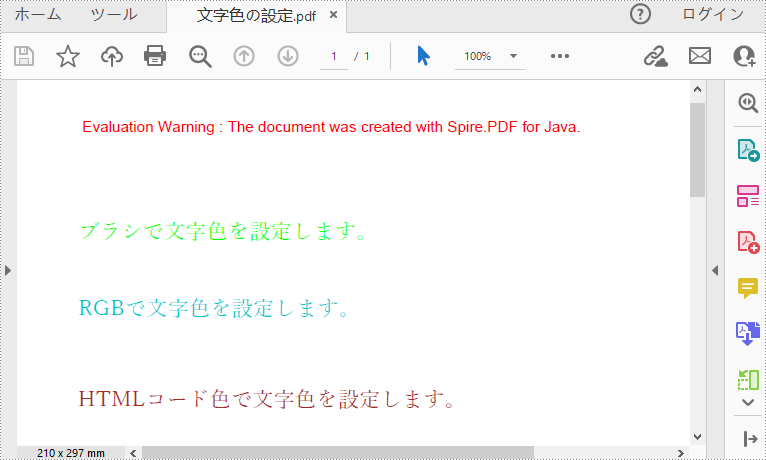
page.getCanvas().drawString("ブラシで文字色を設定します。", trueTypeFont, brush1, 0, (y = y + 30f));
page.getCanvas().drawString("RGBで文字色を設定します。", trueTypeFont, brush2, 0, (y = y + 50f));
page.getCanvas().drawString("HTMLコード色で文字色を設定します。", trueTypeFont, brush3, 0, (y = y + 60f));
//ドキュメントを保存する
doc.saveToFile("文字色の設定.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
XPS (XML Paper Specification) は、固定レイアウトのドキュメント書式です。この書式は、ドキュメントの忠実度を維持し、デバイスに依存しないドキュメントの外観を提供します。XPS は PDF に似ていますが、XPS は PostScript ではなく XML に基づいています。Word を固定レイアウトのドキュメント書式として保存するには、XPS が良い選択です。この記事では、Spire.Doc for .NET を使用して、C# および VB.NET で Word を XPS に変換する方法を示します。
まず、Spire.Doc for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET を使用して Word を XPS に変換するには、Word ドキュメントをロードして XPS ドキュメント書式として保存するだけです。詳細な手順は次のとおりです。
using Spire.Doc;
namespace ConvertWordToXps
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントをロードする
doc.LoadFromFile(@"sample.docx");
//WordをXPSとして保存する
doc.SaveToFile("Word to XPS.xps", FileFormat.XPS);
}
}
}Imports Spire.Doc
Namespace ConvertWordToXps
Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのオブジェクトを作成する
Dim doc As Document = New Document()
'Wordドキュメントをロードする
doc.LoadFromFile("sample.docx")
'WordをXPSとして保存する
doc.SaveToFile("Word to XPS.xps", FileFormat.XPS)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
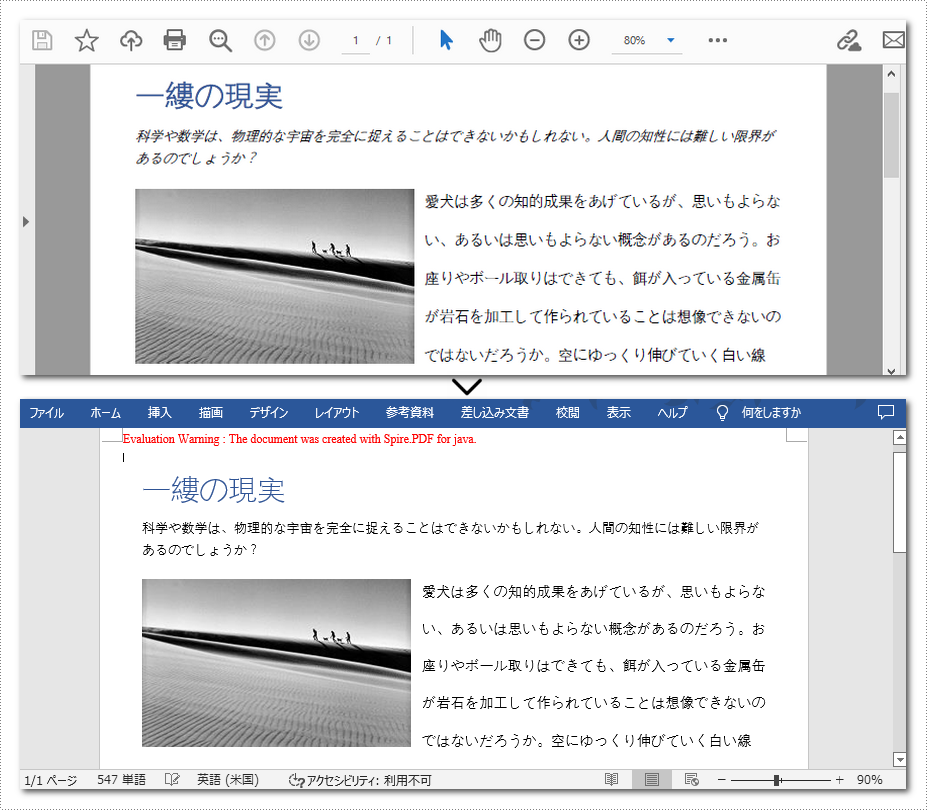
今日では、ソフトウェアを使用して Word ファイルにPDFドキュメントを変換することは困難ではありません。しかし、変換中にレイアウトやフォントの書式まで維持したい場合、それはすべてのソフトウェアが達成できるものではありません。Spire.PDF for Java はそれをうまく行い、Java で PDF を Word に変換するときに、次の2つのモードを提供します。
固定レイアウトモードは、高速な変換速度を持っており、最大限に PDF ファイルの元の外観を維持するために助長される。しかし、PDF のテキストの各行は、生成された Word ドキュメント内の別のフレームに表示されますので、結果のドキュメントの編集可能性は制限されます。
フローアブル構造は、完全な認識モードです。変換されたコンテンツはフレームで表示されず、生成されるドキュメントの構造はフローアブルです。生成された Word ドキュメントは再編集が容易ですが、元の PDF ファイルとは異なる外観になる場合があります。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>以下は、PDF を固定レイアウトの Doc または Docx に変換する手順です。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class PDFToWordWithFixedLayout {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントを読み込む
doc.loadFromFile("C:/Sample.pdf");
//PDFをDocに変換する
doc.saveToFile("ToDoc.doc", FileFormat.DOC);
//PDFをDocxに変換する
doc.saveToFile("ToDocx.docx", FileFormat.DOCX);
doc.close();
}
}以下は、PDF をフローラブル構造の Doc または Docx に変換する手順です。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class PDFToWordWithFlowableStructure {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントを読み込む
doc.loadFromFile("C:/Sample.pdf");
//PDFをフローラブル構造のWordに変換する
doc.getConvertOptions().setConvertToWordUsingFlow(true);
//PDFをDocに変換する
doc.saveToFile("ToDoc.doc", FileFormat.DOC);
//PDFをDocxに変換する
doc.saveToFile("ToDocx.docx", FileFormat.DOCX);
doc.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
SVG とは、Scalable Vector Graphics の略で、XML をベースとした2次元の図形を扱うベクター画像フォーマットです。SVG と PDF ファイルのようなベクター画像ファイルは、非常によく似ています。文字や画像などの要素を同じ外観で表示でき、どんなに拡大しても精細感が保たれる。そして、それらの類似性のために、PDF ファイルは、ほぼロスレスで SVG ファイルに変換することができます。この記事では、Spire.PDF for Java を使用して PDF ファイルを SVG ファイルに変換する簡単な方法を示しています。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>詳細な手順は以下の通りです。
import com.spire.pdf.*;
public class PDFToSVG {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:\\Sample.pdf");
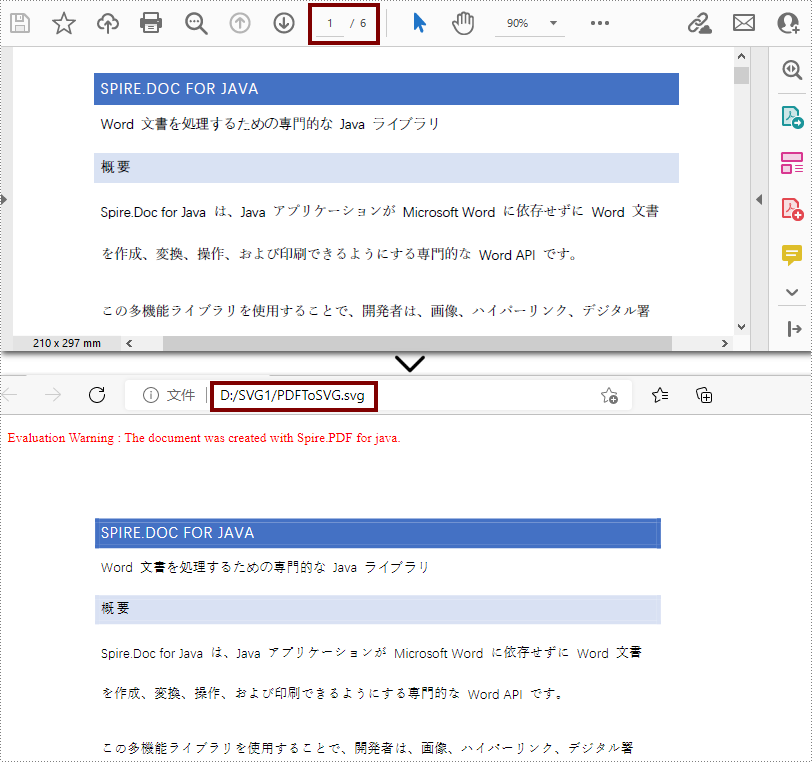
//ドキュメントをSVGに変換して保存する
pdf.saveToFile("D:\\PDFToSVG.svg", FileFormat.SVG);
}
}
詳細な手順は以下の通りです。
import com.spire.pdf.*;
public class PDFToSingleSVG {
public static void main(String[] args) {
//Document クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("D:/Samples/Sample.pdf");
//PDFファイルを1つのSVGファイルに変換するために変換設定を変更する
pdf.getConvertOptions().setOutputToOneSvg(true);
//ドキュメントをSVGに変換して保存する
pdf.saveToFile("D:/javaOutput/PDFToSVG.svg", FileFormat.SVG);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Excel ワークシートを日常的に操作する際には、保存や他の人と共有している間にデータが変更されないように画像に変換する必要がある場合があります。この記事では、Spire.XLS for Java を使用してExcel をイメージに変換する方法を紹介します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.8.4</version>
</dependency>
</dependencies>詳細な手順は次のとおりです。
import com.spire.xls.*;
public class ExcelToImage {
public static void main(String[] args){
// Workbookインスタンスを作成する
Workbook workbook = new Workbook();
// Excelサンプルドキュメントをロードする
workbook.loadFromFile("sample.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
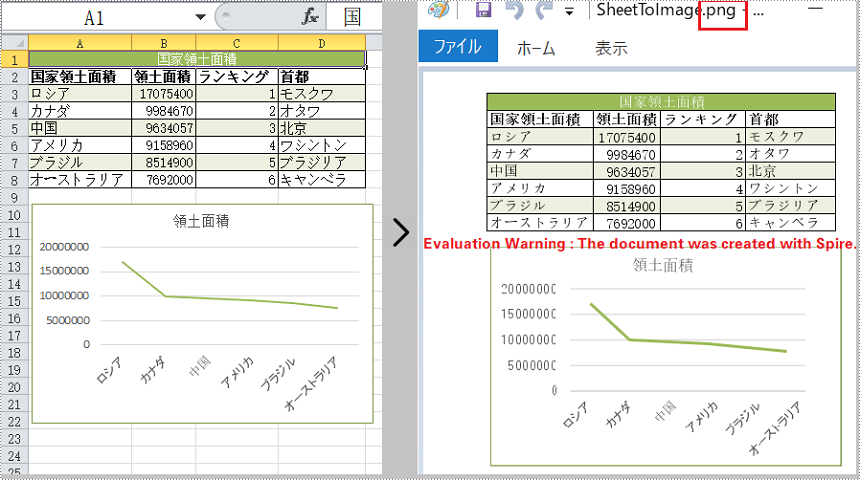
//ワークシートをイメージに変換する
sheet.saveToImage("output/SheetToImage.png");
}
}
Spire.XLS for Java は、Worksheet.toImage (int firstRow,int firstColumn,int lastRow,int lastColumn) メソッドを使用して特定のセル範囲をイメージに変換することをサポートしています。詳細な手順を以下に示します。
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
public class SpecificCellsToImage {
public static void main(String[] args) throws IOException {
//Workbookインスタンスを作成する
Workbook workbook = new Workbook();
//Excelサンプルドキュメントをロードする
workbook.loadFromFile("sample.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
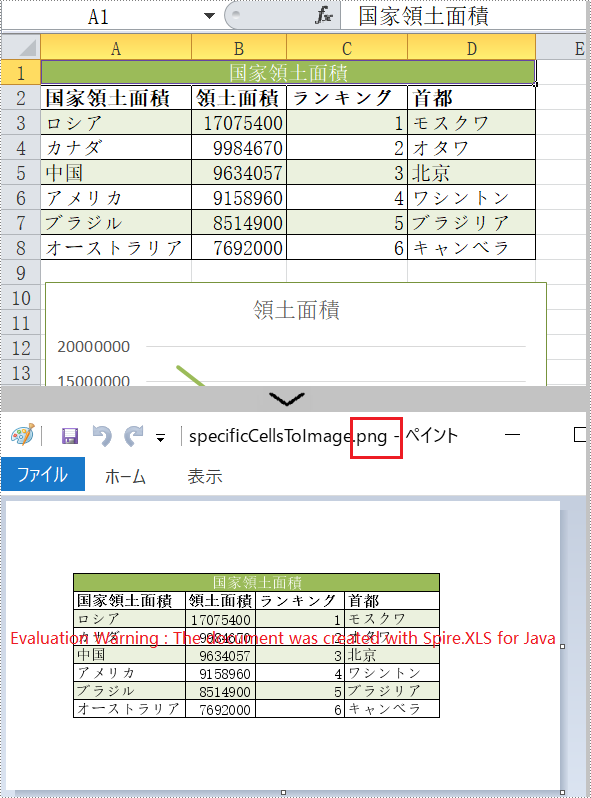
//特定のセル範囲をButteredImageオブジェクトに変換する
BufferedImage bufferedImage = sheet.toImage(1, 1, 8, 4);
//BufferedImageオブジェクトを.pngイメージに保存する
ImageIO.write(bufferedImage,"PNG",new File("output/specificCellsToImage.png"));
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.SpreadSheet 6.9.0 のリリースを発表できることを嬉しく思います。このバージョンでは、Worksheet.Resize メソッドが無効であった問題を修正しました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPREADSHEET-204 | Worksheet.Resize メソッドが無効であった問題を修正しました。 |





