チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

PDF ドキュメントは様々なデバイスやプラットフォームで広くサポートされていますが、画像は動画や他のドキュメントに簡単に追加できるため、特に1つの PDF ページしか表示したくない場合、特定のタスクに適している場合があります。この記事では、Spire.PDF for Java を使ってプログラム的に PDF を画像に変換する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
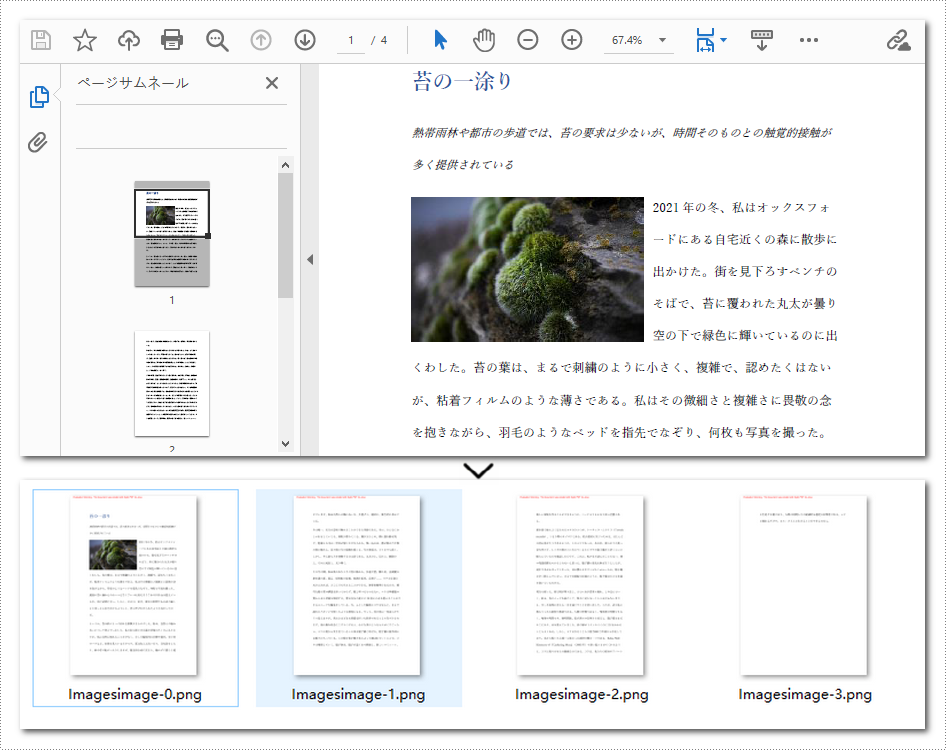
</dependencies>以下は、PDF ドキュメント全体を複数の画像に変換する手順です。
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
public class PDFToImages {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("D:/Sample.pdf");
//全ページをループする
for (int i = 0; i < pdf.getPages().getCount(); i++) {
//全ページを画像に変換し、画像のDpiを設定する
BufferedImage image = pdf.saveAsImage(i, PdfImageType.Bitmap,500,500);
//画像を.pngファイルとして保存する
File file = new File("D:/Images" + String.format(("image-%d.png"), i));
ImageIO.write(image, "PNG", file);
}
pdf.close();
}
}
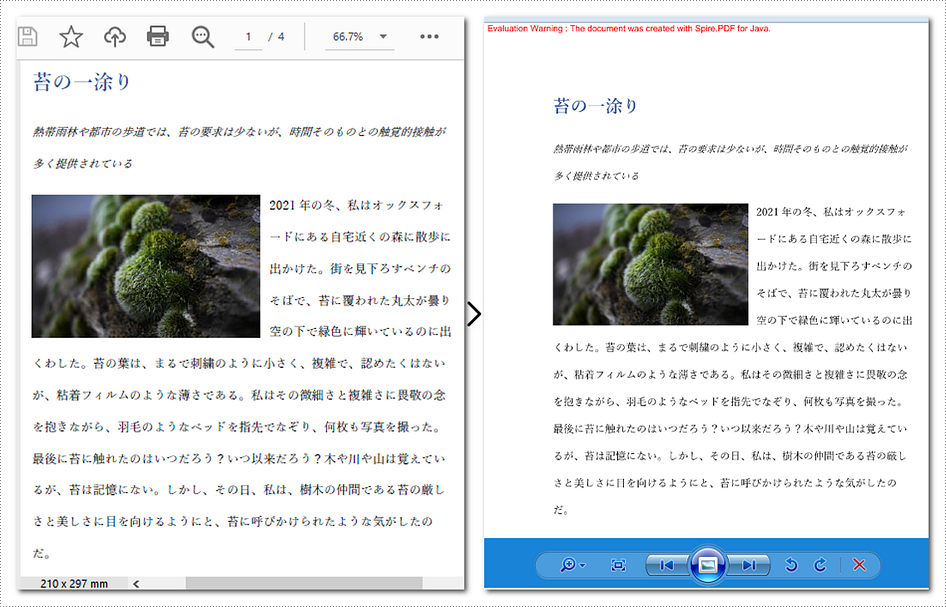
以下の手順は、特定の PDF ページを画像に変換する方法を示しています。
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
public class PDFPageToImage {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/Sample.pdf");
//最初のページを画像に変換し、画像のDpiを設定する
BufferedImage image= pdf.saveAsImage(0, PdfImageType.Bitmap,500,500);
//画像を.pngファイルとして保存する
ImageIO.write(image, "PNG", new File("画像.png"));
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF ファイルの暗号化は、インターネット上で機密ドキュメントを共有する際に非常に重要です。強力なパスワードで PDF ファイルを暗号化することで、ファイルのデータが不正にアクセスされないように保護することができます。また、場合によっては、ドキュメントを公開するために、パスワードを削除する必要があることもあります。この記事では、Spire.PDF for .NET を使用して、プログラムで PDF ファイルを暗号化または復号化する方法について学びます。
まず、Spire.PDF for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPDF ファイルを暗号化するためのパスワードには、「開くパスワード」と「権限パスワード」の2種類があります。前者は PDF ファイルを開くために設定し、後者は印刷や 内容のコピー、コメント付けなどを制限するために設定します。2種類のパスワードで PDF ファイルを保護した場合、どちらかのパスワードで開くことができます。
Spire.PDF for .NET が提供する PdfSecurity.Encrypt(string openPassword, string permissionPassword, PdfPermissionsFlags permissions, PdfEncryptionKeySize keySize) メソッドは、開くパスワードと権限パスワードを設定して、PDF ファイルを暗号化できるようにするものです。詳細な手順は次のとおりです。
using Spire.Pdf;
using Spire.Pdf.Security;
namespace EncryptPDF
{
class Program
{
static void Main(string[] args)
{
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.LoadFromFile(@"C:\Users\YDY_17628305272oEgOG\Desktop\Sample1.pdf");
//パスワードでPDFファイルを暗号化する
pdf.Security.Encrypt("open", "permission", PdfPermissionsFlags.Print | PdfPermissionsFlags.CopyContent, PdfEncryptionKeySize.Key128Bit);
//のファイルを保存する
pdf.SaveToFile("PDFの暗号化.pdf", FileFormat.PDF);
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Security
Namespace EncryptPDF
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocument クラスのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'PDFファイルを読み込む
pdf.LoadFromFile("C:\Users\YDY_17628305272oEgOG\Desktop\Sample1.pdf")
'パスワードでPDFファイルを暗号化する
pdf.Security.Encrypt("open", "permission", PdfPermissionsFlags.Print | PdfPermissionsFlags.CopyContent, PdfEncryptionKeySize.Key128Bit)
'のファイルを保存する
pdf.SaveToFile("PDFの暗号化.pdf", FileFormat.PDF)
End Sub
End Class
End Namespace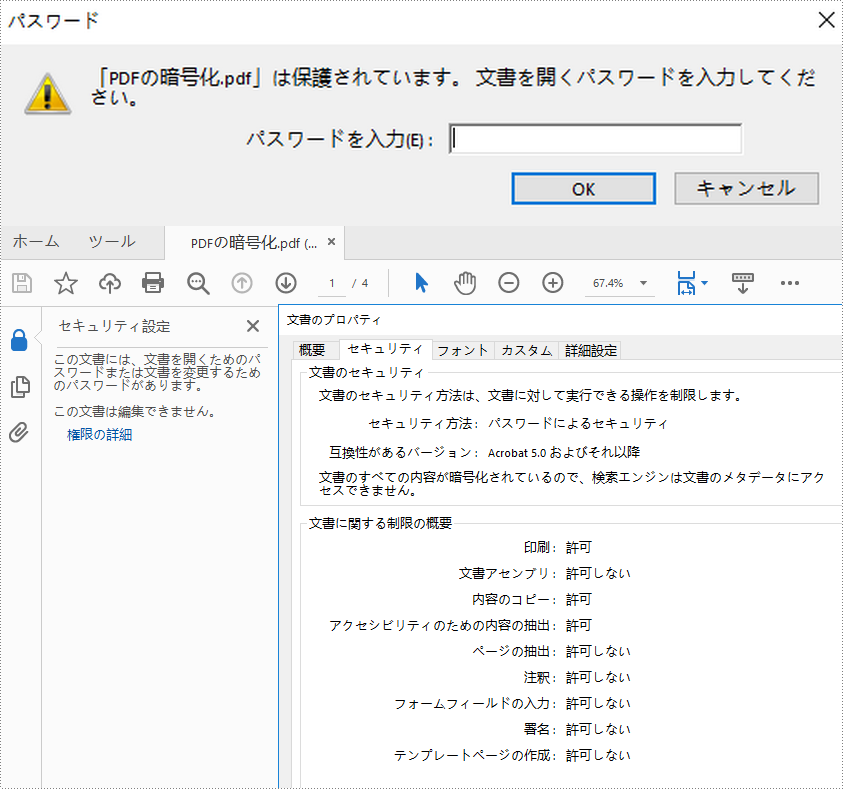
PDF ファイルからパスワードを削除する必要がある場合、PdfSecurity.Encrypt(string openPassword, string permissionPassword, PdfPermissionsFlags permissions, PdfEncryptionKeySize keySize, string originalPermissionPassword) メソッドを呼び出して、開くパスワードと権限パスワードを空に設定することができます。詳細な手順は以下の通りです。
using Spire.Pdf;
using Spire.Pdf.Security;
namespace DecryptPDF
{
class Program
{
static void Main(string[] args)
{
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//パスワードを使って暗号化されたPDFファイルを読み込む
pdf.LoadFromFile(@"C:/PDFの暗号化.pdf", "open");
//パスワードを空に設定し、PDFファイルを復号化する
pdf.Security.Encrypt(string.Empty, string.Empty, PdfPermissionsFlags.Default, PdfEncryptionKeySize.Key128Bit, "permission");
//結果のファイルを保存する
pdf.SaveToFile("PDFの復号化.pdf", FileFormat.PDF);
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Security
Namespace DecryptPDF
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocument クラスのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'パスワードを使って暗号化されたPDFファイルを読み込む
pdf.LoadFromFile("C:/PDFの暗号化.pdf", "open")
'パスワードを空に設定し、PDFファイルを復号化する
pdf.Security.Encrypt(String.Empty, String.Empty, PdfPermissionsFlags.Default, PdfEncryptionKeySize.Key128Bit, "permission")
'結果のファイルを保存する
pdf.SaveToFile("PDFの復号化.pdf", FileFormat.PDF)
End Sub
End Class
End Namespace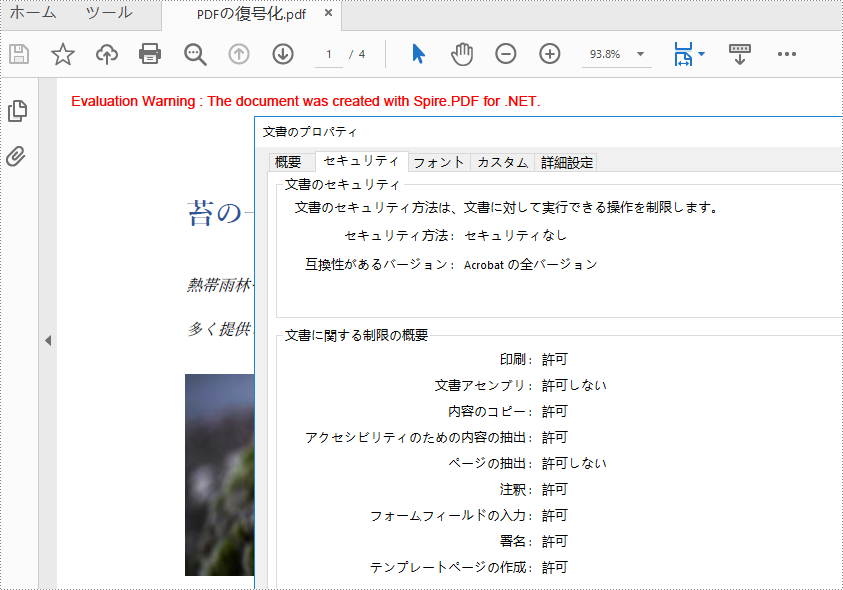
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF 8.9.2 のリリースを発表できることを嬉しく思います。このバージョンでは、添付ファイルと PDF を OFD に変換したり、パンフレットを作成するときにステープル方向を設定したりすることがサポートされています。また、このバージョンでは、PDF から OFD、画像、SVGへの変換機能も強化しました。また、今回の更新、パンフレットを作成する時にページ順序が間違っていたなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5358 | パンフレットを作成する時に、ステープル方向の設定をサポートしました。
float width = PdfPageSize.A4.Width * 2; float height = PdfPageSize.A4.Height; Stream outputstreaml = File.Open(outputFile, FileMode.Create, FileAccess.ReadWrite, FileShare.Read); BookletOptions bookletOptions = new BookletOptions(); bookletOptions.BookletBinding = Spire.Pdf.Utilities.PdfBookletBindingMode.Left; SizeF size = new SizeF(width, height); PdfBookletCreator.CreateBooklet(doc, outputstreaml, size, bookletOptions); |
| New feature | SPIREPDF-5403 | 添付ファイルと PDF を OFD に変換することをサポートしました。 |
| Bug | SPIREPDF-1228 SPIREPDF-5298 |
テキストフィールドが更新された後に、テキストの位置が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5345 | PDF が SVG に変換した後に、テキストの位置ずれの問題が修正されました。 |
| Bug | SPIREPDF-5407 | PDF の画像変換に失敗した問題が修正されました。 |
| Bug | SPIREPDF-5408 | パンフレットを作成する時にページ順序が間違っていた問題が修正されました。 |
| Bug | SPIREPDF-5413 | PDF が OFD に変換されて開かなくなった問題が修正されました。 |
| Bug | SPIREPDF-5431 | 抽出テーブルの内容が重複していた問題が修正されました。 |
| Bug | SPIREPDF-5442 | PDF を SVG に変換した後に、フォントスタイルが失われる問題が修正されました。 |
| Bug | SPIREPDF-5454 | PDF をロードするときに、アプリケーションが一時停止していた問題が修正されました。 |
ブックマークは、特にページ数の多い PDF ドキュメントに役立つ機能です。しおりをクリックすることで、読者はドキュメントの対応する場所にすばやくジャンプすることができます。整理された一連のしおりは、目次としても使用することができます。この記事では、Spire.PDF for .NET を使用して PDF ドキュメントからブックマークを取得する方法について説明します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDF詳細な手順は以下の通りです。
using System;
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Bookmarks;
namespace GetBookmark
{
internal class Program
{
static void Main(string[] args)
{
// PdfDocumentクラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
// PDFドキュメントを読み込む
pdf.LoadFromFile(@"C:\例.pdf");
// PDF ドキュメント内のブックマーク集を取得する
PdfBookmarkCollection bookmarks = pdf.Bookmarks;
//ブックマークを取得し、TXTファイルに保存する
String result = "ブックマークの取得.txt";
GetBookmarks(bookmarks, result);
}
public static void GetBookmarks(PdfBookmarkCollection bookmarks, string result)
{
// StringBuilder クラスのオブジェクトを作成する
StringBuilder content = new StringBuilder();
// PDFブックマークの情報を取得する
if (bookmarks.Count > 0)
{
content.AppendLine("PDFブックマーク:");
foreach (PdfBookmark parentBookmark in bookmarks)
{
//タイトルを取得する
content.AppendLine(parentBookmark.Title);
//テキストのスタイルを取得する
string textStyle = parentBookmark.DisplayStyle.ToString();
content.AppendLine(textStyle);
GetChildBookmark(parentBookmark, content);
}
}
// TXTファイルに保存する
File.WriteAllText(result, content.ToString());
}
public static void GetChildBookmark(PdfBookmark parentBookmark, StringBuilder content)
{
if (parentBookmark.Count > 0)
{
foreach (PdfBookmark childBookmark in parentBookmark)
{
//タイトルを取得する
content.AppendLine(childBookmark.Title);
//テキストのスタイルを取得する
string textStyle = childBookmark.DisplayStyle.ToString();
content.AppendLine(textStyle);
GetChildBookmark(childBookmark, content);
}
}
}
}
}Imports System
Imports System.IO
Imports System.Text
Imports Spire.Pdf
Imports Spire.Pdf.Bookmarks
Namespace GetBookmark
Friend Class Program
Shared Sub Main(ByVal args() As String)
' PdfDocumentクラスのインスタンスを作成する
Dim pdf As PdfDocument = New PdfDocument()
' PDFドキュメントを読み込む
pdf.LoadFromFile("C:\例.pdf")
' PDF ドキュメント内のブックマーク集を取得する
Dim bookmarks As PdfBookmarkCollection = pdf.Bookmarks
'ブックマークを取得し、TXTファイルに保存する
Dim result As String = "ブックマークの取得.txt"
GetBookmarks(bookmarks, result)
End Sub
Public Shared Sub GetBookmarks(ByVal bookmarks As PdfBookmarkCollection, ByVal result As String)
' StringBuilder クラスのオブジェクトを作成する
Dim content As StringBuilder = New StringBuilder()
' PDFブックマークの情報を取得する
If bookmarks.Count > 0 Then
content.AppendLine("PDFブックマーク:")
Dim parentBookmark As PdfBookmark
For Each parentBookmark In bookmarks
'タイトルを取得する
content.AppendLine(parentBookmark.Title)
'テキストのスタイルを取得する
Dim textStyle As String = parentBookmark.DisplayStyle.ToString()
content.AppendLine(textStyle)
GetChildBookmark(parentBookmark, content)
Next
End If
' TXTファイルに保存する
File.WriteAllText(result, content.ToString())
End Sub
Public Shared Sub GetChildBookmark(ByVal parentBookmark As PdfBookmark, ByVal content As StringBuilder)
If parentBookmark.Count > 0 Then
Dim childBookmark As PdfBookmark
For Each childBookmark In parentBookmark
'タイトルを取得する
content.AppendLine(childBookmark.Title)
'テキストのスタイルを取得する
Dim textStyle As String = childBookmark.DisplayStyle.ToString()
content.AppendLine(textStyle)
GetChildBookmark(childBookmark, content)
Next
End If
End Sub
End Class
End Namespace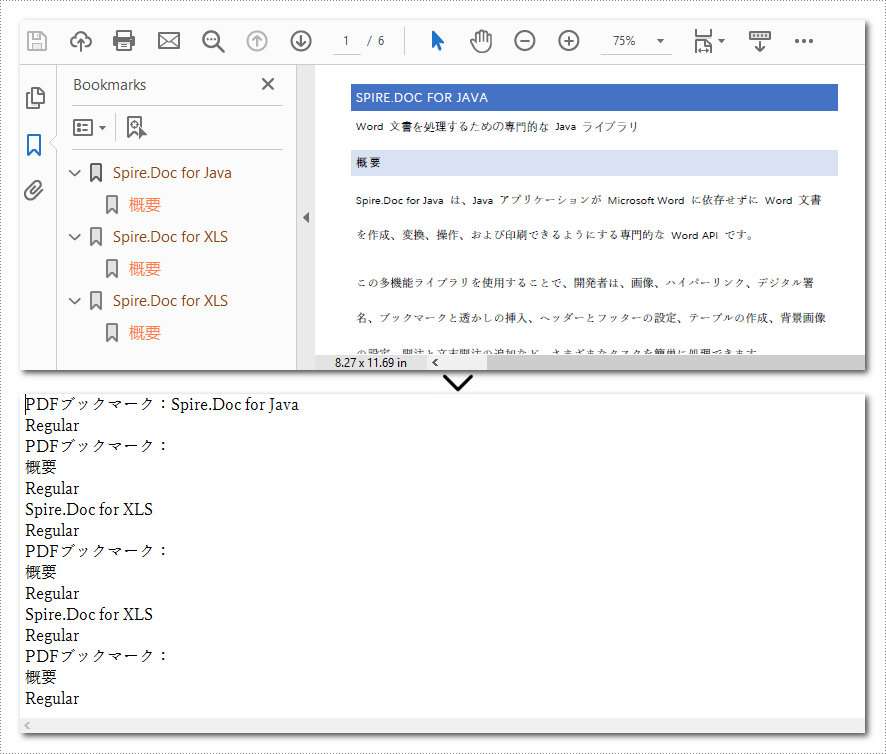
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Excel テーブルを作成して Web ページに公開する場合、最も簡単な方法は HTML ファイルに変換することです。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET でプログラムによって Excel を HTML に変換する方法を紹介します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSSpire.XLS for .NET は、Worksheet.SaveToHtml() メソッドを使用して特定の Excel ワークシートを HTML に変換することをサポートしています。以下に詳細な手順を示します。
using Spire.Xls;
namespace XLSToHTML
{
class Program
{
static void Main(string[] args)
{
//Workbookインスタンスを作成する
Workbook workbook = new Workbook();
//Excelサンプルドキュメントをロードする
workbook.LoadFromFile(@"sample.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//ワークシートをHTMLファイルとして保存する
sheet.SaveToHtml("ExcelToHTML.html");
}
}
}Imports Spire.Xls
Namespace Xls2Html
Class Program
Private Shared Sub Main(args As String())
'Workbookインスタンスを作成する
Dim workbook As New Workbook()
'Excelサンプルドキュメントをロードする
workbook.LoadFromFile("sample.xlsx")
'最初のワークシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'ワークシートをHTMLファイルとして保存する
sheet.SaveToHtml("XLSToHTML.html")
End Sub
End Class
End Namespace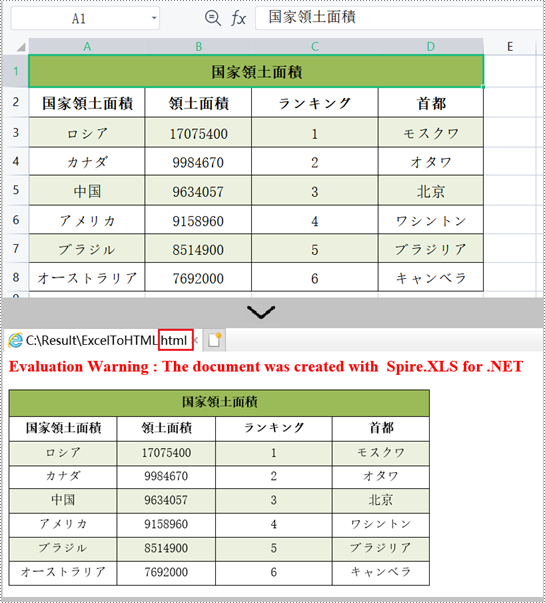
Excel ワークシートを埋め込み画像の HTML に変換する手順を次に示します。
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet;
namespace XLSToHTML
{
class Program
{
static void Main(string[] args)
{
//Workbookインスタンスを作成する
Workbook workbook = new Workbook();
//Excelサンプルドキュメントをロードする
workbook.LoadFromFile(@"sample.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//HTMLOptionsインスタンスを作成する
HTMLOptions options = new HTMLOptions();
//画像をHTMLに埋め込む
options.ImageEmbedded = true;
//ワークシートをHTMLファイルとして保存する
sheet.SaveToHtml("XLS2HTML.html");
}
}
}Imports Spire.Xls
Imports Spire.Xls.Core.Spreadsheet
Namespace Xls2Html
Class Program
Private Shared Sub Main(args As String())
'Workbookインスタンスを作成する
Dim workbook As New Workbook()
'Excelサンプルドキュメントをロードする
workbook.LoadFromFile("sample.xlsx")
'最初のワークシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'HTMLOptionsインスタンスを作成する
Dim options As New HTMLOptions()
'画像をHTMLに埋め込む
options.ImageEmbedded = True
'ワークシートをHTMLファイルとして保存する
sheet.SaveToHtml("Xls2HTML.html")
End Sub
End Class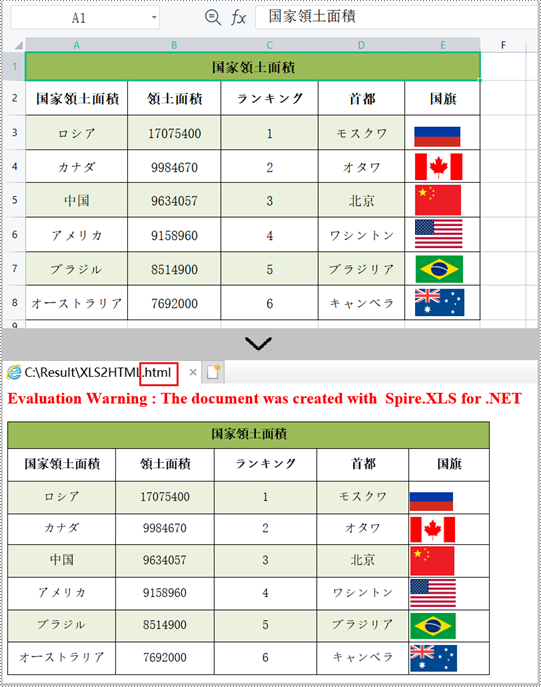
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office 7.9.0 のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.Doc は Word から PDF への変換機能を強化しました。Spire.SpreadSheet は Worksheet.Resize メソッドが無効であった問題を修正しました。さらに、このバージョンでは、多くの既知の問題も修正しました。詳細は以下の内容を読んでください。
このバージョンでは、Spire.Doc,Spire.PDF,Spire.XLS,Spire.Email,Spire.DocViewer, Spire.PDFViewer,Spire.Presentation,Spire.Spreadsheet, Spire.OfficeViewer, Spire.DocViewer, Spire.Barcode, Spire.DataExport の最新バージョンが含まれています。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7351 SPIREDOC-7356 |
Word が PDF に変換した後に、画像がぼやけてしまった問題が修正されました。 |
| Bug | SPIREDOC-7362 SPIREDOC-7597 SPIREDOC-8356 |
Word が PDF に変換した後に、テキスト改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7579 | Word が PDFA1Aに変換した後に、ページ番号部分が黒くなる問題が修正されました。 |
| Bug | SPIREDOC-7606 | Word が PDF に変換した後に、空白のボックスが多くなる問題が修正されました。 |
| Bug | SPIREDOC-7623 | Word が PDF に変換した後に、フォーマットが一致しない問題が修正されました。 |
| Bug | SPIREDOC-7767 | Word が PDF に変換した後に、テーブルレイアウトが間違っていた問題が修正されました。 |
| Bug | SPIREDOC-7787 | セクションのクローニング時に空のポインタがスローされた問題が修正されました。 |
| Bug | SPIREDOC-8019 | 新しいエンジンを使って Word を PD Fに変換した後の段落間隔が一致しない問題が修正されました。 |
| Bug | SPIREDOC-8107 | RTF ファイルをロードするときに、アプリケーションが「System.ArgumentNullException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8124 SPIREDOC-8202 SPIREDOC-8244 SPIREDOC-8287 |
統計的な文字、単語の数が Microsoft Word の結果と一致しない問題が修正されました。 |
| Bug | SPIREDOC-8177 | 横向きのページを PDF に変換した後、フッターの書式が間違っていた問題が修正されました。 |
| Bug | SPIREDOC-8186 | テーブル内のブックマークを削除した後にドキュメントが開かなくなった問題が修正されました。 |
| Bug | SPIREDOC-8252 | WordがPDFに変換した後に、表の書式設定が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8279 | Wordドキュメントを印刷した後にページ右側のコンテンツが失われていた問題が修正されました。 |
| Bug | SPIREDOC-8288 | 統計文字時にアプリケーションが空のポインタをスローする異常が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPREADSHEET-204 | Worksheet.Resize メソッドが無効であった問題を修正しました。 |
Spire.Doc 10.9.1 のリリースを発表できることを嬉しく思います。このバージョンでは、Word から PDF と PDFA1Aへの変換機能を強化しました。また、今回の更新では、統計的な文字、単語の数が Microsoft Word の結果と一致しないなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7351 SPIREDOC-7356 |
Word が PDF に変換した後に、画像がぼやけてしまった問題が修正されました。 |
| Bug | SPIREDOC-7362 SPIREDOC-7597 SPIREDOC-8356 |
Word が PDF に変換した後に、テキスト改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-7579 | Word が PDFA1Aに変換した後に、ページ番号部分が黒くなる問題が修正されました。 |
| Bug | SPIREDOC-7606 | Word が PDF に変換した後に、空白のボックスが多くなる問題が修正されました。 |
| Bug | SPIREDOC-7623 | Word が PDF に変換した後に、フォーマットが一致しない問題が修正されました。 |
| Bug | SPIREDOC-7767 | Word が PDF に変換した後に、テーブルレイアウトが間違っていた問題が修正されました。 |
| Bug | SPIREDOC-7787 | セクションのクローニング時に空のポインタがスローされた問題が修正されました。 |
| Bug | SPIREDOC-8019 | 新しいエンジンを使って Word を PD Fに変換した後の段落間隔が一致しない問題が修正されました。 |
| Bug | SPIREDOC-8107 | RTF ファイルをロードするときに、アプリケーションが「System.ArgumentNullException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8124 SPIREDOC-8202 SPIREDOC-8244 SPIREDOC-8287 |
統計的な文字、単語の数が Microsoft Word の結果と一致しない問題が修正されました。 |
| Bug | SPIREDOC-8177 | 横向きのページを PDF に変換した後、フッターの書式が間違っていた問題が修正されました。 |
| Bug | SPIREDOC-8186 | テーブル内のブックマークを削除した後にドキュメントが開かなくなった問題が修正されました。 |
| Bug | SPIREDOC-8252 | WordがPDFに変換した後に、表の書式設定が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8279 | Wordドキュメントを印刷した後にページ右側のコンテンツが失われていた問題が修正されました。 |
| Bug | SPIREDOC-8288 | 統計文字時にアプリケーションが空のポインタをスローする異常が修正されました。 |
Word ドキュメントを操作する過程で、重要な情報を他人に知られたくない場合があります。このため、それらを隠して機密性を確保することができます。この記事では、Spire.Doc for Java を使って Word ドキュメント内の特定の段落を非表示にする方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Spire.Doc for Java では、TextRange.getCharacterFormat().setHidden(boolean value) メソッドを使用して、Word の特定の段落を非表示にすることができます。以下は、その詳細な手順です。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
public class hideParagraph {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("C:/例.docx");
//Wordドキュメント内の特定のセクションを取得する
Section sec = document.getSections().get(0);
//セクションの特定の段落を取得する
Paragraph para = sec.getParagraphs().get(1);
//子オブジェクトをループする
for (Object docObj : para.getChildObjects()) {
DocumentObject obj = (DocumentObject)docObj;
//子オブジェクトが TextRange クラスのインスタンスであるかどうかを判定する
if ((obj instanceof TextRange)) {
TextRange range = ((TextRange)(obj));
//テキスト範囲を非表示にする
range.getCharacterFormat().setHidden(true);
}
}
//ドキュメントを保存する
document.saveToFile("段落の非表示.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
箇条書きリストとは、先頭に点があり、各項目のインデントが同じであるリストで、番号付きリストとは、先頭に数字があるリストのことです。箇条書きリストや番号付きリストは、よく整理されたリストであれば、読者は各項目の構成やポイントを容易に把握できるため、長いテキスト内容よりもはるかに効果的です。この記事では、Spire.Doc for Java を使って、Word ドキュメント内の既存のテキストからリストを作成する方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Spire.Doc for Java では、ListFormat.applyBulletStyle() とListFormat.applyNumberedStyle() という、箇条書きと番号付きのリストを作成するためのメソッドが用意されています。
箇条書きと番号付きリストの詳しい作成手順は、以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.formatting.ListFormat;
public class createLists {
public static void main(String[] args) {
//Document クラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("C:/例.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//4番目から6番目までの段落をループする
for(int i = 3; i <= 5; i++){
Paragraph para = section.getParagraphs().get(i);
ListFormat listFormat = para.getListFormat();
//箇条書きのスタイルを適用する
listFormat.applyBulletStyle();
//リストの位置を設定する
listFormat.getCurrentListLevel().setNumberPosition(-10);
}
//10番目から12番目までの段落をループさせる
for(int i = 9; i <= 11; i++){
Paragraph para = section.getParagraphs().get(i);
ListFormat listFormat = para.getListFormat();
//番号付きリストのスタイルを適用する
listFormat.applyNumberedStyle();
//リストの位置を設定する
listFormat.getCurrentListLevel().setNumberPosition(-10);
}
//ドキュメントを保存する
document.saveToFile("リストの作成.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
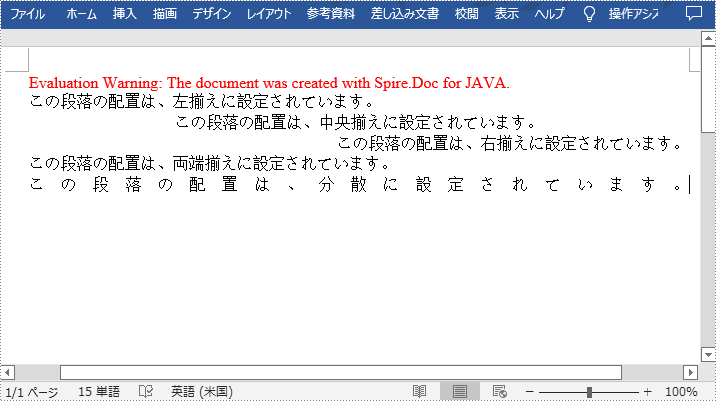
Microsoft Word では、段落のテキスト配置を左・中央・右・両端揃え・分散に設定することができます。この記事では、Spire.Doc for Java を使用して段落の配置を設定する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Spire.Doc for Java では、段落書式を扱うために ParagraphFormat クラスが用意されています。Paragraph.getFormat() メソッドを使用して ParagraphFormat クラスのオブジェクトを取得し、ParagraphFormat.setHorizontalAlignment() メソッドを使用して段落のテキスト配置を設定することができます。
Word ドキュメントで段落のテキスト配置を設定する手順は次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.HorizontalAlignment;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.formatting.ParagraphFormat;
public class setParagraphAlignment {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document document = new Document();
//セクションを追加する
Section section = document.addSection();
//段落を追加し、左揃えに設定する
Paragraph para = section.addParagraph();
para.appendText("この段落の配置は、左揃えに設定されています。");
ParagraphFormat format = para.getFormat();
format.setHorizontalAlignment(HorizontalAlignment.Left);
//段落を追加し、中央揃えに設定する
para = section.addParagraph();
para.appendText("この段落の配置は、中央揃えに設定されています。");
format = para.getFormat();
format.setHorizontalAlignment(HorizontalAlignment.Center);
//段落を追加し、右揃えに設定する
para = section.addParagraph();
para.appendText("この段落の配置は、右揃えに設定されています。");
format = para.getFormat();
format.setHorizontalAlignment(HorizontalAlignment.Right);
//段落を追加し、両端揃えに設定する
para = section.addParagraph();
para.appendText("この段落の配置は、両端揃えに設定されています。");
format = para.getFormat();
format.setHorizontalAlignment(HorizontalAlignment.Justify);
//段落を追加し、分散に設定する。
para = section.addParagraph();
para.appendText("この段落の配置は、分散に設定されています。");
format = para.getFormat();
format.setHorizontalAlignment(HorizontalAlignment.Distribute);
//ドキュメントを保存する
document.saveToFile("段落の配置.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





