チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.XLS for Java 12.7.0 のリリースを発表できることを嬉しく思います。このリリースでは、グラフシリーズのマークにカスタムピクチャを埋めることをサポートしました。さらに、UOS形式のドキュメントのロードと保存をサポートしました。 また、透視表のデータの更新が正しくないなどの既知の問題が修正しました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-3948 | グラフシリーズのマークにカスタムピクチャを埋めることをサポートしました。
IShapeFill markerFill = chart.getSeries().get(0).getDataFormat().getMarkerFill();
markerFill.customPicture("pic.png");
markerFill.setTexture(...);
markerFill.SetPattern(...);
//If use pattern filling, foreground color and backgroud color are needed.
markerFill.setForeColor(...);
markerFill.setBackColor(...);
|
| New feature | - | UOS形式のドキュメントのロードと保存をサポートしました。
Workbook workbook = new Workbook();
workbook.loadFromFile("input.uos");
workbook.saveToFile("output.uos", FileFormat.UOS);
|
| Bug | SPIREXLS-3891 | 多様な文化名前、地域へのサポートを最適化しました。 |
| Bug | SPIREXLS-3899 | 透視表のデータの更新が正しくない問題が修正されました。 |
| Bug | SPIREXLS-3925 | グラフを画像に変換した後、スタイルが正しくない問題を修正しました。 |
| Bug | SPIREXLS-3930 | グラフの傾向線の方程式の読み取りが正しくない問題を修正しました。 |
| Bug | SPIREXLS-3931 | 文書が暗号化されているかどうかの判定エラーの問題を修正しました。 |
| Bug | SPIREXLS-3938 | HTML を Excel に変換した後、画像の位置が上がる問題を修正しました。 |
| Bug | SPIREXLS-3939 | Excel を PDF に変換した後、チェック ボックス コントロールの後にテキストが失われる問題を修正しました。 |
Spire.Doc for Java 10.7.4 のリリースを発表できることを嬉しく思います。このリリースでは、Word ファイルを比較するときに、比較レベルの設定をサポートしました。 さらに、このリリースでは、Word から PDF および画像への変換機能を強化しました。 そして、2 つの Word ファイルをマージした後のコンテンツが正しくないなどの既知の問題が修正しました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | Wordファイルを比較するときに、比較レベルの設定をサポートしました。
Document doc1 = new Document();
doc1.loadFromFile("input1.docx");
Document doc2 = new Document();
doc2.loadFromFile("input2.docx");
doc1.compare(doc2,"user");
//setting comparison level
CompareOptions options = new CompareOptions();
options.setLevel(ComparisonLevel.Character);
doc1.saveToFile("result.docx", FileFormat.Docx_2013);
|
| Bug | SPIREDOC-7530 | 2 つの Word ファイルをマージした後、コンテンツが正しくない問題を修正しました。 |
| Bug | SPIREDOC-7625 | 2 つの Word ファイルを比較した後、結果が正しくない問題を修正しました。 |
| Bug | SPIREDOC-7674 | WordファイルをPDFに変換した後、画像の位置が正しくない問題を修正しました。 |
| Bug | SPIREDOC-7776 | Word ファイルを画像に変換した後、コンテンツが正しくない問題を修正しました。 |
| Bug | SPIREDOC-7799 SPIREDOC-7818 SPIREDOC-7890 SPIREDOC-7891 |
Word ファイルを PDF に変換した後、コンテンツの位置が変更される問題を修正しました。 |
| Bug | SPIREDOC-7818 SPIREDOC-7971 |
取得文字数が正しくない問題を修正しました。 |
| Bug | SPIREDOC-7840 | 注釈を添加した後、保存された doc 形式のファイルが正しくない問題を修正しました。 |
| Bug | SPIREDOC-7891 | Word ファイルを PDF に変換した後、テキストコンテンツの一部が失われる問題を修正しました。 |
| Bug | SPIREDOC-7921 | Word ファイルを PDF に変換した後、コンテンツが正しくない問題を修正しました。 |
| Bug | SPIREDOC-7940 | Word ファイルを PDF に変換した後、改行位置が変更された問題が修正されました。 |
| Bug | SPIREDOC-7953 | 改訂を受け入れ、注釈を消去するときにアプリケーションが 「IndexOutOfBoundsException」をスローする問題を修正しました。 |
| Bug | SPIREDOC-7970 | HTML を添加するときに、アプリケーションが 「The local name for elements or attributes cannot be null or an empty string」 をスローする問題を修正しました。 |
| Bug | SPIREDOC-7983 | WordファイルをPDFに変換するときに、アプリケーションが「IllegalStateException」をスローする問題を修正しました。 |
| Bug | SPIREDOC-8003 | ウイルス スキャン ツールを使用して検出中にエラーが発生する問題を修正します。 |
| Bug | SPIREDOC-8077 | jdk 11、jdk 17などの高いJDKバージョンで使用したときに、アプリケーションが「WindowsPreferences.WindowsRegOpenKey(int,[B,int)」をスローする問題を修正しました。 |
Spire.Doc 10.7 のリリースを発表できることを嬉しく思います。このバージョンは、NewEngine を使用して Word を PDF に変換するときに、テキストの方向を保持しました。また、public IStyle FindById(int styleId)メソッドと public IStyle FindByIstd(int istd) メソッドを放棄して、public IStyle FindByIdentifier (int sIdentifier) メソッドを公開しました。さらに、Word を PDF に変換するときにページングが正しくないなどの既知の問題が修正しました。 詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | NewEngine を使用して Word を PDF に変換するときに、テキストの方向を保持しました。 |
| Adjustment | - | public IStyle FindById(int styleId) メソッドを放棄しました。 |
| Adjustment | - | public IStyle FindByIstd(int istd) メソッドを放棄しました。 |
| Adjustment | - | public IStyle FindByIdentifier(int sIdentifier) メソッドを公開しました。 |
| Bug | SPIREPDF-6923 | Word を PDF に変換し、改ページが正しくない問題を修正しました。 |
| Bug | SPIREPDF-7103 SPIREPDF-7796 |
Word を PDF に変換し、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREPDF-7591 | Word を PDF に変換し、改行が正しくない問題が修正されました。 |
| Bug | SPIREPDF-7601 | Word を PDF に変換し、表形式のテキストが不完全に表示される問題を修正しました。 |
| Bug | SPIREPDF-7660 | HTML をロードするときに、アプリケーションが「InvalidOperationException」 をスローする問題を修正しました。 |
| Bug | SPIREPDF-7793 | 画像を置換するときに、アプリケーションが「InvalidCastException」をスローする問題を修正しました。 |
| Bug | SPIREPDF-7821 | HTML をロードするときに、アプリケーションが「FileNotFoundException」 をスローする問題を修正しました。 |
| Bug | SPIREPDF-7826 | ドメイン値が正しく設定されていない問題を修正しました。 |
| Bug | SPIREPDF-7830 | Word を PDF に変換するときに、数式のずれの問題を修正しました。 |
| Bug | SPIREPDF-7892 | 新しいエンジン方式で Word を PDF に変換する際に、ヘッダーフッターを設定する連続していないと有効にならない問題を修正しました。 |
| Bug | SPIREPDF-7922 | Word から PDF への変換するときに、アプリケーションが「InvalidOperationException」をスローする問題を修正しました。 |
| Bug | - | Comment.CommentMarkEnd と Comment.CommentMarkStart の参照の問題を修正しました。 |
Spire.PDF 8.7.2 のリリースを発表できることを嬉しく思います。このバージョンは、ストリームからOFDファイルのロードをサポートしました。さらに、PDF から画像へ、PDF から OFD へおよび XPS から PDF への変換機能を強化しました。その他、印刷後にバーコードをスキャンできないなどの既知の問題を修正しました。詳細は次の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5166 | WPFアセンブリの印刷設定をサポートするインターフェイスを追加しました。
PdfDocument.Print(PdfPrintSettings printSettings) |
| New feature | SPIREPDF-5241 | ストリームからofdファイルのロードをサポートします。
Stream stream = File.OpenRead(inputFile); OfdConverter converter = new OfdConverter(stream); MemoryStream ms = new MemoryStream(); converter.ToPdf(ms); |
| Bug | SPIREPDF-704 | PDFから変換されたPdfX1A2001が仕様に準拠していなかった問題を修正しました。 |
| Bug | SPIREPDF-715 | アプリケーションが「オブジェクト参照がオブジェクトのインスタンスに設定されていません」という例外をスローした問題を修正しました。 |
| Bug | SPIREPDF-737 SPIREPDF-5096 |
PDFを画像に変換した後にバーコードがぼやける原因となっていた問題を修正しました。 |
| Bug | SPIREPDF-779 | XPSをPDFに変換した後にコンテンツが失われる問題を修正しました。 |
| Bug | SPIREPDF-1397 | 印刷時の時間を最適化しました。 |
| Bug | SPIREPDF-1443 | 印刷後にバーコードをスキャンできない問題を修正しました。 |
| Bug | SPIREPDF-4884 | クロスラインテキストが見つからなかった問題を修正しました。 |
| Bug | SPIREPDF-5204 | PDFを画像に変換した後に誤ったバーコードが発生する問題を修正しました。 |
| Bug | SPIREPDF-5226 | PDFをOFDに変換するときにアプリケーションが「NullReferenceException」をスローする問題を修正しました。 |
| Bug | SPIREPDF-5228 | PDFレイヤーを画像に変換した後に出力が正しくない問題を修正しました。 |
| Bug | SPIREPDF-5238 | ドキュメントの印刷後にページ番号が失われる問題を修正しました。 |
| Bug | SPIREPDF-5249 | PDFをOFDに変換するときに、非表示のコンテンツを変換できなかった問題を修正しました。 |
| Bug | SPIREPDF-5255 | PDFドキュメントをマージするときにアプリケーションが「NullReferenceException」をスローする問題を修正しました。 |
| Bug | SPIREPDF-5264 | PDFを画像に変換するときにアプリケーションが「ArgumentNullException」をスローする問題を修正しました。 |
| Bug | SPIREPDF-5273 | PDFを圧縮するときにアプリケーションが「IndexOutOfRangeException」をスローする問題を修正しました。 |
| Bug | SPIREPDF-5285 | PDFを画像に変換した後にコンテンツが失われる問題を修正しました。 |
| Bug | SPIREPDF-5039 | PDFからパスワードで保存されたストリームをロードするときに、アプリケーションが「暗号化されたドキュメントを開くことができません。パスワードが無効です」とスローする問題を修正しました。 |
PDF は用途の広いファイル形式ですが、それを編集するのが困難です。PDF データを変更および計算する場合は、PDF を Excel に変換するのがよっぽど理想的です。この記事では、Spire.PDF for .NET を使用して C# および VB.NET で PDF を Excel に変換する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPDF ドキュメントを Excel に変換する手順は次のとおりです。
using Spire.Pdf;
using Spire.Pdf.Conversion;
namespace ConvertPdfToExcel
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentクラスのインスタンスを初期化する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントをロードする
pdf.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.pdf");
//PDFドキュメントをXLSXに保存する
pdf.SaveToFile("PdfToExcel.xlsx", FileFormat.XLSX);
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Conversion
Namespace ConvertPdfToExcel
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentクラスのインスタンスを初期化する
Dim pdf As PdfDocument = New PdfDocument()
'PDFドキュメントをロードする
pdf.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.pdf")
'PDFドキュメントをXLSXに保存する
pdf.SaveToFile("PdfToExcel.xlsx", FileFormat.XLSX)
End Sub
End Class
End Namespace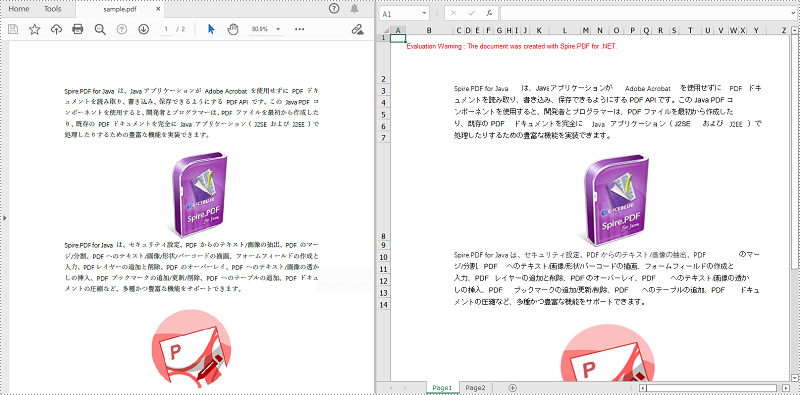
複数ページの PDF を1つの Excel ワークシートに変換する手順は次のとおりです。
using Spire.Pdf;
using Spire.Pdf.Conversion;
namespace ConvertPdfToExcel
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentクラスのインスタンスを初期化する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントをロードする
pdf.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.pdf");
//クラスコンストラクターでXlsxLineLayoutOptionsクラスのインスタンスを初期化し、最初のパラメーターであるconvertToMultipleSheetをfalseに設定する
//4つのパラメーターは、convertToMultipleSheet、showRotatedText、splitCell、wrapTextを表す
XlsxLineLayoutOptions options = new XlsxLineLayoutOptions(false, true, true, true);
//PDFをXLSX変換オプションに設定する
pdf.ConvertOptions.SetPdfToXlsxOptions(options);
//PDFドキュメントをXLSXに保存する
pdf.SaveToFile("PdfToOneExcelSheet.xlsx", FileFormat.XLSX);
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Conversion
Namespace ConvertPdfToExcel
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentクラスのインスタンスを初期化する
Dim pdf As PdfDocument = New PdfDocument()
'PDFドキュメントをロードする
pdf.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.pdf")
'クラスコンストラクターでXlsxLineLayoutOptionsクラスのインスタンスを初期化し、最初のパラメーターであるconvertToMultipleSheetをfalseに設定する
'4つのパラメーターは、convertToMultipleSheet、showRotatedText、splitCell、wrapTextを表す
Dim options As XlsxLineLayoutOptions = New XlsxLineLayoutOptions(False,True,True,True)
'PDFをXLSX変換オプションに設定する
pdf.ConvertOptions.SetPdfToXlsxOptions(options)
'PDFドキュメントをXLSXに保存する
pdf.SaveToFile("PdfToOneExcelSheet.xlsx", FileFormat.XLSX)
End Sub
End Class
End Namespace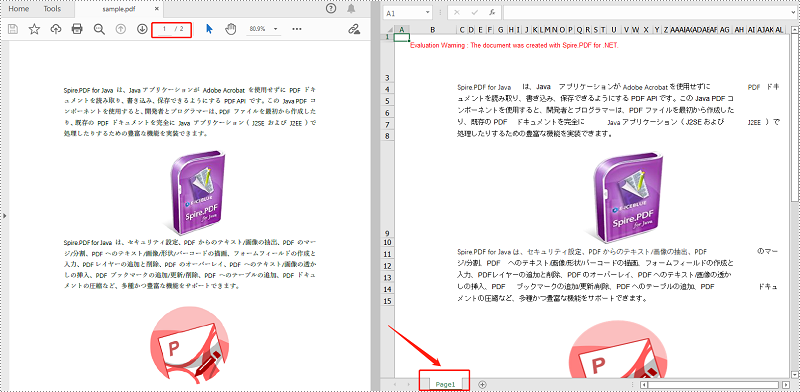
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
場合によって、1つの PDF をいくつかのより小さな PDF に分割すると便利です。たとえば、大規模な契約書、レポート、書籍、学術論文、またはその他のドキュメントを小さな部分に分割して、レビューや再利用を容易にすることができます。この記事では、PDF を単一ページの PDF に分割する方法と、Spire.PDF for .NET を使用して C# および VB.NET で PDF をページ範囲ごとに分割する方法を学習します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF は、複数ページの PDF ドキュメントを複数の単一ページファイルに分割する Split() メソッドを提供します。詳細な手順は次のとおりです。
using System;
using Spire.Pdf;
namespace SplitPDFIntoIndividualPages
{
class Program
{
static void Main(string[] args)
{
//入力ファイルのパスを指定する
String inputFile = "C:\\Users\\Administrator\\Desktop\\License.pdf";
//出力ディレクトリを指定する
String outputDirectory = "C:\\Users\\Administrator\\Desktop\\Output\\";
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルをロードする
doc.LoadFromFile(inputFile);
//PDFを1ページのPDFに分割する
doc.Split(outputDirectory + "output-{0}.pdf", 1);
}
}
}Imports System
Imports Spire.Pdf
Namespace SplitPDFIntoIndividualPages
Class Program
Shared Sub Main(ByVal args() As String)
'入力ファイルのパスを指定する
Dim inputFile As String = "C:\\Users\\Administrator\\Desktop\\License.pdf"
'出力ディレクトリを指定する
Dim outputDirectory As String = "C:\\Users\\Administrator\\Desktop\\Output\\"
'PdfDocumentオブジェクトを作成する
Dim doc As PdfDocument = New PdfDocument()
'PDFファイルをロードする
doc.LoadFromFile(inputFile)
'PDFを1ページのPDFに分割する
doc.Split(outputDirectory + "output-{0}.pdf", 1)
End Sub
End Class
End Namespace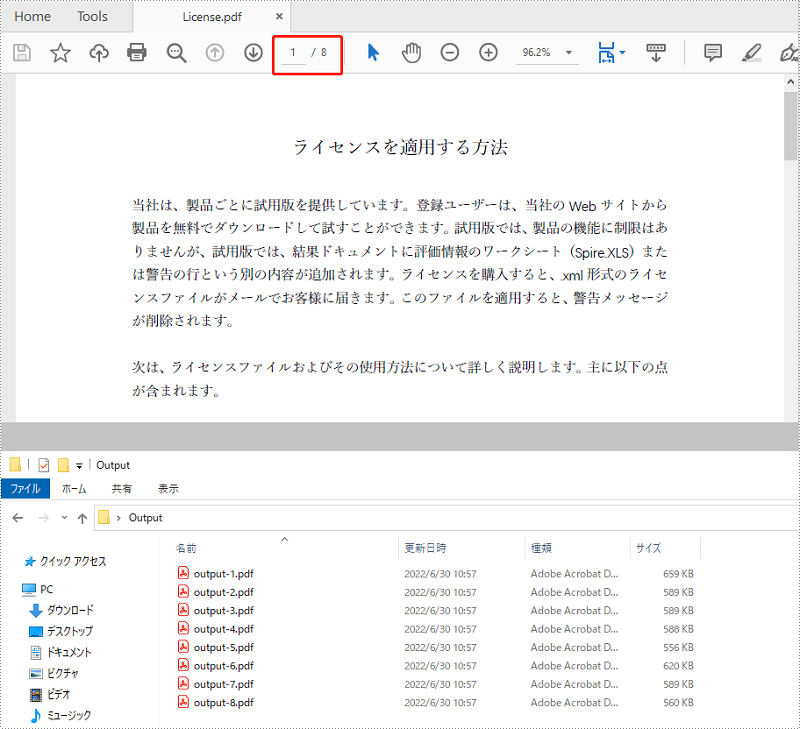
PDF ドキュメントをページ範囲で分割するための簡単な方法は提供されていません。 そのために、2つ以上の新しい PDF ドキュメントを作成し、ソースドキュメントからそれらにページまたはページ範囲をインポートします。詳細な手順は次のとおりです。
using Spire.Pdf;
using System;
namespace SplitPdfByPageRanges
{
class Program
{
static void Main(string[] args)
{
//入力ファイルのパスを指定する
String inputFile = "C:\\Users\\Administrator\\Desktop\\License.pdf";
//出力ディレクトリを指定する
String outputDirectory = "C:\\Users\\Administrator\\Desktop\\Output\\";
//PdfDocumentオブジェクトの初期化中にソースPDFファイルをロードする
PdfDocument sourceDoc = new PdfDocument(inputFile);
//2つの追加のPdfDocumentオブジェクトを作成する
PdfDocument newDoc_1 = new PdfDocument();
PdfDocument newDoc_2 = new PdfDocument();
//ソースファイルの最初のページを最初のドキュメントに挿入する
newDoc_1.InsertPage(sourceDoc, 0);
//ソースファイルの残りのページを2番目のドキュメントに挿入する
newDoc_2.InsertPageRange(sourceDoc, 1, sourceDoc.Pages.Count - 1);
//2つのドキュメントをPDFファイルとして保存する
newDoc_1.SaveToFile(outputDirectory + "output-1.pdf");
newDoc_2.SaveToFile(outputDirectory + "output-2.pdf");
}
}
}Imports Spire.Pdf
Imports System
Namespace SplitPdfByPageRanges
Class Program
Shared Sub Main(ByVal args() As String)
'入力ファイルのパスを指定する
Dim inputFile As String = "C:\\Users\\Administrator\\Desktop\\License.pdf"
'出力ディレクトリを指定する
Dim outputDirectory As String = "C:\\Users\\Administrator\\Desktop\\Output\\"
'PdfDocumentオブジェクトの初期化中にソースPDFファイルをロードする
Dim sourceDoc As PdfDocument = New PdfDocument(inputFile)
'2つの追加のPdfDocumentオブジェクトを作成する
Dim NewDoc_1 As PdfDocument = New PdfDocument()
Dim NewDoc_2 As PdfDocument = New PdfDocument()
'ソースファイルの最初のページを最初のドキュメントに挿入する
NewDoc_1.InsertPage(sourceDoc, 0)
'ソースファイルの残りのページを2番目のドキュメントに挿入する
NewDoc_2.InsertPageRange(sourceDoc, 1, sourceDoc.Pages.Count - 1)
'2つのドキュメントをPDFファイルとして保存する
NewDoc_1.SaveToFile(outputDirectory + "output-1.pdf")
NewDoc_2.SaveToFile(outputDirectory + "output-2.pdf")
End Sub
End Class
End Namespace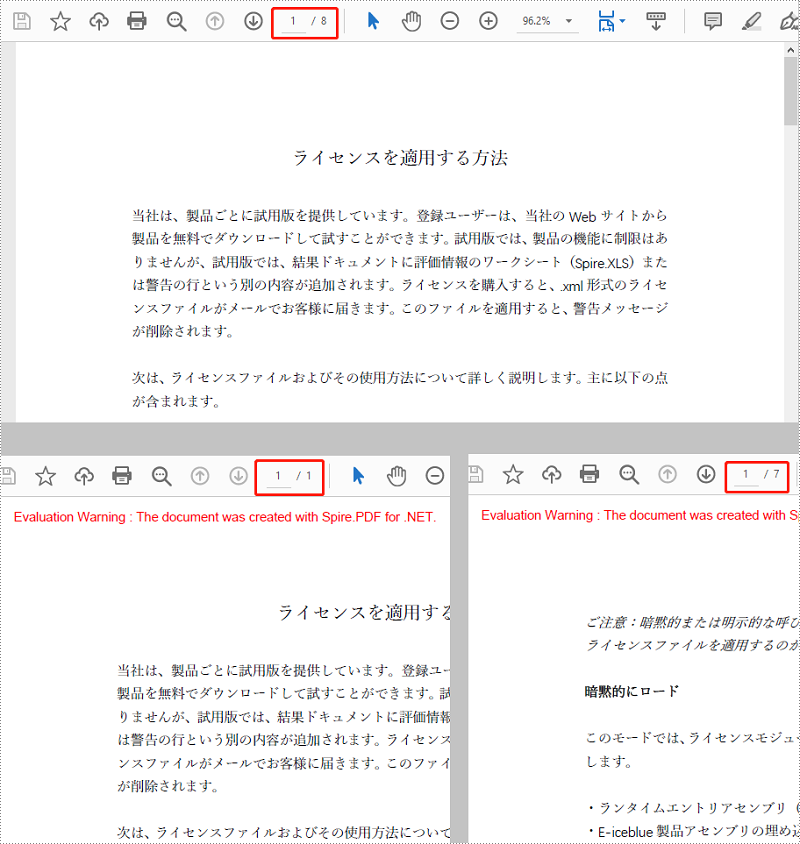
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Spreadsheet 6.6.1 のリリースを発表できることをうれしく思います。このバージョンでは、Excel ファイルの読み込み中に「NullReferenceException」が発生する問題が修正されています。詳細は以下のとおりです。
| カテゴリー | ID | 説明 |
| Bug | SPREADSHEET-202 | Excelファイルの読み込み中に「NullReferenceException」が発生する問題を修正しました。 |
「高速 Web ビュー」とも呼ばれる PDF 線形化は、PDF ファイルを最適化する方法の一つです。通常、ユーザーは、Web ブラウザがサーバーからすべてのページをダウンロードした場合にのみ、複数ページの PDF ファイルをオンラインで表示できます。ただし、PDF ファイルが線形化されている場合、完全なダウンロードが完了していなくても、ブラウザーは最初のページを非常にすばやく表示できます。この記事では、Spire.PDF for .NET を使用して PDF を C# および VB.NET で線形化する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPDF ファイルを線形化に変換する手順は次のとおりです。
using Spire.Pdf.Conversion;
namespace ConvertPdfToLinearized
{
class Program
{
static void Main(string[] args)
{
//PDFファイルをロードする
PdfToLinearizedPdfConverter converter = new PdfToLinearizedPdfConverter("C:\\Users\\Administrator\\Desktop\\Sample.pdf");
//ファイルを線形化されたPDFに変換する
converter.ToLinearizedPdf("Linearized.pdf");
}
}
}Imports Spire.Pdf.Conversion
Namespace ConvertPdfToLinearized
Class Program
Shared Sub Main(ByVal args() As String)
'PDFファイルをロードする
Dim converter As PdfToLinearizedPdfConverter = New PdfToLinearizedPdfConverter("C:\\Users\\Administrator\\Desktop\\Sample.pdf")
'ファイルを線形化されたPDFに変換する
converter.ToLinearizedPdf("Linearized.pdf")
End Sub
End Class
End Namespace結果ファイルを AdobeAcrobat で開き、ドキュメントのプロパティを確認します。「Fast Web View」の値が「はい」であることがわかります。これは、ファイルが線形化されていることを意味します。
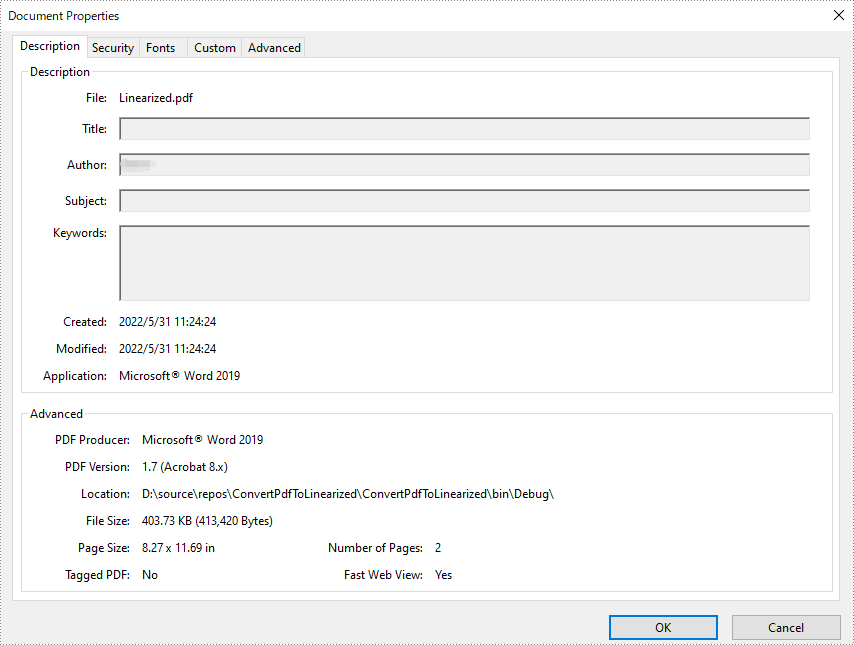
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
カラー画像を含む PDF をグレースケールに変換すると、ファイルサイズを縮小し、カラーインクを消費せずに PDF をより手頃なモードで印刷できます。この記事では、Spire.PDF for .NET を使用して、C# および VB.NET でプログラムによって変換を実行する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFカラー PDF をグレースケールに変換する手順は次のとおりです。
using Spire.Pdf.Conversion;
namespace ConvertPdfToGrayscale
{
class Program
{
static void Main(string[] args)
{
//PdfGrayConverterインスタンスを作成し、PDFファイルをロードする
PdfGrayConverter converter = new PdfGrayConverter(@"C:\Users\Administrator\Desktop\Sample.pdf");
//PDFをグレースケールに変換する
converter.ToGrayPdf("Grayscale.pdf");
converter.Dispose();
}
}
}Imports Spire.Pdf.Conversion
Namespace ConvertPdfToGrayscale
Class Program
Shared Sub Main(ByVal args() As String)
'PdfGrayConverterインスタンスを作成し、PDFファイルをロードする
Dim converter As PdfGrayConverter = New PdfGrayConverter("C:\Users\Administrator\Desktop\Sample.pdf")
'PDFをグレースケールに変換する
converter.ToGrayPdf("Grayscale.pdf")
converter.Dispose()
End Sub
End Class
End Namespace変換する前

変換した後

結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word ドキュメントでは、時間、日付、タイトル、参照情報、ページ番号、コンテンツの説明、画像/ロゴをヘッダーまたはフッターに追加して、ドキュメントを充実させることができます。この記事では、Spire.Doc for .NET を使用して C# および VB.NET アプリケーションにヘッダーとフッターを追加する方法を紹介します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.Docこの表は、操作で使用される主なクラス、プロパティ、およびメソッドのリストを示しています。
| 名前 | 説明 |
| Document Class | Word ドキュメントモデルを表します |
| Document. LoadFromFile() Method | Word 文書をロードします |
| Section Class | Word 文書のセクションを表します |
| Document.Sections Property | ドキュメントセクションを取得します |
| HeaderFooter Class | Word のヘッダーとフッターのモデルを表します |
| Section.HeadersFooters.Header Property | 現在のセクションのヘッダー/フッターを取得します |
| Paragraph Class | ドキュメント内の段落を表します |
| HeaderFooter. AddParagraph() Method | セクションの最後に段落を追加します |
| TextRange Class | テキスト範囲を表します |
| Paragraph.AppendText() Method | 段落の最後にテキストを追加します |
| Document. SaveToFile() Method | ドキュメントを MicrosoftWord または別のファイル形式でファイルに保存します |
ヘッダーとフッターを追加する手順は次のとおりです。
using Spire.Doc;
using Spire.Doc.Documents;
using System.Drawing;
using Spire.Doc.Fields;
namespace AddHeaderAndFooter
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Word文書をロードする
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\sample.docx");
//Wordドキュメントの最初のセクションを取得する
Section section = document.Sections[0];
//HeadersFooters.Headerプロパティを介してヘッダーを取得する
HeaderFooter header = section.HeadersFooters.Header;
//段落を追加し、段落の配置スタイルを設定する
Paragraph headerPara = header.AddParagraph();
headerPara.Format.HorizontalAlignment = HorizontalAlignment.Left;
//テキストを追加し、フォント名、サイズ、色などを設定する
TextRange textrange = headerPara.AppendText("E-iceblue Co. Ltd." + "\n あなたのオフィス開発マスター");
textrange.CharacterFormat.FontName = "Arial";
textrange.CharacterFormat.FontSize = 13;
textrange.CharacterFormat.TextColor = Color.DodgerBlue;
textrange.CharacterFormat.Bold = true;
//フッターを取得し、段落を追加し、テキストを追加する
HeaderFooter footer = section.HeadersFooters.Footer;
Paragraph footerPara = footer.AddParagraph();
footerPara.Format.HorizontalAlignment = HorizontalAlignment.Center;
textrange = footerPara.AppendText("Copyright © 2022 All Rights Reserved.");
textrange.CharacterFormat.Bold = false;
textrange.CharacterFormat.FontSize = 11;
//ファイルに保存する
document.SaveToFile("output.docx", FileFormat.Docx);
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System.Drawing
Imports Spire.Doc.Fields
Namespace AddHeaderAndFooter
Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのインスタンスを作成する
Dim document As Document = New Document()
'Word文書をロードする
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\sample.docx")
'Wordドキュメントの最初のセクションを取得する
Dim section As Section = document.Sections(0)
'HeadersFooters.Headerプロパティを介してヘッダーを取得する
Dim header As HeaderFooter = section.HeadersFooters.Header
'段落を追加し、段落の配置スタイルを設定する
Dim headerPara As Paragraph = header.AddParagraph()
headerPara.Format.HorizontalAlignment = HorizontalAlignment.Left
'テキストを追加し、フォント名、サイズ、色などを設定する
Dim textrange As TextRange = headerPara.AppendText("E-iceblue Co. Ltd." + "\n あなたのオフィス開発マスター")
textrange.CharacterFormat.FontName = "Arial"
textrange.CharacterFormat.FontSize = 13
textrange.CharacterFormat.TextColor = Color.DodgerBlue
textrange.CharacterFormat.Bold = True
'フッターを取得し、段落を追加し、テキストを追加する
Dim footer As HeaderFooter = section.HeadersFooters.Footer
Dim footerPara As Paragraph = footer.AddParagraph()
footerPara.Format.HorizontalAlignment = HorizontalAlignment.Center
textrange = footerPara.AppendText("Copyright © 2022 All Rights Reserved.")
textrange.CharacterFormat.Bold = False
textrange.CharacterFormat.FontSize = 11
'ファイルに保存する
document.SaveToFile("output.docx", FileFormat.Docx)
End Sub
End Class
End Namespace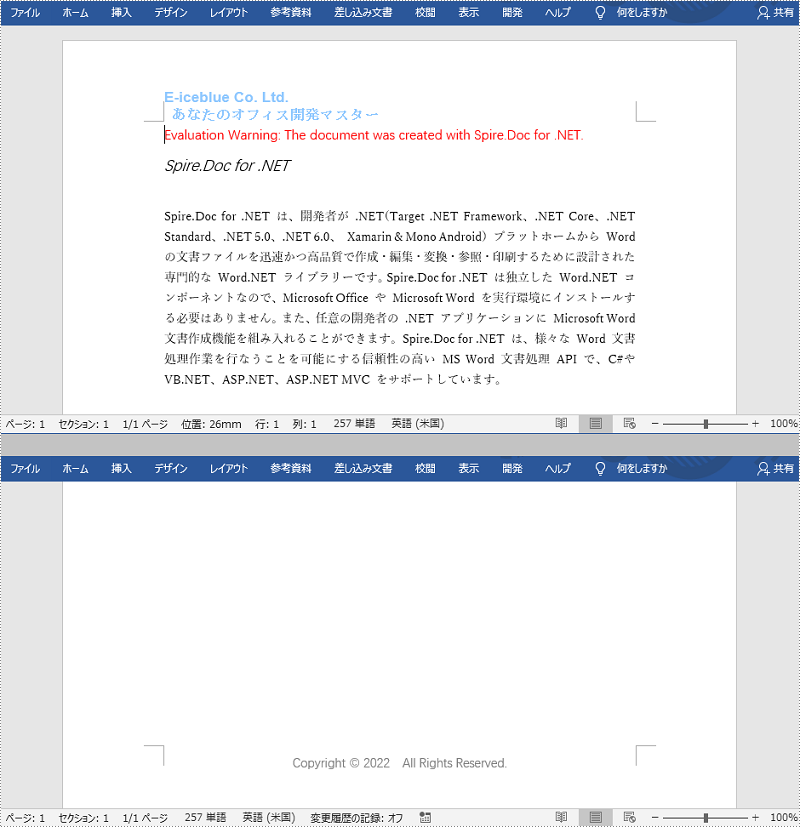
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





