チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.PDF for Java 9.6.2のリリースを発表できることをうれしく思います。今回の更新では、PDFからWordとExcel、OFDからPDFへの変換機能が強化されました。また、WPSツールで文書を開くと、追加されたテキストボックスが表示されないなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5885 | WPSツールで文書を開くと、追加されたテキストボックスが表示されない問題が修正されました。 |
| Bug | SPIREPDF-5966 | OFDをPDFに変換する際に、アプリケーションが「java.lang.ClassCastException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5979 | OFDをPDFに変換する際に、アプリケーションが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6015 | PDFをExcelに変換した後、データが正しくない問題が修正されました。 |
| Bug | SPIREPDF-6026 | PDFをWordに変換した後、フォント名が正しくない問題が修正されました。 |
ウォーターフォールグラフは、Excel で最も直感的なグラフの一つです。それは、一定期間におけるデータの積極的な影響と消極的な影響の累積効果を表示することができます。これは、企業の利益やキャッシュフローを記録したり、製品収入を比較したり、売上高や在庫の変化を分析したりするための有用なツールでもあります。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET でプログラムによって Excel でウォーターフォールグラフを作成する方法を紹介します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSウォーターフォールグラフはは財務諸表を分析する理想的なツールです。ウォーターフォール グラフを Excel ワークシートに追加するために、Spire.XLS for .NET には Worksheet.Charts.Add(ExcelChartType.WaterFall) メソッドが用意されています。詳細な手順は次のとおりです。
using Spire.Xls;
namespace WaterfallChart
{
class Program
{
static void Main(string[] args)
{
//Workbookインスタンスを作成する
Workbook workbook = new Workbook();
//Excel文書を読み込む
workbook.LoadFromFile("sample.xlsx");
//最初のシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//ワークシートにウォーターフォールグラフを追加する
Chart chart = sheet.Charts.Add(ExcelChartType.WaterFall);
//グラフのデータ範囲を設定する
chart.DataRange = sheet["A2:B11"];
//グラフの位置を設定する
chart.LeftColumn = 4;
chart.TopRow = 2;
chart.RightColumn = 15;
chart.BottomRow = 23;
//グラフのタイトルを設定する
chart.ChartTitle = "損益計算書";
//グラフの特定のデータポイントを合計または小計に設定する
chart.Series[0].DataPoints[2].SetAsTotal = true;
chart.Series[0].DataPoints[7].SetAsTotal = true;
chart.Series[0].DataPoints[9].SetAsTotal = true;
//データポイント間の接続線を表示する
chart.Series[0].Format.ShowConnectorLines = true;
//データポイントのデータラベルを表示する
chart.Series[0].DataPoints.DefaultDataPoint.DataLabels.HasValue = true;
chart.Series[0].DataPoints.DefaultDataPoint.DataLabels.Size = 8;
//グラフの凡例位置を設定する
chart.Legend.Position = LegendPositionType.Top;
//結果文書を保存する
workbook.SaveToFile("WaterfallChart.xlsx");
}
}
}Imports Spire.XLS
Namespace WaterfallChart
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookインスタンスを作成する
Dim workbook As Workbook = New Workbook
'Excel文書を読み込む
workbook.LoadFromFile("Data.xlsx")
'最初のシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'ワークシートにウォーターフォールグラフを追加する
Dim chart As Chart = sheet.Charts.Add(ExcelChartType.WaterFall)
'グラフのデータ範囲を設定する
chart.DataRange = sheet("A2:B11")
'グラフの位置を設定する
chart.LeftColumn = 4
chart.TopRow = 2
chart.RightColumn = 15
chart.BottomRow = 23
'グラフのタイトルを設定する
chart.ChartTitle = "損益計算書"
'グラフの特定のデータポイントを合計または小計に設定する
chart.Series(0).DataPoints(2).SetAsTotal = True
chart.Series(0).DataPoints(7).SetAsTotal = True
chart.Series(0).DataPoints(9).SetAsTotal = True
'データポイント間の接続線を表示する
chart.Series(0).Format.ShowConnectorLines = True
'データポイントのデータラベルを表示する
chart.Series(0).DataPoints.DefaultDataPoint.DataLabels.HasValue = True
chart.Series(0).DataPoints.DefaultDataPoint.DataLabels.Size = 8
'グラフの凡例位置を設定する
chart.Legend.Position = LegendPositionType.Top
'結果文書を保存する
workbook.SaveToFile("WaterfallChart.xlsx")
End Sub
End Class
End Namespace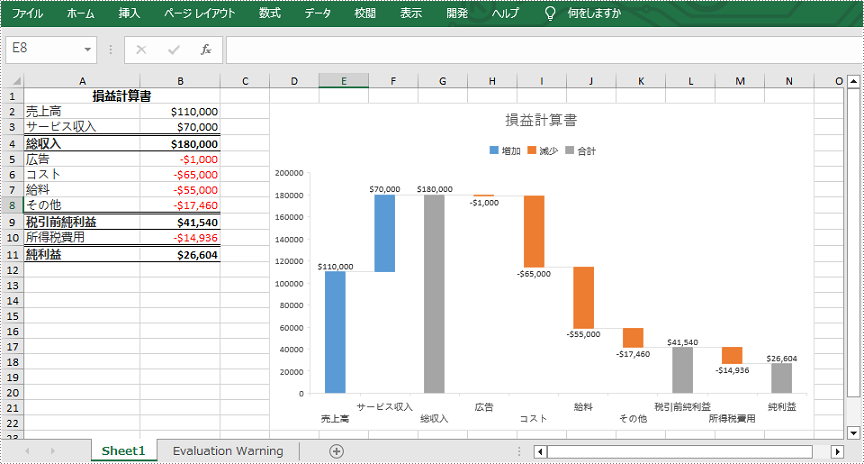
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF の注釈は、ドキュメントに追加されるメモやマーカーで、コメント、説明、フィードバックなどをするのに適しています。ドキュメントの共同制作者は、しばしば注釈を付けてコミュニケーションをとります。しかし、注釈に関連する問題が処理されたり、ドキュメントが最終的に完成した場合、ドキュメントをより簡潔でプロフェッショナルなものにするために注釈を削除することが必要です。この記事では、Spire.PDF for Java を使用して、プログラム的に PDF の注釈を削除する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.5.6</version>
</dependency>
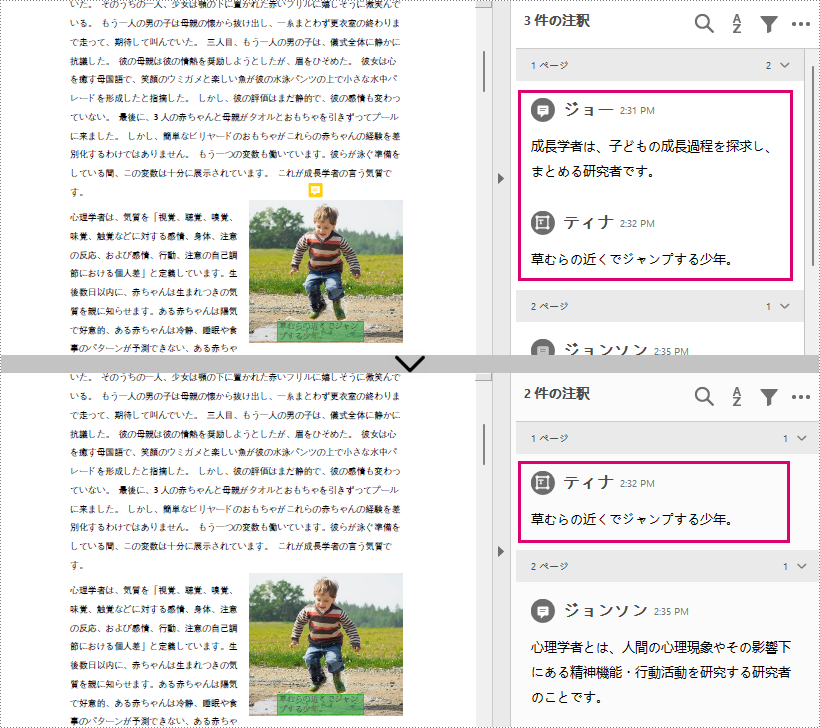
</dependencies>注釈はページレベルのドキュメント要素です。そのため、注釈を削除するには、まず注釈があるページを取得し、PdfPageBase.getAnnotationsWidget().removeAt() メソッドを使用して注釈を削除する必要があります。詳しい手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
public class RemoveAnnotation {
public static void main(String[] args) {
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/注釈.pdf");
//ドキュメントの最初のページを取得する
PdfPageBase page = pdf.getPages().get(0);
//このページの最初の注釈を削除する
page.getAnnotationsWidget().removeAt(0);
//ドキュメントを保存する
pdf.saveToFile("注釈の削除.pdf");
}
}
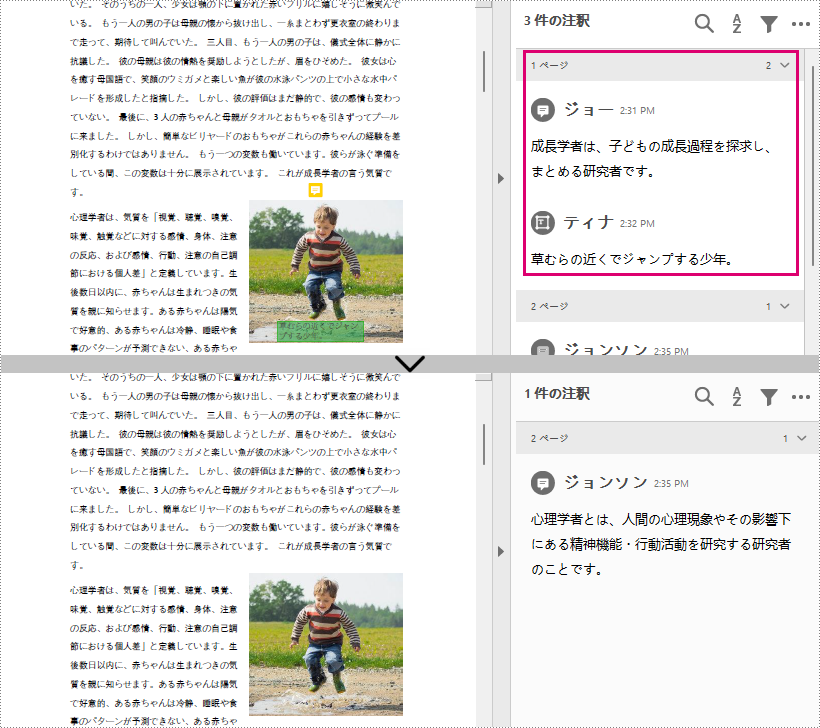
Spire.PDF for Java では、指定したページ内のすべての注釈を削除する PdfPageBase.getAnnotationsWidget().clear() メソッドも提供しています。詳しい手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
public class RemoveAllAnnotationPage {
public static void main(String[] args) {
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/注釈.pdf");
//ドキュメントの最初のページを取得する
PdfPageBase page = pdf.getPages().get(0);
//このページのすべての注釈を削除する
page.getAnnotationsWidget().clear();
//ドキュメントを保存する
pdf.saveToFile("ページ内のすべての注釈を削除.pdf");
}
}
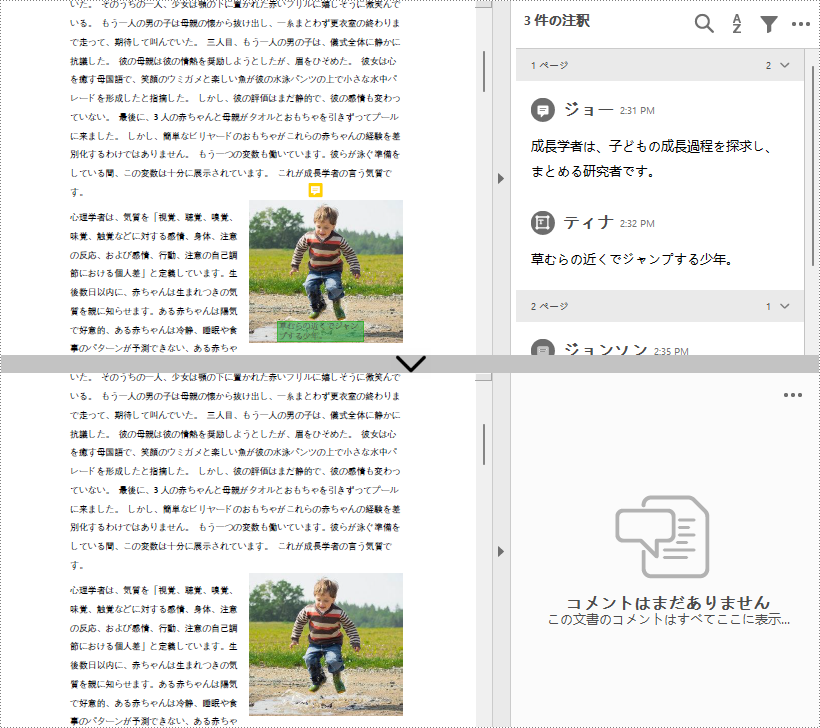
PDF ドキュメントからすべての注釈を削除するには、ドキュメント内のすべてのページをループして、各ページからすべての注釈を削除する必要があります。詳しい手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
public class RemoveAllAnnotations {
public static void main(String[] args) {
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/注釈.pdf");
//ドキュメント内のページをループする
for (PdfPageBase page : (Iterable) pdf.getPages()) {
//各ページの注释をすべて削除する
page.getAnnotationsWidget().clear();
}
//ドキュメントを保存する
pdf.saveToFile("すべての注釈の削除.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF 文書では、テキストをハイライトすることで、読者に文書内の特定のコンテンツにもっと注意を向けさせることができます。キーワードや 文をハイライトすることで、読者に文書内の重要な情報を促し、読者がその情報を探してアクセスすることを容易にし、読書効率や読書体験を向上させることができるのです。この記事では、Spire.PDF for .NET を使用して、プログラムで PDF ドキュメント内の特定のテキストを検索してハイライトする方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPdfTextFinder.Find() メソッドで指定したテキストを検索し、PdfTextFragment.Highlight() メソッドで検索したテキストを強調表示すればいいのです。 詳しい操作手順は以下の通りです。
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
using System.Drawing;
namespace HighlightTextInPdf
{
internal class Program
{
static void Main(string[] args)
{
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.LoadFromFile("C:/サンプル.pdf");
//PdfTextFindOptionsのオブジェクトを作成する
PdfTextFindOptions findOptions = new PdfTextFindOptions();
//テキスト検索のパラメータを設定する
findOptions.Parameter = TextFindParameter.WholeWord;
//文書内のページをループする
foreach (PdfPageBase page in pdf.Pages)
{
//PdfTextFinderのオブジェクトを作成する
PdfTextFinder finder = new PdfTextFinder(page);
//テキスト検索のオプションを設定する
finder.Options = findOptions;
//指定したテキストを検索する
List results = finder.Find("時間を超越した宇宙");
//指定したテキストをすべて強調表示する
foreach (PdfTextFragment text in results)
{
text.HighLight(Color.GreenYellow);
}
}
//ドキュメントを保存する
pdf.SaveToFile("テキストの強調表示.pdf");
}
}
} Imports Spire.Pdf
Imports Spire.Pdf.Texts
Imports System.Drawing
Namespace HighlightTextInPdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'PDFドキュメントを読み込む
pdf.LoadFromFile("C:/サンプル.pdf")
'PdfTextFindOptionsのオブジェクトを作成する
Dim findOptions As PdfTextFindOptions = New PdfTextFindOptions()
'テキスト検索のパラメータを設定する
findOptions.Parameter = TextFindParameter.WholeWord
'文書内のページをループする
Dim page As PdfPageBase
For Each page In pdf.Pages
'PdfTextFinderのオブジェクトを作成する
Dim finder As PdfTextFinder = New PdfTextFinder(page)
'テキスト検索のオプションを設定する
finder.Options = findOptions
'指定したテキストを検索する
Dim results As List= finder.Find("時間を超越した宇宙")
'指定したテキストをすべて強調表示する
Dim text As PdfTextFragment
For Each text In results
text.HighLight(Color.GreenYellow)
Next
Next
'ドキュメントを保存する
pdf.SaveToFile("テキストの強調表示.pdf")
End Sub
End Class
End Namespace 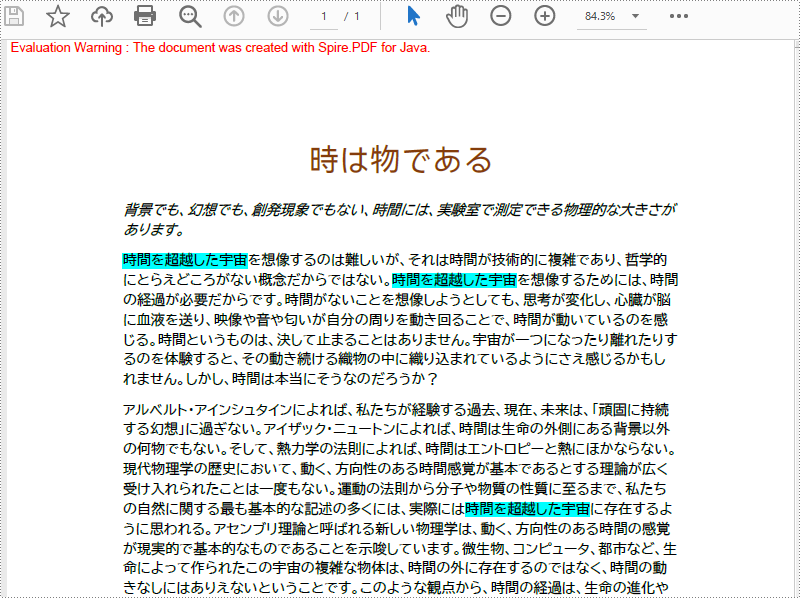
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ハイパーリンクは、Excel で異なる部分を接続したり、Web サイト、メールアドレス、他のファイルなどの外部ソースにリンクすることができる強力なツールです。これにより、ユーザーはワークシート内または異なるワークシート間を素早く簡単に移動できます。ナビゲーションを容易にするだけでなく、ハイパーリンクはファイル内のデータに関連する追加のコンテキストやリソースを提供することもできます。たとえば、ワークシートに記載されている特定の製品に関する詳細情報を提供する Web サイトにリンクし、読者が製品をより深く理解できるようにすることができます。この記事では、Spire.XLS for C++ を使用して C++ で Excel にテキストおよび画像のハイパーリンクを追加する方法について説明します。
Spire.XLS for C++ をアプリケーションに組み込むには、2つの方法があります。一つは NuGet 経由でインストールする方法、もう一つは当社のウェブサイトからパッケージをダウンロードし、ライブラリをプログラムにコピーする方法です。NuGet 経由のインストールの方が便利で、より推奨されます。詳しくは、以下のリンクからご覧いただけます。
Spire.XLS for C++ を C++ アプリケーションに統合する方法
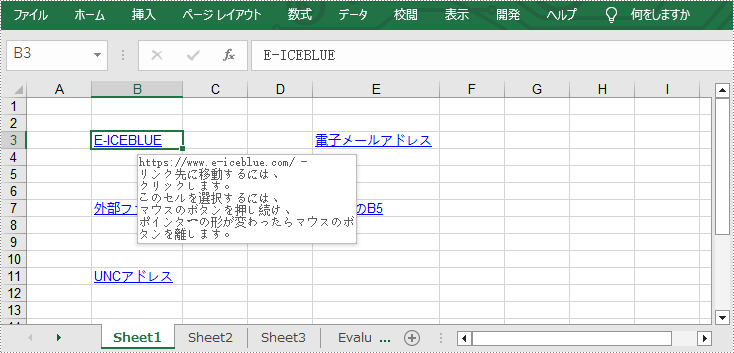
Excel のテキストハイパーリンクはテキストとして表示されます。 テキストをクリックすると、ワークブックの特定の位置、電子メールアドレス、web ページ、外部ファイルなどの特定のページにジャンプできます。 次の手順では、Spire.XLS for C++ を使用して Excel にテキストハイパーリンクを追加する方法を説明します。
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
int main()
{
//Workbookクラスのインスタンスを初期化する
intrusive_ptr<Workbook> workbook = new Workbook();
//最初のワークシートを取得する
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//Webページへのテキストハイパーリンクを追加する
intrusive_ptr<CellRange> cell1 = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B3"));
intrusive_ptr<HyperLink> urlLink = sheet->GetHyperLinks()->Add(cell1);
urlLink->SetType(HyperLinkType::Url);
urlLink->SetTextToDisplay(L"E-ICEBLUE");
urlLink->SetAddress(L"https://www.e-iceblue.com/");
//電子メールアドレスへのテキストハイパーリンクを追加する
intrusive_ptr<CellRange> cell2 = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"E3"));
intrusive_ptr<HyperLink> mailLink = sheet->GetHyperLinks()->Add(cell2);
mailLink->SetType(HyperLinkType::Url);
mailLink->SetTextToDisplay(L"電子メールアドレス");
mailLink->SetAddress(L"mailto:support @e-iceblue.com");
//外部ファイルへのテキストハイパーリンクを追加する
intrusive_ptr<CellRange> cell3 = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B7"));
intrusive_ptr<HyperLink> fileLink = sheet->GetHyperLinks()->Add(cell3);
fileLink->SetType(HyperLinkType::File);
fileLink->SetTextToDisplay(L"外部ファイル");
fileLink->SetAddress(L"C:\\Users\\Administrator\\Desktop\\Report.xlsx");
//別のシートのセルへのテキストハイパーリンクを追加する
intrusive_ptr<CellRange> cell4 = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"E7"));
intrusive_ptr<HyperLink> sheetLink = sheet->GetHyperLinks()->Add(cell4);
sheetLink->SetType(HyperLinkType::Workbook);
sheetLink->SetTextToDisplay(L"sheet2のB5");
sheetLink->SetAddress(L"Sheet2!B5");
//UNCアドレスへのテキストハイパーリンクを追加する
intrusive_ptr<CellRange> cell5 = dynamic_pointer_cast<CellRange>(sheet->GetRange(L"B11"));
intrusive_ptr<HyperLink> uncLink = sheet->GetHyperLinks()->Add(cell5);
uncLink->SetType(HyperLinkType::Unc);
uncLink->SetTextToDisplay(L"UNCアドレス");
uncLink->SetAddress(L"\\192.168.0.121");
//列幅を自動調整する
sheet->AutoFitColumn(2);
sheet->AutoFitColumn(5);
//結果ファイルを保存する
workbook->SaveToFile(L"AddTextHyperlinks.xlsx", ExcelVersion::Version2013);
workbook->Dispose();
}
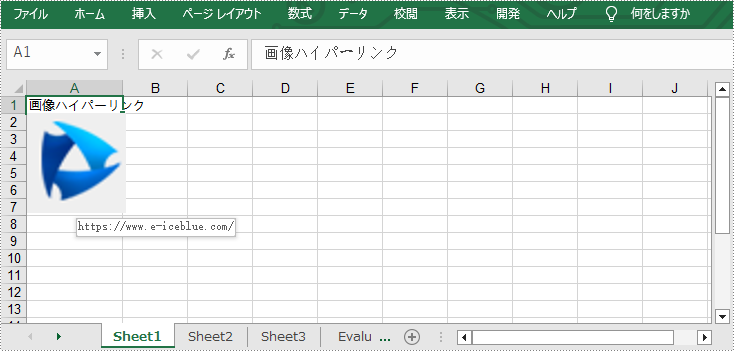
テキストハイパーリンクのほかに、画像ハイパーリンクをクリックすることで特定の web ページにジャンプすることもできます。 次の手順では、Spire.XLS for C++ を使用して画像ハイパーリンクをに追加する方法を説明します。
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
int main()
{
//Workbookクラスのインスタンスを初期化する
intrusive_ptr<Workbook> workbook = new Workbook();
//最初のワークシートを取得する
intrusive_ptr<Worksheet> sheet = dynamic_pointer_cast<Worksheet>(workbook->GetWorksheets()->Get(0));
//特定のセルにテキストを追加する
sheet->GetRange(L"A1")->SetText(L"画像ハイパーリンク");
//特定のセルに画像を追加する
intrusive_ptr<ExcelPicture> picture = ExcelPicture::Dynamic_cast<ExcelPicture>(sheet->GetPictures()->Add(2, 1, L"Logo.png"));
//画像の幅と高さを設定する
picture->SetWidth(100);
picture->SetHeight(100);
//画像へのハイパーリンクを追加する
picture->SetHyperLink(L"https://www.e-iceblue.com", true);
//列幅を設定する
sheet->GetColumns()->GetItem(0)->SetColumnWidth(13);
//結果ファイルを保存する
workbook->SaveToFile(L"AddImageHyperlink.xlsx", ExcelVersion::Version2013);
workbook->Dispose();
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office for Java 8.6.0のリリースを発表できることをうれしく思います。このリリースでは、Spire.Doc for Java は製本線の位置と内容コントロールの色を設定することがサポートされています。Spire.XLS for JavaはExcelからPDFや画像への変換機能が強化されました。さらに、多くの既知のバグが正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-4902 | 製本線の位置の設定がサポートされています。
section.getPageSetup().isTopGutter(boolean value); |
| New feature | SPIREDOC-9054 | メールマージドメインのmailMerge.executeWidthRegion()メソッドは、ストリームからXMLファイルをロードすることがサポートされています。
document.getMailMerge().executeWidthRegion(InputStream stream); |
| New feature | SPIREDOC-9393 | 内容コントロールの色を設定することがサポートされています。
for (Object docObj : doc.getSections().get(0).getBody().getChildObjects()) {
if (docObj instanceof StructureDocumentTag) {
DocumentObject Obj = (DocumentObject) docObj;
SDTProperties sdtProperties = ((StructureDocumentTag) Obj).getSDTProperties();
switch (sdtProperties.getSDTType()) {
case Rich_Text:
sdtProperties.setColor(Color.ORANGE);
break;
case Text:
sdtProperties.setColor(Color.green);
break;
}
}
} |
| Bug | SPIREDOC-9191 | WordをPDFに変換した後、内容が失われる問題が修正されました。 |
| Bug | SPIREDOC-9340 | 目次ページ番号の更新に失敗する問題が修正されました。 |
| Bug | SPIREDOC-9348 | Word文書をPDFに変換した後、画像が切り取られる問題が修正されました。 |
| Bug | SPIREDOC-9380 | Word文書をOFDに変換した後、改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9383 | Word文書をPDFに変換する際に、アプリケーションが「UnsupportedOperationException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9384 | 改訂を受け入れた後に余分な空白段落が出現する問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4611 | Excelを画像に変換した後に、フォント効果が一致しない問題が修正されました。 |
| Bug | SPIREXLS-4639 | Excelを画像に変換した後に、上付き文字と下付き文字の形式が失われる問題が修正されました。 |
| Bug | SPIREXLS-4642 | 画像の透かしを追加した後に、グラフの横軸が変更される問題が修正されました。 |
| Bug | SPIREXLS-4650 | Excel文書を読み込む際に、アプリケーションがフリーズする問題が修正されました。 |
| Bug | SPIREXLS-4669 | ピボットテーブルの列名の背景色を設定できなかった問題が修正されました。 |
| Bug | SPIREXLS-4671 | 画像の透かしを追加した後に、文書のデータが失われる問題が修正されました。 |
| Bug | SPIREXLS-4679 | ExcelをPDFに変換する際に、アプリケーションがメモリ不足のエラーが発生する問題が修正されました。 |
| Bug | SPIREXLS-4680 | グラフを画像に変換した後に、小数点以下の桁数が一致しない問題が修正されました。 |
| Bug | SPIREXLS-4682 | Excel文書を読み込む際に、アプリケーションが「java.lang.ClassCastException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4685 | LOG関数を追加した後に、結果ファイルを開けなくなる問題が修正されました。 |
| Bug | SPIREXLS-4687 | et形式のファイルを保存してロードすると、スタイルが変更される問題が修正されました。 |
| Bug | SPIREXLS-4688 | et形式のファイルを保存してロードすると、グラフの座標軸形式が変更される問題が修正されました。 |
| Bug | SPIREXLS-4736 | ExcelをPDFに変換する際に、アプリケーションが「java.lang.ClassFormatError」をスローする問題が修正されました。 |
Spire.Doc for Java 11.6.0のリリースを発表できることを嬉しく思います。このバージョンで、製本線の位置や内容コントロールの色を設定できるようになりました。また、WordからPDFやOFDへの変換機能も強化されました。さらに、改訂を受け入れた後に余分な空白段落が出現するなど、既知問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-4902 | 製本線の位置の設定がサポートされています。
section.getPageSetup().isTopGutter(boolean value); |
| New feature | SPIREDOC-9054 | メールマージドメインのmailMerge.executeWidthRegion()メソッドは、ストリームからXMLファイルをロードすることがサポートされています。
document.getMailMerge().executeWidthRegion(InputStream stream); |
| New feature | SPIREDOC-9393 | 内容コントロールの色を設定することがサポートされています。
for (Object docObj : doc.getSections().get(0).getBody().getChildObjects()) {
if (docObj instanceof StructureDocumentTag) {
DocumentObject Obj = (DocumentObject) docObj;
SDTProperties sdtProperties = ((StructureDocumentTag) Obj).getSDTProperties();
switch (sdtProperties.getSDTType()) {
case Rich_Text:
sdtProperties.setColor(Color.ORANGE);
break;
case Text:
sdtProperties.setColor(Color.green);
break;
}
}
} |
| Bug | SPIREDOC-9191 | WordをPDFに変換した後、内容が失われる問題が修正されました。 |
| Bug | SPIREDOC-9340 | 目次ページ番号の更新に失敗する問題が修正されました。 |
| Bug | SPIREDOC-9348 | Word文書をPDFに変換した後、画像が切り取られる問題が修正されました。 |
| Bug | SPIREDOC-9380 | Word文書をOFDに変換した後、改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9383 | Word文書をPDFに変換する際に、アプリケーションが「UnsupportedOperationException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9384 | 改訂を受け入れた後に余分な空白段落が出現する問題が修正されました。 |
Spire.PDFViewer 7.11.0のリリースを発表できることを嬉しく思います。このバージョンでは、文書のコンテンツが完全に表示されない問題が修正されました。また、スクロール時に文書のコンテンツがスムーズに読み込まれない問題など、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDFVIEWER-561 | スクロール時に文書のコンテンツがスムーズに読み込まれない問題が修正されました。 |
| Bug | SPIREPDFVIEWER-564 | 文書のコンテンツが完全に表示されない問題が修正されました。 |
コードによる PDF 生成にはさまざまな利点があります。リアルタイムデータ、データベースレコード、ユーザー入力などの動的コンテンツを容易に統合するのに役立ちます。この機能は、ユーザーにより優れたカスタマイズと自動化機能を提供し、面倒な手動操作も回避します。この記事では、Spire.PDF for Java を使用して PDF ドキュメントを作成する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.5.6</version>
</dependency>
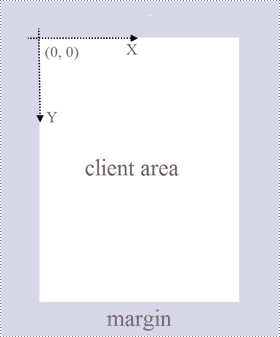
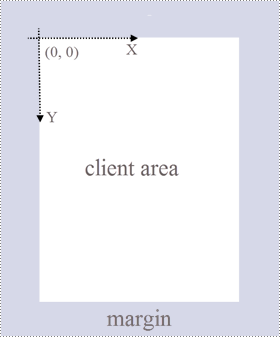
</dependencies>Spire.PDF for Java のページ(PdfPageBase クラスで表される)は、クライアント領域と周囲のマージンで構成されています。コンテンツ領域は、ユーザーがさまざまなコンテンツを記述するための領域であり、ページ余白は通常空白のエッジになります。
下図に示すように、ページ上の座標系の原点はクライアント領域の左上隅にあり、x 軸は水平に右に伸び、y 軸は垂直に下に伸びています。クライアント領域に追加するすべての要素は、指定された座標に基づいている必要があります。
さらに、次の表に重要なクラスと方法を示します。これは、以下のコードを理解しやすくするのに役立ちます。
| クラスと 方法 | 説明 |
| PdfDocument クラス | PDF ドキュメント モデルを表します。 |
| PdfPageBase クラス | PDF ドキュメント内のページを表します。 |
| PdfSolidBrush クラス | オブジェクトを単色で塗りつぶすブラシを表します。 |
| PdfTrueTypeFont クラス | True Typeフォントを表します。 |
| PdfStringFormat クラス | アライメント、文字間隔、インデントなどのテキスト書式情報を表します。 |
| PdfTextWidget クラス | 複数のページにまたがる機能を持つテキスト領域を表します。 |
| PdfTextLayout クラス | テキストのレイアウト情報を表します。 |
| PdfDocument.getPages().add() メソッド | PDF ドキュメントにページを追加します。 |
| PdfPageBase.getCanvas().drawString() メソッド | 指定したフォントとブラシオブジェクトを使用して、ページ上の指定した位置に文字列を描画します。 |
| PdfTextWidget.draw() メソッド | テキストウィジェットをページの指定した位置に描画します。 |
| PdfDocument.save() メソッド | ドキュメントを PDF ファイルに保存します。 |
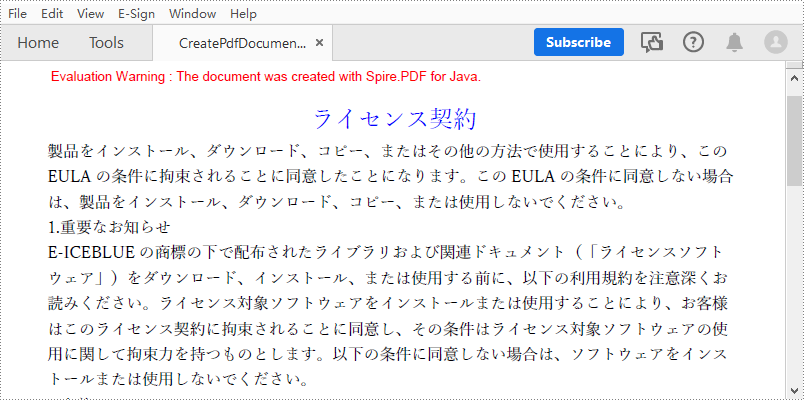
Spire.PDF for Java では、PDF ドキュメントにさまざまな要素を追加できます。この記事では、プレーンテキストの PDF ドキュメントを作成する方法について説明します。詳細な手順は次のとおりです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
import java.io.*;
public class CreatePdfDocument {
public static void main(String[] args) throws IOException {
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(35f));
//タイトルのテキストの指定
String titleText = "ライセンス契約";
//Solid Brusheを作成する
PdfSolidBrush titleBrush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
PdfSolidBrush paraBrush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//True Typeフォントを作成する
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("Yu Mincho",Font.BOLD,18));
PdfTrueTypeFont paraFont = new PdfTrueTypeFont(new Font("Yu Mincho",Font.PLAIN,12));
//PdfStringFormatクラスによるテキストの配置を設定する
PdfStringFormat format = new PdfStringFormat();
format.setAlignment(PdfTextAlignment.Center);
//ページにタイトルを描画する
page.getCanvas().drawString(titleText, titleFont, titleBrush, new Point2D.Float((float)page.getClientSize().getWidth()/2, 20),format);
//.txtファイルから段落テキストを取得する
String paraText = readFileToString("content.txt");
//段落内容を保存するPdfTextWidgetオブジェクトを作成する
PdfTextWidget widget = new PdfTextWidget(paraText, paraFont, paraBrush);
//段落の内容を配置する長方形を作成する
Rectangle2D.Float rect = new Rectangle2D.Float(0, 50, (float)page.getClientSize().getWidth(),(float)page.getClientSize().getHeight());
//PdfLayoutTypeをPaginateに設定して内容を自動的にページング
PdfTextLayout layout = new PdfTextLayout();
layout.setLayout(PdfLayoutType.Paginate);
//ページに段落テキストを描画する
widget.draw(page, rect, layout);
//ファイルに保存する
doc.saveToFile("output/CreatePdfDocument.pdf");
doc.dispose();
}
//.txtファイルを文字列に変換する
private static String readFileToString(String filepath) throws FileNotFoundException, IOException {
StringBuilder sb = new StringBuilder();
String s ="";
BufferedReader br = new BufferedReader(new FileReader(filepath));
while( (s = br.readLine()) != null) {
sb.append(s + "\n");
}
br.close();
String str = sb.toString();
return str;
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
コードによる PDF 生成にはさまざまな利点があります。リアルタイムデータ、データベースレコード、ユーザー入力などの動的コンテンツを容易に統合するのに役立ちます。この機能は、ユーザーにより優れたカスタマイズと自動化機能を提供し、面倒な手動操作も回避します。この記事では、Spire.PDF for .NET を使用して PDF ドキュメントを作成する方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを.NETプロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET のページ(PdfPageBase クラスで表される)は、クライアント領域と周囲のマージンで構成されています。コンテンツ領域は、ユーザーがさまざまなコンテンツを記述するための領域であり、ページ余白は通常空白のエッジになります。
下図に示すように、ページ上の座標系の原点はクライアント領域の左上隅にあり、x 軸は水平に右に伸び、y 軸は垂直に下に伸びています。クライアント領域に追加するすべての要素は、指定された座標に基づいている必要があります。
さらに、次の表に重要なクラスと方法を示します。これは、以下のコードを理解しやすくするのに役立ちます。
| クラスと方法 | 説明 |
| PdfDocument クラス | PDF ドキュメント モデルを表します。 |
| PdfPageBase クラス | PDF ドキュメント内のページを表します。 |
| PdfSolidBrush クラス | オブジェクトを単色で塗りつぶすブラシを表します。 |
| PdfTrueTypeFont クラス | True Typeフォントを表します。 |
| PdfStringFormat クラス | アライメント、文字間隔、インデントなどのテキスト書式情報を表します。 |
| PdfTextWidget クラス | 複数のページにまたがる機能を持つテキスト領域を表します。 |
| PdfTextLayout クラス | テキストのレイアウト情報を表します。 |
| PdfDocument.Pages.Add() メソッド | PDF ドキュメントにページを追加します。 |
| PdfPageBase.Canvas.DrawString() メソッド | 指定したフォントとブラシオブジェクトを使用して、ページ上の指定した位置に文字列を描画します。 |
| PdfTextWidget.Draw() メソッド | テキストウィジェットをページの指定した位置に描画します。 |
| PdfDocument.Save() メソッド | ドキュメントを PDF ファイルに保存します。 |
Spire.PDF for .NET では、PDF ドキュメントにさまざまな要素を追加できます。この記事では、プレーンテキストの PDF ドキュメントを作成する方法について説明します。詳細な手順は次のとおりです。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace CreatePdfDocument
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.Pages.Add(PdfPageSize.A4, new PdfMargins(35f));
//タイトルのテキストを指定する
string titleText = "ライセンス契約";
//Solid Brusheを作成する
PdfSolidBrush titleBrush = new PdfSolidBrush(new PdfRGBColor(Color.Blue));
PdfSolidBrush paraBrush = new PdfSolidBrush(new PdfRGBColor(Color.Black));
//True Typeフォントを作成する
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("Yu Mincho", 18f, FontStyle.Bold),true);
PdfTrueTypeFont paraFont = new PdfTrueTypeFont(new Font("Yu Mincho", 12f, FontStyle.Regular), true);
//PdfStringFormatクラスによるテキストの配置を設定する
PdfStringFormat format = new PdfStringFormat();
format.Alignment = PdfTextAlignment.Center;
//ページにタイトルを描画する
page.Canvas.DrawString(titleText, titleFont, titleBrush, page.Canvas.ClientSize.Width / 2, 20, format);
//.txtファイルから段落テキストを取得する
string paraText = File.ReadAllText("content.txt");
//段落内容を保存するPdfTextWidgetオブジェクトを作成する
PdfTextWidget widget = new PdfTextWidget(paraText, paraFont, paraBrush);
//段落の内容を配置する長方形を作成する
RectangleF rect = new RectangleF(0, 50, page.Canvas.ClientSize.Width, page.Canvas.ClientSize.Height);
//PdfLayoutTypeをPaginateに設定して内容を自動的にページング
PdfTextLayout layout = new PdfTextLayout();
layout.Layout = PdfLayoutType.Paginate;
//ページに段落テキストを描画する
widget.Draw(page, rect, layout);
//ファイルに保存する
doc.SaveToFile("CreatePdfDocument.pdf");
doc.Dispose();
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Graphics
Imports System.Drawing
Namespace CreatePdfDocument
Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentオブジェクトを作成する
Dim doc As PdfDocument = New PdfDocument()
'ページを追加する
Dim page As PdfPageBase = doc.Pages.Add(PdfPageSize.A4,New PdfMargins(35f))
'タイトルのテキストを指定する
Dim titleText As String = "ライセンス契約"
'Solid Brusheを作成する
Dim titleBrush As PdfSolidBrush = New PdfSolidBrush(New PdfRGBColor(Color.Blue))
Dim paraBrush As PdfSolidBrush = New PdfSolidBrush(New PdfRGBColor(Color.Black))
'True Typeフォントを作成する
Dim titleFont As PdfTrueTypeFont = New PdfTrueTypeFont(New Font("Yu Mincho ",18f,FontStyle.Bold),True)
Dim paraFont As PdfTrueTypeFont = New PdfTrueTypeFont(New Font("Yu Mincho ",12f,FontStyle.Regular),True)
'PdfStringFormatクラスによるテキストの配置を設定する
Dim format As PdfStringFormat = New PdfStringFormat()
format.Alignment = PdfTextAlignment.Center
'ページにタイトルを描画する
page.Canvas.DrawString(titleText, titleFont, titleBrush, page.Canvas.ClientSize.Width / 2, 20, format)
'.txtファイルから段落テキストを取得する
Dim paraText As String = File.ReadAllText("content.txt")
'段落内容を保存するPdfTextWidgetオブジェクトを作成する
Dim widget As PdfTextWidget = New PdfTextWidget(paraText,paraFont,paraBrush)
'段落の内容を配置する長方形を作成する
Dim rect As RectangleF = New RectangleF(0,50,page.Canvas.ClientSize.Width,page.Canvas.ClientSize.Height)
'PdfLayoutTypeをPaginateに設定して内容を自動的にページング
Dim layout As PdfTextLayout = New PdfTextLayout()
lay.Layout = PdfLayoutType.Paginate
'ページに段落テキストを描画する
widget.Draw(page, rect, layout)
'ファイルに保存する
doc.SaveToFile("CreatePdfDocument.pdf")
doc.Dispose()
End Sub
End Class
End Namespace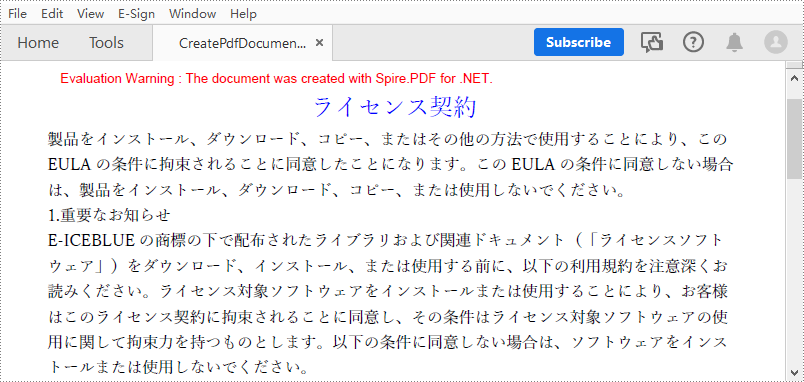
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





