チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Markdown は、軽量なマークアップ言語として、プログラマーや技術文書の執筆者によってそのシンプルさ、読みやすさ、明確な構文のために好まれています。しかし、特定のシナリオでは、Markdown ドキュメントを豊富な書式設定機能とレイアウトの制御を持つ Word ドキュメントに変換したり、印刷や簡単な閲覧に適した PDF ファイルを Markdown ドキュメントから生成する必要がしばしばあります。この記事では、異なるシナリオでのさまざまな文書処理の要件を満たすために、Spire.Doc for .NET を使用して Markdown ファイルを Word ドキュメントまたは PDF ファイルに変換する方法を説明します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET を使用すると、Document.LoadFromFile(string fileName, FileFormat.Markdown) メソッドを使用して Markdown ファイルを読み込み、Document.SaveToFile(string fileName, fileFormat FileFormat) メソッドを使用してそのファイルを他の形式に変換できます。
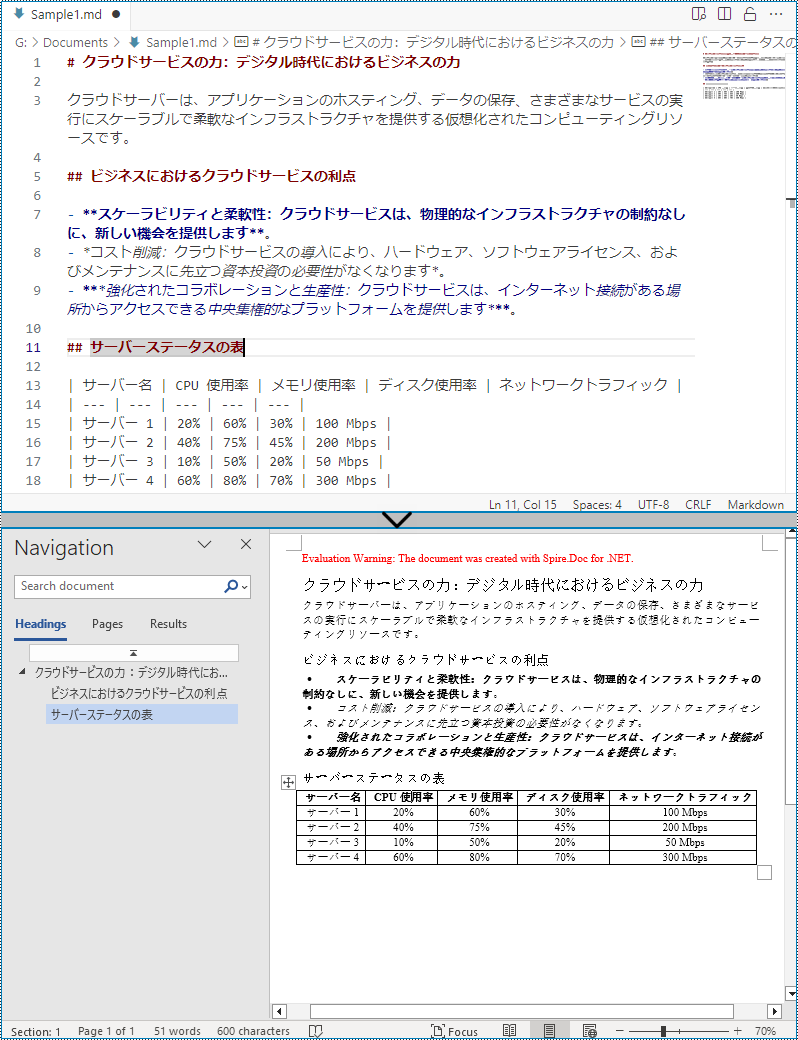
Markdown ファイル内の画像はリンクとして保存されるため、Markdown ファイルを Word ドキュメントに直接変換するのは、画像を含まない Markdown ファイルに適しています。ファイルに画像が含まれている場合は、変換後に画像のさらなる処理が必要です。
以下は、Markdown ファイルを Word ドキュメントに変換する手順です:
using Spire.Doc;
namespace MdToDocx
{
class Program
{
static void Main(string[] args)
{
// Documentクラスのオブジェクトを作成する
Document doc = new Document();
// Markdownファイルを読み込む
doc.LoadFromFile("サンプル.md", FileFormat.Markdown);
// MarkdownファイルをWord文書に変換する
doc.SaveToFile("MarkdownToWord.docx", FileFormat.Docx);
doc.Close();
}
}
}
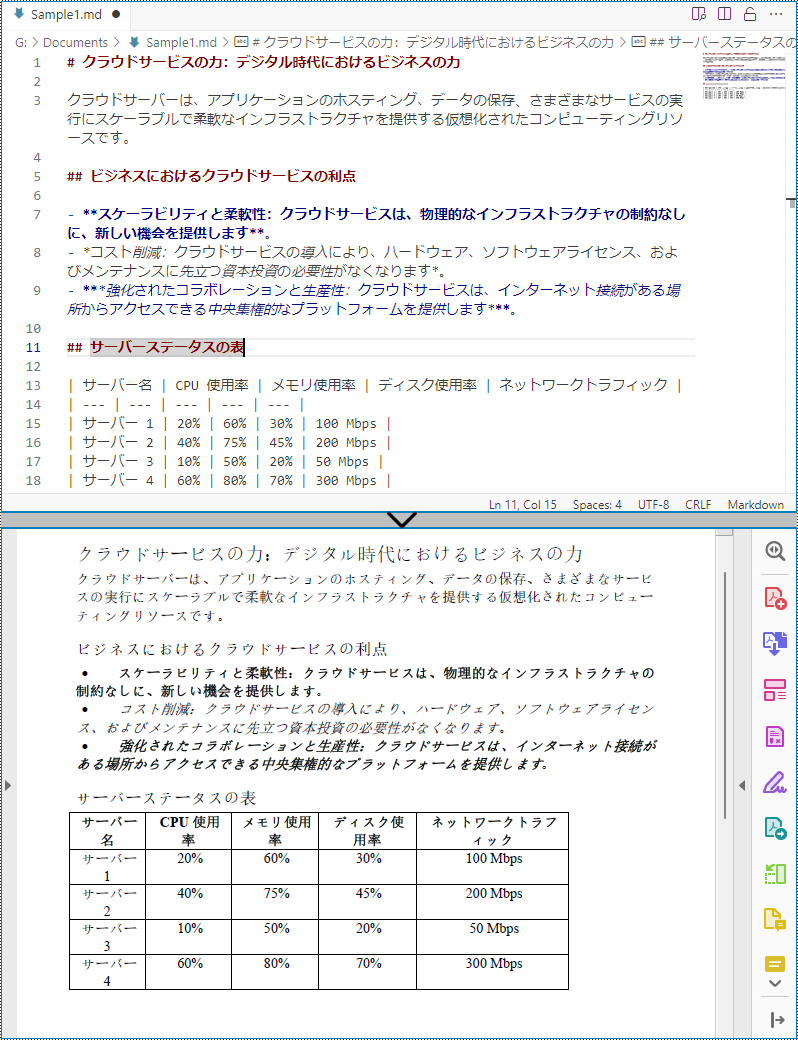
また、FileFormat.PDF Enum をパラメータとして使用することで、Markdown ファイルを直接 PDF ファイルに変換することもできます。以下は Markdown ファイルを PDF ファイルに変換する手順です:
using Spire.Doc;
namespace MdToDocx
{
class Program
{
static void Main(string[] args)
{
// Documentクラスのオブジェクトを作成する
Document doc = new Document();
// Markdownファイルを読み込む
doc.LoadFromFile("サンプル.md", FileFormat.Markdown);
// MarkdownファイルをPDFファイルに変換する
doc.SaveToFile("MarkdownToPDF.pdf", FileFormat.PDF);
doc.Close();
}
}
}
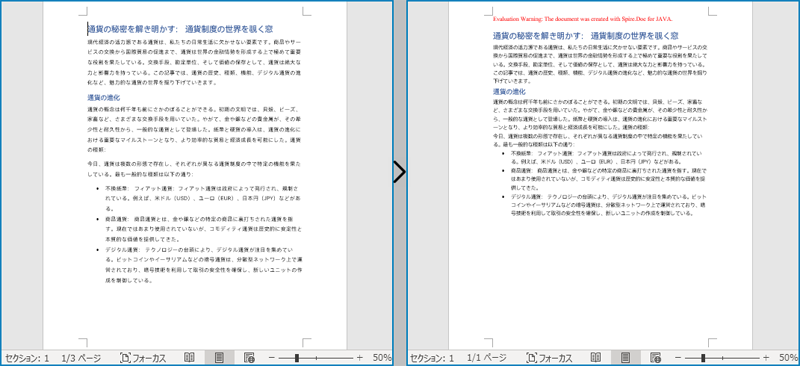
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
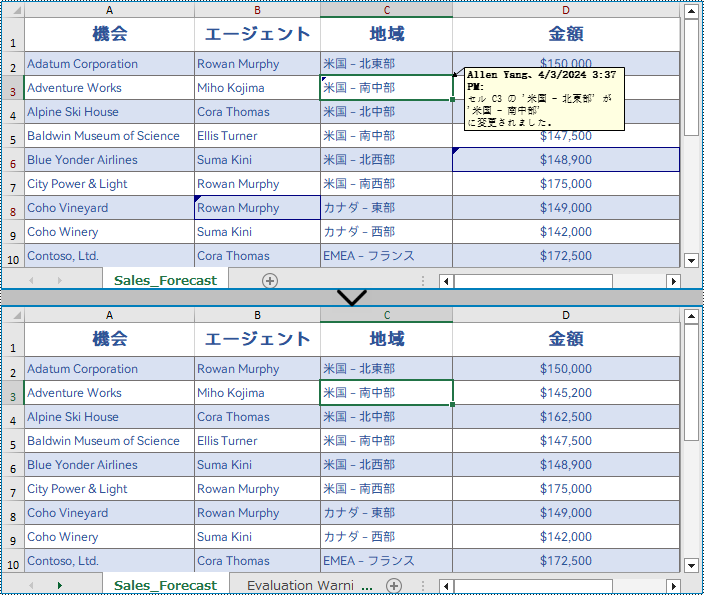
変更履歴をオンにした Excel ドキュメントでは、作成者がドキュメントを保存してからどのような変更が加えられたかを知ることができます。ドキュメントに対する全権限を持っている場合、各リビジョンを承諾したり、元に戻したりすることができます。この記事では、この記事では、Spire.XLS for Java を使用して、Excel ワークブックの変更履歴を承諾および元に戻す方法について説明します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>14.3.2</version>
</dependency>
</dependencies>ワークブックに変更履歴があるかどうかを確認するには、Workbook.hasTrackedChanegs() メソッドを使用します。もしあれば、Workbook.acceptAllTrackedchanges() メソッドを使用して、すべての変更を一度に承諾することができます。以下は、Excel ワークブックで変更履歴を承諾する手順です。
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
public class AcceptTrackedChangesExcel {
public static void main(String[] args) {
// Workbookオブジェクトを作成する
Workbook wb = new Workbook();
// サンプルのExcelファイルを読み込む
wb.loadFromFile("サンプル.xlsx");
// ワークブックに変更履歴があるかどうかを判断する
if (wb.hasTrackedChanges()) {
// ワークブックの変更履歴を承諾する
wb.acceptAllTrackedChanges();
}
// ファイルに保存する
wb.saveToFile("output/変更履歴を承諾.xlsx", FileFormat.Version2013);
}
}
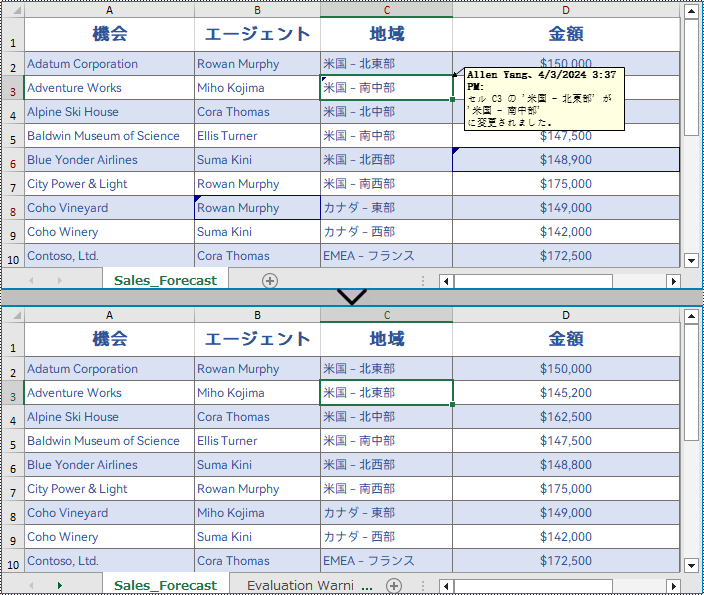
Workbook.rejectAllTrackedChanges() メソッドを使用して、追跡された変更を元に戻すこともできます。そのための手順を以下に示します。
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
public class RejectTrackedChangesExcel {
public static void main(String[] args) {
// Workbookオブジェクトを作成する
Workbook wb = new Workbook();
// サンプルのExcelファイルを読み込む
wb.loadFromFile("サンプル.xlsx");
// ワークブックに変更履歴があるかどうかを判断する
if (wb.hasTrackedChanges()) {
// ワークブックの変更履歴を元に戻す
wb.rejectAllTrackedChanges();
}
// ファイルに保存する
wb.saveToFile("output/変更履歴を元に戻す.xlsx", FileFormat.Version2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Excel ファイルは一般的な表計算フォーマットであり、ユーザーはデータを表に並べたり、分析したり、表示したりすることができる。プログラムで Excel ファイルを操作できることは、Excel の機能を自動化したり、ソフトウェアに統合したりするのに便利である。これは、大量のデータセットや複雑な計算、動的にデータを生成/更新する場合に特に有益です。この記事では、Spire.XLS for Java を使用して、Java で Excel ドキュメントを作成、読み取り、更新する方法について説明します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>14.3.2</version>
</dependency>
</dependencies>Spire.XLS for Java は、Excel ドキュメントの作成や編集に使用できる様々なクラスやインターフェースを提供しています。以下は、この記事に関係する重要なクラス、プロパティ、メソッドのリストです。
| 項目 | 説明 |
| Workbook クラス | Excel のワークブックモデルを表します。 |
| Workbook.getWorksheets().add() メソッド | ワークブックにワークシートを追加します。 |
| Workbook.saveToFile() メソッド | ワークブックを Excel ドキュメントに保存します。 |
| Worksheet クラス | ワークブック内のワークシートを表します。 |
| Worksheet.getRange() メソッド | ワークシートから特定のセルまたはセル範囲を取得します。 |
| Worksheet.insertArray() メソッド | 配列からデータをワークシートにインポートします。 |
| CellRange クラス | ワークシート内のセルまたはセル範囲を表します。 |
| CellRange.setValue() メソッド | セルの値を設定します。 |
| CellRange.getValue() メソッド | セルの値を取得します。 |
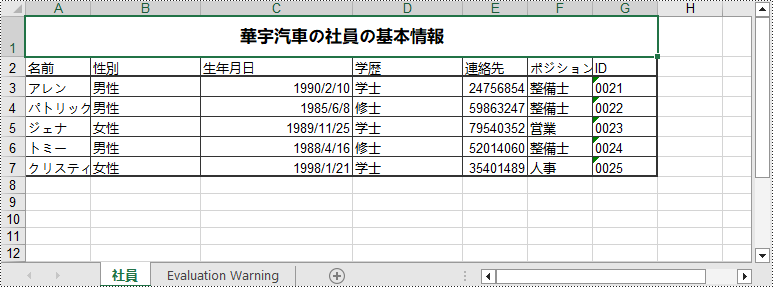
以下は、Spire.XLS for Java を使用して Excel ドキュメントを新規作成する手順です。
import com.spire.xls.*;
public class CreateExcelWorkbook {
public static void main(String[] args) {
//Workbookオブジェクトを作成
Workbook wb = new Workbook();
//デフォルトのワークシートを削除
wb.getWorksheets().clear();
//ワークシートを追加し、名前を「Employee」とする
Worksheet sheet = wb.getWorksheets().add("社員");
//A1からG1までのセルを結合
sheet.getRange().get("A1:G1").merge();
//A1にデータを書き込み、書式を適用
sheet.getRange().get("A1").setValue("華宇汽車の社員の基本情報");
sheet.getRange().get("A1").setHorizontalAlignment(HorizontalAlignType.Center);
sheet.getRange().get("A1").setVerticalAlignment(VerticalAlignType.Center);
sheet.getRange().get("A1").getStyle().getFont().isBold(true);
sheet.getRange().get("A1").getStyle().getFont().setSize(13);
//最初の行の行の高さを設定
sheet.setRowHeight(1,30);
//二次元配列を作成
String[][] twoDimensionalArray = new String[][]{
{"名前", "性別", "生年月日", "学歴", "連絡先", "ポジション", "ID"},
{"アレン", "男性", "1990-02-10", "学士", "24756854", "整備士", "0021"},
{"パトリック", "男性", "1985-06-08", "修士", "59863247", "整備士", "0022"},
{"ジェナ", "女性", "1989-11-25", "学士", "79540352", "営業", "0023"},
{"トミー", "男性", "1988-04-16", "修士", "52014060", "整備士", "0024"},
{"クリスティーナ", "女性", "1998-01-21", "学士", "35401489", "人事", "0025"}
};
//DataTableからデータをワークシートにインポート
sheet.insertArray(twoDimensionalArray,2,1);
//範囲の行の高さを設定
sheet.getRange().get("A2:G7").setRowHeight(15);
//列の幅を設定
sheet.setColumnWidth(2,15);
sheet.setColumnWidth(3,21);
sheet.setColumnWidth(4,15);
//範囲の境界線スタイルを設定
sheet.getRange().get("A2:G7").borderAround(LineStyleType.Medium);
sheet.getRange().get("A2:G7").borderInside(LineStyleType.Thin);
sheet.getRange().get("A2:G2").borderAround(LineStyleType.Medium);
sheet.getRange().get("A2:G7").getBorders().setKnownColor(ExcelColors.Black);
// .xlsxファイルに保存
wb.saveToFile("output/新しいワークブック.xlsx", FileFormat.Version2016);
wb.dispose();
}
}
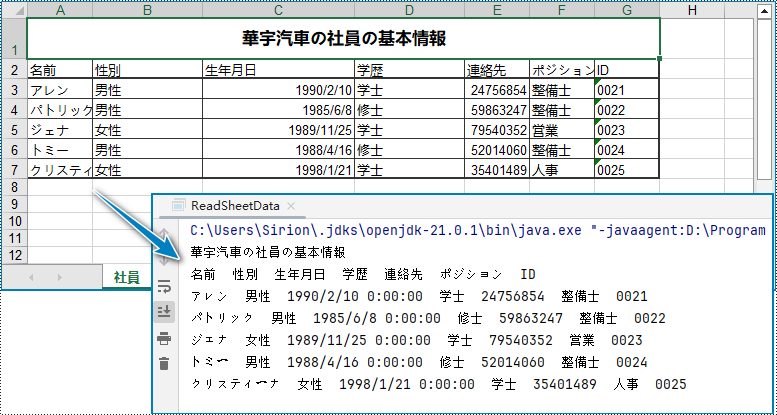
CellRange.getValue() メソッドは、セルの数値またはテキスト値を文字列として返します。ワークシート全体またはセル範囲のデータを取得するには、その中のセルをループします。以下は、Spire.XLS for Java を使用してワークシートのデータを取得する手順です。
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ReadSheetData {
public static void main(String[] args) {
//Workbookオブジェクトを作成
Workbook wb = new Workbook();
//既存のExcelファイルを読み込む
wb.loadFromFile("output/新しいワークブック.xlsx");
//最初のワークシートを取得
Worksheet sheet = wb.getWorksheets().get(0);
//データが含まれるセル範囲を取得
CellRange locatedRange = sheet.getAllocatedRange();
//行を反復処理
for (int i = 0; i < locatedRange.getRows().length; i++) {
//列を反復処理
for (int j = 0; j < locatedRange.getColumnCount(); j++) {
//特定のセルのデータを取得
System.out.print(locatedRange.get(i + 1, j + 1).getValue() + " ");
}
System.out.println();
}
wb.dispose();
}
}
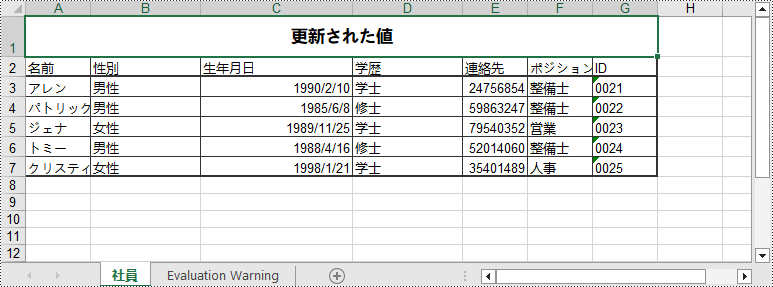
特定のセルの値を変更するには、Worksheet.getRange().setValue() メソッドを使用してセルの値を再設定します。以下はその詳細な手順です。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class UpdateCellValue {
public static void main(String[] args) {
//Workbookオブジェクトを作成
Workbook wb = new Workbook();
//既存のExcelファイルを読み込む
wb.loadFromFile("output/新しいワークブック.xlsx");
//最初のワークシートを取得
Worksheet sheet = wb.getWorksheets().get(0);
//特定のセルの値を変更
sheet.getRange().get("A1").setValue("更新された値");
//ファイルに保存
wb.saveToFile("output/セル値の更新.xlsx", ExcelVersion.Version2016);
wb.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Excel のウィンドウ枠の固定機能を使用すると、スクロール中に特定の行や列をロックすることができ、データセットのサイズに関係なく重要な情報が表示されたままになります。しかし、ペインの凍結を解除することが必要になる場合もあります。行や列の凍結を解除することで、ユーザーは大規模なデータセットをシームレスに操作できるようになり、包括的なデータ分析、編集、および書式設定が容易になります。凍結されたペインの内容は重要な情報であることが多く、凍結されたペインの範囲を取得できることで、この内容へのアクセスが容易になります。この記事では、Spire.XLS for Java を使用して、Java コードで Excel ワークシートのウィンドウ枠の固定を解除し、固定された行と列を取得する方法を示します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.7.4</version>
</dependency>
</dependencies>Spire.XLS for Java では、開発者は Workbook.getWorksheets().get() メソッドでワークシートを取得し、Worksheet.RemovePanes() メソッドでウィンドウ枠の固定を解除します。Excel ワークシートのウィンドウ枠の固定を解除する詳細な手順は、以下の通りです:
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class UnfreezePanes {
public static void main(String[] args) {
// Workbookクラスのオブジェクトを作成します
Workbook wb = new Workbook();
// Excelワークブックをロードします
wb.loadFromFile("サンプル.xlsx");
// 最初のワークシートを取得します
Worksheet sheet = wb.getWorksheets().get(0);
// ウィンドウ枠の固定を解除します
sheet.removePanes();
// ワークブックを保存します
wb.saveToFile("output/ウィンドウ枠固定の解除.xlsx");
wb.dispose();
}
}
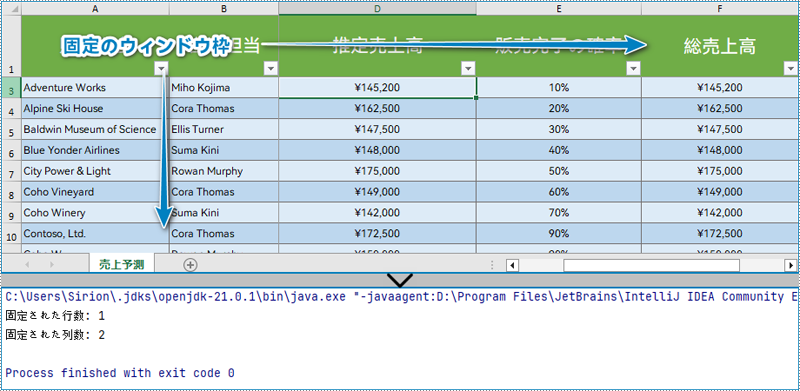
Spire.XLS for Java では、固定ウィンドウ枠の行インデックスと列インデックスを取得する Worksheet.getFreezePanes() メソッドを提供しています。取得されるパラメータは int リスト形式です: [int rowIndex, int columnIndex]。例えば、[1, 0] は最初の行が固定であることを示します。
固定ウィンドウ枠の行と列のパラメータを取得する詳細な手順は以下の通りです:
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class GetFrozenCellRange {
public static void main(String[] args) {
// Workbookクラスのオブジェクトを作成します
Workbook wb = new Workbook();
// Excelファイルをロードします
wb.loadFromFile("サンプル.xlsx");
// 最初のワークシートを取得します
Worksheet ws = wb.getWorksheets().get(0);
// 固定行と列のインデックスを取得します
int[] index = ws.getFreezePanes();
// 結果を出力します
System.out.println("固定された行数: " + index[0] + "\r\n固定された列数: " + index[1]);
wb.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Office Open XML(OOXML とも呼ばれる)は、Excel、Word、および Presentation ドキュメント用の、圧縮された XML ベースのフォーマットです。Excel ファイルをさまざまなアプリケーションやプラットフォームで読めるようにするために、Office Open XML に変換する必要がある場合があります。同様に、データ計算のために Office Open XML を Excel に変換したい場合もあるでしょう。この記事では、Spire.XLS for Java ライブラリを使用して、Java で Excel ファイルを Office Open XML に変換する方法と、Office Open XML を Excel ファイルに変換する方法について説明します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.7.4</version>
</dependency>
</dependencies>以下は、Excel ファイルを Office Open XML に変換する手順です:
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
public class ExcelToOOXML {
public static void main(String[] args) {
// Create an object of Workbook class
Workbook workbook = new Workbook();
// Load an Excel file
workbook.loadFromFile("Sample.xlsx");
// Save the Excel file to OOXML format
workbook.saveAsXml("output/ExcelToXML.xml");
workbook.dispose();
}
}
以下は、Office Open XML ファイルを Excel に変換する手順です:
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
public class OOXMLToExcel {
public static void main(String[] args) {
// Create an object of Workbook class
Workbook workbook = new Workbook();
// Load the source OOXML file
workbook.loadFromXml("Sample.xml");
// Save the file to an Excel workbook
workbook.saveToFile("output/XMLToExcel.docx", FileFormat.Version2016);
workbook.dispose();
}
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office for Java 9.3.1 のリリースをお知らせいたします。このバージョンには、いくつかの素晴らしい機能が含まれています。たとえば、Spire.PDF for Java では、PdfTextReplacer クラスが追加され、PDF のテキストの置換と InkAnnotation の追加がサポートされます。また、Spire.XLS for Java ではAI機能がサポートされ、Spire.Presentation for Java では段落に数式を追加する機能や形状の表示色を取得する機能がサポートされます。さらに、このバージョンでは多くの既知の問題が修正されています。詳細は以下に記載されています。
| カテゴリー | ID | 説明 |
| Improvement | SPIREDOC-10325 | Word を OFD に変換した後の結果ファイルのサイズを最適化しました。 |
| New feature | - | MergeImageFieldEventArgs イベントに setImageLink() を追加して、差し込み印刷画像へのハイパーリンクの追加をサポートします。
Document document = new Document();
document.loadFromFile(inputFile);
String[] fieldNames = new String[]{"ImageFile"};
String[] fieldValues = new String[]{inputFile_img};
document.getMailMerge().MergeImageField = new MergeImageFieldEventHandler() {
@Override
public void invoke(Object sender, MergeImageFieldEventArgs args) {
mailMerge_MergeImageField(sender, args);
}
};
document.getMailMerge().execute(fieldNames, fieldValues);
document.saveToFile(outputFile, FileFormat.Docx);
private static void mailMerge_MergeImageField(Object sender, MergeImageFieldEventArgs field) {
String filePath = field.getImageFileName();
if (filePath != null && !"".equals(filePath)) {
try {
field.setImage(filePath);
field.setImageLink("https://www.baidu.com/");
} catch (Exception e) {
e.printStackTrace();
}
} |
| New feature | SPIREDOC-9369 | getFieldOptions() メソッドを追加して、フィールド更新時のフィールド プロパティの設定をサポートします。
document.getFieldOptions().setCultureSource(FieldCultureSource.CurrentThread); |
| New feature | - | hasDigitalSignature() メソッドを追加して、ドキュメントにデジタル署名があるかどうかの判断をサポートします。
Document.hasDigitalSignature("filepath"); |
| New feature | SPIREDOC-9455 | integrateFontTableTo メソッドを追加して、ソースドキュメントからターゲットドキュメントへのFonttableデータのコピーをサポートします。
sourceDoc.integrateFontTableTo(Document destDoc); |
| New feature | SPIREDOC-9869 | HtmlUrlLoadEvent イベントを追加して、HTML ファイルをロードするときにファイル内の URL をロードする制御をサポートします。
public static void main(String[] args) {
Document document = new Document();
document.HtmlUrlLoadEvent = new MyDownloadEvent();
document.loadFromFile(inputFile, FileFormat.Html, XHTMLValidationType.None);
document.saveToFile(outputFile, FileFormat.PDF);
}
static class MyDownloadEvent extends HtmlUrlLoadHandler {
@Override
public void invoke(Object o, HtmlUrlLoadEventArgs htmlUrlLoadEventArgs) {
try {
byte[] bytes = downloadBytesFromURL(htmlUrlLoadEventArgs.getUrl());
htmlUrlLoadEventArgs.setDataBytes(bytes);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static byte[] downloadBytesFromURL(String urlString) throws Exception {
URL url = new URL(urlString);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setReadTimeout(5000);
int responseCode = connection.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
InputStream inputStream = connection.getInputStream();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
outputStream.close();
return outputStream.toByteArray();
} else {
throw new Exception("Failed to download content. Response code: " + responseCode);
}
} |
| New feature | - | setCustomFonts(InputStream[] fontStreamList) メソッドを追加して、ストリームによるカスタム フォントの設定をサポートします。
document.setCustomFonts(InputStream[] fontStreamList); |
| New feature | - | clearCustomFontsFolders() メソッドを新しい clearCustomFonts() メソッドに置き換えます。
document.clearCustomFonts(); |
| New feature | - | setGlobalCustomFontsFolders(InputStream[] fontStreamList) メソッドを新しい setGlobalCustomFonts(InputStream[] fontStreamList) メソッドに置き換えます。
Document.setGlobalCustomFonts(InputStream[] fontStreamList); |
| New feature | - | clearGlobalCustomFontsFolders() メソッドを新しい clearGlobalCustomFonts() メソッドに置き換えます。
Document.clearGlobalCustomFonts(); |
| カテゴリー | ID | 説明 |
| New feature | - | AIの機能をサポートし、ドキュメントの計算、範囲の結合、画像の生成、ファイルのアップロード、質問と翻訳をAIの支援で行うことができます。 |
| Bug | SPIREXLS-5096 | Excelドキュメントを解析する際にメモリ消費量が高くなる問題を最適化します。 |
| Bug | SPIREXLS-5136 | 直接ロードと保存後にExcelドキュメントを開く際にエラーが報告される問題を修正します。 |
| Bug | SPIREXLS-5138 | ワークシートテーブルをコピーした後に形状が失われる問題を修正します。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-4354 | PdfTextReplacerクラスを追加して、PDFのテキストを置換する機能をサポートします。
PdfDocument doc = new PdfDocument();
doc.loadFromFile("Input.pdf");
PdfPageBase page = doc.getPages().get(0);
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
textReplacer.replaceAllText("old", "NEW");
doc.saveToFile("output.pdf");
doc.dispose(); |
| New feature | SPIREPDF-6591 | PDFにInkAnnotationを追加する機能をサポートします。
PdfDocument doc = new PdfDocument();
PdfPageBase pdfPage = doc.getPages().add();
List<int[]> inkList = new ArrayList<>();
int[] intPoints = new int[]
{
100,800,
200,800,
200,700
};
inkList.add(intPoints);
PdfInkAnnotation ia = new PdfInkAnnotation(inkList);
ia.setColor(new PdfRGBColor(Color.RED));
ia.getBorder().setWidth(12);
ia.setText("e-iceblue");
((PdfNewPage) pdfPage).getAnnotations().add(ia);
doc.saveToFile("inkannotation.pdf"); |
| Bug | SPIREPDF-6606 | PDF署名の時間をシステムのローカル時間に合わせて最適化します。 |
| Bug | SPIREPDF-6548 | pdfDocument.getConformance()を使用して取得したPDFの種類が正しくない問題を修正します。 |
| Bug | SPIREPDF-6554 | setRowSpan()を2回使用すると"StackOverflow"例外が発生する問題を修正します。 |
| Bug | SPIREPDF-6581 | OFDをPDFに変換した後にコンテンツが失われる問題を修正します。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2210 | 段落に数式を追加する機能をサポートします。
Presentation ppt = new Presentation();
String latexMathCode="x^{2}+\\sqrt{x^{2}+1=2}";
IAutoShape shape=ppt.getSlides().get(0).getShapes().appendShape(ShapeType.RECTANGLE,new Rectangle2D.Float(30,100,400,200));
shape.getTextFrame().getParagraphs().clear();
ParagraphEx p=new ParagraphEx();
shape.getTextFrame().getParagraphs().append(p);
PortionEx portionEx=new PortionEx("Test");
p.getTextRanges().append(portionEx);
p.appendFromLatexMathCode(latexMathCode);
PortionEx portionEx2=new PortionEx("Hello");
p.getTextRanges().append(portionEx2);
ppt.saveToFile(outputFile, FileFormat.AUTO); |
| New feature | SPIREPPT-2422 | 図形の表示色を取得する機能をサポートします。
Presentation ppt = new Presentation();
ppt.loadFromFile("input.pptx");
IAutoShape shape = (IAutoShape)ppt.getSlides().get(0).getShapes().get(0);
System.out.println(shape.getDisplayFill().getFillType().getName());
System.out.println(shape.getDisplayFill().getSolidColor().getColor()); |
| Bug | SPIREPPT-2456 | ドキュメントをマージする際にアプリケーションが"DocumentEditException"をスローする問題を修正します。 |
喜んでお知らせいたしますが、Spire.Doc 12.3.12 のリリースがありました。このバージョンでは、Markdown ドキュメントの読み込みと操作、Word ドキュメントの Markdown 形式への変換がサポートされています。さらに、このバージョンでは、Word を PDF に変換する際にブックマークが正しく表示されない問題など、いくつかの既知の問題が修正されています。詳細は以下に記載されています。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-10091 SPIREDOC-10217 |
Markdown ドキュメントの読み込みと操作、または Word ドキュメントを Markdown に変換する機能をサポートします。
Document doc = new Document();
// .md ファイルの読み込み
doc.LoadFromFile("input.md");
// .md ファイルへの保存
//doc.SaveToFile("output.md", Spire.Doc.FileFormat.Markdown);
// .docx ファイルへの保存
//doc.SaveToFile("output.docx", Spire.Doc.FileFormat.Docx);
// .doc ファイルへの保存
//doc.SaveToFile("output.doc", Spire.Doc.FileFormat.Doc);
// .pdf ファイルへの保存
doc.SaveToFile("output.pdf", Spire.Doc.FileFormat.PDF);
doc.Close();
Document doc = new Document();
// .docx ファイルの読み込み
doc.LoadFromFile("input.docx");
// .doc ファイルの読み込み
//doc.LoadFromFile("input.doc");
// .md ファイルへの保存
doc.SaveToFile("output.md", Spire.Doc.FileFormat.Markdown);
doc.Close();
|
| Bug | SPIREDOC-10307 | Header.LinkToPrevious および Footer.LinkToPrevious の設定が反映されない問題を修正します。 |
| Bug | SPIREDOC-10316 | Word を PDF に変換した後、一部の内容が失われる問題を修正します。 |
| Bug | SPIREDOC-10328 | Word を PDF に変換した後、ブックマークが正しくない問題を修正します。 |
| Bug | SPIREDOC-10370 | ReplaceInLine メソッドが "System.NullReferenceException" をスローする問題を修正します。 |
Word ドキュメントのすべての段落では、意図的または非意図的に段落スタイルが使用されます。段落スタイルは、見出し1や見出し2などの組み込みスタイルであることもあれば、カスタマイズされたスタイルであることもあります。この記事では、Spire.Doc for Java を使用して、特定のスタイルを使用している段落を抽出する方法を紹介します。
下表は、MS Word のスタイル名と Spire.Doc のスタイル名の対応表です。非常に簡単なルールとして、プログラミングによって返されるスタイル名にはスペースが含まれません。
| MS Word のスタイル名 | Spire.Doc のスタイル名 |
| 表題 | Title |
| 副題 | Subtitle |
| 見出し1 | Heading1 |
| 見出し2 | Heading2 |
| 見出し3 | Heading3 |
| 行間詰め | NoSpacing |
| 引用文 | Quote |
| 引用文2 | IntenseQuote |
| リスト段落 | ListParagraph |
| 標準 | Normal |
| カスタム名 | CustomName |
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.3.1</version>
</dependency>
</dependencies>特定の段落のスタイル名は、Paragraph.getStyleName() メソッドで取得できます。段落のスタイル名がまさに照会したいものである場合は、Paragraph.getText() メソッドを使用して段落の内容を取得できます。以下は、特定のスタイルを使用している段落を抽出する手順です。
import com.spire.doc.Document;
import com.spire.doc.documents.Paragraph;
public class ExtractWordParagraphByStyle {
public static void main(String[] args) {
// Documentオブジェクトを初期化しながらサンプルのWordドキュメントをロードする
Document doc = new Document("サンプル.docx");
// 変数を宣言する
Paragraph paragraph;
// セクションをループする
for (int i = 0; i < doc.getSections().getCount(); i++) {
// 特定のセクションの段落をループする
for (int j = 0; j < doc.getSections().get(i).getParagraphs().getCount(); j++) {
// 特定の段落を取得する
paragraph = doc.getSections().get(i).getParagraphs().get(j);
// 段落のスタイルが「Heading 1」かどうかを判定する
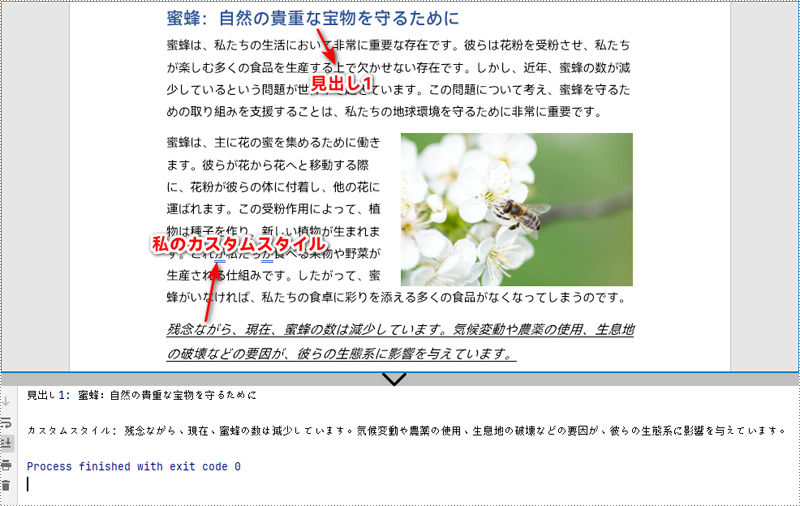
if (paragraph.getStyleName().equals("Heading1")) {
// 「Heading 1」の段落のテキストを取得する
System.out.println("見出し1: " + paragraph.getText() + "\n");
}
// 段落のスタイルが「My Custom Style」かどうかを判定する
if (paragraph.getStyleName().equals("私のカスタムスタイル")) {
// 「私のカスタムスタイル」の段落のテキストを取得する
System.out.println("カスタムスタイル: " + paragraph.getText());
}
}
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation 9.3.4をリリースしました。このバージョンでは、SVGへのPPTX変換オプションを設定するためのSaveToSvgOptionが追加され、また、PowerPointドキュメントのデフォルトのフォントスタイルを取得することをサポートしています。加えて、PDF / SVGにPPTXを変換するときに発生したいくつかの問題は、正常にファイルをロードして保存して修正されます。詳細については、以下の内容を参照してください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2445 | PowerPointドキュメントのデフォルトフォントスタイルの取得をサポートします。
byte[] svgByte = shape.SaveAsSvgInSlide();
FileStream fs = new FileStream("shapePath_" + num + ".svg", FileMode.Create);
fs.Write(svgByte, 0, svgByte.Length);
fs.Close(); |
| New feature | SPIREPPT-2451 | PPTXからSVGへの変換オプションを設定するためのSaveToSvgOptionを追加します。
Presentation ppt = new Presentation(); ppt.LoadFromFile(inputFile); ppt.SaveToSvgOption.SaveUnderlineAsDecoration = true; byte[] svgByte = ppt.Slides[0].Shapes[0].SaveAsSvgInSlide(); FileStream fs = new FileStream(outputFile + "1.svg", FileMode.Create); fs.Write(svgByte, 0, svgByte.Length); fs.Close(); |
| New feature | SPIREPPT-2459 | 背景図形を表示するために、ILayoutクラスにshowMasterShapesプロパティを追加します。
Presentation presentation = new Presentation(); presentation.LoadFromFile(@"in.pptx"); bool showMasterShape = presentation.Slides[1].Layout.ShowMasterShapes; |
| Bug | SPIREPPT-2443 | PPTXをSVGに変換するとき、グラデーションの色が正しくなかった問題を修正しました。 |
| Bug | SPIREPPT-2452 | PPTXをPDFに変換するとき、画質が劣化する問題を修正しました。 |
| Bug | SPIREPPT-2453 | ShapeをSVGに変換するとき、テキストスペースが失われる問題を修正しました。 |
| Bug | SPIREPPT-2454 | PPTXドキュメントを読み込んだり保存したりするときに、コンテンツが正しくなかった問題を修正しました。 |
Word ドキュメントからコンテンツを抽出することは、仕事でも勉強でも重要な役割を果たします。1 ページ分の内容を抽出すると、重要なポイントをすばやく閲覧して要約するのに役立ち、1 つのセクションから内容を抽出すると、特定のトピックやセクションを詳しく学習するのに役立ちます。ドキュメント全体を抽出することで、ドキュメントの内容を包括的に理解することができ、深い分析や包括的な理解が容易になります。この記事では、Java プロジェクトで Spire.Doc for Java を使用して Word ドキュメントのページ、セクション、コンテンツ全体を読み取る方法を紹介します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.3.1</version>
</dependency>
</dependencies>FixedLayoutDocument クラスと FixedLayoutPage クラスを使用すると、指定したページから内容を簡単に抽出することができます。抽出された内容を見やすくするために、次のコード例では、抽出された内容を新しい Word ドキュメントに保存しています。詳しい手順は以下の通りです:
import com.spire.doc.*;
import com.spire.doc.pages.*;
import com.spire.doc.documents.*;
public class readWordPage {
public static void main(String[] args) {
// 新しいドキュメントオブジェクトを作成する
Document document = new Document();
// 指定されたファイルからドキュメントの内容を読み込む
document.loadFromFile("サンプル.docx");
// 固定レイアウトドキュメントオブジェクトを作成する
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// 最初のページを取得する
FixedLayoutPage page = layoutDoc.getPages().get(0);
// ページが所属しているセクションを取得する
Section section = page.getSection();
// ページの最初の段落を取得する
Paragraph paragraphStart = page.getColumns().get(0).getLines().getFirst().getParagraph();
int startIndex = 0;
if (paragraphStart != null) {
// セクション内での段落のインデックスを取得する
startIndex = section.getBody().getChildObjects().indexOf(paragraphStart);
}
// ページの最後の段落を取得する
Paragraph paragraphEnd = page.getColumns().get(0).getLines().getLast().getParagraph();
int endIndex = 0;
if (paragraphEnd != null) {
// セクション内での段落のインデックスを取得する
endIndex = section.getBody().getChildObjects().indexOf(paragraphEnd);
}
// 新しいドキュメントオブジェクトを作成する
Document newdoc = new Document();
// 新しいセクションを追加する
Section newSection = newdoc.addSection();
// 元のセクションのプロパティを新しいセクションにクローンする
section.cloneSectionPropertiesTo(newSection);
// 元のドキュメントのページの内容を新しいドキュメントにコピーする
for (int i = startIndex; i <= endIndex; i++) {
newSection.getBody().getChildObjects().add(section.getBody().getChildObjects().get(i).deepClone());
}
// 新しいドキュメントを指定されたファイルに保存する
newdoc.saveToFile("output/ページの内容.docx", FileFormat.Docx);
// 新しいドキュメントを閉じて解放する
newdoc.close();
newdoc.dispose();
// 元のドキュメントを閉じて解放する
document.close();
document.dispose();
}
}
Document.Sections[index] プロパティを使用すると、ドキュメントのヘッダー、フッター、本文を含む特定のセクションクラスのオブジェクトにアクセスすることができます。次の例では、あるセクションのすべての内容を別のドキュメントにコピーする簡単な方法を示します。詳しい手順は以下のとおりです:
import com.spire.doc.*;
public class readWordSection {
public static void main(String[] args) {
// 新しいドキュメントオブジェクトを作成する
Document document = new Document();
// ファイルからWordドキュメントを読み込む
document.loadFromFile("サンプル.docx");
// ドキュメントの2番目のセクションを取得する
Section section = document.getSections().get(1);
// 新しいドキュメントオブジェクトを作成する
Document newdoc = new Document();
// デフォルトスタイルを新しいドキュメントにクローンする
document.cloneDefaultStyleTo(newdoc);
// 2番目のセクションを新しいドキュメントにクローンする
newdoc.getSections().add(section.deepClone());
// 新しいドキュメントをファイルに保存する
newdoc.saveToFile("output/セクションの内容.docx", FileFormat.Docx);
// 新しいドキュメントオブジェクトを閉じて解放する
newdoc.close();
newdoc.dispose();
// 元のドキュメントオブジェクトを閉じて解放する
document.close();
document.dispose();
}
}
この例では、元のドキュメントの各セクションを繰り返し処理して、ドキュメントの内容全体を読み取り、各セクションを新しいドキュメントにコピーする方法を示します。この方法は、ドキュメント全体の構造と内容の両方をすばやく複製し、新しいドキュメントで元のドキュメントの書式とレイアウトを保持するのに役立ちます。このような操作は、ドキュメント構造の整合性と一貫性を維持するために非常に便利です。詳しい手順は以下のとおりです:
import com.spire.doc.*;
public class readWordContent {
public static void main(String[] args) {
// 新しいドキュメントオブジェクトを作成する
Document document = new Document();
// ファイルからWordドキュメントを読み込む
document.loadFromFile("サンプル.docx");
// 新しいドキュメントオブジェクトを作成する
Document newdoc = new Document();
// デフォルトスタイルを新しいドキュメントにクローンする
document.cloneDefaultStyleTo(newdoc);
// 元のドキュメント内の各セクションをイテレーションし、新しいドキュメントにクローンする
for (Section sourceSection : (Iterable<Section>) document.getSections()) {
newdoc.getSections().add(sourceSection.deepClone());
}
// 新しいドキュメントをファイルに保存する
newdoc.saveToFile("output/ドキュメント内容.docx", FileFormat.Docx);
// 新しいドキュメントオブジェクトを閉じて解放する
newdoc.close();
newdoc.dispose();
// 元のドキュメントオブジェクトを閉じて解放する
document.close();
document.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





