チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Office 8.8.0のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.PDFは、PDFをWordに変換する際に同じフォント名を保持する機能とPDFのテキスト比較機能をサポートしています。Spire.Presentationでは、文書変換のためのデフォルトフォントリストをリセットするメソッドが追加されました。Spire.XLSでは、DIN A0の用紙サイズの設定やグレースケールの印刷がサポートされています。さらに、多くの既知の問題も修正しました。詳細は以下の内容を読んでください。
このバージョンでは、Spire.Doc,Spire.PDF,Spire.XLS,Spire.Email,Spire.DocViewer, Spire.PDFViewer,Spire.Presentation,Spire.Spreadsheet, Spire.OfficeViewer, Spire.Barcode, Spire.DataExportの最新バージョンが含まれています。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-3578 | PDFをWordに変換する際に同じフォント名を保持する機能がサポートされています。
PdfDocument doc = new PdfDocument();
//新しいページの追加
PdfPageBase page = doc.Pages.Add();
PdfGrid grid = new PdfGrid();
grid.Columns.Add(1);
PdfGridRow headerRow1 = grid.Headers.Add(1)[0];
//HEADER WITHOUT UNCICODE SUPPORT BUT VALID WORD FONT
headerRow1.Style.Font = new PdfTrueTypeFont(new Font("Arial", 11f, FontStyle.Regular), true);
headerRow1.Cells[0].Value = "Spire.PDF for .NET";
headerRow1.Cells[0].StringFormat = new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle);
grid.Draw(page, new PointF(0, 10));
//文書をストリームに保存する
MemoryStream stream = new MemoryStream();
doc.SaveToStream(stream, FileFormat.PDF);
stream.Position = 0L;
PdfToWordConverter converter = new PdfToWordConverter(stream);
converter.SaveToDocx(@"out.docx"); |
| New feature | SPIREPDF-4092 SPIREPDF-5734 |
PdfDocument doc = new PdfDocument(); doc.LoadFromFile(@"in.pdf"); PdfSecurityPolicy securityPolicy = new PdfPasswordSecurityPolicy(userPassword, ownerPassword); securityPolicy.EncryptMetadata = false; securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_128; securityPolicy.DocumentPrivilege = PdfDocumentPrivilege.AllowAll; securityPolicy.DocumentPrivilege.AllowPrint = false; doc.Encrypt(securityPolicy); doc.SaveToFile(@"out.pdf"); |
| New feature | - | PDFドキュメントのテキスト比較機能が追加されました。
PdfDocument pdf1 = new PdfDocument(inputFile_1); PdfDocument pdf2 = new PdfDocument(inputFile_2); PdfComparer compare = new PdfComparer(pdf1, pdf2); compare.Options.SetPageRanges(0, pdf1.Pages.Count - 1, 0, pdf2.Pages.Count - 1); compare.Compare(outputFile); |
| Bug | SPIREPDF-6113 | PDFをOFDに変換する際のリソース消費が多い問題が修正されました。 |
| Bug | SPIREPDF-6129 | PDFを画像に変換したり、PDFを印刷する際に、特定のヨーロッパ文字(ü ä ö)の表示が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6145 | 画像を取得する際に、プログラムがヌルポインタ例外を投げる問題が修正されました。 |
| Bug | SPIREPDF-6155 | 非表示署名を追加した後に、「Document Integrity Report」に余分なエラーメッセージが表示される問題が修正されました。 |
| Bug | SPIREPDF-6157 | テーブルを抽出する際に、プログラムが「System.Exception: Cannot create Graphics object from an image with an indexed pixel format」投げる問題が修正されました。 |
| Bug | SPIREPDF-2586 | PDFを画像に変換した後、コンテンツが失われる問題が修正されました。 |
| Bug | SPIREPDF-6013 | PDFファイルを印刷した後、テーブルの枠線が太くなる問題が修正されました。 |
| Bug | SPIREPDF-6057 | 変換後のPDFA3Bファイルを開いた際に、アプリケーションが「cannot extract the embedded font」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6072 | ファイルに透かしが追加された後に取得されたPDFページ数が正しくなくなった問題がが修正されました。 |
| Bug | SPIREPDF-6080 | PDFを画像に変換する際のメモリ消費が最適化されました。 |
| Bug | SPIREPDF-6086 | PDFファイルをロードする際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6088 | XPSファイルをロードする際に、アプリケーションが「System.IndexOutOfRangeException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6093 | PDFを画像に変換した後、結果が黒色になる問題が修正されました。 |
| Bug | SPIREPDF-6100 | PDFを画像に変換する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6126 | Formフィールドの削除メソッドが機能しない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | - | 文書変換のためのデフォルトフォントリストをリセットする機能が追加されました。
presentation.setDefaultFontName("华文行楷"); |
| New feature | - | システムにドキュメントで使用されるフォントがインストールされていない場合でも、PDFや画像などの形式を変換する際に、優先フォントの使用を設定する機能が追加されました。
presentation.resetDefaultFontName(); |
| Bug | SPIREPPT-2300 | PowerPointドキュメントを画像に変換する際にグラフが失われていた問題が修正されました。 |
| Bug | SPIREPPT-2302 | グラフデータを操作した後、結果ファイルが開けない問題が修正されました。 |
| Bug | SPIREPPT-2303 | PPTドキュメントを読み込む際に、アプリケーションが「Spire.Presentation.DocumentUnkownFormatException」をスローする問題が修正されました。 |
| Bug | SPIREPPT-2304 | ハイパーリンクのテキストの色を変更しても効果がない問題を修正しました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-288 | DIN A0の用紙サイズの設定がサポートされています。
sheet.PageSetup.PaperSize = PaperSizeType.PaperA0; |
| New feature | SPIREXLS-4725 | グレースケールの印刷がサポートされています。
workbook.ConverterSetting.GrayLevelForPrint = true; |
| New feature | SPIREXLS-4778 | XLSXからHTMLへの変換処理時間とメモリ使用量が最適化されています。 |
| Bug | SPIREXLS-722 | Excelを画像に変換した後、グラフが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4012 | 形状を画像に変換した後、内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4749 | デジタル署名を行う際に、アプリケーションが「System.Security.Cryptography.CryptographicException: 'Invalid algorithm specified'」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4768 | フォントの置き換えに失敗する問題が修正されました。 |
| Bug | SPIREXLS-4772 | 形状内のテキストを変更した後、スタイルが変わってしまう問題が修正されました。 |
| Bug | SPIREXLS-4773 | 複数のセルに数字形式を設定した後、セルの枠線が変更される問題が修正されました。 |
| Bug | SPIREXLS-4785 | ExcelをPDFに変換した後、週数の計算が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4787 | 形状を削除した後、PrstGeomShapesコレクションが更新されない問題が修正されました。 |
| Bug | SPIREXLS-4788 | ExcelをPDFに変換した後、余分な上枠線が表示される問題が修正されました。 |
| Bug | SPIREXLS-4793 | セルの条件付き書式を取得できない問題が修正されました。 |
| Bug | SPIREXLS-4795 | ExcelをPDFに変換した後、内容が一致しない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7603 | WordをPDFに変換した後、ヘッダーの改行問題が修正されました。 |
| Bug | SPIREDOC-9190 | WordをPDFに変換した後、ハイパーリンクが機能しない問題が修正されました。 |
| Bug | SPIREDOC-9422 | WordをPDFに変換した後、コンテンツのレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREDOC-9471 | 目次のページ番号が更新されない問題が修正されました。 |
| Bug | SPIREDOC-9463 | フィールド値の末尾に余分な「\r」が表示される問題が修正されました。 |
| Bug | SPIREDOC-9495 | 差し込みフィールドの値の更新が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9515 | HTMLをWordに変換した後、数式の表示が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9524 | ロードした文書を別名で保存した後、内容が失われる問題が修正されました。 |
| Bug | SPIREDOC-9558 | Latexの数式を追加した後、不等号の解析が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9563 | Latexの数式を追加した後、平行記号の解析が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9564 | Latexの数式を追加した後、ベクトル記号の位置が正しくない問題が修正されました。 |
Spire.XLS 13.8.0のリリースをお知らせできることをうれしく思います。このバージョンでは、DIN A0の用紙サイズの設定やグレースケールの印刷がサポートされています。XLSXからHTMLへの変換処理時間とメモリ使用量が最適化されています。さらに、ExcelからPDFや画像への変換機能も強化されました。また、多くの既知の問題もこのリリースで修正されました。たとえば、フォントの置き換えに失敗した問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-288 | DIN A0の用紙サイズの設定がサポートされています。
sheet.PageSetup.PaperSize = PaperSizeType.PaperA0; |
| New feature | SPIREXLS-4725 | グレースケールの印刷がサポートされています。
workbook.ConverterSetting.GrayLevelForPrint = true; |
| New feature | SPIREXLS-4778 | XLSXからHTMLへの変換処理時間とメモリ使用量が最適化されています。 |
| Bug | SPIREXLS-722 | Excelを画像に変換した後、グラフが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4012 | 形状を画像に変換した後、内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4749 | デジタル署名を行う際に、アプリケーションが「System.Security.Cryptography.CryptographicException: 'Invalid algorithm specified'」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4768 | フォントの置き換えに失敗する問題が修正されました。 |
| Bug | SPIREXLS-4772 | 形状内のテキストを変更した後、スタイルが変わってしまう問題が修正されました。 |
| Bug | SPIREXLS-4773 | 複数のセルに数字形式を設定した後、セルの枠線が変更される問題が修正されました。 |
| Bug | SPIREXLS-4785 | ExcelをPDFに変換した後、週数の計算が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4787 | 形状を削除した後、PrstGeomShapesコレクションが更新されない問題が修正されました。 |
| Bug | SPIREXLS-4788 | ExcelをPDFに変換した後、余分な上枠線が表示される問題が修正されました。 |
| Bug | SPIREXLS-4793 | セルの条件付き書式を取得できない問題が修正されました。 |
| Bug | SPIREXLS-4795 | ExcelをPDFに変換した後、内容が一致しない問題が修正されました。 |
Spire.Doc 11.7.25のリリースを発表できることを嬉しく思います。このバージョンでは、WordからPDFへの、HTMLからWordへの変換機能が強化されました。さらに、目次のページ番号が更新されない問題など、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7603 | WordをPDFに変換した後、ヘッダーの改行問題が修正されました。 |
| Bug | SPIREDOC-9190 | WordをPDFに変換した後、ハイパーリンクが機能しない問題が修正されました。 |
| Bug | SPIREDOC-9422 | WordをPDFに変換した後、コンテンツのレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREDOC-9471 | 目次のページ番号が更新されない問題が修正されました。 |
| Bug | SPIREDOC-9463 | フィールド値の末尾に余分な「\r」が表示される問題が修正されました。 |
| Bug | SPIREDOC-9495 | 差し込みフィールドの値の更新が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9515 | HTMLをWordに変換した後、数式の表示が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9524 | ロードした文書を別名で保存した後、内容が失われる問題が修正されました。 |
| Bug | SPIREDOC-9558 | Latexの数式を追加した後、不等号の解析が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9563 | Latexの数式を追加した後、平行記号の解析が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9564 | Latexの数式を追加した後、ベクトル記号の位置が正しくない問題が修正されました。 |
PowerPoint プレゼンテーションの背景は、プレゼンテーションの基調や雰囲気を設定し、スライドの美的センスや効果を大きく向上させることができます。PowerPoint プレゼンテーションには、単色背景、グラデーション背景、画像背景、テクスチャ背景、パターン背景の5種類の背景があり、それぞれ異なる使用シナリオに適用されます。例えば、プロのビジネスプレゼンテーションでは、クリーンでシンプルな単色背景が有効であり、クリエイティブなプレゼンテーションでは、魅力的で興味深い画像背景を使用して、観客の注意を引きつけることができます。この記事では、Spire.Presentation for Java を使って、Java プログラムで PowerPoint プレゼンテーションの背景を設定する方法を紹介します。
まず、Spire.Presentation for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>8.7.3</version>
</dependency>
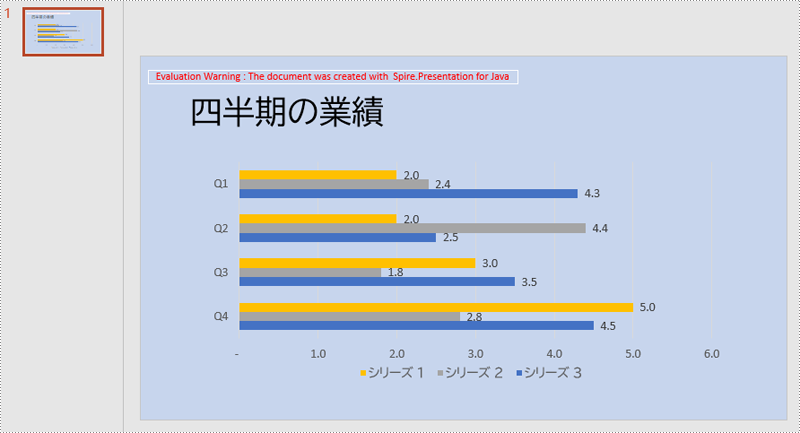
</dependencies>カスタムスライド背景を設定する前に、SlideBackground.setType(BackgroundType.CUSTOM) メソッドを使用して、カスタム背景の設定を許可する必要があります。次に、SlideBackground.getFill().setFillType(FillFormatType.SOLID) メソッドを使用して、背景の種類を単色背景に設定し、FileFormat.getSolidColor().setColor() メソッドを使用して、背景色を設定します。
具体的な操作手順は以下の通りです。
import com.spire.presentation.FileFormat;
import com.spire.presentation.ISlide;
import com.spire.presentation.Presentation;
import com.spire.presentation.SlideBackground;
import com.spire.presentation.drawing.BackgroundType;
import com.spire.presentation.drawing.FillFormat;
import com.spire.presentation.drawing.FillFormatType;
import java.awt.*;
public class SolidColor {
public static void main(String[] args) throws Exception {
//Presentationクラスのオブジェクトを作成する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションを読み込む
ppt.loadFromFile("サンプル.pptx");
//最初のスライドを取得する
ISlide slide = ppt.getSlides().get(0);
//スライドの背景を取得する
SlideBackground background = slide.getSlideBackground();
//背景タイプをカスタムに設定する
background.setType(BackgroundType.CUSTOM);
//背景の塗りつぶしタイプを単色に設定する
background.getFill().setFillType(FillFormatType.SOLID);
//背景色を設定する
FillFormat fillFormat = background.getFill();
fillFormat.getSolidColor().setColor(new Color(199, 213, 237));
//プレゼンテーションを保存する
ppt.saveToFile("単色背景.pptx", FileFormat.AUTO);
}
}
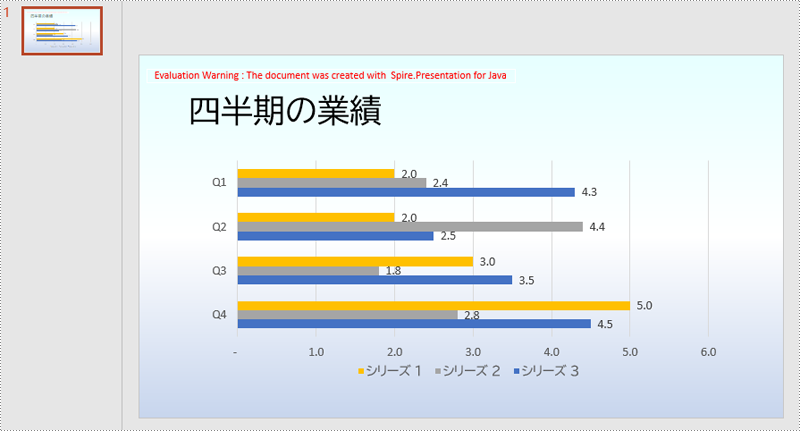
グラデーション背景は、背景タイプをグラデーション背景に設定し、グラデーションの種類、ストップポイント、色、および角度を設定することで設定できます。具体的な手順は以下の通りです。
import com.spire.presentation.FileFormat;
import com.spire.presentation.ISlide;
import com.spire.presentation.Presentation;
import com.spire.presentation.SlideBackground;
import com.spire.presentation.drawing.*;
import java.awt.*;
public class Gradient {
public static void main(String[] args) throws Exception {
//Presentationクラスのオブジェクトを作成する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションを読み込む
ppt.loadFromFile("サンプル.pptx");
//最初のスライドを取得する
ISlide slide = ppt.getSlides().get(0);
//スライドの背景を取得する
SlideBackground background = slide.getSlideBackground();
//背景タイプをカスタムに設定する
background.setType(BackgroundType.CUSTOM);
//背景の塗りつぶしタイプをグラデーションに設定する
background.getFill().setFillType(FillFormatType.GRADIENT);
//グラデーションの種類を線形グラデーションに設定する
GradientFillFormat gradient = background.getFill().getGradient();
gradient.setGradientShape(GradientShapeType.LINEAR);
//グラデーションのストップを追加し、色を設定する
gradient.getGradientStops().append(0f, new Color(230, 255, 255));
gradient.getGradientStops().append(0.5f, new Color(255, 255, 255));
gradient.getGradientStops().append(1f, new Color(199, 213, 237));
//グラデーションの角度を設定する
gradient.getLinearGradientFill().setAngle(90);
//プレゼンテーションを保存する
ppt.saveToFile("グラデーション背景.pptx", FileFormat.AUTO);
}
}
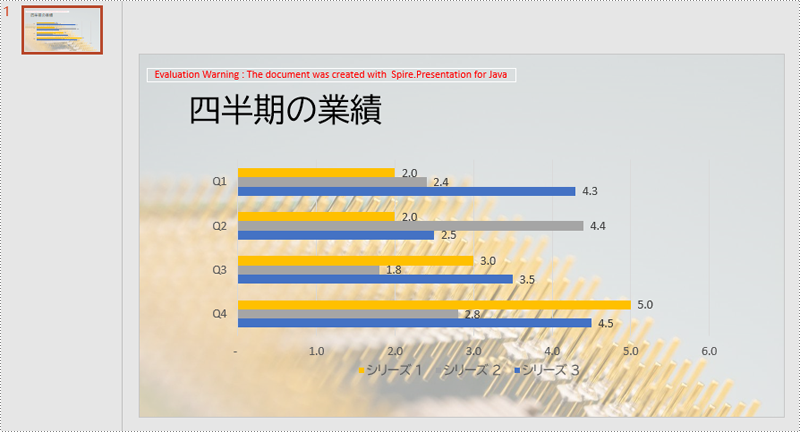
スライドの背景に画像を設定する場合、背景の種類を画像に設定し、次に画像の塗りつぶしタイプをストレッチ塗りつぶしに設定し、最後に背景画像を設定する必要があります。具体的な手順は以下の通りです。
import com.spire.presentation.FileFormat;
import com.spire.presentation.ISlide;
import com.spire.presentation.Presentation;
import com.spire.presentation.SlideBackground;
import com.spire.presentation.drawing.*;
import javax.imageio.ImageIO;
import java.io.File;
public class Picture {
public static void main(String[] args) throws Exception {
//Presentationクラスのオブジェクトを作成する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションを読み込む
ppt.loadFromFile("サンプル.pptx");
//画像を読み込む
IImageData image = ppt.getImages().append(ImageIO.read(new File("背景.jpg")));
//最初のスライドを取得する
ISlide slide = ppt.getSlides().get(0);
//スライドの背景を取得する
SlideBackground background = slide.getSlideBackground();
//背景タイプをカスタムに設定する
background.setType(BackgroundType.CUSTOM);
//背景の塗りつぶしタイプを画像に設定する
background.getFill().setFillType(FillFormatType.PICTURE);
//画像の塗りつぶしタイプをストレッチに設定する
PictureFillFormat pictureFillFormat = background.getFill().getPictureFill();
pictureFillFormat.setFillType(PictureFillType.STRETCH);
//画像背景の透明度を設定する
pictureFillFormat.getPicture().setTransparency(50);
//背景画像を設定する
pictureFillFormat.getPicture().setEmbedImage(image);
//プレゼンテーションを保存する
ppt.saveToFile("画像背景.pptx", FileFormat.AUTO);
}
}
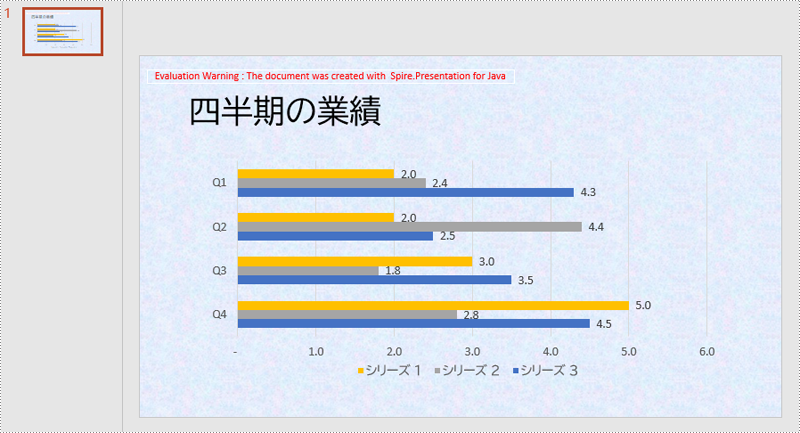
テクスチャの背景の設定は、画像背景の設定に似ています。 違いは、画像の塗りつぶしタイプをタイル状の塗りつぶしに変更する必要があることと、テクスチャの配置を設定できることです。 手順は以下の通りです。
import com.spire.presentation.*;
import com.spire.presentation.drawing.*;
import javax.imageio.ImageIO;
import java.io.File;
public class Texture {
public static void main(String[] args) throws Exception {
//Presentationクラスのオブジェクトを作成する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションを読み込む
ppt.loadFromFile("サンプル.pptx");
//テクスチャ画像を読み込む
IImageData image = ppt.getImages().append(ImageIO.read(new File("テクスチャ.png")));
//最初のスライドを取得する
ISlide slide = ppt.getSlides().get(0);
//スライドの背景を取得する
SlideBackground background = slide.getSlideBackground();
//背景タイプをカスタムに設定する
background.setType(BackgroundType.CUSTOM);
//背景の塗りつぶしタイプを画像に設定する
background.getFill().setFillType(FillFormatType.PICTURE);
//画像の塗りつぶしタイプをタイル状に設定する
PictureFillFormat pictureFillFormat = background.getFill().getPictureFill();
pictureFillFormat.setFillType(PictureFillType.TILE);
//テクスチャの配置を設定する
pictureFillFormat.setAlignment(RectangleAlignment.TOP_LEFT);
//テクスチャの背景の透明度を設定する
pictureFillFormat.getPicture().setTransparency(50);
//背景のテクスチャを設定する
pictureFillFormat.getPicture().setEmbedImage(image);
//プレゼンテーションを保存する
ppt.saveToFile("テクスチャの背景.pptx", FileFormat.AUTO);
}
}
パターン背景を設定する場合、パターンタイプとパターンの前景色と背景色を設定する必要があります。 詳しい手順は以下の通り。
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF 9.7.17のリリースを発表できることを嬉しく思います。このバージョンでは、PDFドキュメントのテキスト比較機能が追加されました。さらに、PDFをOFDに変換する際のリソース消費が多い問題など、いくつかの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | PDFドキュメントのテキスト比較機能が追加されました。
PdfDocument pdf1 = new PdfDocument(inputFile_1); PdfDocument pdf2 = new PdfDocument(inputFile_2); PdfComparer compare = new PdfComparer(pdf1, pdf2); compare.Options.SetPageRanges(0, pdf1.Pages.Count - 1, 0, pdf2.Pages.Count - 1); compare.Compare(outputFile); |
| Bug | SPIREPDF-6113 | PDFをOFDに変換する際のリソース消費が多い問題が修正されました。 |
| Bug | SPIREPDF-6129 | PDFを画像に変換したり、PDFを印刷する際に、特定のヨーロッパ文字(ü ä ö)の表示が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6145 | 画像を取得する際に、プログラムがヌルポインタ例外を投げる問題が修正されました。 |
| Bug | SPIREPDF-6155 | 非表示署名を追加した後に、「Document Integrity Report」に余分なエラーメッセージが表示される問題が修正されました。 |
| Bug | SPIREPDF-6157 | テーブルを抽出する際に、プログラムが「System.Exception: Cannot create Graphics object from an image with an indexed pixel format」投げる問題が修正されました。 |
Spire.PDF for Java 9.7.8のリリースを発表できることをうれしく思います。このバージョンでは、PDFからWordへの変換の新しいインターフェース、「クロップボックス」の設定インターフェース、および文書の印刷時に「Margins」の設定インターフェースが追加されました。PDFからWord、PDFA、およびOFDへの変換機能も強化されました。さらに、このバージョンではいくつかの既知の問題が修正されました。例えば、PDFを読み込む際にプログラムが「java.lang.NullPointerException」をスローした問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5843 SPIREPDF-5854 |
PDFからWordへの変換の新しいインターフェースが追加されました。
PdfToWordConverter converter = new PdfToWordConverter(inputPath); converter.saveToDocx(OutputPath); converter.dispose(); |
| New feature | SPIREPDF-6115 | 「クロップボックス」の設定インターフェースが追加されました。
PdfDocument pdfDocument = new PdfDocument();
pdfDocument.loadFromFile("input.pdf");
PdfPageBase pdfPageBase = pdfDocument.getPages().get(0);
// setting the "crop box".
pdfPageBase.setCropBox(new Rectangle2D.Float(0,0,400,800));
pdfDocument.saveToFile("output.pdf", FileFormat.PDF); |
| New feature | SPIREPDF-6167 | 文書の印刷時に「Margins」の設定インターフェースが追加されました。
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile(inputFile);
PrintSettings setting = pdf.getPrintSettings();
pdf.getPrintSettings().setPaperMargins(30,30, 30, 30);
setting.setPrinter("Microsoft XPS Document Writer");
pdf.getPrintSettings().printToFile(outputFile);
pdf.print();
pdf.close(); |
| Bug | SPIREPDF-3556 | PDFをWordに変換した後、グラフの座標軸の座標が失われる問題が修正されました。 |
| Bug | SPIREPDF-4980 | フローレイアウトでPDFをWordに変換した後、内容が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5047 | PDFをWordに変換した後、フォント名に余分な接尾辞が付く問題が修正されました。 |
| Bug | SPIREPDF-5067 | PDFをWordに変換した後、Office365で開くと文字化けする問題が修正されました。 |
| Bug | SPIREPDF-6085 | PDFを読み込む際に、プログラムが「java.lang.NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREPDF-6102 | PDFをPDFAに変換した後、文書を表示する際に必要なフォントが見つからないという警告が表示される問題が修正されました。 |
| Bug | SPIREPDF-6104 | PDFをSVGに変換した後、枠線が切り取られる問題が修正されました。 |
| Bug | SPIREPDF-6105 | PDFをPDFAに変換する際に、PdfDocument.setCustomFontsFolders()メソッドが無効になっていた問題が修正されました。 |
| Bug | SPIREPDF-6112 | PDFを読み込む際に、プログラムが「PDF file structure is not valid」をスローした問題が修正されました。 |
| Bug | SPIREPDF-6147 SPIREPDF-6175 |
PDFをOFDに変換した後、フォントの太字効果がわかりにくい問題が修正されました。 |
| Bug | SPIREPDF-6154 | 文書を結合してPDFA1Aに変換する際に、プログラムが「For input string: "e-"」をスローした問題が修正されました。 |
| Bug | SPIREPDF-6187 | 回転させた文書を元の位置に再度回転させる際に、プログラムが「NullPointerException」をスローした問題が修正されました。 |
Excel の図形は、テキストボックスや画像などのオブジェクトを含む、ワークシートを装飾または最適化できる視覚要素として機能します。図形を挿入することで、データをより直感的に表示し、重要な情報を強調し、スプレッドシートの可読性を高めることができます。図形内の内容を独立して扱う必要がある場合は、プログラムを使って図形から抽出してさらなる処理を行うことができます。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET で Excel の図形からテキストと画像を抽出する方法を紹介します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSSpire.XLS for .NET を使用すると、ユーザーは IPrstGeomShape.Text プロパティを使用して図形からテキストを抽出し、新しい .txt ファイルに書き込むことができます。以下は詳細な手順です。
using System.IO;
using System.Text;
using Spire.Xls;
using Spire.Xls.Core;
namespace Extracttext
{
class Program
{
static void Main(string[] args)
{
//Workbookオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.LoadFromFile("sample.xlsx");
//最初のシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//2番目の図形を取得してテキストを抽出する
IPrstGeomShape shape1 = sheet.PrstGeomShapes[1];
string s = shape1.Text;
//StringBuilderオブジェクトに抽出されたテキストをアタッチする
StringBuilder sb = new StringBuilder();
sb.AppendLine(s);
//テキストを.txtファイルに書き込む
File.WriteAllText("ShapeText.txt", sb.ToString());
workbook.Dispose();
}
}
}Imports System.IO
Imports System.Text
Imports Spire.Xls
Imports Spire.Xls.Core
Namespace Extracttext
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookオブジェクトを作成する
Dim workbook As Workbook = New Workbook
'Excelファイルをロードする
workbook.LoadFromFile("sample.xlsx")
'最初のシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'2番目の図形を取得してテキストを抽出する
Dim shape1 As IPrstGeomShape = sheet.PrstGeomShapes(1)
Dim s As String = shape1.Text
'StringBuilderオブジェクトに抽出されたテキストをアタッチする
Dim sb As StringBuilder = New StringBuilder
sb.AppendLine(s)
'テキストを.txtファイルに書き込む
File.WriteAllText("ShapeText.txt", sb.ToString)
workbook.Dispose
End Sub
End Class
End Namespace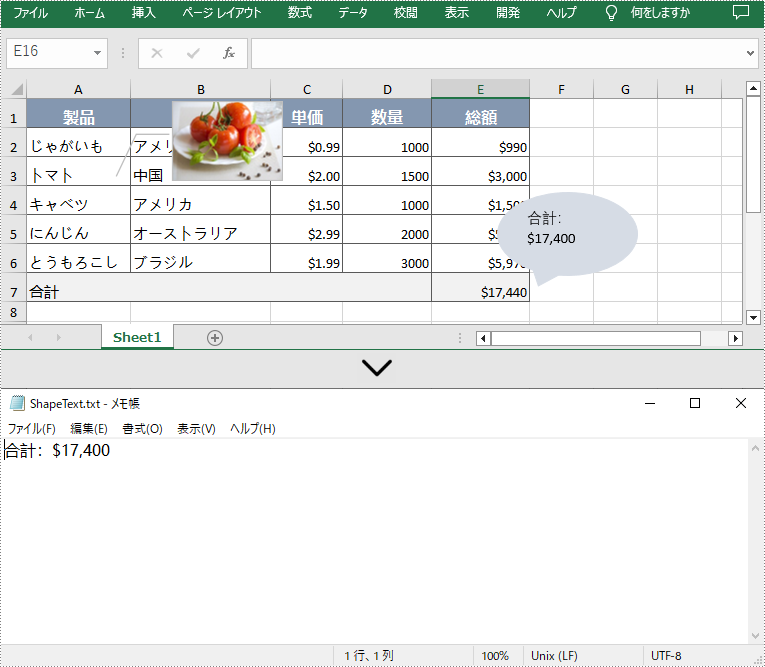
さらに、Spire.XLS for .NET では、IPrstGeomShape.Fill.Picture プロパティを使用して画像を抽出し、フォルダーに保存することもできます。関連する手順は次のとおりです。
using System.Drawing;
using System.Drawing.Imaging;
using Spire.Xls;
using Spire.Xls.Core;
namespace Extractimage
{
class Program
{
static void Main(string[] args)
{
//Workbookオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.LoadFromFile("sample.xlsx");
//最初のシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//最初の図形を取得して画像を抽出する
IPrstGeomShape shape2 = sheet.PrstGeomShapes[0];
Image image = shape2.Fill.Picture;
//抽出した画像をフォルダに保存する
image.Save(@"Image\ShapeImage.png", ImageFormat.Png);
workbook.Dispose();
}
}
}Imports System.Drawing
Imports System.Drawing.Imaging
Imports Spire.Xls
Imports Spire.Xls.Core
Namespace Extractimage
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookオブジェクトを作成する
Dim workbook As Workbook = New Workbook
'Excelファイルをロードする
workbook.LoadFromFile("sample.xlsx")
'最初のシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'最初の図形を取得して画像を抽出する
Dim shape2 As IPrstGeomShape = sheet.PrstGeomShapes(0)
Dim image As Image = shape2.Fill.Picture
'抽出した画像をフォルダに保存する
image.Save("Image\ShapeImage.png", ImageFormat.Png)
workbook.Dispose
End Sub
End Class
End Namespace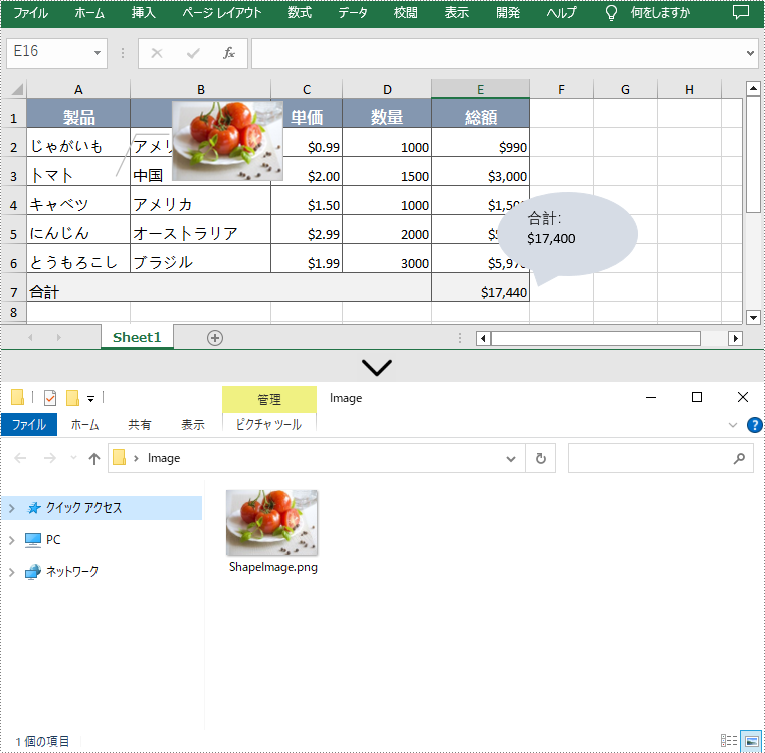
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation for Java 8.7.3を発表できることをうれしく思います。このバージョンは、複数のスライドを選択して1つのSVGファイルに結合して変換する機能が追加されました。また、PPTから画像への変換機能も強化されました。さらに、既知の問題のいくつかも修正されました。例えば、図形を画像に保存した後に内容が切り取られる問題などです。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2293 | 複数のスライドを選択して、1つのSVGファイルに結合して変換する機能が追加されました。
Presentation ppt = new Presentation();
ppt.loadFromFile("input.pptx");
//saveToOneSVG(int startSlide,int endSlide)
//startSlide:Start slide index endSlide:End slide index
byte[] bytes = ppt.saveToOneSVG(10,13);
FileOutputStream fos = new FileOutputStream(new File("result.svg"));
fos.write(bytes);
fos.flush();
fos.close(); |
| Bug | SPIREPPT-2269 | 図形を画像として保存した後、内容が切り取られる問題が修正されました。 |
| Bug | SPIREPPT-2283 | PPTを画像に変換した後、テキストのレイアウトが乱れる問題が修正されました。 |
| Bug | SPIREPPT-2295 | PICTURE_ORGANIZATION_CHARTですべてのノードを削除した後、手動で画像を追加する際に画像のプレースホルダーを取得できない問題が修正されました。 |
| Bug | SPIREPPT-2301 | PPTを結合した後、TXTの添付ファイルが開けない問題が修正されました。 |
Word ドキュメントのヘッダーとフッターは、ドキュメントページの上部と下部にそれぞれ配置され、ページ番号、ドキュメントタイトル、著者などの情報を表示します。しかし、ドキュメントを印刷したりオンラインで共有したりする場合、プライバシーを保護するためにこれらの情報を削除することが望ましい場合があります。さらに、ヘッダーとフッターは、印刷されたページの貴重なスペースを余分に占め、ドキュメントの全体的な書式を妨げる可能性があります。ヘッダーやフッターを削除することで、ページスペースを確保し、ドキュメントの書式が乱雑にならないようにすることができます。この記事では、Spire.Doc for Java を使用して、Java プログラムで Word ドキュメントからヘッダーとフッターを削除する方法を紹介します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.7.0</version>
</dependency>
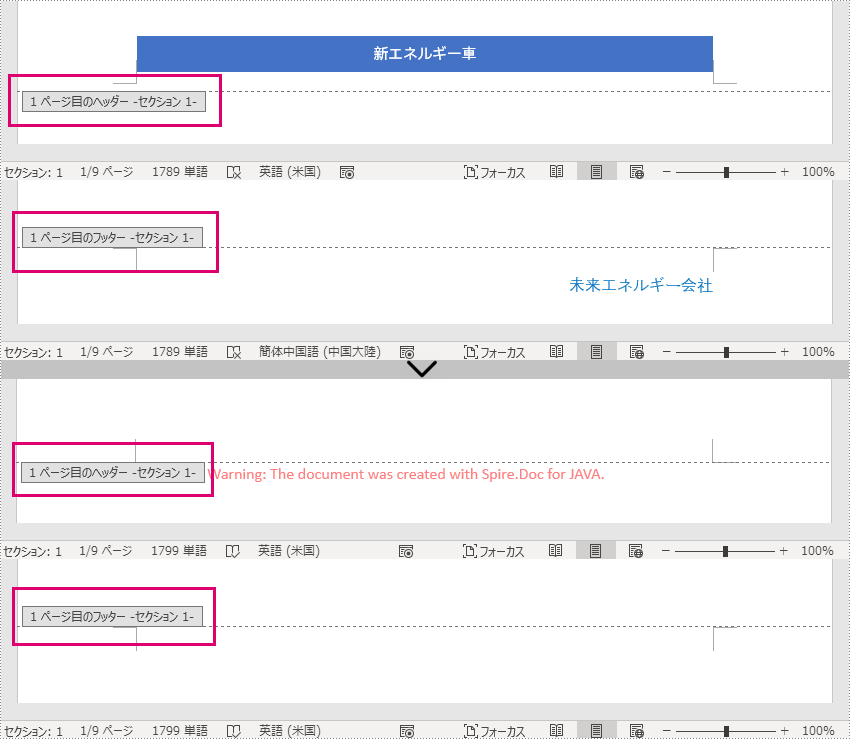
</dependencies>Word ドキュメントでは、最初のページ、奇数ページ、偶数ページに異なるヘッダーとフッターを設定することができます。これらのタイプのヘッダーとフッターは HeaderFooter.getByHeaderFooterType(hfType) メソッドで取得でき、 HeaderFooter.getChildObjects().clear() メソッドで削除できます。
以下に、列挙型と、それらが表すヘッダーとフッターのタイプのリストを示します。
| 列挙型 | 説明 |
| HeaderFooterType.Header_First_Page | 1ページ目のヘッダーを表します。 |
| HeaderFooterType.Footer_First_Page | 1ページ目のフッターを表します。 |
| HeaderFooterType.Header_Odd | 奇数ページのヘッダーを表します。 |
| HeaderFooterType.Footer_Odd | 奇数ページのフッターを表します。 |
| HeaderFooterType.Header_Even | 偶数ページのヘッダーを表します。 |
| HeaderFooterType.Footer_Even | 偶数ページのフッターを表します。 |
詳しい手順は以下の通り。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.HeaderFooter;
import com.spire.doc.Section;
import com.spire.doc.documents.HeaderFooterType;
public class removeHeaderFooter {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//ドキュメントの最初のセクションを取得する
Section section = doc.getSections().get(0);
//1ページ目のヘッダーを取得し、その内容を削除する
HeaderFooter header = section.getHeadersFooters().getByHeaderFooterType(HeaderFooterType.Header_First_Page);
header.getChildObjects().clear();
//1ページ目のフッターを取得し、その内容を削除する
HeaderFooter footer = section.getHeadersFooters().getByHeaderFooterType(HeaderFooterType.Footer_First_Page);
footer.getChildObjects().clear();
//奇数ページのヘッダーとフッターを取得し、その内容を消去する
//HeaderFooter header1 = section.getHeadersFooters().getByHeaderFooterType(HeaderFooterType.Header_Odd);
//header1.getChildObjects().clear();
//HeaderFooter footer1 = section.getHeadersFooters().getByHeaderFooterType(HeaderFooterType.Footer_Odd);
//footer1.getChildObjects().clear();
//偶数ページのヘッダーとフッターを取得し、その内容を消去する
//HeaderFooter header2 = section.getHeadersFooters().getByHeaderFooterType(HeaderFooterType.Header_Even);
//header2.getChildObjects().clear();
//HeaderFooter footer2 = section.getHeadersFooters().getByHeaderFooterType(HeaderFooterType.Footer_Even);
//footer2.getChildObjects().clear();
//ファイルを保存する
doc.saveToFile("ヘッダーとフッターの種類別に削除.docx", FileFormat.Auto);
doc.dispose();
}
}
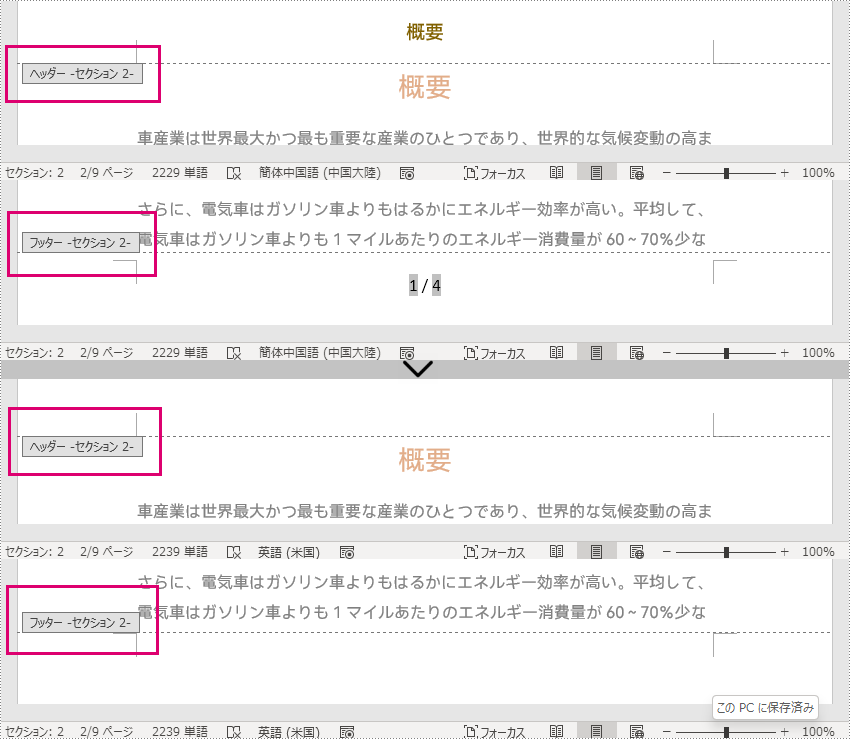
セクションによってヘッダーとフッターは異なります。あるセクションのヘッダーとフッターを削除するには、Document.getSections().get() メソッドでそのセクションを取得し、HeaderFooter.getChildObjects().clear() メソッドでその中のヘッダーとフッターを削除します。
注意しなければならないのは、セクション内のヘッダーとフッターの内容を削除すると、自動的に前のセクションの内容に変わってしまうということです。そのため、ヘッダーとフッターを削除した後に空白の段落を追加して、自動的に変更されないようにする必要があります。
詳しい手順は以下の通り。
import com.spire.doc.Document;
import com.spire.doc.HeaderFooter;
import com.spire.doc.Section;
public class removeHeaderFooterSection {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル1.docx");
//ドキュメントの2番目のセクションを取得する
Section section = doc.getSections().get(1);
//セクションのヘッダーを取得し、その内容を削除し、空白の段落を追加する
HeaderFooter header1 = section.getHeadersFooters().getHeader();
header1.getChildObjects().clear();
header1.addParagraph();
//セクションのフッターを取得し、その内容を削除し、空白の段落を追加する。
HeaderFooter footer1 = section.getHeadersFooters().getFooter();
footer1.getChildObjects().clear();
footer1.addParagraph();
//ファイルを保存する
doc.saveToFile("ヘッダーとフッターのセクション別に削除.docx");
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF を作成する際には、異なる状況に応じて適切なフォントを使用することが重要です。通常の PDF ファイルでは、Arial や Times New Roman などの一般的なフォントでテキストを描画できます。独自のビジュアルアイデンティティを持つ特徴的な PDF を作成したい場合は、プライベートフォントを使用することができます。この記事では、Spire.PDF for Java を使用して PDF にさまざまなフォントを適用する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.6.2</version>
</dependency>
</dependencies>Spire.PDF for Java は、標準フォント, TrueType フォント, 私有フォントおよび CJK フォントをサポートしています。以下は、これらのフォントを使用して PDF でテキストを描画する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
public class PdfFonts {
public static void main(String[] args) {
//PdfDocumentインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//ページを追加する
PdfPageBase page = pdf.getPages().add();
//ブラシを作成する
PdfBrush brush = PdfBrushes.getBlack();
//y座標を初期化する
float y = 30;
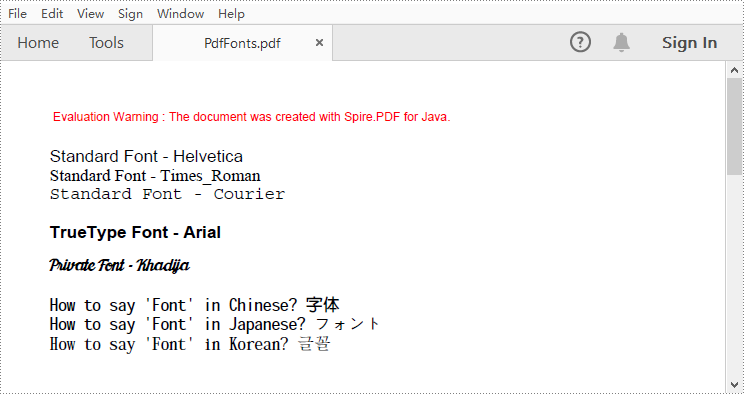
//標準フォントを使用してテキストを描画する
PdfFont standardFont = new PdfFont(PdfFontFamily.Helvetica, 14f);
page.getCanvas().drawString("Standard Font - Helvetica", standardFont, brush, 0, y);
standardFont = new PdfFont(PdfFontFamily.Times_Roman, 14f);
page.getCanvas().drawString("Standard Font - Times_Roman", standardFont, brush, 0, (y = y + 16));
standardFont = new PdfFont(PdfFontFamily.Courier, 14f);
page.getCanvas().drawString("Standard Font - Courier", standardFont, brush, 0, (y = y + 16));
//TrueTypeフォントを使用してテキストを描画する
java.awt.Font font = new java.awt.Font("Arial", java.awt.Font.BOLD, 14);
PdfTrueTypeFont trueTypeFont = new PdfTrueTypeFont(font);
page.getCanvas().drawString("TrueType Font - Arial", trueTypeFont, brush, 0, (y = y + 30f));
//私有フォントを使用してテキストを描画する
String fontFileName = "Khadija.ttf";
trueTypeFont = new PdfTrueTypeFont(fontFileName, 14f);
page.getCanvas().drawString("Private Font - Khadija", trueTypeFont, brush, 0, (y = y + 30f));
//CJKフォントを使用してテキストを描画する
PdfCjkStandardFont cjkFont = new PdfCjkStandardFont(PdfCjkFontFamily.Monotype_Hei_Medium, 14f);
page.getCanvas().drawString("How to say 'Font' in Chinese? \u5B57\u4F53", cjkFont, brush, 0, (y = y + 30f));
cjkFont = new PdfCjkStandardFont(PdfCjkFontFamily.Hanyang_Systems_Gothic_Medium, 14f);
page.getCanvas().drawString("How to say 'Font' in Japanese? \u30D5\u30A9\u30F3\u30C8", cjkFont, brush, 0, (y = y + 16f));
cjkFont = new PdfCjkStandardFont(PdfCjkFontFamily.Hanyang_Systems_Shin_Myeong_Jo_Medium, 14f);
page.getCanvas().drawString("How to say 'Font' in Korean? \uAE00\uAF34", cjkFont, brush, 0, (y = y + 16f));
//結果文書を保存する
pdf.saveToFile("PdfFonts.pdf");
pdf.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





