チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

他人がオンラインで共有する PowerPoint ドキュメントを使用するには、表示する前にパソコンにダウンロードする必要があります。しかし、プレゼンテーションが非常に大きい場合、ダウンロードプロセスは非常に煩雑で時間がかかります。PowerPoint を HTML に変換するのは、オンラインで直接プレゼンテーションを見るための良い解決策です。この記事では、Spire.Presentation for .NET を使用して、C# および VB.NET で PowerPoint を HTML に変換する方法を示します。
まず、Spire.Presentation for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PresentationSpire.Presentation for .NET では、Presentation.SaveToFile(string, FileFormat) メソッドを使用して、PowerPoint プレゼンテーションを PDF、XPS、HTML などの他のファイル形式に変換します。次の手順では、Spire.Presentation for .NET を使用して PowerPoint プレゼンテーションを HTML に変換する方法を示します。
using Spire.Presentation;
namespace ConvertPowerPointToHtml
{
class Program
{
static void Main(string[] args)
{
//Presentationクラスのインスタンスを初期化する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションをロードする
ppt.LoadFromFile(@"sample.pptx");
//HTMLを出力するファイルパスを指定する
string result = @"D:\output\PowerPointToHtml.html";
//PowerPointプレゼンテーションをHTML形式で保存する
ppt.SaveToFile(result, FileFormat.Html);
}
}
}Imports Spire.Presentation
Namespace ConvertPowerPointToHtml
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Presentationクラスのインスタンスを初期化する
Dim ppt As Presentation = New Presentation()
'PowerPointプレゼンテーションをロードする
ppt.LoadFromFile("sample.pptx")
'HTMLを出力するファイルパスを指定する
Dim result = "D:\output\PowerPointToHtml.html "
'PowerPointプレゼンテーションをHTML形式で保存する
ppt.SaveToFile(result, FileFormat.Html)
End Sub
End Class
End Namespace
場合によっては、プレゼンテーション全体ではなく、特定のスライドを HTML に変換する必要があります。Spire.Presentation は、PowerPoint スライドを HTML に変換する ISlide.SaveToFile(string, FileFormat) メソッドを提供しています。詳細な手順は次のとおりです。
using Spire.Presentation;
using System;
namespace ConvertPowerPointSlideToHtml
{
class Program
{
static void Main(string[] args)
{
//Presentationクラスのインスタンスを初期化する
Presentation presentation = new Presentation();
//PowerPointプレゼンテーションをロードする
presentation.LoadFromFile(@"sample.pptx");
//最初のスライドを取得する
ISlide slide = presentation.Slides[0];
//HTMLを出力するファイルパスを指定する
String result = @"D:\output\SlideToHtml.html";
//最初のスライドをHTML形式で保存する
slide.SaveToFile(result, FileFormat.Html);
}
}
}Imports Spire.Presentation
Namespace ConvertPowerPointSlideToHtml
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Presentationクラスのインスタンスを初期化する
Dim presentation As Presentation = New Presentation()
' PowerPointプレゼンテーションをロードする
presentation.LoadFromFile("sample.pptx")
'最初のスライドを取得する
Dim slide As ISlide = presentation.Slides(0)
'HTMLを出力するファイルパスを指定する
Dim result = "D:\output\SlideToHtml.html "
'最初のスライドをHTML形式で保存する
slide.SaveToFile(result, FileFormat.Html)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ドキュメントのプロパティは、タイトル、サブジェクト、作成者、管理者、会社名、分類、キーワード (タグとも呼ばれる)、コメントなど、ドキュメントと内容に関する一連の情報です。この情報はドキュメントには表示されませんが、ドキュメントを検索、ソート、選別するのに役立ちます。この記事では、Spire.Doc for Java を使用して Word にドキュメントのプロパティを追加する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.12.2</version>
</dependency>
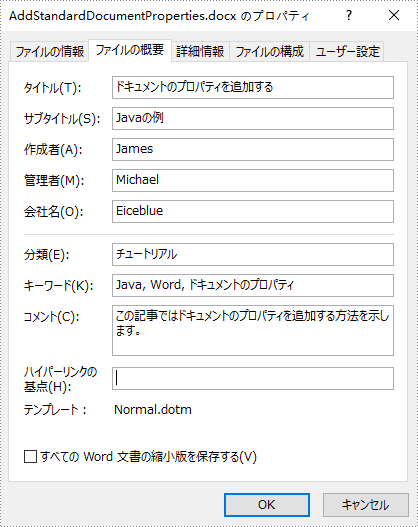
</dependencies>ビルトインドキュメントのプロパティ(標準ドキュメントのプロパティとも呼ばれる)は、名前と値で構成されています。Microsoft Word によって事前定義されているため、プロパティの名前を設定または変更することはできませんが、値を設定または変更することはできます。次に、Spire.Doc for Java を使用して Word にプロパティの値を設定する具体的な手順を示します。
import com.spire.doc.BuiltinDocumentProperties;
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class AddBuiltinDocumentProperties {
public static void main(String []args) throws Exception {
//Documentインスタンスを作成する
Document document = new Document();
//Wordドキュメントをロードする
document.loadFromFile("Sample.docx");
//ドキュメントのビルトインのプロパティにアクセスする
BuiltinDocumentProperties standardProperties = document.getBuiltinDocumentProperties();
//特定のプロパティの値を設定する
standardProperties.setTitle("ドキュメントのプロパティを追加する");
standardProperties.setSubject("Javaの例");
standardProperties.setAuthor("James");
standardProperties.setCompany("Eiceblue");
standardProperties.setManager("Michael");
standardProperties.setCategory("チュートリアル");
standardProperties.setKeywords("Java, Word, ドキュメントのプロパティ");
standardProperties.setComments("この記事ではドキュメントのプロパティを追加する方法を示します。");
//結果ドキュメントを保存する
document.saveToFile("AddStandardDocumentProperties.docx", FileFormat.Docx_2013);
}
}
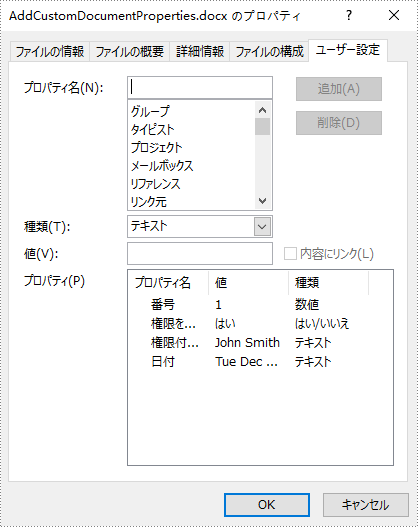
カスタムドキュメントのプロパティは、作成者またはユーザーによって定義できます。このプロパティには、名前と値とデータ型が含まれている必要があります。データ型は、「テキスト」、「数値」、「はい/いいえ」、「日付」の4つのタイプのいずれかになります。次に、Spire.Doc for Java を使用して Word に異なるデータ型のカスタムドキュメントプロパティを追加する具体的な手順を示します。
import com.spire.doc.CustomDocumentProperties;
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.util.Date;
public class AddCustomDocumentProperties {
public static void main(String []args) throws Exception {
//Documentインスタンスを作成する
Document document = new Document();
//Wordドキュメントをロードする
document.loadFromFile("Sample.docx");
//ドキュメントのカスタムのプロパティにアクセスする
CustomDocumentProperties customProperties = document.getCustomDocumentProperties();
//Wordに異なるデータ型のカスタムドキュメントプロパティを追加する
customProperties.add("番号", 1);
customProperties.add("権限を授ける", true);
customProperties.add("権限付与者", "John Smith");
customProperties.add("日付",new Date().toString());
//結果ドキュメントを保存する
document.saveToFile("AddCustomDocumentProperties.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
表は、情報やデータを水平方向の行と垂直方向の列の形で表現します。特にデータが数字で構成されていたり、サイズが大きい場合は、段落テキストにデータを入れるよりも表を作成した方が効果的です。表形式のデータ表示により、読みやすく、理解しやすくなります。この記事では、Spire.PDF for Java を使用して、Java で PDF 文書に表を作成する方法を説明します。
Spire.PDF for Java は、PDF ドキュメント内のテーブルを扱うために PdfTable と PdfGrid クラスを提供しています。PdfTable クラスは、あまり多くの書式を持たない簡単な、通常の表を素早く作成するために使用され、一方、PdfGrid クラスは、より複雑な表を作成するために使用されます。
下の表は、この2つのクラスの違いを示したものです。
| PdfTable | PdfGrid | |
| 書式設定 | ||
| 行 | イベントで設定可能。API は未対応。 | API で設定可能。 |
| 列 | API で設定可能。 | API で設定可能。 |
| セル | イベントで設定可能。API は未対応。 | API で設定可能。 |
| その他 | ||
| 列を跨ぐ | 対応していない。 | API で設定可能。 |
| 行を跨ぐ | イベントで設定可能。API は未対応。 | API で設定可能。 |
| ネストされた表 | イベントで設定可能。API は未対応。 | API で設定可能。 |
| イベント | BeginCellLayout, EndCellLayout, BeginRowLayout, EndRowLayout, BeginPageLayout, EndPageLayout. | BeginPageLayout, EndPageLayout. |
以下のセクションでは、PdfTable クラスと PdfGrid クラスを使って、それぞれ PDF に表を作成する方法を説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
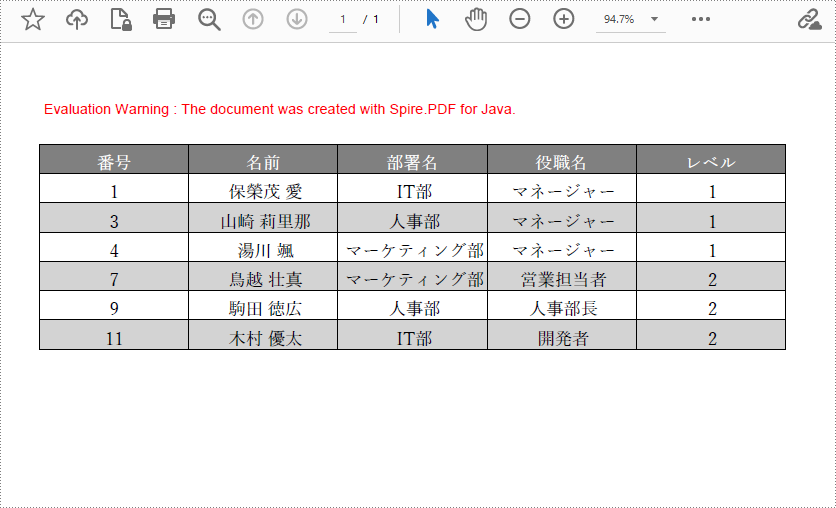
</dependencies>PdfTable クラスを使用して表を作成する手順を以下に示します。
import com.spire.data.table.DataTable;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.tables.*;
import java.awt.*;
import java.awt.geom.Point2D;
public class createTable {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(40));
//PdfTable クラスのオブジェクトを作成する
PdfTable table = new PdfTable();
//ヘッダーとそれ以外のセルのフォントを設定する
table.getStyle().getDefaultStyle().setFont(new PdfTrueTypeFont(new Font("Yu Mincho", Font.PLAIN, 12), true));
table.getStyle().getHeaderStyle().setFont(new PdfTrueTypeFont(new Font("Yu Mincho", Font.BOLD, 12), true));
//データを定義する
String[] data = {"番号;名前;部署名;役職名;レベル",
"1; 保榮茂 愛; IT部; マネージャー; 1",
"3; 山崎 莉里那; 人事部; マネージャー; 1",
"4; 湯川 颯; マーケティング部; マネージャー; 1",
"7; 鳥越 壮真; マーケティング部; 営業担当者; 2",
"9; 駒田 徳広; 人事部; 人事部長; 2",
"11; 木村 優太; IT部; 開発者; 2"};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
//データを表のデータとして設定する
table.setDataSource(dataSource);
//最初の行をヘッダー行として設定する
table.getStyle().setHeaderSource(PdfHeaderSource.Rows);
table.getStyle().setHeaderRowCount(1);
//ヘッダーの表示(デフォルトでは非表示)
table.getStyle().setShowHeader(true);
//ヘッダー列の文字色と背景色を設定する
table.getStyle().getHeaderStyle().setBackgroundBrush(PdfBrushes.getGray());
table.getStyle().getHeaderStyle().setTextBrush(PdfBrushes.getWhite());
//ヘッダー列のテキスト配置を設定する
table.getStyle().getHeaderStyle().setStringFormat(new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle));
//他のセルのテキスト配置を設定する
for (int i = 0; i < table.getColumns().getCount(); i++) {
table.getColumns().get(i).setStringFormat(new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle));
}
//BeginRowLayoutイベントに対応する
table.beginRowLayout.add(new BeginRowLayoutEventHandler() {
public void invoke(Object sender, BeginRowLayoutEventArgs args) {
Table_BeginRowLayout(sender, args);
}
});
//ページ上に表を描画する
table.draw(page, new Point2D.Float(0, 30));
//ドキュメントを保存する
doc.saveToFile("PDFの表.pdf");
}
//イベント処理
private static void Table_BeginRowLayout(Object sender, BeginRowLayoutEventArgs args) {
//行の高さを設定する
args.setMinimalHeight(20f);
//ヘッダー行以外の行の色を変更する
if (args.getRowIndex() == 0) {
return;
}
if (args.getRowIndex() % 2 == 0) {
args.getCellStyle().setBackgroundBrush(PdfBrushes.getLightGray());
} else {
args.getCellStyle().setBackgroundBrush(PdfBrushes.getWhite());
}
}
}
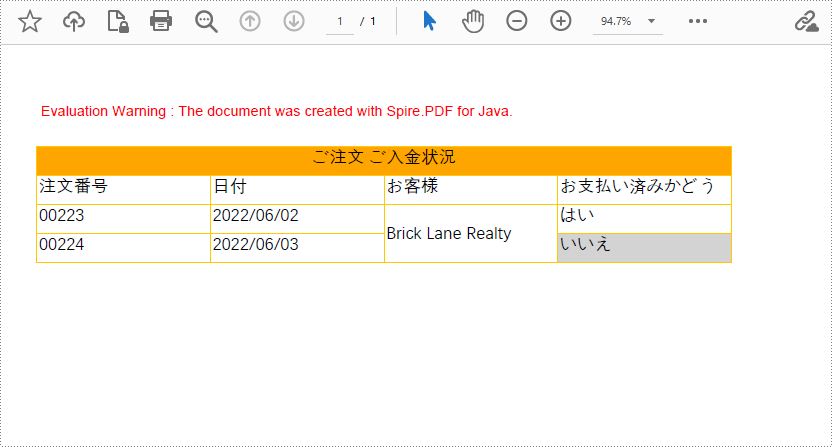
以下は、PdfGrid クラスを使用して PDF に表を作成する手順です。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.grid.PdfGrid;
import com.spire.pdf.grid.PdfGridRow;
import java.awt.*;
import java.awt.geom.Point2D;
public class createGrid {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//ページを追加する
PdfPageBase page = doc.getPages().add(PdfPageSize.A4,new PdfMargins(40));
//PdfGrid クラスのオブジェクトを作成する
PdfGrid grid = new PdfGrid();
//セルの余白を設定する
grid.getStyle().setCellPadding(new PdfPaddings(1, 1, 1, 1));
//フォントを設定する
grid.getStyle().setFont(new PdfTrueTypeFont(new Font("等线", Font.PLAIN, 12), true));
//行と列を追加する
PdfGridRow row1 = grid.getRows().add();
PdfGridRow row2 = grid.getRows().add();
PdfGridRow row3 = grid.getRows().add();
PdfGridRow row4 = grid.getRows().add();
grid.getColumns().add(4);
//列の幅を設定する
for (int i = 0; i < grid.getColumns().getCount(); i++) {
grid.getColumns().get(i).setWidth(120);
}
//特定のセルにデータを書き込む
row1.getCells().get(0).setValue("ご注文・ご入金状況");
row2.getCells().get(0).setValue("注文番号");
row2.getCells().get(1).setValue("日付");
row2.getCells().get(2).setValue ("お客様");
row2.getCells().get(3).setValue("お支払い済みかどうか");
row3.getCells().get(0).setValue("00223");
row3.getCells().get(1).setValue("2022/06/02");
row3.getCells().get(2).setValue("Brick Lane Realty");
row3.getCells().get(3).setValue("はい");
row4.getCells().get(0).setValue("00224");
row4.getCells().get(1).setValue("2022/06/03");
row4.getCells().get(3).setValue("いいえ");
//列をまたぐセルを配置する
row1.getCells().get(0).setColumnSpan(4);
//行をまたいでセルを配置する
row3.getCells().get(2).setRowSpan(2);
//特定のセルのテキスト配置を設定する
row1.getCells().get(0).setStringFormat(new PdfStringFormat(PdfTextAlignment.Center));
row3.getCells().get(2).setStringFormat(new PdfStringFormat(PdfTextAlignment.Left, PdfVerticalAlignment.Middle));
//特定のセルの背景色を設定する
row1.getCells().get(0).getStyle().setBackgroundBrush(PdfBrushes.getOrange());
row4.getCells().get(3).getStyle().setBackgroundBrush(PdfBrushes.getLightGray());
//セルの罫線の書式を設定する
PdfBorders borders = new PdfBorders();
borders.setAll(new PdfPen(new PdfRGBColor(Color.ORANGE), 0.8f));
for (int i = 0; i < grid.getRows().getCapacity(); i++) {
PdfGridRow gridRow = grid.getRows().get(i);
gridRow.setHeight(20f);
for (int j = 0; j < gridRow.getCells().getCount(); j++) {
gridRow.getCells().get(j).getStyle().setBorders(borders);
}
}
//ページ上に表を描画する
grid.draw(page, new Point2D.Float(0, 30));
//ドキュメントを保存する
doc.saveToFile("PDFグリッド.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF 8.12.5のリリースを発表できることを嬉しく思います。このバージョンでは、フォームドメインの可視と非表示プロパティの設定、カスタムメタデータの追加、PDFドキュメントのメタデータに新しい名前空間の追加をサポートします。今回の更新では、PDFからDOCXと画像への変換機能も強化されました。また、透かしを描画した後にテキストを検索して失敗した問題など、多くの問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-2352 | フォームドメインの可視と非表示プロパティの設定をサポートします。
Spire.Pdf.Fields.PdfField field = formWidget.FieldsWidget.List[0] as Spire.Pdf.Fields.PdfField; //field.AnnotationFlags = Spire.Pdf.Annotations.PdfAnnotationFlags.Default; // Setting visibility field.AnnotationFlags = Spire.Pdf.Annotations.PdfAnnotationFlags.Hidden; // Setting hidden |
| New feature | SPIREPDF-5495 | カスタムメタデータの追加をサポートします。
using(PdfDocument doc = new PdfDocument("1.pdf"))
{
using(Stream stream = new FileStream('1.xml',FileMode.Open))
{
doc.Metadata = PdfXmlMetadata.Parse(stream);
}
doc.SaveToFile('result.pdf');
} |
| New feature | SPIREPDF-5506 | PDFドキュメントのメタデータに新しい名前空間の追加をサポートします。
SPIREPDF-5506 PDFドキュメントのメタデータに新しい名前空間の追加をサポートします。
PdfXmlMetadata.RegisterNamespace("http://myRandomNamespace", "zf");
using(PdfDocument doc = new PdfDocument("1.pdf"))
{
doc.Metadata.SetPropertyString("http://myRandomNamespace", "test1","my test");
doc.SaveToFile('result.pdf');
}
PdfXmlMetadata.ResetNamespaces(); |
| Bug | SPIREPDF-5479 | プロパティoptions.IsShowHiddenText = falseを設定して隠しテキストを抽出しない問題が機能しなかった問題を修正します。 |
| Bug | SPIREPDF-5523 | PDFをdocxに変換した後の表の背景色が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5597 | 特殊文字の置換に失敗した問題が修正されました。 |
| Bug | SPIREPDF-5615 | PDF-Xchangerエディタに選択したボタンが表示されない問題が修正されました。 |
| Bug | SPIREPDF-5623 | 透かしを描画した後にテキストを検索できなかった問題が修正されました。 |
| Bug | SPIREPDF-5644 | PDFを画像に変換する際にアプリケーションが「Object reference not set to an instance of an object.」をスローする問題が修正されました。 |
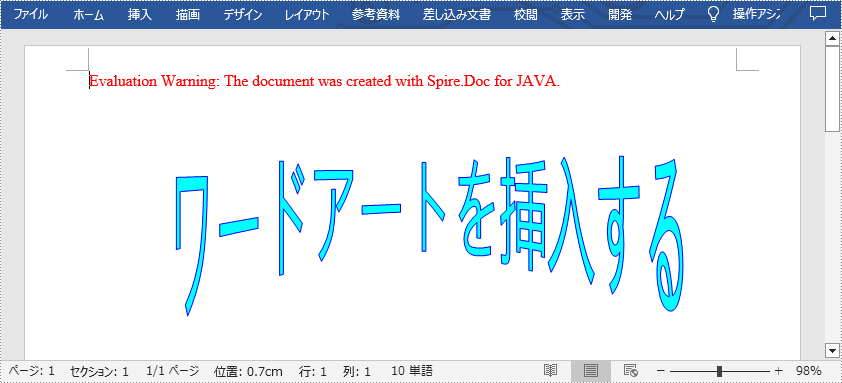
MS Word では、ワードアートはシャドウ、輪郭、色、グラデーション、3D 効果などの特殊な効果を持つテキストを挿入するためによく使用されます。スタイリッシュなタイトルを作成したり、特定のコンテンツをハイライト表示したりする際には、ワードアートを挿入するのが良い選択です。この記事では、Spire.Doc for Java を使用して Word にワードアートを挿入する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.11.6</version>
</dependency>
</dependencies>Spire.Doc for Java が提供する ShapeType 列挙は、「Text」で始まるさまざまな名前のワードアート形状タイプを定義しています。Word でワードアートを挿入するには、ShapeObject のインスタンスを初期化して、ワードアートのタイプとテキストの内容を指定します。具体的な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.ShapeObject;
import java.awt.*;
public class WordArt{
public static void main(String[] args) throws Exception {
//ドキュメントインスタンスを作成する
Document doc = new Document();
//セクションを追加する
Section section = doc.addSection();
//段落を追加する
Paragraph paragraph = section.addParagraph();
//段落に形状を追加し、形状のサイズとタイプを指定する
ShapeObject shape = paragraph.appendShape(400, 150, ShapeType.Text_Deflate_Bottom);
//形状の位置を設定する
shape.setVerticalPosition(60);
shape.setHorizontalPosition(60);
//ワードアートのテキストを設定する
shape.getWordArt().setText("ワードアートを挿入する");
//ワードアートの塗りつぶし色とストローク色を設定する
shape.setFillColor(Color.CYAN);
shape.setStrokeColor(Color.BLUE);
//ドキュメントを保存する
doc.saveToFile("WordArt.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PDF からテキストを抽出することは、特に日常的に何百もの PDF 文書を受け取っている場合には、困難な作業となることがあります。プログラムによるデータ抽出の自動化が必要になるのは、プログラムが文書を素早く大量に処理し、抽出された内容が絶対的に正確であることを保証するためです。この記事では、Spire.PDF for Java を使用して、検索可能な PDF 文書からテキストを抽出する方法について説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
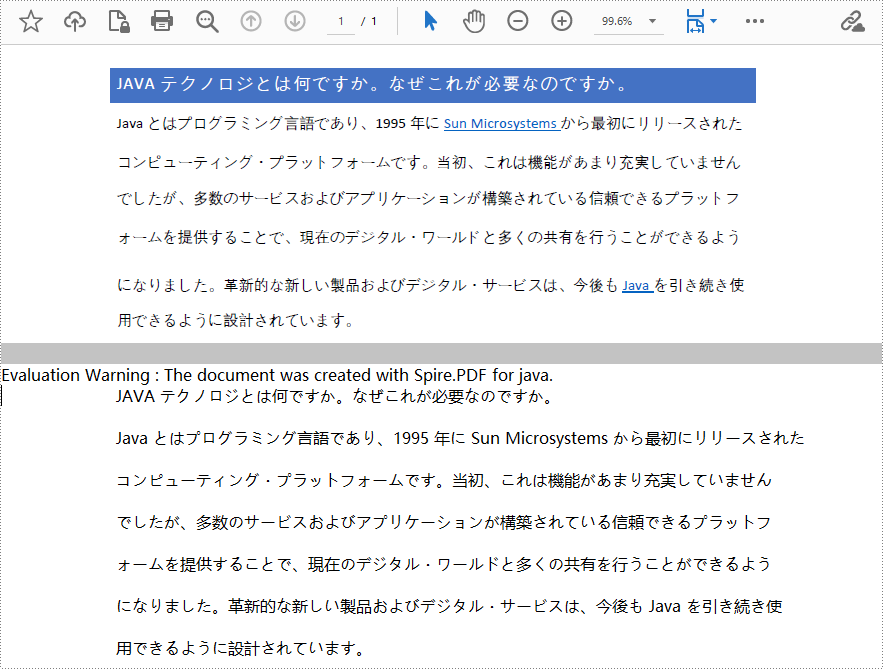
</dependencies>Spire.PDF for Java は、検索可能な PDF からテキストを抽出する PdfTextExtractor クラスと、抽出オプションを管理する PdfTextExtractOptions クラスを提供します。PdfTextExtractor.extract() メソッドは、デフォルトで特定の抽出オプションを指定する必要なく、指定されたページからすべてのテキストを抽出します。詳細な手順は以下のとおりです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class extractTextFromPage {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("Java.pdf");
//最初のページを表示する
PdfPageBase page = doc.getPages().get(0);
//PdfTextExtractor クラスオブジェクトを作成する
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//PdfTextExtractOptions クラスオブジェクトを作成する
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//ページ内のテキストを抽出する
String text = textExtractor.extract(extractOptions);
//テキストをtxtファイルに書き出す
Files.write(Paths.get("抽出されたテキスト.txt"), text.getBytes());
}
}
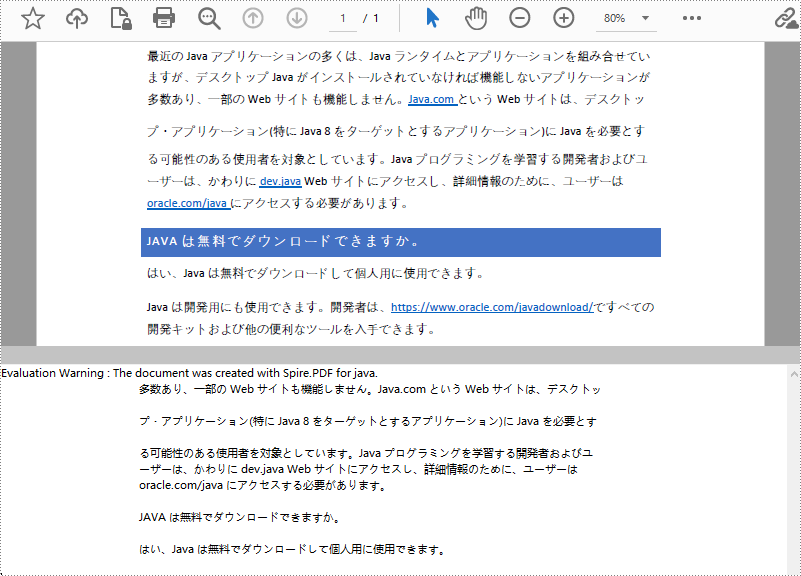
テキストを抽出する矩形領域を指定するには、PdfTextExtractOptions クラスの下にある setExtractArea() メソッドを使用する必要があります。次の手順は、Spire.PDF for Java を使用して、ページの矩形領域からテキストを抽出する方法を示しています。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.awt.geom.Rectangle2D;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class extractTextFromRectangleArea {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("Java.pdf");
//最初のページを取得する
PdfPageBase page = doc.getPages().get(0);
//PdfTextExtractor クラスのオブジェクトを作成する
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//PdfTextExtractOptions クラスのオブジェクトを作成する
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//矩形領域からテキストを抽出するオプションを設定する
Rectangle2D rectangle2D = new Rectangle2D.Float(0, 300, 890, 170);
extractOptions.setExtractArea(rectangle2D);
//指定した領域からテキストを抽出する
String text = textExtractor.extract(extractOptions);
//テキストをtxtファイルに書き出す
Files.write(Paths.get("抽出されたテキスト.txt"), text.getBytes());
}
}
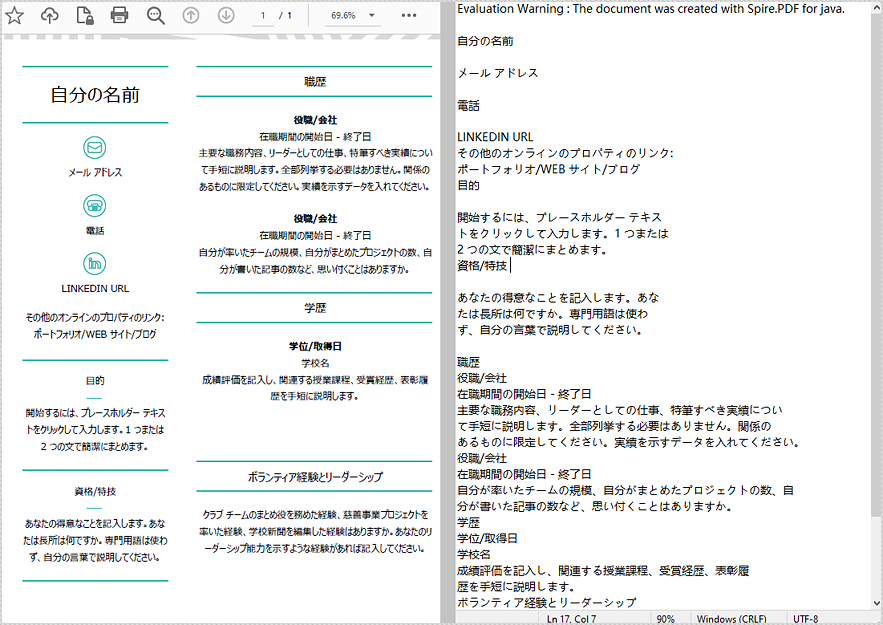
上記のメソッドは、テキストを一行ずつ抽出します。SimpleExtraction を使用してテキストを抽出する場合、各文字列の現在の垂直位置を記録し、垂直位置が変更された場合、出力に改行を挿入します。以下、詳細な手順を説明します。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class extractTextWithSimpleExtraction {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFファイルを読み込む
doc.loadFromFile("Java.pdf");
//最初のページを取得する
PdfPageBase page = doc.getPages().get(0);
//PdfTextExtractor クラスのオブジェクトを作成する
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//PdfTextExtractOptions クラスのオブジェクトを作成する
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//SimpleExtractionを有効にする
extractOptions.setSimpleExtraction(true);
//指定した領域からテキストを抽出する
String text = textExtractor.extract(extractOptions);
//抽出されたテキストをtxtファイルに書き出す
Files.write(Paths.get("抽出されたテキスト.txt"), text.getBytes());
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
スプレッドシートを他人と共有する場合、受け手に内容を変更されたくない、あるいは特定の内容だけを変更してもらい、残りの内容は変更しないでほしいという場合があります。ワークシートが他の人に編集されないように保護するために、Excel には保護機能が用意されています。この記事では、Spire.XLS for Java を使って、Java でプログラム的にワークブックまたはワークシートの保護と保護解除を行う方法について説明します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.8.4</version>
</dependency>
</dependencies>Excel ドキュメントをパスワードで暗号化することで、あなたや許可された人だけがそのドキュメントを読んだり編集したりできるようにすることができます。以下は、Spire.XLS for Java を使用してワークブックをパスワードで保護する手順です。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
public class passwordProtectWorkbook {
public static void main(String[] args) {
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込むc
workbook.loadFromFile("月間個人予算.xlsx");
//パスワードでワークブックを保護する
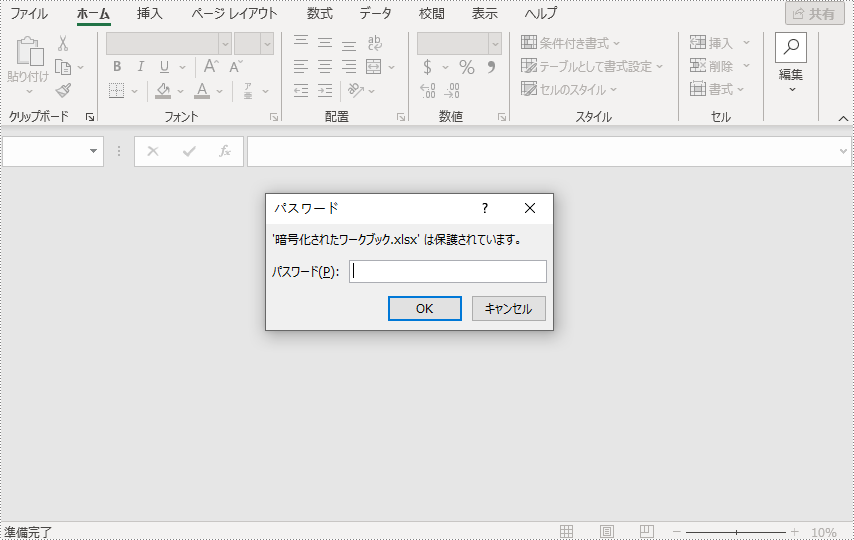
workbook.protect("e-iceblue");
//ワークブックを保存する
workbook.saveToFile("暗号化されたワークブック.xlsx", ExcelVersion.Version2016);
}
}
Excel 文書の閲覧は許可するが、ワークシートに加えることのできる変更の種類を制限したい場合、特定の保護タイプでワークシートを保護することができます。下の表は、SheetProtectionType クラスに含まれるさまざまな保護タイプの一覧です。
| 保護タイプ | 編集権限 |
| Content | コンテンツを変更または挿入する。 |
| DeletingColumns | 列を削除する。 |
| DeletingRows | 行を削除する。 |
| Filtering | フィルタを設定する。 |
| FormattingCells | セルの書式を設定する。 |
| FormattingColumns | 列の書式を設定する。 |
| FormattingRows | 行の書式を設定する。 |
| InsertingColumns | 列を挿入する。 |
| InsertingRows | 行を挿入する。 |
| InsertingHyperlinks | ハイパーリンクを挿入する。 |
| LockedCells | ロックされたセルを選択する。 |
| UnlockedCells | ロックされていないセルを選択する。 |
| Objects | 描画オブジェクトを編集する |
| Scenarios | 保存されたシナリオを編集する |
| Sorting | データを並べ替える。 |
| UsingPivotTables | ピボットテーブルとピボットチャートを使用する。 |
| All | 保護されたワークシート上で上記の操作を行う。 |
| None | 保護されたワークシート上で何もしない。 |
Spire.XLS for Java を使用して、特定の保護タイプでワークシートを保護する手順は次のとおりです。
import com.spire.xls.ExcelVersion;
import com.spire.xls.SheetProtectionType;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import java.util.EnumSet;
public class protectWorksheet {
public static void main(String[] args) {
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.loadFromFile("月間個人予算.xlsx");
//特定のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
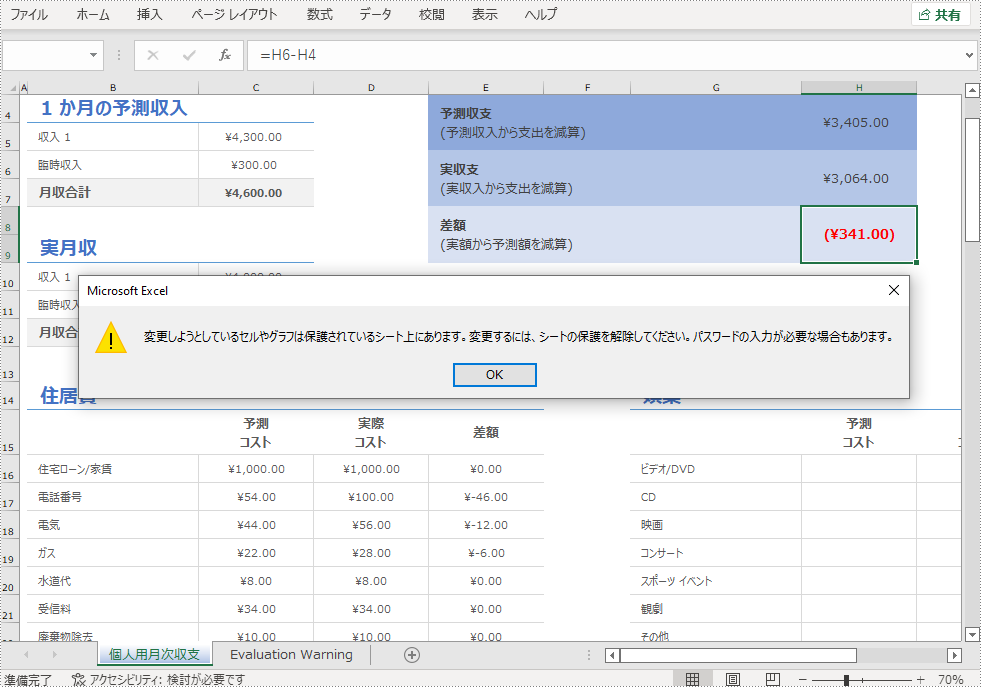
//権限パスワードと特定の保護タイプでワークシートを保護する
worksheet.protect("e-iceblue", EnumSet.of(SheetProtectionType.All));
//ワークブックを保存する
workbook.saveToFile("ワークシートの保護.xlsx", ExcelVersion.Version2016);
}
}
場合によっては、保護されたワークシートで選択された範囲をユーザーが編集できるようにする必要があるかもしれません。次の手順は、その方法を示しています。
import com.spire.xls.ExcelVersion;
import com.spire.xls.SheetProtectionType;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import java.util.EnumSet;
public class allowEditRanges {
public static void main(String[] args) {
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.loadFromFile("月間個人予算.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
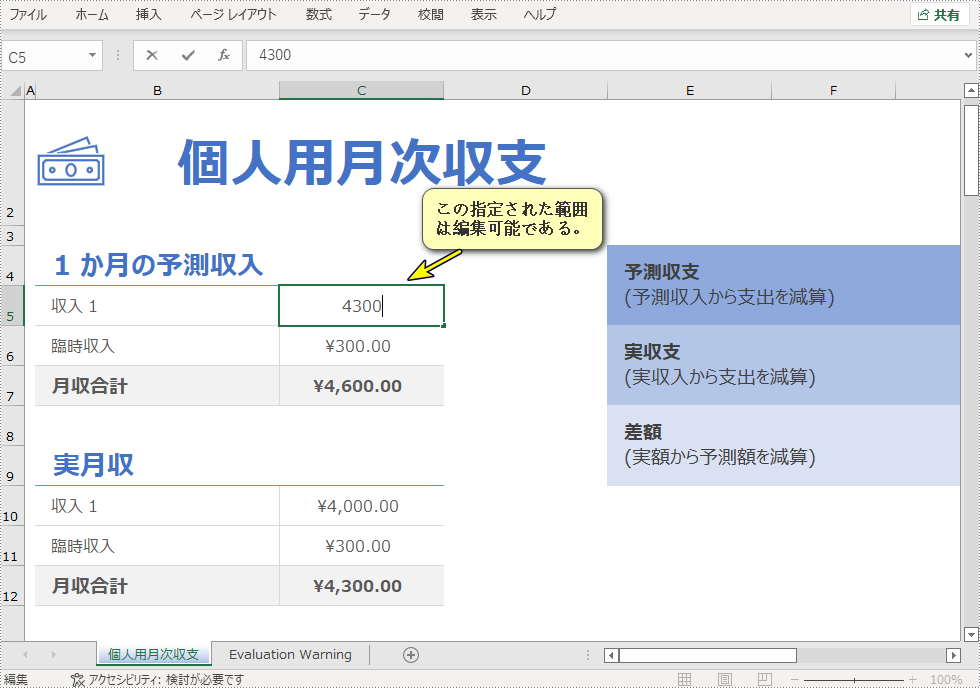
//編集可能な範囲を追加する
sheet.addAllowEditRange("範囲1", sheet.getRange().get("C5:C7"));
sheet.addAllowEditRange("範囲2", sheet.getRange().get("C10:C12"));
//パスワードと保護タイプでワークシートを保護する
sheet.protect("e-iceblue", EnumSet.of(SheetProtectionType.All));
//ワークブックを保存する
workbook.saveToFile("特定の範囲.xlsx", ExcelVersion.Version2016);
}
}
通常、ロックされたオプションは、ワークシート内のすべてのセルに対して有効になっています。そのため、セルまたはセル範囲をロックする前に、すべてのセルのロックを解除する必要があります。セルのロックは、ワークシートが保護されるまで有効でないことに注意してください。
Excel 特定のセルをロックする手順は次のとおりです。
import com.spire.xls.*;
import java.util.EnumSet;
public class lockCells {
public static void main(String []args){
//Workbookクラスのインスタンスを作成する
Workbook workbook = new Workbook();
//Excelファイルを読み込む
workbook.loadFromFile("月間個人予算.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
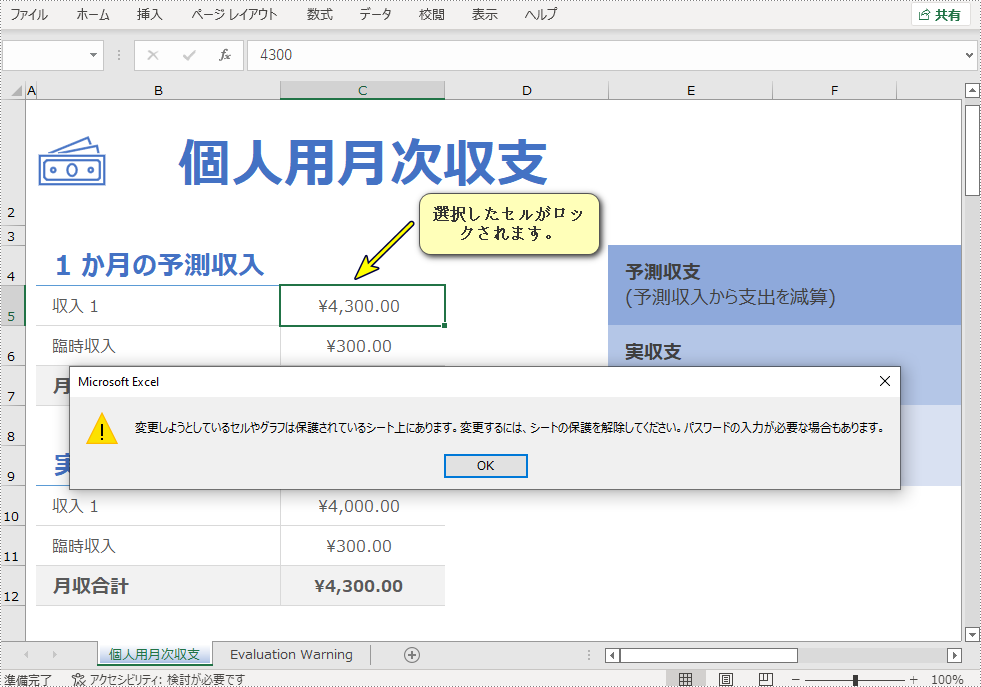
//ワークシートの使用中の範囲にあるすべてのセルのロックを解除する
CellRange usedRange = sheet.getRange();
usedRange.getStyle().setLocked(false);
//特定のセルをロックする
CellRange cells = sheet.getRange().get("C5:C6");
cells.getStyle().setLocked(true);
//ワークシートをパスワードで保護する
sheet.protect("e-iceblue", EnumSet.of(SheetProtectionType.All));
//ワークブックを保存する
workbook.saveToFile("セルのロック.xlsx", ExcelVersion.Version2016);
}
}
パスワードで保護されたワークシートの保護を解除するには、Worksheet.unprotect() ソッドを呼び出して、パスワードを使用する必要があります。詳細な手順は以下の通りです。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class unprotectWorksheet {
public static void main(String[] args) {
//Workbook クラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//保護されたワークシートを含む Excel ファイルを読み込む
workbook.loadFromFile("ワークシートの保護.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
//指定したパスワードでワークシートの保護を解除する
sheet.unprotect("e-iceblue");
//ワークブックを保存する
workbook.saveToFile("ワークシートの保護の解除.xlsx", ExcelVersion.Version2016);
}
}暗号化されたワークブックのパスワードを削除またはリセットするには、それぞれ Workbook.unprotect() メソッドおよび Workbook.protect() メソッドを使用できます。以下の手順では、暗号化された Excel ドキュメントを読み込み、そのパスワードを削除または変更する方法を説明します。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
public class removeResetPassword {
public static void main(String[] args) {
//Workbookクラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//ワークブックを開くためのパスワードを指定する
workbook.setOpenPassword("psd-123");
//暗号化されたExcelファイルを読み込む
workbook.loadFromFile("暗号化されたワークブック.xlsx");
//ワークブックの保護を解除する
workbook.unProtect();
//パスワードをリセットする
//workbook.protect("newpassword");
//ワークブックを保存する
workbook.saveToFile("パスワードの削除・再設定.xlsx", ExcelVersion.Version2016);
}
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
画像は、さまざまな文書で重要な役割を果たします。テキストでは表現しにくい複雑な情報を伝えたり、文書をより視覚的に魅力的なものにするために役立ちます。この記事では、Spire.PDF for Java を使用して、Java で PDF 文書に画像を挿入、置換、削除する方法を中心に説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.8</version>
</dependency>
</dependencies>PDF 文書に画像を挿入するには、画像を挿入する領域を指定し、そこ に PdfPageBase.getCanvas().drawImage() メソッドで画像を挿入する必要があります。
以下は、既存の PDF 文書に画像を挿入する手順です。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
public class insertImage {
public static void main(String []args){
//PdfDocumentクラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
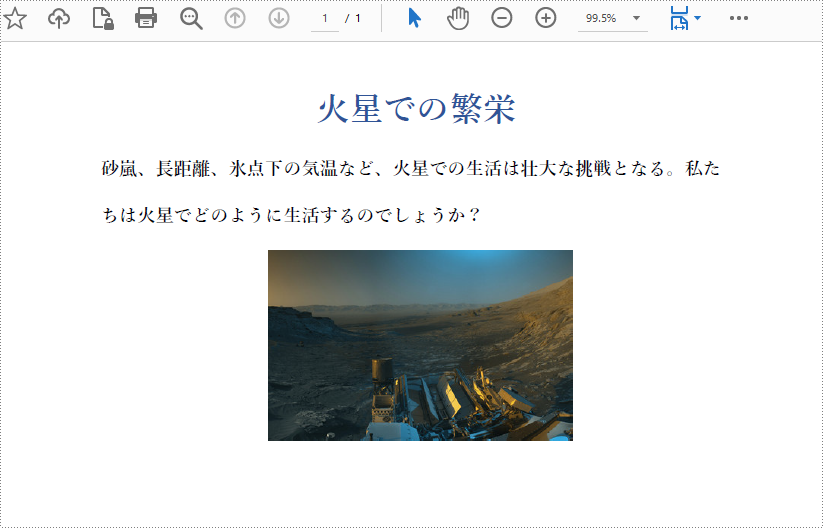
pdf.loadFromFile("火星での繁栄.pdf");
//PDF文書の最初のページを取得する
PdfPageBase page = pdf.getPages().get(0);
//画像を読み込む
PdfImage image = PdfImage.fromFile("火星表面の写真.jpg");
//ページ上の画像領域の幅と高さを指定する
float width = image.getWidth() * 0.50f;
float height = image.getHeight() * 0.50f;
//画像の描画を開始するX座標とY座標を指定する
float x = 200f;
float y = 200f;
//ページ上の指定した位置に画像を描画する
page.getCanvas().drawImage(image, x, y, width, height);
//ドキュメントを保存する
pdf.saveToFile("画像の挿入.pdf", FileFormat.PDF);
}
}
Spire.PDF for Java は、PDF 文書内の画像を簡単に新しい画像に置き換えるための PdfPageBase.replaceImage() メソッドを提供します。
以下の手順で、PDF 文書内の画像を別の画像に置き換える方法を説明します。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
public class replaceImage {
public static void main(String []args){
//PdfDocumentクラスのインスタンスを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントを読み込む
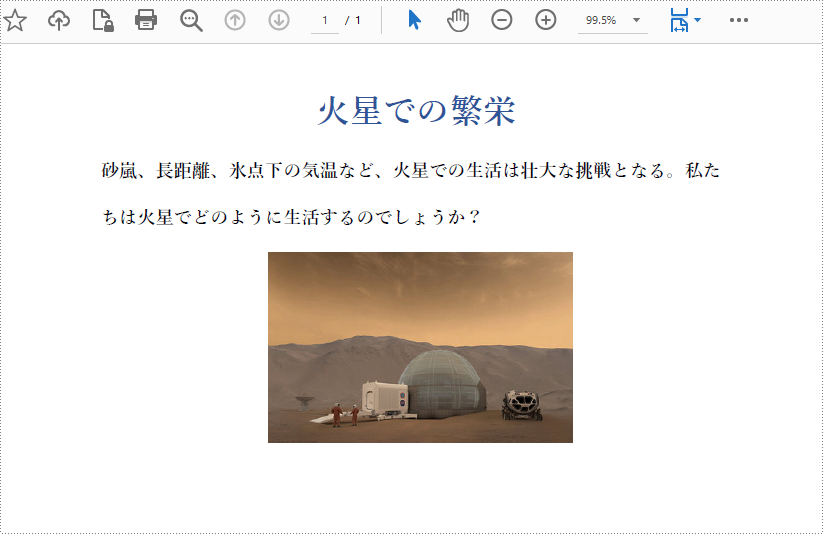
doc.loadFromFile("画像の挿入.pdf");
//最初のページを取得する
PdfPageBase page = doc.getPages().get(0);
//画像を読み込む
PdfImage image = PdfImage.fromFile("火星基地のイメージ図.jpg");
//ページの最初の画像を読み込んだ画像で置き換える
page.replaceImage(0, image);
//結果ドキュメントを保存する
doc.saveToFile("画像の置き換え.pdf", FileFormat.PDF);
}
}
PDF 文書内の画像を削除することも非常に簡単です。PdfPageBase.deleteImage() メソッドを使用すると、PDF ページ上の任意の画像を削除することができます。
以下の手順は、PDF 文書から画像を削除する方法を示しています。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
public class deleteImage {
public static void main(String []args){
//PdfDocumentクラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
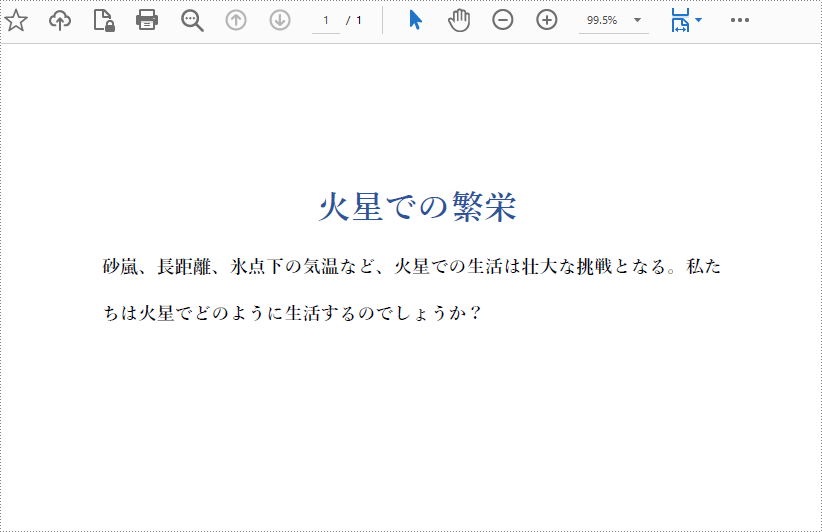
pdf.loadFromFile("画像の置き換え.pdf");
//最初のページを取得する
PdfPageBase page = pdf.getPages().get(0);
//ページ内の最初の画像を削除する
page.deleteImage(0);
//結果ドキュメントを保存する
pdf.saveToFile("画像の削除.pdf", FileFormat.PDF);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office for Java 7.12.2のリリースを発表できることをうれしく思います。今回のアップデートには、いくつかの新機能が含まれています。Spire.PDF for JavaはPdfTrueTypeFontオブジェクトの解放がサポートされました。Spire.Doc for JavaはWordからPDFと画像への変換機能とHTMLからWordへの変換機能が強化されました。Spire.XLS for JavaはExcelからPDFへの変換機能が強化されました。Spire.Presentation for JavaはPPTからSVGへの変換機能が強化されました。さらに、多くの既知のバグが正常に修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5590 | PdfTrueTypeFontオブジェクトの解放がサポートされました。
pdfTrueTypeFont.dispose(); |
| Bug | SPIREPDF-3959 | PDFをExcelに変換した後のセル線がマージされていない問題が修正されました。 |
| Bug | SPIREPDF-5505 | .pfx証明書ファイルを使用して署名したときに、証明書チェーン内のすべての証明書が署名に含まれていなかった問題が修正されました。 |
| Bug | SPIREPDF-5509 SPIREPDF-5583 |
抽出されたテーブルの内容が不完全である問題が修正されました。 |
| Bug | SPIREPDF-5540 | Mac OS環境でPDFを画像に変換した後の内容が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5582 | PDFを画像に変換した後に部分的に黒い長方形で表示されていた問題が修正されました。 |
| Bug | SPIREPDF-5585 | PDFを画像に変換した後に線が失われていた問題が修正されました。 |
| Bug | SPIREPDF-5594 | 設定ドロップダウンボックスに値が表示された後、WPSで出力されたPDFドキュメントを開く際に値が文字化けしてしまう問題が修正されました。 |
| Bug | SPIREPDF-5618 | PdfHorizontalOverflowType列挙タイプが混同されていた問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-4737 | WordをPDFに変換した後の段落の改行が一致しない問題が修正されました。 |
| Bug | SPIREDOC-5771 | WordをPDFに変換した後に表が重なる問題が修正されました。 |
| Bug | SPIREDOC-8031 | ファイルのマージ後にフォントサイズと段落間隔が変化した問題が修正されました。 |
| Bug | SPIREDOC-8306 | WordをPDFに変換するとコンテンツの位置がずれてしまう問題が修正されました。 |
| Bug | SPIREDOC-8362 | WordをPDFに変換したタイトルテキストがわずかに遮られている問題を修正しました。 |
| Bug | SPIREDOC-8375 | WordをPDFに変換した後のテーブル内の数字が重なる問題が修正されました。 |
| Bug | SPIREDOC-8536 | WordをPDFに変換した後のグラフの内容が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8560 | ファイルのマージ後にスタイルが失われていた問題が修正されました。 |
| Bug | SPIREDOC-8561 | WordをPDFに変換すると表に黒い枠が多くなる問題が修正されました。 |
| Bug | SPIREDOC-8565 | document.getText()を呼び出し、新しいファイルに保存した後に内容が変更された問題が修正されました。 |
| Bug | SPIREDOC-8631 | docxドキュメントをロードして保存した後、MS Wordで結果ドキュメントを開く際にプロンプト内容に誤りがあった問題が修正されました。 |
| Bug | SPIREDOC-8639 | 改訂を受け入れた後も文書の一部の内容が改訂されたままである問題が修正されました。 |
| Bug | SPIREDOC-8655 | WordをPDFに変換した後、表の内容の一部が黒い領域になっていた問題が修正されました。 |
| Bug | SPIREDOC-8669 | ドキュメントコンテンツコントロールのコンテンツを別のドキュメントにコピーする際に、アプリケーションが「An element with the same key already exists in the dictionary」とスローした問題が修正されました。 |
| Bug | SPIREDOC-8678 | WordをPDFに変換した結果文書の行の高さが、WPSでWordをPDFに変換した結果文書の行の高さよりも大きい問題が修正されました。 |
| Bug | SPIREDOC-8692 | WordをPDFに変換すると表中の画像が重複する問題が修正された。 |
| Bug | SPIREDOC-8711 | ドキュメントの比較効果が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8753 | WordをPDFに変換した後の単語間のスペースが欠落していた問題が修正されました |
| Bug | SPIREDOC-8743 | HTMLをWordに変換する際にアプリケーションが「class com.spire.doc.packages.sprdwr:Unknown format」をスローした問題が修正されました。 |
| Bug | SPIREDOC-8744 | 段落スタイルを変更した際に、フォントが変化した問題が修正されました。 |
| Bug | SPIREDOC-8761 | ファイルのロード時にアプリケーションが「The string contains invalid characters」をスローした問題が修正されました。 |
| Bug | SPIREDOC-8767 | Wordを画像に変換する際にアプリケーションが「NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-8774 | ページ余白の設定が無効になっていた問題が修正されました。 |
| Bug | SPIREDOC-8821 | Wordから変換されたTiffファイルが占有状態にあり、2回目の操作ができない問題が修正されました。 |
| Bug | SPIREDOC-8831 | WordをPDFに変換した後のテキスト文字化けの問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4154 SPIREXLS-4190 |
ExcelをPDFに変換した後の内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4166 | ExcelをPDFに変換する際にアプリケーションが「java.lang.ClassCastException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4181 | ExcelをPDFに変換した後のフォント変更の問題が修正されました。 |
| Bug | SPIREXLS-4198 | Excelファイルをロードするときにアプリケーションが「java.lang.OutOfMemoryError」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4208 | ExcelをPDFに変換した後にグラフが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4241 | セルに入力されたデータが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4250 | ExcelをPDFに変換した後のコンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4257 | ExcelをPDFに変換する際にアプリケーションが「Index is less than 0 or more than or equal to the list count.」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4261 | InserArrayを呼び出してint配列を挿入するとスタックがオーバーフローする問題が修正されました。 |
| Bug | SPIREXLS-4264 | グラフの枠線をフィレットに設定しても機能しない問題が修正されました。 |
| Bug | SPIREXLS-4266 | ドキュメントのマージ後にセルスタイルが変更された問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPPT-2085 | PPTをSVGに変換した後にコンテンツスタイルが変更された問題が修正されました。 |
| Bug | SPIREPPT-2099 | PPTをSVGに変換した後の形状の線のグラデーションが失われる問題が修正されました。 |
| Bug | SPIREPPT-2101 | PPTドキュメントをロードする際にアプリケーションが「Index must be>=0 and<=Count」をスローした問題が修正されました。 |
| Bug | SPIREPPT-2102 | PPTをPDFに変換した後にアプリケーションがハングアップした問題が修正されました。 |
| Bug | SPIREPPT-2108 | PPTをSVGに変換するとコンテンツが失われる問題が修正されました。 |
Spire.Doc for Java 10.12.2のリリースを発表できることを嬉しく思います。このバージョンは、WordからPDFと画像への変換機能、HTMLからWordへの変換機能が強化されました。また、この更新では、ファイルのマージ後にフォントサイズと段落間隔が変化したなど、多くの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-4737 | WordをPDFに変換した後の段落の改行が一致しない問題が修正されました。 |
| Bug | SPIREDOC-5771 | WordをPDFに変換した後に表が重なる問題が修正されました。 |
| Bug | SPIREDOC-8031 | ファイルのマージ後にフォントサイズと段落間隔が変化した問題が修正されました。 |
| Bug | SPIREDOC-8306 | WordをPDFに変換するとコンテンツの位置がずれてしまう問題が修正されました。 |
| Bug | SPIREDOC-8362 | WordをPDFに変換したタイトルテキストがわずかに遮られている問題を修正しました。 |
| Bug | SPIREDOC-8375 | WordをPDFに変換した後のテーブル内の数字が重なる問題が修正されました。 |
| Bug | SPIREDOC-8536 | WordをPDFに変換した後のグラフの内容が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8560 | ファイルのマージ後にスタイルが失われていた問題が修正されました。 |
| Bug | SPIREDOC-8561 | WordをPDFに変換すると表に黒い枠が多くなる問題が修正されました。 |
| Bug | SPIREDOC-8565 | document.getText()を呼び出し、新しいファイルに保存した後に内容が変更された問題が修正されました。 |
| Bug | SPIREDOC-8631 | docxドキュメントをロードして保存した後、MS Wordで結果ドキュメントを開く際にプロンプト内容に誤りがあった問題が修正されました。 |
| Bug | SPIREDOC-8639 | 改訂を受け入れた後も文書の一部の内容が改訂されたままである問題が修正されました。 |
| Bug | SPIREDOC-8655 | WordをPDFに変換した後、表の内容の一部が黒い領域になっていた問題が修正されました。 |
| Bug | SPIREDOC-8669 | ドキュメントコンテンツコントロールのコンテンツを別のドキュメントにコピーする際に、アプリケーションが「An element with the same key already exists in the dictionary」とスローした問題が修正されました。 |
| Bug | SPIREDOC-8678 | WordをPDFに変換した結果文書の行の高さが、WPSでWordをPDFに変換した結果文書の行の高さよりも大きい問題が修正されました。 |
| Bug | SPIREDOC-8692 | WordをPDFに変換すると表中の画像が重複する問題が修正された。 |
| Bug | SPIREDOC-8711 | ドキュメントの比較効果が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8753 | WordをPDFに変換した後の単語間のスペースが欠落していた問題が修正されました |
| Bug | SPIREDOC-8743 | HTMLをWordに変換する際にアプリケーションが「class com.spire.doc.packages.sprdwr:Unknown format」をスローした問題が修正されました。 |
| Bug | SPIREDOC-8744 | 段落スタイルを変更した際に、フォントが変化した問題が修正されました。 |
| Bug | SPIREDOC-8761 | ファイルのロード時にアプリケーションが「The string contains invalid characters」をスローした問題が修正されました。 |
| Bug | SPIREDOC-8767 | Wordを画像に変換する際にアプリケーションが「NullPointerException」をスローした問題が修正されました。 |
| Bug | SPIREDOC-8774 | ページ余白の設定が無効になっていた問題が修正されました。 |
| Bug | SPIREDOC-8821 | Wordから変換されたTiffファイルが占有状態にあり、2回目の操作ができない問題が修正されました。 |
| Bug | SPIREDOC-8831 | WordをPDFに変換した後のテキスト文字化けの問題が修正されました。 |





