チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Doc for Java 10.9.0 のリリースを発表できることを嬉しく思います。 このバージョンは、Word から PDF への変換機能が強化されました。また、このリリースでは、DOC から DOCX 2007 に変換されたときにコンテンツの配置が不一致などの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-7704 | Word で PDF を変換する際に、otf形式のプライベートフォントを設定した後にアプリケーションが「IllegalArgumentException」をスローする問題を修正しました。 |
| Bug | SPIREDOC-7841 | Word を PDF に変換する際に、プライベートフォントを埋め込むことに失敗した問題が修正されました。 |
| Bug | SPIREDOC-8242 | DOC から DOCX 2007 に変換するときに、コンテンツの配置が不一致の問題を修正しました。 |
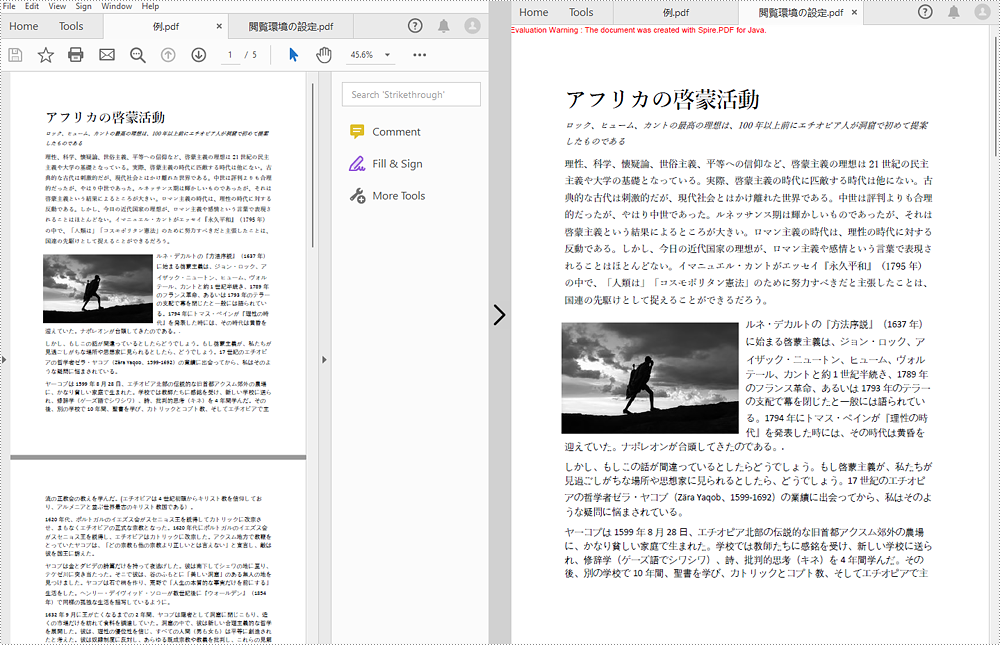
ドキュメントを正確に保存し、表示することは、PDF の主要な機能です。しかし、異なるデバイスやユーザーの閲覧環境設定が、PDF ドキュメントの表示に影響を与えることに変わりはありません。この問題を解決するために、PDF は、PDF ドキュメントが画面上に表示される方法を制御するために、ドキュメント内の閲覧環境設定エントリを提供します。これがないと、PDF ドキュメントは、現在のユーザーの環境設定に従って表示されます。この記事では、Spire.PDF for Java を使用したプログラミングによって、PDF の閲覧環境の設定を行う方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire.PDF for Java は、PdfViewerPreferences クラスの下に、ウィンドウの中央配置、タイトルの表示、ウィンドウのフィット、メニューバーやツールバーの非表示、ページレイアウト、ページモード、スケーリングモードなどを設定できるメソッドをいくつか備えています。以下は、閲覧環境の設定に関する詳細な手順である。
import com.spire.pdf.*;
public class setViewerPreference {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.loadFromFile("C:/例.pdf");
//ドキュメントの閲覧環境の設定を取得する
PdfViewerPreferences preferences = pdf.getViewerPreferences();
//閲覧環境を設定する
preferences.setCenterWindow(true);
preferences.setDisplayTitle(false);
preferences.setFitWindow(true);
preferences.setHideMenubar(true);
preferences.setHideToolbar(true);
preferences.setPageLayout(PdfPageLayout.Single_Page);
//preferences.setPageMode(PdfPageMode.Full_Screen);
//preferences.setPrintScaling(PrintScalingMode.App_Default);
//ファイルを保存する
pdf.saveToFile("閲覧環境の設定.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
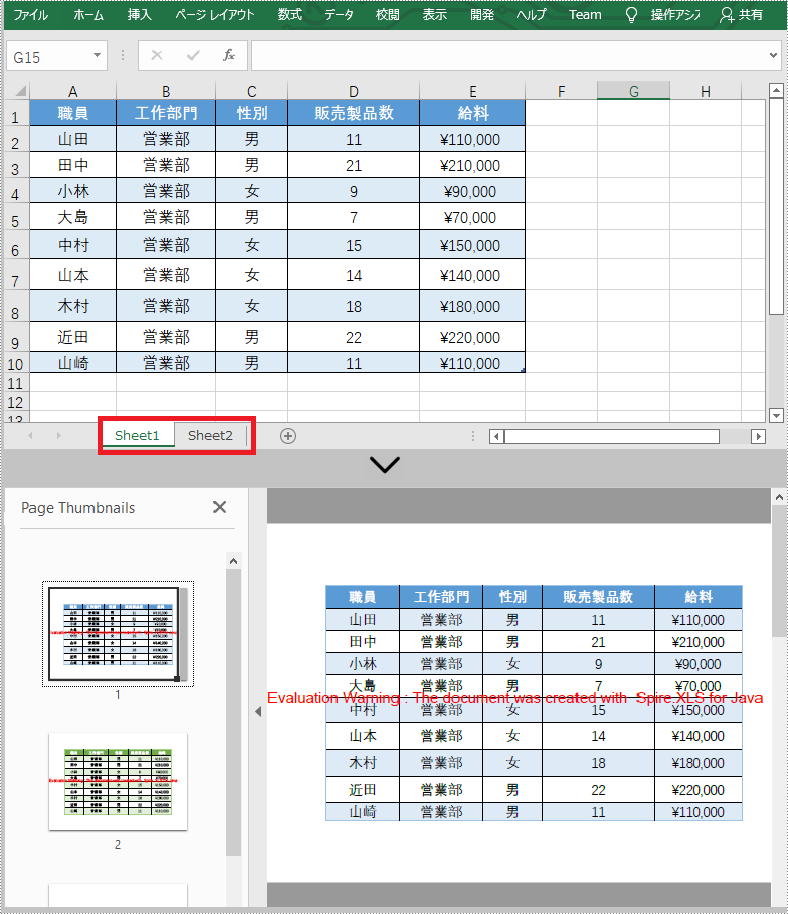
多くの場合、Excel を PDF に変換するのは一般的な方法です。送信ドキュメントのフォーマットとして PDF を使用することで、元のドキュメントのフォーマットが変化しないことを確認できます。この記事では、Spire.XLS for Java を使用して Excel を PDF に変換する方法を紹介します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.7.4</version>
</dependency>
</dependencies>詳細な手順は次のとおりです。
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
public class ConvertExcelToPdf {
public static void main(String[] args) {
//Workbookインスタンスを作成する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
//変換したPDFページのサイズをシートの内容サイズに合わせるように設定します
workbook.getConverterSetting().setSheetFitToPage(true);
//生成されたドキュメントを指定されたパスに保存する
workbook.saveToFile("output/ExcelToPdf.pdf", FileFormat.PDF);
}
}
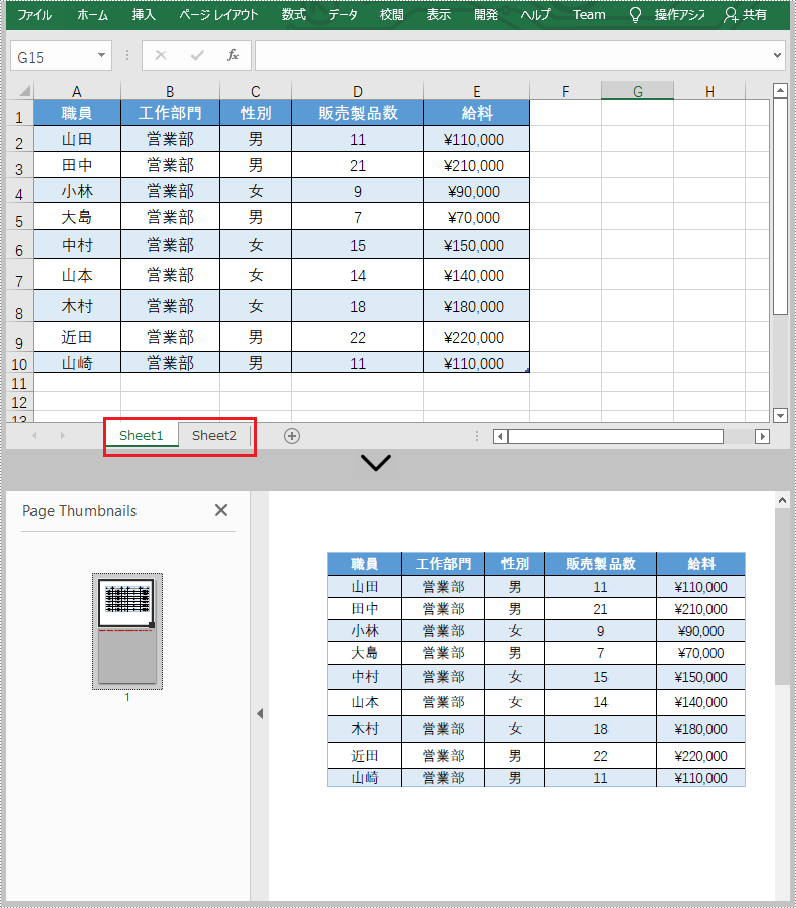
詳細な手順は次のとおりです。
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ConvertWorksheetToPdf {
public static void main(String[] args) {
//Workbookインスタンスを作成する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
//変換したPDFのページ幅をワークシートの内容幅に合わせて設定する
workbook.getConverterSetting().setSheetFitToWidth(true);
//最初のシートの取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//生成されたドキュメントを指定されたパスに保存する
worksheet.saveToPdf("output/WorksheetToPdf.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
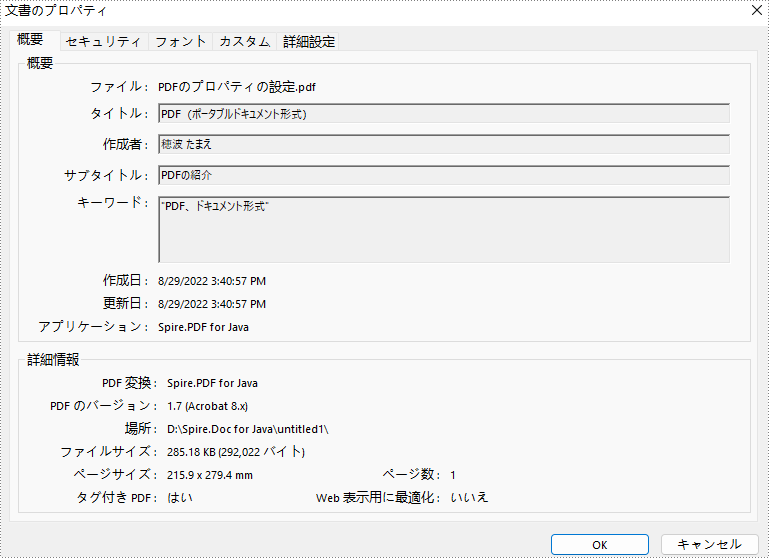
PDF プロパティは、PDF ドキュメントの一部ですが、ページには表示されません。それらのプロパティは、タイトル、著者、サブタイトル、キーワード、作成日、アプリケーションなど、ドキュメントに関する情報を含んでいます。プロパティ値の中には、自動的に生成されないものもあり、自分で設定する必要があります。この記事では、Spire.PDF for Java を使用してプログラム的に PDF プロパティを設定または取得する方法を説明します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>PDF のプロパティを設定する詳細な手順は以下のとおりです。
import com.spire.pdf.*;
import java.util.Date;
public class setPDFProperties {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdfDocument = new PdfDocument();
//PDFドキュメントを読み込む
pdfDocument.loadFromFile("C:/例.pdf");
//タイトルを設定する
pdfDocument.getDocumentInformation().setTitle("PDF(ポータブルドキュメント形式)");
//Set the author
pdfDocument.getDocumentInformation().setAuthor("穂波 たまえ");
//サブタイトルを設定する
pdfDocument.getDocumentInformation().setSubject("PDFの紹介");
//キーワードを設定する
pdfDocument.getDocumentInformation().setKeywords("PDF、ドキュメント形式");
//作成日を設定する
pdfDocument.getDocumentInformation().setCreationDate(new Date());
//作成者を設定する
pdfDocument.getDocumentInformation().setCreator("穂波 たまえ");
//更新日を設定する
pdfDocument.getDocumentInformation().setModificationDate(new Date());
//PDF変換を設定する
pdfDocument.getDocumentInformation().setProducer("Spire.PDF for Java");
//ドキュメントを保存する
pdfDocument.saveToFile("PDFのプロパティの設定.pdf");
}
}
PDF のプロパティを取得する詳細な手順は、以下の通りです。
import com.spire.pdf.*;
import java.io.*;
public class getPDFProperties {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("PDFのプロパティの設定.pdf");
//ドキュメントのプロパティの値を格納するための StringBuilder クラスのインスタンスを作成する
StringBuilder stringBuilder = new StringBuilder();
//プロパティの値を取得し、StringBuilder に格納する
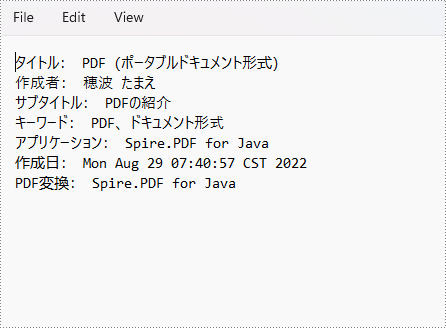
stringBuilder.append("タイトル: " + pdf.getDocumentInformation().getTitle() + "\r\n");
stringBuilder.append("作成者: " + pdf.getDocumentInformation().getAuthor() + "\r\n");
stringBuilder.append("サブタイトル: " + pdf.getDocumentInformation().getSubject() + "\r\n");
stringBuilder.append("キーワード: " + pdf.getDocumentInformation().getKeywords() + "\r\n");
stringBuilder.append("アプリケーション: " + pdf.getDocumentInformation().getCreator() + "\r\n");
stringBuilder.append("作成日: " + pdf.getDocumentInformation().getCreationDate() + "\r\n");
stringBuilder.append("PDF変換: " + pdf.getDocumentInformation().getProducer() + "\r\n");
//TXTファイルを新規に作成する
File file = new File("PDFのプロパティの取得.txt");
file.createNewFile();
//StringBuilder をTXTファイルに書き込む
FileWriter fileWriter = new FileWriter(file, true);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
bufferedWriter.write(stringBuilder.toString());
bufferedWriter.flush();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Web から Word ドキュメントにコンテンツをコピーすると、段落間に空白が多くなり、長い文章に見えると同時に、文章の可読性が低下する可能性があります。この記事では、Spire.Doc for .NET を使用して C# および VB.NET でプログラムによって既存の Word ドキュメント内の空の行/空白の段落を削除する方法を示します。
まず、Spire.Doc for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.Doc詳細な手順は次のとおりです。
using Spire.Doc;
using Spire.Doc.Documents;
using System;
namespace RemoveEmptyLines
{
class Program
{
static void Main(string[] args)
{
//Documentインスタンスを作成する
Document doc = new Document();
//Word ドキュメントをロードする
doc.LoadFromFile(@"input.docx");
//ドキュメント内のすべての段落をループする
foreach (Section section in doc.Sections)
{
for (int i = 0; i < section.Body.ChildObjects.Count; i++)
{
if (section.Body.ChildObjects[i].DocumentObjectType == DocumentObjectType.Paragraph)
{
//段落が空白の段落であるかどうかを決定する
if (String.IsNullOrEmpty((section.Body.ChildObjects[i] as Paragraph).Text.Trim()))
{
//空白の段落を削除する
section.Body.ChildObjects.Remove(section.Body.ChildObjects[i]);
i--;
}
}
}
}
//結果ドキュメントの保存する
doc.SaveToFile("RemoveEmptyLines.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Namespace RemoveEmptyLines
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Documentインスタンスを作成する
Dim doc As Document = New Document()
'Word ドキュメントをロードする
doc.LoadFromFile("input.docx")
'ドキュメント内のすべての段落をループする
For Each section As Section In doc.Sections
For i As Integer = 0 To section.Body.ChildObjects.Count - 1
If section.Body.ChildObjects(i).DocumentObjectType Is DocumentObjectType.Paragraph Then
'段落が空白の段落であるかどうかを決定する
If String.IsNullOrEmpty(TryCast(section.Body.ChildObjects(i), Paragraph).Text.Trim()) Then
'空白の段落を削除する
section.Body.ChildObjects.Remove(section.Body.ChildObjects(i))
i -= 1
End If
End If
Next
Next
'結果ドキュメントの保存する
doc.SaveToFile("RemoveEmptyLines.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
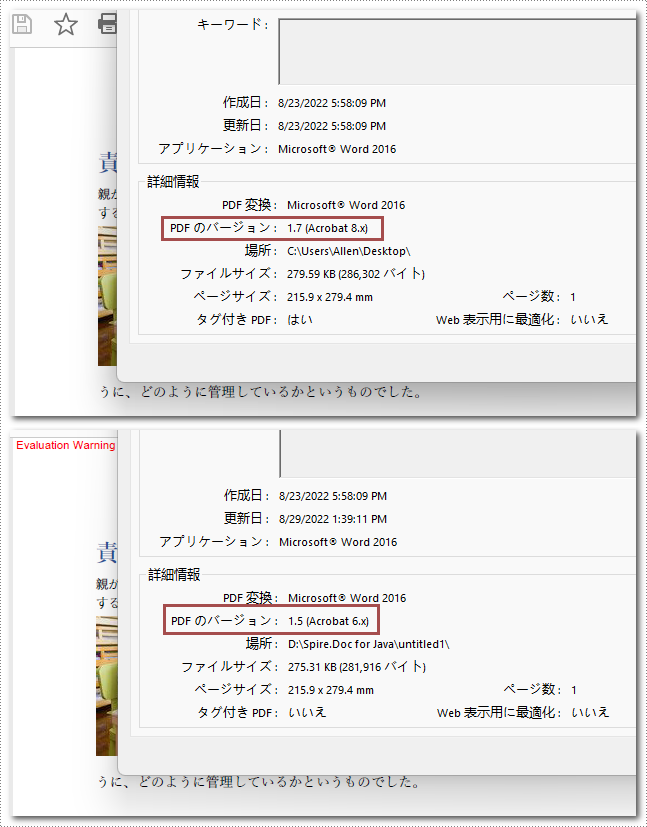
PDF は、1992年に Adobe 社が開発したドキュメント形式です。長年の更新を経て、このドキュメント形式は多くの変化を遂げました。一部のデバイスは、PDF のバージョンに厳しい要件を持っています。したがって、これらのデバイスと互換性を持つために、これらのデバイスでサポートされている PDF のバージョンを切り替える必要があります。この記事では、Spire.PDF for Java を使用して PDF のバージョンを変更する方法について紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire.PDF for Java は、1.0から1.7までの PDF のバージョンに対応しています。以下は、PDF のバージョンを変更するための詳細な手順です。
import com.spire.pdf.*;
public class changePDFVersion {
public static void main(String[] args) {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument document = new PdfDocument();
//PDFファイルを読み込む
document.loadFromFile("C:/例.pdf");
//PDFのバージョンを1.5に変更する
document.getFileInfo().setVersion(PdfVersion.Version_1_5);
//ファイルを保存する
document.saveToFile("PDFのバージョンの変更.pdf", FileFormat.PDF);
document.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
PowerPoint プレゼンテーションを PDF に変換する場合、ドキュメントのレイアウトとフォーマットは固定されます。受信者は、Microsoft PowerPoint をインストールせずに変換されたドキュメントを表示できますが、勝手に変更することはできません。この記事では、Spire.Presentation for Java を使用して PowerPoint プレゼンテーションを PDF に変換する方法を示します。
まず、Spire.Presentation for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>7.8.2</version>
</dependency>
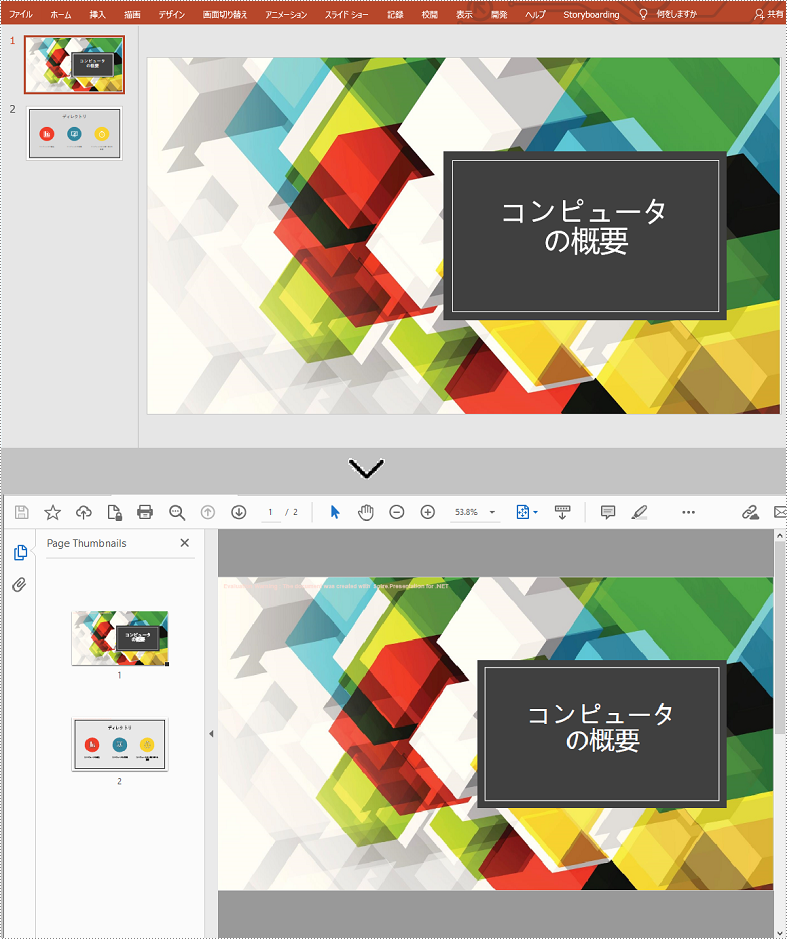
</dependencies>次の手順は、Spire.Presentation for Java を使用して PowerPoint プレゼンテーション全体を PDF に変換する方法を示しています。
import com.spire.presentation.FileFormat;
import com.spire.presentation.ISlide;
import com.spire.presentation.Presentation;
public class ConvertPowerPointToPDF {
public static void main(String []args) throws Exception {
//Presentationクラスのインスタンスを作成する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションをロードする
ppt.loadFromFile("Sample.pptx");
//ファイルをPDFとして保存する
ppt.saveToFile("ToPdf1.pdf", FileFormat.PDF);
}
}
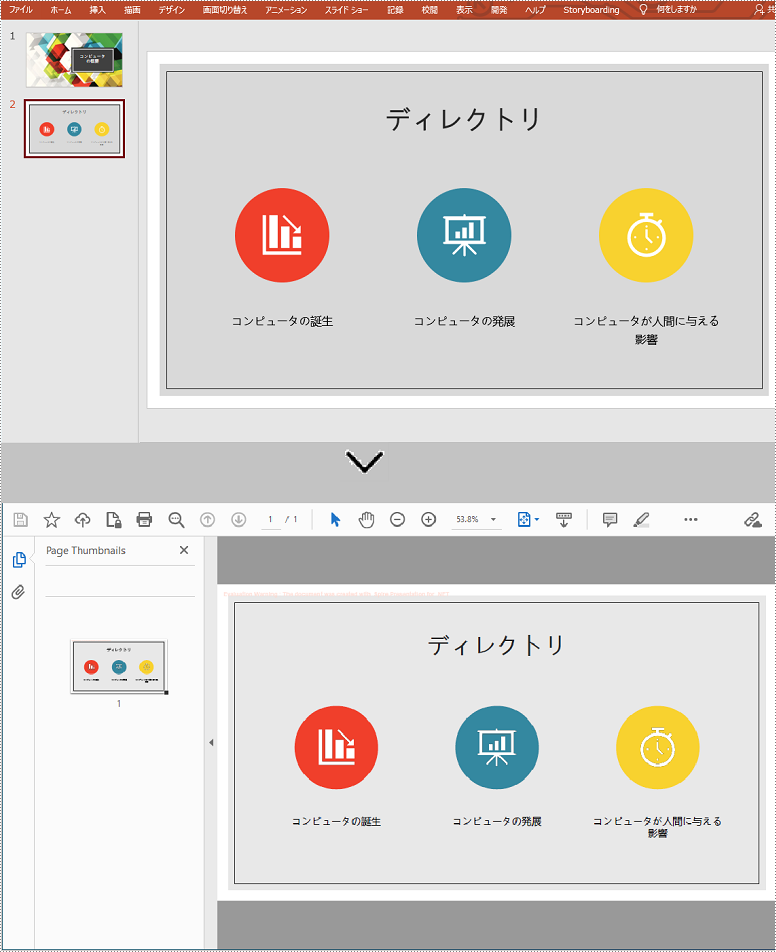
次の手順は、Spire.Presentation for Java を使用して PowerPoint プレゼンテーションの特定のスライドを PDF に変換する方法を示しています。
import com.spire.presentation.FileFormat;
import com.spire.presentation.ISlide;
import com.spire.presentation.Presentation;
public class ConvertSlidesToPDF {
public static void main(String []args) throws Exception {
//Presentationクラスのインスタンスを作成する
Presentation ppt = new Presentation();
//PowerPointプレゼンテーションをロードする
ppt.loadFromFile("Sample.pptx");
//2枚目のスライドを取得する
ISlide slide= ppt.getSlides().get(1);
//スライドをPDFとして保存する
slide.saveToFile("ToPdf2.pdf", FileFormat.PDF);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.SpreadSheet 6.8 のリリースを発表できることを嬉しく思います。このバージョンでは、Worksheet.Resize メソッドが無効であった問題を修正しました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPREADSHEET-204 | Worksheet.Resize メソッドが無効であった問題を修正しました。 |
大量の PDF ファイルを扱うのは面倒なので、複数の PDF ファイルを1つのファイルに結合して、私たちが扱いやすいようにします。 複数のPDFファイルを1つの PDF ファイルに結合することで、これらのファイルの保存、共有、レビューが容易になります。 この記事では、プログラミングによって Spire.PDF for Java を使用して PDF ファイルを結合する方法を説明します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire.PDF for Java は、複数の PDF ドキュメントを1つの PDF ドキュメントに結合する PdfDocument.mergeFiles() メソッドを提供します。 以下、詳しい手順を説明します。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfDocumentBase;
public class mergePDF {
public static void main(String[] args) {
//結合されるPDFドキュメントのパスを取得する
String[] files = new String[] {
"C:\\PDF\\Sample1.pdf",
"C:\\PDF\\Sample2.pdf",
"C:\\PDF\\Sample3.pdf"};
//これらのドキュメントをマージし、PdfDocumentBase クラスのオブジェクトを返す
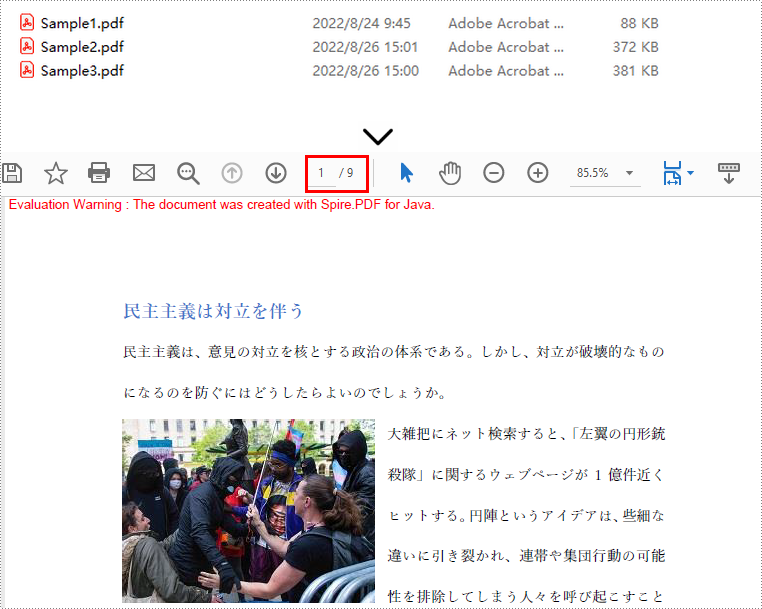
PdfDocumentBase doc = PdfDocument.mergeFiles(files);
//マージしたドキュメントを保存する
doc.save("PDFドキュメントの結合.pdf", FileFormat.PDF);
}
}
Spire.PDF for Java は、ある PDF ドキュメントから別の PDF ドキュメントにページまたはページ範囲を取り込むための PdfDocument.insertPage() メソッドおよび PdfDocument.insertPageRange() メソッドを提供します。 以下は、異なるPDFドキュメントから選択したページを新しいPDFドキュメントに結合する手順です。
import com.spire.pdf.PdfDocument;
public class mergeSelectedPages {
public static void main(String[] args) {
//結合されるPDFドキュメントのパスを取得する
String[] files = new String[] {
"C:\\PDF\\Sample1.pdf",
"C:\\PDF\\Sample2.pdf",
"C:\\PDF\\Sample3.pdf"};
//PdfDocument クラスの配列を作成する
PdfDocument[] docs = new PdfDocument[files.length];
//すべてのドキュメントをループする
for (int i = 0; i < files.length; i++)
{
//指定されたドキュメントを読み込む
docs[i] = new PdfDocument(files[i]);
}
//PdfDocument クラスのオブジェクトを作成して、新しい PDF ドキュメントを生成する
PdfDocument doc = new PdfDocument();
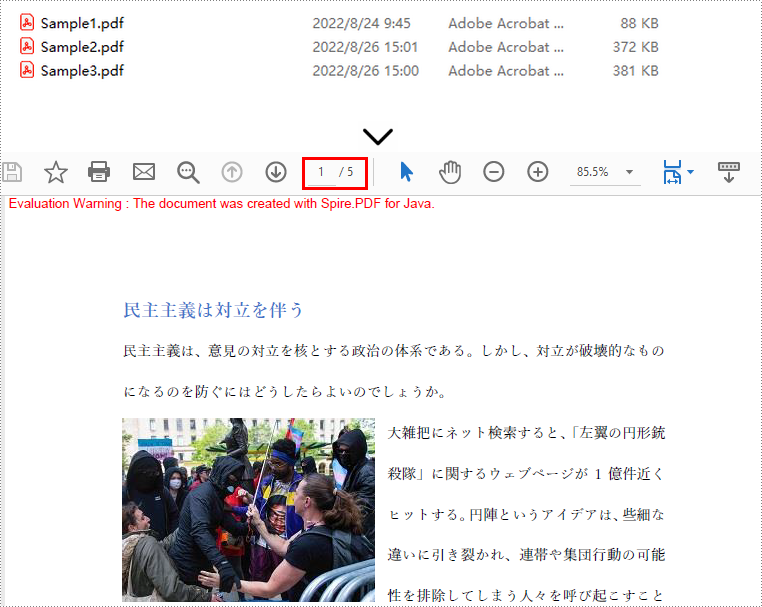
//異なるドキュメントから選択したページを新しいドキュメントに挿入する
doc.insertPage(docs[0], 0);
doc.insertPageRange(docs[1], 0,2);
doc.insertPage(docs[2], 0);
//新しいドキュメントを保存する
doc.saveToFile("指定したページのマージ.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
機密情報や重要な情報を含む PDF ドキュメントには、パスワードを使って保護し、指定された人だけがドキュメント内の情報にアクセスできるようにすることができます。この記事では、Spire.PDF for Java を使用して PDF ドキュメントを暗号化し、パスワードで保護されたドキュメントを復号化する方法を説明します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
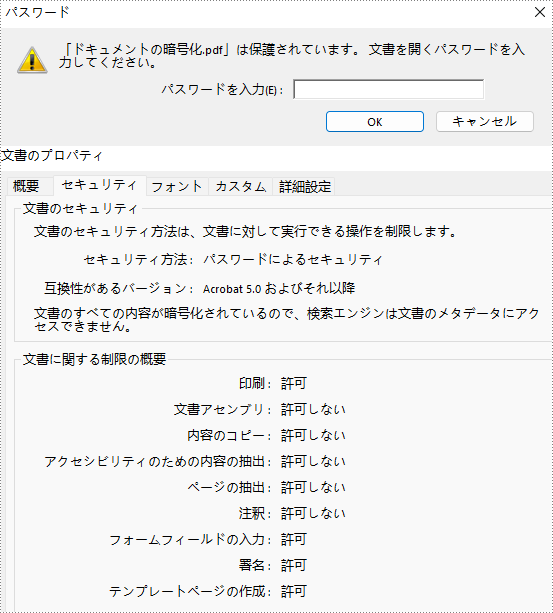
</dependencies>PDF ファイルを暗号化するためのパスワードには、「開くパスワード」と「権限パスワード」の2種類があります。前者は PDF ファイルを開くために設定し、後者は印刷や 内容のコピー、コメント付けなどを制限するために設定します。両方の種類のパスワードで PDF ファイルを保護した場合、どちらか一方のパスワードで開くことができます。
Spire.PDF for Java が提供する PdfDocument.getSecurity().encrypt(java.lang.String openPassword, java.lang.String permissionPassword, java.util.EnumSet<PdfPermissionsFlags> permissions, PdfEncryptionKeySize keySize) メソッドは PDF ファイルを暗号化するのに開くパスワードと権限パスワード両方を設定できるようにします。詳細な手順は次のとおりです。
import java.util.EnumSet;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.security.PdfEncryptionKeySize;
import com.spire.pdf.security.PdfPermissionsFlags;
public class encryptPDF {
public static void main(String[] args) {
//PdfDocumentクラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/例.pdf");
//ドキュメントを暗号化する
PdfEncryptionKeySize keySize = PdfEncryptionKeySize.Key_128_Bit;
String openPassword = "e-iceblue";
String permissionPassword = "permission";
EnumSet flags = EnumSet.of(PdfPermissionsFlags.Print, PdfPermissionsFlags.Fill_Fields);
pdf.getSecurity().encrypt(openPassword, permissionPassword, flags, keySize);
//ドキュメントを保存する
pdf.saveToFile("ドキュメントの暗号化.pdf");
pdf.close();
}
}
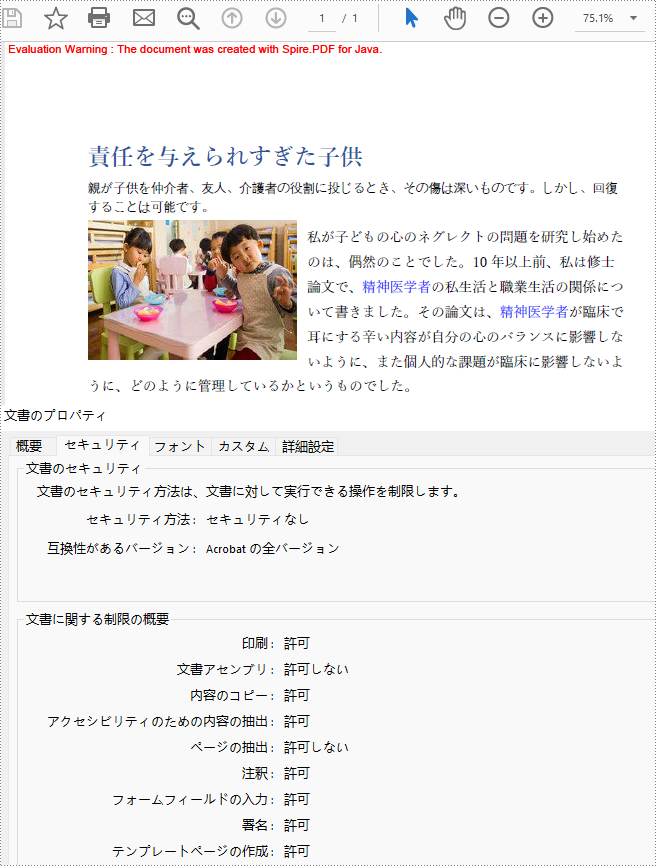
PDF ファイルのパスワードを削除する必要がある場合、PdfDocument.getSecurity().encrypt(java.lang.String openPassword, java.lang.String permissionPassword, java.util.EnumSet<PdfPermissionsFlags> permissions, PdfEncryptionKeySize keySize, java.lang.String originalPermissionPassword) メソッドを用いて開くパスワードと権限パスワードを空に設定することが可能です。詳細な手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.security.PdfEncryptionKeySize;
import com.spire.pdf.security.PdfPermissionsFlags;
public class decryptPDF {
public static void main(String[] args) throws Exception {
//PdfDocumentクラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//パスワードで暗号化されたPDFドキュメントを読み込む
pdf.loadFromFile("ドキュメントの暗号化.pdf", "e-iceblue");
//ドキュメントを復号化する
pdf.getSecurity().encrypt("", "", PdfPermissionsFlags.getDefaultPermissions(), PdfEncryptionKeySize.Key_256_Bit, "permission");
//ドキュメントを保存する
pdf.saveToFile("ドキュメントの復号化.pdf");
pdf.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





