チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

PDF ドキュメントに埋め込まれた画像を他の場所で使用したい場合、それらを取り出してファイルフォルダに保存することができます。この記事では、Spire.PDF for Java を使用して PDF ドキュメントから画像を抽出する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>Spire.PDF for Java は、PDF ドキュメントから画像を抽出するための PdfPageBase.extractImages() メソッドを提供しています。詳細な手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
public class extractImage {
public static void main(String[] args) throws IOException {
//PdfDocument クラスのインスタンスを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントを読み込む
doc.loadFromFile("C:/例.pdf");
//int型変数を宣言する
int index = 0;
//全ページをループする
for (PdfPageBase page : (Iterable<PdfPageBase>) doc.getPages()) {
//ページからの画像を抽出する
for (BufferedImage image : page.extractImages()) {
//ファイルのパスと名前を指定する
File output = new File("C:/抽出した画像/" + String.format("Image_%d.png", index++));
//画像をPNGファイルとして保存する
ImageIO.write(image, "PNG", output);
}
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS for Java 12.8.4 のリリースを発表できることを嬉しく思います。このリリースでは、Worksheet.getMaxDispalyRange() メソッドを使用して画像、形状などのオブジェクトを含むすべてのセル範囲の取得と =Days() 式をサポートしました。また、今回のアップデートでは Excel から PDF への変換機能も強化されました。グラフ DataRange を取得するときに、アプリケーションが「NullPointerException」をスローする既知の問題が修正されます。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4002 | Worksheet.getMaxDispalyRange() メソッドを使用して画像、形状などのオブジェクトを含むすべてのセル範囲の取得をサポートしました。
Workbook workbook = new Workbook();
workbook.loadFromFile("TEST.xlsx");
Worksheet sheet1 = workbook.getWorksheets().get(0);
//copy all objects(such as text, shape, image...) from sheet2 to sheet1
for(int i=1;i<workbook.getWorksheets().getCount(); i++){
Worksheet sheet2 = workbook.getWorksheets().get(i);
sheet2.copy((CellRange) sheet2.getMaxDisplayRange(),sheet1,sheet1.getLastRow()+1,sheet2.getFirstColumn(),true);
}
workbook.saveToFile("output.xlsx", ExcelVersion.Version2013); |
| New feature | SPIREXLS-4026 | =Days() 式をサポートしました。
Workbook workbook = new Workbook();
workbook.loadFromFile("Test.xlsx");
Worksheet sheet = workbook.getWorksheets().get(0);
sheet.getCellRange("C4").setFormula("=DAYS(A8,A1)");
workbook.saveToFile(""RES.xlsx""); |
| Bug | SPIREXLS-3980 | XML から Excel に変換した後、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-3995 | Excel から SVG に変換した後、グラフのタイトルが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4014 | Excel から PDF に変換した後、コンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4020 | Excel から PDF に変換するときに、アプリケーションが「StringIndexOutOfBoundsException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4054 | グラフ DataRange を取得するときに、アプリケーションが「NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4070 | Files.deleteIfExists() を使用して isPasswordProtected() メソッドで検出されたファイルを削除するときに、アプリケーションが「FileSystemException」をスローする問題が修正されました。 |
Word ドキュメントを処理する際には、ドキュメント内の段落を削除する必要があることがよくあります。たとえば、冗長性の高い段落が多数含まれるコンテンツを Web 上からドキュメントにコピーした後、有用なコンテンツだけを残すために余分な段落を削除する必要があります。Spire.Doc for .NET は、他のソフトウェアを使用することなく、コードを介してこれらの段落をすばやく削除するのに役立ちます。この記事では、Spire.Doc for .NET を使用して、C# および VB.NET で Word ドキュメントの段落を削除する方法を示します。
まず、Spire.Doc for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET は、Word ドキュメントから指定した段落を削除するための ParagraphCollection クラスの RemoveAt() メソッドを提供しています。詳細な手順は次のとおりです。
using System;
using Spire.Doc;
namespace RemoveParagraphs
{
internal class Program
{
static void Main(string[] args)
{
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントをロードする
document.LoadFromFile("Sample.docx");
//ドキュメントの最初のセクションを取得する
Section section = document.Sections[0];
//セクションの4段目を削除する
section.Paragraphs.RemoveAt(3);
//ドキュメントを保存する
document.SaveToFile("RemoveParagraphs.docx", FileFormat.Docx2013);
}
}
}Imports System
Imports Spire.Doc
Module Program
Sub Main(args As String())
'Documentクラスのオブジェクトを作成する
Dim document As Document = New Document
'Wordドキュメントをロードする
document.LoadFromFile("Sample.docx")
'ドキュメントの最初のセクションを取得する
Dim section As Section = document.Sections(0)
'セクションの4段目を削除する
section.Paragraphs.RemoveAt(3)
'ドキュメントを保存する
document.SaveToFile("RemoveParagraphs.docx", FileFormat.Docx2013)
End Sub
End Module
Spire.Doc for .NET は、Word ドキュメント内のすべての段落を削除するための ParagraphCollection クラスの Clear() メソッドを提供しています。詳細な手順は次のとおりです。
using System;
using Spire.Doc;
namespace RemoveAllParagraphs
{
internal class Program
{
static void Main(string[] args)
{
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントをロードする
document.LoadFromFile("Sample.docx");
//すべてのセクションをループする
foreach (Section section in document.Sections)
{
//各セクションのすべての段落を削除する
section.Paragraphs.Clear();
}
//ドキュメントを保存する
document.SaveToFile("RemoveAllParagraphs.docx", FileFormat.Docx2013);
}
}
}Imports System
Imports Spire.Doc
Module Program
Sub Main(args As String())
'Documentクラスのオブジェクトを作成する
Dim document As Document = New Document()
'Wordドキュメントをロードする
document.LoadFromFile("Sample.docx")
'すべてのセクションをループする
For Each section As Section In document.Sections
'各セクションのすべての段落を削除する
section.Paragraphs.Clear()
Next
'ドキュメントを保存する
document.SaveToFile("RemoveAllParagraphs.docx", FileFormat.Docx2013)
End Sub
End Module
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
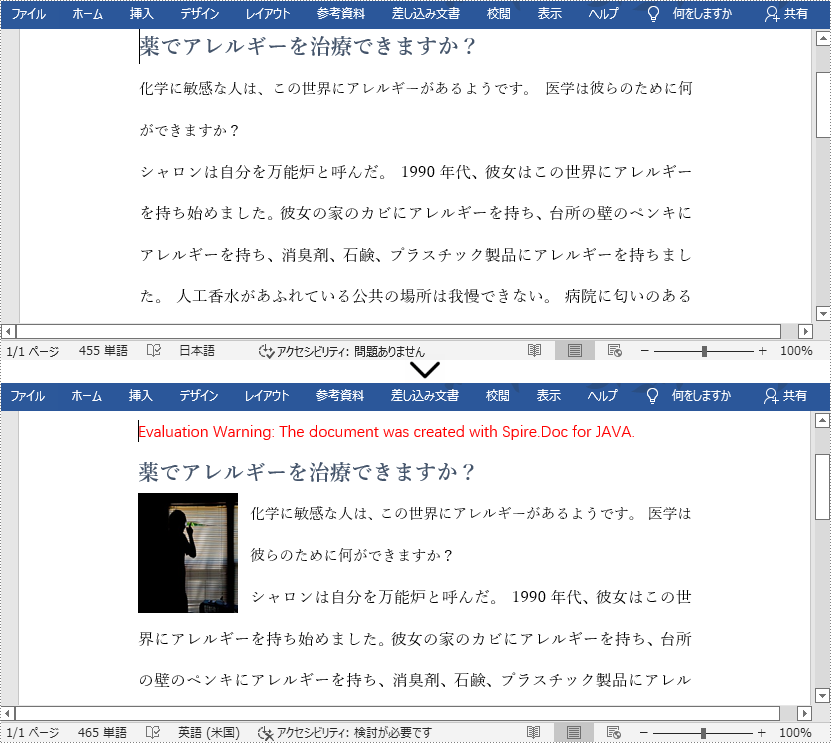
MS Word では、テキスト、画像、図表、ファイルなど、Word ドキュメントに多くの素材を挿入することができます。画像は、直感的に理解できるようにするため、言葉で表現しにくいアイデアを表現するため、または単に美しくするために Word ドキュメントで頻繁に使用されています。この記事では、Spire.Doc for Java の助けを借りて、Word ドキュメントに画像を挿入する便利で効率的な方法を提供します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>詳細な手順は以下の通りです。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
public class insertImage {
public static void main(String[] args) throws Exception {
//Document クラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("C:/例.docx");
//DocPicture クラスのオブジェクトを作成する
DocPicture picture = new DocPicture(doc);
//画像を読み込む
picture.loadImage("C:/画像.jpg");
//画像の大きさを設定する
picture.setWidth(75);
picture.setHeight(90);
//画像のテキストの回り込みスタイルを「Square」に設定する
picture.setTextWrappingStyle( TextWrappingStyle.Square);
//2段落目の先頭に画像を挿入する
doc.getSections().get(0).getParagraphs().get(1).getChildObjects().insert(0,picture);
//ドキュメントを保存する
doc.saveToFile("画像の挿入.docx", FileFormat.Docx);
}
}
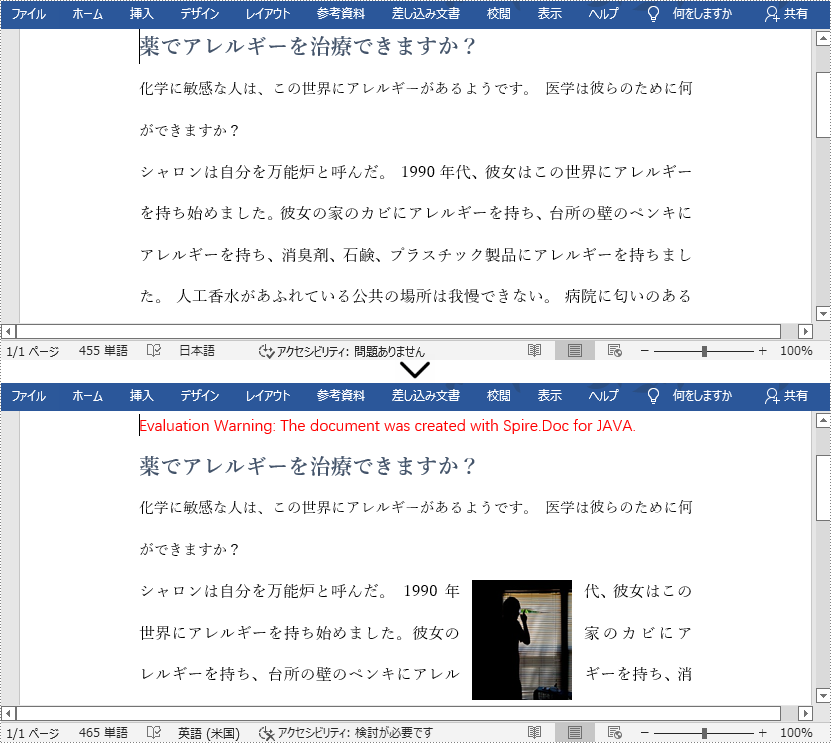
詳細な手順は以下の通りです。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
public class insertImage {
public static void main(String[] args) throws Exception {
//Document クラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("C:/例.docx");
//DocPicture クラスのオブジェクトを作成する
DocPicture picture = new DocPicture(doc);
//画像を読み込む
picture.loadImage("C:/画像.jpg");
//画像の大きさを設定する
picture.setWidth(75);
picture.setHeight(90);
//画像のテキストラッピングスタイルをTightに設定する
picture.setTextWrappingStyle( TextWrappingStyle.Tight);
//3番目の段落に画像を挿入する
doc.getSections().get(0).getParagraphs().get(2).getChildObjects().insert(0,picture);
//画像の位置を設定する
picture.setHorizontalPosition(250.0F);
picture.setVerticalPosition(7.0F);
//ドキュメントを保存する
doc.saveToFile("画像の挿入.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
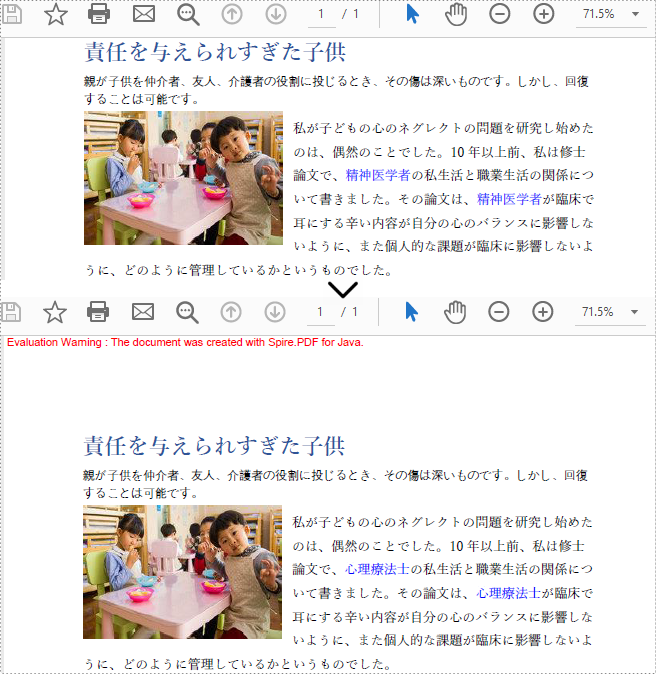
MS Word とは異なり、PDF は自動的にページの内容を再配置しないので、PDF ドキュメント内のテキストはほとんど変更することはできません。Spire.PDF for Java が提供するこの方法は、既存のドキュメント内のテキストを置き換えるのではなく、古いテキストを白い矩形で覆い、その上に新しいテキストを描画します。置き換え後の空白や重なりの問題を回避するために、置き換えに使用するテキストの長さが、置き換えられるテキストの長さと同じであることを確認してください。この記事では、PDF ドキュメント内のテキストを検索して置換する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>以下は、特定の PDF ページで選択されたテキストを検索し、新しいテキストでそれらを覆うための手順です。
import com.spire.pdf.*;
import com.spire.pdf.general.find.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class replaceText {
public static void main(String[] args) throws Exception {
//PdfDocument クラスのオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントを読み込む
doc.loadFromFile("C:/例.pdf");
//ドキュメントの最初のページを取得する
PdfPageBase page = doc.getPages().get(0);
//検索テキスト「精神医学者」
PdfTextFindCollection collection = page.findText("精神医学者",false);
//置換テキスト「心理療法士」を指定する
String newText = "心理療法士";
PdfBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.blue));
//PdfTrueTypeFontクラスのオブジェクトを作成し、フォントを設定する
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Mincho", Font.BOLD, 12));
for (Object findObj : collection.getFinds()) {
PdfTextFind find=(PdfTextFind)findObj;
//ページ上のテキストの境界を取得する
Rectangle2D.Float rec = (Rectangle2D.Float)find.getBounds();
page.getCanvas().drawRectangle(PdfBrushes.getWhite(), rec);
//テキストを描画する
page.getCanvas().drawString(newText, font, brush, rec.getX(), rec.getY()-7);
}
String result = "テキストの置換.pdf";
//ドキュメントを保存する
doc.saveToFile(result, FileFormat.PDF);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
特定の段落やテキストのフォントの色を変更することで、Word ドキュメント内でその段落やテキストを目立たせることができます。今回は、Spire.Doc for Java を使用して Word ドキュメントのフォントの色を変更する方法を説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>以下は、Word ドキュメントで段落のフォントの色を変更する手順です。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.ParagraphStyle;
import java.awt.*;
public class ChangeFontColorOfParagraph {
public static void main(String[] args) {
//Document クラスのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("C:/例.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//このセクションで最初の段落のフォント色を変更する
Paragraph p1 = section.getParagraphs().get(0);
ParagraphStyle s1 = new ParagraphStyle(document);
s1.setName("色1");
s1.getCharacterFormat().setTextColor(new Color(6, 84, 148));
document.getStyles().add(s1);
p1.applyStyle(s1.getName());
//このセクションで2番目の段落のフォント色を変更する
Paragraph p2 = section.getParagraphs().get(1);
ParagraphStyle s2 = new ParagraphStyle(document);
s2.setName("色2");
s2.getCharacterFormat().setTextColor(new Color(128, 128, 128));;
document.getStyles().add(s2);
p2.applyStyle(s2.getName());
//ドキュメントを保存する
document.saveToFile("段落のフォント色の変更.docx", FileFormat.Docx);
}
}
以下は、Word ドキュメントに含まれる指定した文字のフォントの色を変更する手順です。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.TextSelection;
import java.awt.*;
public class ChangeFontColorOfText {
public static void main(String[] args) {
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("C:/例.docx");
//フォントの色を変更したいテキストを探す
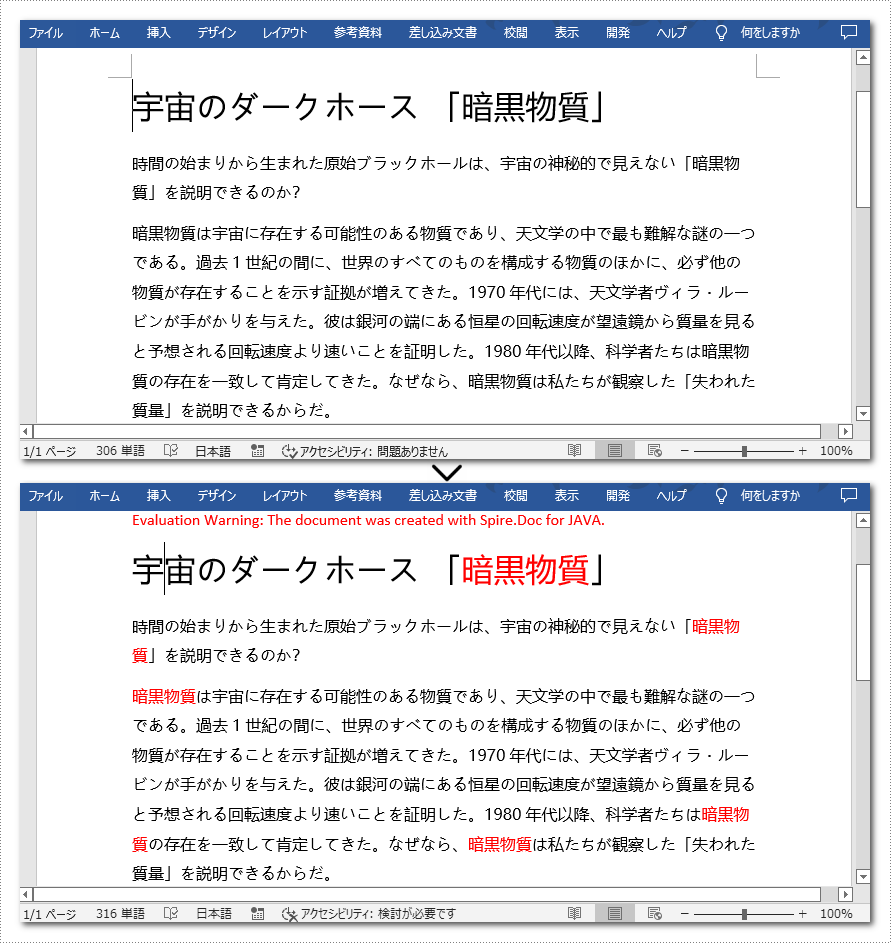
TextSelection[] text = document.findAllString("暗黒物質", false, true);
//検索されたテキストのフォントの色を変更する
for (TextSelection selection : text)
{
selection.getAsOneRange().getCharacterFormat().setTextColor(Color.red);
}
//ドキュメントを保存する
document.saveToFile("テキストのフォント色の変更.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
テキストボックスは、Word ドキュメント内の任意の場所に挿入できるテキストや画像の入れ物です。 MS Word には、あらかじめいくつかのテキストボックスのスタイルが用意されていますが、独自のアイデアで読者を魅了するカスタム外観のテキストボックスを作成することも可能です。 この記事では、Spire.Doc for Java を使用して Word ドキュメントにテキストボックスを追加または削除する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Spire.Doc for Java には、指定した段落にテキストボックスを挿入する Paragraph.appendTextBox(float width, float height) というメソッドが用意されています。 以下は、その詳細な手順です。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextBox;
import com.spire.doc.fields.TextRange;
import java.awt.*;
public class InsertTextBox {
public static void main(String[] args) {
//Document クラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("C:/例.docx");
//テキストボックスを作成し、テキスト折り返しを設定する
TextBox tb = doc.getSections().get(0).getParagraphs().get(0).appendTextBox(120f, 230f);
tb.getFormat().setTextWrappingStyle(TextWrappingStyle.Square);
//テキストボックスの位置を設定する
tb.getFormat().setHorizontalOrigin(HorizontalOrigin.Right_Margin_Area);
tb.getFormat().setHorizontalPosition(-100f);
tb.getFormat().setVerticalOrigin(VerticalOrigin.Page);
tb.getFormat().setVerticalPosition(165f);
//テキストボックスのボーダーの色と塗りつぶしの色を設定する
tb.getFormat().setLineColor(Color.BLUE);
tb.getFormat().setFillColor(new Color(203,234,253) );
//テキストボックスに画像を挿入する
Paragraph para = tb.getBody().addParagraph();
DocPicture picture = para.appendPicture("C:/画像.jpg");
//段落の配置を設定する
para.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//画像サイズを設定する
picture.setHeight(90f);
picture.setWidth(90f);
//テキストボックスに文字を挿入する
para = tb.getBody().addParagraph();
TextRange textRange = para.appendText("考古学者が発掘にいそしむ一方で、イアンは「ポストプロセス」考古学というポストモダンなアプローチを構築しています。");
//段落の配置を設定する
para.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//フォントを設定する
textRange.getCharacterFormat().setFontName("Yu Mincho");
textRange.getCharacterFormat().setFontSize(9f);
textRange.getCharacterFormat().setItalic(true);
//ドキュメントを保存する
doc.saveToFile("テキストボックスの挿入.docx", FileFormat.Docx_2013);
}
}
Spire.Doc for Java には、指定したテキストボックスを削除する Document.getTextBoxes().removeAt() メソッドが用意されています。 すべてのテキストボックスを削除したい場合は、Document.getTextBoxes().clear() メソッドで削除できます。 テキストボックスを削除する手順は、次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class RemoveTextBox {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("C:/例.docx");
//テキストボックスをインデックスで削除する
doc.getTextBoxes().removeAt(0);
//すべてのテキストボックスを削除する
//doc.getTextBoxes().clear();
//ドキュメントを保存する
doc.saveToFile("テキストボックスの削除.docx", FileFormat.Docx);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF for Java 8.8.3 のリリースを発表できることをうれしく思います。このバージョンは、無秩序リストの作成をサポートして、署名タイムスタンプの内部セキュリティが調整されました。また、PDF から Tiff への変換機能も強化されています。さらに、既知の問題の一部も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | 無秩序リストの作成をサポートしました。
public void DrawMarker(PdfUnorderedMarkerStyle style, String outputFile) {
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(style);
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close();
}
public void PdfMarker_CustomImage() throws Exception {
String outputFile = "PdfMarker_CustomImage.pdf";
String inputFile_Img = "sample.png";
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_Image);
marker.setImage(PdfImage.fromFile(inputFile_Img));
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close();
}
public void PdfMarker_CustomTemplate() throws Exception {
String outputFile = "PdfMarker_CustomTemplate.pdf";
String inputFile_Img = "sample.png";
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_Template);
PdfTemplate template = new PdfTemplate(210, 210);
marker.setTemplate(template);
template.getGraphics().drawImage(PdfImage.fromFile(inputFile_Img), 0, 0);
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close();
}
public void PdfMarker_CustomString() throws Exception {
String outputFile = "PdfMarker_CustomString.pdf";
PdfDocument doc = new PdfDocument();
PdfNewPage page = (PdfNewPage) doc.getPages().add();
PdfMarker marker = new PdfMarker(PdfUnorderedMarkerStyle.Custom_String);
marker.setText("AAA");
String listContent = "Data Structure\n"
+ "Algorithm\n"
+ "Computer Newworks\n"
+ "Operating System\n"
+ "C Programming\n"
+ "Computer Organization and Architecture";
PdfUnorderedList list = new PdfUnorderedList(listContent);
list.setIndent(2);
list.setTextIndent(4);
list.setMarker(marker);
list.draw(page, 100, 100);
doc.saveToFile(outputFile, FileFormat.PDF);
doc.close(); |
| Adjustment | - | 署名タイムスタンプの内部セキュリティが調整されました。 |
| Bug | SPIREPDF-4780 | PDF を Tiff に変換し、アプリケーションの実行時間が長く、メモリ消費が大きい問題が修正されました。 |
| Bug | SPIREPDF-5387 | PDF ドキュメントのロードするときに、アプリケーションが「Read failure」をスローした問題を修正しました。 |
Word ドキュメント内のハイパーリンクを使用すると、読者はドキュメントの任意の位置、ファイル、Web サイト、または電子メールにジャンプすることができます。ハイパーリンクを使用すると、読者は関連する情報へすばやく簡単に移動することができます。この記事では、Spire.Doc for .NET を使用して Word ドキュメント内のテキストや画像にハイパーリンクを挿入する方法について説明します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc では、段落内のテキストや画像に Web リンク、メールリンク、ファイルリンク、ブックマークリンクを追加する Paragraph.AppendHyperlink() メソッドを提供しています。以下は、その詳細な手順です。
using Spire.Doc;
using Spire.Doc.Documents;
using System.Drawing;
namespace InsertHyperlinks
{
internal class Program
{
static void Main(string[] args)
{
//Wordドキュメントを作成する
Document doc = new Document();
//セクションを追加する
Section section = doc.AddSection();
//段落を追加する
Paragraph paragraph = section.AddParagraph();
paragraph.AppendHyperlink("https://jp.e-iceblue.com/", "公式サイト", HyperlinkType.WebLink);
//改行を追加する
paragraph.AppendBreak(BreakType.LineBreak);
paragraph.AppendBreak(BreakType.LineBreak);
//メールリンクを追加する
paragraph.AppendHyperlink("mailto:support @e-iceblue.com", "メールでのお問い合わせ", HyperlinkType.EMailLink);
//改行を追加する
paragraph.AppendBreak(BreakType.LineBreak);
paragraph.AppendBreak(BreakType.LineBreak);
//ファイルリンクを追加する
string filePath = @"C:\レポート.xlsx";
paragraph.AppendHyperlink(filePath, "クリックするとレポートが開きます", HyperlinkType.FileLink);
//改行を追加する
paragraph.AppendBreak(BreakType.LineBreak);
paragraph.AppendBreak(BreakType.LineBreak);
//別のセクションを追加し、ブックマークを作成する
Section section2 = doc.AddSection();
Paragraph bookmarkParagrapg = section2.AddParagraph();
bookmarkParagrapg.AppendText("これは1つのブックマークです");
BookmarkStart start = bookmarkParagrapg.AppendBookmarkStart("私のブックマーク");
bookmarkParagrapg.Items.Insert(0, start);
bookmarkParagrapg.AppendBookmarkEnd("私のブックマーク");
//ブックマークへのリンクを追加する
paragraph.AppendHyperlink("私のブックマーク", "このドキュメントの中の特定の位置へジャンプする", HyperlinkType.Bookmark);
//改行を追加する
paragraph.AppendBreak(BreakType.LineBreak);
paragraph.AppendBreak(BreakType.LineBreak);
paragraph.AppendBreak(BreakType.LineBreak);
//画像に基づくハイパーリンクを追加する
Image image = Image.FromFile(@"C:\.net.png");
Spire.Doc.Fields.DocPicture picture = paragraph.AppendPicture(image);
paragraph.AppendHyperlink("https://docs.microsoft.com/ja-jp/dotnet/", picture, HyperlinkType.WebLink);
//ドキュメントを保存する
doc.SaveToFile("ハイパーリンクの挿入.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System.Drawing
Namespace InsertHyperlinks
Friend Class Program
Shared Sub Main(ByVal args() As String)
'Wordドキュメントを作成する
Dim doc As Document = New Document()
'セクションを追加する
Dim section As Section = doc.AddSection()
'段落を追加する
Dim paragraph As Paragraph = section.AddParagraph()
paragraph.AppendHyperlink("https://jp.e-iceblue.com/", "公式サイト", HyperlinkType.WebLink)
'改行を追加する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
'メールリンクを追加する
paragraph.AppendHyperlink("mailto:support @e-iceblue.com", "メールでのお問い合わせ", HyperlinkType.EMailLink)
'改行を追加する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
'ファイルリンクを追加する
Dim filePath As String = "C:\レポート.xlsx"
paragraph.AppendHyperlink(filePath, "クリックするとレポートが開きます", HyperlinkType.FileLink)
'改行を追加する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
'別のセクションを追加し、ブックマークを作成する
Dim section2 As Section = doc.AddSection()
Dim bookmarkParagrapg As Paragraph = section2.AddParagraph()
bookmarkParagrapg.AppendText("これは1つのブックマークです")
Dim start As BookmarkStart = bookmarkParagrapg.AppendBookmarkStart("私のブックマーク")
bookmarkParagrapg.Items.Insert(0, start)
bookmarkParagrapg.AppendBookmarkEnd("私のブックマーク")
'ブックマークへのリンクを追加する
paragraph.AppendHyperlink("私のブックマーク", "このドキュメントの中の特定の位置へジャンプする", HyperlinkType.Bookmark)
'改行を追加する
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
paragraph.AppendBreak(BreakType.LineBreak)
'画像に基づくハイパーリンクを追加する
Dim image As Image = Image.FromFile("C:\.net.png")
Dim picture As Spire.Doc.Fields.DocPicture = paragraph.AppendPicture(image)
paragraph.AppendHyperlink("https://docs.microsoft.com/ja-jp/dotnet/", picture, HyperlinkType.WebLink)
'ドキュメントを保存する
doc.SaveToFile("ハイパーリンクの挿入.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace
ドキュメント内の既存のテキストにハイパーリンクを追加するのは、少し複雑です。対象となる文字列を見つけ、それをハイパーリンクフィールドに置き換える必要があります。以下はその手順です。
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using Spire.Doc.Interface;
namespace InsertHyperlinks
{
internal class Program
{
static void Main(string[] args)
{
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.LoadFromFile(@"C:\例.docx");
//ドキュメント内の「.NET Framework」文字列をすべて検索する
TextSelection[] selections = document.FindAllString(".NET Framework", true, true);
//2番目に見つかった文字列を取得する
TextRange range = selections[1].GetAsOneRange();
//この文字列が含まれる段落を取得する
Paragraph parapgraph = range.OwnerParagraph;
//段落内のこの文字列の位置を取得する
int index = parapgraph.Items.IndexOf(range);
//この文字列を段落から削除する
parapgraph.Items.Remove(range);
//ハイパーリンクフィールドを作成する
Spire.Doc.Fields.Field field = new Spire.Doc.Fields.Field(document);
field.Type = Spire.Doc.FieldType.FieldHyperlink;
Hyperlink hyperlink = new Hyperlink(field);
hyperlink.Type = HyperlinkType.WebLink;
hyperlink.Uri = "https://ja.wikipedia.org/wiki/.NET_Framework";
parapgraph.Items.Insert(index, field);
//段落にフィールドマーク「start」を挿入する
IParagraphBase start = document.CreateParagraphItem(ParagraphItemType.FieldMark);
(start as FieldMark).Type = FieldMarkType.FieldSeparator;
parapgraph.Items.Insert(index + 1, start);
//2つのフィールドマークの間にテキスト範囲を挿入する
ITextRange textRange = new Spire.Doc.Fields.TextRange(document);
textRange.Text = ".NET Framework";
textRange.CharacterFormat.FontName = range.CharacterFormat.FontName;
textRange.CharacterFormat.TextColor = System.Drawing.Color.Blue;
textRange.CharacterFormat.UnderlineStyle = UnderlineStyle.Single;
parapgraph.Items.Insert(index + 2, textRange);
//段落にフィールドマーク「end」を挿入する
IParagraphBase end = document.CreateParagraphItem(ParagraphItemType.FieldMark);
(end as FieldMark).Type = FieldMarkType.FieldEnd;
parapgraph.Items.Insert(index + 3, end);
//ドキュメントを保存する
document.SaveToFile("ハイパーリンクの追加.docx", Spire.Doc.FileFormat.Docx);
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Imports Spire.Doc.Interface
Namespace InsertHyperlinks
Friend Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのオブジェクトを作成する
Dim document As Document = New Document()
'Wordドキュメントを読み込む
document.LoadFromFile("C:\例.docx")
'ドキュメント内の「.NET Framework」文字列をすべて検索する
Dim selections() As TextSelection = document.FindAllString(".NET Framework", True, True)
'2番目に見つかった文字列を取得する
Dim range As TextRange = selections(1).GetAsOneRange()
'この文字列が含まれる段落を取得する
Dim parapgraph As Paragraph = range.OwnerParagraph
'段落内のこの文字列の位置を取得する
Dim index As Integer = parapgraph.Items.IndexOf(range)
'この文字列を段落から削除する
parapgraph.Items.Remove(range)
'ハイパーリンクフィールドを作成する
Dim field As Spire.Doc.Fields.Field = New Spire.Doc.Fields.Field(document)
field.Type = Spire.Doc.FieldType.FieldHyperlink
Dim hyperlink As Hyperlink = New Hyperlink(field)
hyperlink.Type = HyperlinkType.WebLink
hyperlink.Uri = "https://ja.wikipedia.org/wiki/.NET_Framework"
parapgraph.Items.Insert(index, field)
'段落にフィールドマーク「start」を挿入する
Dim start As IParagraphBase = document.CreateParagraphItem(ParagraphItemType.FieldMark)
(start as FieldMark).Type = FieldMarkType.FieldSeparator
parapgraph.Items.Insert(index + 1, start)
'2つのフィールドマークの間にテキスト範囲を挿入する
Dim textRange As ITextRange = New Spire.Doc.Fields.TextRange(document)
textRange.Text = ".NET Framework"
textRange.CharacterFormat.FontName = range.CharacterFormat.FontName
textRange.CharacterFormat.TextColor = System.Drawing.Color.Blue
textRange.CharacterFormat.UnderlineStyle = UnderlineStyle.Single
parapgraph.Items.Insert(index + 2, textRange)
'段落にフィールドマーク「end」を挿入する
Dim nd As IParagraphBase = document.CreateParagraphItem(ParagraphItemType.FieldMark)
(nd as FieldMark).Type = FieldMarkType.FieldEnd
parapgraph.Items.Insert(index + 3, nd)
'ドキュメントを保存する
document.SaveToFile("ハイパーリンクの追加.docx", Spire.Doc.FileFormat.Docx)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
HTML ドキュメントは HTML でエンコードされた Web ページで、Web ブラウザで表示できます。ほとんどの静的なページには .html 拡張子があるため、Web 上で広く使用されています。時々、Word を HTML に変換する必要があります。この記事では、Spire.Doc for Java を使用して Word を HTML に変換する方法を説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>以下の手順に従って、Word ドキュメントを HTML 形式に変換できます。
import com.spire.doc.*;
public class WordToHtml {
public static void main(String[] args) {
// Documentクラスのインスタンスを作成する
Document document = new Document();
// Word ドキュメントをロードする
document.loadFromFile("Sample.docx");
// Html形式で保存する
document.saveToFile("ToHtml.html", FileFormat.Html);
}
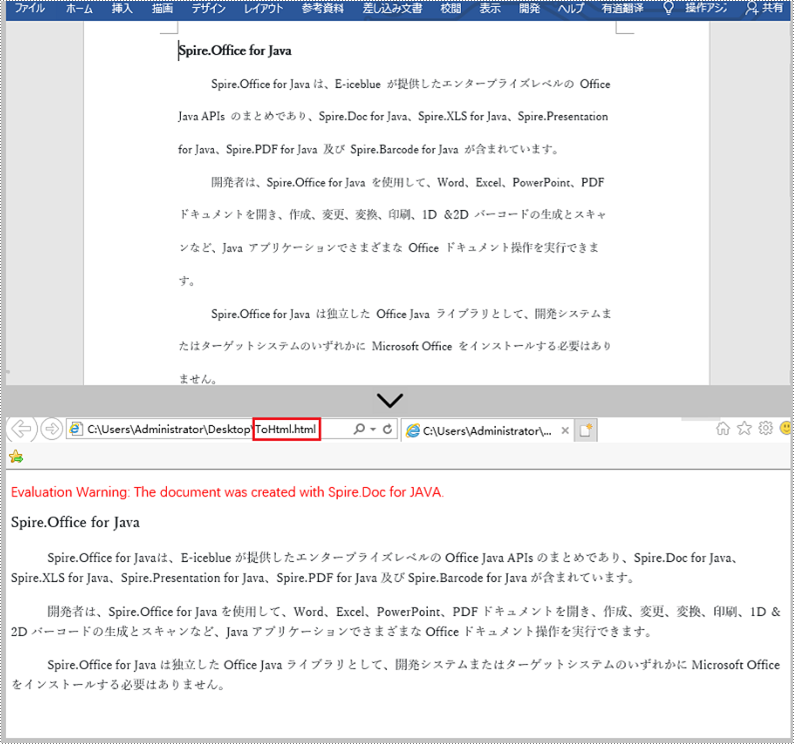
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。 にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





