チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Presentation for Java 9.2.2を発表できることをうれしく思います。このバージョンでは、色の透明度と明るさを取得および設定するための新しいメソッドが追加されています。 PPTからPDFへの変換機能も強化されました。さらに、取得したテキストの配置が正しくないなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2419 | 色の透明度を取得および設定するための getTransparency() および setTransparency(value) メソッドと、色の明るさを取得および設定するための getBrightness() および setBrightness(value) メソッドが追加されました。 |
| Bug | SPIREPPT-2392 | PPT を PDF に変換するときにグラフが正しくない問題を修正しました。 |
| Bug | SPIREPPT-2413 | 取得したテキストの配置が正しくない問題を修正しました。 |
| Bug | SPIREPPT-2429 | htmlのcolor:rgb(0, 0, 0)の解析に失敗する問題を修正しました。 |
| Bug | SPIREPPT-2430 | PPTをPDFに変換すると座標軸の値が変わる問題を修正しました。 |
Spire.PDF 10.2.2のリリースをお知らせいたします。このバージョンでは、PDF から PDF/A、OFDおよび画像への変換機能が強化されています。さらに、テキスト検索や強調表示が機能しないなど、いくつかの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-6427 SPIREPDF-6489 |
テキストの検索と強調表示が機能しない問題を修正しました。 |
| Bug | SPIREPDF-6456 | PDF文書をPDF/A文書に変換する際、アラブ文字体が失われる問題を修正しました。 |
| Bug | SPIREPDF-6493 | PDF文書を印刷する時、印鑑の位置がずれてしまう問題を修正しました。 |
| Bug | SPIREPDF-6509 | 双面印刷する場合、正反面の向き設定が無視される問題を修正しました。 |
| Bug | SPIREPDF-6510 | PDF文書を画像に変換する時、プログラムが「System.NullReferenceException」例外を投げる問題を修正しました。 |
| Bug | SPIREPDF-6524 | PDF文書をOFD文書に変換してから元のPDF文書に戻すと、フォントが過度に太字になる問題を修正しました。 |
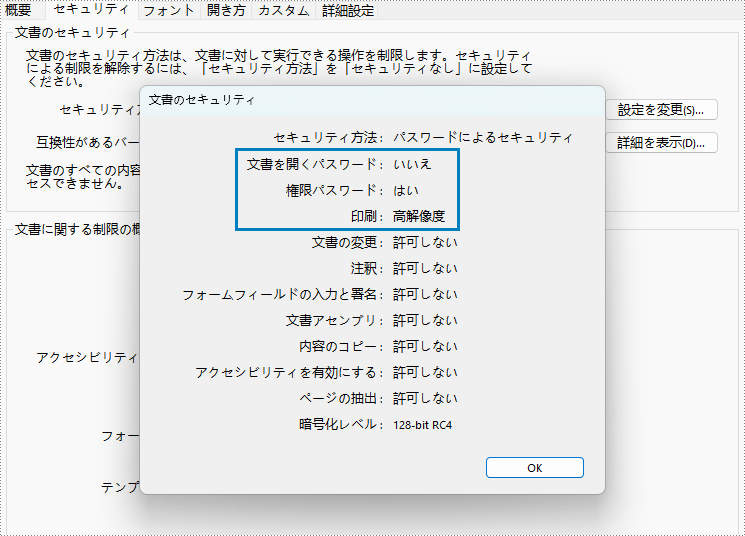
PDF ドキュメントは、いくつかの方法でセキュリティを付加することができます。PDF が許可パスワードで保護されている場合、読者はパスワードを入力せずにドキュメントを開くことができますが、印刷やコンテンツのコピーなど、ドキュメントをさらに操作する権限を持っていないかもしれません。この記事では、Java で Spire.PDF for Java ライブラリを使用して PDF ドキュメントのセキュリティ権限を設定する方法について学びます。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.1.9</version>
</dependency>
</dependencies>以下は、Spire.PDF for Java を使用して PDF ドキュメントにセキュリティ権限を適用する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.security.PdfEncryptionKeySize;
import com.spire.pdf.security.PdfPermissionsFlags;
import java.util.EnumSet;
public class ChangeSecurityPermissions {
public static void main(String[] args) {
//PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
//サンプルのPDFファイルをロードします
doc.loadFromFile("サンプル.pdf");
//オープンパスワードを指定します
String openPsd = "";
//許可パスワードを指定します
String permissionPsd = "password";
//権限を指定します
EnumSet permissionsFlags = EnumSet.of(PdfPermissionsFlags.Print, PdfPermissionsFlags.Full_Quality_Print);
//ドキュメントをオープンパスワードと許可パスワードで暗号化し、権限と暗号化キーサイズを設定します
doc.getSecurity().encrypt(openPsd, permissionPsd, permissionsFlags, PdfEncryptionKeySize.Key_128_Bit);
//ドキュメントを別のPDFファイルに保存します
doc.saveToFile("output/セキュリティ権限.pdf");
}
} 
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
表は PDF の請求書や財務報告書によく見られます。MS Excel が提供するツールを使ってデータを分析できるように、PDF の表データを Excel にエクスポートする必要がある場面に遭遇するかもしれません。この記事では、Spire.Office for Java を使って PDF ページから表を抽出し、それを Excel ワークシートに書き込む方法を説明します。
実際には、PDF から表を抽出するために Spire.PDF for Java を使用し、Excel ファイルを生成するために Spire.XLS for Java を使用します。同じプロジェクトでこれらを使用するには、Java プログラムの依存関係として Spire.Office.jar ファイルを追加する必要があります。
JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>9.1.10</version>
</dependency>
</dependencies>以下は、あるページからすべての表を抽出し、それぞれを独立したワークシートとして Excel ファイルに保存するための主な手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractTableDataAndSaveInExcel {
public static void main(String[] args) {
//PDFドキュメントをロードします
PdfDocument pdf = new PdfDocument("サンプル.pdf");
//PdfTableExtractorインスタンスを作成します
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
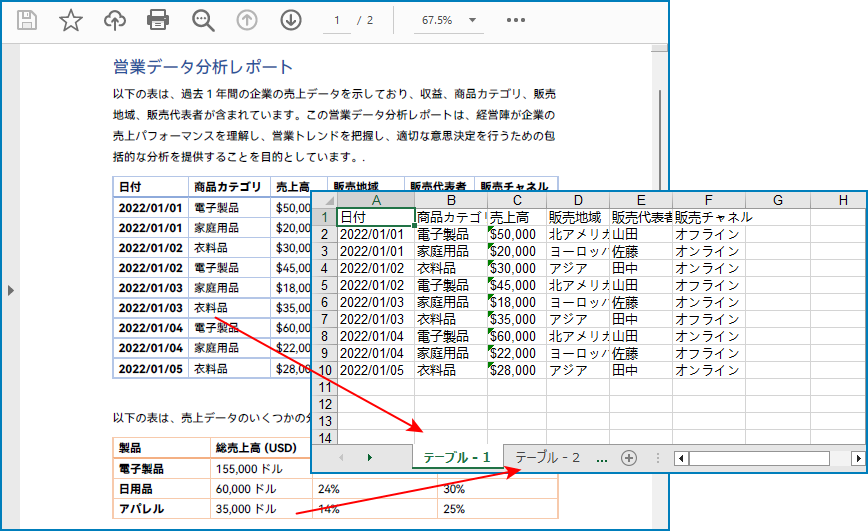
//最初のページからテーブルを抽出します
PdfTable[] pdfTables = extractor.extractTable(0);
//Workbookオブジェクトを作成します
Workbook wb = new Workbook();
//デフォルトのワークシートを削除します
wb.getWorksheets().clear();
//テーブルが見つかった場合
if (pdfTables != null && pdfTables.length > 0) {
//テーブルをループします
for (int tableNum = 0; tableNum < pdfTables.length; tableNum++) {
//ワークシートをワークブックに追加します
String sheetName = String.format("テーブル - %d", tableNum + 1);
Worksheet sheet = wb.getWorksheets().add(sheetName);
//現在のテーブルの行をループします
for (int rowNum = 0; rowNum < pdfTables[tableNum].getRowCount(); rowNum++) {
//現在のテーブルの列をループします
for (int colNum = 0; colNum < pdfTables[tableNum].getColumnCount(); colNum++) {
//現在のテーブルセルからデータを抽出します
String text = pdfTables[tableNum].getText(rowNum, colNum);
//特定のセルにデータを挿入します
sheet.get(rowNum + 1, colNum + 1).setText(text);
}
}
//列幅を自動調整します
for (int sheetColNum = 0; sheetColNum < sheet.getColumns().length; sheetColNum++) {
sheet.autoFitColumn(sheetColNum + 1);
}
}
}
//ワークブックをExcelファイルに保存します
wb.saveToFile("output/PDFの表をExcelに書き出す.xlsx", ExcelVersion.Version2016);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc 12.1.17のリリースをお知らせいたします。 このバージョンでは、段落の左右のインデント機能に文字数を設定するオプションをサポートしています。WordからPDF、HTMLへの変換機能も強化された。さらに、Word を PDF に変換する際の不正なコンテンツ形式の問題など、いくつかの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-9979 SPIREDOC-10058 |
段落の左右のインデント機能に文字数を設定するオプションをサポートしています。
//文字数に応じて左インデントを設定する paragraph.Format.LeftIndentChars = 10; //文字数に応じて右インデントを設定する paragraph.Format.RightIndentChars = 10; |
| Bug | SPIREDOC-3363 | Word ドキュメントを PDF ドキュメントに変換するときにコンテンツ形式が正しくない問題を修正しました。 |
| Bug | SPIREDOC-3363 SPIREDOC-10083 |
Word 文書を PDF 文書に変換するときにフォントが変更される問題を修正しました。 |
| Bug | SPIREDOC-9136 | Word文書をPDF文書に変換する際に、文書構造タグが失われる問題を修正しました。 |
| Bug | SPIREDOC-9718 | 保存された Docx ドキュメント内の数式コンテンツのフォントが傾いてしまう問題を修正しました。 |
| Bug | SPIREDOC-9756 | Word文書をHTML文書に変換する際にプログラムがSystem.ArgumentExceptionをスローする問題を修正しました。 |
| Bug | SPIREDOC-10001 | Word 文書を PDF 文書に変換するときに表の境界線が変更される問題を修正しました。 |
| Bug | SPIREDOC-10016 | ブックマークの内容を置き換えた後に余分な空白の段落が表示される問題を修正しました。 |
| Bug | SPIREDOC-10084 | Word 文書を PDF 文書に変換するときにフォントの太字スタイルが失われる問題を修正しました。 |
| Bug | SPIREDOC-10110 | Doc ドキュメントのロード時にプログラムが System.ArgumentOutOfRangeException をスローする問題を修正しました。 |
| Bug | SPIREDOC-10111 | Word ドキュメントを PDF ドキュメントに変換するときにコンテンツがインデントされる問題を修正しました。 |
| Bug | SPIREDOC-10119 | クロス参照フィールドでコードを取得できない問題を修正しました。 |
| Bug | SPIREDOC-10132 | 空のドキュメントでFixedLayoutDocumentオブジェクトを取得するときにプログラムがSystem.ArgumentOutOfRangeExceptionをスローする問題を修正しました。 |
| Bug | SPIREDOC-10195 | ドキュメントをコピーした後にブックマークのコンテンツを削除するときにプログラムが System.NullReferenceException をスローする問題を修正しました。 |
Spire.Office for C++ 9.1.0のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.XLS for C++ に SpireException と呼ばれるカスタム例外クラスが追加されます。 また、システム言語環境をスペイン語に設定した場合に、ExcelからPDFに変換するとヘッダーの高さが広くなる問題を修正しました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | SpireException というカスタム例外クラスを追加します。 |
| Bug | SPIREXLS-5040 | システム言語環境がスペイン語に設定されている場合に、Excel を PDF に変換するとヘッダーの高さが増加する問題を修正しました。 |
Spire.Office for Java 9.1.10を発表できることをうれしく思います。このバージョンでは、Spire.PDF for Java に PDF を復号化するための 2 つの新しいメソッドが追加されています。 Spire.Doc for Java は、存在しないドキュメントをロードする際の例外キャッチを最適化します。 Spire.Barcode for Java は、QR コードの中央への画像の追加をサポートしています。さらに、多くの既知のバグも修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-6479 | PDF を復号化するための 2 つの新しい方法を追加します。
PdfDocument pdf1 =new PdfDocument();
pdf1.loadFromFile("input.pdf");
pdf1.decrypt();
pdf1.saveToFile("output.pdf"); PdfDocument pdf2 =new PdfDocument();
pdf2.loadFromFile("input.pdf");
pdf2.decrypt(ownerPassword);
pdf2.saveToFile("output.pdf"); |
| Bug | SPIREPDF-6429 | OFD を PDF に変換するときに、プログラムが 「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6482 | PDF を画像に変換するときに、プログラムがハングする問題が修正されました。 |
| Bug | SPIREPDF-6485 | OFD を に変換した後にコンテンツが失われる問題が修正されました。 |
| Bug | SPIREPDF-6486 | PDF を XLSX に変換するときに、プログラムが 「java.lang.NullPointerException」 をスローする問題が修正されました。 |
| Bug | SPIREPDF-6502 | テキストを置換すると内容が文字化けする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-10090 | Bookmark.getFirstColumn() メソッドおよび Bookmark.getLastColumn() メソッドを追加しました。 |
| New feature | SPIREDOC-10163 | 存在しないドキュメントパスの読み込み時の例外キャッチメカニズムを最適化しました。 |
| Bug | SPIREDOC-8257 | Docx ドキュメントを PDF に変換する際のページ分割が正しくない問題を修正しました。 |
| Bug | SPIREDOC-8568 SPIREDOC-9172 |
Docx ドキュメントを PDF に変換する際の内容が正しくない問題を修正しました。 |
| Bug | SPIREDOC-8586 | Docx ドキュメントを PDF に変換する際のヘッダーの下への移動が発生する問題を修正しました。 |
| Bug | SPIREDOC-8797 | Docx ドキュメントを HTML に変換する際に、組み合わせ図形の描画エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-9069 | Docx ドキュメントを PDF に変換する際に、チェックボックスの選択マークが失われ、余分なページが生成される問題を修正しました。 |
| Bug | SPIREDOC-9577 | Docx ドキュメントを PDF に変換する際に、「java.lang.ArrayIndexOutOfBoundsException 」例外がスローされる問題を修正しました。 |
| Bug | SPIREDOC-9611 | Docx ドキュメントを PDF に変換する際に、一部のコンテンツの欠落や正しくないフォーマットの問題を修正しました。 |
| Bug | SPIREDOC-9709 | Doc ドキュメントの読み込み時に 「No have this value 63」 エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-9713 | Docx ドキュメントを PDF に変換する際に、画像の位置がずれる問題を修正しました。 |
| Bug | SPIREDOC-9763 | 変更履歴の効果が正しく反映されない問題を修正しました。 |
| Bug | SPIREDOC-9783 | Docx ドキュメントを PDF に変換する際に、画像とテキストが重なる問題を修正しました。 |
| Bug | SPIREDOC-9799 | ブックマークの内容を置換後、フォントと段落スタイルが変更される問題を修正しました。 |
| Bug | SPIREDOC-10011 | Docx ドキュメントを PDF に変換する際に、ヘッダーの内容が正しく表示されない問題を修正しました。 |
| Bug | SPIREDOC-10015 | Docx ドキュメントを PDF に変換する際に、テーブルのスタイルが正しく反映されない問題を修正しました。 |
| Bug | SPIREDOC-10040 | Docx ドキュメントを PDF に変換する際に、「Argument path cannot be empty」エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-10054 | Docx ドキュメントを PDF に変換する際に、画像の表示が正しくない問題を修正しました。 |
| Bug | SPIREDOC-10074 | Doc ドキュメントを PDF に変換する際に、一部の表が欠落し、表の高さが増加する問題を修正しました。 |
| Bug | SPIREDOC-10143 | WPS で暗号化された Docx ドキュメントを読み込む際に 「java.lang.IllegalStateException: Wrong Word version」 エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-10148 | Docx ドキュメントを PDF に変換する際の目次のリンク先が正しくない問題を修正しました。 |
| Bug | SPIREDOC-10157 | BuiltinDocumentProperties.setKeyWord() メソッドを使用して文書に追加したキーワードが正常に設定されない問題を修正しました。 |
| Bug | SPIREDOC-10179 | Docx ドキュメントを PDF に変換する際のページ番号の形式が変化する問題を修正しました。 |
| カテゴリー | ID | 説明 |
| New feature | - | ライセンスの適用方法が「com.spire.barcode.license.LicenseProvider.setLicenseKey(key)」に変更されました。 |
| New feature | SPIREBARCODE-244 | QRコードの中央への画像の追加をサポートします。
BarcodeSettings barCodeSetting = new BarcodeSettings();
BufferedImage image = ImageIO.read(new File("Image/1.png"));
barCodeSetting.setQRCodeLogoImage(image); |
| Bug | SPIREBARCODE-243 | 縦向きでバーコード認識が失敗する問題を修正しました。 |
Spire.Doc for Java 12.1.16のリリースを発表できることを嬉しく思います。このメソッドは Bookmark.getFirstColumn() メソッドと Bookmark.getLastColumn() メソッドを追加し、存在しないドキュメントパスの読み込み時の例外キャッチメカニズムを最適化しました。 Word から PDF および HTML への変換機能が強化されました。 さらに、リビジョン効果の誤った受け入れなど、いくつかの既知の問題がこのバージョンで修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-10090 | Bookmark.getFirstColumn() メソッドおよび Bookmark.getLastColumn() メソッドを追加しました。 |
| New feature | SPIREDOC-10163 | 存在しないドキュメントパスの読み込み時の例外キャッチメカニズムを最適化しました。 |
| Bug | SPIREDOC-8257 | Docx ドキュメントを PDF に変換する際のページ分割が正しくない問題を修正しました。 |
| Bug | SPIREDOC-8568 SPIREDOC-9172 |
Docx ドキュメントを PDF に変換する際の内容が正しくない問題を修正しました。 |
| Bug | SPIREDOC-8586 | Docx ドキュメントを PDF に変換する際のヘッダーの下への移動が発生する問題を修正しました。 |
| Bug | SPIREDOC-8797 | Docx ドキュメントを HTML に変換する際に、組み合わせ図形の描画エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-9069 | Docx ドキュメントを PDF に変換する際に、チェックボックスの選択マークが失われ、余分なページが生成される問題を修正しました。 |
| Bug | SPIREDOC-9577 | Docx ドキュメントを PDF に変換する際に、「java.lang.ArrayIndexOutOfBoundsException 」例外がスローされる問題を修正しました。 |
| Bug | SPIREDOC-9611 | Docx ドキュメントを PDF に変換する際に、一部のコンテンツの欠落や正しくないフォーマットの問題を修正しました。 |
| Bug | SPIREDOC-9709 | Doc ドキュメントの読み込み時に 「No have this value 63」 エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-9713 | Docx ドキュメントを PDF に変換する際に、画像の位置がずれる問題を修正しました。 |
| Bug | SPIREDOC-9763 | 変更履歴の効果が正しく反映されない問題を修正しました。 |
| Bug | SPIREDOC-9783 | Docx ドキュメントを PDF に変換する際に、画像とテキストが重なる問題を修正しました。 |
| Bug | SPIREDOC-9799 | ブックマークの内容を置換後、フォントと段落スタイルが変更される問題を修正しました。 |
| Bug | SPIREDOC-10011 | Docx ドキュメントを PDF に変換する際に、ヘッダーの内容が正しく表示されない問題を修正しました。 |
| Bug | SPIREDOC-10015 | Docx ドキュメントを PDF に変換する際に、テーブルのスタイルが正しく反映されない問題を修正しました。 |
| Bug | SPIREDOC-10040 | Docx ドキュメントを PDF に変換する際に、「Argument path cannot be empty」エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-10054 | Docx ドキュメントを PDF に変換する際に、画像の表示が正しくない問題を修正しました。 |
| Bug | SPIREDOC-10074 | Doc ドキュメントを PDF に変換する際に、一部の表が欠落し、表の高さが増加する問題を修正しました。 |
| Bug | SPIREDOC-10143 | WPS で暗号化された Docx ドキュメントを読み込む際に 「java.lang.IllegalStateException: Wrong Word version」 エラーが発生する問題を修正しました。 |
| Bug | SPIREDOC-10148 | Docx ドキュメントを PDF に変換する際の目次のリンク先が正しくない問題を修正しました。 |
| Bug | SPIREDOC-10157 | BuiltinDocumentProperties.setKeyWord() メソッドを使用して文書に追加したキーワードが正常に設定されない問題を修正しました。 |
| Bug | SPIREDOC-10179 | Docx ドキュメントを PDF に変換する際のページ番号の形式が変化する問題を修正しました。 |
Spire.Presentation 9.1.5のリリースをお知らせいたします。このバージョンでは、PPTX へのフォントの埋め込みがサポートされています。 また、Ole オブジェクトが非表示かどうかを判断するための IsHidden プロパティも提供されています。 さらに、システムの地域言語がトルコ語に設定されているときに PPTX ドキュメントをロードすると、プログラムが「Microsoft PowerPoint 2007 file is corrpt.」をスローするなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | PPTX でのフォントの埋め込みをサポート: PPTX へのフォントの埋め込みのみをサポートし、PDF および PowerPoint 2003 形式への埋め込みはサポートしません。中国語名のフォントを埋め込む場合、フォント名は中国語で表示されません。
ppt.AddEmbeddedFont(string fontpath); |
| New feature | SPIREPPT-2424 | Ole オブジェクトが非表示かどうかを判断する IsHidden プロパティを提供されています。
OleObjectCollection oles = ppt.Slides[0].OleObjects; OleObject ole= oles[0]; bool result=ole.IsHidden; |
| Bug | SPIREPPT-2418 | システムの地域言語がトルコ語に設定されているときに PPTX ドキュメントをロードすると、プログラムが「Microsoft PowerPoint 2007 file is corrpt.」をスローする問題が修正されました。 |
| Bug | SPIREPPT-2396 | グラフのラベルの位置を変更した後の効果が正しくなくなる問題が修正されました。 |
Spire.PDF 10.1.17のリリースをお知らせいたします。このバージョンでは、PDF から画像、OFDへの変換機能および OFD、 HTML から PDF への変換機能が強化されています。さらに、テキストを置換した後のコンテンツの重複の問題など、既知の問題も修正されています。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-6278 | PdfHTMLTextElement インターフェースを使用して HTML テキストを描画する際の効果が正しくない問題を修正しました。 |
| Bug | SPIREPDF-6400 | ブックマークを追加した後、ドキュメントを保存する際に「 System.OutOfMemoryException」例外が発生する問題を修正しました。 |
| Bug | SPIREPDF-6426 | テキストを置換した後に重複コンテンツが表示される問題を修正しました。 |
| Bug | SPIREPDF-6430 | OFDを PDFに変換する際に 「System.IndexOutOfRangeException」例外が発生する問題を修正しました。 |
| Bug | SPIREPDF-6445 | テーブルを抽出する際に 「System.Collections.Generic.KeyNotFoundException」例外が発生する問題を修正しました。 |
| Bug | SPIREPDF-6471 | ページを回転させた後、画像として保存する際に 「System.ArgumentException」例外が発生する問題を修正しました。 |
| Bug | SPIREPDF-6473 | HTML を PDF に変換する際にカラフルな絵文字が白黒になる問題を修正しました。 |
| Bug | SPIREPDF-6477 | PDF を画像に変換する際の内容が正しくない問題を修正しました。 |
| Bug | SPIREPDF-6480 | PDFを印刷する際に「System.NullReferenceException」例外が発生する問題を修正しました。 |
| Bug | SPIREPDF-6483 | PDF を OFD に変換した後、一部のテキストが太字スタイルでなくなる問題を修正しました。 |





