チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.XLS for Java 12.11.8のリリースを発表できることを嬉しく思います。今回の更新では、ExcelからPDFへの変換機能が強化されました。Excelファイルをロードするときに、アプリケーションが「java.lang.OutOfMemoryError」をスローするなどの問題を修正するなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4154 SPIREXLS-4190 |
ExcelをPDFに変換した後の内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4166 | ExcelをPDFに変換する際にアプリケーションが「java.lang.ClassCastException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4181 | ExcelをPDFに変換した後のフォント変更の問題が修正されました。 |
| Bug | SPIREXLS-4198 | Excelファイルをロードするときにアプリケーションが「java.lang.OutOfMemoryError」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4208 | ExcelをPDFに変換した後にグラフが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4241 | セルに入力されたデータが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4250 | ExcelをPDFに変換した後のコンテンツフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4257 | ExcelをPDFに変換する際にアプリケーションが「Index is less than 0 or more than or equal to the list count.」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4261 | InserArrayを呼び出してint配列を挿入するとスタックがオーバーフローする問題が修正されました。 |
| Bug | SPIREXLS-4264 | グラフの枠線をフィレットに設定しても機能しない問題が修正されました。 |
| Bug | SPIREXLS-4266 | ドキュメントのマージ後にセルスタイルが変更された問題が修正されました。 |
Spire.Doc 10.11.9のリリースを発表できることを嬉しく思います。このバージョンでは、形状の塗りつぶし色の透明度の設定がサポートされ、WordからPDFへの変換機能が強化されました。また、メールマージするときにアプリケーションが「System.InvalidOperationException」をスローするなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-8443 | 形状の塗りつぶし色の透明度の設定がサポートされました。
Paragraph paragraph = section.AddParagraph(); Spire.Doc.Fields.TextBox textbox1 = paragraph.AppendTextBox(100, 50); textbox1.Format.FillColor = Color.Red; textbox1.FillTransparency = 0.45; |
| Bug | SPIREDOC-5456 | WordをPDFに変換した後のテキストフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-5718 | WordをPDFに変換した後の改ページが正しくない問題が修正されました。 |
| Bug | SPIREDOC-7350 SPIREDOC-7605 |
WordをPDFに変換した後のヘッダーの下線と表の枠線が重なる問題が修正されました。 |
| Bug | SPIREDOC-8539 | RTFをPDFに変換した後のテキストフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8635 | メールによるデータのマージに失敗した問題が修正されました。 |
| Bug | SPIREDOC-8636 | メールマージ時にアプリケーションが「System.InvalidOperationException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8691 | 追跡リビジョン機能をオンにした後、コンテンツコントロールのコンテンツを変更した後にdoc.HasChangesがfalseに戻る問題が修正されました。 |
| Bug | SPIREDOC-8709 | WordをPDFに変換して内容が失われていた問題が修正されました。 |
| Bug | SPIREDOC-8785 | WordをPDFに変換する際にアプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
2022年のクリスマスが近づいています。まずはクリスマスおめでとうございます!
セール期間(2022年12月1日~2023年1月5日)には、E-iceblue が今年最大のキャンペーンセールを展開します。弊社の製品に興味がある場合は、この機会に超低価格で購入してください。すでにライセンスを購入している場合は、よりお得な価格で更新することもできます。
キャンペーン期間中に製品を購入する前に、このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。に連絡してクーポンコードを入手してください。
注:これらの割引は、弊社に直接購入する場合にのみ適用されます。
ライセンスが期限切れになっていない場合は、更新後のライセンス期間が前にライセンス期限に基づいて増加します。
Spire.XLS for C++ は、Excel の作成、読み取り、書き込み、変換、印刷に使用できる専門的な C++ API です。この製品は間もなくオンラインになり、他の C++ 製品も続々とオンラインになる。
Sale: このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。
Technical Support: このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。
Skype ID: iceblue.support
文書プロパティ(メタデータとも呼ばれる)とは、文書に関する一連の情報のことです。すべての Word 文書には、タイトル、著者名、テーマ、キーワードなど、一連の組み込み文書プロパティが付属しています。内蔵の文書プロパティに加えて、Microsoft Word では、ユーザーが Word 文書にカスタム文書プロパティを追加することもできます。この記事では、Spire.Doc for .NET を使用して、C# と VB.NET で Word 文書に文書プロパティを追加する方法を説明します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.Doc標準文書プロパティは、名前と値で構成されています。標準文書プロパティは、Microsoft Word によって事前に定義されているため、名前を設定または変更することはできませんが、値を設定または変更することは可能です。
次の手順では、Word 文書内の内蔵文書プロパティに値を設定する方法を説明します。
using Spire.Doc;
namespace AddBuiltinDocumentProperties
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Word文書の読み込み
document.LoadFromFile("洞窟芸術.docx");
//組み込みの文書プロパティを文書に追加する
BuiltinDocumentProperties standardProperties = document.BuiltinDocumentProperties;
standardProperties.Title = "洞窟芸術";
standardProperties.Subject = "石器時代の芸術";
standardProperties.Author = "Izzy Wisher";
standardProperties.Company = "Aeon.co";
standardProperties.Manager = "Nigel Warburton";
standardProperties.Category = "芸術";
standardProperties.Keywords = "洞窟芸術、石器時代";
standardProperties.Comments = "石器時代の洞窟芸術を紹介した資料です。";
//結果文書を保存する
document.SaveToFile("標準文書プロパティ.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Namespace AddBuiltinDocumentProperties
Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのインスタンスを作成する
Dim document As Document = New Document()
'Word文書の読み込み
document.LoadFromFile("洞窟芸術.docx")
'組み込みの文書プロパティを文書に追加する
Dim standardProperties As BuiltinDocumentProperties = document.BuiltinDocumentProperties
standardProperties.Title = "洞窟芸術"
standardProperties.Subject = "石器時代の芸術"
standardProperties.Author = "Izzy Wisher"
standardProperties.Company = "Aeon.co"
standardProperties.Manager = "Nigel Warburton"
standardProperties.Category = "芸術"
standardProperties.Keywords = "洞窟芸術、石器時代"
standardProperties.Comments = "石器時代の洞窟芸術を紹介した資料です。"
'結果文書を保存する
document.SaveToFile("標準文書プロパティ.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace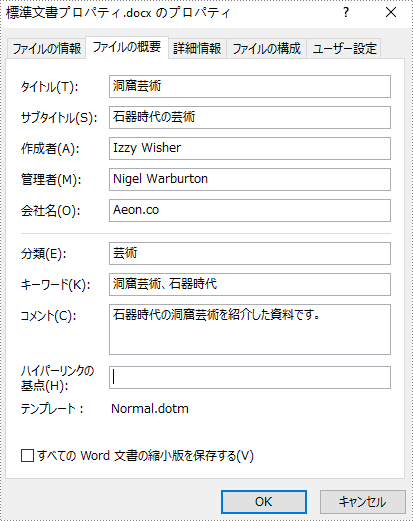
カスタム文書プロパティは、文書の作成者やユーザが定義することができます。各カスタム文書プロパティは、名前、値、データ型を含む必要があります。データ型は、この4つの種類(Text、Date、Number、Yes or No)のうちの1つです。
以下の手順は、Word 文書にさまざまなデータ型を持つカスタム文書プロパティを追加する方法を示しています。
using Spire.Doc;
using System;
namespace AddCustomDocumentProperties
{
class Program
{
static void Main(string[] args)
{
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Word文書の読み込み
document.LoadFromFile("洞窟芸術.docx");
//カスタム文書プロパティを文書に追加する
CustomDocumentProperties customProperties = document.CustomDocumentProperties;
customProperties.Add("文書ID", 1);
customProperties.Add("許可取得の有無", true);
customProperties.Add("許可者", "John Smith");
customProperties.Add("許可日", DateTime.Today);
//結果文書を保存する
document.SaveToFile("カスタム文書プロパティ.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Imports System
Imports System.Reflection.Metadata
Namespace AddCustomDocumentProperties
Class Program
Shared Sub Main(ByVal args() As String)
'Documentクラスのインスタンスを作成する
Dim document As Document = New Document()
'Word文書の読み込み
document.LoadFromFile("洞窟芸術.docx")
'カスタム文書プロパティを文書に追加する
Dim customProperties As CustomDocumentProperties = document.CustomDocumentProperties
customProperties.Add("文書ID", 1)
customProperties.Add("許可取得の有無", True)
customProperties.Add("許可者", "John Smith")
customProperties.Add("許可日", DateTime.Today)
'結果文書を保存する
document.SaveToFile("カスタム文書プロパティ.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace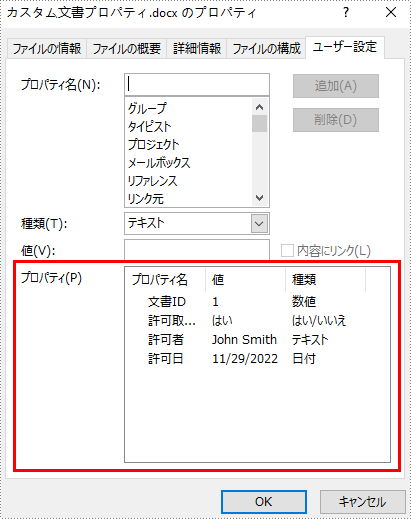
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS 12.11.3のリリースを発表できることを嬉しく思います。このリリースでは、CEILING.MATH、BITOR、BITAND、BITLSHIFT、BITRSHIFT 関数、および「SHA-512」暗号化方式が追加されました。また、shapeグループ化と全体のピボット・テーブルのレイアウト・モードを設定することもサポートしました。また、今回のアップデートではExcelからPDF、HTMLからExcelへの変換機能が強化されました。また、このバージョンでは既知の問題の一部が正常に修正されました。詳細は以下をお読みください。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4120 | CEILING.MATH関数をサポートしました。
Workbook workbook = new Workbook();
workbook.Worksheets[0].Range["A1"].Formula = "CEILING.MATH(-2.78,5,-1)";
workbook.CalculateAllValue();
workbook.SaveToFile("1.xlsx",ExcelVersion.Version2016); |
| New feature | SPIREXLS-4195 | BITOR関数をサポートしました。
Workbook workbook = new Workbook();
workbook.Worksheets[0].Range["A1"].Formula = "BITOR(23,10)";
workbook.CalculateAllValue();
workbook.SaveToFile("1.xlsx",ExcelVersion.Version2016); |
| New feature | SPIREXLS-4199 | BITAND関数をサポートしました。
Workbook workbook = new Workbook();
workbook.Worksheets[0].Range["A1"].Formula = "BITAND(23,10)";
workbook.CalculateAllValue();
workbook.SaveToFile("1.xlsx",ExcelVersion.Version2016); |
| New feature | SPIREXLS-4212 | BITLSHIFT関数をサポートしました。
Supports BITLSHIFT formula.
Workbook workbook = new Workbook();
workbook.Worksheets[0].Range["A1"].Formula = "BITLSHIFT(23,2)";
workbook.CalculateAllValue();
workbook.SaveToFile("1.xlsx",ExcelVersion.Version2016); |
| New feature | SPIREXLS-4214 | BITRSHIFT関数をサポートしました。
Workbook workbook = new Workbook();
workbook.Worksheets[0].Range["A1"].Formula = "BITRSHIFT(23,2)";
workbook.CalculateAllValue();
workbook.SaveToFile("1.xlsx",ExcelVersion.Version2016); |
| New feature | SPIREXLS-4191 | shapeグループ化をサポートしました。
Workbook workbook = new Workbook();
Worksheet worksheet = workbook.Worksheets[0];
IPrstGeomShape shape1 = worksheet.PrstGeomShapes.AddPrstGeomShape(1, 3, 50, 50, PrstGeomShapeType.RoundRect);
IPrstGeomShape shape2 = worksheet.PrstGeomShapes.AddPrstGeomShape(5, 3, 50, 50, PrstGeomShapeType.Triangle);
GroupShapeCollection groupShapeCollection = worksheet.GroupShapeCollection;
groupShapeCollection.Group(new Spire.Xls.Core.IShape[] { shape1,shape2});
workbook.SaveToFile("1.xlsx",ExcelVersion.Version2013); |
| New feature | SPIREXLS-4194 | 「SHA-512」暗号化方式をサポートしました。 |
| New feature | SPIREXLS-4200 | ピボット・テーブル全体を設定するためのレイアウト・モードが追加されました。
xlsPivotTable.Options.ReportLayout = PivotTableLayoutType.Tabular; |
| Bug | SPIREXLS-4161 | HtmlをExcelに変換した後の表の枠線とスタイルが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4163 | 条件付きフォーマットの色を取得する際にアプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4164 | グラフを画像に変換した後にコンマが1つ多くなる問題が修正されました。 |
| Bug | SPIREXLS-4182 | エラーパスワードでExcelドキュメントを復号したときにアプリケーションがスローしなかった問題が修正されました。 |
| Bug | SPIREXLS-4189 | 隠し列を削除するとExcelに空白列が多くなる問題が修正されました。 |
| Bug | SPIREXLS-4197 | ドキュメントをロードして保存した後、結果ドキュメントと元のドキュメントの内容が異なる問題が修正されました。 |
| Bug | SPIREXLS-4211 | ExcelをCSVドキュメントに変換した後の二重引用符が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4218 | セル範囲の計算結果が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4227 | セルのRTFテキストを取得する際にアプリケーションが「Unknown font」をスローした問題が修正されました。 |
| Bug | SPIREXLS-4231 | ExcelをPDFに変換する際にアプリケーションが「Shapes fail to be rendered」をスローした問題が修正されました。 |
| Bug | SPIREXLS-4245 | ExcelをPDFに変換する際にアプリケーションが「System.OutOfMemoryException」をスローした問題が修正されました。 |
| Bug | SPIREXLS-4247 | HtmlをExcelに変換した後のフォーマットの不一致が修正されました。 |
| Bug | SPIREXLS-4252 | ストリーム形式でファイルを保存すると、スライサー(slicers)が失われる問題が修正されました。 |
| Bug | SPIREXLS-4254 | オペレーティングシステムの言語領域が変更された後、保存されたドキュメントのオープンプロンプトの内容に誤りがあった問題が修正されました。 |
| Bug | SPIREXLS-4258 | sheetをコピーする際にアプリケーションが「System.NullReferenceException」をスローした問題が修正されました。 |
Word 文書を扱う過程で、しばしば困った事態が発生します。例えば、大きな Word 文書を完成させたとき、何度も出てくる名称や専門用語の中に間違いがあることが判明した。間違っている言葉を一つずつ変えていくとなると、作業量が多すぎて大変です。幸いなことに、このような問題を素早く解決する簡単な方法がいくつかあります。MS Word には、検索と置換という機能があり、ユーザーは置き換えたいものを素早く見つけて、新しいテキストに置き換えることができます。プロフェッショナル向け開発コンポーネント Spire.Doc for Java は、コードを通じて単語の検索と置換を行う機能を開発者に提供します。この記事では、Spire.Doc for Java を使って、Word 文書内のテキストを素早く検索し、新しいテキストや画像に置き換える方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.7.10</version>
</dependency>
</dependencies>Spire.Doc for Java が提供する Document.replace() メソッドを使うだけで、素早くテキストを検索し、新しいテキストに置き換えることができます。 このメソッドは、すべてのマッチを新しいテキストに置き換えます。大文字と小文字を区別するかどうか、検索語を完全に検索するかどうかの設定に対応しています。
テキストを検索し、一致するものをすべて置き換える詳細な手順は次のとおりです。
import com.spire.doc.Document;
public class replaceAll {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("洞窟芸術.docx");
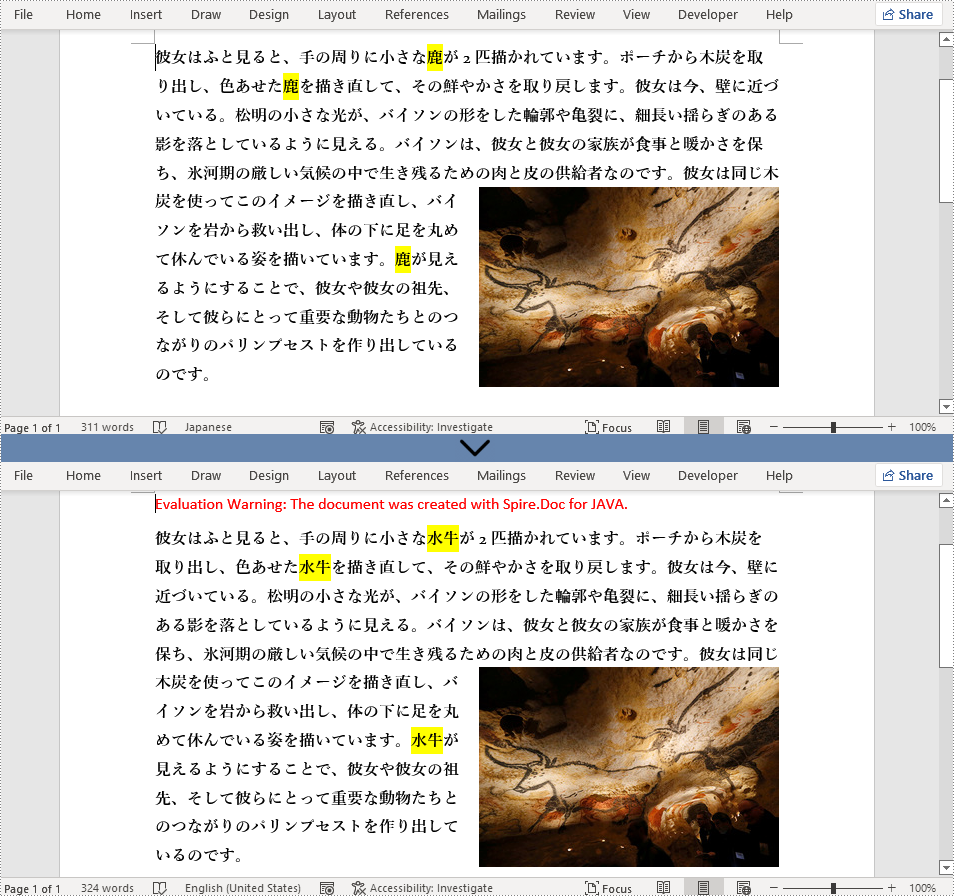
//「鹿」のマッチングをすべて「水牛」に置き換える
document.replace("鹿", "水牛", false, true);
//結果ファイルを保存する
document.saveToFile("すべて置き換える.docx");
}
}
Doc for Java には、Document.setReplaceFirst() メソッドもあり、Document.replace() メソッドの置換モードを、最初の一致を置換するか、すべての一致を置換するかを変更することができます。
テキストを検索し、最初に一致したものを置き換えるには、次のように操作します。
import com.spire.doc.Document;
public class replaceFirst {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("洞窟芸術.docx");
//置換モードを最初のマッチを置換するモードに変更する
document.setReplaceFirst(true);
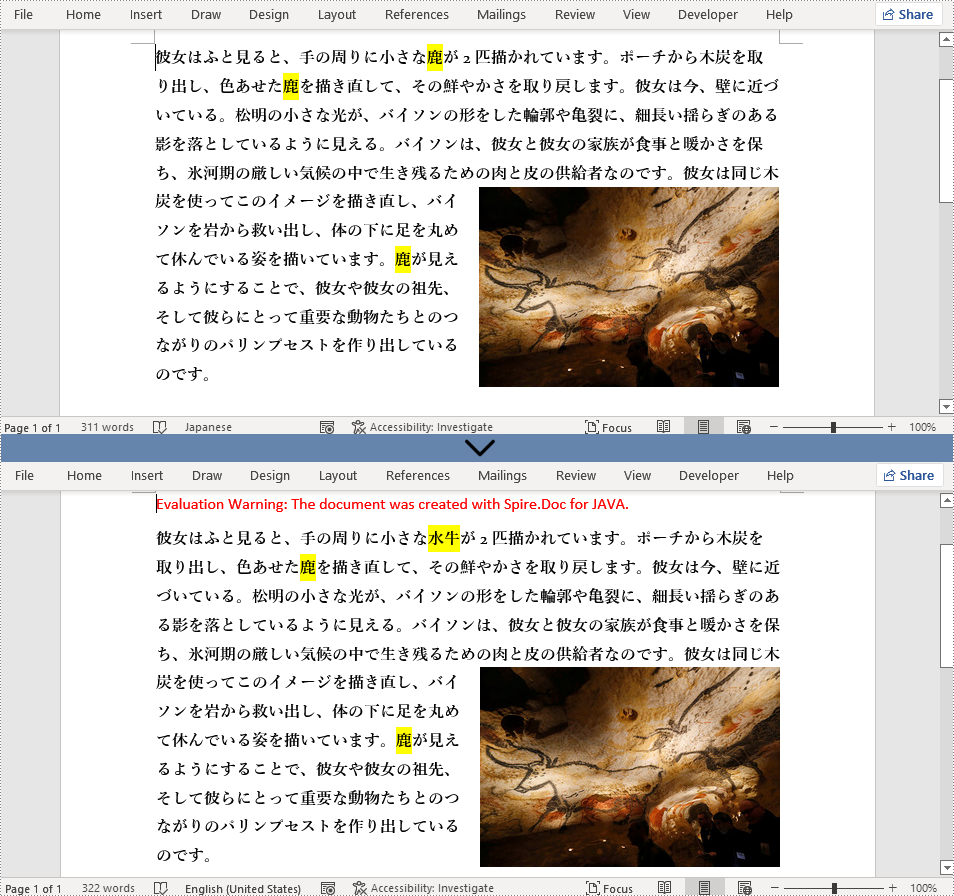
//「テキスト「鹿」の最初のマッチを新しいテキスト「水牛」に置き換える
document.replace("鹿", "水牛", false, true);
//結果ファイルを保存する
document.saveToFile("最初のマッチを置き換える.docx");
}
}
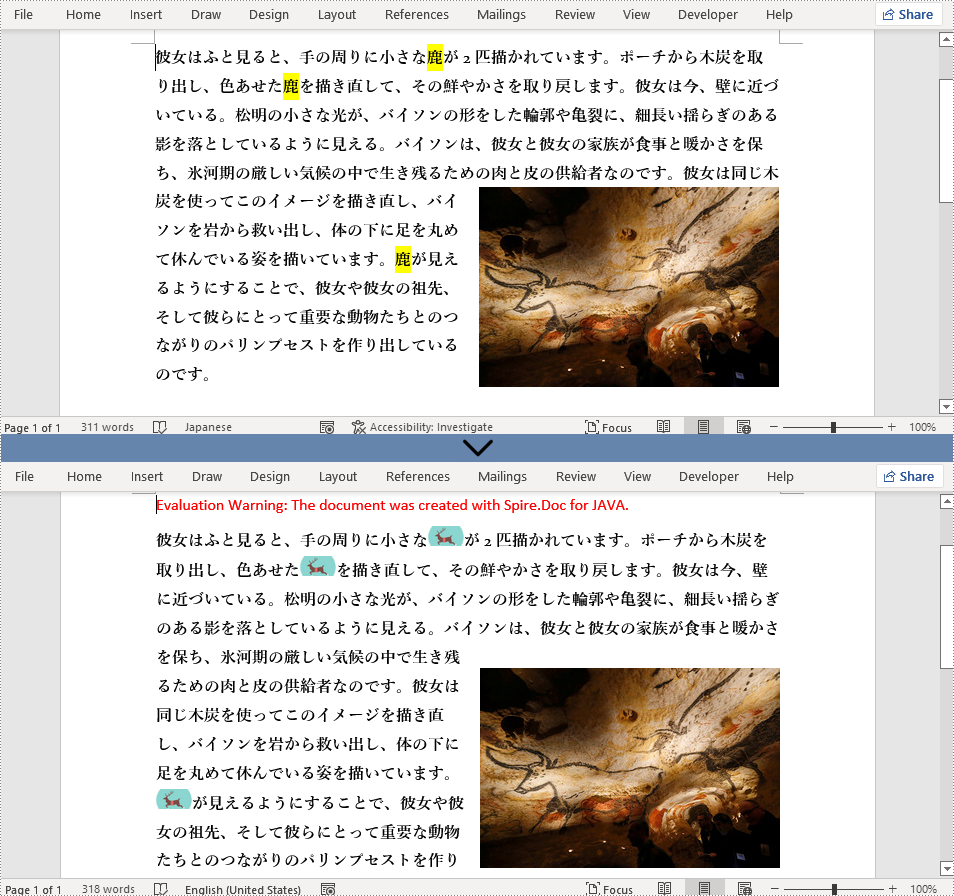
Spire.Doc for Java は、テキストを検索し、一致したものをすべて画像として置き換えることもサポートしています。そのためには、テキストを検索して、マッチしたものを全て取得する必要があります。次に、画像をドキュメントのオブジェクトとして読み込み、マッチしたテキストがある場所に挿入し、テキストを削除します。
詳細な手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.TextSelection;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextRange;
public class replaceTextWithImage {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("洞窟芸術.docx");
//ドキュメント内の「鹿」にマッチするすべてのテキストを検索する
TextSelection[] selections = document.findAllString("鹿", true, true);
//一致したテキストをループして、すべて画像に置き換える
int index = 0;
TextRange range = null;
for (Object obj : selections) {
TextSelection textSelection = (TextSelection)obj;
//DocPictureクラスのオブジェクトを作成し、画像を読み込む
DocPicture pic = new DocPicture(document);
pic.loadImage("鹿.png");
range = textSelection.getAsOneRange();
index = range.getOwnerParagraph().getChildObjects().indexOf(range);
range.getOwnerParagraph().getChildObjects().insert(index,pic);
range.getOwnerParagraph().getChildObjects().remove(range);
}
//指定されたマッチを画像に置き換える
//DocPictureクラスのオブジェクトを作成し、画像を読み込む
//DocPicture pic = new DocPicture(document);
//pic.loadImage("鹿.png");
//Object object = selections[1];
//TextSelection selection = (TextSelection) object;
//TextRange textRange = selection.getAsOneRange();
//int i = textRange.getOwnerParagraph().getChildObjects().indexOf(textRange);
//textRange.getOwnerParagraph().getChildObjects().insert(i,pic);
//textRange.getOwnerParagraph().getChildObjects().remove(textRange);
//結果ファイルを保存する
document.saveToFile("テキストを検索して画像に置き換える.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
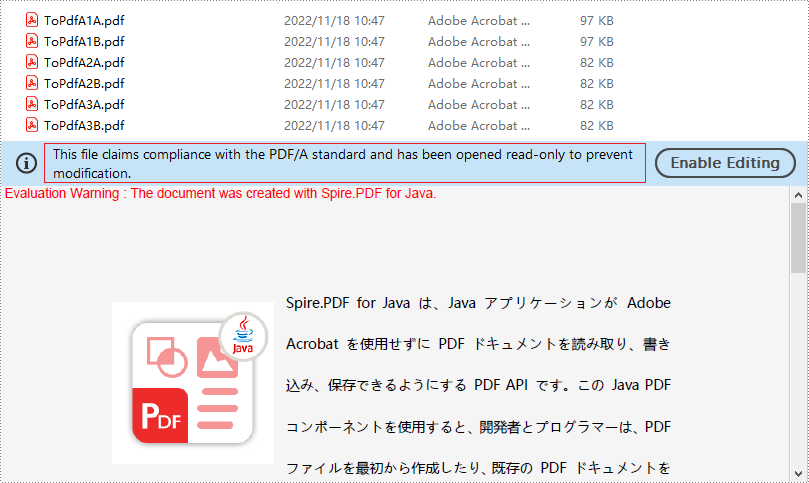
PDF/A は、電子文書のアーカイブと長期保存のために設計された一種の PDF 形式です。簡単に破損したり汚れたりする紙のドキュメントとは異なり、PDF/A 形式は、長期保存後でもまったく同じ方法でドキュメントを複製できることを保証します。この記事では、Spire.PDF for Java を使用して PDF を PDF/A-1A, 2A, 3A, 1B, 2B と 3B の PDF に変換する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
</dependencies>Spire.PDF for Java は、PDF を PDF/A-1A, 2A, 3A, 1B, 2B と 3B など、さまざまな PDF/A フォーマットに変換することをサポートしています。以下に詳細な変換手順を示します。
import com.spire.pdf.conversion.PdfStandardsConverter;
public class ConvertPdfToPdfA {
public static void main(String[] args) {
//PdfStandardsConverterインスタンスを作成し、パラメータとしてPDFサンプルファイルをアップロードする
PdfStandardsConverter converter = new PdfStandardsConverter("sample.pdf");
//PDFをPDF/A1Aに変換する
converter.toPdfA1A("output/ToPdfA1A.pdf");
//PDFをPDFA1Bに変換する
converter.toPdfA1B("output/ToPdfA1B.pdf");
//PDFをPDFA2Aに変換する
converter.toPdfA2A( "output/ToPdfA2A.pdf");
//PDFをPDFA2Bに変換する
converter.toPdfA2B("output/ToPdfA2B.pdf");
//PDFをPDFA3Aに変換する
converter.toPdfA3A("output/ToPdfA3A.pdf");
//PDFをPDFA3Aに変換する
converter.toPdfA3B("output/ToPdfA3B.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF for Java 8.11.8のリリースを発表できることをうれしく思います。 このバージョンでは、PdfTrueTypeFontオブジェクトの解放がサポートされました。PDFから画像への変換機能が強化されました。また、抽出されたテーブルの内容が不完全であるなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5590 | PdfTrueTypeFontオブジェクトの解放がサポートされました。
pdfTrueTypeFont.dispose(); |
| Bug | SPIREPDF-3959 | PDFをExcelに変換した後のセル線がマージされていない問題が修正されました。 |
| Bug | SPIREPDF-5505 | .pfx証明書ファイルを使用して署名したときに、証明書チェーン内のすべての証明書が署名に含まれていなかった問題が修正されました。 |
| Bug | SPIREPDF-5509 SPIREPDF-5583 |
抽出されたテーブルの内容が不完全である問題が修正されました。 |
| Bug | SPIREPDF-5540 | Mac OS環境でPDFを画像に変換した後の内容が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5582 | PDFを画像に変換した後に部分的に黒い長方形で表示されていた問題が修正されました。 |
| Bug | SPIREPDF-5585 | PDFを画像に変換した後に線が失われていた問題が修正されました。 |
| Bug | SPIREPDF-5594 | 設定ドロップダウンボックスに値が表示された後、WPSで出力されたPDFドキュメントを開く際に値が文字化けしてしまう問題が修正されました。 |
| Bug | SPIREPDF-5618 | PdfHorizontalOverflowType列挙タイプが混同されていた問題が修正されました。 |
セキュリティ上の理由から、送り状などの多くの財務ファイルは通常 PDF 形式で保存されています。これらのドキュメントに対してデータ分析と計算を実行するには、Excel に変換する必要がある場合があります。この記事では、Spire.PDF for Java を使用して PDF を Excel に変換する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
</dependencies>Spire.PDF for Java が提供する PdfDocument.saveToFile(String, FileFormat) メソッドは、PDF ドキュメントを Excel に変換することをサポートします。次は詳細な変換手順です。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class ConvertPdfToExcel {
public static void main(String[] args) {
//PdfDocumentクラスのインスタンスを初期化する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントをロードする
pdf.loadFromFile("Sample.pdf");
//ドキュメントをExcelに保存する
pdf.saveToFile("PdfToExcel.xlsx", FileFormat.XLSX);
}
}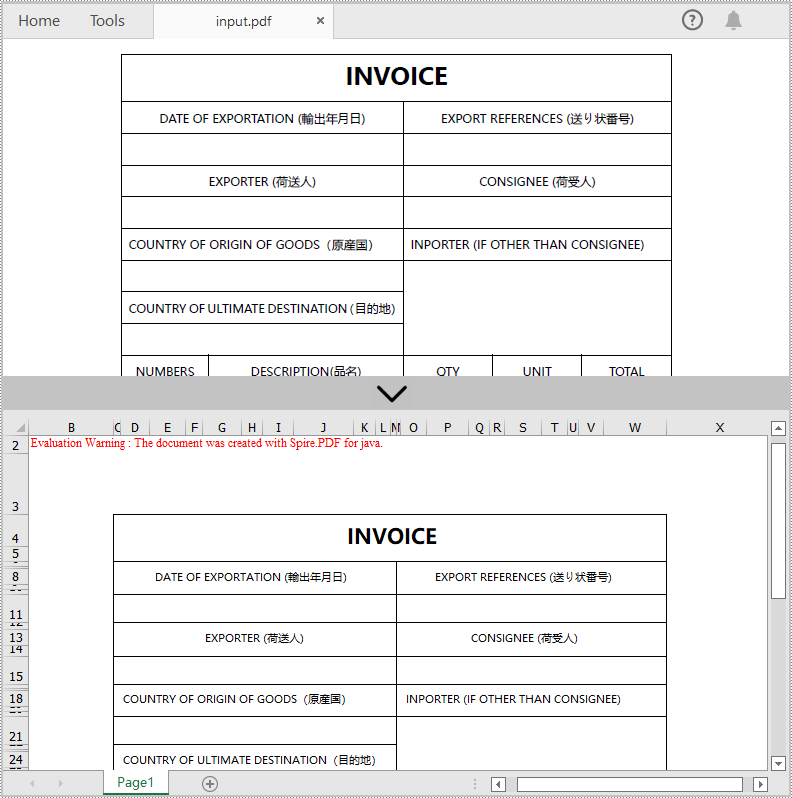
この例では、複数の PDF ページを複数の Excel ワークシートに変換します。複数ページの PDF を単一の Excel ワークシートに変換する場合は、Java:複数の PDF ページを1つの Excel ワークシートに変換する方法 を参照してください。
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
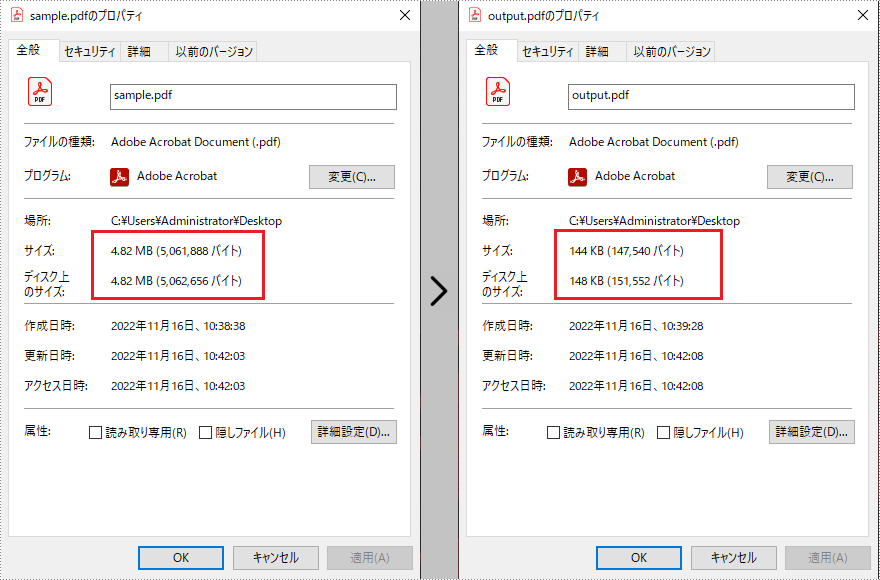
大きい PDF ドキュメントよりも小さいサイズのドキュメントの方が転送や保存に便利です。これが PDF を圧縮する最も一般的な理由の1つです。この記事では、Spire.PDF for Java を使用して PDF ドキュメントを圧縮する方法を紹介します。
ここでは、画像、フィールド、コメント、ブックマーク、添付ファイル、埋め込みフォントを削除することによって PDF サイズを小さくすることには触れません。ライブラリを使用してこれらの操作を実行したい場合は、チュートリアルに記載されている適切な記事を参照してください。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.11.0</version>
</dependency>
</dependencies>Spire.PDF for Java が提供する PdfDocument.setCompressionLevel() と PdfBitmap.setQuality() メソッドは、圧縮レベルの最適な設定と画像の品質の圧縮をサポートします。次に、PdfPageBase.replaceImage() メソッドを使用して圧縮された画像を元の画像に置き換えます。以下に詳細な圧縮手順を示します。
import com.spire.pdf.PdfCompressionLevel;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.exporting.PdfImageInfo;
import com.spire.pdf.graphics.PdfBitmap;
public class CompressPdfDocument {
public static void main(String[] args) {
//PdfDocumentオブジェクトを作成する
PdfDocument doc = new PdfDocument();
//PDFドキュメントをロードする
doc.loadFromFile("sample.pdf");
//増分更新を禁止する
doc.getFileInfo().setIncrementalUpdate(false);
//圧縮レベルを最適に設定する
doc.setCompressionLevel(PdfCompressionLevel.Best);
//ドキュメント内のページをループする
for (int i = 0; i < doc.getPages().getCount(); i++) {
//特定のページを取得する
PdfPageBase page = doc.getPages().get(i);
//ページの画像情報コレクションを取得する
PdfImageInfo[] images = page.getImagesInfo();
//コレクション内のすべてのアイテムをループする
if (images != null && images.length > 0)
for (int j = 0; j < images.length; j++) {
//特定の画像を取得する
PdfImageInfo image = images[j];
PdfBitmap bp = new PdfBitmap(image.getImage());
//圧縮品質を設定する
bp.setQuality(20);
//元の画像を圧縮された画像に替える
page.replaceImage(j, bp);
}
//文書を別のPDFファイルに保存する
doc.saveToFile("output.pdf");
doc.close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





