チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Doc for Java 12.1.0のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.Pdf.jarへの依存を削除し、ライセンスの適用方法を「com.spire.doc.license.LicenseProvider.setLicenseKey(key)」に変更しました。 さらに、画像透かしを追加する新しいメソッドなど、多くの新機能が追加されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Adjustment | - | Spire.Pdf.jar への依存関係を削除しました。 |
| Adjustment | - | ライセンスの適用方法を 「com.spire.doc.license.LicenseProvider.setLicenseKey(key) 」に変更しました。 |
| New feature | - | 次のメソッド、クラス、およびインターフェイスは非推奨になりました。
The "newEngine" parameter in the Document constructor no longer has any effect. The internal mechanism now defaults to using the new engine. The HeaderType enum. The GroupedShapeCollection class. The ShapeObjectTextCollection class. The MailMergeData interface. The EnumInterface interface. The public PictureWaterMark(InputStream inputeStream, boolean washout) constructor. The public PictureWaterMark(String filename, boolean washout) constructor. The downloadImage method in the Field class. The IDocOleObject interface. PointsConverter クラス |
| New feature | - | TableCell クラスの getWidth() メソッドと setWidth() メソッドは非推奨となり、getCellWidth() メソッドと setCellWidth() メソッドに置き換えられました。 |
| New feature | - | 以下の名前空間を変更します。
com.spire.license.LicenseProvider -> com.spire.doc.License.LicenseProvider |
| New feature | - | 継承関係を変更します。「ShapeGroup implements ShapeObject」を「ShapeGroup implements ShapeBase」に変更します。 |
| New feature | - | Documentの破棄時に、カスタムフォントに関連するデータも同時に破棄できるようになりました。
// カスタムフォントを設定する
Document.setCustomFontsFolders(string filePath);
// カスタムフォントを破棄する
Document.clearCustomFontsFolders();
// キャッシュ内のメモリを占有しているシステム フォント キャッシュをクリアする
Document.clearSystemFontCache();
Example code:
Document doc = new Document();
doc.loadFromFile("inputFile.docx");
doc.setCustomFontsFolders(@"d:\Fonts");
doc.saveToFile("output.pdf", FileFormat.PDF);
doc.close();
doc.dispose(); |
| New feature | - | 次の列挙型クラスを変更します。
com.spire.doc.FileFormat.WPS -> com.spire.doc.FileFormat.Wps com.spire.doc.FileFormat.WPT -> com.spire.doc.FileFormat.Wpt ComparisonLevel -> TextDiffMode |
| New feature | - | 以下のメソッドを変更します。
ComparisonLevel getLevel() -> getTextCompareLevel() setLevel(ComparisonLevel value) -> setTextCompareLevel(TextDiffMode) IsPasswordProtect() -> isEncrypted() getFillEfects() -> getFillEffects() |
| New feature | - | 画像の透かしを追加するメソッドを追加しました。
File imageFile = new File("data/E-iceblue.png");
BufferedImage bufferedImage = ImageIO.read(imageFile);
// Create a new instance of the PictureWatermark class with the input BufferedImage, and set the scaling factor for the watermark image
PictureWatermark picture = new PictureWatermark(bufferedImage,false);
// Or another way to create PictureWatermark
// PictureWatermark picture = new PictureWatermark();
// picture.setPicture(bufferedImage);
// picture.isWashout(false);
// Set the scaling factor for the watermark image
picture.setScaling(250);
// Set the watermark to be applied to the document
document.setWatermark(picture); |
| New feature | - | Shape は、グラフィックスの塗りつぶしを操作するための getFill() メソッドを公開します。setFillColor(null) メソッドの代わりに getFill().setOn(false) を使用します。 |
| New feature | SPIREDOC-10005 | グラフの追加のサポートが追加されました。
// Document の新しいインスタンスを作成します
Document document = new Document();
// ドキュメントにセクションを追加します
Section section = document.addSection();
// セクションに段落を追加し、そこにテキストを追加します
section.addParagraph().appendText("Line chart.");
// セクションに新しい段落を追加します
Paragraph newPara = section.addParagraph();
// 指定された幅と高さの折れ線グラフの形状を段落に追加します
ShapeObject shape = newPara.appendChart(ChartType.Line, 500, 300);
// 図形からチャートオブジェクトを取得します
Chart chart = shape.getChart();
// チャートのタイトルを取得します
ChartTitle title = chart.getTitle();
// グラフのタイトルのテキストを設定します
title.setText("My Chart");
// チャート内の既存の系列をクリアします
ChartSeriesCollection seriesColl = chart.getSeries();
seriesColl.clear();
// カテゴリ (X 軸の値) を定義します
String[] categories = { "C1", "C2", "C3", "C4", "C5", "C6" };
// 指定されたカテゴリと Y 軸値を持つ 2 つの系列をグラフに追加します
seriesColl.add("AW Series 1", categories, new double[] { 1, 2, 2.5, 4, 5, 6 });
seriesColl.add("AW Series 2", categories, new double[] { 2, 3, 3.5, 6, 6.5, 7 });
// ドキュメントを Docx 形式でファイルに保存します
document.saveToFile("AppendLineChart.docx", FileFormat.Docx_2016);
// ドキュメントオブジェクトを使い終わったら破棄します
document.dispose(); |
| New feature | SPIREDOC-7515 | ページのコンテンツを取得するために、ページ モデル Spire.Doc.Pages が提供されています。
// Document の新しいインスタンスを作成します
Document doc = new Document();
// 指定されたファイルからドキュメントを読み込みます
doc.loadFromFile(inputFile);
// ロードされたドキュメントを使用してFixedLayoutDocumentオブジェクトを作成します
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(doc);
// 抽出されたテキストを保存する StringBuilder を作成します
StringBuilder stringBuilder = new StringBuilder();
// 最初のページの最初の行を取得し、StringBuilder に追加します
FixedLayoutLine line = layoutDoc.getPages().get(0).getColumns().get(0).getLines().get(0);
stringBuilder.append("Line: " + line.getText() + "\r\n");
// その行に関連付けられた元の段落を取得し、そのテキストを StringBuilder に追加します
Paragraph para = line.getParagraph();
stringBuilder.append("Paragraph text: " + para.getText() + "\r\n");
// ヘッダーとフッターを含む最初のページのすべてのテキストを取得し、StringBuilder に追加します
String pageText = layoutDoc.getPages().get(0).getText();
stringBuilder.append(pageText + "\r\n");
// ドキュメントの各ページを反復処理し、各ページの行数を出力します
for (Object obj : layoutDoc.getPages()) {
FixedLayoutPage page = (FixedLayoutPage) obj;
LayoutCollection |
| New feature | - | SVG グラフィックの追加のサポートが追加されました。
//新しい Document オブジェクトを作成します Document document = new Document(); //新しいセクションをドキュメントに追加します Section section = document.addSection(); //新しい段落をセクションに追加します Paragraph paragraph = section.addParagraph(); //画像 (SVG) を段落に追加します paragraph.appendPicture(inputSvg); //ドキュメントを指定された出力ファイルに保存します document.saveToFile(outputFile, FileFormat.Docx_2013); //ドキュメントを閉じます document.dispose(); |
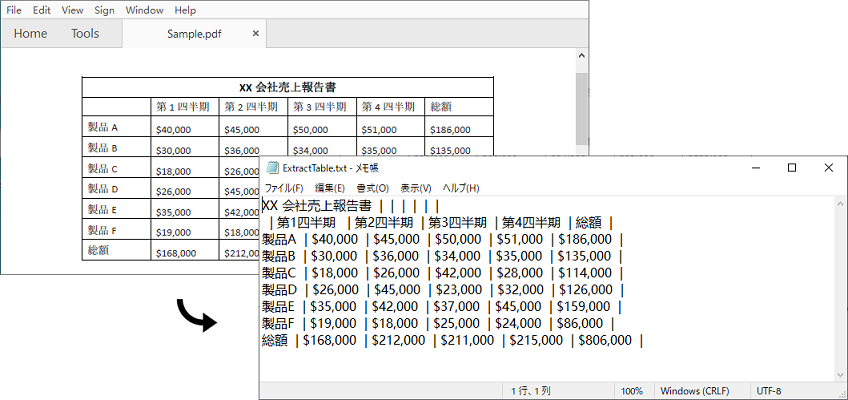
テーブルは、PDF で最もよく使用される書式設定要素の 1 つです。 場合によっては、さらに分析を行うために PDF のテーブルからデータを抽出する必要がある場合があります。この記事では、Spire.PDF for Java を使用して PDF からテーブルのデータを抽出する方法を紹介します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Mavenを使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.12.0</version>
</dependency>
</dependencies>Spire.PDF for Java は、PdfTableExtractor.extractTable(int pageIndex) メソッドを使用して、特定の PDF ページからテーブルを検出して抽出します。以下は、PDF ファイルからテーブルデータを抽出する手順です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String []args) throws Exception {
//サンプルPDFファイルをロードする
PdfDocument pdf = new PdfDocument("Sample.pdf");
//StringBuilder インスタンスを作成する
StringBuilder builder = new StringBuilder();
//PdfTableExtractor インスタンスを作成する
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//PDFのページをループする
for (int pageIndex = 0; pageIndex < pdf.getPages().getCount(); pageIndex++) {
//現在のページからテーブルを PdfTable 配列に抽出する
PdfTable[] tableLists = extractor.extractTable(pageIndex);
//テーブルが見つかった場合
if (tableLists != null && tableLists.length > 0) {
//配列内のテーブルをループする
for (PdfTable table : tableLists) {
//現在のテーブルの行をループする
for (int i = 0; i < table.getRowCount(); i++) {
//現在のテーブルの列をループする
for (int j = 0; j < table.getColumnCount(); j++) {
//現在のテーブルのセルからデータを抽出し、StringBuilder に追加する
String text = table.getText(i, j);
builder.append(text + " | ");
}
builder.append("\r\n");
}
}
}
}
//データを .txt ファイルに書き込む
FileWriter fw = new FileWriter("ExtractTable.txt");
fw.write(builder.toString());
fw.flush();
fw.close();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
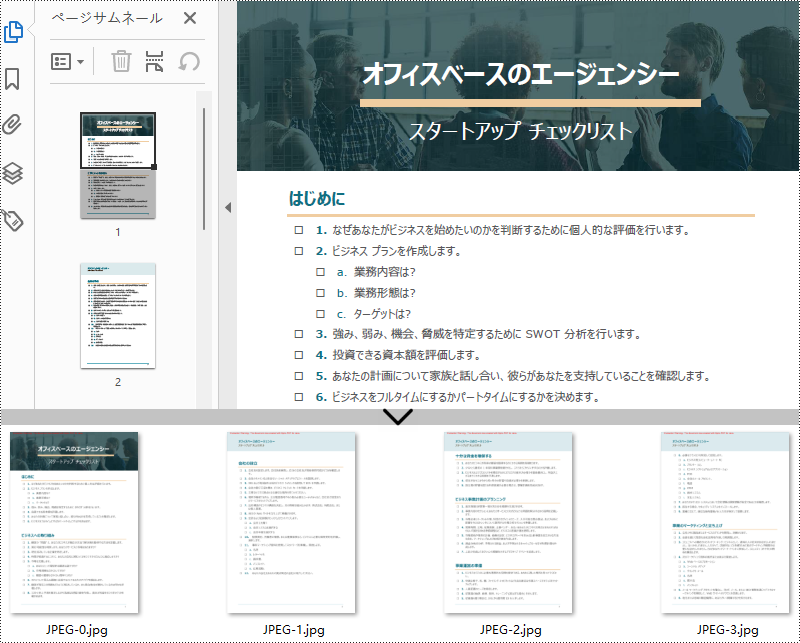
PDF ドキュメントを JPEG や PNG などの画像形式に変換することは、さまざまな理由で便利です。例えば、ソーシャルメディアでコンテンツを共有しやすくしたり、ウェブサイトに埋め込んだり、プレゼンテーションに含めたりすることができます。PDF を画像に変換することによって、PDF 形式を十分にサポートしていないプリンターによる印刷の問題も回避できます。この記事では、Spire.PDF for Java を使用して Java で PDF を JPEG や PNG に変換する方法を説明します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.12.0</version>
</dependency>
</dependencies>Spire.PDF for Java が提供する PdfDocument.saveAsImage() メソッドを使用すると、PDF ドキュメントの特定のページを BufferedImage オブジェクトに変換し、それを .jpg または .png 形式のファイルとして保存することができます。以下に、PDF ドキュメントの各ページを JPEG イメージファイルに変換する手順を示します。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertPdfToJpeg {
public static void main(String[] args) throws IOException {
// PdfDocumentのインスタンスを作成します
PdfDocument pdf = new PdfDocument();
// サンプルのPDFドキュメントを読み込みます
pdf.loadFromFile("サンプル.pdf");
// ページをループします
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 現在のページをバッファイメージとして保存します
BufferedImage image = pdf.saveAsImage(i, PdfImageType.Bitmap, 300, 300);
// RGBタイプのバッファイメージを再作成します
BufferedImage newImg = new BufferedImage(image.getWidth(), image.getHeight(), BufferedImage.TYPE_INT_RGB);
newImg.getGraphics().drawImage(image, 0, 0, null);
// 画像データを.jpgファイルとして書き込みます
File file = new File("output/Images/" + String.format(("JPEG-%d.jpg"), i));
ImageIO.write(newImg, "JPEG", file);
}
pdf.close();
}
}
Spire.PDF for Java を使用して PDF を PNG に変換する手順は次の通りです。
import com.spire.pdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertPdfToPng {
public static void main(String[] args) throws IOException {
// PdfDocumentのオブジェクトを作成します
PdfDocument doc = new PdfDocument();
// サンプルのPDFドキュメントを読み込みます
doc.loadFromFile("サンプル.pdf");
// 生成されるPNGファイルの背景を透明にします
// doc.getConvertOptions().setPdfToImageOptions(0);
// ページをループします
for (int i = 0; i < doc.getPages().getCount(); i++) {
// 現在のページをバッファイメージとして保存します
BufferedImage image = doc.saveAsImage(i);
// 画像データを.pngファイルとして書き込みます
File file = new File("output/Images/" + String.format("PNG-%d.png", i));
ImageIO.write(image, "PNG", file);
}
doc.close();
}
}
PDF ドキュメントの背景が白で、PNG に変換するときにそれを透明にしたい場合は、各ページを BufferedImage オブジェクトに保存する前に、以下のコード行を追加することができます。
doc.getConvertOptions().setPdfToImageOptions(0);結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
HTML(Hypertext Markup Language) は、インターネット上で最も一般的に使用されるテキストマークアップ言語の1つとなり、ほぼすべてのウェブページは HTML を使用して作成されます。HTML には多くのタグや書式情報が含まれていますが、最も価値のあるコンテンツは通常、表示されるテキストです。テキストを HTML ファイルから抽出する方法を知っておくことは重要です。これを利用して編集、AI のトレーニング、またはデータベースへの保存などのタスクに使用するユーザーがいる場合です。この記事では、Java プログラム内で Spire.Doc for Java を使用して HTML からテキストを抽出する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.12.1</version>
</dependency>
</dependencies>Spire.Doc for Java では、Document.loadFromFile(filename, FileFormat.Html) メソッドを使用して HTML ファイルを読み込むことができます。その後、Document.getText() メソッドを使用してブラウザで表示されるテキストを取得し、それを TXT ファイルに書き込むことができます。具体的な手順は以下の通りです:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromHTML {
public static void main(String[] args) throws IOException {
// Documentクラスのオブジェクトを作成します
Document doc = new Document();
// HTMLファイルを読み込みます
doc.loadFromFile("サンプル.html", FileFormat.Html);
// HTMLファイルからテキストを取得します
String text = doc.getText();
// テキストをTXTファイルに書き込みます
FileWriter fileWriter = new FileWriter("HTMLのテキスト.txt");
fileWriter.write(text);
fileWriter.close();
}
}
URL からテキストを抽出するには、ユーザーは HTML ファイルを URL から取得し、その後テキストを抽出するためにカスタムメソッドを作成する必要があります。具体的な手順は以下の通りです:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
public class ExtractTextFromURL {
public static void main(String[] args) throws IOException {
// Documentクラスのオブジェクトを作成します
Document doc = new Document();
// カスタムメソッドを呼び出してURLからHTMLファイルを読み込みます
doc.loadFromFile(readHTML("https://aeon.co/essays/for-rachel-bespaloff-philosophy-was-a-sensual-activity", "output.html"), FileFormat.Html);
// HTMLファイルからテキストを取得します
String urlText = doc.getText();
// テキストをTXTファイルに書き込みます
FileWriter fileWriter = new FileWriter("URLのテキスト.txt");
fileWriter.write(urlText);
fileWriter.close();
}
public static String readHTML(String urlString, String saveHtmlFilePath) throws IOException {
// URLクラスのオブジェクトを作成します
URL url = new URL(urlString);
// URLを開きます
URLConnection connection = url.openConnection();
// URLをHTMLファイルとして保存します
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(saveHtmlFilePath), "UTF-8"));
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
reader.close();
writer.close();
// 保存されたHTMLファイルのファイルパスを返します
return saveHtmlFilePath;
}
}結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation for Java 8.12.1を発表できることをうれしく思います。このバージョンでは、PPT から SVG への変換速度が向上されました。 同時に、パスワード付きストリームファイルの読み込み、座標による不規則な多角形の作成、2点を通る線の描画をサポートする新機能が追加されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2395 | PPTからSVGへの変換速度が向上されました。 |
| New feature | SPIREPPT-2400 | パスワード付きのストリーム ファイルを読み取るメソッドが追加されました。
presentation.loadFromStream(inputStream, FileFormat.AUTO,"password"); |
| New feature | SPIREPPT-2405 | 座標による不規則多角形作成機能が追加されました。
Presentation ppt = new Presentation();
ISlide slide = ppt.getSlides().get(0);
List<Point2D> points = new ArrayList<>();
points.add(new Point2D.Float(50f, 50f));
points.add(new Point2D.Float(50f, 150f));
points.add(new Point2D.Float(60f, 200f));
points.add(new Point2D.Float(200f, 200f));
points.add(new Point2D.Float(220f, 150f));
points.add(new Point2D.Float(150f, 90f));
points.add(new Point2D.Float(50f, 50f));
IAutoShape autoShape = slide.getShapes().appendFreeformShape(points);
autoShape.getFill().setFillType(FillFormatType.NONE);
ppt.saveToFile("out.pptx", FileFormat.PPTX_2013);
ppt.dispose(); |
| New feature | SPIREPPT-2406 | 2点による直線描画機能が追加されました。
Presentation ppt = new Presentation(); ppt.getSlides().get(0).getShapes().appendShape(ShapeType.LINE, new Point2D.Float(50, 70), new Point2D.Float(150, 120)); ppt.saveToFile( "result.pptx ,FileFormat.PPIX_2013), ppt.dispose(). |
Excel は、データ管理と分析に広く使用されている多用途ツールです。 Excel ファイル内の特定のデータを見つけて、更新された値に置き換える必要がある場合があります。この記事では、Spire.XLS for Javaを使用して、Java で Excel のデータを検索して置き換える方法を示します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.12.12</version>
</dependency>
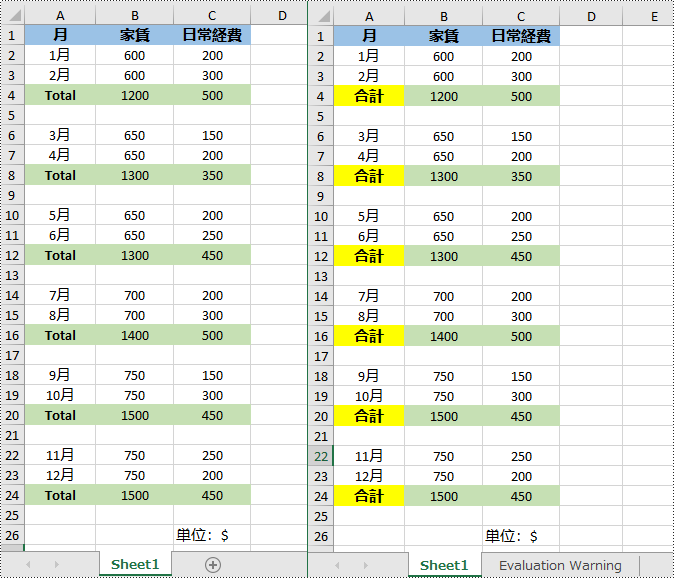
</dependencies>Spire.XLS for Java によって提供される Worksheet.findAllString() メソッドは、Excel ファイル内の特定のテキストを含むセルを検索するのに役立ちます。 見つかったら、CellRange.setText() メソッドを使用して、これらの値を新しい値に置き換えることができます。 手順は次のとおりです。
import com.spire.xls.CellRange;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import java.awt.Color;
public class ReplaceData {
public static void main(String[] args) {
// Workbookクラスのインスタンスを作成する
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.loadFromFile("Sample.xlsx");
// 最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
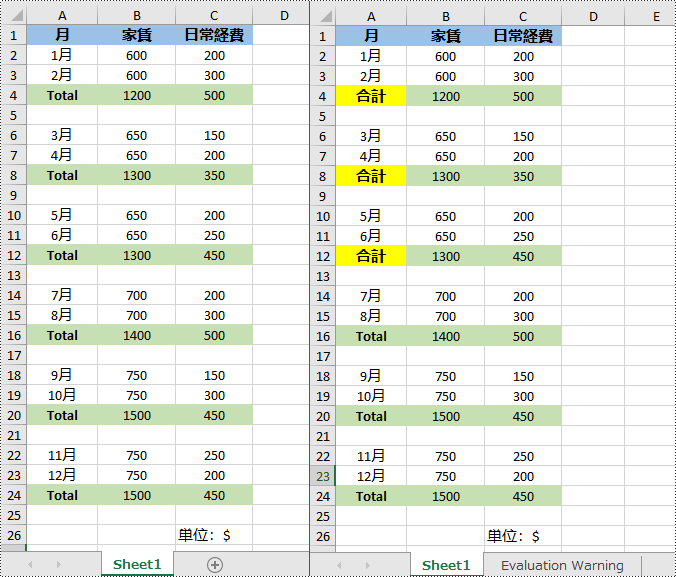
// ワークシート内の特定の文字列値「Total」を持つセルを検索する
CellRange[] cells = worksheet.findAllString("Total", true, true);
// 見つかったセルをループする
for (CellRange cell : cells) {
// セルの値を別の値に置き換える
cell.setText("合計");
// セルの背景色を設定する
cell.getStyle().setColor(Color.YELLOW);
}
// 結果ファイルを保存する
workbook.saveToFile("ReplaceDataInWorksheet.xlsx", ExcelVersion.Version2016);
workbook.dispose();
}
}
特定のセル範囲のデータを置換するには、CellRange.findAllString() メソッドを使用して、目的の値を含む範囲内のセルを検索します。 次に、CellRange.setText() メソッドを使用して、セル値を新しい値に置き換えます。詳細な手順は次のとおりです。
import com.spire.xls.CellRange;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import java.awt.Color;
public class ReplaceDataInCellRange {
public static void main(String[] args) {
// Workbookクラスのインスタンスを作成する
Workbook workbook = new Workbook();
// Excelファイルを読み込む
workbook.loadFromFile("sample.xlsx");
// 最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
// 特定のセル範囲を取得する
CellRange range = worksheet.getCellRange("A1:C12");
// セル範囲内で特定の値「Total」を持つセルを検索する
CellRange[] cells = range.findAllString("Total", true, true);
// 見つかったセルをループする
for (CellRange cell : cells) {
// セルの値を別の値に置き換える
cell.setText("合計");
// セルの背景色を設定する
cell.getStyle().setColor(Color.YELLOW);
}
// 結果ファイルを保存する
workbook.saveToFile("ReplaceDataInCellRange.xlsx", ExcelVersion.Version2016);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
MS Excel において、行は左から右にオブジェクトが配置され、行番号で識別されます。一方、列は上から下にオブジェクトが配置され、列番号で識別されます。Excel データを処理する際には、場合によってはデータテーブルに追加の列と行を挿入したり、不要な列と行を削除したりする必要があります。この記事では、Spire.XLS for Java を使用して、Excel で行と列を挿入または削除する方法を示します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.11.6</version>
</dependency>
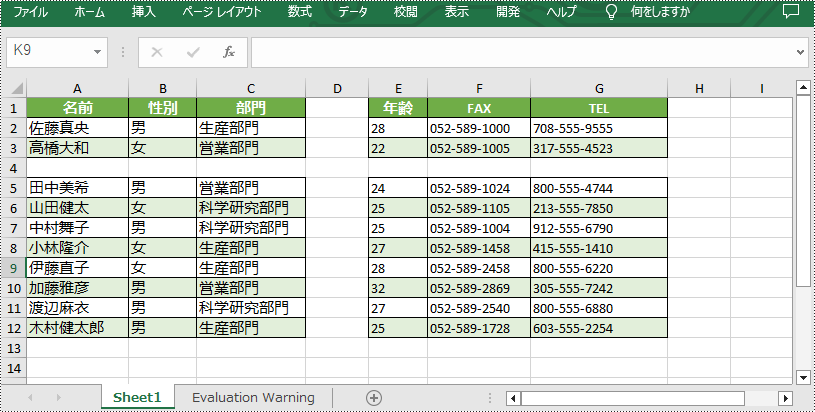
</dependencies>Spire.XLS for Java が提供する Worksheet.insertRow(int rowIndex) メソッドと Worksheet.insertColumn(int columnIndex) メソッドは、それぞれワークシートへの行と列の挿入をサポートします。 詳細な手順は次のとおりです。
import com.spire.xls.*;
public class InsertRowandColumn {
public static void main(String[] args) throws Exception {
//Workbook インスタンスを作成する
Workbook workbook = new Workbook();
//サンプルExcelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
//最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//ワークシートに行を挿入する
worksheet.insertRow(4);
//ワークシートに列を挿入する
worksheet.insertColumn(4);
//結果ファイルを保存する
workbook.saveToFile("InsertRowAndColumn.xlsx", ExcelVersion.Version2013);
workbook.dispose();
}
}
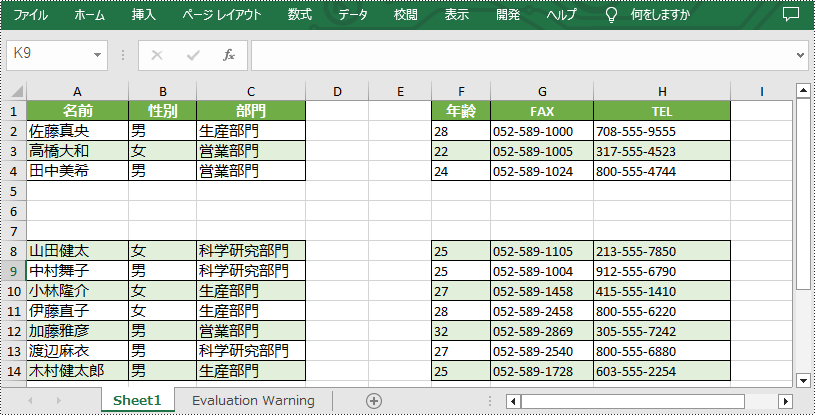
Worksheet.insertRow((int rowIndex, int rowCount) メソッドと Worksheet.insertColumn(int columnIndex, int columnCount) メソッドでは、ワークシートへの複数の行または列の挿入もサポートされています。 詳細な手順は次のとおりです。
import com.spire.xls.*;
public class InsertRowsandColumns {
public static void main(String[] args) throws Exception {
//Workbook インスタンスを作成する
Workbook workbook = new Workbook();
//サンプルExcelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
//最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//ワークシートに複数の行を挿入する
worksheet.insertRow(5, 3);
//ワークシートに複数の列を挿入する
worksheet.insertColumn(4, 2);
//結果ファイルを保存する
workbook.saveToFile("InsertRowsAndColumns.xlsx", ExcelVersion.Version2013);
workbook.dispose();
}
}
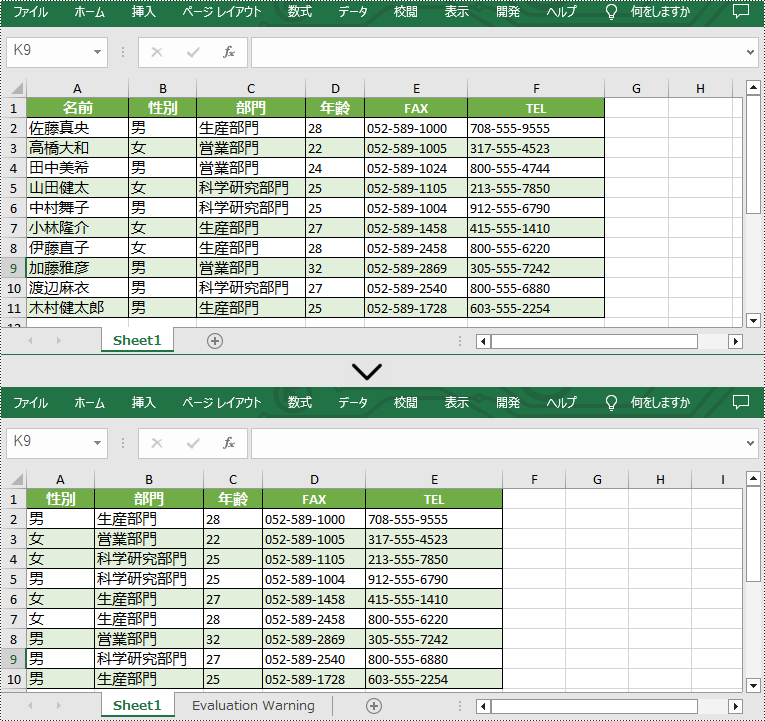
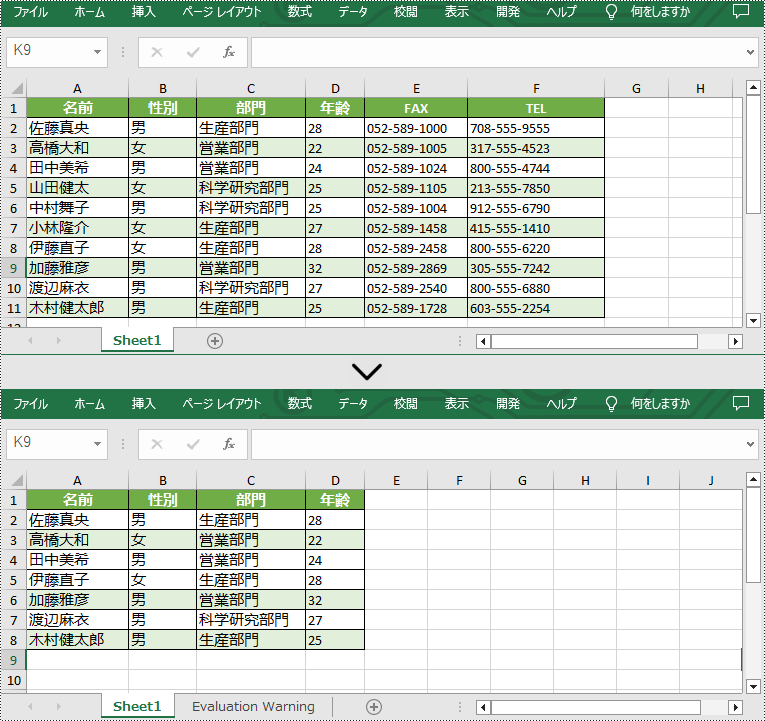
Spire.XLS for Java が提供する Worksheet.deleteRow(int rowindex) メソッドと Worksheet.deleteColumn(int columnIndex) メソッドは、それぞれワークシートから行と列の削除をサポートします。 詳細な手順は次のとおりです。
import com.spire.xls.*;
public class DeleteRowColumn {
public static void main(String[] args) throws Exception {
//Workbook インスタンスを作成する
Workbook workbook = new Workbook();
//サンプルExcelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
//最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//ワークシートから特定の行を削除する
worksheet.deleteRow(4);
//ワークシートから特定の列を削除する
worksheet.deleteColumn(1);
//結果ファイルを保存する
workbook.saveToFile("DeleteRowAndColumn.xlsx", ExcelVersion.Version2013);
workbook.dispose();
}
}
Worksheet.deleteRow(int rowIndex, int rowCount) メソッドと Worksheet.deleteColumn(int columnIndex, int columnCount) メソッドでは、ワークシートから複数の行または列の削除もサポートされています。 詳細な手順は次のとおりです。
import com.spire.xls.*;
public class DeleteRowColumn {
public static void main(String[] args) throws Exception {
//Workbook インスタンスを作成する
Workbook workbook = new Workbook();
//サンプルExcelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
//最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//ワークシートから複数の行を削除する
worksheet.deleteRow(5, 3);
//ワークシートから複数の列を削除する
worksheet.deleteColumn(5, 2);
//結果ファイルを保存する
workbook.saveToFile("DeleteRowsAndColumns.xlsx", ExcelVersion.Version2013);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office for Java 8.12.0を発表できることをうれしく思います。このリリースでは、Spire.XLS for JavaはWPSツールで追加された埋め込み画像の取得をサポートしています。Spire.PDF for JavaではPDF から SVG、PDF/A1B、および PDF/A2A への変換機能が強化されました。さらに、多くの既知のバグも修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4971 | WPS ツールを使用して追加された埋め込み画像を取得するための worksheet.getCellImages() メソッドが追加されました。
Workbook workbook = new Workbook();
workbook.loadFromFile("sample.xlsx");
Worksheet sheet = workbook.getWorksheets().get(0);
ExcelPicture[] picture = sheet.getCellImages();
for (int i = 0; i < picture.length; i++) {
ExcelPicture ep = picture[i];
BufferedImage image = ep.getPicture();
ImageIO.write(image,"PNG", new File(outputFile + String.format("pic_%d.png",i)));
} |
| Bug | SPIREXLS-4971 | WPS ツールで追加された埋め込み画像を取得するときに、プログラムが「Index is less than 0 or more than or equal to the list count.」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4996 | Excel 文書を読み込むときにプログラムがハングする問題が修正されました。 |
| Bug | SPIREXLS-5010 | 取得したテキストのフォントサイズが正しくない問題が修正されました。 |
| Bug | SPIREXLS-5021 | 保存されたExcel文書内のグラフの座標軸データが正しくない問題が修正されました。 |
| Bug | SPIREXLS-5024 | XLSM を PDF に変換するときに、プログラムが「java.lang.StringIndexOutOfBoundsException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4966 | Excel ワークシートを HTML に変換するときに、プログラムが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4967 | ExcelをHTMLに変換した後、テキストコンテンツに多くの余分な「0」が表示される問題が修正されました。 |
| Bug | SPIREXLS-4968 | 行の高さが自動調整される Excel を PDF に変換した後、セルの内容が部分的に失われる問題が修正されました。 |
| Bug | SPIREXLS-4970 | 結合されたセルの取得内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4975 | 文字列を検索すると間違った結果が返される問題が修正されました。 |
| Bug | SPIREXLS-4977 | ワークシートをコピーするときに、チャート参照が誤って更新される問題が修正されました。 |
| Bug | SPIREXLS-4990 | DisplayedText 値の取得が正しくない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-6265 | Linux システム上で PDF を SVG に変換した後、結果文書が空白になる問題が修正されました。 |
| Bug | SPIREPDF-6363 | PDFをPDF/A1Bに変換した後、結果が非標準になる問題が修正されました。 |
| Bug | SPIREPDF-6394 | PDF を SVG に変換するときに、プログラムが「NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6396 | PDFを追加してロックした後、印刷するとスタンプが失われる問題が修正されました。 |
| Bug | SPIREPDF-6401 | PDFをPDF/A2Aに変換した後、コンテンツが失われる問題が修正されました。 |
Spire.Office 8.12.2を発表できることを嬉しく思います。このバージョンでは、Spire.DocはWordからPCLやPostScriptへのテキスト整形機能をサポートしています。Spire.Presentationではマスターページを画像に変換する機能をサポートしています。Spire.PDFViewer ではWinFormプロジェクトで「Ctrl+スクロール」によるズームをサポートしています。さらに、多くの既知の問題も修正しました。詳細は以下の内容を読んでください。
このバージョンでは、Spire.Doc,Spire.PDF,Spire.XLS,Spire.Email,Spire.DocViewer, Spire.PDFViewer,Spire.Presentation,Spire.Spreadsheet, Spire.OfficeViewer, Spire.Barcode, Spire.DataExportの最新バージョンが含まれています。
| カテゴリー | ID | 説明 |
| New feature | - | WordからPostScriptへのテキスト整形機能が追加されました(.NET 4.6 以降のバージョンをサポート)。
Document document = new Document();
document.LoadFromFile("input.docx");
document.LayoutOptions.UseHarfBuzzTextShaper = true; // trueで有効、falseで無効
document.SaveToFile("output.ps", FileFormat.PostScript); |
| New feature | - | WordからPCLへのテキスト整形機能をサポートします。
Document document = new Document();
document.LoadFromFile("input.docx");
document.LayoutOptions.UseHarfBuzzTextShaper = true; // Enable with true, disable with false
document.SaveToFile("output.pcl", FileFormat.PCL); |
| New feature | SPIREDOC-10007 | 文書が暗号化されているかどうかを判断する機能をサポートします。
Document.IsPassWordProtected("sample.docx"); |
| Bug | SPIREDOC-9615 | WordをPDFに変換後、改行が正しく表示されない問題が修正されました。 |
| Bug | SPIREDOC-9859 SPIREDOC-9890 |
LaTeXの数式が正しく解析されない問題が修正されました。 |
| Bug | SPIREDOC-9976 | 正規表現を使用してテキストを検索する際に一致が失敗する問題が修正されました。 |
| Bug | SPIREDOC-9981 | WordをXPSに変換後、テーブルの枠線が消える問題が修正されました。 |
| Bug | SPIREDOC-9997 | HTMLをWordに変換後、記号が誤って英字として認識される問題が修正されました。 |
| Bug | SPIREDOC-10029 | メールマージ機能を実行した後、入力されたデータの計算結果が正しくなくなる問題が修正されました。 |
| Bug | SPIREDOC-10036 | WordをPDFに変換後、テーブルのヘッダー部分が切り取られる問題が修正されました。 |
| Bug | SPIREDOC-10037 | 行を追加した後にテーブルをPDFに変換すると、幅が変更されてしまう問題が修正されました。 |
| Bug | SPIREDOC-10039 | ブックマークの内容をコピーする際に、「System.ArgumentException」 のエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-10081 | ブックマークの内容をコピーする際に、「System.NullReferenceException」のエラーが発生する問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2397 | マスターページを画像に変換する機能をサポートしています。
Presentation ppt = new Presentation();
ppt.LoadFromFile("1.pptx");
for (int i = 0; i < ppt.Masters[0].Layouts.Count; i++)
{
Image image = ppt.Masters[0].Layouts[i].SaveAsImage();
String fileName = String.Format("{0}.png", i);
image.Save(fileName, System.Drawing.Imaging.ImageFormat.Png);
}
ppt.Dispose(); |
| Bug | SPIREPPT-2394 | PPT を PDF に変換した後のコンテンツ レイアウトが正しくない問題が修正されました。 |
| Bug | SPIREPPT-2396 | グラフのラベルの位置を変更した後に効果が正しくなくなる問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPDFVIEWER-579 | WinFormプロジェクトで「Ctrl+スクロール」によるズームをサポートしています。
this.KeyPreview = true; this.KeyDown += new System.Windows.Forms.KeyEventHandler(this.Form1_KeyDown); this.KeyUp += new System.Windows.Forms.KeyEventHandler(Form1_KeyUp); this.MouseWheel += new System.Windows.Forms.MouseEventHandler(Form1_MouseWheel); private bool m_PressCtrl = false;
private float m_ZoomFactor = 1.0f;
private void Form1_KeyDown(object sender, KeyEventArgs e)
{
m_PressCtrl = e.Control;
}
private void Form1_KeyUp(object sender, KeyEventArgs e)
{
m_PressCtrl = false;
}
private float[] array = new float[] { 0.5f, 0.75f, 1f, 1.25f, 1.5f, 2f, 4f };
private int index = 2;
private void Form1_MouseWheel(object sender, MouseEventArgs e)
{
if (m_PressCtrl)
{
if (e.Delta > 0)
{
index = index < 6 ? index + 1 : 6;
}
if (e.Delta < 0)
{
index = index == 0 ? 0 : index - 1;
}
this.pdfViewer1.SetZoomFactor(array[index]);
}
} |
| Bug | SPIREPDFVIEWER-577 | テキストコンテンツが表示できない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-6041 | PDF フォームフィールドをフラット化した後に 2 ページ目以降のデータが失われる問題が修正されました。 |
| Bug | SPIREPDF-6331 | SVGから変換したPDF文書がAdobeで開けない問題が修正されました。 |
| Bug | SPIREPDF-6351 | テキスト抽出に失敗する問題が修正されました。 |
| Bug | SPIREPDF-6375 | テキストのハイライト機能が効かない問題が修正されました。 |
| Bug | SPIREPDF-6384 | OFDをPDFに変換するときに、プログラムが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6385 SPIREPDF-6390 |
PDF文書を読み込むときに、プログラムが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6393 | PDF 文書を小冊子として印刷するときに、プログラムが「System.NullReferenceException」をスローする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4838 | マルチスレッド並列でワークシートをHTMLに変換するときに、「System.IndexOutOfRangeException」と 「System.NullReferenceException」が発生する問題が修正されました。 |
| Bug | SPIREXLS-4899 | VLOOKUP 関数の解析が正しく行われない問題が修正されました。 |
| Bug | SPIREXLS-4969 | セルの色の透明度値が正しく取得されない問題が修正されました。 |
| Bug | SPIREXLS-4972 | Excel を PDF に変換する際にコンテンツが重複する問題が修正されました。 |
| Bug | SPIREXLS-4974 | 文書の読み込み時に、「 System.ArgumentNullException」が発生する問題が修正されました。 |
| Bug | SPIREXLS-4980 | Excel を PDF に変換する際に 、「Shape failing to render!」が発生する問題が修正されました。 |
| Bug | SPIREXLS-4993 | Excel ドキュメントをマージする際に 、「System.NullReferenceException 」が発生する問題が修正されました。 |
| Bug | SPIREXLS-4998 | データで MarkerDesigner テンプレートを埋める際に失敗する問題が修正されました。 |
| Bug | SPIREXLS-5000 | 行を削除した後、データの有効性検証時に、「System.ArgumentOutOfRangeException」が発生する問題が修正されました。 |
| Bug | SPIREXLS-5004 | 一部の数式の計算が失敗する問題が修正されました。 |
| Bug | SPIREXLS-5005 | 追加されたデジタル署名の署名時間が実際の時間よりも8時間長く表示される問題が修正されました。 |
| Bug | SPIREXLS-5009 | CLEAN 関数の読み取りに失敗する問題が修正されました。 |
| Bug | SPIREXLS-5015 | 文書の読み込み時に、「 System.FormatException」 が発生する問題が修正されました。 |
| Bug | SPIREXLS-5019 | HTML の読み取り時に 、「Cannot read that as a ZipFile」が発生する問題が修正されました。 |
Spire.PDFViewer 7.12.3のリリースをお知らせいたします。このバージョンでは、WinFormプロジェクトで「Ctrl+スクロール」によるズームをサポートしています。また、テキストコンテンツが表示できない問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDFVIEWER-579 | WinFormプロジェクトで「Ctrl+スクロール」によるズームをサポートしています。
this.KeyPreview = true; this.KeyDown += new System.Windows.Forms.KeyEventHandler(this.Form1_KeyDown); this.KeyUp += new System.Windows.Forms.KeyEventHandler(Form1_KeyUp); this.MouseWheel += new System.Windows.Forms.MouseEventHandler(Form1_MouseWheel); private bool m_PressCtrl = false;
private float m_ZoomFactor = 1.0f;
private void Form1_KeyDown(object sender, KeyEventArgs e)
{
m_PressCtrl = e.Control;
}
private void Form1_KeyUp(object sender, KeyEventArgs e)
{
m_PressCtrl = false;
}
private float[] array = new float[] { 0.5f, 0.75f, 1f, 1.25f, 1.5f, 2f, 4f };
private int index = 2;
private void Form1_MouseWheel(object sender, MouseEventArgs e)
{
if (m_PressCtrl)
{
if (e.Delta > 0)
{
index = index < 6 ? index + 1 : 6;
}
if (e.Delta < 0)
{
index = index == 0 ? 0 : index - 1;
}
this.pdfViewer1.SetZoomFactor(array[index]);
}
} |
| Bug | SPIREPDFVIEWER-577 | テキストコンテンツが表示できない問題が修正されました。 |





